El problema de la búsqueda automática de texto en imágenes existe desde hace mucho tiempo, al menos desde principios de los años noventa del siglo pasado. Los veteranos podrían recordarlos por la distribución generalizada de ABBYY FineReader, que puede traducir los escaneos de documentos a sus versiones editables.
Los escáneres conectados a computadoras personales funcionan muy bien en las empresas, pero el progreso no se detiene y los dispositivos móviles se han apoderado del mundo. La gama de tareas para trabajar con texto también ha cambiado. Ahora es necesario buscar el texto, no en hojas A4 perfectamente rectas con texto negro sobre fondo blanco, sino en varias tarjetas de presentación, menús coloridos, letreros de tiendas y mucho más sobre lo que una persona puede encontrar en la jungla de una ciudad moderna.
 Un verdadero ejemplo del trabajo de nuestra red neuronal. Se puede hacer clic en la imagen.
Un verdadero ejemplo del trabajo de nuestra red neuronal. Se puede hacer clic en la imagen.Requisitos básicos y limitaciones
Con tal variedad de condiciones para presentar texto, los algoritmos escritos a mano ya no pueden hacer frente. Aquí, las redes neuronales con su capacidad de generalizar vienen al rescate. En esta publicación, hablaremos sobre nuestro enfoque para crear una arquitectura de red neuronal que detecte texto en imágenes complejas con buena calidad y alta velocidad.
Los dispositivos móviles imponen restricciones adicionales en la elección del enfoque:
- Los usuarios no siempre tienen la oportunidad de usar una red móvil para comunicarse con el servidor debido al costoso tráfico móvil o problemas de privacidad. Entonces, soluciones como Google Lens no ayudarán aquí.
- Dado que nos centramos en el procesamiento local de datos, sería bueno para nuestra solución:
- Ocupaba poca memoria;
- Funcionó rápidamente utilizando las capacidades técnicas del teléfono inteligente.
- El texto se puede girar y estar en un fondo aleatorio.
- Las palabras pueden ser muy largas. En las redes neuronales convolucionales, el alcance del núcleo de convolución generalmente no cubre la palabra alargada en su conjunto, por lo que tomará algún truco para sortear esta restricción.

- Los tamaños de texto en una foto pueden ser diferentes:

Solución
¡La solución más simple para el problema de búsqueda de texto que viene a la mente es tomar la mejor red de los
concursos ICDAR (Conferencia Internacional sobre Análisis y Reconocimiento de Documentos) especializados en esta tarea y negocio! Desafortunadamente, tales redes logran calidad debido a su volumen y complejidad computacional, y solo son adecuadas como una solución en la nube, que no cumple con los párrafos 1 y 2 de nuestros requisitos. Pero, ¿qué sucede si tomamos una red grande que funciona bien en los escenarios que necesitamos cubrir e intentamos reducirla? Este enfoque ya es más interesante.
Baoguang Shi et al. En su red neuronal
SegLink [1] propuso lo siguiente:
- Para encontrar no palabras completas a la vez (áreas verdes en la imagen a ), sino sus partes, llamadas segmentos, con la predicción de su rotación, inclinación y desplazamiento. Tomemos prestada esta idea.
- Debe buscar segmentos de palabras en varias escalas a la vez para cumplir con el requisito 5. Los segmentos se muestran con rectángulos verdes en la imagen b .
- Para evitar que una persona invente cómo combinar estos segmentos, simplemente hacemos que la red neuronal prediga conexiones (enlaces) entre segmentos relacionados con la misma palabra
a. dentro de la misma escala (líneas rojas en la imagen c )
b. y entre escalas (líneas rojas en la imagen d ), resolviendo el problema de la cláusula 4 de los requisitos.
Los cuadrados azules en la imagen a continuación muestran las áreas de visibilidad de los píxeles de las capas de salida de la red neuronal de diferentes escalas, que "ven" al menos parte de la palabra.
 Ejemplos de segmentos y enlaces
Ejemplos de segmentos y enlacesSegLink utiliza la conocida arquitectura VGG-16 como base. La predicción de segmentos y enlaces se realiza en 6 escalas. Como primer experimento, comenzamos con la implementación de la arquitectura original. Resultó que la red contiene 23 millones de parámetros (pesos) que deben almacenarse en un archivo de 88 megabytes de tamaño. Si crea una aplicación basada en VGG, será uno de los primeros candidatos para la eliminación si no hay suficiente espacio, y la búsqueda de texto en sí funcionará muy lentamente, por lo que la red debe perder peso con urgencia.
 Arquitectura de red SegLink
Arquitectura de red SegLinkEl secreto de nuestra dieta.
Puede reducir el tamaño de la red simplemente cambiando la cantidad de capas y canales en ella, o cambiando la propia circunvolución y las conexiones entre ellas. Mark Sandler y sus asociados justo a tiempo recogieron la arquitectura en su red
MobileNetV2 [2] para que funcione rápidamente en dispositivos móviles, ocupe poco espacio y aún no se quede atrás del mismo VGG en calidad de trabajo. El secreto para acelerar y reducir el consumo de memoria está en tres pasos principales:
- El número de canales con mapas de características en la entrada del bloque se reduce por convolución de puntos a toda la profundidad (el llamado cuello de botella) sin una función de activación.
- La convolución clásica se reemplaza por una convolución separable por canal. Tal convolución requiere menos peso y menos cómputo.
- Las cartas de personaje después del cuello de botella se envían a la entrada del siguiente bloque para sumar sin convoluciones adicionales.
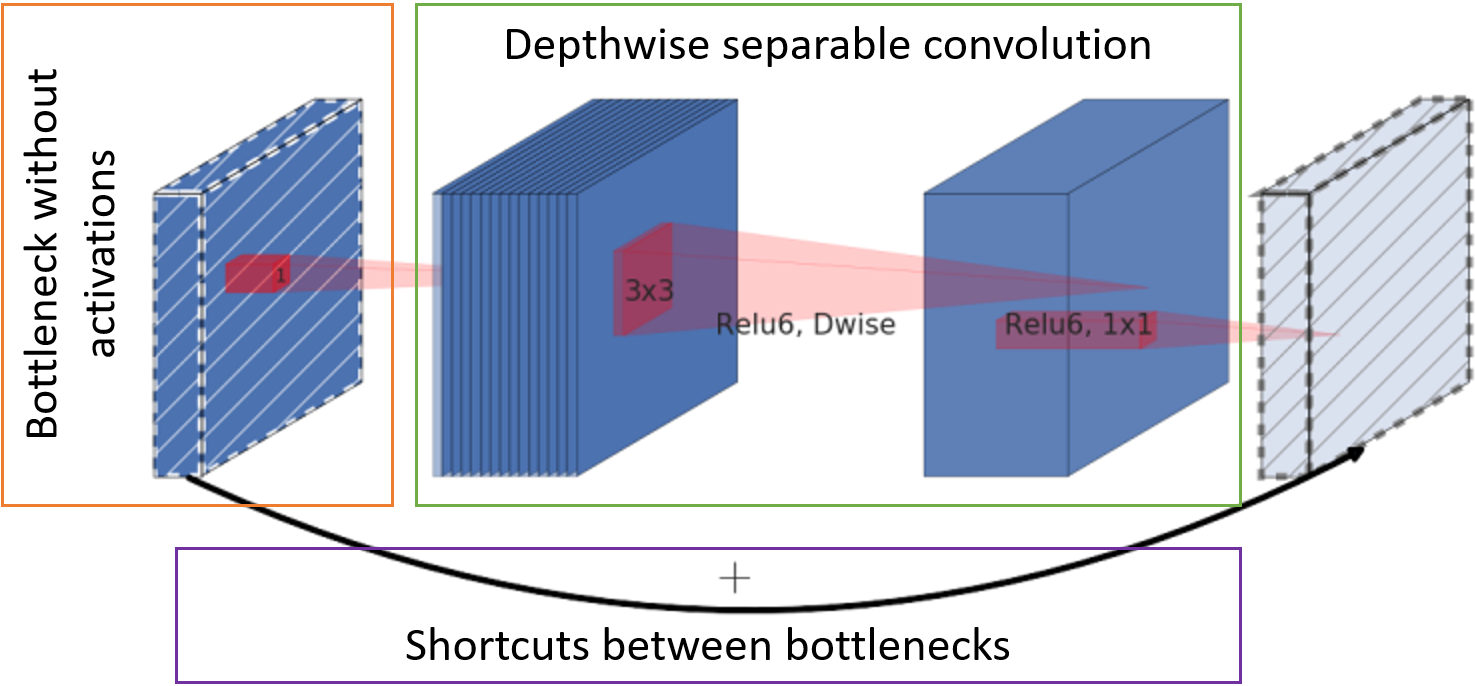 Unidad base MobileNetV2
Unidad base MobileNetV2
Red neuronal resultante
Usando los enfoques anteriores, llegamos a la siguiente estructura de red:
- Usamos segmentos y enlaces de SegLink
- Reemplace VGG con un MobileNetV2 menos glotón
- Reduzca la cantidad de escalas de búsqueda de texto de 6 a 5 para mayor velocidad
 Red de resumen de búsqueda de texto
Red de resumen de búsqueda de texto
Descifrado de valores en bloques de arquitectura de red
El paso de zancada y el número base de canales en los canales se indican como s <stride> c <channels>, respectivamente. Por ejemplo, s2c32 significa 32 canales con un desplazamiento de 2. El número real de canales en las capas de convolución se obtiene multiplicando su número base por un factor de escala α, que le permite simular rápidamente diferentes "espesores" de la red. A continuación se muestra una tabla con el número de parámetros en la red dependiendo de α.

Tipo de bloque:
- Conv2D: una operación de convolución completa;
- D-wise Conv - convolución separable por canal;
- Bloques: un grupo de bloques MobileNetV2;
- Salida: convolución para obtener la capa de salida. Los valores numéricos de tipo NxN indican el tamaño del campo receptivo del píxel.
Como función de activación, los bloques usan ReLU6.

La capa de salida tiene 31 canales:
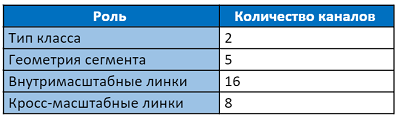
Los primeros dos canales de la capa de salida votan para que el píxel pertenezca al texto y no al texto. Los siguientes cinco canales contienen información para reconstruir con precisión la geometría del segmento: desplazamientos verticales y horizontales en relación con la posición del píxel, factores de ancho y alto (ya que el segmento generalmente no es cuadrado) y el ángulo de rotación. 16 valores de enlaces intracanal indican si hay una conexión entre ocho píxeles adyacentes en la misma escala. Los últimos 8 canales nos informan sobre la presencia de enlaces a cuatro píxeles de la escala anterior (la escala anterior siempre es 2 veces mayor). Cada 2 valores de segmentos, los enlaces intra y de escala cruzada se normalizan mediante la función softmax. El acceso a la primera escala no tiene enlaces de escala cruzada.
Asamblea de palabras
La red predice si un segmento particular y sus vecinos pertenecen al texto. Queda por recopilarlos en palabras.
Para comenzar, combine todos los segmentos que están vinculados por enlaces. Para hacer esto, componimos un gráfico donde los vértices son todos los segmentos en todas las escalas, y los bordes son enlaces. Luego encontramos los componentes conectados de la gráfica. Para cada componente, ahora es posible calcular la palabra que encierra el rectángulo de la siguiente manera:
- Calculamos el ángulo de rotación de la palabra θ
- O como el valor promedio de las predicciones del ángulo de rotación de los segmentos, si hay muchos de ellos,
- O como el ángulo de rotación de la línea obtenida por regresión en los puntos de los centros de los segmentos, si hay pocos segmentos.
- El centro de la palabra se selecciona como el centro de masa de los puntos centrales de los segmentos.
- Expanda todos los segmentos por -θ para organizarlos horizontalmente. Encuentra los límites de la palabra.
- Los límites izquierdo y derecho de la palabra se seleccionan como los límites de los segmentos más a la izquierda y a la derecha, respectivamente.
- Para obtener el límite superior de la palabra, los segmentos se ordenan por la altura del borde superior, se corta el 20% de los más altos y el valor del primer segmento se selecciona de la lista que queda después del filtrado.
- El límite inferior se obtiene de los segmentos más bajos con un límite del 20% del más bajo, por analogía con el límite superior.
- Gira el rectángulo resultante de nuevo a θ.
La solución final se llama
FaSTExt : Extractor de texto rápido y pequeño [3]
¡Experimente el tiempo!
Detalles de entrenamiento
La red misma y sus parámetros se seleccionaron para un buen trabajo en una muestra interna grande, que refleja el escenario principal del uso de la aplicación en el teléfono: apuntó la cámara a un objeto con texto y tomó una foto. Resultó que una red grande con α = 1 omite en calidad la versión con α = 0.5 en solo un 2%. Esta muestra no está disponible públicamente, por lo que para mayor claridad, tuve que entrenar a la red en la muestra pública
ICDAR2013 , en la que las condiciones de disparo son similares a las nuestras. La muestra es muy pequeña, por lo que la red se entrenó previamente en una gran cantidad de datos sintéticos de
SynthText en el Wild Dataset . El proceso de pre-entrenamiento tomó aproximadamente 20 días de cálculos para cada experimento en el GTX 1080 Ti, por lo que la operación de la red en datos públicos se verificó solo para las opciones α = 0.75, 1 y 2.
Como optimizador, se
utilizó la versión
AMSGrad de Adam.
Funciones de error:
- Entropía cruzada para la clasificación de segmentos y enlaces;
- Función de pérdida de Huber para geometría de segmento.
Resultados
En términos de la calidad del rendimiento de la red en el escenario objetivo, podemos decir que no está muy por detrás de la competencia en calidad, e incluso supera a algunos. MS es una red de competidores multiescala pesada.
 * En el artículo sobre EAST no hubo resultados en la muestra que necesitábamos, por lo que realizamos el experimento nosotros mismos.
* En el artículo sobre EAST no hubo resultados en la muestra que necesitábamos, por lo que realizamos el experimento nosotros mismos.La imagen a continuación muestra un ejemplo de cómo funciona FaSTExt en imágenes de ICDAR2013. La primera línea muestra que las letras iluminadas de la palabra ESPMOTO no estaban marcadas, pero la red pudo encontrarlas. La versión menos espaciosa con α = 0,75 hizo frente a texto pequeño peor que las versiones más "gruesas". La línea inferior muestra nuevamente defectos de marcado en la muestra con texto perdido en la reflexión. FaSTExt al mismo tiempo ve dicho texto.

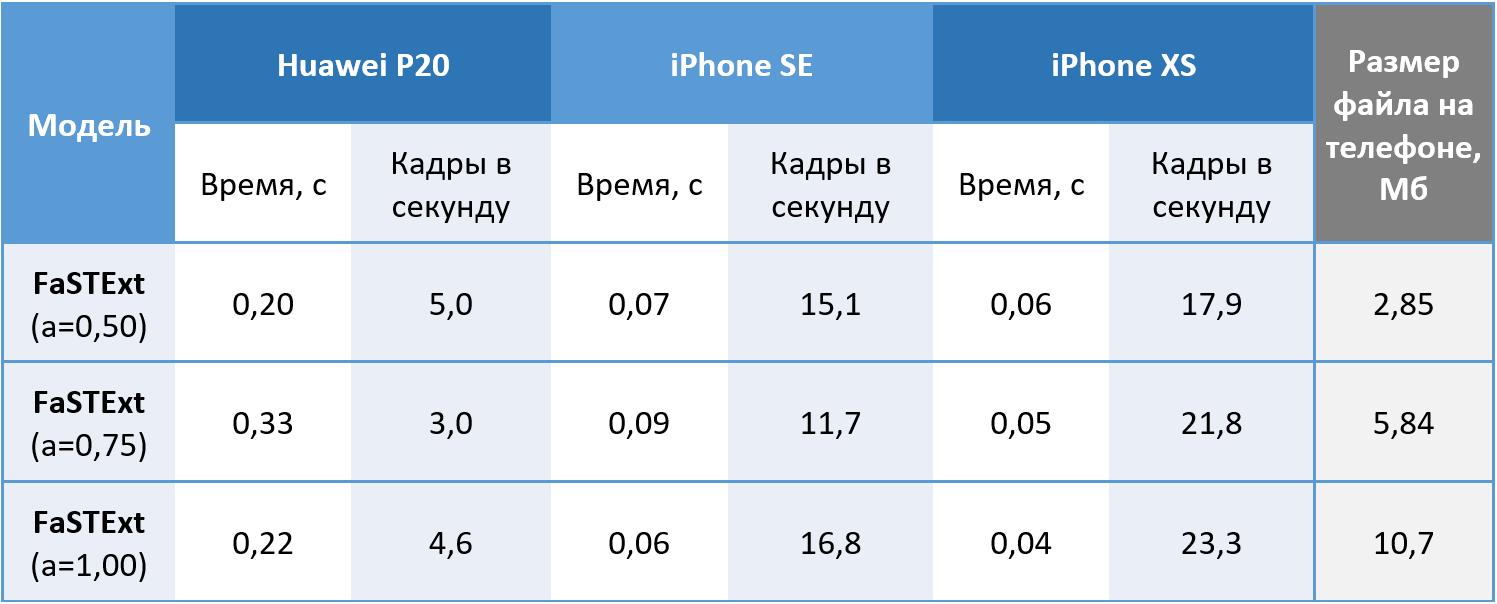
Entonces, la red realiza sus tareas. Queda por comprobar si realmente se puede usar en teléfonos? Los modelos se lanzaron en imágenes en color de 512x512 en el Huawei P20 usando la CPU, y en el iPhone SE y iPhone XS usando la GPU, porque nuestro sistema de aprendizaje automático todavía permite usar la GPU solo en iOS. Valores obtenidos promediando 100 comienzos. En Android, logramos alcanzar una velocidad de 5 fotogramas por segundo aceptable para nuestra tarea. El iPhone XS mostró un efecto interesante con una disminución en el tiempo promedio requerido para los cálculos al tiempo que complica la red. Un iPhone moderno detecta texto con un retraso mínimo, lo que se puede llamar una victoria.
Referencias
[1] B. Shi, X. Bai y S. Belongie, "Detección de texto orientado en imágenes naturales mediante la vinculación de segmentos", Hawaii, 2017.
enlace[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov y L.-C. Chen, "MobileNetV2: Residuos invertidos y cuellos de botella lineales", Salt Lake City, 2018.
enlace[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov e I. Zagaynov, "FaSTExt: Extractor de texto rápido y pequeño", en el 8º Taller internacional sobre análisis y reconocimiento de documentos basados en cámara, Sydney, 2019
enlace[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu y X. Bai, "Detección de texto de orientación múltiple con redes totalmente convolucionales", Las Vegas, 2016.
enlace[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He y J. Liang, "ESTE: un detector de texto de escena eficiente y preciso", en la Conferencia de informática IEEE 2017 Visión y patrón, Honolulu, 2017.
enlace[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia y X. Bai, "Regresión sensible a la rotación para la detección de texto de escenas orientadas", en la Conferencia IEEE / CVF 2018 sobre visión y patrón por computadora, Salt Lake City, 2018.
enlace[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao y J. Yan, "Fots: localización rápida de texto orientado con una red unificada", en la Conferencia IEEE / CVF 2018 sobre visión por computadora y Patrón, Salt Lake City, 2018.
enlaceGrupo de visión por computadora