Fiabilidad de flash: esperada e inesperada. Parte 1. XIV conferencia de la asociación USENIX. Tecnologías de almacenamiento de archivosFiabilidad de flash: esperada e inesperada. Parte 2. XIV conferencia de la asociación USENIX. Tecnologías de almacenamiento de archivos5.5. Errores irrecuperables y litografía
Curiosamente, el efecto de la litografía sobre errores no corregibles es menos claro que en el caso de RBER, donde una litografía más pequeña, como se esperaba, conduce a un RBER más alto. Por ejemplo, la Figura 6 muestra que el modelo SLC-B tiene una tasa de corrección de errores más rápida que el modelo SLC-A, aunque el SLC-B tiene una litografía más grande (50 nm en comparación con 34 nm para el modelo SLC-A). Además, los modelos de la serie MLC con un tamaño de trabajo más pequeño (modelo MLC-B), por regla general, no tienen tasas de error fatales más altas que otros modelos.
De hecho, durante el primer tercio de su vida útil (el número de ciclos PE de 0 a 1000) y en el último tercio de su vida útil (> 2200 ciclos PE), este modelo tiene una frecuencia de UE más baja que, por ejemplo, el modelo MLC-D. Recuerde que todas las unidades MLC y SLC utilizan el mismo mecanismo ECC, por lo que estas consecuencias no pueden atribuirse a diferencias en ECC.
En general, encontramos que la litografía tiene un efecto menor sobre los errores esperados de lo esperado y un efecto menor que el que observamos al estudiar el efecto de RBER.
5.6. El impacto de otros tipos de errores en comparación con los errores no corregibles
Considere si la presencia de otros errores aumenta la probabilidad de errores no corregibles.
La Figura 7 muestra la probabilidad de que ocurra un error fatal en un mes dado de operación del disco, dependiendo de si ocurrieron varios tipos de errores en el disco en algún momento del período de operación anterior (color amarillo de las franjas) o en el mes anterior (color verde de las franjas), y comparación esta probabilidad con la probabilidad de ocurrencia de un error no corregible (barras rojas) en el próximo mes.
Vemos que todos los tipos de errores aumentan la probabilidad de errores no corregibles. En este caso, el aumento máximo ocurre cuando el error anterior se notó hace relativamente poco tiempo (es decir, en el mes anterior; las barras verdes en el gráfico son más altas que las amarillas) o si el error anterior también fue un error que no se puede corregir. Por ejemplo, la probabilidad de que ocurra un error no corregible un mes después de otro error no corregible es casi del 30% en comparación con la probabilidad del 2% de ver un error no corregible en cualquier otro mes. Pero los errores finales de escritura, meta errores y errores de borrado también aumentan la probabilidad de UE en más de 5 veces.
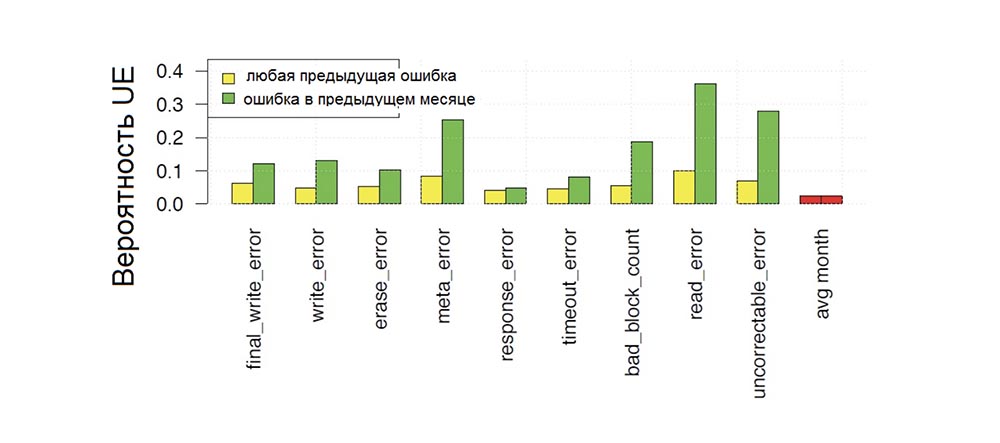 Fig. 7. La probabilidad mensual de ocurrencia de errores de accionamiento no corregibles en función de la dependencia de la presencia de errores previos de varios tipos.
Fig. 7. La probabilidad mensual de ocurrencia de errores de accionamiento no corregibles en función de la dependencia de la presencia de errores previos de varios tipos.Por lo tanto, los errores previos, en particular los errores no corregibles anteriores, aumentan la posibilidad de que se produzcan errores no corregibles posteriores en más de un orden de magnitud.
6. Fallos de hardware
6.1. Bloques dañados
Un bloque es una sección de memoria en la que se realizan operaciones de borrado. En nuestro estudio, distinguimos entre unidades dañadas en el campo y aquellas que ya tenían daños de fábrica cuando las unidades se entregaron a los usuarios.
En nuestro estudio, las unidades declararon que el bloque estaba dañado después del error final de lectura, escritura o borrado, y en consecuencia lo reasignaron (es decir, el bloque se excluyó de un uso posterior y cualquier dato que se colocó en este bloque y que se pudo restaurar se redirigió a otro bloque) .
 Tab. 4. Estadísticas sobre la presencia de bloques dañados que surgen en el proceso de las condiciones de operación del campo, y la presencia de bloques dañados que surgen en el proceso de fabricación de un disco en una fábrica.
Tab. 4. Estadísticas sobre la presencia de bloques dañados que surgen en el proceso de las condiciones de operación del campo, y la presencia de bloques dañados que surgen en el proceso de fabricación de un disco en una fábrica.La mitad superior de la Tabla 4 proporciona estadísticas sobre unidades dañadas en unidades probadas en campo. La línea superior muestra la proporción de unidades con bloques dañados para cada uno de los 10 modelos de unidades, el promedio muestra el número promedio de bloques dañados para aquellas unidades que contienen bloques dañados, la línea inferior muestra el número promedio de bloques dañados entre discos con bloques dañados.
Consideramos solo las unidades que se pusieron en producción al menos hace cuatro años, y solo los bloques dañados que surgieron durante los primeros 4 años de pruebas de campo. La mitad inferior de la tabla proporciona estadísticas sobre unidades en las que hubo bloques dañados que surgieron durante la fabricación en fábrica.
6.1.1. La aparición de unidades dañadas en el campo.
Llegamos a la conclusión de que los bloques dañados son frecuentes: en el campo, según el modelo, se encuentran en el 30-80% de los discos. El estudio de la función de distribución acumulativa (CDF) para la cantidad de bloques de unidades dañadas mostró que la mayoría de los discos con bloques dañados tienen solo una pequeña cantidad de tales bloques: el número medio de bloques defectuosos para discos con bloques dañados, según el modelo, es de 2 a 4. Sin embargo, si la cantidad de bloques dañados Los bloques de la unidad son más que el número medio, por lo general, es mucho más. Este fenómeno se ilustra en la Figura 8.
 Fig. 8. Figura que muestra un aumento en la cantidad de bloques dañados dependiendo de la cantidad de bloques inicialmente dañados.
Fig. 8. Figura que muestra un aumento en la cantidad de bloques dañados dependiendo de la cantidad de bloques inicialmente dañados.La Figura 8 muestra cómo se desarrolla el número medio de bloques de transmisión dañados con un aumento en el número de bloques ya dañados. La línea azul corresponde a los modelos MLC, las líneas discontinuas rojas corresponden a los modelos SLC. En particular, para las unidades MLC, observamos un fuerte aumento en el número de bloques dañados después del segundo bloque dañado detectado, mientras que el número medio salta a 200, es decir, se detecta el 50% de los discos que tienen 2 bloques dañados, con el tiempo aparecen 200 o más bloques dañados.
Mientras no tengamos acceso al conteo de errores a nivel de chip, los bloques dañados se consideran cientos, probablemente debido a fallas del chip en sí, por lo que la Figura 8 indica que después de la aparición de varios bloques dañados, hay una alta probabilidad de que un chip falle por completo. Este resultado puede servir como una oportunidad potencial para predecir fallas en el chip si confía en cálculos previos de bloques defectuosos y tiene en cuenta otros factores como la edad, la carga de trabajo y los ciclos de PE.
Además de determinar la frecuencia de aparición de bloques defectuosos, también estamos interesados en descubrir cómo se detectan los bloques dañados: durante las operaciones de escritura o borrado, cuando un fallo de bloque es invisible para el usuario, o cuando ocurre un error de lectura final que es visible para el usuario y crea el riesgo de pérdida de datos. Aunque no tenemos datos sobre fallas de bloque individuales y cómo se detectaron, podemos referirnos a las frecuencias observadas de varios tipos de errores, que indican una falla de bloque. Volviendo a la Tabla 2, vemos que para todos los modelos, la frecuencia de errores de borrado y errores de escritura es menor que para los errores de lectura final, es decir, la mayoría de los bloques dañados se detectan como resultado de la aparición de errores opacos, es decir, durante las operaciones de lectura.
6.1.2. Unidades dañadas en la fábrica.
Arriba, examinamos la dinámica de la aparición de bloques defectuosos en el campo. Aquí observamos que casi todos los discos (> 99% para la mayoría de los modelos) contenían defectos de fábrica en forma de bloques dañados, y su número varía mucho entre los modelos, comenzando desde el número medio menor que 100 para 2 modelos SLC y terminando con un valor más típico de más de 800 para otros modelos La distribución de los bloques dañados de fábrica corresponde a la distribución normal, mientras que los valores promedio y mediano tienen un valor cercano. Curiosamente, el número de unidades dañadas de fábrica en cierta medida predice la aparición de otros problemas de manejo en el campo. Por ejemplo, notamos que para todos los modelos de unidades menos una, el 95% de las unidades que tienen bloques defectuosos de fábrica tienen una mayor proporción de nuevos bloques dañados en el campo y una mayor proporción de errores de escritura final que el disco promedio del mismo modelos. También tienen una mayor participación en el desarrollo de ciertos tipos de errores de lectura (finales o no finales). Los discos en el percentil 5% tienen una cuota de errores de tiempo de espera por debajo del promedio. Por lo tanto, llegamos a las siguientes conclusiones con respecto a los bloques defectuosos: el daño del bloque es una ocurrencia bastante común observada en el 30-80% de las unidades que tienen al menos uno de esos bloques. Al mismo tiempo, existe una fuerte dependencia: si el disco contiene al menos 2-4 bloques dañados, hay un 50% de posibilidades de que cientos de bloques dañados sigan. Casi todos los discos vienen con bloques dañados de fábrica, lo que da razones para predecir su desarrollo en el campo, así como el desarrollo de algunos otros tipos de errores.
6.2. Chips de memoria dañados
En nuestro estudio, se cree que el chip de disco falló si más del 5% de los bloques fallaron, o si el número de errores de disco durante el último intervalo de tiempo excedió el valor límite. Algunas unidades flash de fábrica contienen un chip de repuesto, por lo que si un chip falla, la unidad usa el segundo. En nuestro estudio, las unidades tenían la misma función. En lugar de trabajar en un chip de repuesto, los chips de memoria dañados se excluyeron del uso posterior, y la unidad continuó funcionando con un rendimiento reducido en los chips restantes.
La primera línea de la Tabla 5 muestra la prevalencia de chips dañados. Vemos que del 2 al 7% de los discos tienen mal funcionamiento del chip durante los primeros cuatro años de operación. Las unidades que no tienen un mecanismo para mapear chips dañados requieren reparación y se devuelven al fabricante.
 Tab. 5. La participación de varios modelos de discos con chips defectuosos que requieren reparación y reemplazo durante los primeros 4 años de pruebas de campo.
Tab. 5. La participación de varios modelos de discos con chips defectuosos que requieren reparación y reemplazo durante los primeros 4 años de pruebas de campo.También examinamos los síntomas que hacen que el chip se marque como defectuoso: en todos los modelos, aproximadamente dos tercios de los chips se marcan como dañados después de que se forma el 5% de los bloques dañados, y un tercio de los chips se marcan como fallidos después de alcanzar el límite de días con errores.
Notamos que los proveedores de todos los chips de memoria flash para estas unidades dieron una garantía de que el número de bloques dañados por chip no excedería el 2% hasta que se alcanzara el límite de los ciclos de PE. Por lo tanto, dos tercios de los chips defectuosos, en los que más del 5% de los bloques fallaron, no cumplen con la garantía del fabricante.
6.3. Reparación y reemplazo de unidades
La unidad debe ser reemplazada o reparada si surgen problemas que requieren la intervención del personal técnico. La segunda fila de la Tabla 5 muestra el porcentaje de discos que requirieron reparación en algún momento durante los primeros 4 años de operación. Observamos diferencias significativas en las necesidades de reparación de discos de varios modelos. Mientras que para la mayoría de los modelos solo el 6–9% necesita reparación en algún momento, algunos modelos de unidades, como SLC-B y SLC-C, requieren reparación en el 30% y 26% de los casos, respectivamente. Al observar la frecuencia relativa de reparaciones, es decir, la relación entre los días de operación del variador y el número de casos de reparación, la tercera fila de la Tabla 5), observamos un rango de un par de miles de días entre eventos de reparación para los peores modelos a 15,000 días entre reparaciones para los mejores modelos.
También examinamos la frecuencia de las reparaciones repetidas: durante todo el período de operación, el 96% de los discos se someten a solo 1 reparación. Un estudio de la flota de discos operativos mostró que aproximadamente el 5% de las unidades fueron reemplazadas constantemente dentro de los 4 años posteriores a la fecha de puesta en servicio (la cuarta fila de la Tabla 5), mientras que entre los peores modelos (MLC - B y SLC-B), aproximadamente 10% de unidades. Entre los discos reemplazados, aproximadamente la mitad fue a reparar, y se entendió que al menos la mitad de todas las reparaciones serían exitosas.
7. Comparación de MLC, eMLC y SLC - unidades
Los actuadores como eMLC y SLC atraen al mercado de consumo a un precio más alto.Además del hecho de que se caracterizan por la mayor resistencia, es decir, una gran cantidad de ciclos de reescritura, los clientes consideran que dichos productos del segmento más alto del SSD se caracterizan por su confiabilidad y durabilidad generales. En esta sección del artículo, tratamos de evaluar la imparcialidad de esta opinión.
Volviendo a la Tabla 3, vemos que esta opinión es cierta en relación con los discos SLC en relación con RBER, ya que este coeficiente es un orden de magnitud menor que el de las unidades de tecnología MLC y eMLC. Sin embargo, las tablas 2 y 5 muestran que los discos SLC no tienen la mejor confiabilidad: la frecuencia de su reemplazo y reparación, así como la frecuencia de errores opacos no son inferiores a los indicadores similares de unidades fabricadas con otras tecnologías.
Las unidades EMLC muestran RBER más altas que las MLC, incluso teniendo en cuenta que los límites de RBER más bajos para las unidades MLC pueden ser hasta 16 veces más altas en el peor de los casos. Sin embargo, es posible que estas diferencias ocurran debido a una menor litografía que otras diferencias tecnológicas. Con base en las observaciones anteriores, concluimos que las unidades SLC generalmente no son más confiables que las unidades MLC.
8. Comparación con HDD
La pregunta obvia es cómo la fiabilidad de las unidades flash se compara con la fiabilidad de sus principales competidores: los discos duros.
Encontramos que cuando se trata de la frecuencia de reemplazo de discos, las unidades flash ganan. De acuerdo con estudios previos realizados en 2007, alrededor del 2-9% del número total de HDD se reemplaza anualmente, lo que es significativamente más del 4-10% de los SSD reemplazados 4 años después del inicio de la operación. Sin embargo, las unidades flash son menos atractivas cuando se trata de tasas de error. Más del 20% de las unidades flash desarrollan errores irrecuperables durante 4 años de funcionamiento, los bloques dañados aparecen en 30-80% y los chips fallan en 2-7%. Los datos de uno de los trabajos de investigación de 2007 indican la aparición de sectores dañados en solo el 3.5% de los discos duros durante 32 meses. Este es un número bastante bajo, pero dado que el número total de sectores de HDD es un orden de magnitud mayor que el número de bloques o chips SSD, y estos sectores son más pequeños que los bloques, las peores características de los SSD no parecen ser tan graves.
En general, llegamos a la conclusión de que las unidades flash requieren reemplazo con mucha menos frecuencia dentro de la vida útil normal que las unidades de disco duro. Por otro lado, en comparación con los discos duros, los SSD tienen más errores no corregibles.
9. Otros estudios en esta área
Existe una gran cantidad de investigación sobre la confiabilidad de los chips flash basados en experimentos de laboratorio controlados con un pequeño número de chips, enfocados en identificar tendencias en los errores y sus fuentes. Por ejemplo, algunos de los primeros trabajos de 2002-2006 estudiaron la preservación, programación y violación de las operaciones de lectura de chips flash, y en algunos trabajos recientes, se estudian las tendencias en la aparición de errores en los últimos chips MLC. Estábamos interesados en el comportamiento de las unidades flash en el campo, por lo que los resultados de nuestras observaciones a veces difieren de los resultados de estudios publicados anteriormente. Por ejemplo, creemos que RBER no es un indicador confiable de la probabilidad de ocurrencia de errores no corregibles y que RBER crece con ciclos PE linealmente, en lugar de exponencialmente.
Solo hay un estudio de campo publicado recientemente sobre errores de memoria flash basado en datos recopilados en Facebook: "Estudio a gran escala de fallas de memoria flash en el campo" (MEZA, J., WU, Q., KUMAR, S., MUTLU, O. "Un estudio a gran escala de fallas de memoria flash en el campo". En Actas de la Conferencia Internacional ACM SIGMETRICS 2015 sobre Medición y Modelado de Sistemas de Computadora, Nueva York, 2015, SIGMETRICS '15, ACM, pp. 177–190 ) Esto y nuestra investigación se complementan, ya que se superponen muy poco.
Los datos de la encuesta de Facebook consisten en un vistazo rápido a la flota de medios flash, que consiste en discos muy jóvenes (en términos de su uso en comparación con el límite de los valores del ciclo de PE), y contiene información solo sobre errores no corregibles, mientras que nuestro estudio se basa en Intervalos de tiempo que cubren todo el ciclo de vida de los discos e incluye información detallada sobre varios tipos de errores, incluyendo corregibles, varios tipos de fallas de hardware, así como unidades de varias tecnologías (MLC, eMLC, SLC). Como resultado, nuestro estudio cubre una gama más amplia de modos de error y falla, incluido el efecto del desgaste en todo el ciclo de vida.
Por otro lado, el estudio de Facebook toma en cuenta el papel de algunos factores (temperatura, consumo de energía del bus, uso del búfer DRAM) que no tomamos en cuenta.
Nuestros estudios se cruzan solo en dos puntos pequeños, y en ambos casos llegamos a conclusiones ligeramente diferentes:
- un estudio de Facebook examinó la incidencia de errores no corregibles, y estos errores se estudian en función del uso del disco. Los autores del estudio observan una "mortalidad infantil" significativa de las unidades, que llaman "detección temprana" y "falla temprana", mientras que nosotros no. Las diferencias en los resultados pueden explicarse tanto probando las unidades en las dos compañías, que podrían afectar la imagen de "mortalidad infantil", como por el hecho de que la investigación de Facebook se centra más en la vida temprana del disco (sin considerar los puntos clave después de un par de cientos de ciclos de PE para discos cuyos El límite de PE se mide en decenas de miles). Nuestro estudio es de naturaleza más macroscópica y cubre toda la vida útil del disco;
- Un estudio de Facebook concluye que los errores de violación de lectura no tienen un impacto significativo. Nuestra visión de los errores de este tipo es más diferenciada, ya que muestra que la violación de lectura no crea errores irreparables y que los errores de violación de lectura ocurren con una frecuencia lo suficientemente alta como para afectar el RBER en el campo.
10. Conclusiones
Este artículo presenta una serie de hallazgos interesantes con respecto a la confiabilidad de la memoria flash en el campo. Algunos de ellos son consistentes con las suposiciones y expectativas generalmente aceptadas, mientras que la mayoría de las conclusiones son inesperadas. A continuación presentamos conclusiones basadas en los resultados de nuestro estudio.
- En 20-63% de los discos, se produce al menos un error irrecuperable durante los primeros cuatro años de operación, y los errores irrecuperables no corregibles más comunes son de dos a 6 días de 1000 días de operación de los discos.
- En la mayoría de los días de funcionamiento del disco, se produce al menos un error corregible, pero otros tipos de errores transparentes, es decir, errores que son invisibles para el usuario, son raros en comparación con los errores opacos.
- Encontramos que la métrica RBER estándar como indicador de la confiabilidad del disco no es una forma suficientemente buena de predecir fallas que suceden en la práctica. En particular, un RBER más alto no necesariamente resulta en una alta frecuencia de errores no corregibles.
- Creemos que la métrica estándar para medir los errores fatales de UBER no es lo suficientemente objetiva, ya que no vimos la relación entre el UE y el número de lecturas. Debido a esto, la normalización de errores no corregibles por el número de bits de lectura aumentará artificialmente la tasa de error para discos con un número bajo de operaciones de lectura.
- Tanto el RBER como la cantidad de errores no corregibles aumentan con el crecimiento de los ciclos de PE, pero las tasas de crecimiento inferiores a las esperadas ocurren de forma lineal y no exponencial, y no hay saltos bruscos cuando el disco excede el límite de la cantidad de ciclos de PE establecidos por el fabricante para las condiciones de operación.
- Si bien el desgaste durante el funcionamiento del disco es a menudo el centro de atención, debe tenerse en cuenta que, independientemente de la edad del disco, el tiempo que pasa en el campo afecta la confiabilidad del disco.
- Las unidades SLC que apuntan al mercado corporativo y pertenecen al segmento de productos más alto no son más confiables que las unidades MLC que pertenecen al segmento más bajo de SSD.
- , RBER, , , .
- , SSD , HDD, , , , .
- . , .
- : , 30-80% 2-7% . () , .
- , , , , , (, , ). , , .
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un servidor de nivel de entrada analógico único que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps desde $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?