
Hola Habr! Continuamos publicando reseñas de artículos científicos de miembros de la comunidad Open Data Science del canal #article_essense. Si quieres recibirlos antes que los demás, ¡únete a la comunidad !
Artículos para hoy:
- Rotación de capas: ¿un indicador sorprendentemente poderoso de generalización en redes profundas? (Université catholique de Louvain, Bélgica, 2018)
- Aprendizaje de transferencia eficiente de parámetros para PNL (Google Research, Jagiellonian University, 2019)
- RoBERTa: un enfoque de capacitación previa BERT robustamente optimizado (Universidad de Washington, Facebook AI, 2019)
- EfficientNet: repensar la escala del modelo para redes neuronales convolucionales (Google Research, 2019)
- Cómo pasa el cerebro de la percepción consciente a la subliminal (EE. UU., Argentina, España, 2019)
- Grandes capas de memoria con claves de producto (Facebook AI Research, 2019)
- ¿Realmente estamos progresando mucho? Un análisis preocupante de los enfoques recientes de recomendaciones neuronales (Politecnico di Milano, Universidad de Klagenfurt, 2019)
- Omni-Scale Feature Learning para reidentificación de personas (University of Surrey, Queen Mary University, Samsung AI, 2019)
- La reparameterización neuronal mejora la optimización estructural (Google Research, 2019)
Enlaces a colecciones pasadas de la serie: 1. Rotación de capas: ¿un indicador sorprendentemente poderoso de generalización en redes profundas?
Autores: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Bélgica, 2018)
→ Artículo original
Autor de la revisión: Svyatoslav Skoblov (en slack error_derivative)

En este artículo, los autores llamaron la atención sobre una observación bastante simple: la distancia del coseno entre los pesos de las capas durante la inicialización y después del entrenamiento (el proceso de aumentar la distancia durante el entrenamiento se llama rotación de capas). Los caballeros dicen que en la mayoría de los experimentos, las redes que han alcanzado una distancia de 1 en todas las capas son consistentemente superiores en precisión a otras configuraciones. El documento también presenta el algoritmo Layca (Cantidad controlada de rotación de peso a nivel de capa), que permite utilizar esta tasa de aprendizaje en capas para controlar esta misma rotación de capa. De hecho, difiere del algoritmo SGD habitual por la presencia de proyección ortogonal y normalización. En el artículo se puede encontrar una lista detallada del algoritmo junto con el esquema de capacitación.
La idea principal que deducen los autores es: cuanto mayor sea la rotación de las capas, mejor será el rendimiento de la generalización . La mayor parte del artículo es un registro de experimentos en los que se estudiaron varios escenarios de capacitación: MNIST, CIFAR-10 / CIFAR-100, se utilizó una pequeña ImageNet con diferentes arquitecturas, desde una red de una sola capa hasta la familia ResNet.
Una serie de experimentos se dividió en varias etapas:
- Vanilla SGD Resultó que, en general, el comportamiento de las escalas coincide con la hipótesis (grandes cambios en la distancia correspondieron a los mejores valores métricos), sin embargo, también se notaron problemas: la rotación de la capa se detuvo mucho antes de los valores deseados; También se notó inestabilidad en el cambio de distancia.
- Descenso de peso SGD + La disminución de la norma de peso mejoró en gran medida la imagen de entrenamiento: la mayoría de las capas alcanzaron la distancia máxima, y el rendimiento de la prueba es similar al Layca propuesto. La ventaja indudable del método del autor es la falta de un hiperparámetro adicional.
- Calentamientos LR Resultó que el calentamiento ayuda a SGD a superar el problema de la rotación inestable de la capa, sin embargo, no tiene ningún efecto en Layca.
- Métodos de gradiente adaptativos Además de la verdad bien conocida (que al usar estos métodos es más difícil lograr el nivel de generalización que SGD + descomposición de peso puede dar), resultó que los efectos de la rotación de capas son muy diferentes: el primer aumento de rotación en las últimas capas, mientras que SGD en las capas iniciales . Los autores insinúan que esta puede ser la mezquindad de los métodos adaptativos. Y sugieren usar Layca junto con ellos (mejorando la capacidad de generalizar en métodos adaptativos y acelerando el aprendizaje en SGD).
El artículo concluye con un intento de interpretar el fenómeno. Para hacer esto, los autores entrenaron una red con 1 capa oculta en una versión reducida de MNIST, después de lo cual visualizaron neuronas aleatorias, llegando a una conclusión bastante lógica: un mayor grado de rotación de la capa corresponde a un menor efecto de inicialización y un mejor estudio de las características, lo que contribuye a una mejor generalización.
Se cargan el código del algoritmo implementado (tf / keras) y el código para reproducir experimentos.
2. Aprendizaje de transferencia eficiente de parámetros para PNL
Autores del artículo: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Google Research, Universidad Jagiellonian, 2019)
→ Artículo original
Autor de la revisión: Alexey Karnachev (en slack zhirzemli)
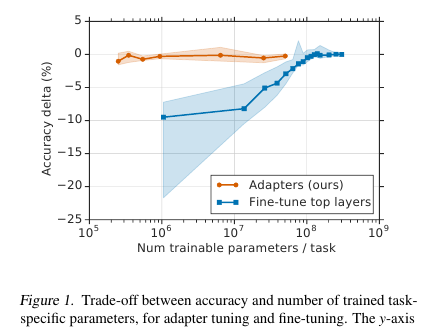
Aquí los caballeros ofrecen una técnica de ajuste simple pero efectiva para los modelos de PNL (en este caso, BERT). La idea es integrar capas de aprendizaje (adaptadores) directamente en la red. Cada una de estas capas es una red con un cuello de botella, que adapta los estados latentes del modelo original a una tarea específica aguas abajo. Los pesos del modelo original, a su vez, permanecen congelados.
Motivación
En las condiciones de la capacitación de transmisión (o capacitación casi en línea), donde hay muchas tareas posteriores, realmente no quiero presentar el modelo completo. En primer lugar, durante mucho tiempo, y en segundo lugar, es difícil, y en tercer lugar, incluso si está ajustado, el modelo debe almacenarse de alguna manera: para volcar o guardar en la memoria. Y no podremos reutilizar este modelo para la siguiente tarea: cada vez que tengamos que sintonizar de una manera nueva. Como resultado, podemos intentar adaptar los estados de red ocultos al problema actual. Además, el modelo original permanece intacto, y los adaptadores en sí mismos son mucho más capaces que el modelo principal (~ 4% del número total de parámetros)
Implementación
El problema se resuelve de una manera increíblemente simple: agregamos 2 adaptadores a cada capa del modelo. Antes de la normalización de capa en los modelos basados en transformadores, se produce una conexión de omisión: la entrada transformada (estado oculto actual) se agrega a la entrada original.
Hay 2 secciones de este tipo en cada capa de transformador: una después de la atención de múltiples cabezales y la segunda después de la alimentación hacia adelante. Por lo tanto, los estados ocultos de estas secciones se pasan adicionalmente a través del adaptador: una red poco profunda con una capa oculta de 1 cuello de botella y con salida de la misma dimensión que la entrada. La no linealidad se aplica al estado de cuello de botella y la entrada (conexión de omisión) se agrega a la salida. Resulta que el número total de parámetros entrenados es: 2md + m + d, donde d es la dimensión del estado oculto del modelo original, m es el tamaño de la capa del adaptador de cuello de botella. Resulta que para el modelo base BERT (12 capas, parámetros de 110M) y para el tamaño del adaptador bottlneck'a 128, obtenemos el 4,3% del número total de parámetros
Resultados
La comparación se realizó con el ajuste completo del modelo. Para todas las tareas, este enfoque mostró una pérdida menor en las métricas (en promedio menos de 1 punto), con el número de pesas entrenadas: 3% del total. No enumeraré las tareas en sí, hay muchas, hay una tableta en el artículo.
Ajuste fino
En este modelo, solo se ajusta la parte del adaptador (+ el clasificador de salida en sí). Para escalas de adaptadores, proponen hacer una inicialización de identidad cercana. Por lo tanto, un modelo no entrenado no cambiará los estados ocultos de la red de ninguna manera, y esto ya hará posible que en el proceso de capacitación del modelo decida qué estados adaptar para la tarea y cuáles dejar sin cambios.
La tasa de aprendizaje recomienda tomar más que con el ajuste fino BERT estándar. Personalmente, en mi tarea, 1e-04 lr funcionó bien. Además, (ya personalmente mi observación) durante el proceso de ajuste, el modelo casi siempre explota los gradientes, por lo que debe recordar hacer el recorte. Optimizador - Adam con calentamiento 10%
Código
Se adjunta el código en su artículo. Implementación en Tensorflow .
Para Torch, el autor de la revisión bifurcó los transformadores de pytorch y agregó una capa de Adaptador (al comienzo del archivo README.md hay un pequeño manual de inicio)
3. RoBERTa: un enfoque de preentrenamiento BERT robustamente optimizado
Autores del artículo: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (Universidad de Washington, Facebook AI, 2019)
→ Artículo original
Autor de la revisión: Artem Rodichev (en slack fuckai)
Elevó drásticamente la calidad de los modelos BERT, primer lugar en la tabla de clasificación de GLUE y SOTA en muchas tareas de PNL. Sugirieron varias formas de entrenar el modelo BERT lo mejor posible sin ningún cambio en la arquitectura del modelo en sí.
Diferencias clave con el BERT original:
- Se incrementó la construcción de trenes 10 veces, de 16 GB de texto sin formato a 160 GB
- Enmascaramiento dinámico para cada muestra
- Se eliminó el uso de la siguiente oración de predicción de pérdida
- Se incrementó el tamaño del mini lote de 256 muestras a 8k
- Se mejoró la codificación BPE al traducir la base de datos de Unicode a bytes.
El mejor modelo final fue entrenado en 1024 tarjetas Nvidia V100 (128 servidores DGX-1) durante 5 días.
La esencia del enfoque:
Datos. Además de los shells Wiki y BookCorpus (16GB en total), que enseñaron el BERT original, agregaron 3 shells más grandes, todos en inglés:
- SS-News 63 millones de noticias en 2.5 años con 76GB
- OpenWebText es el marco en el que se enseñó a OpenAI el modelo GPT2. Estos son artículos rastreados a los que se dieron enlaces en publicaciones en un reddit con al menos tres actualizaciones. 38 GB de datos
- Historias - 31GB CommonCrawl Story Case
Enmascaramiento dinámico. En el BERT original, el 15% de los tokens están enmascarados en cada muestra y estos tokens se predicen usando la parte sin enmascarar de la secuencia. Se genera una máscara para cada muestra una vez durante el preprocesamiento y no cambia. Al mismo tiempo, la misma muestra en el tren puede ocurrir varias veces, dependiendo del número de eras en el cuerpo. La idea del enmascaramiento dinámico es crear una nueva máscara para la secuencia cada vez, en lugar de usar una máscara fija en el preprocesamiento.
Objetivo de predicción de la siguiente oración. ¿Vamos a cortar este objektiv y ver si empeoró? Ha mejorado o también se ha mantenido, en las tareas SQuAD, MNLI, SST y RACE.
Aumentar el tamaño del mini lote. En muchos lugares, en particular en la traducción automática, se demostró que cuanto más grande es el mini lote, mejores son los resultados finales del tren. Mostraron que si aumenta el minibatch de 256 muestras, como en el BERT original, a 2k, y luego a 8k, entonces la perplejidad en la validación cae, y las métricas en MNLI y SST-2 crecen.
BPE El BPE de la implementación BERT original utiliza caracteres Unicode como base para las unidades de subpalabras. Esto lleva al hecho de que, en casos grandes y diversos, una parte significativa del diccionario estará ocupada por caracteres Unicode individuales. OpenAI en GPT2 sugirió usar no caracteres Unicode, sino bytes como base para las subpalabras. Si usamos un diccionario BPE de 50k, no tendremos tokens desconocidos. En comparación con el BERT original, el tamaño del modelo ha crecido en 15 millones de parámetros para el modelo base y en 20 millones para los grandes, es decir, 5-10% más.
Resultados:
BERT-large y XLNet-large se utilizan como modelos de comparación. RoBERTa en sí es el mismo en parámetros que BERT-large. Como resultado, ganaron el primer lugar en el punto de referencia GLUE. Utilizamos el ajuste de archivos de una sola tarea, a diferencia de muchos otros enfoques desde el punto de referencia GLUE que hacen el ajuste de archivos de tareas múltiples. En las chicas de GLUE, se comparan los resultados del modelo único, obtuvieron SOTA en las 9 tareas. En el conjunto de prueba, se compara el conjunto de modelos, SOTA para 4 de 9 tareas y la velocidad final de la cola. En dos versiones de SQuAD en la red de desarrollo SOTA, en el conjunto de prueba en el nivel XLNet. Además, a diferencia de XLNet, no quedan atrapados en paquetes de control de calidad adicionales antes de resolver SQuAD.

SOTA en la tarea RACE en la que se proporciona un texto, una pregunta sobre este texto y 4 opciones de respuesta donde debe elegir la correcta. Para resolver esta tarea, concatenan el texto, la pregunta y la respuesta, ejecutan BERT, obtienen una representación del token CLF, se aplican a una capa totalmente conectada y predicen si la respuesta es correcta. Esto se hace 4 veces, para cada una de las opciones de respuesta.
Publicamos el código y el pre-entrenamiento del modelo RoBERTa en nabo fairseq . Puedes usarlo, todo se ve ordenado y simple.
4. EfficientNet: repensando la escala del modelo para redes neuronales convolucionales
Autores: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Artículo original
Autor de la revisión: Alexander Denisenko (en flojo Alexander Denisenko)

Estudian la escala (escala) de los modelos y el equilibrio entre ellos la profundidad y el ancho (número de canales) de la red, así como la resolución de las imágenes en la cuadrícula. Ofrecen un nuevo método de escala que escala uniformemente la profundidad / ancho / resolución. Muestre su efectividad en MobileNet y ResNet.
También usan Neural Architecture Search para crear una nueva malla y escalarla, obteniendo así una clase de nuevos modelos: EfficientNets. Son mejores y mucho más económicos que las cuadrículas anteriores. En ImageNet, EfficientNet-B7 logra una precisión de 84.4% top-1 y 97.1% top-5 de vanguardia, siendo 8.4 veces menos y 6.1 veces más rápido en inferencia que el mejor ConvNet actual en su clase. Se transfiere bien a otros conjuntos de datos: obtuvieron SOTA en 5 de los 8 conjuntos de datos más populares.
Escala de modelo compuesto
El escalado es cuando las operaciones realizadas dentro de la cuadrícula son fijas y solo cambian la profundidad (número de repeticiones de los mismos módulos) d, el ancho (número de canales en convolución) w y la resolución r. En el localizador, la escala se formula como un problema de optimización: queremos la máxima precisión (Neto (d, w, r)) a pesar de que no nos arrastramos fuera de los límites en la memoria y en FLOPS.
Realizamos experimentos y nos aseguramos de que realmente ayude también a escalar en profundidad y resolución al escalar en ancho. Con los mismos FLOPS, logramos un resultado significativamente mejor en ImageNet (vea la imagen de arriba). En general, esto es razonable, porque parece que con un aumento en la resolución de la imagen de la red, se necesitan más capas en profundidad para aumentar el campo receptivo y más canales para capturar todos los patrones de la imagen con una resolución más alta.
La esencia de la escala compuesta: tomamos el coeficiente compuesto phi, que escala uniformemente d, w y r con este coeficiente: donde - constantes obtenidas de una vista de cuadrícula pequeña en la cuadrícula de origen. - coeficiente que caracteriza la cantidad de recursos informáticos disponibles.
Red eficiente
Para crear la cuadrícula, utilizamos la búsqueda de arquitectura neuronal de objetivos múltiples, precisión optimizada y FLOPS con el parámetro responsable de la compensación entre ellos. Tal búsqueda dio EfficientNet-B0. En resumen: Conv seguido de varios MBConv, al final de Conv1x1, Pool, FC.
Luego realice el escalado en dos pasos:
- Para comenzar, arreglamos , hacer búsqueda de cuadrícula para buscar .
- Escale la cuadrícula usando las fórmulas para d, w y r. Tengo EffiientNet-B1. Del mismo modo, aumentando , obtenga EfficientNet-B2, ... B7.
Escalado para diferentes ResNet y MobileNet, en todas partes recibió mejoras significativas en ImageNet, el escalado compuesto dio un aumento significativo en comparación con el escalado en una sola dimensión. También realizamos experimentos con EfficientNet en ocho conjuntos de datos más populares, en todas partes obtuvimos SOTA o un resultado cercano con un número significativamente menor de parámetros.
Código
5. Cómo pasa el cerebro de la percepción consciente a la subliminal
Autores del artículo: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (EE. UU., Argentina, España, 2019)
→ Artículo original
Autor de la revisión: Svyatoslav Skoblov (en slack error_derivative)
Este artículo es una continuación y un replanteamiento del trabajo de Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB y Rivie`re, D. Mecanismos cerebrales de enmascaramiento de palabras y cebado de repetición inconsciente , en que los autores trataron de considerar los modos de función cerebral consciente e inconsciente.
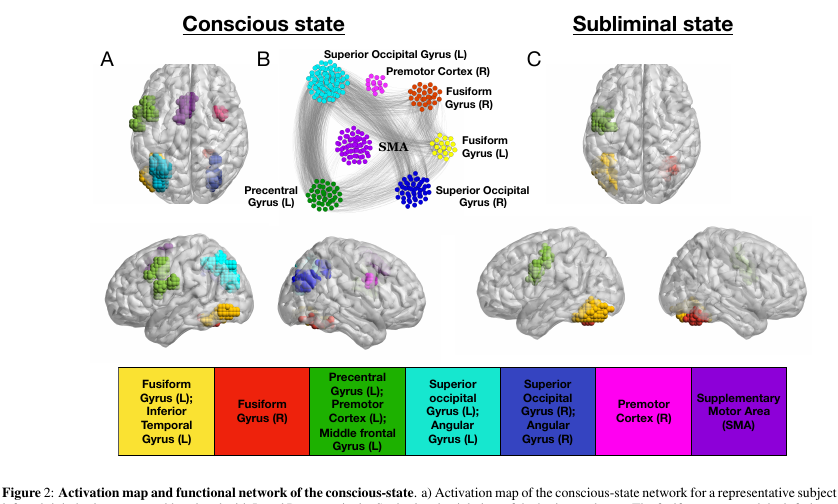
Experimento:
A los voluntarios se les muestran imágenes (palabras de 4 letras, o una pantalla en blanco, o garabatos). Cada uno de ellos se muestra durante 30 ms, en general, toda la acción dura 5 minutos.
- En el modo "consciente" del experimento, una pantalla en blanco se alterna con palabras, lo que permite a una persona percibir conscientemente el texto.
- En el modo "inconsciente", las palabras se alternan con garabatos, lo que interfiere bastante efectivamente con la percepción del texto en un nivel consciente.
Datos:
Durante esta presentación, los cerebros de nuestros primates fueron escaneados usando fMRI. En total, los investigadores tuvieron 15 voluntarios, cada uno repitió el experimento 5 veces, un total de 75 flujos de fMRI. Vale la pena señalar que el escaneo de voxel resultó ser bastante grande (muy simplificado: voxel es un cubo 3D que contiene una cantidad bastante grande de celdas) - 4x4x4mm.
Magia:
Llamemos al nodo voxel activo de nuestra secuencia. Dado que el cerebro es un paño modular, introducimos dos tipos de conexiones en él: externo e interno (correspondiente a la disposición espacial de los nodos). Las conexiones se ensamblan de una manera interesante: construimos una matriz de correlación cruzada entre nodos y conectamos los nodos con una conexión si la correlación es mayor que algún parámetro adaptativo lambda. Este parámetro afecta la descarga de nuestra red.
El ajuste de parámetros se lleva a cabo utilizando el procedimiento de "filtrado". Si balanceamos nuestro lambda un poco, las transiciones bruscas entre las dimensiones finales de la red se vuelven notorias (es decir, un cambio de parámetro suficientemente pequeño corresponde a un gran incremento de tamaño).
Entonces: las conexiones internas se activan con el valor lambda-1, que corresponde al valor lambda justo antes de una transición brusca. Externo: valor lambda-2 correspondiente al valor lambda inmediatamente después de una transición brusca.
Magia 2:
filtrado de k-core. El concepto k-core describe la conectividad de red y está formulado de manera bastante simple: la subred máxima, cuyos nodos tienen al menos k vecinos. Dicha subred se puede obtener mediante la eliminación iterativa de nodos con menos de k vecinos. Como los nodos restantes perderán vecinos, el proceso continúa hasta que no haya nada que eliminar. Lo que queda es la red k-core.
Resultados:
Aplicando esta artillería a nuestros cerebros, puede ver una serie de características muy interesantes.
- El número de nodos en k-core con k pequeño / muy grande es extremadamente grande. Pero para el medio k, por el contrario, no es suficiente. En la imagen, parece una forma de U, es decir, una configuración de red de este tipo proporciona la mayor estabilidad del sistema (resistencia a los errores locales y globales).
- y los nodos más importantes que pertenecen a k-core con k pequeña se pueden ver en casi cualquier estado de la red. Pero un k-core con k muy grande es característico solo para aquellas partes del cerebro que están activas en el estado inconsciente de giro fusiforme y giro precentral izquierdo . Las mismas partes de la corteza son más activas y en un estado consciente.
Para verificar el resultado, los autores crearon un millón de redes aleatorias basadas en redes reales, haciendo cableado aleatorio, manteniendo el grado original de los nodos (el mismo que el grado del vértice en el gráfico). Las redes reales diferían de las aleatorias por valores mucho mayores de k máximo. Al mismo tiempo, la forma de U del número de nodos en los grupos permaneció notable en redes aleatorias, lo que llevó a los autores a la idea de que es el grado de los nodos el responsable de este fenómeno.
Conclusiones:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. Es decir query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
Los resultados de la prueba ReID para OSNet (aproximadamente 2 millones de parámetros) indican la ventaja de esta arquitectura sobre otros modelos ligeros (Mercado: R1 93.6%, mAP 81.0% para OSNet y R1 87.0%, mAP 69.5% para MobileNetV2) y la ausencia de una diferencia significativa en la precisión con modelos pesados de ResNet y DenseNet (Mercado: R1 94.8%, mAP 84.9% para OSNet y R1 94.8%, mAP 86.0% para ResNet).
Otro desafío es la adaptación del dominio : los modelos entrenados en un conjunto de datos tienen mala calidad en otro. OSNet también muestra buenos resultados en este segmento sin el uso de "adaptación de dominio no supervisada" (utilizando datos de prueba en una forma no asignada para igualar la distribución de datos).
La arquitectura también se ha probado en ImageNet, donde logró una precisión similar con MobileNetV2 con menos parámetros, pero más operaciones.
9. La reparameterización neural mejora la optimización estructural.
Autores: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Artículo original
Autor de la revisión: Alexey (en Arech slack)
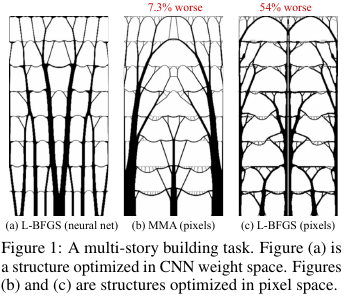
En la construcción y otras tecnologías, existen tareas de optimización de la estructura / topología de alguna solución. Hablando en términos generales, esta es una respuesta de computadora a una pregunta como, por ejemplo, cómo diseñar un puente / edificio / ala de avión / pala de turbina / blablabla para que se cumplan ciertas restricciones y la estructura sea lo suficientemente fuerte. Hay un conjunto de métodos de solución "estándar": funciona, pero no todo es fácil allí.
¿Qué inventaron estos tipos de Google? Dijeron: vamos a generar una solución a través de una red neuronal (la parte de muestreo superior de UNet), y luego utilizando un modelo físico diferenciable, que calculará el comportamiento de una solución bajo la influencia de todas las fuerzas y la gravedad, calcularemos la función objetivo - fuerza (más precisamente, lo inverso de ella - cumplimiento) ) diseños. Luego, dado que todo es automáticamente diferenciable, obtenemos el gradiente de la función objetivo, que se empuja a través de toda la estructura hacia los pesos y la entrada de la red neuronal. Cambiamos los pesos y la entrada y continuamos el ciclo hasta la convergencia hacia una solución estable.
Los resultados resultaron en problemas pequeños (en términos del tamaño del espacio de posibles soluciones) comparables a los métodos tradicionales para optimizar las topologías, y para problemas grandes, son notablemente mejores que los tradicionales (sobrepeso en 99 frente a 66 de 116 problemas). Además, las soluciones resultantes son a menudo significativamente más tecnológicas y óptimas que las decisiones de las líneas de base.
Es decir de hecho, utilizaron el NS como una forma complicada de parametrizar el modelo físico de la estructura, que implícitamente (debido a la arquitectura del NS) puede imponer algunas restricciones útiles sobre los valores de los parámetros (controlados eliminando el NS del método y la optimización directa de los valores de píxeles).
Código fuente
Una descripción más detallada de este artículo sobre habr.