
La infraestructura web moderna consta de muchos componentes para diversos fines, con evidentes y poco interconectados. Esto se hace especialmente evidente cuando se utilizan aplicaciones que utilizan diferentes paquetes de software, que con la llegada de los microservicios comenzaron a ocurrir literalmente en cada paso. Los factores externos (API de terceros, servicios, etc.) se agregan a la "diversión" general, lo que complica una imagen ya difícil.
En general, incluso si estas aplicaciones van a estar unidas por ideas y soluciones arquitectónicas comunes, para eliminar problemas inusuales en ellas, a menudo tienen que atravesar los próximos entornos desconocidos. Si ocurren tales problemas es solo cuestión de tiempo. Estos son los ejemplos de nuestra última práctica a la que se dedica este artículo. Reparto: Golang, Sentry, RabbitMQ, nginx, PostgreSQL y otros.
Historia No. 1. Golang y HTTP / 2
La ejecución de un punto de referencia que realiza muchas solicitudes HTTP a una aplicación web ha dado lugar a resultados inesperados. Una aplicación Go simple en el proceso de referencia va a otra aplicación Go ubicada detrás de la entrada / openresty. Cuando HTTP / 2 está habilitado, obtenemos errores con el código 400 para algunas solicitudes. Para comprender el motivo de este comportamiento, eliminamos la aplicación Go en el otro extremo de la cadena e hicimos una ubicación simple en Ingress, que siempre devuelve 200. ¡El comportamiento no ha cambiado!
Luego se decidió reproducir el script fuera del entorno de Kubernetes, en una pieza diferente de hardware. El resultado fue un Makefile, con la ayuda de la cual se lanzan dos contenedores: en uno, puntos de referencia que van a nginx, en el otro, en Apache. Ambos escuchan HTTP / 2 con un certificado autofirmado. El tiempo de funcionamiento final se ve en
este repositorio .
Ejecute los puntos de referencia con
concurrency=200 :
1.1. Nginx:
Completed 0 requests Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests ----- Bench results begin ----- Requests per second: 10336.09 Failed requests: 1623 ----- Bench results end -----
1.2. Apache
… ----- Bench results begin ----- Requests per second: 11427.60 Failed requests: 0 ----- Bench results end -----
Suponemos que el punto aquí es una implementación menos estricta de HTTP / 2 en Apache.
Probemos con
concurrency=1000 :
2.1. Nginx:
… ----- Bench results begin ----- Requests per second: 11274.92 Failed requests: 4205 ----- Bench results end -----
2.2. Apache
… ----- Bench results begin ----- Requests per second: 11211.48 Failed requests: 5 ----- Bench results end -----
Al mismo tiempo, notamos que los resultados
no se reproducen siempre : algunos de los lanzamientos pasan sin problemas.
Una búsqueda de problemas en el github del proyecto Golang condujo a
# 25009 y
# 32441 . A través de ellos fuimos a
PR 903 : ¡deshabilitamos HTTP / 2 en Go por defecto!
Interpretar los resultados de referencia sin profundizar en la arquitectura de los servidores web anteriores es bastante difícil. En un caso específico, fue suficiente deshabilitar HTTP / 2 para el servicio especificado.
Historia No. 2. Viejo symfony y centinela
En uno de los proyectos, una versión muy antigua del framework PHP de Symfony (v2.3) sigue funcionando. Un antiguo cliente de Raven y una clase autoescrita en PHP se adjuntan "en el kit", lo que complica un poco la depuración.
Después de la transferencia de uno de los servicios en Kubernetes a Sentry, utilizado para rastrear errores en la aplicación de este proyecto, los eventos de repente dejaron de llegar. Para reproducir este comportamiento, utilizamos ejemplos del sitio web de Sentry, tomamos dos opciones y copiamos el DSN de la configuración de Sentry. Visualmente, todo funcionó: los mensajes de error (supuestamente) se enviaron uno tras otro.
Opción de verificación de JavaScript:
<!DOCTYPE html> <html> <body> <script src="https://browser.sentry-cdn.com/5.6.3/bundle.min.js" integrity="sha384-/Cqa/8kaWn7emdqIBLk3AkFMAHBk0LObErtMhO+hr52CntkaurEnihPmqYj3uJho" crossorigin="anonymous"> </script> <h2>JavaScript in Body</h2> <p id="demo">A Paragraph.</p> <button type="button" onclick="myFunction()">Try it</button> <script> Sentry.init({ dsn: 'http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12' }); try { throw new Error('Caught'); } catch (err) { Sentry.captureException(err); } </script> </body> </html>
Del mismo modo en Python:
from sentry_sdk import init, capture_message init("http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12") capture_message("Hello World")
Sin embargo, no entraron en Sentry. Al enviar un mensaje, se crea la ilusión de que el mensaje se envió, porque los clientes generan inmediatamente un hash para el problema.
Como resultado, el problema se resolvió de manera muy simple: el envío de eventos fue a HTTP, y el servicio Sentry solo escuchó HTTPS. Se proporcionó una redirección de HTTP a HTTPS, pero el cliente anterior (el código en el lado de Symfony) no pudo seguir las redirecciones, lo que no espera de forma predeterminada en estos días.
Historia No. 3. RabbitMQ y proxy de terceros
En un proyecto, la nube Evotor se usa para conectar cajas registradoras. De hecho, funciona como un proxy: las solicitudes POST de Evotor van directamente a RabbitMQ, a través del
complemento STOMP implementado a través de conexiones WebSocket.
Uno de los desarrolladores realizó solicitudes de prueba utilizando Postman y recibió las respuestas esperadas de
200 OK , sin embargo, las solicitudes a través de la nube llevaron a un inesperado
405 Method Not Allowed .
200 OK source: kubernetes namespace: kube-nginx-ingress host: kube-node-2 pod_name: nginx-2bpt7 container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:42:50+00:00 request_id: 1271dba228f0943ab2df0196ff0d7f67 user: client address: 100.200.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.eeeeffff111:1.onlinecassa:55556666/get request_query: referrer: user_agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 content_kind: cacheable namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 2538 nginx_upstream_response_time: 0.008 nginx_upstream_status: 200 bytes_received: 757 bytes_sent: 1254 request_time: 0 status: 200 upstream_response_time: 0 upstream_retries: 0
405 Método no permitido source: kubernetes namespace: kube-nginx-ingress host: kube-node-1 pod_name: nginx-4xx6h container_name: nginx stream: stdout app: nginx controller-revision-hash: 5bdbfd564 pod-template-generation: 25 time: 2019-09-10T09:46:26+00:00 request_id: b8dd789604864c95b4af499ed6805630 user: client address: 200.100.300.400 protocol: HTTP/1.1 scheme: http method: POST host: rmq-review.kube-dev.client.domain path: /api/queues/vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get request_query: referrer: user_agent: ru.evotor.proxy/37 content_kind: cache-headers-not-present namespace: review ingress: stomp-ws service: rabbitmq service_port: stats vhost: rmq-review.kube-dev.client.domain location: / nginx_upstream_addr: 10.127.1.1:15672 nginx_upstream_bytes_received: 134 nginx_upstream_response_time: 0.004 nginx_upstream_status: 405 bytes_received: 878 bytes_sent: 137 request_time: 0 status: 405 upstream_response_time: 0 upstream_retries: 0
Solicitud de tcpdump de Evotor 200.100.300.400.21519 > 100.200.400.300: Flags [P.], cksum 0x8e29 (correct), seq 1:879, ack 1, win 221, options [nop,nop,TS val 2313007107 ecr 79097074], length 878: HTTP, length: 878 POST /api/queues//vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 device-model: ST-5 device-os: android Accept-Encoding: gzip content-type: application/json; charset=utf-8 connection: close accept: application/json x-original-forwarded-for: 10.11.12.13 originhost: rmq-review.kube-dev.client.domain x-original-uri: /api/v2/apps/e114-aaef-bbbb-beee-abadada44ae/requests x-scheme: https accept-encoding: gzip user-agent: ru.evotor.proxy/37 Authorization: Basic X-Evotor-Store-Uuid: 20180417-73DC-40C9-80B7-00E990B77D2D X-Evotor-Device-Uuid: 20190909-A47B-40EA-806A-F7BC33833270 X-Evotor-User-Id: 01-000000000147888 Content-Length: 58 Host: rmq-review.kube-dev.client.domain {"count":1,"encoding":"auto","ackmode":"ack_requeue_true"}[!http] 12:53:30.095385 IP (tos 0x0, ttl 64, id 5512, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 200.100.300.400.21519: Flags [.], cksum 0xfa81 (incorrect -> 0x3c87), seq 1, ack 879, win 60, options [nop,nop,TS val 79097122 ecr 2313007107], length 0 12:53:30.096876 IP (tos 0x0, ttl 64, id 5513, offset 0, flags [DF], proto TCP (6), length 189) 100.200.400.300:80 > 200.100.300.400.21519: Flags [P.], cksum 0xfb0a (incorrect -> 0x03b9), seq 1:138, ack 879, win 60, options [nop,nop,TS val 79097123 ecr 2313007107], length 137: HTTP, length: 137 HTTP/1.1 405 Method Not Allowed Date: Tue, 10 Sep 2019 10:53:30 GMT Content-Length: 0 Connection: close allow: HEAD, GET, OPTIONS
Solicitud de tcpdump hecha por curl 777.10.74.11.61211 > 100.200.400.300:80: Flags [P.], cksum 0x32a8 (correct), seq 1:397, ack 1, win 2052, options [nop,nop,TS val 734012594 ecr 4012360530], length 396: HTTP, length: 396 POST /api/queues/%2Fvhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1 Host: rmq-review.kube-dev.client.domain User-Agent: curl/7.54.0 Authorization: Basic = Content-Type: application/json Accept: application/json Content-Length: 58 {"count":1,"ackmode":"ack_requeue_true","encoding":"auto"}[!http] 12:40:11.001442 IP (tos 0x0, ttl 64, id 50844, offset 0, flags [DF], proto TCP (6), length 52) 100.200.400.300:80 > 777.10.74.11.61211: Flags [.], cksum 0x2d01 (incorrect -> 0xfa25), seq 1, ack 397, win 59, options [nop,nop,TS val 4012360590 ecr 734012594], length 0 12:40:11.017065 IP (tos 0x0, ttl 64, id 50845, offset 0, flags [DF], proto TCP (6), length 2621) 100.200.400.300:80 > 777.10.74.11.61211: Flags [P.], cksum 0x370a (incorrect -> 0x6872), seq 1:2570, ack 397, win 59, options [nop,nop,TS val 4012360605 ecr 734012594], length 2569: HTTP, length: 2569 HTTP/1.1 200 OK Date: Tue, 10 Sep 2019 10:40:11 GMT Content-Type: application/json Content-Length: 2348 Connection: keep-alive Vary: Accept-Encoding cache-control: no-cache vary: accept, accept-encoding, origin
El ojo entrenado de un ingeniero ve inmediatamente la diferencia:
- curl:
POST /api/queues/%2Fclient… - Evotor:
POST /api/queues//client…
El caso fue que en un caso
//vhost %2Fvhost incomprensible (para RabbitMQ)
//vhost y en el otro -
%2Fvhost , que es el comportamiento esperado cuando:
# rabbitmqctl list_vhosts Listing vhosts ... /vhost
En el
tema del proyecto RabbitMQ sobre este tema, el desarrollador explica:
No reemplazaremos la codificación%. Es una forma estándar de codificación de ruta URL y lo ha sido durante siglos. Suponiendo que la codificación porcentual en las herramientas basadas en HTTP desaparecerá debido incluso al marco más popular, suponiendo que tales rutas de URL sean "maliciosas" es miope e ingenua. El nombre de host virtual predeterminado se puede cambiar a cualquier valor (como uno que no utilice barras o cualquier otro carácter que requiera una codificación%) y al menos con la versión Pivotal BOSH de RabbitMQ, el host virtual predeterminado se elimina en el momento de la implementación. .
El problema se resolvió sin una mayor participación de nuestros ingenieros (en el lado de Evotor después de contactarlos).
Historia No. 4. Gene en PostgreSQL
PostgreSQL tiene un índice muy útil, que a menudo se olvida. Esta historia comenzó con quejas sobre los frenos en la aplicación. En un
artículo reciente, ya dimos un ejemplo de un flujo de trabajo aproximado al analizar tales situaciones. Y aquí nuestro APM -
Atatus - mostró la siguiente imagen:

A las 10 de la mañana hay un aumento en el tiempo que la aplicación pasa trabajando con la base de datos. Como se esperaba, la razón radica en las respuestas lentas del DBMS. Para nosotros, analizar consultas, identificar áreas problemáticas e índices "colgantes" es una rutina comprensible. El
okmeter que utilizamos ayuda
mucho : hay paneles estándar para monitorear el estado de los servidores y la capacidad de construir
rápidamente el nuestro, con el resultado de métricas problemáticas:

Los gráficos de carga de la CPU indican que una de las bases de datos está cargada al 100%. Por qué Los nuevos paneles PostgreSQL le preguntarán:

La causa de los problemas es evidente de inmediato: el principal consumidor de la CPU:
SELECT u.* FROM users u WHERE u.id = ? & u.field_1 = ? AND u.field_2 LIKE '%somestring%' ORDER BY u.id DESC LIMIT ?
Teniendo en cuenta el plan de trabajo de la consulta del problema, descubrimos que el filtrado por campos indexados de la tabla ofrece una selección demasiado grande: la base de datos recibe más de 70 mil filas por
id y
field_1 , y luego busca una subcadena entre ellas. Resulta que
LIKE en una subcadena itera sobre una gran cantidad de datos de texto, lo que conduce a una desaceleración grave en la ejecución de consultas y un aumento en la carga de la CPU.
Aquí puede notar correctamente que no se descarta un problema arquitectónico (se requiere una corrección lógica de la aplicación o incluso un motor de texto completo ...), pero no hay tiempo para volver a trabajar, pero debería haber funcionado rápidamente hace 15 minutos. Al mismo tiempo, la palabra de búsqueda es en realidad un identificador (y ¿por qué no en un campo separado? ..), que produce unidades de líneas. De hecho, si pudiéramos componer un índice en este campo de texto, todos los demás serían innecesarios.La solución actual final es agregar un índice GIN para
field_2 . Ese es el héroe del día, ese mismo "genio". En resumen, GIN es un tipo de índice que funciona muy bien en la búsqueda de texto completo, acelerándolo cualitativamente. Puede leer más sobre esto, por ejemplo, en
este maravilloso material .

Como puede ver, esta operación simple permitió eliminar la carga adicional, y con ella, y ahorrar dinero para el cliente.
Historia No. 5. Almacenamiento en caché de s3 en nginx
El almacenamiento en la nube compatible con S3 ha estado firmemente en la lista de tecnologías utilizadas por muchos proyectos. Si necesita un almacenamiento de imágenes confiable para su sitio o para datos de red neuronal, Amazon S3 es una excelente opción. La fiabilidad del almacenamiento y la alta disponibilidad de datos (y la falta de la necesidad de "cercar el jardín") es cautivadora.
Sin embargo, a veces para ahorrar dinero, porque generalmente el pago de S3 va por solicitudes y por tráfico, una buena solución es instalar un servidor proxy de almacenamiento en caché frente al almacenamiento. Este método reducirá los costos cuando se trata, por ejemplo, de avatares de usuarios, de los cuales hay muchos en cada página.
¿Parece que es más fácil que tomar nginx y configurar proxies con almacenamiento en caché, revalidación, actualización de fondo y otro blackjack? Sin embargo, como en otros lugares, hay algunos matices ...
La configuración aproximada de tal proxy con almacenamiento en caché se veía así:
proxy_cache_key $uri; proxy_cache_methods GET HEAD; proxy_cache_lock on; proxy_cache_revalidate on; proxy_cache_background_update on; proxy_cache_use_stale updating error timeout invalid_header http_500 http_502 http_503 http_504; proxy_cache_valid 200 1h; location ~ ^/(?<bucket>avatars|images)/(?<filename>.+)$ { set $upstream $bucket.s3.amazonaws.com; proxy_pass http://$upstream/$filename; proxy_set_header Host $upstream; proxy_cache aws; proxy_cache_valid 200 1h; proxy_cache_valid 404 60s; }
Y, en general, funcionó: se mostraban imágenes, todo estaba bien con el caché ... sin embargo, surgieron problemas con los clientes de AWS S3. En particular, el cliente de
aws-sdk-php dejó de funcionar. El análisis de los registros nginx mostró que el flujo ascendente devolvió el código 403 para las solicitudes HEAD, y la respuesta contenía un error específico:
SignatureDoesNotMatch . Cuando vimos que nginx realiza una solicitud GET para el flujo ascendente, todo encajó.
El hecho es que el cliente S3 firma cada solicitud y el servidor verifica esta firma. En el caso de un proxy simple, todo funciona bien: la solicitud llega al servidor sin cambios. Sin embargo, cuando el almacenamiento en caché está habilitado, nginx comienza a optimizar el trabajo con el backend y reemplaza las solicitudes HEAD con GET. La lógica es simple: es mejor recuperar y guardar todo el objeto, y luego todas las solicitudes HEAD del caché también. Sin embargo, en nuestro caso, la solicitud no se puede modificar porque está firmada.
Hay esencialmente dos soluciones:
- No conduzca clientes S3 a través de servidores proxy;
- si es "necesario", desactive la opción
proxy_cache_convert_head y agregue $request_method a la clave de almacenamiento en caché. En este caso, nginx envía solicitudes HEAD "tal cual" y almacena las respuestas en caché por separado.
Historia No. 6. DDoS y contenido de usuario de Google
El domingo por la noche no presagió problemas hasta que, de repente. - La cola de invalidación de caché en servidores perimetrales no ha crecido, lo que da tráfico a usuarios reales. Este es un síntoma muy extraño: después de todo, la memoria caché se implementa en la memoria y no está vinculada a los discos duros. Vaciar el caché en la arquitectura utilizada es una operación barata, por lo que este error solo puede aparecer en el caso de una carga realmente alta. Esto se confirmó por el hecho de que los mismos servidores comenzaron a notificar la aparición de 500 errores
(picos de línea roja en el gráfico a continuación) .

Una oleada tan aguda condujo a desbordamientos de la CPU:
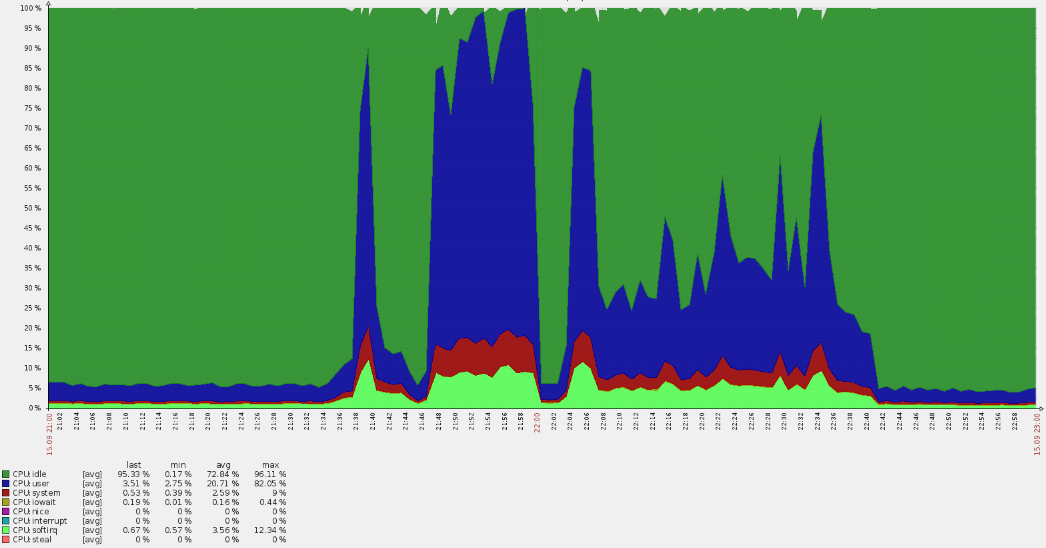
Un análisis rápido mostró que las solicitudes no llegaron a los dominios principales, pero a partir de los registros quedó claro que estaban en vhost predeterminado. En el camino, resultó que muchos usuarios estadounidenses acudieron al recurso ruso. Tales circunstancias siempre plantean preguntas de inmediato.
Habiendo recopilado datos de los registros de nginx, revelamos que estamos lidiando con cierta botnet:
35.222.30.127 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?ITPDH=XHJI" HTTP/1.1 301 178 "http://example.ru/ORQHYGJES" "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?ITPDH=XHJI" "redirect=http://www.example.ru/?ITPDH=XHJI" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?REVQSD=VQPYFLAJZ" HTTP/1.1 301 178 "http://www.usatoday.com/search/results?q=MLAJSBZAK" "Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?REVQSD=VQPYFLAJZ" "redirect=http://www.example.ru/?REVQSD=VQPYFLAJZ" ancient=1 cipher=- "LM=-;EXP=-;CC=-" 107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?MPYGEXB=OMJ" HTTP/1.1 301 178 "http://engadget.search.aol.com/search?q=MIWTYEDX" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?MPYGEXB=OMJ" "redirect=http://www.example.ru/?MPYGEXB=OMJ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
Se traza un patrón comprensible en los registros:
- verdadero agente de usuario;
- una solicitud a la URL raíz con un argumento GET aleatorio para evitar ingresar al caché;
- el árbitro indica que la solicitud provino de un motor de búsqueda.
Recopilamos las direcciones y verificamos su afiliación: todas pertenecen a
googleusercontent.com , con dos subredes (107.178.192.0/18 y 34.64.0.0/10). Estas subredes contienen máquinas virtuales GCE y diversos servicios, como la traducción de páginas.
Afortunadamente, el ataque no duró tanto (aproximadamente una hora) y disminuyó gradualmente. Parece que los algoritmos de protección dentro de Google han funcionado, por lo que el problema se resolvió "por sí mismo".
Este ataque no fue destructivo, pero planteó preguntas útiles para el futuro:
- ¿Por qué no funciona el anti-ddos? Se utiliza un servicio externo, al que enviamos una solicitud correspondiente. Sin embargo, había muchas direcciones ...
- ¿Cómo protegerse de esto en el futuro? En nuestro caso, incluso las opciones para cerrar el acceso sobre una base geográfica son posibles.
PS
Lea también en nuestro blog: