Pavel Selivanov, arquitecto de soluciones de Southbridge y profesor de Slurm, dio una charla en DevOpsConf 2019. Esta charla es parte de Kubernetes Slur Mega, un curso en profundidad sobre Kubernetes.
Slurm Basic: una introducción a Kubernetes tiene lugar en Moscú del 18 al 20 de noviembre.
Slurm Mega: Miramos bajo el capó de Kubernetes - Moscú, 22-24 de noviembre.
Slurm Online: Ambos cursos de Kubernetes siempre están disponibles.
Debajo del corte - transcripción del informe.
Buenas tardes, colegas y simpatizantes. Hoy hablaré sobre seguridad.
Veo que hay muchos guardias de seguridad en el pasillo hoy. Le pido disculpas de antemano si no voy a utilizar los términos del mundo de la seguridad de la manera habitual en usted.
Dio la casualidad de que hace unos seis meses me puse en manos de un grupo público de Kubernetes. Público: significa que hay un enésimo número de espacios de nombres, en estos espacios de nombres hay usuarios aislados en sus espacios de nombres. Todos estos usuarios pertenecen a diferentes empresas. Bueno, se suponía que este clúster debería usarse como CDN. Es decir, le dan un clúster, le dan al usuario allí, usted va allí en su espacio de nombres, despliega sus frentes.
Intentaron vender ese servicio a mi empresa anterior. Y me pidieron que hiciera un clúster sobre el tema: ¿es esta solución adecuada o no?
Vine a este grupo. Me dieron derechos limitados, espacio de nombres limitado. Allí, los chicos entendieron qué era la seguridad. Leyeron qué es el control de acceso basado en Rober (RBAC) para Kubernetes, y lo torcieron para que no pudiera ejecutar pods por separado de la implementación. No recuerdo la tarea que estaba tratando de resolver ejecutando sin implementación, pero realmente quería ejecutar justo debajo. Decidí por suerte ver qué derechos tengo en el clúster, qué puedo, qué no puedo, qué arruinaron allí. Al mismo tiempo, le diré lo que han configurado incorrectamente en el RBAC.
Dio la casualidad de que en dos minutos llevé un administrador a su clúster, miré todos los espacios de nombres vecinos, vi los frentes de producción de las empresas que ya habían comprado el servicio y me quedé estancado allí. Apenas me detuve, para no acercarme a alguien en el frente y no poner ninguna palabra obscena en la página principal.
Te diré con ejemplos cómo hice esto y cómo protegerme de esto.
Pero primero, presénteme. Me llamo Pavel Selivanov. Soy arquitecto en Southbridge. Entiendo a Kubernetes, DevOps y todo tipo de cosas elegantes. Los ingenieros de Southbridge y yo estamos construyendo todo esto, y lo aconsejo.
Además de nuestro negocio principal, recientemente lanzamos proyectos llamados Slory. Estamos tratando de llevar nuestra capacidad de trabajar con Kubernetes a las masas, para enseñar a otras personas cómo trabajar con K8 también.
De lo que hablaré hoy. El tema del informe es obvio: la seguridad del clúster de Kubernetes. Pero quiero decir de inmediato que este tema es muy grande y, por lo tanto, quiero estipular de inmediato lo que no diré con certeza. No voy a hablar de términos tristes que ya están sobreexcitados en Internet. Cualquier RBAC y certificados.
Hablaré sobre cómo mis colegas y yo estamos hartos de la seguridad en el grupo de Kubernetes. Vemos estos problemas tanto con los proveedores que proporcionan clústeres de Kubernetes como con los clientes que acuden a nosotros. E incluso con clientes que nos visitan desde otras empresas de consultoría administrativa. Es decir, la escala de la tragedia es, de hecho, muy grande.
Literalmente tres puntos, de los que hablaré hoy:
- Derechos de usuario vs derechos de pod. Los derechos de usuario y los derechos de hogar no son lo mismo.
- Recopilación de información del clúster. Le mostraré que desde el clúster puede recopilar toda la información que necesita sin tener derechos especiales en este clúster.
- Ataque DoS en el clúster. Si no podemos recopilar información, podemos poner el clúster en cualquier caso. Hablaré sobre los ataques DoS en los controles de clúster.
Otra cosa común que mencionaré es dónde lo probé todo, lo que puedo decir con certeza de que todo funciona.
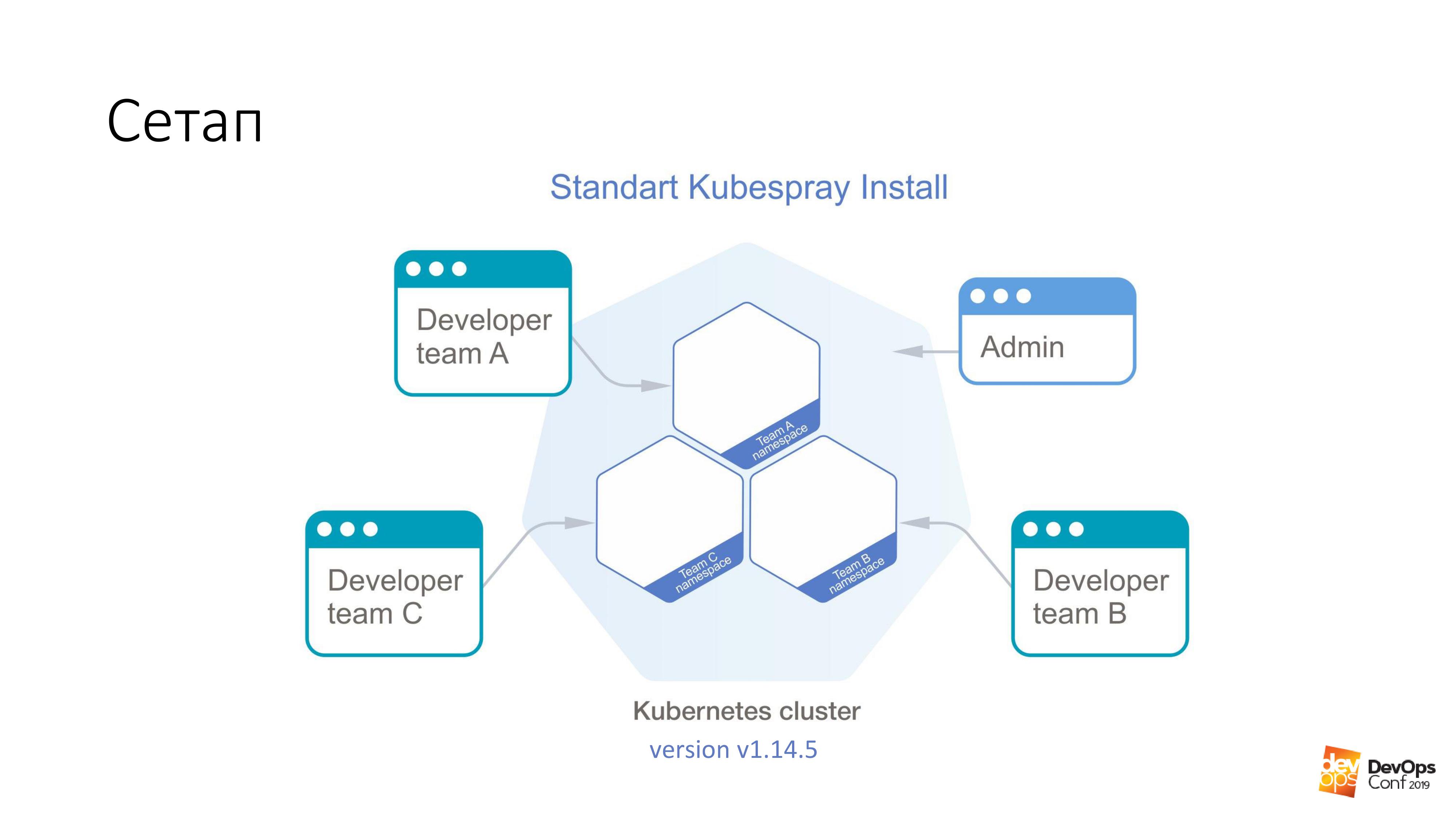
Como base, tomamos la instalación de un clúster de Kubernetes usando Kubespray. Si alguien no sabe, este es en realidad un conjunto de roles para Ansible. Lo estamos usando constantemente en nuestro trabajo. Lo bueno es que puedes rodar en cualquier lugar, puedes rodar en las glándulas y en algún lugar de la nube. Un método de instalación es adecuado en principio para todo.
En este clúster, tendré Kubernetes v1.14.5. Todo el grupo de Cuba, que consideraremos, está dividido en espacios de nombres, cada espacio de nombres pertenece a un equipo separado, los miembros de este equipo tienen acceso a cada espacio de nombres. No pueden ir a espacios de nombres diferentes, solo a los suyos. Pero hay alguna cuenta de administrador que tiene derechos para todo el clúster.
Prometí que lo primero que tendremos será obtener derechos de administrador para el clúster. Necesitamos una cápsula especialmente preparada que rompa el clúster de Kubernetes. Todo lo que tenemos que hacer es aplicarlo al clúster de Kubernetes.
kubectl apply -f pod.yaml
Esta cápsula llegará a uno de los maestros del grupo Kubernetes. Y después de eso, el clúster nos devolverá un archivo llamado admin.conf. En Cuba, todos los certificados de administrador se almacenan en este archivo y, al mismo tiempo, se configura la API del clúster. Así es como puede obtener acceso de administrador, creo, al 98% de los grupos de Kubernetes.
Repito, este pod fue creado por un desarrollador en su clúster que tiene acceso para implementar sus propuestas en un pequeño espacio de nombres, todo está sujeto por RBAC. No tenía derechos. Sin embargo, el certificado ha regresado.
Y ahora sobre el hogar especialmente preparado. Ejecutar en cualquier imagen. Por ejemplo, tome debian: jessie.
Tenemos tal cosa:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
¿Qué es la tolerancia? Los maestros en el grupo de Kubernetes suelen estar marcados con una cosa llamada mancha ("infección" en inglés). Y la esencia de esta "infección": dice que las vainas no pueden asignarse a nodos maestros. Pero nadie se molesta en indicar de ninguna manera que es tolerante con la "infección". La sección de Tolerancia solo dice que si NoSchedule está en algún nodo, entonces nuestra infección es tolerante, y no hay problemas.
Además, decimos que nuestro bajo no solo es tolerante, sino que también quiere caer específicamente en el maestro. Porque los maestros son los más deliciosos que necesitamos: todos los certificados. Por lo tanto, decimos nodeSelector, y tenemos una etiqueta estándar en los asistentes, que nos permite seleccionar exactamente aquellos nodos que son asistentes de todos los nodos del clúster.
Con tales dos secciones, definitivamente vendrá al maestro. Y se le permitirá vivir allí.
Pero solo venir al maestro no es suficiente para nosotros. No nos dará nada. Por lo tanto, además tenemos estas dos cosas:
hostNetwork: true hostPID: true
Indicamos que nuestro under, que estamos lanzando, vivirá en el espacio de nombres del núcleo, en el espacio de nombres de la red y en el espacio de nombres PID. Tan pronto como se inicie en el asistente, podrá ver todas las interfaces reales y en vivo de este nodo, escuchar todo el tráfico y ver el PID de todos los procesos.
A continuación, es pequeño. Toma etcd y lee lo que quieras.
Lo más interesante es esta característica de Kubernetes, que está presente allí de forma predeterminada.
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
Y su esencia es que podemos decir que queremos crear un volumen de tipo hostPath en el pod que ejecutamos, incluso sin los derechos de este clúster. Significa tomar el camino desde el host en el que comenzaremos, y tomarlo como volumen. Y luego llámalo nombre: host. Todo este hostPath lo montamos dentro del hogar. En este ejemplo, al directorio / host.
Repito una vez más. Le dijimos al pod que viniera al maestro, obtenga hostNetwork y hostPID allí, y monte toda la raíz del maestro dentro de este pod.
Entiende que en Debian tenemos bash ejecutándose, y este bash funciona bajo nuestra raíz. Es decir, acabamos de obtener la raíz del maestro, sin tener ningún derecho en el clúster de Kubernetes.
Entonces, toda la tarea es ir al directorio bajo / host / etc / kubernetes / pki, si no me equivoco, recoger todos los certificados maestros del clúster allí y, en consecuencia, convertirme en el administrador del clúster.
Si mira de esta manera, estos son algunos de los derechos más peligrosos en los pods, a pesar de los derechos del usuario:

Si tengo derechos para ejecutar en algún espacio de nombres de clúster, entonces este sub tiene estos derechos por defecto. Puedo ejecutar pods privilegiados, y esto es generalmente todos los derechos, prácticamente root en el nodo.
Mi favorito es el usuario root. Y Kubernetes tiene esa opción Ejecutar como no raíz. Este es un tipo de protección contra piratas informáticos. ¿Sabes qué es el "virus de Moldavia"? Si eres un hacker y vienes a mi clúster de Kubernetes, entonces, los administradores pobres, preguntamos: “Por favor, indica en tus pods con los que piratearás mi clúster, ejecuta como no root. Y sucede que comienzas el proceso en tu hogar debajo de la raíz, y será muy fácil para ti hackearme. Protégete de ti mismo ".
Volumen de ruta de host: en mi opinión, la forma más rápida de obtener el resultado deseado del clúster de Kubernetes.
¿Pero qué hacer con todo esto?
Pensamientos que deberían venir a cualquier administrador normal que se encuentre con Kubernetes: “Sí, te lo dije, Kubernetes no funciona. Hay agujeros en ella. Y todo el cubo es una mierda ". De hecho, existe una documentación, y si mira allí, hay una sección de Política de Seguridad de Pod .
Este es un objeto yaml: podemos crearlo en el clúster de Kubernetes, que controla los aspectos de seguridad en la descripción de los hogares. Es decir, de hecho, controla esos derechos para usar todo tipo de hostNetwork, hostPID, ciertos tipos de volumen, que están en los pods durante el inicio. Con la Política de seguridad de Pod, todo esto se puede describir.
Lo más interesante de la Política de seguridad de pod es que en el clúster de Kubernetes, todos los instaladores de PSP no solo no se describen en absoluto, simplemente se desactivan de forma predeterminada. La política de seguridad de pod se habilita mediante el complemento de admisión.
Bien, terminemos en una política de seguridad de pod de clúster, digamos que tenemos algún tipo de pod de servicio en el espacio de nombres, al que solo los administradores tienen acceso. Digamos que en todas las demás cápsulas tienen derechos limitados. Porque lo más probable es que los desarrolladores no necesiten ejecutar pods privilegiados en su clúster.
Y todo parece estar bien con nosotros. Y nuestro clúster de Kubernetes no puede ser pirateado en dos minutos.
Hay un problema Lo más probable es que si tiene un clúster de Kubernetes, la supervisión se instala en su clúster. Incluso supongo que predecir que si hay monitoreo en su clúster, entonces se llama Prometheus.
Lo que le diré ahora será válido tanto para el operador Prometheus como para el Prometheus entregado en su forma pura. La pregunta es que si no puedo poner al administrador tan rápido en el clúster, significa que tengo que buscar más. Y puedo buscar usando su monitoreo.
Probablemente, todos leen los mismos artículos sobre Habré, y el monitoreo está en monitoreo. Helm chart se llama aproximadamente igual para todos. Supongo que si hace helm install stable / prometheus, obtendrá aproximadamente los mismos nombres. E incluso lo más probable es que no tenga que adivinar el nombre DNS en su clúster. Porque es estándar.
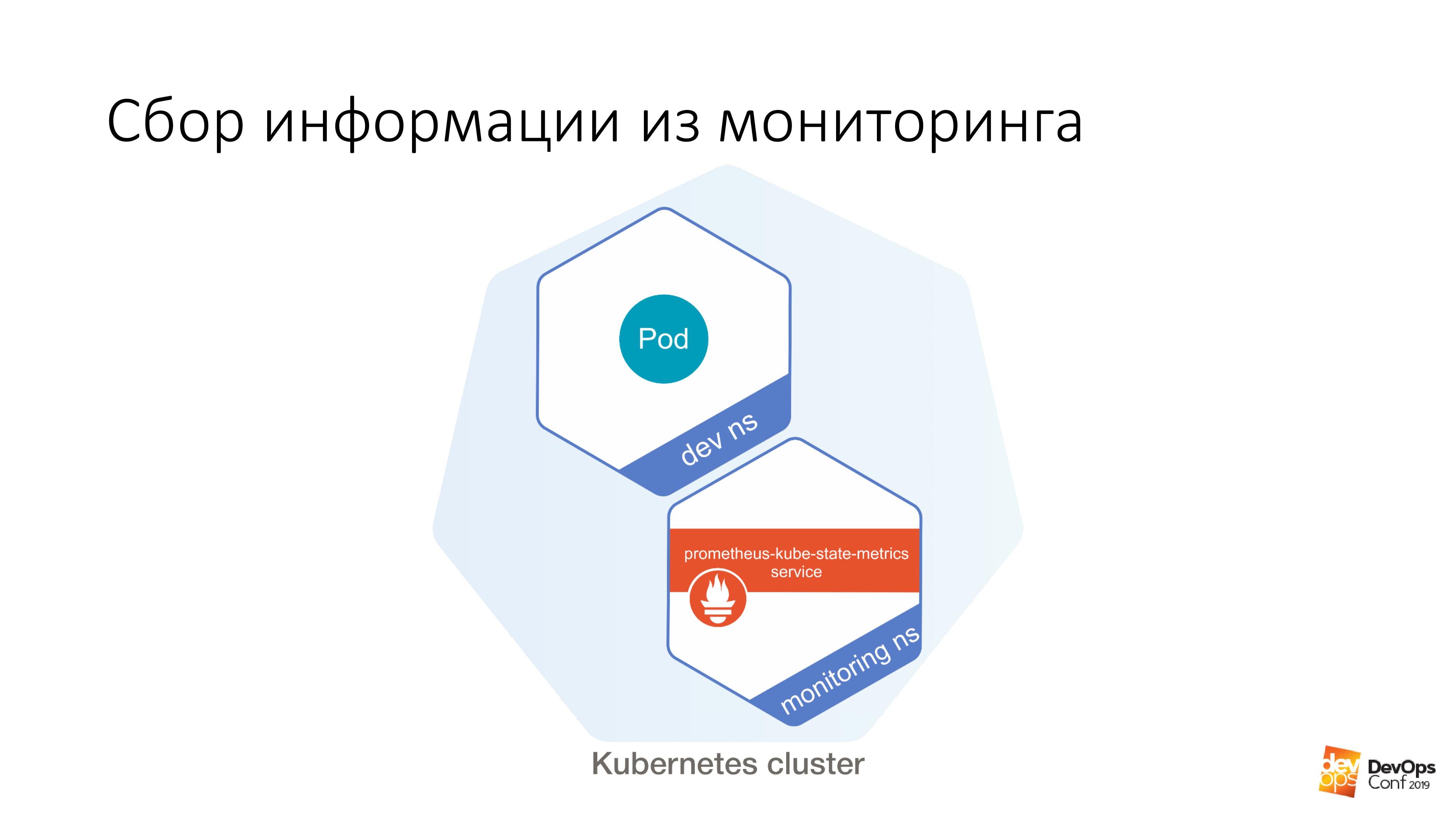
Además, tenemos un cierto dev ns, en él es posible lanzar un cierto under. Y más allá de este hogar, es muy fácil hacer esto:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state-metrics es uno de los exportadores de prometheus que recopila métricas de la API de Kubernetes. Hay muchos datos que se ejecutan en su clúster, qué es, qué problemas tiene con él.
Como un simple ejemplo:
kube_pod_container_info {namespace = "kube-system", pod = "kube-apiserver-k8s-1", container = "kube-apiserver", image =
"gcr.io/google-containers/kube-apiserver:v1.14.5"
, Image_id = "ventana acoplable-pullable: //gcr.io/google-containers/kube- apiserver @ sha256: e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989", container_id = "ventana acoplable: // 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b"} 1
Después de haber realizado una simple solicitud de curl desde un archivo sin privilegios, puede obtener dicha información. Si no sabe en qué versión de Kubernetes se está ejecutando, se lo informará fácilmente.
Y lo más interesante es que, además del hecho de que recurra a kube-state-metrics, también puede aplicar directamente a Prometheus. Puede recopilar métricas desde allí. Incluso puedes construir métricas desde allí. Incluso teóricamente, puede crear una solicitud de este tipo desde un clúster en Prometheus, que simplemente la desactiva. Y su monitoreo generalmente deja de funcionar desde el clúster.
Y aquí surge la pregunta de si algún monitoreo externo monitorea su monitoreo. Acabo de tener la oportunidad de actuar en el grupo de Kubernetes sin ninguna consecuencia para mí. Ni siquiera sabrá que estoy actuando allí, ya que ya no hay monitoreo.
Al igual que con PSP, parece que el problema es que todas estas tecnologías de moda, Kubernetes, Prometheus, simplemente no funcionan y están llenas de agujeros. En realidad no
Existe tal cosa - Política de red .
Si es un administrador normal, lo más probable es que sobre la Política de red sepa que este es otro yaml, que en el clúster ya está desactivado. Y algunas políticas de red definitivamente no son necesarias. E incluso si lee qué es la Política de red, qué es el cortafuegos yaml de Kubernetes, le permite restringir los derechos de acceso entre espacios de nombres, entre pods, entonces definitivamente decidió que el cortafuegos tipo yaml en Kubernetes está en las próximas abstracciones ... No, no . Esto definitivamente no es necesario.
Incluso si a sus especialistas en seguridad no se les dijo que al usar sus Kubernetes, puede construir un firewall de manera fácil y simple, y es muy granular. Si todavía no saben esto y no lo atraen: "Bueno, den, den ..." En cualquier caso, necesita una Política de red para bloquear el acceso a algunos lugares oficiales que puede extraer de su clúster sin ninguna autorización.
Como en el ejemplo que cité, puede extraer las métricas de estado de kube de cualquier espacio de nombres en el clúster de Kubernetes sin tener ningún derecho. Las políticas de red cerraron el acceso de todos los demás espacios de nombres a la supervisión del espacio de nombres y, por así decirlo, todo: sin acceso, sin problemas. En todos los gráficos que existen, tanto el prometeus estándar como ese prometeus que está en el operador, simplemente hay una opción en los valores de timón para habilitar simplemente políticas de red para ellos. Solo necesita encenderlo y funcionarán.
Realmente hay un problema aquí. Al ser un administrador barbudo normal, lo más probable es que hayas decidido que las políticas de red no son necesarias. Y después de leer todo tipo de artículos sobre recursos como Habr, decidió que la franela, especialmente con el modo host-gateway, es lo mejor que puede elegir.
Que hacer
Puede intentar volver a implementar la solución de red que está en su clúster de Kubernetes, intente reemplazarla con algo más funcional. En el mismo Calico, por ejemplo. Pero inmediatamente quiero decir que la tarea de cambiar la solución de red en el clúster de trabajo de Kubernetes es bastante trivial. Lo resolví dos veces (ambas veces, sin embargo, teóricamente), pero incluso mostramos cómo hacer esto en Slurms. Para nuestros estudiantes, mostramos cómo cambiar la solución de red en el clúster de Kubernetes. En principio, puede intentar asegurarse de que no haya tiempo de inactividad en el clúster de producción. Pero probablemente no tendrás éxito.
Y el problema se resuelve de manera muy simple. Hay certificados en el clúster, y sabe que sus certificados irán mal en un año. Bueno, y generalmente es una solución normal con certificados en el clúster: ¿por qué vamos a utilizar vapor? Levantaremos un nuevo clúster junto a él, lo dejaremos podrido en el anterior y lo rehaceremos todo. Es cierto que cuando va mal, todo se acostará en nuestros días, pero luego un nuevo grupo.
Cuando levantes un nuevo grupo, al mismo tiempo inserta Calico en lugar de franela.
¿Qué hacer si tiene certificados emitidos durante cien años y no va a reagrupar el clúster? Existe tal cosa Kube-RBAC-Proxy. Este es un desarrollo muy bueno, le permite integrarse como un contenedor de sidecar a cualquier hogar en el clúster de Kubernetes. Y en realidad agrega autorización a través de Kubernetes RBAC a este pod.
Hay un problema Anteriormente, Kube-RBAC-Proxy se incorporó al prometeo del operador. Pero luego se fue. Ahora, las versiones modernas se basan en el hecho de que tienes una política de red y dejas de usarlas. Y entonces tienes que reescribir un poco la tabla. De hecho, si va a este repositorio , hay ejemplos de cómo usarlo como sidecars, y tendrá que reescribir los gráficos mínimamente.
Hay otro pequeño problema. Prometheus no solo brinda sus métricas a cualquiera que las obtenga. Tenemos todos los componentes del clúster de Kubernetes, también, pueden dar sus métricas.
Pero como dije, si no puede acceder al clúster y recopilar información, al menos puede hacer daño.
Así que le mostraré rápidamente dos formas en que puede estropear su clúster de Kubernetes.
Te reirás cuando te lo diga, estos son dos casos de la vida real.
La primera manera Quedando sin recursos.
Lanzamos un especial más bajo. Tendrá esa sección.
resources: requests: cpu: 4 memory: 4Gi
Como sabe, las solicitudes son la cantidad de CPU y memoria reservada en el host para pods específicos con solicitudes. Si tenemos un host de cuatro núcleos en el clúster de Kubernetes, y cuatro CPU vienen con solicitudes, significa que no pueden venir más pods con solicitudes a este host.
Si ejecuto esto debajo, entonces haré un comando:
$ kubectl scale special-pod --replicas=...
Entonces nadie más podrá desplegarse en el clúster de Kubernetes. Porque en todos los nodos las solicitudes finalizarán. Y así detengo tu grupo de Kubernetes. Si hago esto por la noche, entonces puedo detener la implementación durante bastante tiempo.
Si volvemos a mirar la documentación de Kubernetes, veremos algo llamado Rango Límite. Establece recursos para objetos de clúster. Puede escribir un objeto de Límite de rango en yaml, aplicarlo a ciertos espacios de nombres, y además en este espacio de nombres puede decir que tiene recursos para los pods predeterminados, máximos y mínimos.
Con la ayuda de tal cosa, podemos limitar a los usuarios en espacios de nombres de productos específicos de equipos en la capacidad de indicar cualquier cosa desagradable en sus pods. Pero desafortunadamente, incluso si le dice al usuario que es imposible ejecutar pods con solicitudes de más de una CPU, hay un comando de escala tan maravilloso, bueno, o bien a través del tablero de instrumentos pueden escalar.
Y de aquí viene el método número dos. Lanzamos 11 111 111 111 111 hogares. Eso es once mil millones. Esto no es porque se me ocurrió ese número, sino porque lo vi yo mismo.
La verdadera historia A última hora de la tarde estaba a punto de abandonar la oficina. Miro, un grupo de desarrolladores está sentado en la esquina y haciendo algo frenéticamente con las computadoras portátiles. Me acerco a los chicos y les pregunto: "¿Qué te pasó?"
Un poco antes, a las nueve de la noche, uno de los desarrolladores se iba a casa. Y decidió: "Voy a omitir mi solicitud hasta una ahora". Hice clic un poco e Internet fue un poco aburrido. Una vez más hizo clic en la unidad, presionó la unidad, hizo clic en Entrar. Empujó todo lo que pudo. Luego, Internet cobró vida, y todo comenzó a escalar a esta fecha.
Es cierto que esta historia no ocurrió en Kubernetes, en ese momento era nómada. Terminó con el hecho de que después de una hora de nuestros intentos de detener a Nomad de los obstinados intentos de permanecer juntos, Nomad respondió que no dejaría de quedarse y no haría nada más. "Estoy cansado, me voy". Y acurrucado.
Naturalmente intenté hacer lo mismo en Kubernetes. Los once mil millones de vainas de Kubernetes no estaban contentos, dijo: "No puedo. Excede los protectores bucales internos ". Pero 1,000,000,000 de hogares podrían.
En respuesta a mil millones, el Cubo no entró. Realmente comenzó a escalar. Cuanto más avanzaba el proceso, más tiempo le llevó crear nuevos hogares. Pero aún así el proceso continuó. El único problema es que si puedo ejecutar pods indefinidamente en mi espacio de nombres, entonces, incluso sin solicitudes y límites, puedo iniciar tal cantidad de pods con algunas tareas que con estas tareas los nodos comienzan a acumularse desde la memoria, desde la CPU. Cuando ejecuto tantos hogares, la información de ellos debe ir al repositorio, es decir, etc. Y cuando llega demasiada información allí, el almacén comienza a ceder muy lentamente, y en Kubernetes comienzan las cosas aburridas.
Y un problema más ... Como saben, los elementos de control de Kubernetes no son solo una cosa central, sino varios componentes. Allí, en particular, hay un administrador de controlador, un planificador, etc. Todos estos tipos comenzarán a hacer un estúpido trabajo innecesario al mismo tiempo, lo que con el tiempo comenzará a tomar más y más tiempo. El administrador del controlador creará nuevos pods. El programador intentará encontrarles un nuevo nodo. Los nuevos nodos en su clúster probablemente terminarán pronto. El Clúster de Kubernetes comenzará a trabajar más y más lentamente.
Pero decidí ir aún más lejos. Como saben, en Kubernetes existe una cosa llamada servicio. Bueno, y de manera predeterminada en sus clústeres, lo más probable es que el servicio funcione con tablas IP.
Si ejecuta mil millones de hogares, por ejemplo, y luego usa un script para obligar a Kubernetis a crear nuevos servicios:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
En todos los nodos del clúster, se generarán aproximadamente nuevas reglas de iptables aproximadamente de forma simultánea. Además, para cada servicio, se generarán mil millones de reglas de iptables.
Revisé todo esto en varios miles, hasta una docena. Y el problema es que ya en este umbral ssh en el nodo es bastante problemático de hacer. Debido a que los paquetes, al pasar tantas cadenas, comienzan a no sentirse muy bien.
Y todo esto también se resuelve con la ayuda de Kubernetes. Existe tal objeto de cuota de recursos. Establece el número de recursos y objetos disponibles para un espacio de nombres en un clúster. Podemos crear un objeto yaml en cada espacio de nombres del clúster de Kubernetes. Con este objeto, podemos decir que hemos asignado un cierto número de solicitudes, límites para este espacio de nombres, y luego podemos decir que en este espacio de nombres es posible crear 10 servicios y 10 pods. Y un único desarrollador puede al menos exprimir las noches. Kubernetes le dirá: "No puedes poner tus cápsulas a tal cantidad porque excede la cuota de recursos". Todo, el problema está resuelto. La documentación está aquí .
Un punto problemático surge en relación con esto. Siente lo difícil que resulta crear un espacio de nombres en Kubernetes. Para crearlo, debemos considerar un montón de cosas.
Cuota de recursos + Rango límite + RBAC
• Crear un espacio de nombres
• Crear dentro del rango límite
• Crear dentro de la cuota de recursos
• Crear una cuenta de servicio para CI
• Crear un rolebinding para CI y usuarios
• Opcionalmente, ejecute los pods de servicio necesarios
Por lo tanto, aprovechando esta oportunidad, me gustaría compartir mis desarrollos. Existe tal cosa, llamada operador SDK. Esta es una forma en el clúster de Kubernetes para escribir operadores para él. Puedes escribir declaraciones usando Ansible.
Primero, fue escrito en Ansible, y luego miré que había un operador de SDK y reescribí el rol de Ansible en el operador. Este operador le permite crear un objeto en el clúster de Kubernetes llamado equipo. yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.