El fundador y director de Otomato Software, uno de los iniciadores e instructores de la primera certificación DevOps de Israel, Anton Weiss, habló sobre la teoría del caos y los principios básicos de la ingeniería caótica en
DevOpsDays Moscú el año pasado, y también explicó cómo funciona la organización DevOps ideal del futuro.
Hemos preparado una versión de texto del informe.
Buenos dias
DevOpsDays en Moscú por segundo año consecutivo, soy la segunda vez en este escenario, muchos de ustedes son la segunda vez en esta sala. ¿Qué significa esto? Esto significa que el movimiento DevOps en Rusia está creciendo, multiplicándose y, lo que es más importante, significa que es hora de hablar sobre qué es DevOps en 2018.
Levanta tus manos aquellos que piensan que en 2018 DevOps ya es una profesión? Hay algunos. ¿Hay ingenieros de DevOps en la sala que tengan un "ingeniero de DevOps" escrito en la descripción del trabajo? ¿Hay gerentes de DevOps en la sala? No hay ninguno Arquitectos DevOps? No tampoco. No es suficiente ¿Qué, realmente, nadie ha escrito que él es un ingeniero de DevOps?
¿Entonces la mayoría de ustedes piensa que esto es antipatrón? ¿Qué no debería ser una profesión así? Podemos pensar cualquier cosa, pero por ahora creemos que la industria está avanzando solemnemente hacia los sonidos de la tubería DevOps.
¿Quién escuchó sobre un nuevo tema llamado DevDevOps? Esta es una técnica tan nueva que permite una cooperación efectiva entre desarrolladores y desarrolladores. Y no tan nuevo. A juzgar por Twitter, hace 4 años comenzaron a hablar de ello. Y aún así el interés en esto está creciendo y creciendo, es decir, hay un problema. El problema debe ser resuelto.

Somos personas creativas, así que no te calmes. Decimos: DevOps no es una palabra lo suficientemente completa; todavía no hay suficientes elementos interesantes diferentes. Y vamos a nuestros laboratorios secretos y comenzamos a producir mutaciones interesantes: DevTestOps, GitOps, DevSecOps, BizDevOps, ProdOps.
La lógica es de hierro, ¿verdad? Nuestro sistema de entrega no es funcional, nuestros sistemas son inestables y los usuarios no están satisfechos, no tenemos tiempo para implementar el software a tiempo, no nos ajustamos al presupuesto. ¿Cómo resolveremos todo esto? Vamos a inventar una nueva palabra! Terminará en Ops y se resolverá el problema.
Entonces llamo a este enfoque: "Ops, y el problema está resuelto".
Todo esto se desvanece en el fondo si nos recordamos por qué se nos ocurrió todo esto. Se nos ocurrió todo este DevOps para hacer que la entrega de software y nuestro propio trabajo en este proceso sean sin obstáculos, indoloros, efectivos y, lo más importante, agradables.
DevOps ha surgido del dolor. Y estamos cansados de sufrir. Y para que esto suceda, confiamos en las prácticas imperecederas: colaboración efectiva, prácticas de flujo y, lo más importante, pensamiento sistémico, porque sin él, ningún DevOps funciona.
¿Qué es un sistema?
Y si ya estamos hablando del pensamiento sistémico, recordemos qué es un sistema.

Si eres un hacker revolucionario, entonces para ti el sistema es un mal claro. Esta es una nube que se cierne sobre ti y te hace hacer lo que no quieres hacer.

Desde el punto de vista del pensamiento sistémico, un sistema es un todo que consta de partes. En este sentido, cada uno de nosotros es un sistema. Las organizaciones para las que trabajamos son sistemas. Y lo que estamos construyendo es lo que se llama: el sistema.
Todo esto es parte de un gran sistema sociotecnológico. Y solo si entendemos cómo este sistema sociotecnológico funciona en conjunto, solo entonces podemos realmente optimizar algo en este asunto.
Desde el punto de vista del pensamiento sistémico, un sistema tiene varias propiedades interesantes. En primer lugar, consta de partes, lo que significa que su comportamiento depende del comportamiento de las partes. Además, todas sus partes también son interdependientes. Resulta que mientras más partes tiene el sistema, más difícil es comprender o predecir su comportamiento.
En términos de comportamiento, hay otro hecho interesante. El sistema puede hacer algo que ninguna de sus partes individuales puede hacer.
Como dijo el Dr. Russell Akoff (uno de los fundadores del pensamiento sistémico), esto es bastante fácil de probar con la ayuda de un experimento mental. Por ejemplo, ¿quién en la audiencia puede escribir código? Muchas manos, y esto es normal, porque este es uno de los requisitos básicos para nuestra profesión. ¿Puedes escribir y tus manos pueden escribir código por separado de ti? Hay personas que dicen: "Mis manos no escriben código, mi cerebro escribe código". ¿Puede el cerebro escribir código por separado de usted? Bueno, muy probablemente no.
El cerebro es una máquina increíble, el 10% de nosotros no sabemos cómo funciona allí, pero no puede funcionar por separado del sistema que es nuestro cuerpo. Y esto es fácil de probar: abre tu caja de calaveras, saca tu cerebro de ella, ponla frente a la computadora, deja que intente escribir algo simple. "Hola, mundo" en Python, por ejemplo.
Si un sistema puede hacer algo que ninguna de sus partes puede hacer individualmente, entonces esto significa que su comportamiento no está determinado por el comportamiento de sus partes. ¿Y entonces por qué está determinado? Está determinado por la interacción entre estas partes. Y en consecuencia, cuantas más partes, más difícil sea la interacción, más difícil será comprender y predecir el comportamiento del sistema. Y esto hace que un sistema de este tipo sea caótico, porque cualquiera, el cambio más pequeño e invisible a la vista en cualquier parte del sistema puede conducir a resultados completamente impredecibles.
Esta sensibilidad a las condiciones iniciales fue descubierta e investigada por primera vez por el meteorólogo estadounidense Ed Lorenz. Posteriormente, se llamó el "efecto mariposa" y condujo al desarrollo de un movimiento de pensamiento científico llamado "teoría del caos". Esta teoría se ha convertido en uno de los principales cambios de paradigma en la ciencia del siglo XX.
Teoría del caos
Las personas que estudian el caos se llaman caosólogos.

En realidad, la razón de este informe fue que, trabajando con sistemas distribuidos complejos y grandes organizaciones internacionales, en algún momento me di cuenta de que esto es lo que siento. Soy caosologo. Esto, en general, es una manera ingeniosa de decir: "No entiendo lo que está sucediendo aquí y no sé qué hacer con eso".
Creo que muchos de ustedes también se sienten tan a menudo, por lo que también son caosólogos. Te invito al gremio de caosólogos. Los sistemas que nosotros, queridos colegas de caosólogos, estudiaremos, se denominan "sistemas adaptativos complejos".
¿Qué es la adaptabilidad? Adaptabilidad significa que el comportamiento individual y colectivo de las partes en dicho sistema adaptativo cambia y se autoorganiza, respondiendo a eventos o cadenas de microeventos en el sistema. Es decir, el sistema se adapta a los cambios a través de la autoorganización. Y esta capacidad de autoorganización se basa en la cooperación voluntaria y completamente descentralizada de los agentes autónomos libres.
Otra propiedad interesante de tales sistemas es que son libremente escalables. Que nosotros, como caosólogos-ingenieros, sin duda deberíamos ser de interés. Entonces, si dijimos que el comportamiento de un sistema complejo está determinado por la interacción de sus partes, entonces, ¿qué debería interesarnos? Interacción
Hay dos conclusiones más interesantes.

Primero, entendemos que un sistema complejo no se puede simplificar simplificando sus partes. En segundo lugar, la única forma de simplificar un sistema complejo es simplificar las interacciones entre sus partes.
¿Cómo interactuamos? Todos somos parte de un gran sistema de información llamado sociedad humana. Interactuamos a través de un lenguaje común, si lo tenemos, si lo encontramos.
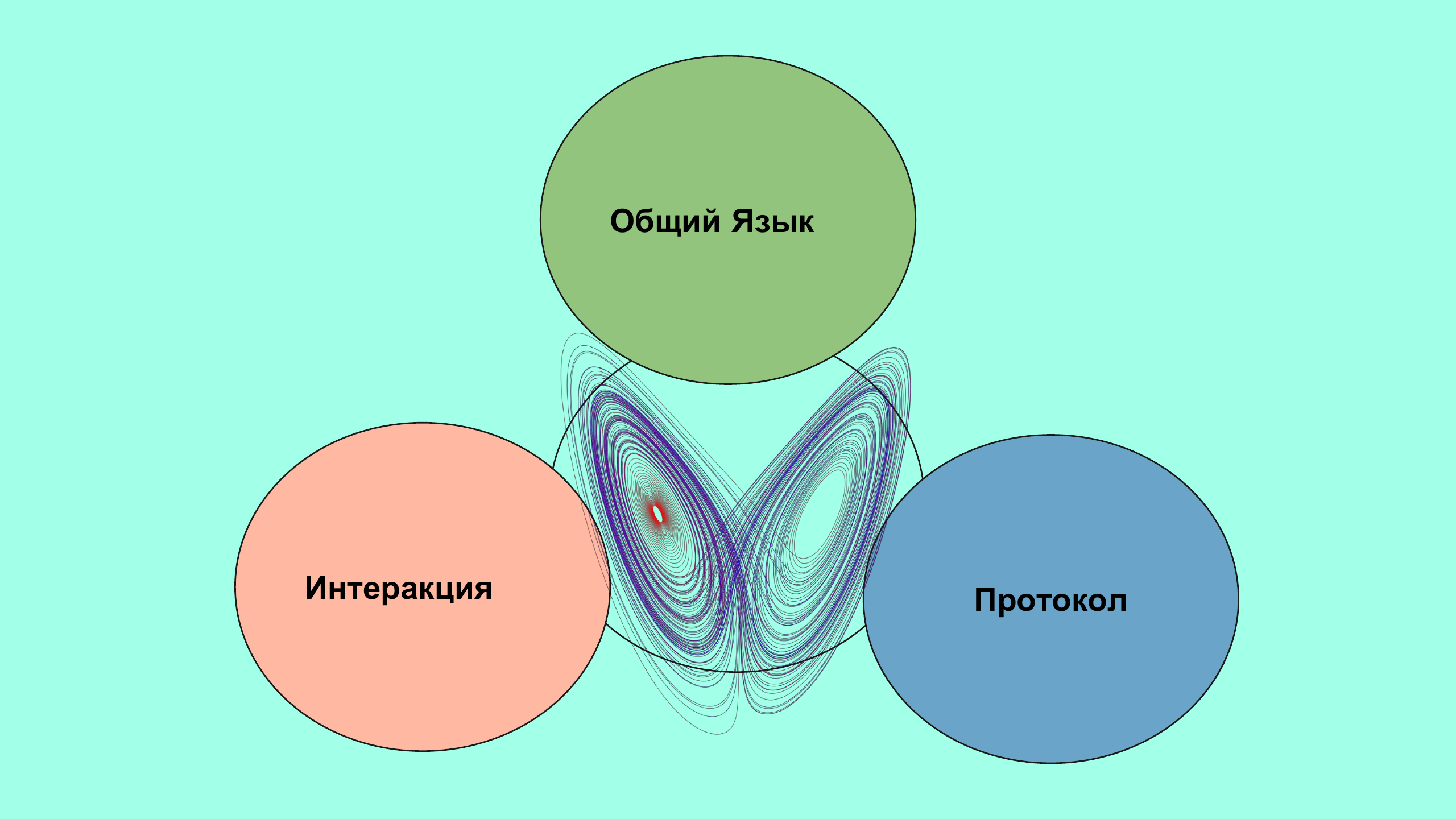
Pero el lenguaje en sí es un sistema adaptativo complejo. En consecuencia, para interactuar de manera más eficiente y simple, necesitamos crear algún tipo de protocolos. Es decir, una secuencia de símbolos y acciones que harán que el intercambio de información entre nosotros sea más simple, más predecible, más comprensible.
Quiero decir que las tendencias a la complicación, a la adaptabilidad, a la descentralización, a la aleatoriedad se remontan en todo. Y en esos sistemas que estamos construyendo, y en aquellos sistemas de los cuales somos parte.
Y para no ser infundado, veamos cómo están cambiando los sistemas que creamos.

Estabas esperando esta palabra, lo entiendo. Estamos en la conferencia DevOps, hoy esta palabra sonará en algún lugar cien mil veces y luego soñaremos por la noche.
Microservices es la primera arquitectura de software que surgió como reacción a las prácticas de DevOps, que está diseñada para hacer que nuestros sistemas sean más flexibles, más escalables y garanticen una entrega continua. ¿Cómo hace ella esto? Al reducir el volumen de servicios, reduciendo los límites de los problemas que procesan estos servicios, reduciendo el tiempo de entrega. Es decir, reducimos, simplificamos partes del sistema, aumentamos su número, en consecuencia, la complejidad de las interacciones entre estas partes aumenta constantemente, es decir, surgen nuevos problemas que tenemos que resolver.

Los microservicios no son el final, los microservicios son, en general, ya ayer, porque Serverless está llegando. Todos los servidores quemados, sin servidores, sin sistemas operativos, solo código ejecutable limpio. La configuración está separada, el estado está separado, todo está controlado por eventos. Belleza, pureza, silencio, sin eventos, no pasa nada, orden completo.
¿Dónde está la dificultad? Complejidad, por supuesto, en las interacciones. ¿Cuánto puede hacer una función por sí sola? ¿Cómo interactúa con otras funciones? Colas de mensajes, bases de datos, equilibradores. ¿Cómo recrear un evento cuando ocurre una falla? Un montón de preguntas y pocas respuestas.
Microservicios y Serverless son todo lo que los hipsters de computadoras llamamos Cloud Native. Se trata de la nube. Pero la nube también es esencialmente escalable. Estamos acostumbrados a pensarlo como un sistema distribuido. De hecho, ¿dónde viven los servidores del proveedor de la nube? En centros de datos. Es decir, aquí tenemos un cierto modelo centralizado, muy limitado y distribuido.
Hoy entendemos que Internet de las cosas ya no son solo palabras importantes que, incluso según predicciones modestas, miles de millones de dispositivos conectados a Internet nos esperan en los próximos cinco a diez años. Una gran cantidad de datos útiles e inútiles que se fusionarán en la nube y se inundarán desde la nube.
La nube no se mantendrá, por lo que estamos hablando cada vez más de lo que se llama "computación periférica". O también me gusta la maravillosa definición de la computación de niebla. Está hecha jirones con el misticismo del romanticismo y el misterio.

Misty informática. El punto es que las nubes son coágulos centralizados de agua, vapor, hielo, piedras. Y la niebla son gotas de agua que se encuentran dispersas a nuestro alrededor en la atmósfera.
En un paradigma brumoso, la mayor parte del trabajo es realizado por estas gotitas de manera completamente autónoma o en colaboración con otras gotitas. Y recurren a la nube solo cuando realmente lo hacen.
Es decir, nuevamente, descentralización, autonomía y, por supuesto, muchos de ustedes ya entienden de qué se trata, porque no pueden hablar de descentralización y no mencionar la cadena de bloques.
Hay quienes creen, estos son los que han invertido en criptomonedas. Hay quienes creen, pero tienen miedo, como yo, por ejemplo. Y hay quienes no creen. Aquí puedes relacionarte de manera diferente. Hay tecnología, un nuevo negocio incomprensible, hay problemas. Como cualquier tecnología nueva, plantea más preguntas que respuestas.
La exageración alrededor de la cadena de bloques es comprensible. Incluso si dejas de lado la fiebre del oro, la tecnología en sí misma hace maravillosas promesas de un futuro más brillante: más libertad, más autonomía, confianza global distribuida. ¿Qué hay para no querer?
En consecuencia, cada vez más ingenieros de todo el mundo están comenzando a desarrollar aplicaciones descentralizadas. Y esta es una fuerza que no se puede descartar simplemente diciendo: "Ahh, la cadena de bloques es solo una base de datos distribuida mal implementada". O cómo les gusta decir a los escépticos: "No hay usos reales para la cadena de bloques". Si lo piensas, hace 150 años dijeron lo mismo sobre la electricidad. E incluso en algunos aspectos tenían razón, porque lo que la electricidad hace posible hoy en el siglo XIX no era realista de ninguna manera.
Por cierto, ¿quién sabe qué tipo de logotipo hay en la pantalla? Este es Hyperledger. Este es un proyecto que se está desarrollando bajo los auspicios de The Linux Foundation, incluye un conjunto de tecnologías blockchain. Este es realmente el poder de nuestra comunidad de código abierto.
Ingeniería del caos

Entonces, el sistema que estamos desarrollando se está volviendo más complejo, más caótico, más adaptable. Netflix: pioneros de los sistemas de microservicios. Fueron uno de los primeros en entender esto, desarrollaron un kit de herramientas llamado Simian Army, el más famoso de los cuales fue
Chaos Monkey . Definió lo que se conoció como los
"principios de la ingeniería del caos" .
Por cierto, en el proceso de trabajar en el informe, incluso tradujimos este texto al ruso, así que vaya al
enlace , lea, comente, regañe.
Brevemente, los principios de la ingeniería del caos indican lo siguiente. Los sistemas distribuidos complejos son inherentemente impredecibles e inherentemente tienen errores en ellos. Los errores son inevitables, lo que significa que debemos aceptar estos errores y trabajar con estos sistemas de una manera completamente diferente.
Nosotros mismos debemos tratar de introducir estos errores en nuestros sistemas de producción para probar nuestros sistemas en busca de esta adaptabilidad, de esta capacidad de autoorganizarse, de sobrevivir.
Y eso lo cambia todo. No solo cómo ejecutamos el sistema en producción, sino también cómo los desarrollamos, cómo los probamos. No hay proceso de estabilización, congelación de código, por el contrario, hay un proceso constante de desestabilización. Estamos tratando de matar el sistema y ver que continúa sobreviviendo.
Protocolos de integración de sistemas distribuidos

En consecuencia, esto requiere que nuestros sistemas también cambien de alguna manera. Para que se vuelvan más estables, necesitan algunos protocolos nuevos de interacción entre sus partes. Para que estas partes puedan negociar y llegar a algún tipo de autoorganización. Y hay todo tipo de nuevas herramientas, nuevos protocolos, que llamo "protocolos para la interacción de sistemas distribuidos".

De que estoy hablando En primer lugar, el proyecto
Opentracing . Algunos intentan crear un protocolo común para el seguimiento distribuido, que es una herramienta absolutamente indispensable para depurar sistemas distribuidos complejos.

El siguiente es el
Open Policy Agent . Decimos que no podemos predecir qué sucederá con el sistema, es decir, necesitamos aumentar su observabilidad, observabilidad. Opentracing es una familia de herramientas que dan observabilidad a nuestros sistemas. Pero necesitamos observabilidad para determinar si el sistema se comporta como esperamos de él o no. ¿Cómo determinamos el comportamiento esperado? Al definir en él algún tipo de política, algún tipo de conjunto de reglas. El proyecto Open Policy Agent está definiendo este conjunto de reglas en una amplia gama: desde el acceso hasta la asignación de recursos.

Como dijimos, nuestros sistemas están cada vez más impulsados por eventos. Sin servidor es un gran ejemplo de sistemas controlados por eventos. Para poder transmitir eventos entre sistemas y rastrearlos, necesitamos un lenguaje común, un protocolo común de cómo hablamos de eventos, cómo los transmitimos entre nosotros. Este es un proyecto llamado
Cloudevents .

El flujo continuo de cambios que lava nuestros sistemas, desestabilizándolos constantemente, es un flujo continuo de artefactos de software. Para que podamos mantener este flujo constante de cambios, necesitamos un protocolo general con el que podamos hablar sobre qué es un artefacto de software, cómo se verifica, qué verificación pasó. Este es un proyecto llamado
Grafeas . Es decir, un protocolo de metadatos de artefactos de software común.

Y, por último, si queremos que nuestros sistemas sean completamente independientes, adaptables y autoorganizados, debemos otorgarles el derecho a la autoidentificación. Un proyecto llamado
spiffe hace exactamente eso. Este es también un proyecto patrocinado por la Cloud Native Computing Foundation.
Todos estos proyectos son jóvenes, todos necesitan nuestro amor, nuestra prueba. Todo esto es de código abierto, nuestras pruebas, nuestra implementación. Nos muestran en qué dirección se mueve la tecnología.
Pero DevOps nunca se trató principalmente de tecnología, principalmente se trató de colaboración entre personas. Y, en consecuencia, si queremos que cambien los sistemas que desarrollamos, debemos cambiar nosotros mismos. De hecho, ya estamos cambiando, no tenemos otra opción en particular.
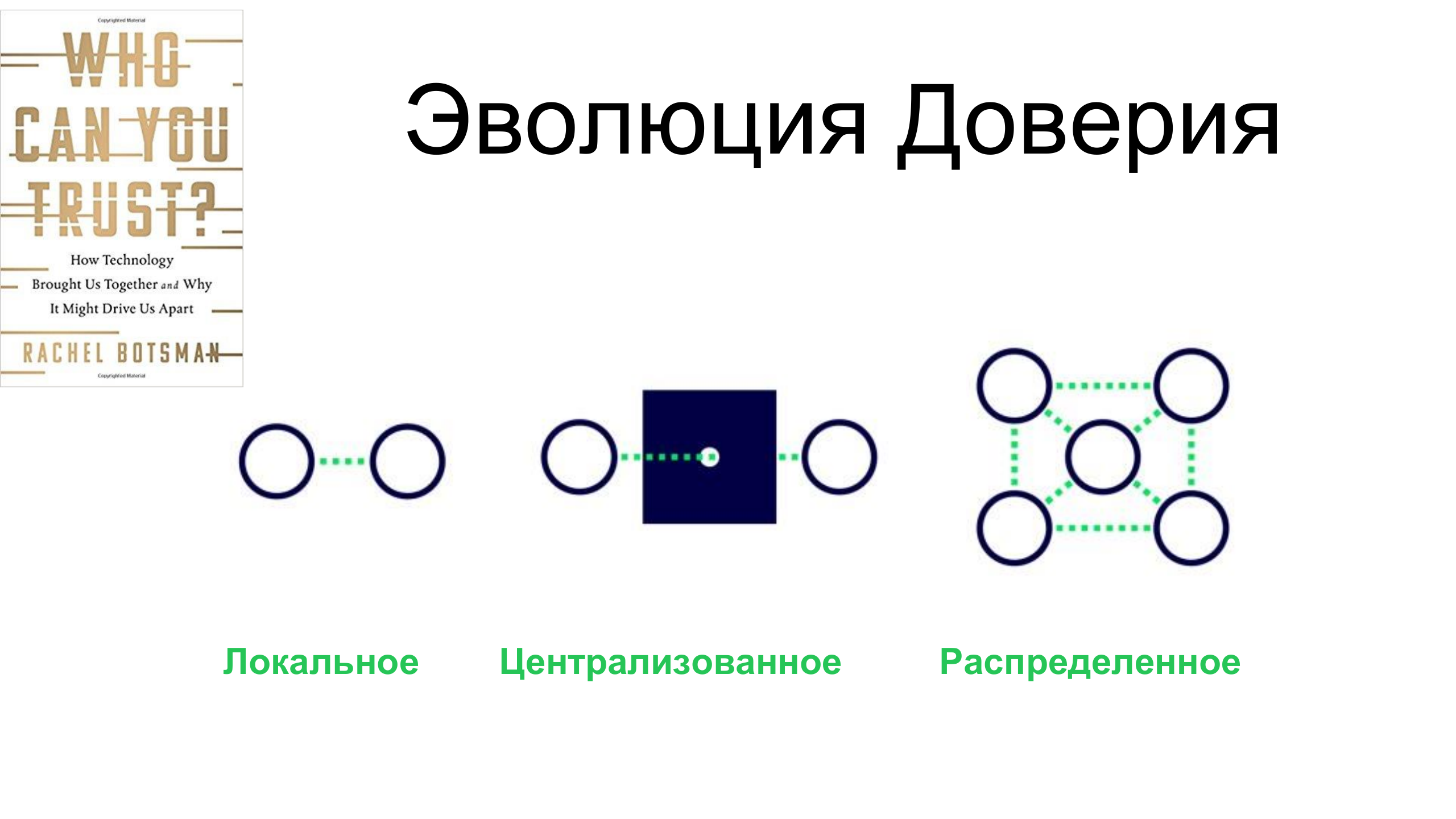
Hay un
libro maravilloso
de la escritora británica Rachel Botsman en el que escribe sobre la evolución de la confianza a lo largo de la historia humana. Ella dice que inicialmente, en las sociedades primitivas, la confianza era local, es decir, confiamos solo en aquellos a quienes conocemos personalmente.
Luego hubo un período muy largo, un tiempo oscuro, cuando la confianza se centralizó, cuando comenzamos a confiar en las personas que no conocemos porque pertenecemos a la misma institución pública o estatal.
Y esto es lo que vemos en nuestro mundo moderno: la confianza se está volviendo cada vez más distribuida y descentralizada, y se basa en la libertad de los flujos de información, en la disponibilidad de información.
Si lo piensa, esta misma accesibilidad que hace posible esta confianza es lo que estamos implementando. , , , , , IT- . .
DevOps-
DevOps- — , , , . , , . , ? .
, . , , .

DevOps-: , , , .
, , , , , , , , . , . , , .

, , . , , - , , .
, , . - , , . , .
, , — , , .
: , , . , . , , , - , , , , , , «Ops!», .
Chaos Monkey?, , . Netflix . . , , - .
, , . . . .
, , , , , . , ., — . , . ? , . .
DevOps — ?. : , , , , .
- : ?, , , , , , , , . — . , : , . .
, , , , , , , ? DevOps ?, . ?
, , — . , . .Netflix, . ? . , , . — , , , , - , . . , — .
, ? , ? . , , , , , . , , DevOps.. , :
. . , .
DevOpsDays Moscow 7 «». 11 . , .
, 7000 . !