
Hola Habr! Dirijo el desarrollo de la plataforma
Vision : esta es nuestra plataforma pública, que proporciona acceso a modelos de visión por computadora y le permite resolver tareas tales como reconocer caras, números, objetos y escenas completas. Y hoy quiero decir con el ejemplo de Vision cómo implementar un servicio rápido y altamente cargado usando tarjetas de video, cómo implementarlo y operarlo.
¿Qué es la visión?
Esto es esencialmente una API REST. El usuario genera una solicitud HTTP con una foto y la envía al servidor.
Suponga que necesita reconocer una cara en una imagen. El sistema lo encuentra, lo corta, extrae algunas propiedades de la cara, lo guarda en la base de datos y le asigna un número condicional. Por ejemplo, persona42. El usuario luego carga la siguiente foto, que tiene la misma persona. El sistema extrae propiedades de su cara, busca en la base de datos y devuelve el número condicional que se asignó inicialmente a la persona, es decir, persona42.
Hoy, los principales usuarios de Vision son varios proyectos del Grupo Mail.ru. La mayoría de las solicitudes provienen de Mail and Cloud.
En la nube, los usuarios tienen carpetas en las que se cargan las fotos. La nube ejecuta archivos a través de Vision y los agrupa en categorías. Después de eso, el usuario puede hojear convenientemente sus fotos. Por ejemplo, cuando desea mostrar fotos a amigos o familiares, puede encontrar rápidamente las que necesita.
Tanto Mail como Cloud son servicios muy grandes con millones de personas, por lo que Vision procesa cientos de miles de solicitudes por minuto. Es decir, es un servicio clásico de alta carga, pero con un giro: tiene nginx, un servidor web, una base de datos y colas, pero en el nivel más bajo de este servicio hay inferencia: ejecutar imágenes a través de redes neuronales. Es la ejecución de redes neuronales que ocupa la mayor parte del tiempo y requiere recursos. Las redes de computación consisten en una secuencia de operaciones matriciales que generalmente requieren mucho tiempo en la CPU, pero están perfectamente paralelas en la GPU. Para ejecutar redes de manera efectiva, utilizamos un grupo de servidores con tarjetas de video.
En este artículo quiero compartir un conjunto de consejos que pueden ser útiles al crear dicho servicio.
Desarrollo de servicios
Tiempo de procesamiento para una solicitud
Para un sistema con una carga pesada, el tiempo de procesamiento de una solicitud y el rendimiento del sistema son importantes. La selección correcta de la arquitectura de la red neuronal proporciona, en primer lugar, una alta velocidad de procesamiento de consultas. En ML, como en cualquier otra tarea de programación, las mismas tareas pueden resolverse de diferentes maneras. Tomemos la detección de rostros: para resolver este problema, primero tomamos redes neuronales con arquitectura R-FCN. Muestran una calidad bastante alta, pero tomaron alrededor de 40 ms en una imagen, lo que no nos convenía. Luego recurrimos a la arquitectura MTCNN y obtuvimos un doble aumento de velocidad con una ligera pérdida de calidad.
A veces, para optimizar el tiempo de cálculo de las redes neuronales, puede ser ventajoso implementar la inferencia en otro marco, no en el que se enseñó. Por ejemplo, a veces tiene sentido convertir su modelo a NVIDIA TensorRT. Aplica una serie de optimizaciones y es especialmente bueno en modelos bastante complejos. Por ejemplo, de alguna manera puede reorganizar algunas capas, fusionarlas e incluso tirarlas; el resultado no cambiará y la velocidad de cálculo de inferencia aumentará. TensorRT también le permite administrar mejor la memoria y, después de algunos trucos, puede reducirla a calcular números con menos precisión, lo que también aumenta la velocidad de cálculo de la inferencia.
Descargar tarjeta de video
La inferencia de red se lleva a cabo en la GPU, la tarjeta de video es la parte más cara del servidor, por lo que es importante usarla de la manera más eficiente posible. ¿Cómo entender, hemos cargado completamente la GPU o podemos aumentar la carga? Esta pregunta puede responderse, por ejemplo, utilizando el parámetro de Utilización GPU en la utilidad nvidia-smi del paquete de controladores de video estándar. Esta figura, por supuesto, no muestra cuántos núcleos CUDA se cargan directamente en la tarjeta de video, sino cuántos están inactivos, pero le permite evaluar de alguna manera la carga de la GPU. Por experiencia, podemos decir que una carga del 80-90% es buena. Si tiene una carga del 10-20%, entonces esto es malo y todavía hay potencial.
Una consecuencia importante de esta observación: debe intentar organizar el sistema para maximizar la carga de las tarjetas de video. Además, si tiene 10 tarjetas de video, cada una de las cuales se carga al 10-20%, lo más probable es que dos tarjetas de video de alta carga puedan resolver el mismo problema.
Rendimiento del sistema
Cuando envía una imagen a la entrada de una red neuronal, el procesamiento de la imagen se reduce a una variedad de operaciones matriciales. La tarjeta de video es un sistema multinúcleo, y las imágenes de entrada que generalmente enviamos son pequeñas. Digamos que hay 1,000 núcleos en nuestra tarjeta de video, y tenemos 250 x 250 píxeles en la imagen. Solo, no podrán cargar todos los núcleos debido a su tamaño modesto. Y si enviamos esas imágenes al modelo de una en una, la carga de la tarjeta de video no excederá el 25%.
Por lo tanto, debe cargar varias imágenes para inferencia a la vez y formar un lote a partir de ellas.
En este caso, la carga de la tarjeta de video aumenta al 95%, y el cálculo de la inferencia llevará tiempo como para una sola imagen.
Pero, ¿qué pasa si no hay 10 imágenes en la cola para que podamos combinarlas en un lote? Puede esperar un poco, por ejemplo, 50-100 ms con la esperanza de que lleguen las solicitudes. Esta estrategia se llama estrategia de latencia fija. Le permite combinar solicitudes de clientes en un búfer interno. Como resultado, aumentamos nuestro retraso en una cantidad fija, pero aumentamos significativamente el rendimiento del sistema.
Lanzamiento de inferencia
Capacitamos modelos en imágenes de un formato y tamaño fijos (por ejemplo, 200 x 200 píxeles), pero el servicio debe admitir la capacidad de cargar varias imágenes. Por lo tanto, todas las imágenes antes de enviarlas a inferencia, debe prepararse adecuadamente (cambiar el tamaño, centrar, normalizar, traducir a flotante, etc.). Si todas estas operaciones se realizan en un proceso que inicia inferencia, entonces su ciclo de trabajo se verá así:
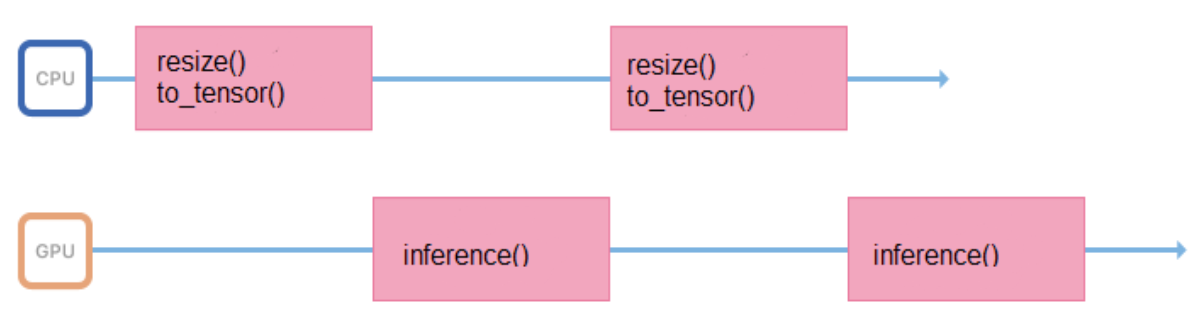
Pasa algo de tiempo en el procesador, preparando los datos de entrada, durante algún tiempo esperando una respuesta de la GPU. Es mejor minimizar los intervalos entre inferencias para que la GPU esté menos inactiva.
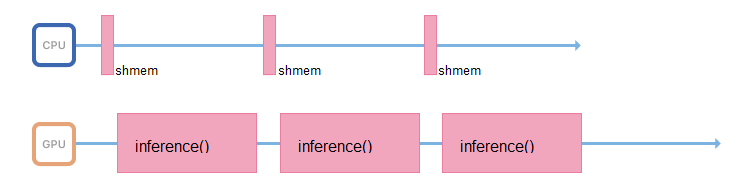
Para hacer esto, puede iniciar otra transmisión o transferir la preparación de imágenes a otros servidores, sin tarjetas de video, pero con procesadores potentes.
Si es posible, el proceso responsable de la inferencia solo debe ocuparse de ella: acceder a la memoria compartida, recopilar datos de entrada, copiarlos inmediatamente a la memoria de la tarjeta de video y ejecutar la inferencia.
Turbo boost
Lanzar redes neuronales es una operación que consume recursos no solo de la GPU, sino también del procesador. Incluso si todo está organizado correctamente en términos de ancho de banda, y el hilo que realiza la inferencia ya está esperando nuevos datos, en un procesador débil simplemente no tendrá tiempo para saturar este flujo con nuevos datos.
Muchos procesadores admiten la tecnología Turbo Boost. Le permite aumentar la frecuencia del procesador, pero no siempre está habilitado de forma predeterminada. Vale la pena echarle un vistazo. Para esto, Linux tiene la utilidad CPU Power:
$ cpupower frequency-info -m .
Los procesadores también tienen un modo de consumo de energía que puede ser reconocido por tal CPU Power: comando de
performance .
En el modo de ahorro de energía, el procesador puede acelerar su frecuencia y funcionar más lentamente. Debe ingresar al BIOS y seleccionar el modo de rendimiento. Entonces el procesador siempre funcionará a la frecuencia máxima.
Implementación de aplicaciones
Docker es excelente para implementar la aplicación, le permite ejecutar aplicaciones en la GPU dentro del contenedor. Para acceder a las tarjetas de video, primero debe instalar los controladores para la tarjeta de video en el sistema host: un servidor físico. Luego, para iniciar el contenedor, debe hacer mucho trabajo manual: arroje correctamente las tarjetas de video dentro del contenedor con los parámetros correctos. Después de iniciar el contenedor, aún será necesario instalar controladores de video dentro de él. Y solo después de eso puedes usar tu aplicación.

Este enfoque tiene una advertencia. Los servidores pueden desaparecer del clúster y agregarse. Es posible que diferentes servidores tengan diferentes versiones de controladores, y diferirán de la versión que está instalada dentro del contenedor. En este caso, un Docker simple se romperá: la aplicación recibirá un error de desajuste de la versión del controlador cuando intente acceder a la tarjeta de video.

¿Cómo lidiar con eso? Hay una versión de Docker de NVIDIA, gracias a la cual es más fácil y más agradable usar el contenedor. Según la propia NVIDIA y según las observaciones prácticas, la sobrecarga del uso de nvidia-docker es de aproximadamente el 1%.
En este caso, los controladores deben instalarse solo en la máquina host. Cuando inicie el contenedor, no necesita tirar nada dentro, y la aplicación tendrá acceso inmediato a las tarjetas de video.

La "independencia" de nvidia-docker de los controladores le permite ejecutar un contenedor desde la misma imagen en diferentes máquinas en las que están instaladas diferentes versiones de los controladores. ¿Cómo se implementa esto? Docker tiene un concepto llamado docker-runtime: es un conjunto de estándares que describe cómo un contenedor debe comunicarse con el kernel host, cómo debe comenzar y detenerse, cómo interactuar con el kernel y el controlador. Comenzando con una versión específica de Docker, es posible reemplazar este tiempo de ejecución. Esto es lo que hizo NVIDIA: reemplazan el tiempo de ejecución, capturan las llamadas al controlador de video interno y convierten la versión correcta en llamadas al controlador de video.
Orquestación
Elegimos a Kubernetes como la orquesta. Es compatible con muchas características muy buenas que son útiles para cualquier sistema muy cargado. Por ejemplo, la detección automática permite que los servicios accedan entre sí dentro de un clúster sin reglas de enrutamiento complejas. O tolerancia a fallas: cuando Kubernetes siempre tiene varios contenedores listos, y si algo le sucede a los suyos, Kubernetes lanzará inmediatamente un nuevo contenedor.
Si ya tiene un clúster de Kubernetes configurado, no necesita tanto para comenzar a usar tarjetas de video dentro del clúster:
- conductores relativamente nuevos
- instalado nvidia-docker versión 2
- Docker Runtime configurado de forma predeterminada en `nvidia` en /etc/docker/daemon.json:
"default-runtime": "nvidia"
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml instalado kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
Después de configurar su clúster e instalar el complemento del dispositivo, puede especificar una tarjeta de video como recurso.
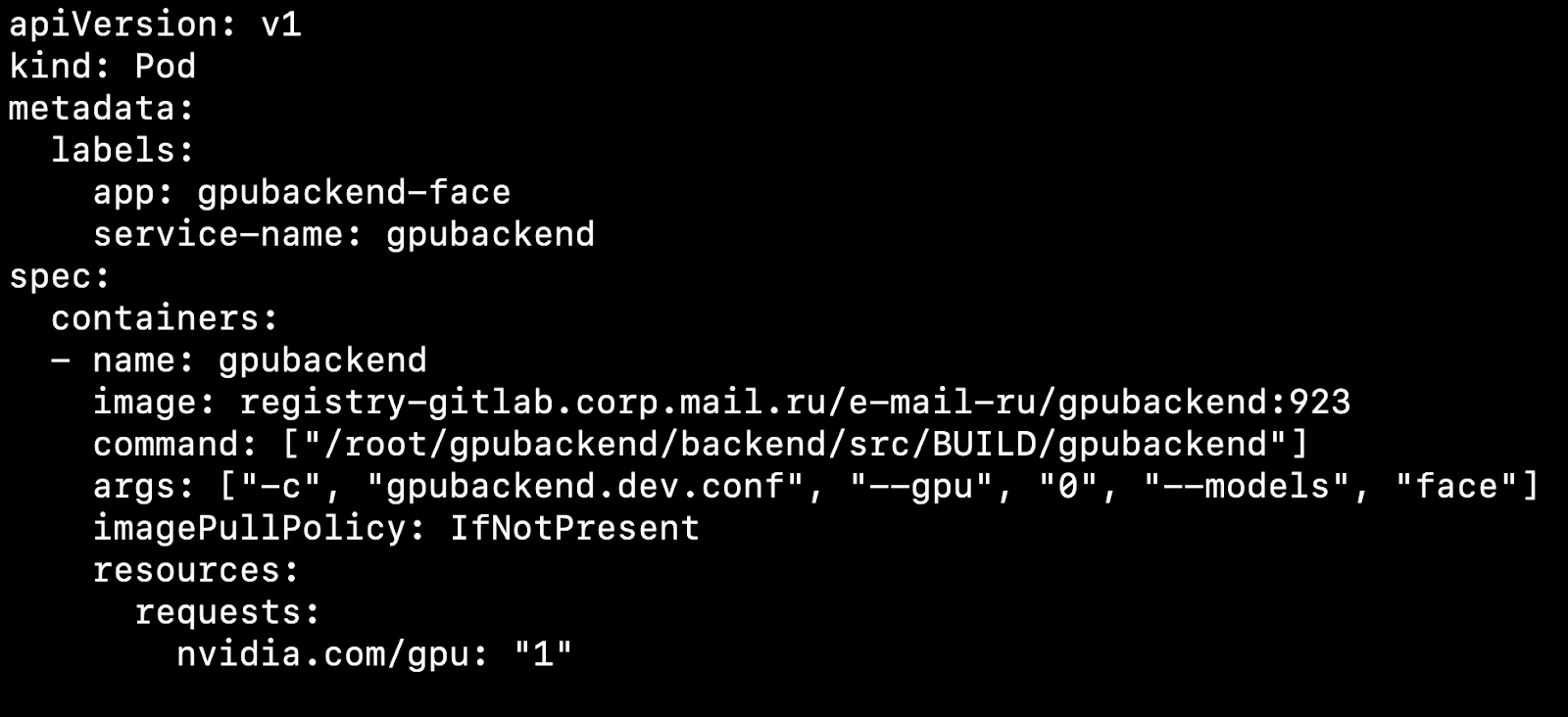
¿Qué afecta esto? Digamos que tenemos dos nodos, máquinas físicas. En una hay una tarjeta de video, en la otra no. Kubernetes detectará una máquina con una tarjeta de video y recogerá nuestro pod en ella.
Es importante tener en cuenta que Kubernetes no sabe cómo manipular una tarjeta de video de forma competente entre las cápsulas. Si tiene 4 tarjetas de video y necesita 1 GPU para iniciar el contenedor, entonces no puede aumentar más de 4 pods en su clúster.
Tomamos como regla 1 Pod = 1 Modelo = 1 GPU.
Hay una opción para ejecutar más instancias en 4 tarjetas de video, pero no lo consideraremos en este artículo, ya que esta opción no sale de la caja.
Si varios modelos deben girar a la vez, es conveniente crear Implementación en Kubernetes para cada modelo. En su archivo de configuración, puede especificar el número de hogares para cada modelo, teniendo en cuenta la popularidad del modelo. Si llegan muchas solicitudes al modelo, debe especificar muchos pods para él, si hay pocas solicitudes, hay pocos pods. En total, el número de hogares debe ser igual al número de tarjetas de video en el clúster.
Considera un punto interesante. Digamos que tenemos 4 tarjetas de video y 3 modelos.
En las dos primeras tarjetas de video, deje que aumente la inferencia del modelo de reconocimiento facial, en otro reconocimiento de objetos y en otro reconocimiento de números de automóviles.
Usted trabaja, los clientes van y vienen, y una vez, por ejemplo en la noche, surge una situación en la que una tarjeta de video con objetos de inferencia simplemente no se carga, una pequeña cantidad de solicitudes llega y las tarjetas de video con reconocimiento facial se sobrecargan. Me gustaría sacar un modelo con objetos en este momento y lanzar caras en su lugar para descargar las líneas.
Para el escalado automático de modelos en tarjetas de video, hay herramientas dentro de Kubernetes: escalado automático de solera horizontal (HPA, escalador automático de pod horizontal).
Fuera de la caja, Kubernetes admite el autoescalado en la utilización de la CPU. Pero en una tarea con tarjetas de video, será mucho más razonable usar información sobre la cantidad de tareas para cada modelo de escala.
Hacemos esto: poner solicitudes para cada modelo en una cola. Cuando se completan las solicitudes, las eliminamos de esta cola. Si logramos procesar rápidamente las solicitudes de modelos populares, entonces la cola no aumenta. Si el número de solicitudes para un modelo en particular aumenta repentinamente, entonces la cola comienza a crecer. Queda claro que necesita agregar tarjetas de video que ayuden a alinear la línea.
Información sobre las colas que enviamos a través de HPA a través de Prometheus:
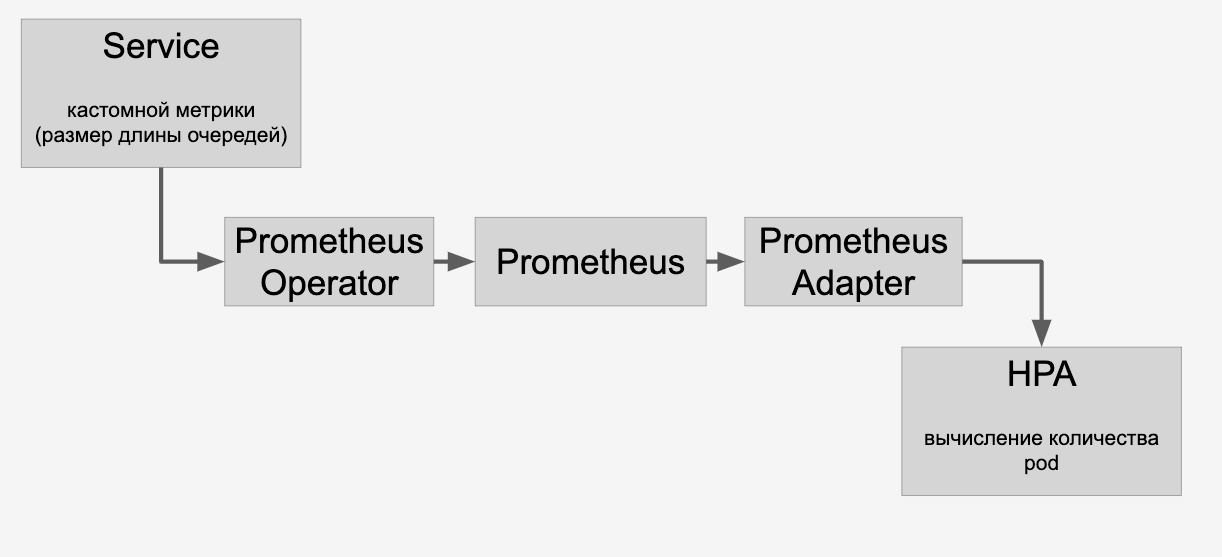
Y luego hacemos un autoescalado de los modelos en las tarjetas de video en el clúster, dependiendo de la cantidad de solicitudes que les envíen.
CI / CD
Después de que haya adjuntado la aplicación y la haya envuelto en Kubernetes, literalmente le queda un paso hacia la parte superior del proyecto. Puede agregar CI / CD, aquí hay un ejemplo de nuestra tubería:
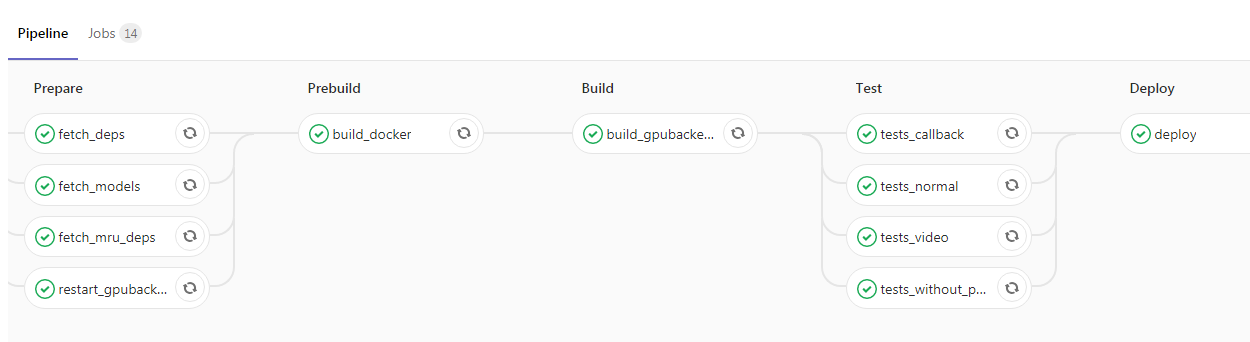
Aquí el programador lanzó el nuevo código en la rama maestra, después de lo cual la imagen de Docker con nuestros demonios de fondo se recopila automáticamente y se ejecutan las pruebas. Si todas las marcas de verificación son verdes, la aplicación se vierte en el entorno de prueba. Si no hay problemas, puede enviar la imagen a la operación sin ninguna dificultad.
Conclusión
En mi artículo, mencioné algunos aspectos del trabajo de un servicio altamente cargado utilizando una GPU. Hablamos sobre formas de reducir el tiempo de respuesta de un servicio, como:
- selección de la arquitectura de red neuronal óptima para reducir la latencia;
- Aplicaciones de marcos de optimización como TensorRT.
Planteó los problemas de aumentar el rendimiento:
- el uso de procesamiento por lotes de imágenes;
- aplicando una estrategia de latencia fija para reducir el número de ejecuciones de inferencia, pero cada inferencia procesará un mayor número de imágenes;
- optimización de la tubería de entrada de datos para minimizar el tiempo de inactividad de la GPU;
- "Lucha" con trote de procesador, eliminación de operaciones vinculadas a la CPU a otros servidores.
Analizamos el proceso de implementación de una aplicación con una GPU:
- Usando nvidia-docker dentro de Kubernetes
- escalado basado en el número de solicitudes y HPA (escalador automático de pod horizontal).