
Buenas tardes, quiero compartir con ustedes mi experiencia en la configuración y uso del servicio AWS EKS (Elastic Kubernetes Service) para contenedores de Windows, o más bien sobre la imposibilidad de usarlo, y un error encontrado en el contenedor del sistema AWS, para aquellos que estén interesados en este servicio para contenedores de Windows, por favor debajo del gato
Sé que los contenedores de Windows no son un tema popular, y pocas personas los usan, pero sin embargo decidieron escribir este artículo, ya que había un par de artículos sobre kubernetes y ventanas en Habré y todavía hay personas así.
Inicio
Todo comenzó con el hecho de que los servicios de nuestra empresa, se decidió migrar a kubernetes, es 70% de Windows y 30% de Linux. Para esto, el servicio en la nube de AWS EKS se consideró como una de las posibles opciones. Hasta el 8 de octubre de 2019, AWS EKS Windows estaba en la Vista previa pública, comencé con él, la versión de kubernetes usaba el antiguo 1.11, pero decidí comprobarlo de todos modos y ver en qué etapa funciona este servicio en la nube, si resultó que funcionaba, no estaba funcionando un error con la adición de eliminar hogares, mientras que los viejos dejaron de responder a través de la IP interna desde la misma subred que el nodo de trabajo de Windows.
Por lo tanto, se decidió abandonar el uso de AWS EKS en favor de su propio clúster en kubernetes en el mismo EC2, solo todo el equilibrio y la HA tendrían que ser descritos por mí mismo a través de CloudFormation.
La compatibilidad con Amazon EKS Windows Container ahora está generalmente disponible
por Martin Beeby | el 08 OCT 2019No tuve tiempo de agregar una plantilla a CloudFormation para mi propio clúster, ya que vi esta noticia.
Amazon EKS Windows Container Support ahora está generalmente disponible.Por supuesto, pospuse todos mis desarrollos y comencé a estudiar lo que hicieron para GA, y cómo todo cambió de Public Preview. Sí, los becarios de AWS actualizaron las imágenes para el nodo de trabajador de Windows a la versión 1.14, así como la versión de clúster 1.14 en EKS ahora con soporte para nodos de Windows. Cerraron el proyecto Public Preview en el
github y dijeron que ahora usen la documentación oficial aquí:
EKS Windows SupportIntegración de un clúster de EKS en la VPC y subredes actuales
En todas las fuentes, en el enlace anterior al anuncio y también en la documentación, se propuso implementar el clúster a través de la utilidad patentada eksctl o a través de CloudFormation + kubectl después, solo usando subredes públicas en Amazon, así como creando una VPC separada para un nuevo clúster.
Esta opción no es adecuada para muchos, en primer lugar, una VPC separada es el costo adicional de su costo + tráfico de interconexión a su VPC actual. ¿Qué hacer para aquellos que ya tienen una infraestructura preparada en AWS con sus múltiples cuentas de AWS, VPC, subredes, tablas de rutas, pasarela de tránsito, etc.? Por supuesto, no quiero desglosarlo o rehacerlo todo, y necesito integrar el nuevo clúster EKS en la infraestructura de red actual utilizando la VPC existente y, para dividir el máximo, crear nuevas subredes para el clúster.
En mi caso, se eligió esta ruta, utilicé la VPC existente, agregué solo 2 subredes públicas y 2 subredes privadas para un nuevo clúster, por supuesto, todas las reglas se tuvieron en cuenta de acuerdo con la documentación
Cree su VPC de clúster de Amazon EKS .
También había una condición para que ningún nodo de trabajo en subredes públicas utilizara EIP.eksctl vs CloudFormation
Inmediatamente haré una reserva de que probé ambos métodos de implementación del clúster, en ambos casos la imagen era la misma.
Mostraré un ejemplo solo con el uso de eksctl ya que el código es más corto aquí. Uso de la implementación del clúster eksctl en 3 pasos:
1.Cree el propio clúster + nodo de trabajo de Linux en el que se colocarán más tarde los contenedores del sistema y el desafortunado controlador vpc.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
Para implementar en una VPC existente, solo especifique la identificación de sus subredes, y eksctl determinará la propia VPC.
Para que su nodo de trabajo se implemente solo en la subred privada, debe especificar --node-private-networking para el grupo de nodos.
2. Instale vpc-controller en nuestro clúster, que luego procesará nuestros nodos de trabajo contando el número de direcciones IP libres, así como el número de ENI en la instancia, agregándolos y eliminándolos.
eksctl utils install-vpc-controllers --name yyy --approve
3.Después de que los contenedores de su sistema se iniciaron con éxito en su nodo de trabajador de Linux, incluido vpc-controller, solo queda crear otro grupo de nodos con trabajadores de Windows.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
Después de que su nodo se ha conectado con éxito a su clúster y todo parece estar bien, está en estado Listo, pero no.
Error en el controlador vpc
Si intentamos ejecutar pods en el nodo de trabajo de Windows, obtenemos un error:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
Mirando más profundo, vemos que nuestra instancia de AWS se ve así:

Y debería ser así:

A partir de esto, está claro que vpc-controller no funcionó por su parte por alguna razón y no pudo agregar nuevas direcciones IP a la instancia para que los pods pudieran usarlas.
Subimos para mirar los registros de pod del controlador vpc y esto es lo que vemos:
kubectl log <vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Las búsquedas en Google no condujeron a nada, ya que aparentemente nadie había detectado ese error todavía, bueno, o publicado un problema, tuve que pensar primero en todas las opciones. Lo primero que me vino a la mente es que tal vez vpc-controller no puede sobrio ip-10-xxx.ap-xxx.compute.internal y llegar a él y, por lo tanto, los errores caen.
Sí, de hecho, utilizamos servidores dns personalizados en VPC y no utilizamos servidores de Amazon en principio, por lo tanto, incluso el reenvío no se configuró en este dominio ap-xxx.compute.internal. Marqué esta opción, y no arrojó ningún resultado, tal vez la prueba no estaba limpia y, por lo tanto, al comunicarme con el soporte técnico, sucumbí a su idea.
Como no había ninguna idea, todos los grupos de seguridad fueron creados por el propio eksctl, por lo que no había duda de que estaban trabajando, las tablas de rutas también eran correctas, nat, dns, también había acceso a Internet con nodos de trabajo.
Al mismo tiempo, si implementa el nodo de trabajo en la subred pública sin usar --node-private-networking, vpc-controller actualiza este nodo de inmediato y todo funciona como un reloj.
Había dos opciones:
- Martille y espere hasta que alguien describa este error en AWS y lo arreglen y luego puede usar AWS EKS Windows de forma segura, porque acaban de ingresar a GA (tardó 8 días en el momento de la escritura), lo más probable es que muchos sigan el mismo camino que yo .
- Escríbale a AWS Support y explíqueles la esencia del problema con todo el conjunto de registros de todas partes y demuéstrales que su servicio no funciona al usar su VPC y subredes, no fue en vano que contáramos con Business Support, debemos usarlo al menos una vez :-)
Comunicación con ingenieros de AWS
Después de crear un ticket en el portal, elegí por error responderme a través de la web: correo electrónico o centro de soporte, a través de esta opción pueden responderle después de unos días, a pesar de que mi ticket tenía Severity - Sistema dañado, lo que implicaba una respuesta dentro de <12 horas, y dado que el plan de soporte comercial tiene soporte 24/7, esperaba lo mejor, pero resultó como siempre.
Mi boleto aterrizó en Sin asignar de viernes a lunes, luego decidí volver a escribirlo y elegí la opción de respuesta de chat. Después de una breve espera, Harshad Madhav fue nombrado para mí, y luego comenzó ...
Debatimos con él en línea durante 3 horas seguidas, transfiriendo registros, implementando el mismo clúster en el laboratorio de AWS para emular el problema, recreando el clúster de mi parte, y así sucesivamente, lo único que encontramos fue que los registros mostraron que la resolución no estaba funcionando Nombres de dominio interno de AWS como escribí anteriormente, y Harshad Madhav me pidió que creara reenvío, supuestamente usamos dns personalizados y esto puede ser un problema.
Reenvío
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
Lo que se hizo, el día había terminado. Harshad Madhav canceló la suscripción de ese cheque y debería funcionar, pero no, la resolución no ayudó.
Luego hubo una conversación con 2 ingenieros más, uno simplemente se cayó del chat, aparentemente asustado de un caso difícil, el segundo pasó mi día nuevamente en un ciclo de depuración completo, enviando registros, creando grupos en ambos lados, al final solo dijo, funciona para mí, así que yo documentación oficial. Hago todo paso a paso y tú y tú tendrás éxito.
A lo que cortésmente le pedí que se fuera, y asigne otro a mi boleto si no sabe dónde buscar el problema.
Final
El tercer día, un nuevo ingeniero, Arun B., fue nombrado para mí, y desde el comienzo de la comunicación con él, fue inmediatamente claro que no se trataba de 3 ingenieros anteriores. Leyó toda la historia e inmediatamente solicitó recolectar los registros con su propio script en ps1 que estaba en su github. Luego, todas las iteraciones de crear grupos, generar los resultados de los equipos, recopilar registros seguidos nuevamente, pero Arun B. se movía en la dirección correcta a juzgar por las preguntas que me hicieron.
Cuando llegamos a incluir -stderrthreshold = debug en su controlador vpc, ¿y qué pasó después? ciertamente no funciona) el pod simplemente no comienza con esta opción, solo -stderrthreshold = info funciona.
Aquí es donde terminamos y Arun B. dijo que intentaría reproducir mis pasos para obtener el mismo error. Al día siguiente recibí una respuesta de Arun B. Él no descartó este caso, pero tomó el código de revisión de su controlador vpc y encontró el mismo lugar donde funciona y por qué no funciona:
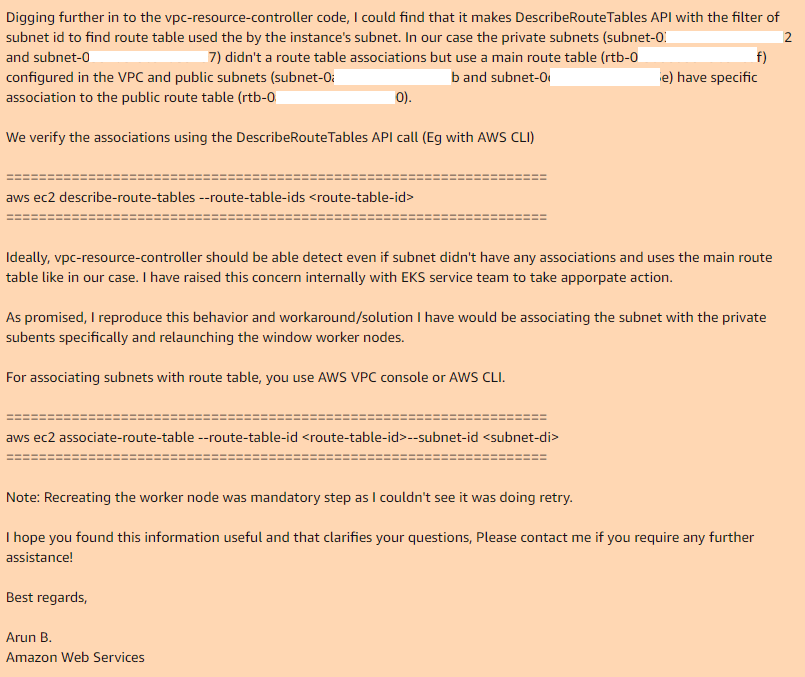
Por lo tanto, si utiliza la tabla de ruta principal en su VPC, de manera predeterminada no tiene asociaciones con las subredes necesarias, por lo que el controlador vpc necesario, en el caso de la subred pública, tiene una tabla de ruta personalizada que tiene una asociación.
Al agregar manualmente asociaciones para la tabla de ruta principal con las subredes deseadas y volver a crear el grupo de nodos, todo funciona perfectamente.
Espero que Arun B. informe este error a los desarrolladores de EKS y veremos una nueva versión de vpc-controller, y donde todo saldrá de la caja. Actualmente la última versión: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
tiene este problema
Gracias a todos los que leyeron hasta el final, prueben todo lo que van a utilizar en la producción, antes de la implementación.
Actualización: Nuevo error # 2
Después de encontrar una solución al primer problema, continuamos preparando este servicio para nuestras necesidades, y ahora en la última etapa, encontramos otro error incompatible con la vida.
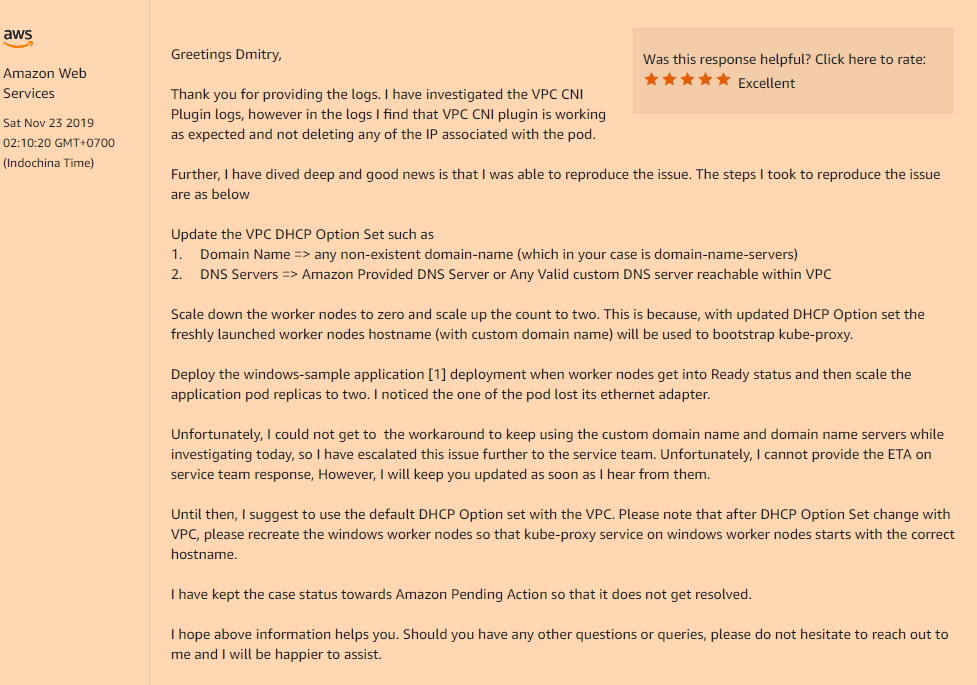
Problema:Implemente la aplicación en Kubernetes, configure su implementación, réplicas> 1 y vea la siguiente imagen. El nuevo pod se inicia normalmente y funciona, mientras que el viejo pierde su interfaz de red. Sí, sí, el viejo pod completamente sin una red, aunque continúa colgando en el estado En ejecución. Reduzca o aumente las réplicas, elimine los pods para que no siempre haga solo el pod que el último ha entrado en el estado En ejecución funcionará, el resto no lo hará. Independientemente, las vainas o en diferentes comienzan en el mismo nodo.
Solución:Sí, el problema volvió a estar en la configuración personalizada de nuestra VPC, es decir, si usa el conjunto de opciones de DHCP que indica el valor personalizado del campo de nombre de dominio o está completamente vacío (como en mi caso, cambié solo los servidores de nombre de dominio, No necesitaba el resto) obtendrá un problema tan incomprensible con la desaparición de las interfaces de red dentro de sus pods después del lanzamiento.
Debe registrarlo en su conjunto de opciones de DHCP:
domain-name = <aws-region-name>.compute.internal;
Y después de eso es reinstalar todos los nodos de trabajo para que durante el arranque todos los componentes registren la configuración correcta.
A continuación se muestran los detalles de cómo esta opción de nombre de dominio afecta a sus nodos de trabajo:
Esta vez, les pedí que agregaran al menos documentación a AWS EKS para Windows, estas "características" de su servicio.