Parece que tengo la costumbre de escribir sobre
máquinas potentes , donde muchos núcleos están
inactivos debido a bloqueos incorrectos. Entonces ... si. De nuevo sobre eso.
Esta historia es especialmente impresionante. De hecho, ¿con qué frecuencia tiene un giro de hilo durante unos segundos en un ciclo de siete comandos, manteniendo un bloqueo que detiene el trabajo de otros 63 procesadores? Es simplemente increíble, en un sentido terrible.
Contrariamente a la creencia popular, en realidad no tengo una máquina con 64 procesadores lógicos, y nunca he visto este problema en particular. Pero mi amigo se topó con él,
este nerd me enganchó, pidió ayuda y decidí que el problema era bastante interesante. Envió un
seguimiento de ETW con suficiente información para que la mente colectiva en Twitter resolviera rápidamente el problema.
La queja del amigo fue bastante simple: recolectó la construcción usando
ninja . Típicamente, ninja hace un gran trabajo al aumentar la carga, constantemente apoyando procesos n + 2 para evitar el tiempo de inactividad. Pero aquí, el uso de la CPU en los primeros 17 segundos del ensamblaje se veía así:

Si observa de cerca (una broma), puede ver una línea delgada donde la carga total de la CPU cae del 100% al 0% en un par de segundos. En solo medio segundo, la carga se reduce de 64 a dos o tres hilos. Aquí hay un fragmento ampliado de una de estas caídas: los segundos se marcan a lo largo del eje horizontal:
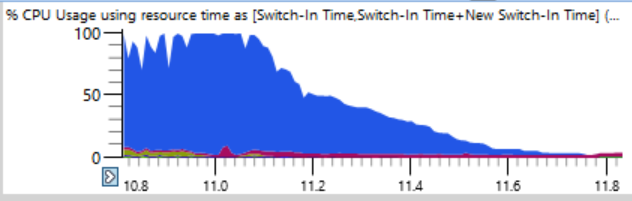
El primer pensamiento fue que ninja no puede crear procesos rápidamente. Lo he visto muchas veces, generalmente debido a la intervención del software antivirus. Pero cuando clasifiqué los gráficos por el tiempo final, descubrí que durante tales choques no se completaron procesos, por lo que ninja no tiene la culpa.
La tabla de
uso de CPU (precisa) es ideal para identificar la causa del tiempo de inactividad. Los registros de todos los cambios de contexto se almacenan allí, incluidos los registros precisos de cada inicio de la transmisión, incluido el lugar y el tiempo de espera.
El truco es que no hay nada de malo en el tiempo de inactividad. El problema surge cuando realmente queremos que el hilo haga el trabajo, pero en cambio está inactivo. Por lo tanto, debe seleccionar ciertos momentos de inactividad.
Al analizar, es importante comprender que el cambio de contexto ocurre cuando un subproceso reanuda la operación. Si miramos esos lugares cuando la carga del procesador comienza a caer, no encontraremos nada. En cambio, concéntrese en cuándo el sistema comenzó a funcionar nuevamente. Esta fase de rastreo es aún más dramática. Mientras que la caída de carga de la CPU tarda medio segundo, el proceso inverso de un subproceso usado a una carga completa tarda solo doce milisegundos. El gráfico a continuación está muy ampliado y, sin embargo, la transición de inactivo a carga es casi una línea vertical:

Acerqué doce milisegundos y encontré 500 cambios de contexto, aquí se requiere un análisis cuidadoso.
La tabla de cambio de contexto tiene muchas columnas que he
documentado aquí . Cuando un proceso se congela, para encontrar la razón, hago una agrupación por nuevos procesos, nuevos hilos, nuevas pilas de hilos, etc. (
discutido aquí ), pero esto no funciona en cientos de procesos detenidos. Si estudié cualquier proceso incorrecto, está claro que fue preparado por el proceso anterior, que fue preparado por el anterior, y escanearía una cadena larga para encontrar el primer enlace que (presumiblemente) mantiene un bloqueo importante durante mucho tiempo.
Entonces, probé un diseño de columna diferente en el programa:
- Tiempo de cambio (cuando ocurrió el cambio de contexto)
- Proceso de preparación (quién liberó el bloqueo después de esperar)
- Nuevo proceso (que comenzó a trabajar)
- Tiempo desde el último (cuánto tiempo ha estado esperando el nuevo proceso)
Esto proporciona una lista ordenada de cambios de contexto con una nota de quién preparó a quién y cuánto tiempo estuvieron listos los procesos para funcionar.
Resultó que esto es suficiente. La tabla a continuación habla por sí sola si sabe cómo leerla. Los primeros cambios de contexto no son de interés, porque el tiempo de espera para un nuevo proceso (Tiempo desde el último) es bastante pequeño, pero en la línea resaltada (# 4) comienza algo interesante:
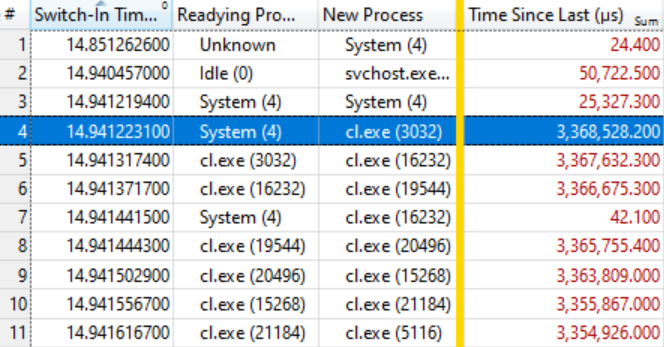
Esta línea dice que el
Sistema (4) preparó el
cl. Exe (3032) , que esperó 3.368 segundos. La siguiente línea dice que en menos de 0.1 ms,
cl. Exe (3032) preparó
cl.exe (16232) , que esperó 3.367 segundos. Y así sucesivamente.
Varios cambios de contexto, como en la línea # 7, no están incluidos en la cadena de espera, sino que simplemente reflejan otro trabajo en el sistema, pero en general la cadena se extiende a muchas decenas de elementos.
Esto significa que todos estos procesos están esperando la liberación del mismo bloqueo. Cuando el proceso del
Sistema (4) libera el bloqueo (¡después de mantenerlo presionado durante 3.368 segundos!), Los procesos de espera, a su vez, lo capturan, hacen su pequeño trabajo y le pasan el bloqueo. La cola de espera tiene aproximadamente cien procesos, lo que muestra el grado de influencia de un solo bloqueo.
Un pequeño estudio de
Ready Thread Stacks mostró que la mayoría de las expectativas provienen de
KernelBase.dllWriteFile . Le pedí a WPA que mostrara los llamadores de esta función, con agrupación. Allí puede ver que en 12 milisegundos de esta catarsis 174 hilos salen de
WriteFile esperando, y esperaron un promedio de 1,184 segundos:
 174 hilos en espera de WriteFile, tiempo de espera promedio 1.184 segundos
174 hilos en espera de WriteFile, tiempo de espera promedio 1.184 segundosEste es un retraso asombroso y, de hecho, ni siquiera la extensión total del problema, porque muchos hilos de otras funciones, como
KernelBase.dll! GetQueuedCompletionStatus, esperan el lanzamiento del mismo bloqueo.
Qué hace el sistema (4)
En este punto, sabía que el progreso de la compilación se detuvo porque todos los procesos del compilador y otros esperaban
WriteFile , ya que el
Sistema (4) mantuvo el bloqueo. Otra columna de
Id. De subproceso listo mostró que el subproceso 3276 liberó el bloqueo en el proceso del sistema.
Durante todos los "bloqueos" del ensamblaje, el subproceso 3276 se cargó al 100%, por lo que está claro que funcionó un poco en la CPU mientras mantenía el bloqueo. Para averiguar dónde se invierte el tiempo de la CPU, veamos el
gráfico de Uso de la
CPU (Muestreo) para el hilo 3276. Los datos de uso de la CPU fueron sorprendentemente claros. ¡Casi todo el tiempo toma el trabajo de una función
ntoskrnl.exe! RtlFindNextForwardRunClear (el número de muestras se indica en la columna con números):
 ¡La pila de llamadas conduce a ntoskrnl.exe! RtlFindNextForwardRunClear
¡La pila de llamadas conduce a ntoskrnl.exe! RtlFindNextForwardRunClearAl ver la pila de subprocesos,
Readying Thread Id confirmó que
NtfsCheckpointVolume liberó el bloqueo después de 3.368 s:
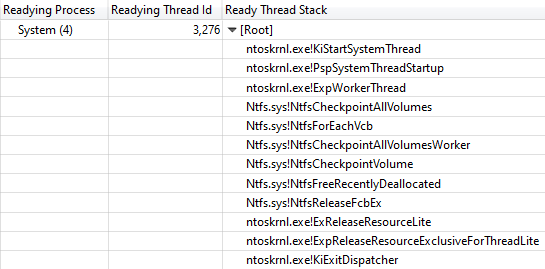 Llamar a la pila desde NtfsCheckpointVolume a ExReleaseResourceLite
Llamar a la pila desde NtfsCheckpointVolume a ExReleaseResourceLiteEn este momento, me pareció que era hora de usar el rico conocimiento de mis seguidores en Twitter, así que publiqué
esta pregunta y mostré una pila de llamadas completa. Los tweets con tales preguntas pueden ser muy efectivos si proporciona suficiente información.
En este caso, la
respuesta correcta de
Caitlin Gadd llegó muy rápidamente, junto con muchas otras sugerencias geniales. Apagó la función de recuperación del sistema, ¡y de repente la construcción fue dos o tres veces más rápida!
Pero espera, aún más es mejor
Bloquear la ejecución en todo el sistema durante más de 3 segundos es bastante impresionante, pero la situación es aún más impresionante si agrega la columna
Dirección a la tabla de
Uso de CPU (Muestreo) y ordena por ella. Muestra dónde exactamente en
RtlFindNextForwardRunClear se obtienen muestras, ¡y el 99% de ellas corresponden a una sola instrucción!

Tomé los
archivos ntoskrnl.exe y
ntkrnlmp.pdb (la misma versión que mi amigo) y ejecuté
dumpbin /disasm para ver la función de interés en el ensamblador. Los primeros dígitos de las direcciones son diferentes porque el código se mueve en el arranque, pero los últimos cuatro valores hexadecimales son los mismos (no cambian después de ASLR):
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx
140064652: 73 0F jae 0000000140064663
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663
140064659: 49 83 C0 04 agregar r8.4
14006465D: 41 83 C1 20 agregar r9d, 20h
140064661: EB EC jmp 000000014006464F
...
Vemos que la instrucción sobre ... 4657 se incluye en un ciclo de siete instrucciones, que se encuentran en otras muestras. El número de tales muestras se indica a la derecha:
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx 4
140064652: 73 0F jae 0000000140064663 41
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663 7498
140064659: 49 83 C0 04 agregar r8.4 2
14006465D: 41 83 C1 20 agregar r9d, 20h 1
140064661: EB EC jmp 000000014006464F 1
...
Como ejercicio para el lector, dejemos la interpretación del número de muestras en un procesador superescalar con una ejecución extraordinaria de instrucciones, aunque se pueden encontrar algunas buenas ideas en
este artículo . En este caso, tenemos un AMD Ryzen Threadripper 2990WX de 32 núcleos. Aparentemente, la función de procesador de Micro-Up Fusion con la ejecución de cinco instrucciones a la vez realmente permite que cada ciclo se complete en jne, ya que la instrucción después de la instrucción más costosa cae en la mayoría de las interrupciones en la selección.
Entonces resulta que una máquina con 64 procesadores lógicos se detiene por un ciclo de siete comandos en el proceso del sistema, mientras mantiene un bloqueo NTFS vital, que se corrige al desactivar la recuperación del sistema.
Coda
No está claro por qué este código se comportó mal en esta máquina en particular. Supongo que esto está relacionado de alguna manera con la distribución de datos en un disco de 2 TB casi vacío. Cuando la recuperación del sistema se volvió a activar, el problema también volvió, pero no tan grave. ¿Quizás hay algún tipo de patología para discos con enormes fragmentos de espacio vacío?
Otro seguidor en Twitter mencionó el error Volume Shadow Copy de Windows 7, que permite la
ejecución durante O (n ^ 2) . Este error supuestamente se solucionó en Windows 8, pero puede haberse conservado de alguna forma. Mis trazas de pila muestran claramente que
VspUpperFindNextForwardRunClearLimited (encontrar un bit usado en esta área de 16 megabytes) llama a
VspUpperFindNextForwardRunClear (buscando el siguiente bit usado en cualquier lugar, pero no lo devuelve si está fuera del área especificada). Por supuesto, esto provoca una cierta sensación de deja vu. Como dije
recientemente , O (n ^ 2) es un punto débil de algoritmos poco escalables. Aquí coinciden dos factores: dicho código es lo suficientemente rápido como para entrar en producción, pero lo suficientemente lento como para abandonar esta producción.
Hubo informes de que ocurre un problema similar con una
eliminación masiva de archivos , pero nuestro seguimiento no muestra muchas eliminaciones, por lo que el problema, aparentemente, no es ese.
En conclusión, duplicaré el programa de carga de CPU de todo el sistema desde el comienzo del artículo, pero esta vez indicando el uso de CPU por el proceso del problema del
sistema (en verde a continuación). En tal imagen, el problema es completamente obvio. El proceso del sistema es técnicamente visible en el gráfico superior, pero en esta escala es fácil pasarlo por alto.
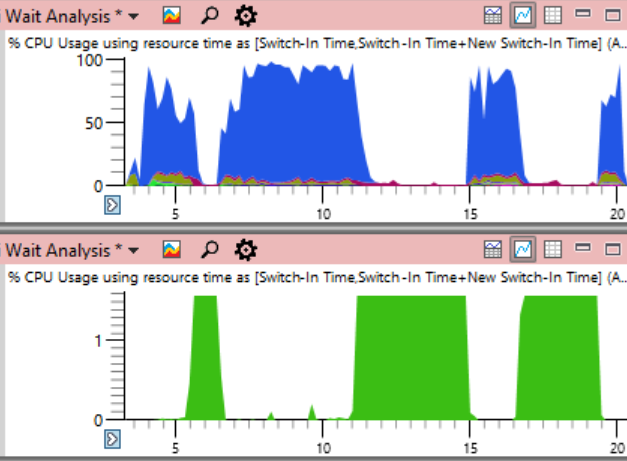
Aunque el problema es claramente visible en el gráfico, en realidad no prueba nada.
Como dicen , la correlación no es una relación causal. Solo un análisis de los eventos de cambio de contexto muestra que es este flujo el que mantiene el bloqueo crítico, y luego puede estar seguro de que hemos encontrado la causa real, y no solo una correlación aleatoria.
Consultas
Como de costumbre, concluyo esta investigación con una
llamada para nombrar mejor los hilos . El proceso del sistema tiene docenas de hilos, muchos de los cuales tienen un propósito especial, y ninguno tiene un nombre. El subproceso del sistema más ocupado en esta traza fue
MiZeroPageThread . Me sumergí repetidamente en su pila, y cada vez que recordaba que no era de interés. El compilador de VC ++ tampoco nombra sus hilos. Cambiar el nombre de las transmisiones no lleva mucho tiempo, y es realmente útil. Solo dale el nombre.
Es simple Chromium incluso incluye una herramienta para
listar nombres de secuencias en un proceso .
Si alguien del equipo NTFS de Microsoft quiere hablar sobre este tema, hágamelo saber y puedo conectarlo con el autor del informe original y proporcionarle un seguimiento de ETW.
Referencias