La última vez obtuvimos un generador de analizador PEG simple. Ahora mostraré qué hace realmente el analizador generado al analizar el programa. Me sumergí en el mundo retro del arte ASCII, en particular, una biblioteca llamada "maldiciones", que está disponible en la distribución estándar de Python para Linux y Mac, así como un complemento para Windows.
Contenido de la serie Python PEG Parser 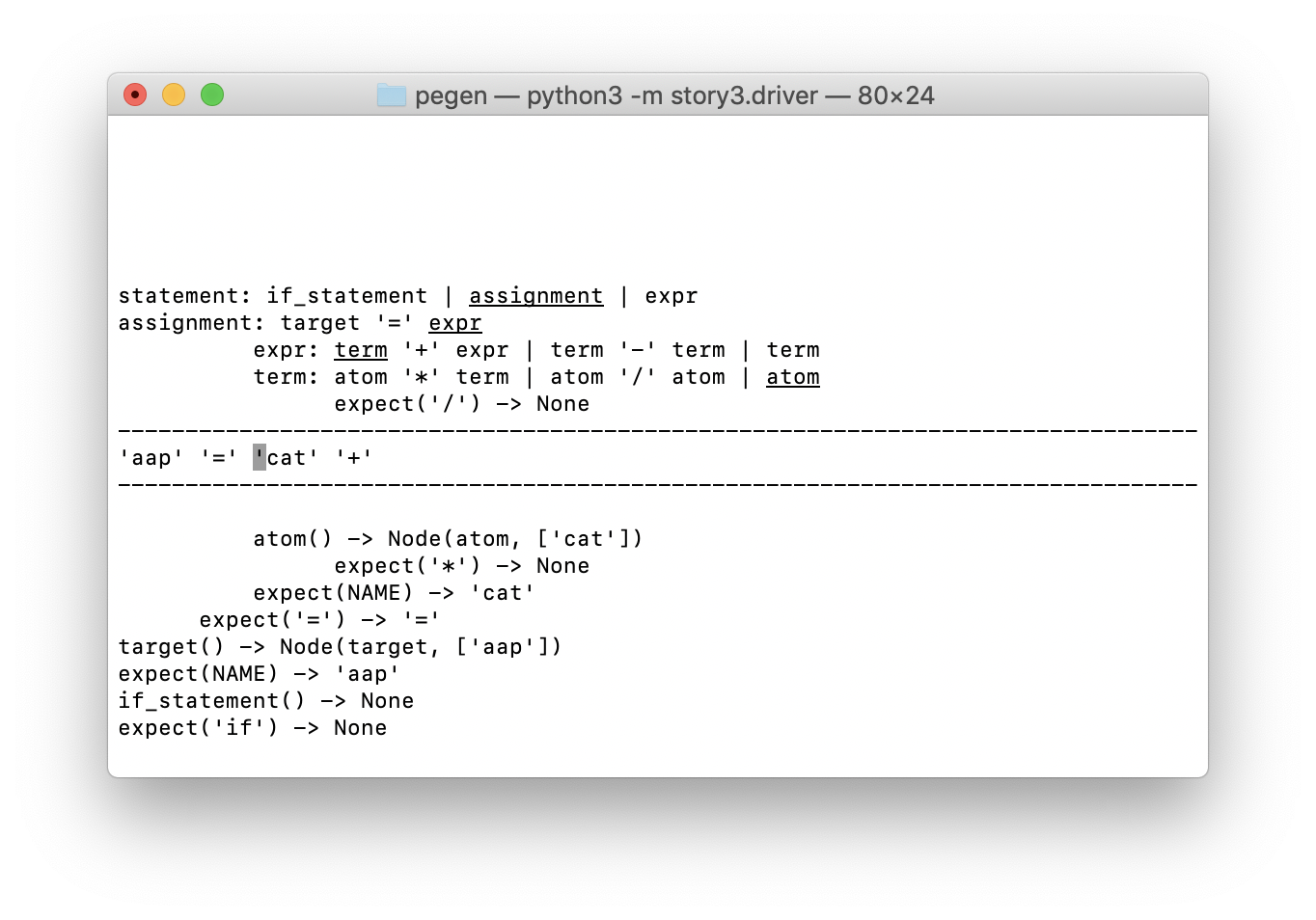
<Al final del artículo, se entrega un gif debajo del spoiler. Me pareció más comprensible que una imagen estática>
Veamos la visualización. La pantalla se divide en tres partes, como es habitual en ASCII, con una línea de guión:
- La parte superior muestra la pila de llamadas del analizador, que, como recordará, es un analizador de descenso recursivo con retorno ilimitado. A continuación explicaré con más detalle.
- La sección de una sola línea en el medio muestra el contenido del búfer de token con un cursor apuntando al token que se analizará a continuación.
- A continuación, visualizamos el caché utilizado por el algoritmo del analizador packrat. La grabación de sus elementos es algo similar a algunos elementos de la pila del analizador (con resultados).
Lo principal que necesita saber para comprender esta visualización es que la sangría de las líneas en las partes superior e inferior corresponde al búfer de token.
- Las primeras dos líneas (comenzando con la
statement y la assignment ) muestran las llamadas a los métodos analizadores correspondientes que están haciendo el análisis en este momento. Se llamaron cuando el puntero del tokenizer estaba antes del primer token ( 'aap' ). - Las siguientes dos líneas (comenzando con
expr y term ) están alineadas con el comienzo del token 'cat' , donde se llamaron los métodos analizadores correspondientes. - La quinta y última línea de representación de la pila muestra la llamada a
expect('/') , que devuelve None . Se ofreció como voluntario en la posición de token '+' .
La sangría de elementos en el caché también corresponde a una posición en el búfer de token. Por ejemplo, en la parte inferior hay entradas negativas en el caché, se obtuvieron al buscar el token 'if' y la regla if_statement al comienzo del búfer de token. También encontramos entradas de caché exitosas para el token '=' y para NAME (en particular, 'cat' ) correspondientes a otras posiciones de entrada.
Tanto en el bloque de pila del analizador como en el bloque de caché, las llamadas devueltas se muestran como function(args) -> result . A veces, se muestran varios métodos devueltos en la pila del analizador: hice esto para reducir la fluctuación de texto de los frecuentes cambios de contenido.
(Hablando de jitter, las líneas superiores de la pila del analizador se mueven hacia arriba cuando se agrega una llamada a la pila y caen cuando se retira de la pila. Es decir, cada nueva llamada se inserta en la parte inferior del bloque de visualización de la pila, desplazando las líneas existentes hacia arriba. Me parece a mí que mirar esta parte de la pantalla no es un problema, al menos para mí. Probablemente, una parte importante de nuestro cerebro se dedica a rastrear objetos en movimiento. :-)
El caché se representa como LRU, con elementos de uso frecuente en la parte superior; los más raros bajan de la pantalla. (El prototipo de analizador Packrat que mostré en artículos anteriores no usa LRU, pero probablemente sea una buena idea optimizar el consumo de memoria).
Veamos algunos detalles al representar la pila de análisis. Las cuatro entradas principales corresponden a los métodos del analizador que todavía se están procesando, cada línea es una línea de la gramática. El elemento resaltado es el que generó el próximo desafío.
Es decir a juzgar por la captura de pantalla, estamos en la segunda alternativa para la statement , a saber, la assignment . En esta regla, estamos en el tercer punto, a saber, expr . En la regla expr , solo estamos en el primer párrafo de la primera alternativa ( term '+' expr ); y en la regla del term estamos en la última alternativa ( atom ).
A continuación vemos el resultado que condujo al fracaso de la segunda alternativa ( atom '/' term ): expect('/') -> None sangría con el token '+' . En el siguiente paso, veremos cómo se mete en el caché.
¡Pero seguramente preferirías ver toda la animación tú mismo!
Grabé un análisis completo del programa de ejemplo canónico También puedes jugar con código listo, pero ten en cuenta que esto no es deporte.
Cuando mira un GIF grabado , puede parecer un poco extraño que a veces no se muestre el siguiente token (por ejemplo, al principio la pila se incrementa en varios registros antes de que se detecte el token 'aap' ). Esto es exactamente lo que ve el analizador: el token buffer se llena perezosamente. Los tokens no se escanean hasta que el analizador los solicite llamando a la función expect() . Tan pronto como el token ingresa al búfer, permanece allí, incluso si el analizador rebobina la secuencia de tokens. El seguimiento inverso se muestra en el búfer de token con un cursor que salta a la izquierda; Hay muchas de esas situaciones en el registro. También puede observar el llenado de caché cuando el analizador no realiza llamadas recursivas adicionales. (Tengo que resaltar cuando esto sucede, pero no tuve suficiente tiempo).
La próxima semana desarrollaré un analizador, quizás agregue mi perspectiva sobre las reglas de la izquierda de la gramática recursiva. (¡Son geniales!)
Agradecimientos: para el registro utilicé ttygif de Ilya Choli y ttyrec de Matthew Jording.
Licencia para este artículo y código citado: CC BY-NC-SA 4.0