Estamos en el proceso de preparar la próxima versión principal de Tokio, un entorno de tiempo de ejecución asíncrono para Rust. El 13 de octubre, se emitió una
solicitud de grupo con un planificador de tareas completamente reescrito para fusionarse en una rama. El resultado serán grandes mejoras de rendimiento y una latencia reducida. ¡Algunas pruebas registraron una aceleración de diez veces! Como de costumbre, las pruebas sintéticas no reflejan los beneficios reales en la realidad. Por lo tanto, también verificamos cómo los cambios en el planificador afectaron tareas reales, como
Hyper y
Tonic (spoiler: el resultado es maravilloso).
Preparándome para trabajar en un nuevo planificador, pasé tiempo buscando recursos temáticos. Aparte de las implementaciones reales, no se encontró nada especial. También descubrí que el código fuente de las implementaciones existentes es difícil de navegar. Para solucionar esto, tratamos de escribir el programador de Tokio lo más limpio posible. Espero que este artículo detallado sobre la implementación del programador ayude a aquellos que están en la misma posición y buscan sin éxito información sobre este tema.
El artículo comienza con una revisión de alto nivel del diseño, incluidas las políticas de captura de trabajo. Luego sumérgete en los detalles de optimizaciones específicas en el nuevo planificador de Tokio.
Optimizaciones consideradas:
Como puede ver, el tema principal es "reducción". Después de todo, ¡el código más rápido es su falta!
También hablaremos sobre
probar el nuevo planificador . Es muy difícil escribir el código paralelo correcto sin bloqueos. Es mejor trabajar lentamente, pero correctamente, que rápidamente, pero con fallas, especialmente si los errores están relacionados con la seguridad de la memoria. La mejor opción, sin embargo, debería funcionar rápidamente y sin errores, por lo que escribimos
Loom , una herramienta de prueba de concurrencia.
Antes de sumergirme en el tema, quiero agradecer a:
- @withoutboats y otros que trabajaron en la función
async / await en Rust. Hiciste un gran trabajo. Esta es una característica asesina.
- @cramertj y otros que desarrollaron
std::task . Esta es una gran mejora sobre lo que era antes. Y gran código.
- Boyante , el creador de Linkerd, y lo más importante, mi empleador. Gracias por dejarme pasar tanto tiempo en este trabajo. Si alguien está interesado en la malla de servicios, eche un vistazo a Linkerd. Pronto incluirá todos los beneficios discutidos en este artículo.
- Ve por una implementación tan buena del planificador.
Toma una taza de café y siéntate. Este será un artículo largo.
¿Cómo funcionan los planificadores?
La tarea del planificador es planificar el trabajo. La aplicación se divide en unidades de trabajo, que llamaremos
tareas . Una tarea se considera ejecutable cuando puede avanzar en su ejecución, pero ya no se realiza o en modo inactivo, cuando está bloqueada en un recurso externo. Las tareas son independientes en el sentido de que cualquier cantidad de tareas se pueden realizar simultáneamente. El planificador es responsable de ejecutar tareas en un estado de ejecución hasta que regresen al modo de espera. La ejecución de la tarea implica asignar tiempo de procesador a la tarea, un recurso global.
El artículo analiza los planificadores de espacio de usuario, es decir, trabajar sobre los hilos del sistema operativo (que, a su vez, están controlados por un programador de nivel de núcleo). El programador de Tokio ejecuta futuros de Rust, que pueden considerarse como "hilos verdes asíncronos". Este es un patrón de
transmisión mixta M: N en el que muchas tareas de la interfaz de usuario se multiplexan en múltiples subprocesos del sistema operativo.
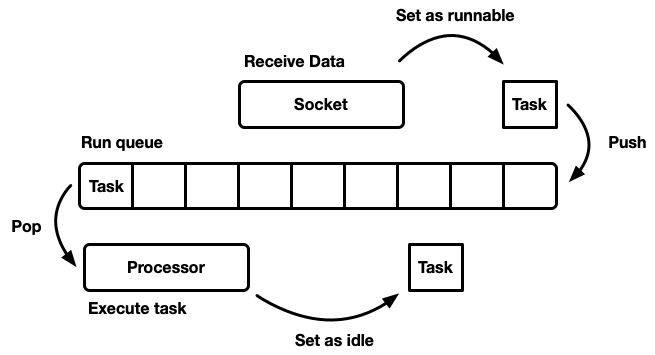
Hay muchas formas diferentes de simular un programador, cada una con sus propios pros y contras. En el nivel más básico, el planificador se puede modelar como una
cola de ejecución y un
procesador que lo separa. Un procesador es una pieza de código que se ejecuta en un hilo. En pseudocódigo, hace lo siguiente:
while let Some(task) = self.queue.pop() { task.run(); }
Cuando una tarea se vuelve factible, se inserta en la cola de ejecución.
Aunque puede diseñar un sistema en el que existan recursos, tareas y un procesador en el mismo hilo, Tokio prefiere usar múltiples hilos. Vivimos en un mundo donde una computadora tiene muchos procesadores. El desarrollo de un planificador de un solo subproceso conducirá a una carga insuficiente de hierro. Queremos usar todas las CPU. Hay varias formas de hacer esto:
- Una cola de ejecución global, muchos procesadores.
- Muchos procesadores, cada uno con su propia cola de ejecución.
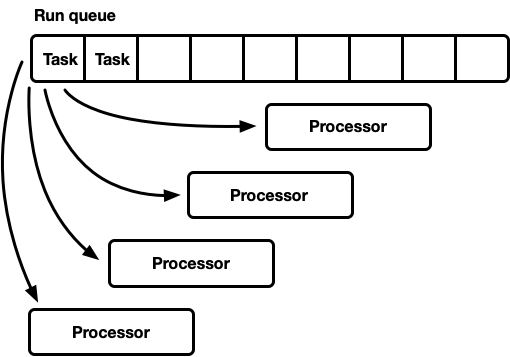
Una vuelta, muchos procesadores
Este modelo tiene una cola de ejecución global. Cuando las tareas se completan, se colocan en la cola de la cola. Hay varios procesadores, cada uno en un hilo separado. Cada procesador toma una tarea del jefe de la cola o bloquea el hilo si no hay tareas disponibles.
La línea de ejecución debe ser apoyada por muchos fabricantes y consumidores. Por lo general, se utiliza una lista
intrusiva , en la que la estructura de cada tarea incluye un puntero a la siguiente tarea en la cola (en lugar de envolver las tareas en una lista vinculada). Por lo tanto, se puede evitar la asignación de memoria para operaciones push y pop. Puede usar
la operación de inserción sin bloqueo , pero para coordinar a los consumidores, se requiere el mutex para la operación emergente (es técnicamente posible implementar una cola multiusuario sin bloqueo).
Sin embargo, en la práctica, la sobrecarga para una protección adecuada contra bloqueos es más que simplemente usar un mutex.
Este enfoque se usa a menudo para un grupo de subprocesos de uso general, porque tiene varias ventajas:
- Las tareas están bastante planificadas.
- Implementación relativamente simple. Una cola más o menos estándar se interconecta con el ciclo del procesador descrito anteriormente.
Una breve nota sobre la planificación justa (equitativa). Significa que las tareas se llevan a cabo honestamente: quien vino antes es el que se fue antes. Los planificadores de propósito general intentan ser justos, pero hay excepciones, como la paralelización a través de la unión de la bifurcación, donde la velocidad de cálculo del resultado, en lugar de la justicia para cada subtarea individual, es un factor importante.
Este modelo tiene un inconveniente. Todos los procesadores solicitan tareas desde la cabecera de la cola. Para hilos de propósito general, esto generalmente no es un problema. El tiempo para completar una tarea supera con creces el tiempo para recuperarla de la cola. Cuando las tareas se realizan durante un largo período de tiempo, se reduce la competencia en la cola. Sin embargo, se espera que las tareas de Rust asincrónicas se completen muy rápidamente. En este caso, los costos generales para la pelea en la cola aumentan significativamente.
Concurrencia y simpatía mecánica.
Para lograr el máximo rendimiento, debemos aprovechar al máximo las características del hardware. El término "simpatía mecánica" para el software fue utilizado por primera vez por
Martin Thompson (cuyo blog ya no se actualiza, pero sigue siendo muy informativo).
Una discusión detallada de la implementación del paralelismo en equipos modernos está más allá del alcance de este artículo. En términos generales, el hierro aumenta la productividad no debido a la aceleración, sino a la introducción de una mayor cantidad de núcleos de CPU (¡incluso mi computadora portátil tiene seis!) Cada núcleo puede realizar grandes cantidades de cómputo en pequeños intervalos de tiempo. Las acciones como acceder a la memoria caché y la memoria requieren
mucho más tiempo en relación con el tiempo de ejecución en la CPU. Por lo tanto, para acelerar las aplicaciones, debe maximizar el número de instrucciones de la CPU para cada acceso a la memoria. Aunque el compilador ayuda mucho, aún tenemos que pensar en cosas como la alineación y los patrones de acceso a la memoria.
Los subprocesos separados funcionan de manera muy parecida a un subproceso único aislado,
hasta que varios subprocesos modifiquen simultáneamente la misma línea de caché (mutaciones concurrentes) o se requiera una
coherencia constante . En este caso,
se activa el
protocolo de coherencia de caché de la
CPU . Garantiza la relevancia de la memoria caché de cada CPU.
La conclusión es obvia: en la medida de lo posible, evite la sincronización entre hilos, porque es lenta.
Muchos procesadores, cada uno con su propia cola de ejecución
Otro modelo son varios planificadores de subproceso único. Cada procesador recibe su propia cola de ejecución y las tareas se fijan en un procesador específico. Esto evita completamente el problema de sincronización. Dado que el modelo de tarea Rust requiere la capacidad de poner en cola una tarea desde cualquier subproceso, todavía debe haber una forma segura de subprocesos para ingresar tareas en el planificador. La cola de ejecución de cada procesador admite la operación de inserción segura para subprocesos (MPSC) o cada procesador tiene
dos colas de ejecución: no sincronizada y segura para subprocesos.
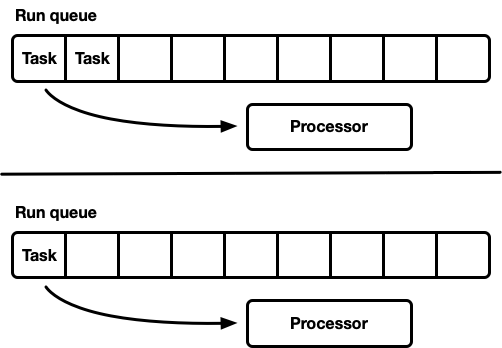
Esta estrategia utiliza
Seastar . Como evitamos casi por completo la sincronización, esta estrategia ofrece muy buena velocidad. Pero ella no resuelve todos los problemas. Si la carga de trabajo no es completamente homogénea, algunos procesadores están bajo carga, mientras que otros están inactivos, lo que conduce a un uso no óptimo de los recursos. Esto sucede porque las tareas se arreglan en un procesador específico. Cuando se planifica un grupo de tareas en un paquete en un procesador, solo alcanza la carga máxima, incluso si otras están inactivas.
La mayoría de las cargas de trabajo "reales" no son homogéneas. Por lo tanto, los planificadores de propósito general generalmente evitan este modelo.
Programador de captura de trabajo
El planificador con planificadores de robo de trabajo se basa en el modelo de planificador fragmentado y resuelve el problema de la carga incompleta de recursos de hardware. Cada procesador admite su propia cola de ejecución. Las tareas que se realizan se colocan en la cola de ejecución del procesador actual y funciona en él. Pero cuando el procesador está inactivo, comprueba las colas del procesador hermano e intenta tomar algo de allí. El procesador pasa al modo de suspensión solo después de que no puede encontrar trabajo en las colas de ejecución de igual a igual.

A nivel de modelo, este es el enfoque de "lo mejor de ambos mundos". Bajo carga, los procesadores funcionan de forma independiente, evitando la sincronización de sobrecarga. En los casos en que la carga entre los procesadores se distribuye de manera desigual, el planificador puede redistribuirla. Es por eso que tales planificadores se usan en
Go ,
Erlang ,
Java y otros idiomas.
La desventaja es que este enfoque es mucho más complicado. El algoritmo de la cola debe admitir la captura de trabajos, y para una ejecución fluida se requiere
cierta sincronización entre los procesadores. Si no se implementa correctamente, la sobrecarga para la captura puede ser más que la ganancia.
Considere esta situación: el procesador A está ejecutando actualmente una tarea y tiene una cola de ejecución vacía. El procesador B está inactivo; intenta capturar alguna tarea, pero falla, por lo que pasa al modo de suspensión. Luego se generan 20 tareas de la tarea del procesador A. Idealmente, el procesador B debería despertarse y tomar algunos de ellos. Para esto, es necesario implementar ciertas heurísticas en el planificador, donde los procesadores señalan a los procesadores pares inactivos sobre la aparición de nuevas tareas en su cola. Por supuesto, esto requiere sincronización adicional, por lo que estas operaciones se minimizan mejor.
En resumen:
- Cuanto menos sincronización, mejor.
- La captura de trabajos es el algoritmo óptimo para los planificadores de propósito general.
- Cada procesador funciona independientemente de los demás, pero se requiere cierta sincronización para capturar el trabajo.
Tokio 0.1 Scheduler
El primer planificador de trabajo para Tokio se lanzó en marzo de 2018. Este fue el primer intento, basado en algunas suposiciones que resultaron estar equivocadas.
En primer lugar, el programador Tokio 0.1 sugirió que los hilos del procesador deberían cerrarse si estaban inactivos durante un cierto período de tiempo. El planificador se creó originalmente como un sistema de "propósito general" para el grupo de subprocesos Rust. En ese momento, el tiempo de ejecución de Tokio todavía estaba en una etapa temprana de desarrollo. Luego, el modelo asumió que las tareas de E / S se realizarían en el mismo hilo que el selector de E / S (epoll, kqueue, iocp ...). Se podrían dirigir más tareas computacionales al grupo de subprocesos. En este contexto, se supone una configuración flexible del número de subprocesos activos, por lo que tiene más sentido deshabilitar los subprocesos inactivos. Sin embargo, en el planificador con captura de trabajo, el modelo cambió para realizar
todas las tareas asincrónicas, y en este caso tiene sentido mantener siempre un pequeño número de subprocesos en el estado activo.
En segundo lugar, se implementó una línea de
viga transversal de dos vías. Esta implementación se basa en la
línea de Chase-Lev bidireccional , y no es adecuada para planificar tareas asincrónicas independientes por los motivos que se describen a continuación.
En tercer lugar, la implementación resultó ser demasiado complicada. Esto se debe en parte al hecho de que este fue mi primer programador de tareas. Además, estaba demasiado impaciente cuando usaba atómica en las ramas, donde el mutex hubiera funcionado bien. Una lección importante es que muy a menudo son los mutexes los que funcionan mejor.
Finalmente, hubo muchos defectos menores en la implementación inicial. En los primeros años, los detalles de implementación del modelo Rust asíncrono evolucionaron significativamente, pero las bibliotecas mantuvieron la API estable todo el tiempo. Esto condujo a la acumulación de alguna deuda técnica.
Ahora Tokio se acerca al primer lanzamiento importante, y podemos pagar toda esta deuda, así como aprender de la experiencia adquirida durante los años de desarrollo. Este es un momento emocionante!
Programador de Tokio de próxima generación
Ahora es el momento de mirar más de cerca lo que ha cambiado en el nuevo programador.
Nuevo sistema de tareas
Primero, es importante resaltar lo que
no es parte de Tokio, pero es crucial en términos de mejorar la eficiencia: este es un
nuevo sistema de tareas std , desarrollado originalmente por
Taylor Kramer . Este sistema proporciona los ganchos que el planificador debe implementar para realizar tareas de Rust asincrónicas, y el sistema está verdaderamente excelentemente diseñado e implementado. Es mucho más ligero y más flexible que la iteración anterior.
La estructura de
Waker de los recursos indica que hay una tarea
factible que debe colocarse en la cola del planificador. En el nuevo sistema de tareas, esta es una estructura de dos punteros, mientras que antes era mucho más grande. Reducir el tamaño es importante para minimizar la sobrecarga de copiar el valor de
Waker en diferentes lugares, y ocupa menos espacio en las estructuras, lo que le permite exprimir datos más importantes en la línea de caché. El diseño de
vtable hizo una serie de optimizaciones, que discutiremos más adelante.
Elegir el mejor algoritmo de cola
La cola de ejecución está en el centro del planificador. Por lo tanto, este es el componente más importante para arreglar. El programador original de Tokio utilizó una
cola de dos vías: una implementación de fuente única (productor) y muchos consumidores. Una tarea se coloca en un extremo y los valores se recuperan del otro. La mayoría de las veces, el hilo "empuja" los valores desde el final de la cola, pero a veces otros hilos interceptan el trabajo, realizando la misma operación. La cola bidireccional es compatible con una matriz y un conjunto de índices que siguen la cabeza y la cola. Cuando la cola está llena, su introducción dará lugar a un aumento en el espacio de almacenamiento. Se asigna una nueva matriz más grande y los valores se mueven al nuevo almacenamiento.
La capacidad de crecer se logra a través de la complejidad y los gastos generales. Las operaciones push / pop deberían tener en cuenta este crecimiento. Además, liberar la matriz original está lleno de dificultades adicionales. En un lenguaje de recolección de basura (GC), la matriz anterior quedará fuera de alcance y eventualmente el GC la borrará. Sin embargo, Rust se envía sin un GC. Esto significa que nosotros mismos somos responsables de liberar la matriz, pero los hilos pueden intentar acceder a la memoria al mismo tiempo. Para resolver este problema, crossbeam utiliza una estrategia de recuperación basada en la época. Aunque no requiere muchos recursos, agrega una sobrecarga no trivial a la ruta principal (ruta activa). Cada operación ahora debe realizar operaciones atómicas de RMW (lectura-modificación-escritura) en la entrada y salida de secciones críticas para indicar a otros hilos que la memoria está en uso y no se puede borrar.
Debido a la sobrecarga para el crecimiento de la cola de ejecución, tiene sentido pensar: ¿es realmente necesario el apoyo para este crecimiento? Esta pregunta finalmente me llevó a reescribir el planificador. La nueva estrategia es tener un tamaño de cola fijo para cada proceso. Cuando la cola está llena, en lugar de aumentar la cola local, la tarea pasa a la cola global con varios consumidores y varios productores. Los procesadores verificarán periódicamente esta cola global, pero a una frecuencia mucho menor que la local.
Como parte de uno de los primeros experimentos, reemplazamos la viga transversal con
mpmc . Esto no condujo a una mejora significativa debido a la cantidad de sincronización para push y pop. La clave para capturar el trabajo es que casi no hay competencia en las colas bajo carga, ya que cada procesador solo accede a su propia cola.
En esta etapa, decidí estudiar cuidadosamente las fuentes de Go, y descubrí que usan un tamaño de cola fijo con un fabricante y varios consumidores, con una sincronización mínima, lo cual es muy impresionante. Para adaptar el algoritmo al planificador de Tokio, hice algunos cambios. Es de destacar que la implementación de Go utiliza operaciones atómicas secuenciales (según tengo entendido). La versión de Tokio también reduce el número de algunas operaciones de copia en ramas de código más raras.
Una implementación de cola es un búfer circular que almacena valores en una matriz. La cabeza y la cola de la cola son rastreadas por operaciones atómicas con valores enteros.
struct Queue {
La cola se realiza mediante un solo hilo:
loop { let head = self.head.load(Acquire);
Tenga en cuenta que en esta función de
push , las únicas operaciones atómicas son cargar con la
Acquire pedidos y guardar con la
Release pedidos. No hay operaciones RMW (
compare_and_swap ,
fetch_and ...) u orden secuencial como antes. Esto es importante porque en los chips x86 todas las descargas / guardados ya son "atómicos". Por lo tanto, a nivel de CPU,
esta función no se sincronizará . Las operaciones atómicas evitarán ciertas optimizaciones en el compilador, pero eso es todo. Lo más probable es que la primera operación de
load pueda realizar de forma segura con un pedido
Relaxed , pero el reemplazo no conlleva ninguna sobrecarga notable.
Cuando la cola está llena, se
push_overflow .
Esta función mueve la mitad de las tareas de la cola local a la cola global. La cola global es una lista intrusiva protegida por un mutex. Al pasar a la cola global, las tareas primero se vinculan entre sí, luego se crea un mutex y todas las tareas se insertan actualizando el puntero a la cola de la cola global. Esto ahorra un pequeño tamaño de sección crítica.Si está familiarizado con los detalles del ordenamiento de la memoria atómica, puede notar un "problema" potencial con la función que se muestra arriba push. La operación de loadordenamiento atómico es Acquirebastante débil. Puede devolver valores obsoletos, es decir, una operación de captura paralela ya puede aumentar el valor self.head, pero en la memoria caché de flujopushel valor anterior permanecerá, por lo que no notará la operación de captura. Esto no es un problema con la corrección del algoritmo. En la forma principal (rápida), pushsolo nos importa si la cola local está llena o no. Dado que solo el hilo actual puede empujar la cola, una operación desactualizada loadsimplemente hará que la cola se vea más llena de lo que realmente es. Puede determinar incorrectamente que la cola está llena y causar push_overflow, pero esta función incluye una operación atómica más fuerte. Si push_overflowdetermina que la cola no está llena, devuelve w / Erry la operación pushcomienza nuevamente. Esta es otra razón por la cualpush_overflowmueve la mitad de la cola de ejecución a la cola global. Después de este movimiento, estos falsos positivos ocurren con mucha menos frecuencia.Local pop(desde el procesador al que pertenece la cola) también se implementa simplemente: loop { let head = self.head.load(Acquire);
En esta función, uno atómico loady otro compare_and_swaps Release. La sobrecarga principal proviene de compare_and_swap.La función steales similar a pop, pero la self.tailcarga atómica debe transferirse desde . Además, de manera similar push_overflow, la operación stealintenta pretender ser la mitad de la cola en lugar de una sola tarea. Esto tiene un buen efecto en el rendimiento, que discutiremos más adelante.La última parte que falta es el análisis de la cola global, que recibe tareas que desbordan las colas locales, así como para transferir tareas al planificador desde subprocesos que no son del procesador. Si el procesador está bajo carga, es decir, hay tareas en la cola local, el procesador intentará sacar las tareas de la cola global después de cada 60 tareas en la cola local. También comprueba la cola global cuando está en el estado de "búsqueda" que se describe a continuación.Simplifique las plantillas de mensajes
Las aplicaciones de Tokio generalmente consisten en muchas tareas pequeñas e independientes. Interactúan entre sí a través de mensajes. Dicha plantilla es similar a otros idiomas como Go y Erlang. Dado lo común que es la plantilla, tiene sentido que el planificador la optimice.Suponga que se dan las tareas A y B. La tarea A ahora se está ejecutando y envía un mensaje a la tarea B a través del canal de transmisión. Un canal es un recurso en el que la tarea B está bloqueada actualmente, por lo que la acción de enviar un mensaje hará que la tarea B pase a un estado ejecutable, y se colocará en la cola de ejecución del procesador actual. Luego, el procesador deducirá la siguiente tarea de la cola de ejecución, la ejecutará y repetirá este ciclo hasta que alcance la tarea B.El problema es que puede haber un retraso significativo entre enviar un mensaje y completar la tarea B. Además, los datos activos, como un mensaje, se almacenan en la memoria caché de la CPU, pero para cuando se complete la tarea, es probable que se borren las memorias caché correspondientes.Para resolver este problema, el nuevo planificador de Tokio implementa la optimización (como en los planificadores Go y Kotlin). Cuando una tarea entra en un estado ejecutable, no se coloca al final de la cola, sino que se almacena en un espacio especial de "siguiente tarea". El procesador siempre verifica esta ranura antes de verificar la cola. Si ya hay una tarea anterior al insertar en la ranura, se elimina de la ranura y se mueve al final de la cola. Por lo tanto, la tarea de transmitir un mensaje se realizará prácticamente sin demora.
Captura del acelerador
En un planificador de captura de trabajos, si la cola de ejecución del procesador está vacía, el procesador intenta capturar tareas de las CPU pares. Primero, se selecciona una CPU par aleatoria, si no se encuentran tareas para ella, se busca la siguiente, y así sucesivamente, hasta que se encuentren las tareas.En la práctica, varios procesadores a menudo terminan de procesar la cola de ejecución aproximadamente al mismo tiempo. Esto sucede cuando llega un paquete de trabajo (por ejemplo, cuandoepollsondeado para la disponibilidad del zócalo). Los procesadores se despiertan, reciben tareas, las inician y las completan. Esto lleva al hecho de que todos los procesadores están tratando simultáneamente de capturar las tareas de otras personas, es decir, muchos hilos están tratando de acceder a las mismas colas. Hay un conflicto Una elección aleatoria del punto de partida ayuda a reducir la competencia, pero la situación aún no es muy buena.Para solucionar este problema, el nuevo planificador limita el número de procesadores paralelos que realizan operaciones de captura. Llamamos al estado del procesador en el que está tratando de capturar las tareas de otras personas "búsqueda de empleo" o "búsqueda" para abreviar (más sobre eso más adelante). Dicha optimización se realiza utilizando el valor atómico.int, que el procesador aumenta antes de comenzar la búsqueda y disminuye al salir del estado de búsqueda. Tanto como sea posible en un estado de búsqueda puede ser la mitad del número total de procesadores. Es decir, se establece el límite aproximado, y esto es normal. No necesitamos un límite estricto en la cantidad de CPU en la búsqueda, solo aceleración. Sacrificamos la precisión en aras de la eficiencia del algoritmo.Después de ingresar al estado de búsqueda, el procesador intenta capturar el trabajo de las CPU pares y verifica la cola global.Disminuya la sincronización entre hilos
Otra parte importante del planificador es notificar a las CPU pares de nuevas tareas. Si el "hermano" está dormido, se despierta y captura tareas. Las notificaciones juegan otro papel importante. Recuerde que el algoritmo de la cola utiliza un orden atómico débil ( Acquire/ Release). Debido a la asignación atómica de la memoria, no hay garantía de que un procesador homólogo vea tareas en la cola sin sincronización adicional. Por lo tanto, las notificaciones también son responsables de ello. Por esta razón, las notificaciones se vuelven caras. El objetivo es minimizar su número para no utilizar los recursos de la CPU, es decir, el procesador tiene tareas y el hermano no puede robarlas. Un número excesivo de notificaciones conduce a un problema de rebaño de truenos .El planificador original de Tokio adoptó un enfoque ingenuo para las notificaciones. Cada vez que se colocaba una nueva tarea en la cola de ejecución, el procesador recibía una notificación. Cada vez que se notificó a la CPU y vio la tarea después de despertarse, notificó a otra CPU. Esta lógica condujo muy rápidamente a que todos los procesadores se despertaran y buscaran trabajo (causando un conflicto). A menudo, la mayoría de los procesadores no encontraron trabajo y se quedaron dormidos nuevamente.El nuevo planificador mejoró enormemente este patrón, similar al planificador Go. Las notificaciones se envían como antes, pero solo si no hay CPU en el estado de búsqueda (consulte la sección anterior). Cuando el procesador recibe una notificación, ingresa inmediatamente al estado de búsqueda. Cuando el procesador en el estado de búsqueda encuentra nuevas tareas, primero abandona el estado de búsqueda y luego notifica al otro procesador.Esta lógica limita la velocidad a la que los procesadores se activan. Si un paquete de tareas completo se planifica de inmediato (por ejemplo, cuandoepollsondeado para la disponibilidad del zócalo), entonces la primera tarea dará como resultado una notificación al procesador. Ahora está en un estado de búsqueda. Las tareas programadas restantes en el paquete no notificarán al procesador, ya que hay al menos una CPU en el estado de búsqueda. Este procesador notificado capturará la mitad de las tareas en el lote y, a su vez, notificará al otro procesador. Un tercer procesador se activa, encuentra las tareas de uno de los dos primeros procesadores y captura la mitad de ellos. Esto conduce a un aumento suave en el número de CPU en funcionamiento, así como a un rápido equilibrio de carga.Reduce la asignación de memoria
El nuevo planificador de Tokio requiere solo una asignación de memoria para cada tarea generada, mientras que el anterior requería dos. Anteriormente, la estructura de tareas se parecía a esto: struct Task {
La estructura Tasktambién se resaltará en Box. Durante mucho tiempo quise arreglar esta articulación (lo intenté por primera vez en 2014). Dos cosas han cambiado desde el viejo planificador de Tokio. Primero, estabilizado std::alloc. En segundo lugar, el futuro sistema de tareas ha cambiado a una estrategia vtable explícita . Eran estas dos cosas las que faltaban, finalmente, para deshacerse de la ineficiente asignación de doble memoria para cada tarea.Ahora la estructura Taskse presenta de la siguiente forma: struct Task<T> { header: Header, future: T, trailer: Trailer, }
Para las tareas necesarias y Headery Trailer, pero que se dividen entre los datos "calientes" (cabeza) y "frío" (cola), m. E. Aproximadamente entre datos de acceso frecuente y los que se utilizan en raras ocasiones. Los datos "activos" se colocan en la cabecera de la estructura y se almacenan lo menos posible. Cuando el procesador desreferencia el puntero de la tarea, carga inmediatamente la línea de caché (de 64 a 128 bytes). Queremos que estos datos sean lo más relevantes posible.Conteo de enlaces atómicos reducido
La última optimización que discutimos en este artículo es reducir el número de enlaces atómicos. Hay muchas referencias a la estructura de la tarea, incluso desde el planificador y desde cada waker. La estrategia general para administrar esta memoria es el conteo de enlaces atómicos . Esta estrategia requiere una operación atómica cada vez que se clona un enlace y cada vez que se elimina un enlace. Cuando el último enlace queda fuera de alcance, la memoria se libera.En el antiguo planificador de Tokio, tanto el planificador como todos los wakers contenían un enlace a un descriptor de tareas, aproximadamente: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Cuando la tarea se activa, el enlace se clona (se produce un incremento atómico). Luego, el enlace se coloca en la cola de ejecución. Cuando el procesador recibe la tarea y completa su ejecución, descarta el enlace, lo que conduce a la reducción atómica. Estas operaciones atómicas (incremento y disminución) se suman.Este problema fue identificado previamente por los desarrolladores del sistema de tareas std::future. Se dieron cuenta de que al llamar, el Waker::wakeenlace original a wakermenudo ya no es necesario. Esto le permite reutilizar el contador de enlace atómico al mover una tarea a la cola de ejecución. El sistema de tareas std::futureahora incluye dos llamadas API para "despertar":Tal construcción de API nos hace usarlo cuando llamamos wake, evitando el incremento atómico. La implementación se convierte así: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Esto evita la sobrecarga de recuentos de enlaces adicionales solo si puede asumir la responsabilidad de despertarse. En mi experiencia, en cambio, casi siempre es recomendable despertarse &self. El despertar selfevita la reutilización de waker (útil en casos en los que el recurso envía muchos valores, es decir, canales, enchufes, ...). Además, en el caso es selfmás difícil implementar un despertador seguro para subprocesos (dejaremos los detalles para otro artículo).El nuevo planificador resuelve el problema de "despertar self" evitando el incremento atómico wake_by_ref, lo que lo hace tan efectivo comowake(self). Para hacer esto, el planificador mantiene una lista de todas las tareas que están actualmente activas (aún no completadas). La lista representa el contador de referencia necesario para enviar la tarea a la cola de ejecución.La complejidad de esta optimización radica en el hecho de que el planificador no eliminará tareas de su lista hasta que reciba una garantía de que la tarea se colocará nuevamente en la cola de ejecución. Los detalles de la implementación de este esquema están más allá del alcance de este artículo, pero le recomiendo que consulte la fuente.Concurrencia (insegura) audaz con Loom
Es muy difícil escribir el código paralelo correcto sin bloqueos. Es mejor trabajar lentamente, pero correctamente, que rápidamente, pero con fallas, especialmente si los errores están relacionados con la seguridad de la memoria. La mejor opción, sin embargo, debería funcionar rápidamente y sin errores. El nuevo planificador realizó algunas optimizaciones bastante agresivas y evita la mayoría de los tipos stdpor especialización. En general, hay bastante código inseguro en él unsafe.Hay varias formas de probar el código paralelo. Una de ellas es que los usuarios prueben y depuren en lugar de usted (una opción atractiva, eso es seguro). Otra es escribir pruebas unitarias que se ejecutan en un bucle y pueden detectar un error. Tal vez incluso use TSAN. Por supuesto, si encuentra un error, no puede reproducirse fácilmente sin reiniciar el ciclo de prueba. Además, ¿cuánto dura este ciclo? Diez segundos? Diez minutos? Diez dias? Anteriormente, tenía que probar el código paralelo en Rust.Encontramos esta situación inaceptable. Cuando lanzamos el código, queremos sentirnos seguros (tanto como sea posible), especialmente en el caso de código paralelo sin bloqueos. Los usuarios de Tokio necesitan confiabilidad.Por lo tanto, desarrollamos Loom : una herramienta para la prueba de permutación de código paralelo. Las pruebas se escriben como de costumbre, peroloomLos ejecutará muchas veces, reorganizando todas las opciones posibles de ejecución y comportamiento que la prueba puede encontrar en un entorno de transmisión. También verifica el acceso correcto a la memoria, la liberación de memoria, etc.Como ejemplo, aquí está la prueba de telar para el nuevo planificador: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
Parece bastante normal, pero un fragmento de código en un bloque se loom::modelejecuta miles de veces (posiblemente millones), cada vez con un ligero cambio en el comportamiento. Cada ejecución cambia el orden exacto de los hilos. Además, para cada operación atómica, loom prueba todos los diferentes comportamientos permitidos en el modelo de memoria C ++ 11. Recuerde que la carga atómica con Acquireera bastante débil y podía devolver valores obsoletos. La prueba loomprobará todos los valores posibles que se pueden cargar.loomse convirtió en una herramienta invaluable para desarrollar un nuevo planificador. Captó más de diez errores que pasaron todas las pruebas unitarias, pruebas manuales y pruebas de carga.Un lector exigente puede dudar de que el telar verifique "todas las permutaciones posibles", y tendrá razón. Las permutaciones ingenuas conducirán a una explosión combinatoria. Cualquier prueba no trivial nunca terminará. Este problema se ha estudiado durante muchos años y se han desarrollado varios algoritmos para evitar una explosión combinatoria. Loom básica algoritmo basado en la reducción dinámica con ordenación parcial (reducción de orden parcial dinámica). Este algoritmo elimina las permutaciones que conducen al mismo resultado. Pero el espacio de estado todavía puede crecer hasta tal tamaño que no se procesará en un período de tiempo razonable (varios minutos). Loom le permite limitarlo aún más mediante la reducción dinámica con pedidos parciales.En general, gracias a las extensas pruebas con Loom, ahora tengo mucha más confianza en la corrección del programador.Resultados
Entonces, analizamos qué son los planificadores y cómo el nuevo planificador de Tokio logró un gran aumento de rendimiento ... pero ¿qué tipo de crecimiento? Dado que el nuevo planificador solo se ha desarrollado, en el mundo real aún no se ha probado por completo. Aquí está lo que sabemos.En primer lugar, el nuevo planificador es mucho más rápido en micro benchmarks:Viejo planificador
test chained_spawn ... banco: 2,019,796 ns / iter (+/- 302,168)
prueba ping_pong ... banco: 1,279,948 ns / iter (+/- 154,365)
prueba spawn_many ... banco: 10,283,608 ns / iter (+/- 1,284,275)
test yield_many ... bench: 21,450,748 ns / iter (+/- 1,201,337)
Nuevo planificador
test chained_spawn ... banco: 168,854 ns / iter (+/- 8,339)
prueba ping_pong ... banco: 562,659 ns / iter (+/- 34,410)
prueba spawn_many ... banco: 7,320,737 ns / iter (+/- 264,620)
prueba de rendimiento_mucho ... banco: 14,638,563 ns / iter (+/- 1,573,678)
Este punto de referencia incluye lo siguiente:chained_spawn genera nuevas tareas de forma recursiva, es decir, genera una tarea que genera otra tarea, que también genera una tarea, etc.
ping_pongselecciona un canal oneshoty genera una tarea que envía un mensaje en ese canal. La tarea original está esperando un mensaje. Esta es la prueba más cercana al "mundo real".
spawn_many Comprueba la implementación de tareas en el planificador, es decir, genera tareas desde fuera de su contexto.
yield_many comprueba el despertar de tareas independientes.
La diferencia en los puntos de referencia es muy impresionante. Pero, ¿cómo se reflejará esto en el "mundo real"? Es difícil decirlo con certeza, pero intenté ejecutar los puntos de referencia Hyper .Aquí está el servidor Hyper más simple, cuyo rendimiento se mide con wrk -t1 -c50 -d10:Viejo planificador
Ejecutando 10s test @ http://127.0.0.1 {000
1 hilos y 50 conexiones
Thread Stats Avg Stdev Max +/- Stdev
Latencia 371.53us 99.05us 1.97ms 60.53%
Req / Sec 114.61k 8.45k 133.85k 67.00%
1139307 solicitudes en 10.00s, lectura de 95.61MB
Solicitudes / seg: 113923.19
Transferencia / seg: 9.56MB Nuevo planificador
Ejecutando 10s test @ http://127.0.0.1 {000
1 hilos y 50 conexiones
Thread Stats Avg Stdev Max +/- Stdev
Latencia 275.05us 69.81us 1.09ms 73.57%
Req / Sec 153.17k 10.68k 171.51k 71.00%
1522671 solicitudes en 10.00s, 127.79MB de lectura
Solicitudes / seg: 152258.70
Transferencia / seg: 12.78MB ¡Vemos un aumento del 34% en las solicitudes por segundo justo después del cambio de planificador! La primera vez que vi esto, me sentí muy feliz, porque esperaba un aumento de un máximo del 5-10%. Pero luego me sentí triste, porque este resultado también mostró que el viejo programador de Tokio no es tan bueno. Entonces recordé que Hyper ya es líder en calificaciones de TechEmpower . Es interesante ver cómo el nuevo planificador afectará las calificaciones.Tonic , el cliente y servidor gRPC, con el nuevo planificador acelerado en aproximadamente un 10%, lo cual es bastante impresionante teniendo en cuenta que Tonic aún no está completamente optimizado.Conclusión
Estoy realmente muy feliz de finalmente completar este proyecto después de varios meses de trabajo. Esta es una mejora importante para la E / S asíncrona de Rust. Estoy muy satisfecho con las mejoras realizadas. Todavía hay mucho espacio para la optimización en el código de Tokio, por lo que aún no hemos terminado con la mejora del rendimiento.Espero que el material del artículo sea útil para los colegas que intentan escribir su programador de tareas.