Conferencia de Habr: la historia no es debut. Solíamos llevar a cabo eventos bastante grandes de Tostadora para 300-400 personas, pero ahora decidimos que las pequeñas reuniones temáticas serán relevantes, cuya dirección también puede establecer, por ejemplo, en los comentarios. La primera conferencia de este formato se celebró en julio y se dedicó al desarrollo de backend. Los participantes escucharon informes sobre las características de la transición del backend a ML y sobre el diseño del servicio Quadrupel en el portal de servicios estatales, y también participaron en una mesa redonda dedicada a Serverless. Para aquellos que no pudieron asistir personalmente al evento, en este post les contamos los más interesantes.

Del desarrollo de backend al aprendizaje automático
¿Qué hacen los ingenieros de datos de ML? ¿Cuáles son las similitudes y diferencias entre las tareas del desarrollador de backend y el ingeniero de ML? ¿Qué camino debes seguir para cambiar la primera profesión a la segunda? Esto fue dicho por Alexander Parinov, quien entró en el aprendizaje automático después de 10 años de backend.
 Alexander Parinov
Alexander ParinovHoy, Alexander trabaja como arquitecto de sistemas de visión por computadora en X5 Retail Group y contribuye a proyectos de código abierto relacionados con la visión por computadora y el aprendizaje profundo (github.com/creafz). Sus habilidades se confirman por su participación en el top 100 del ranking mundial de Kaggle Master (kaggle.com/creafz), la plataforma más popular que alberga competencias de aprendizaje automático.
¿Por qué cambiar al aprendizaje automático?
Hace un año y medio, Jeff Dean, jefe de Google Brain, el proyecto de investigación de inteligencia artificial de aprendizaje profundo de Google, le dijo a Google que medio millón de líneas de código en Google Translate fueron reemplazadas por una red neuronal con Tensor Flow, que consta de solo 500 líneas. Después de entrenar la red, la calidad de los datos ha crecido y la infraestructura se ha simplificado. Parece que este es nuestro brillante futuro: ya no tenemos que escribir código, solo hacer neuronas y arrojarlas con datos. Pero en la práctica, todo es mucho más complicado.
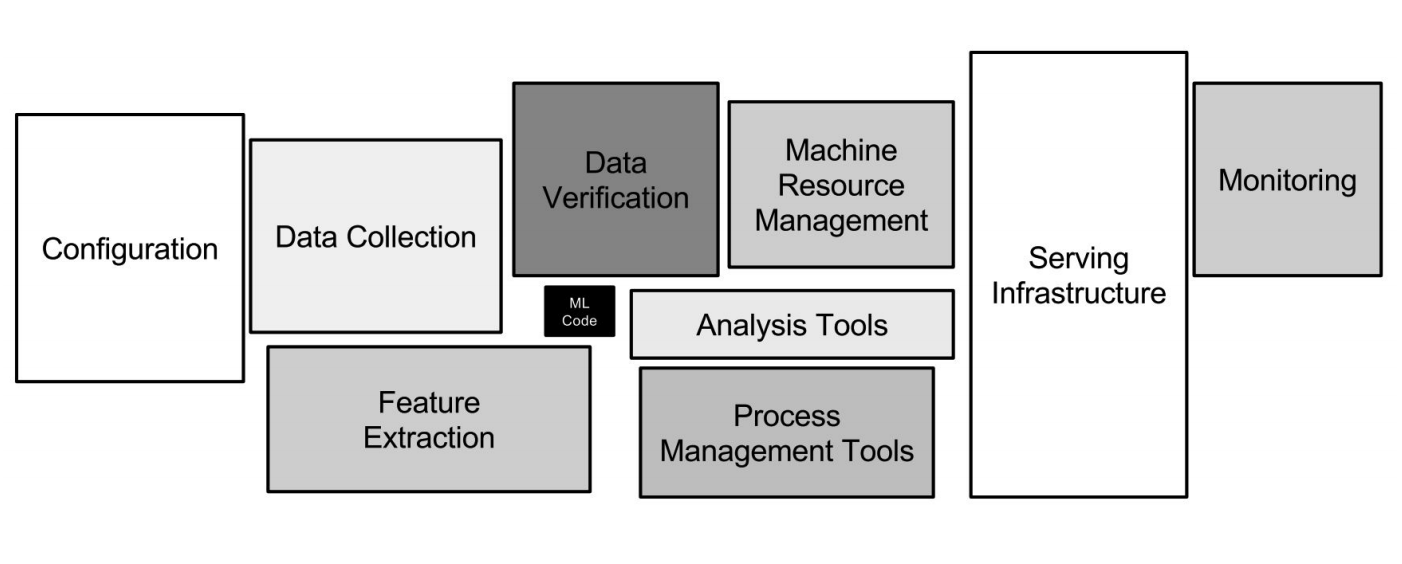 Infraestructura de Google ML
Infraestructura de Google MLLas redes neuronales son solo una pequeña parte de la infraestructura (un pequeño cuadro negro en la imagen de arriba). Se requieren muchos más sistemas auxiliares para recibir datos, procesarlos, almacenarlos, verificar la calidad, etc., necesitamos la infraestructura para la capacitación, desplegar el código de aprendizaje automático en producción, probar este código. Todas estas tareas son como lo que hacen los desarrolladores de back-end.
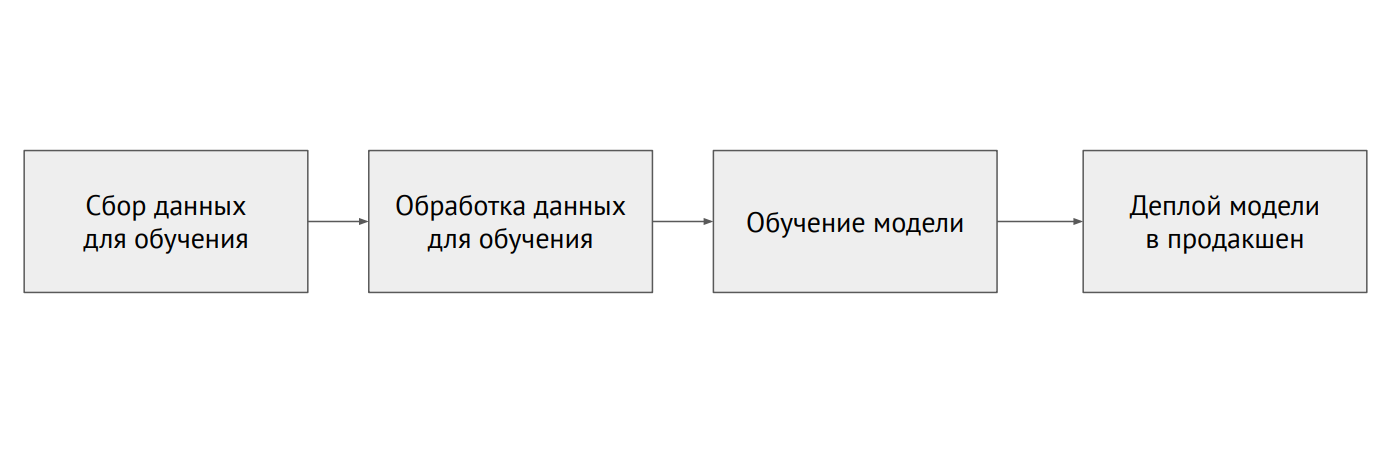 Proceso de aprendizaje automático
Proceso de aprendizaje automático¿Cuál es la diferencia entre ML y backend?
En la programación clásica, escribimos código, y esto dicta el comportamiento del programa. En ML, tenemos un código de modelo pequeño y muchos datos con los que descartamos el modelo. Los datos en ML son muy importantes: el mismo modelo, entrenado con datos diferentes, puede mostrar resultados completamente diferentes. El problema es que casi siempre los datos están fragmentados y se encuentran en diferentes sistemas (bases de datos relacionales, bases de datos NoSQL, registros, archivos).
 Versionado de datos
Versionado de datosML requiere el control de versiones no solo del código, como en el desarrollo clásico, sino también de los datos: es necesario comprender claramente en qué se entrenó el modelo. Puede usar la popular biblioteca Data Science Version Control (dvc.org) para esto.
 Marcado de datos
Marcado de datosLa siguiente tarea es el marcado de datos. Por ejemplo, marque todos los objetos en la imagen o diga a qué clase pertenece. Esto se realiza mediante servicios especiales como Yandex.Tolki, el trabajo con el que se simplifica enormemente la disponibilidad de la API. Las dificultades surgen debido al "factor humano": es posible mejorar la calidad de los datos y minimizar los errores al confiar la misma tarea a varios artistas.
 Visualización en Tensor Board
Visualización en Tensor BoardEl registro de experimentos es necesario para comparar resultados, eligiendo el mejor modelo para algunas métricas. Para la visualización hay un gran conjunto de herramientas, por ejemplo, Tensor Board. Pero no hay métodos ideales para almacenar experimentos. En las pequeñas empresas, a menudo se las arreglan con una placa de excelencia, en las grandes empresas utilizan plataformas especiales para almacenar resultados en la base de datos.
 Existen muchas plataformas para el aprendizaje automático, pero ninguna de ellas cubre ni siquiera el 70% de las necesidades.
Existen muchas plataformas para el aprendizaje automático, pero ninguna de ellas cubre ni siquiera el 70% de las necesidades.El primer problema con el que tiene que lidiar cuando trae un modelo entrenado a producción está relacionado con su herramienta científica de datos favorita: Jupyter Notebook. No hay modularidad en él, es decir, la salida da como resultado un "pie de página" de código que no se divide en partes lógicas: módulos. Todo está mezclado: clases, funciones, configuraciones, etc. Este código es difícil de versionar y probar.
¿Cómo lidiar con eso? Puede soportar Netflix y crear su propia plataforma que le permita ejecutar estas computadoras portátiles directamente en producción, transferirles datos y obtener el resultado. Puede obligar a los desarrolladores que incorporan el modelo a producción a reescribir el código normalmente, dividirlo en módulos. Pero con este enfoque, es fácil cometer un error y el modelo no funcionará según lo previsto. Por lo tanto, la opción ideal es prohibir el uso de Jupyter Notebook para el código del modelo. Si, por supuesto, los científicos de datos están de acuerdo con esto.
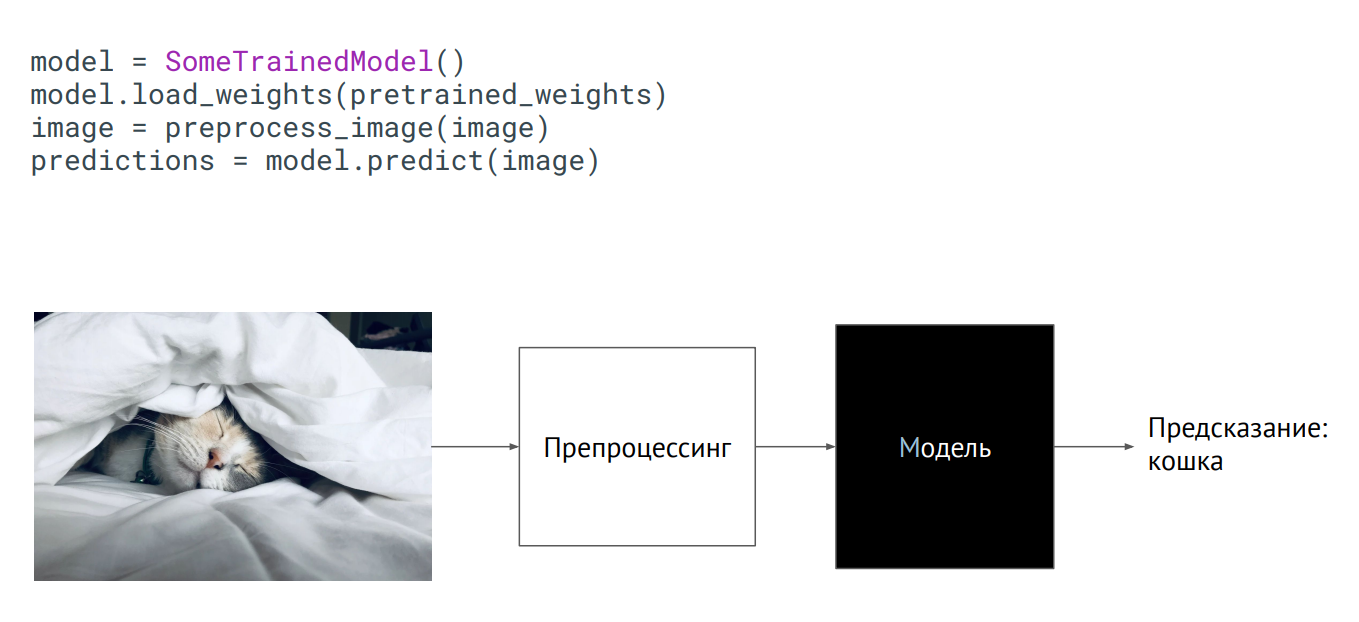 Modelo como caja negra
Modelo como caja negraLa forma más fácil de llevar un modelo a producción es usarlo como una caja negra. Tiene alguna clase del modelo, se le pasaron los pesos del modelo (parámetros de las neuronas de la red entrenada), y si inicializa esta clase (llame al método de predicción, coloque una imagen), entonces la salida obtendrá algún tipo de predicción. Lo que pasa adentro no importa.
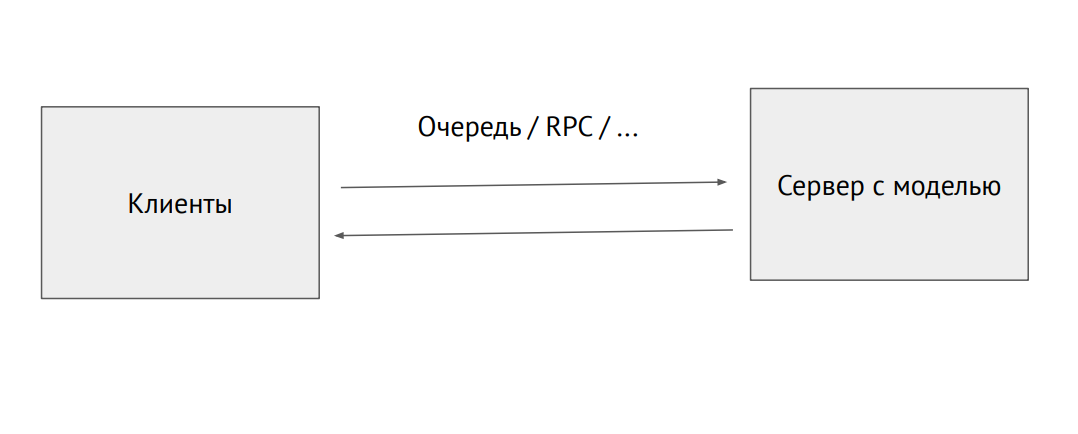 Proceso de servidor separado con un modelo
Proceso de servidor separado con un modeloTambién puede recoger un proceso separado y enviarlo a través de la cola RPC (con imágenes u otros datos de origen. En la salida, recibiremos predicciones.
Un ejemplo de uso del modelo en Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
El problema con este enfoque es la limitación del rendimiento. Supongamos que tenemos un código Phyton escrito por científicos de datos que se ralentiza, y queremos obtener el máximo rendimiento. Para hacer esto, puede usar herramientas que conviertan el código a nativo o lo conviertan a otro marco, afilado para producción. Existen tales herramientas para cada marco, pero no hay herramientas ideales, tendrá que terminarlo usted mismo.
La infraestructura en ML es la misma que en un backend regular. Hay Docker y Kubernetes, solo para Docker necesita configurar el tiempo de ejecución de NVIDIA, que permite que los procesos dentro del contenedor accedan a las tarjetas de video en el host. Kubernetes necesita un complemento para poder administrar servidores con tarjetas de video.
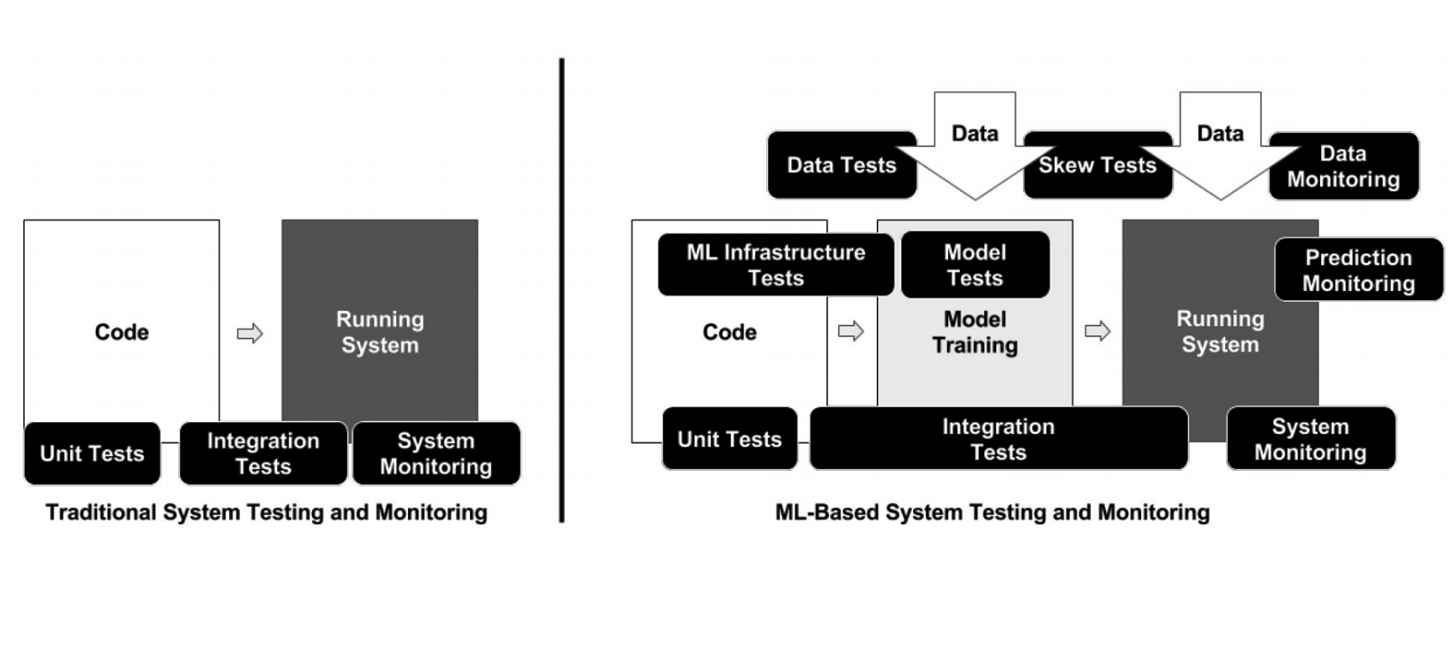
A diferencia de la programación clásica, en el caso de ML, la infraestructura tiene muchos elementos móviles diferentes que deben verificarse y probarse, por ejemplo, el código de procesamiento de datos, la tubería de capacitación del modelo y la producción (consulte el diagrama anterior). Es importante probar el código que conecta diferentes piezas de tuberías: hay muchas piezas y muy a menudo surgen problemas en los bordes de los módulos.
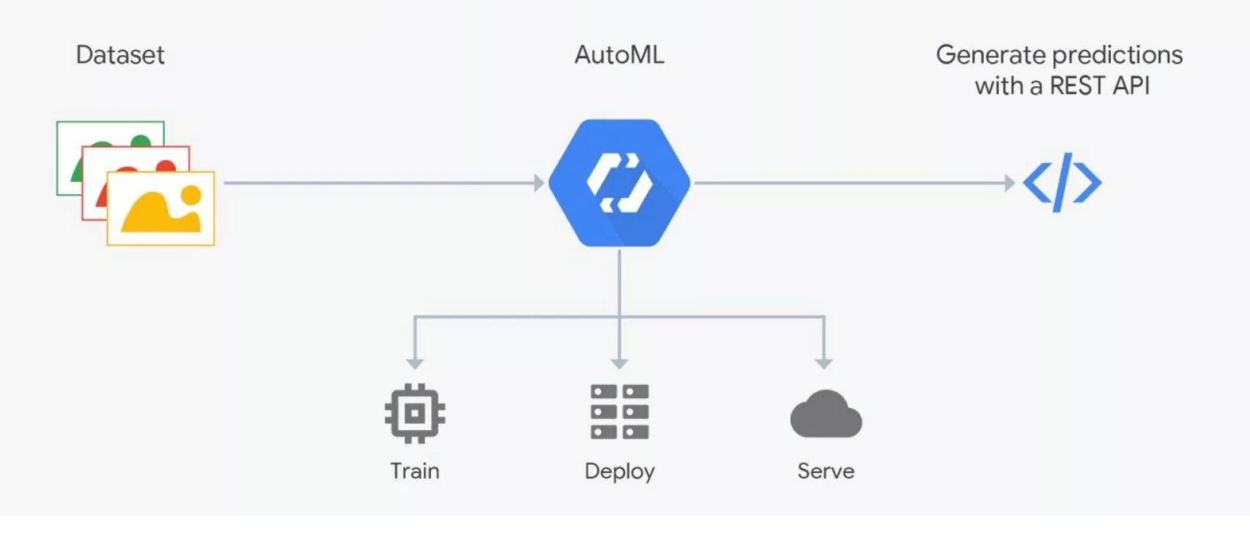 Cómo funciona AutoML
Cómo funciona AutoMLLos servicios de AutoML prometen seleccionar el mejor modelo para sus objetivos y entrenarlo. Pero debe comprender: en ML los datos son muy importantes, el resultado depende de su preparación. La gente está marcando, que está llena de errores. Sin un control estricto, la basura puede resultar, pero la automatización aún no funciona; verificación por expertos: se necesitan científicos de datos. Aquí es donde AutoML "se rompe". Pero puede ser útil para la selección de arquitectura, cuando ya haya preparado los datos y desee realizar una serie de experimentos para encontrar el mejor modelo.
Cómo entrar en el aprendizaje automático
Entrar en ML es más fácil si está desarrollando en Python, que se usa en todos los frameworks de aprendizaje profundo (y frameworks regulares). Este idioma es prácticamente necesario para este campo de actividad. C ++ se usa para algunas tareas con visión por computadora, por ejemplo, en sistemas de control de vehículos no tripulados. JavaScript y Shell: para visualización y cosas tan extrañas como el lanzamiento de una neurona en un navegador. Java y Scala se utilizan cuando se trabaja con Big Data y para el aprendizaje automático. R y Julia son amados por las personas que hacen estadísticas.
Obtener experiencia práctica para comenzar es más conveniente en Kaggle, la participación en uno de los concursos de la plataforma brinda más de un año de estudio de la teoría. En esta plataforma, puede tomar el código presentado y comentado de alguien e intentar mejorarlo, optimizarlo para sus objetivos. El rango de bonificación en Kaggle afecta tu salario.
Otra opción es ir como desarrollador de backend al equipo de ML. Ahora hay muchas nuevas empresas involucradas en el aprendizaje automático, en las que adquieres experiencia ayudando a tus colegas a resolver sus problemas. Finalmente, puede unirse a una de las comunidades de científicos de datos: Open Data Science (ods.ai) y otras.
El orador colocó información adicional sobre el tema en https://bit.ly/backend-to-ml
"Quadrupel" - el servicio de notificaciones específicas del portal "Servicios del Estado"

Evgeny Smirnov
El siguiente orador fue Yevgeny Smirnov, jefe del departamento de desarrollo de infraestructura de gobierno electrónico, quien habló sobre Quadrupel. Este es un servicio de notificación dirigido del portal Gosuslugi (gosuslugi.ru), el recurso estatal más visitado en la Internet rusa. La audiencia diaria es de 2.6 millones, en total, 90 millones de usuarios están registrados en el sitio, de los cuales 60 millones están confirmados. La carga en la API del portal es de 30 mil RPS.
 Tecnologías utilizadas en el backend Gosuslug
Tecnologías utilizadas en el backend Gosuslug"Cuádruple" es un servicio de notificación de direcciones, con la ayuda de la cual el usuario recibe una oferta de servicio en el momento más adecuado para él mediante el establecimiento de reglas de información especiales. Los requisitos principales en el desarrollo del servicio fueron configuraciones flexibles y tiempo adecuado para el envío.
¿Cómo funciona el Cuádruple?

El diagrama anterior muestra una de las reglas del "Cuádruple" en el ejemplo de una situación con la necesidad de reemplazar una licencia de conducir. Primero, el servicio busca usuarios cuya fecha de vencimiento expire en un mes. Pusieron una pancarta con una oferta para recibir el servicio correspondiente y enviar un mensaje de correo electrónico. Para aquellos usuarios que ya han expirado, el banner y el correo electrónico están cambiando. Después de un intercambio exitoso de derechos, el usuario recibe otras notificaciones, con una propuesta para actualizar los datos en el certificado.
Desde un punto de vista técnico, estos son scripts maravillosos en los que se escribe el código. En la entrada - datos, en la salida - verdadero / falso, coincidente / no coincidente. En total, más de 50 reglas, desde determinar el cumpleaños del usuario (la fecha actual es igual al cumpleaños del usuario) hasta situaciones difíciles. Todos los días, de acuerdo con estas reglas, se determinan alrededor de un millón de coincidencias, personas que necesitan ser notificadas.
 Canales de notificaciones cuádruples
Canales de notificaciones cuádruplesBajo el capó del Quadrupel hay una base de datos en la que se almacenan los datos del usuario y tres aplicaciones:
- El trabajador está diseñado para actualizar los datos.
- La API Rest retoma y entrega los banners al portal y a la aplicación móvil.
- El programador lanza recuentos de pancartas o envíos masivos.
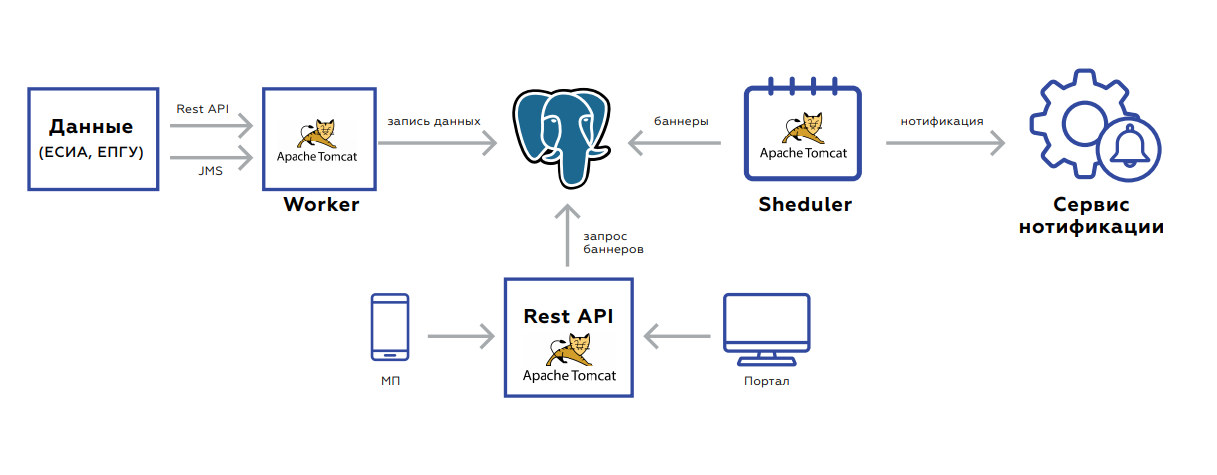
El backend está orientado a eventos para actualizar datos. Dos interfaces: descanso o JMS. Hay muchos eventos, antes de que se guarden y procesen, se agregan para no realizar solicitudes innecesarias. La base de datos en sí, la placa en la que se almacenan los datos, se parece al almacenamiento del valor de la clave: la clave del usuario y el valor en sí mismo: banderas que indican la presencia o ausencia de documentos relevantes, su período de validez, estadísticas agregadas sobre el orden de los servicios de este usuario, etc.

Después de guardar los datos, la tarea se configura en JMS para que los banners se vuelvan a contar de inmediato; esto debe mostrarse inmediatamente en la web. El sistema comienza por la noche: en JMS las tareas se lanzan a intervalos de usuario, de acuerdo con las cuales debe contar las reglas. Esto es recogido por los contadores. Además, los resultados del procesamiento entran en la siguiente cola, que guarda los banners en la base de datos o envía tareas al usuario para notificar al usuario. El proceso dura de 5 a 7 horas, es fácilmente escalable debido al hecho de que siempre puede soltar procesadores o aumentar instancias con procesadores nuevos.

El servicio funciona bastante bien. Pero la cantidad de datos está creciendo a medida que más usuarios. Esto lleva a un aumento en la carga en la base de datos, incluso teniendo en cuenta el hecho de que la API Rest está mirando la réplica. El segundo punto es JMS, que, como resultó, no es muy adecuado debido al gran consumo de memoria. Existe un alto riesgo de desbordamiento de cola con bloqueo JMS y parada de procesamiento. Es imposible elevar el JMS después de esto sin limpiar los registros.
Está previsto resolver problemas mediante el fragmentación, lo que permitirá equilibrar la carga en la base. También hay planes para cambiar el esquema de almacenamiento de datos y cambiar el JMS a Kafka, una solución más tolerante a fallas que resolverá los problemas de memoria.
Back-end como servicio vs. Sin servidor
 De izquierda a derecha: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
De izquierda a derecha: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan¿Backend como servicio o solución sin servidor? Las siguientes personas participaron en la discusión de este tema apremiante en la mesa redonda:
- Ara Israelyan, CTO CTO y fundador de Scorocode.
- Nikolay Markov, ingeniero de datos sénior en Aligned Research Group.
- Andrey Tomilenko, Jefe del Departamento de Desarrollo RUVDS.
La conversación fue moderada por el desarrollador senior Alexander Borgart. Presentamos el debate, en el que participó el público, en una versión abreviada.
- ¿Qué es Serverless en tu comprensión?
Andrei : Este es un modelo computacional, una función Lambda que debe procesar los datos para que el resultado dependa solo de los datos. El término vino de Google o de Amazon y su servicio AWS Lambda. Es más fácil para el proveedor procesar dicha función al asignar un grupo de capacidad para esto. Se pueden considerar diferentes usuarios de forma independiente en los mismos servidores.
Nikolay : Si es simple, transferimos parte de nuestra infraestructura de TI, lógica de negocios a la nube, para externalizar.
Ara : Por parte de los desarrolladores, un buen intento de ahorrar recursos, por parte de los vendedores, para ganar más dinero.
- Sin servidor: ¿lo mismo que los microservicios?
Nikolai : No, Serverless es más una organización de arquitectura. El microservicio es una unidad atómica de cierta lógica. Sin servidor es un enfoque, no una "entidad separada".
Ara : La función Serverless puede empaquetarse en un microservicio, pero a partir de esto dejará de ser Serverless, dejará de ser una función Lambda. En Serverless, una función solo se inicia cuando se solicita.
Andrew : Difieren en la vida. Lanzamos y olvidamos la función Lambda. Funcionó durante un par de segundos, y el siguiente cliente puede procesar su solicitud en otra máquina física.
- ¿Qué escala mejor?
Ara : con la escala horizontal, las funciones de Lambda se comportan exactamente de la misma manera que los microservicios.
Nikolai : cuántas réplicas pides, habrá tantas, que no habrá problemas con el escalado sin servidor. Kubernetes creó un conjunto de réplicas, lanzó 20 instancias "en algún lugar" y le devolvieron 20 enlaces anónimos. ¡Adelante!
- ¿Es posible escribir un backend en Serverless?
Andrew : Teóricamente, pero no tiene sentido en esto. Las funciones de Lambda se basarán en un único repositorio: debemos proporcionar una garantía. Por ejemplo, si el usuario realizó una determinada transacción, la próxima vez que vea: la transacción se ha completado, los fondos se han acreditado. Todas las funciones de Lambda se bloquearán en esta llamada. De hecho, un grupo de funciones sin servidor se convertirá en un solo servicio con un punto de acceso limitado a la base de datos.
- ¿En qué situaciones tiene sentido utilizar la arquitectura sin servidor?
Andrew : Tareas en las que no se requiere un almacenamiento común: la misma minería, blockchain. Donde necesitas contar mucho. Si tiene mucha potencia informática, puede definir una función como "calcular el hash de algo allí ..." Pero puede resolver el problema del almacenamiento de datos tomando, por ejemplo, las funciones de Amazon y Lambda, y su almacenamiento distribuido. Y resulta que estás escribiendo un servicio regular. Las funciones de Lambda accederán al repositorio y darán algún tipo de respuesta al usuario.
Nikolai : Los contenedores que se ejecutan en Serverless son extremadamente limitados en recursos. Hay poca memoria y todo lo demás. Pero si tiene toda la infraestructura implementada completamente en algún tipo de nube (Google, Amazon) y tiene un contrato permanente con ellos, hay un presupuesto para todo esto, entonces, para algunas tareas, puede usar contenedores sin servidor. Es necesario ubicarse exactamente dentro de esta infraestructura, porque todo está diseñado para su uso en un entorno específico. Es decir, si está listo para vincular todo a la infraestructura de la nube, puede experimentar. La ventaja es que no tiene que administrar esta infraestructura.
Ara : Que Serverless no requiere que administres Kubernetes, Docker, instales Kafka, etc., es autoengaño. El mismo Amazon y Google son el administrador y lo expresaron. Otra cosa es que tienes un SLA. Con el mismo éxito, puede externalizar todo y no programarlo usted mismo.
Andrew : Serverless en sí es económico, pero hay que pagar mucho por el resto de los servicios de Amazon, por ejemplo, una base de datos. La gente ya los ha demandado por el hecho de que estaban rompiendo dinero loco por la puerta API.
Ara : Si hablamos de dinero, entonces debe considerar este punto: tendrá que desplegar 180 grados toda la metodología de desarrollo en la empresa para transferir todo el código a Serverless. Tomará mucho tiempo y dinero.
- ¿Hay alguna alternativa decente a Amazon y Google sin servidor de pago?
Nikolay : En Kubernetes, comienzas algún tipo de trabajo, se cumple y muere; esto es bastante sin servidor desde el punto de vista de la arquitectura. Si desea crear una lógica de negocios realmente interesante con colas, con bases, debe pensar un poco más al respecto. Todo esto se resuelve sin salir de Kubernetes. No comenzaría a arrastrar una implementación adicional.
- ¿Qué tan importante es monitorear lo que está sucediendo en Serverless?
Ara : Depende de la arquitectura del sistema y los requisitos comerciales. De hecho, el proveedor debe proporcionar informes que ayuden a la persona a resolver posibles problemas.
Nikolai : En Amazon hay CloudWatch, donde se transmiten todos los registros, incluso con Lambda. Integre el reenvío de registros y use alguna herramienta separada para ver, alertar, etc. En los contenedores que comienzas, puedes abarrotar agentes.
 - Resumamos.
- Resumamos.
Andrew : Pensar en las funciones de Lambda es útil. Si crea un servicio rápido, no un microservicio, sino uno que escribe una solicitud, accede a la base de datos y envía una respuesta, la función Lambda resuelve una serie de problemas: subprocesamiento múltiple, escalabilidad y más. Si su lógica se construye de esta manera, en el futuro podrá transferir estos Lambda a microservicios o utilizar servicios de terceros como Amazon. La tecnología es útil, una idea interesante. Cuánto se justifica para los negocios sigue siendo una pregunta abierta.
Nikolai: Sin servidor es mejor usarlo para tareas de operación que calcular algún tipo de lógica de negocios. Siempre tomo esto como procesamiento de eventos. Si lo tienes en Amazon, si estás en Kubernetes, sí. De lo contrario, tendrá que hacer muchos esfuerzos para aumentar Serverless usted mismo. Necesita ver un caso de negocios específico. Por ejemplo, ahora tengo una de las tareas: cuando los archivos aparecen en un disco en un formato determinado, debe cargarlos en Kafka. Puedo usar este WatchDog o Lambda. Lógicamente, ambos son adecuados, pero Serverless es más difícil de implementar, y prefiero la forma más simple, sin Lambda.
Ara : sin servidor: una idea interesante, aplicable y muy hermosa técnicamente. Tarde o temprano, la tecnología llegará al punto en que cualquier función aumentará en menos de 100 milisegundos. Entonces, en principio, no habrá dudas de si el tiempo de espera es crítico para el usuario. Al mismo tiempo, la aplicabilidad de Serverless, como ya han dicho sus colegas, depende completamente de la tarea empresarial.
Agradecemos a nuestros patrocinadores que nos ayudaron mucho:
- El espacio de conferencias de TI " Primavera " detrás de la plataforma para la conferencia.
- Calendario de eventos de TI Runet-ID y la publicación " Internet en números " para soporte de información y noticias.
- Akronis para regalos.
- Avito para la co-creación.
- "Asociación de Comunicaciones Electrónicas" RAEC por su participación y experiencia.
- El patrocinador principal de RUVDS , ¡para todo!
