Carro volador, Afu ChanTrabajo en
Mail.ru Cloud Solutons como arquitecto y desarrollador, incluida mi nube. Se sabe que una infraestructura de nube distribuida necesita un almacenamiento de bloques productivo, del que depende la operación de los servicios y soluciones de PaaS creados con ellos.
Inicialmente, cuando implementamos dicha infraestructura, usamos solo Ceph, pero gradualmente el almacenamiento en bloque evolucionó. Queríamos que
nuestras bases de datos , almacenamiento de archivos y varios servicios funcionaran con el máximo rendimiento, por lo que agregamos almacenes localizados y configuramos la supervisión avanzada de Ceph.
Te diré cómo fue, tal vez esta historia, los problemas que encontramos y nuestras soluciones serán útiles para aquellos que también usan Ceph. Por cierto,
aquí hay una versión en video de este informe.
De los procesos de DevOps a su propia nube
Las prácticas de DevOps tienen como objetivo implementar el producto lo más rápido posible:
- Automatización de procesos: todo el ciclo de vida: montaje, prueba, entrega a prueba y productividad. Automatice los procesos gradualmente, comenzando con pequeños pasos.
- La infraestructura como código es un modelo cuando el proceso de configuración de la infraestructura es similar al proceso de programación del software. Primero prueban el producto, el producto tiene ciertos requisitos para la infraestructura y la infraestructura necesita ser probada. En esta etapa, los deseos de que ella aparezca, quiero "ajustar" la infraestructura, primero en el entorno de prueba, luego en el supermercado. En la primera etapa, esto puede hacerse manualmente, pero luego pasan a la automatización, al modelo de "infraestructura como código".
- Virtualización y contenedores: aparecen en la empresa cuando está claro que necesita poner procesos en una vía industrial, implementar nuevas funciones más rápido con una mínima intervención manual.
 La arquitectura de todos los entornos virtuales es similar: máquinas invitadas con contenedores, aplicaciones, redes públicas y privadas, almacenamiento.
La arquitectura de todos los entornos virtuales es similar: máquinas invitadas con contenedores, aplicaciones, redes públicas y privadas, almacenamiento.Gradualmente, se implementan más y más servicios en la infraestructura virtual integrada en los procesos de DevOps, y el entorno virtual se está convirtiendo no solo en una prueba (utilizada para el desarrollo y las pruebas), sino también productiva.
Como regla general, en las etapas iniciales son ignorados por las herramientas de automatización básicas más simples. Pero a medida que se atraen nuevas herramientas, tarde o temprano es necesario implementar una plataforma en la nube completa para utilizar las herramientas más avanzadas como Terraform.
En esta etapa, la infraestructura virtual de "hipervisores, redes y almacenamiento" se convierte en una infraestructura de nube completa con herramientas y componentes desarrollados para orquestar procesos. Luego aparece su propia nube, en la que tienen lugar los procesos de prueba y entrega automática de actualizaciones a los servicios existentes y la implementación de nuevos servicios.
El segundo camino hacia su propia nube es la necesidad de no depender de recursos externos y proveedores de servicios externos, es decir, proporcionar cierta independencia técnica para sus propios servicios.
 La primera nube parece casi una infraestructura virtual: un hipervisor (uno o varios), máquinas virtuales con contenedores, almacenamiento compartido: si construye la nube no en soluciones propietarias, generalmente es Ceph o DRBD.
La primera nube parece casi una infraestructura virtual: un hipervisor (uno o varios), máquinas virtuales con contenedores, almacenamiento compartido: si construye la nube no en soluciones propietarias, generalmente es Ceph o DRBD.Resiliencia y rendimiento de la nube privada
La nube está creciendo, el negocio depende cada vez más de ella, la empresa comienza a exigir mayor confiabilidad.
Aquí, la distribución se agrega a la nube privada, aparece la infraestructura de nube distribuida: puntos adicionales donde se encuentra el equipo. La nube gestiona dos, tres o más instalaciones creadas para proporcionar una solución tolerante a fallas.
Al mismo tiempo, se necesitan datos de todos los sitios, y existe un problema: dentro de un sitio no hay grandes retrasos en la transferencia de datos, pero entre los sitios los datos se transmiten más lentamente.
 Sitios de instalación y almacenamiento común. Los rectángulos rojos son cuellos de botella en el nivel de la red.
Sitios de instalación y almacenamiento común. Los rectángulos rojos son cuellos de botella en el nivel de la red.La parte externa de la infraestructura desde el punto de vista de la red de administración o la red pública no está tan ocupada, pero en la red interna los volúmenes de datos transferidos son mucho mayores. Y en los sistemas distribuidos, comienzan los problemas, expresados en un largo tiempo de servicio. Si el cliente llega a un grupo de nodos de almacenamiento, los datos deben replicarse instantáneamente en el segundo grupo para que los cambios no se pierdan.
Para algunos procesos, la latencia de replicación de datos es aceptable, pero en casos como el procesamiento de transacciones, las transacciones no se pueden perder. Si se utiliza la replicación asincrónica, se produce un retraso de tiempo que puede conducir a la pérdida de una parte de los datos si falla una de las "colas" del sistema de almacenamiento (sistema de almacenamiento de datos). Si se usa la replicación sincrónica, el tiempo de servicio aumenta.
También es bastante natural que cuando aumenta el tiempo de procesamiento (latencia) del almacenamiento, las bases de datos comienzan a disminuir y hay efectos negativos que deben combatirse.
En nuestra nube, buscamos soluciones equilibradas para mantener la fiabilidad y el rendimiento. La técnica más simple es localizar los datos, y luego agregamos grupos de Ceph localizados adicionales.
 El color verde indica grupos de Ceph localizados adicionales.
El color verde indica grupos de Ceph localizados adicionales.La ventaja de una arquitectura tan compleja es que aquellos que necesitan una entrada / salida rápida de datos pueden usar almacenamientos localizados. Los datos para los cuales la disponibilidad total es crítica dentro de dos sitios se encuentran en un clúster distribuido. Funciona más lento, pero los datos que contiene se replican en ambos sitios. Si su rendimiento no es suficiente, puede usar clústeres Ceph localizados.
La mayoría de las nubes públicas y privadas llegan a tener aproximadamente el mismo patrón de trabajo, cuando, según los requisitos, la carga se despliega en diferentes tipos de almacenamientos (diferentes tipos de discos).
Diagnóstico ceph: cómo construir monitoreo
Cuando implementamos y lanzamos la infraestructura, era hora de asegurar su funcionamiento, para minimizar el tiempo y la cantidad de fallas. Por lo tanto, el siguiente paso en el desarrollo de la infraestructura fue la construcción de diagnósticos y monitoreo.
Considere la tarea de monitoreo en todo momento: tenemos una pila de aplicaciones en un entorno de nube virtual: una aplicación, un sistema operativo invitado, un dispositivo de bloque, los controladores de este dispositivo de bloque en un hipervisor, una red de almacenamiento y el sistema de almacenamiento real (sistema de almacenamiento). Y todo esto aún no ha sido cubierto por el monitoreo.
 Elementos no cubiertos por el monitoreo.
Elementos no cubiertos por el monitoreo.El monitoreo se implementa en varias etapas, comenzamos con discos. Obtenemos el número de operaciones de lectura / escritura, con cierta precisión, el tiempo de servicio (megabytes por segundo), la profundidad de la cola, otras características, y también recopilamos SMART sobre el estado de los discos.
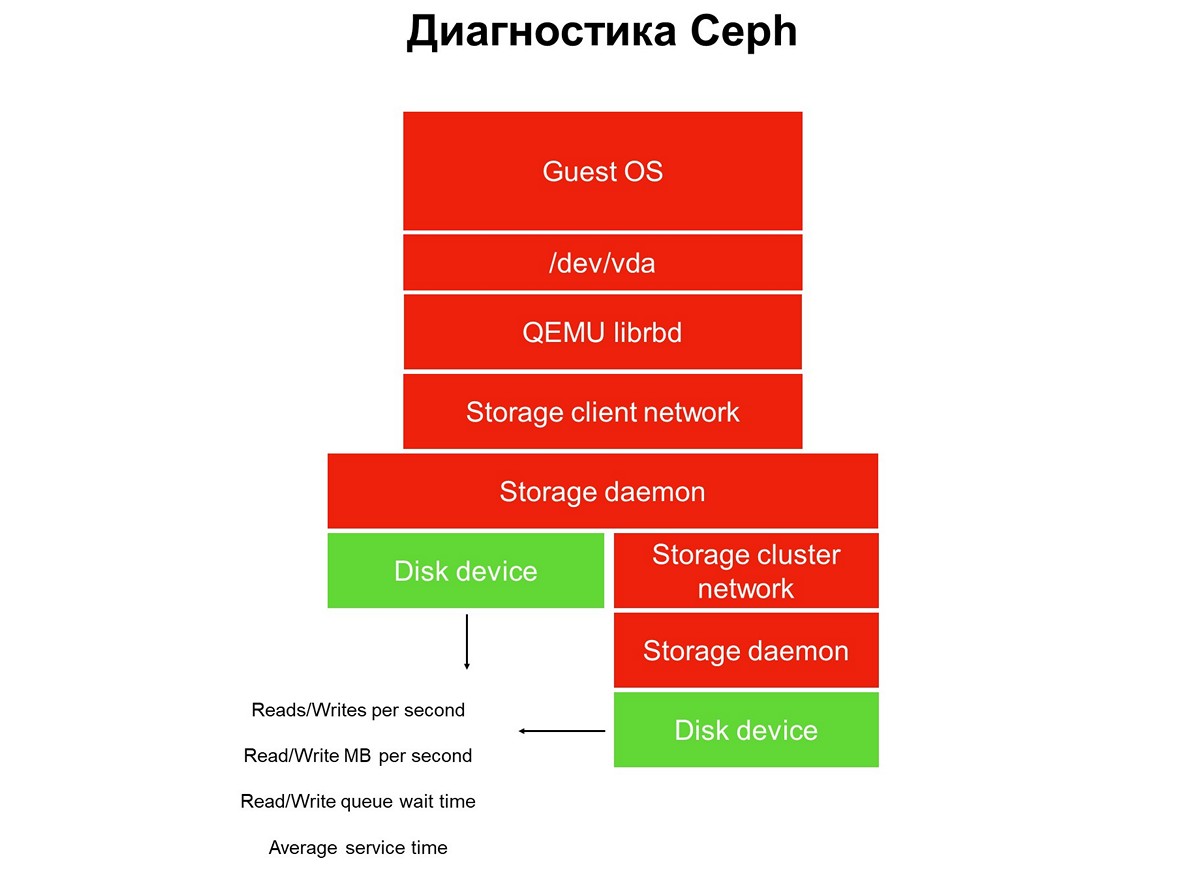 La primera etapa: cubrimos los discos de monitoreo.
La primera etapa: cubrimos los discos de monitoreo.El monitoreo de disco no es suficiente para obtener una imagen completa de lo que está sucediendo en el sistema. Por lo tanto, pasamos a monitorear un elemento crítico de la infraestructura: la red del sistema de almacenamiento. En realidad, hay dos: el clúster interno y el cliente, que conecta clústeres de almacenamiento con hipervisores. Aquí obtenemos las velocidades de transferencia de paquetes de datos (megabytes por segundo, paquetes por segundo), el tamaño de las colas de la red, las memorias intermedias y posiblemente las rutas de datos.
 Segunda etapa: monitoreo de la red.
Segunda etapa: monitoreo de la red.A menudo se detienen en esto, pero esto no se puede hacer, porque la mayor parte de la infraestructura aún no se ha cerrado por monitoreo.
Todo el almacenamiento distribuido utilizado en nubes públicas y privadas es SDS, almacenamiento definido por software. Se pueden implementar en las soluciones de un proveedor en particular, soluciones de código abierto, puede hacer algo usted mismo utilizando una pila de tecnologías familiares. Pero siempre es SDS, y el trabajo de estas partes de software debe ser monitoreado.
 Tercer paso: monitorear el demonio de almacenamiento.
Tercer paso: monitorear el demonio de almacenamiento.La mayoría de los operadores de Ceph utilizan datos recopilados de los demonios de control y monitoreo de Ceph (monitor y gerente, también conocido como mgr). Inicialmente, seguimos el mismo camino, pero rápidamente nos dimos cuenta de que esta información no era suficiente: las advertencias sobre solicitudes pendientes aparecen tarde: la solicitud se suspendió durante 30 segundos, solo entonces la vimos. Mientras se trate de monitoreo, mientras el monitoreo activa la alarma, pasarán al menos tres minutos. En el mejor de los casos, esto significa que parte del almacenamiento y las aplicaciones estarán inactivas durante tres minutos.
Naturalmente, decidimos expandir el monitoreo y pasamos al elemento principal de Ceph: el demonio OSD. Al monitorear el daemon de Object Storage, obtenemos el tiempo aproximado de operación como lo ve el OSD, así como estadísticas sobre solicitudes bloqueadas: quién, cuándo, en qué PG, durante cuánto tiempo.
¿Por qué solo Ceph no es suficiente y qué hacer al respecto?
Ceph por sí solo no es suficiente por varias razones. Por ejemplo, tenemos un cliente con un perfil de base de datos. Implementó todas las bases de datos en el clúster todo flash, la latencia de las operaciones que se emitieron allí le convenía, sin embargo, hubo quejas de tiempo de inactividad.
El sistema de monitoreo no le permite ver lo que sucede dentro de los clientes del entorno virtual. Como resultado, para identificar el problema, utilizamos el análisis avanzado, que se solicitó utilizando la utilidad blktrace de su máquina virtual.
 El resultado de un análisis extendido.
El resultado de un análisis extendido.Los resultados del análisis contienen operaciones marcadas con las banderas W y WS. El indicador W es un registro, el indicador WS es un registro síncrono, esperando que el dispositivo complete la operación. Cuando trabajamos con bases de datos, casi todas las bases de datos SQL tienen un cuello de botella: WAL (registro de escritura anticipada).
La base de datos siempre escribe primero los datos en el registro, recibe la confirmación del disco con buffers de descarga y luego escribe los datos en la base de datos. Si no ha recibido la confirmación de un reinicio del búfer, cree que un reinicio de energía puede borrar una transacción confirmada por el cliente. Esto es inaceptable para la base de datos, por lo que muestra "escribir SYNC / FLUSH", luego escribe los datos. Cuando los registros están llenos, se produce su cambio y todo lo que ingresó en la caché de la página también se muestra a la fuerza.
Agregado: no hay reinicio en la imagen en sí, es decir, operaciones con el indicador de pre-vaciado. Se ven como FWS - pre-flush + write + sync o FWSF - pre-flush + write + sync + FUACuando un cliente tiene muchas transacciones pequeñas, prácticamente todas sus E / S se convierten en una cadena secuencial: escritura - descarga - escritura - descarga. Como no puede hacer algo con la base de datos, comenzamos a trabajar con el sistema de almacenamiento. En este momento, entendemos que las capacidades de Ceph no son suficientes.
Para nosotros, en esta etapa, la mejor solución era agregar repositorios locales pequeños y rápidos que no se implementaron utilizando herramientas Ceph (básicamente agotamos sus capacidades). Y convertimos el almacenamiento en la nube en algo más que Ceph. En nuestro caso, hemos agregado muchas historias locales (locales en términos del centro de datos, no del hipervisor).
 Repositorios localizados adicionales Objetivo A y B.
Repositorios localizados adicionales Objetivo A y B.El tiempo de servicio de dicho almacenamiento local es de aproximadamente 0,3 ms por flujo. Si se encuentra en otro centro de datos, funciona más lentamente, con un rendimiento de aproximadamente 0,7 ms. Este es un aumento significativo en comparación con Ceph, que produce 1,2 ms, y se distribuye en centros de datos: 2 ms. El rendimiento de estas pequeñas fábricas, de las cuales tenemos más de una docena, es de aproximadamente 100 mil por módulo, 100 mil IOPS por registro.
Después de tal cambio en la infraestructura, nuestra nube exprime menos de un millón de IOPS para escribir, o alrededor de dos a tres millones de IOPS para leer en total para todos los clientes:

Es importante tener en cuenta que este tipo de almacenamiento no es el método principal de expansión, colocamos la apuesta principal en Ceph, y la presencia de almacenamiento rápido es importante solo para los servicios que requieren tiempo de respuesta del disco.
Nuevas iteraciones: mejoras de código e infraestructura
Todas nuestras historias son recursos compartidos. Dicha infraestructura requiere que
implementemos una política de nivel de servicio : debemos proporcionar un cierto nivel de servicio y no permitir que un cliente interfiera con otro por accidente o a propósito, deshabilitando el almacenamiento.
Para hacer esto, tuvimos que hacer la finalización y el despliegue no trivial: entrega iterativa a los productivos.
Este despliegue fue diferente de las prácticas habituales de DevOps, cuando todos los procesos: ensamblaje, prueba, despliegue de código, reinicio del servicio, si es necesario, comienzan con un clic de un botón, y luego todo funciona. Si despliega las prácticas de DevOps en la infraestructura, permanecerá vigente hasta el primer error.
Es por eso que la "automatización completa" no se arraigó particularmente en el equipo de infraestructura. Por supuesto, existe un cierto enfoque para la automatización de pruebas y entregas, pero siempre está controlado y la entrega es iniciada por los ingenieros de SRE del equipo de la nube.
Implementamos cambios en varios servicios: en el backend de Cinder, en la interfaz de Cinder (cliente de Cinder) y en el servicio Nova. Los cambios se aplicaron en varias iteraciones, una iteración a la vez. Después de la tercera iteración, los cambios correspondientes se aplicaron a las máquinas invitadas de los clientes: alguien migró, alguien reinició la VM (reinicio completo) o planeó la migración para servir a los hipervisores.
El siguiente problema que surgió son los
saltos en la velocidad de escritura . Cuando trabajamos con almacenamiento conectado a la red, el hipervisor predeterminado considera que la red es lenta y, por lo tanto, almacena en caché todos los datos. Escribe rápidamente, hasta varias decenas de megabytes, y luego comienza a vaciar el caché. Hubo muchos momentos desagradables debido a tales saltos.
Descubrimos que si enciende el caché, el rendimiento de la SSD disminuye en un 15%, y si apaga el caché, el rendimiento del HDD disminuye en un 35%. Se requirió otro desarrollo, implementado la administración de caché administrada, cuando el almacenamiento en caché se asigna explícitamente para cada tipo de disco. Esto nos permitió conducir SSD sin caché y HDD: con un caché, como resultado, dejamos de perder rendimiento.
La práctica de entregar desarrollo a un productivo es similar: iteraciones. Implementamos el código, reiniciamos el demonio y luego, según sea necesario, reiniciamos o migramos máquinas virtuales invitadas, que deberían estar sujetas a cambios. La máquina virtual del cliente migró del HDD, su caché se activó: todo funciona o, por el contrario, el cliente migró con SSD, su caché se activó: todo funciona.
El tercer problema es el
funcionamiento incorrecto de las máquinas virtuales implementadas desde imágenes GOLD en el HDD .
Hay muchos clientes de este tipo, y la peculiaridad de la situación es que el trabajo de la VM se ajustó por sí mismo: se garantizó que el problema ocurriera durante la implementación, pero se resolvió mientras el cliente contactaba con el soporte técnico. Al principio, les pedimos a los clientes que esperaran media hora hasta que la VM se estabilizara, pero luego comenzamos a trabajar en la calidad del servicio.
En el proceso de investigación, nos dimos cuenta de que las capacidades de nuestra infraestructura de monitoreo aún no son suficientes.
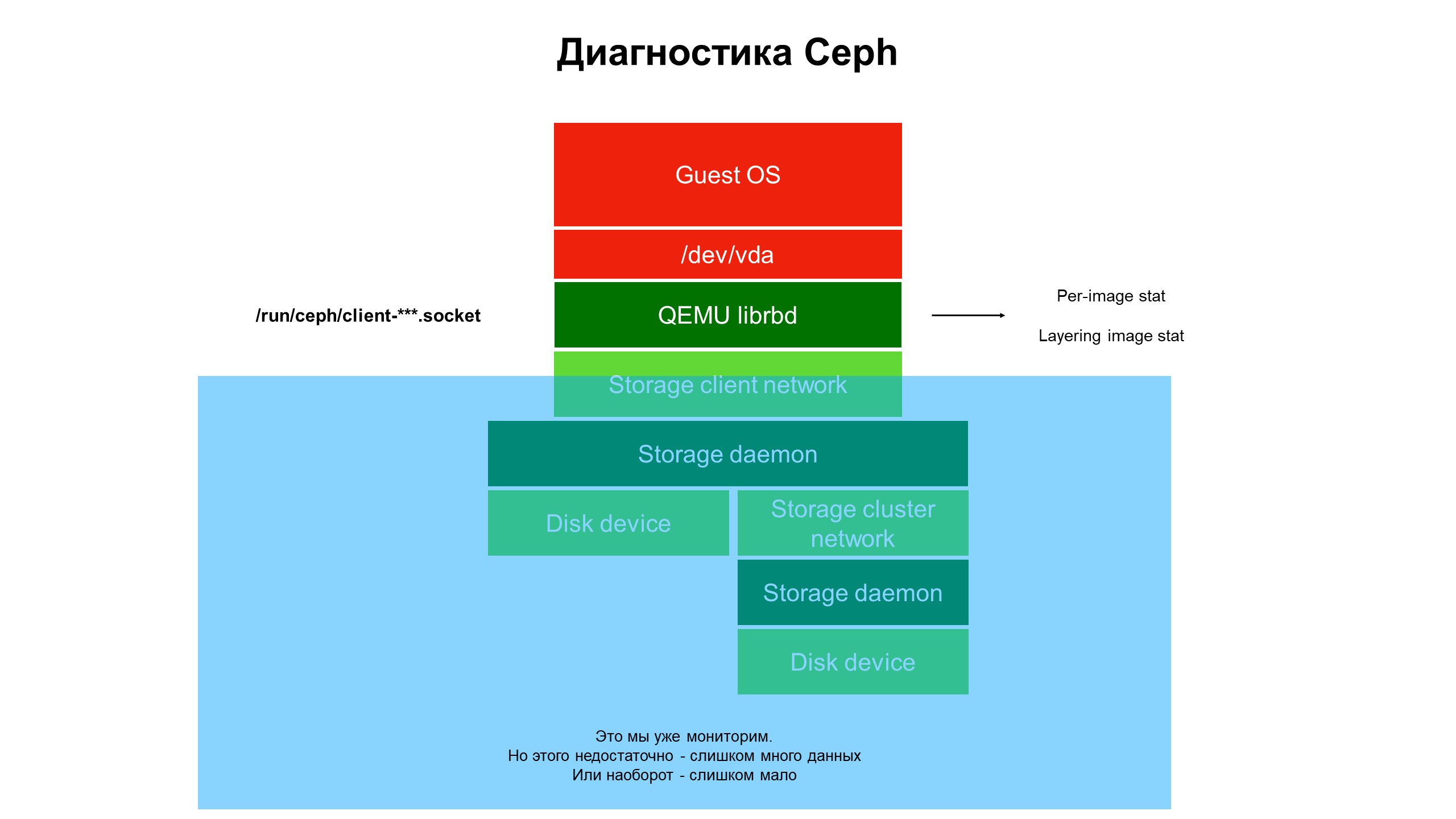 El monitoreo cerró la parte azul, y el problema estaba en la parte superior de la infraestructura, no cubierto por el monitoreo.
El monitoreo cerró la parte azul, y el problema estaba en la parte superior de la infraestructura, no cubierto por el monitoreo.Comenzamos a lidiar con lo que está sucediendo en la parte de la infraestructura que no estaba cubierta por el monitoreo. Para hacer esto, utilizamos el diagnóstico avanzado de Ceph (o más bien, una de las variedades del cliente Ceph - librbd). Utilizando herramientas de automatización, realizamos cambios en la configuración del cliente Ceph para acceder a las estructuras de datos internas a través del socket del dominio Unix, y comenzamos a tomar estadísticas de los clientes Ceph en el hipervisor.
Que vimos No vimos estadísticas en el clúster / OSD / clúster Ceph, sino estadísticas en cada disco de la máquina virtual del cliente cuyos discos estaban en Ceph, es decir, estadísticas asociadas con el dispositivo.
 Resultados avanzados de estadísticas de monitoreo.
Resultados avanzados de estadísticas de monitoreo.Fueron las estadísticas ampliadas las que dejaron en claro que el problema solo ocurre en discos clonados de otros discos.
Luego, observamos las estadísticas sobre las operaciones, en particular las operaciones de lectura y escritura. Resultó que la carga en las imágenes de nivel superior es relativamente pequeña, y en las iniciales, de las cuales proviene el clon, es grande pero sin equilibrio: una gran cantidad de lectura sin ninguna grabación.
El problema está localizado, ahora se necesita una solución: ¿código o infraestructura?
No se puede hacer nada con el código Ceph, es "difícil". Además, la seguridad de los datos del cliente depende de ello. Pero hay un problema, debe resolverse y cambiamos la arquitectura del repositorio. El clúster HDD se convirtió en un clúster híbrido: se agregó una cierta cantidad de SSD al HDD, luego se cambiaron las prioridades de los demonios OSD para que el SSD siempre tuviera prioridad y se convirtiera en el OSD primario dentro del grupo de colocación (PG).
Ahora, cuando el cliente despliega la máquina virtual desde el disco clonado, sus operaciones de lectura van al SSD. Como resultado, la recuperación del disco se hizo rápida, y solo los datos del cliente que no sean la imagen original se escriben en el HDD. Recibimos un triple aumento en la productividad casi gratis (en relación con el costo inicial de la infraestructura).
Por qué es importante el monitoreo de la infraestructura
- La infraestructura de monitoreo debe incluirse al máximo en toda la pila, comenzando con la máquina virtual y terminando con el disco. Después de todo, mientras un cliente que utiliza una nube pública o privada llega a su infraestructura y proporciona la información necesaria, el problema cambiará o se trasladará a otro lugar.
- Monitorear todo el hipervisor, la máquina virtual o el contenedor "en su totalidad" no produce casi nada. Intentamos entender del tráfico de red lo que está sucediendo con Ceph: es inútil, los datos vuelan a alta velocidad (de 500 megabytes por segundo), es extremadamente difícil seleccionar los necesarios. Se necesitará un volumen monstruoso de discos para almacenar tales estadísticas y mucho tiempo para analizarlas.
- , - . : , , — , .
- — . , . — , . , . — , , .
- MCS Cloud Solutions — , . .