Una de las mejores características de iPhone X es el método de desbloqueo: FaceID. Este artículo analiza el principio de funcionamiento de esta tecnología.

La imagen de la cara del usuario se captura con una cámara infrarroja, que es más resistente a los cambios de luz y color del entorno. Mediante un entrenamiento en profundidad, un teléfono inteligente puede reconocer la cara del usuario en los detalles más pequeños, "reconociendo" al propietario cada vez que levanta su teléfono. Sorprendentemente, Apple dijo que este método es aún más seguro que TouchID: la tasa de error es 1: 1 000 000.
Este artículo explora el principio de un algoritmo similar a FaceID usando Keras. También se presentan algunos de los desarrollos finales creados con Kinect.
Entendiendo FaceID
"... las redes neuronales en las que se basa la tecnología FaceID no solo realizan la clasificación".
El primer paso es analizar cómo funciona FaceID en el iPhone X.
La documentación técnica puede ayudarnos con esto. Con TouchID, el usuario primero tenía que registrar sus huellas digitales tocando el sensor varias veces. Después de 10-15 toques diferentes, el teléfono inteligente completa el registro.
De manera similar con FaceID: el usuario debe registrar su cara. El proceso es bastante simple: el usuario simplemente mira el teléfono como lo hace a diario, y luego lentamente gira la cabeza en un círculo, registrando así su rostro en diferentes poses. Esto finaliza el registro y el teléfono está listo para desbloquear. Este procedimiento de registro increíblemente rápido puede decir mucho sobre los algoritmos básicos de aprendizaje. Por ejemplo, las redes neuronales en las que se basa la tecnología FaceID no solo realizan la clasificación.
Realizar una clasificación para una red neuronal significa la capacidad de predecir si la persona que está "viendo" en este momento es la cara del usuario. Por lo tanto, debería usar algunos datos de entrenamiento para predecir "verdadero" o "falso", pero a diferencia de muchas otras aplicaciones de aprendizaje profundo, este enfoque no funcionará aquí.
Primero, la red debe entrenarse desde cero, utilizando los nuevos datos recibidos de la cara del usuario. Esto requeriría mucho tiempo, energía y muchos datos de diferentes personas (no siendo la cara del usuario) para tener ejemplos negativos. Además, este método no permitirá a Apple entrenar una red más compleja "fuera de línea", es decir, en sus laboratorios, y luego enviarla ya entrenada y lista para usar en sus teléfonos. Se cree que FaceID se basa en la red neuronal convolucional siamesa, que está entrenada "fuera de línea" para mostrar caras en un espacio oculto de baja dimensión, formado para maximizar la diferencia entre las caras de diferentes personas, utilizando la pérdida de contraste. Obtiene una arquitectura que puede hacer capacitación única, como se menciona en Keynote.

De cara a números
La red neuronal siamesa consiste básicamente en dos redes neuronales idénticas, que también comparten todos los pesos. Esta arquitectura puede aprender a distinguir distancias entre datos específicos, como imágenes. La idea es que transmita pares de datos a través de redes siamesas (o simplemente transfiera datos en dos pasos diferentes a través de la misma red), la red los muestra en las características de baja dimensión del espacio, como una matriz n-dimensional, y luego entrena la red, para hacer una comparación tal que los datos de puntos de diferentes clases estuvieran lo más lejos posible, mientras que los datos de puntos de la misma clase estuvieran lo más cerca posible.
Finalmente, la red aprenderá a extraer las funciones más significativas de los datos y comprimirlas en una matriz, creando una imagen. Para entender esto, imagine cómo describiría las razas de perros usando un vector pequeño para que perros similares tengan vectores casi similares. Probablemente usaría un número para codificar el color del perro, el otro para indicar el tamaño del perro, el tercero para la longitud del pelaje, etc. Por lo tanto, los perros que sean iguales tendrán vectores similares. Una red neuronal siamesa puede hacer esto por usted, tal como lo hace un
codificador automático .
Con esta tecnología, se necesita una gran cantidad de personas para entrenar dicha arquitectura para reconocer las más similares. Con el presupuesto y la potencia informática adecuados (como lo hace Apple), también puede usar ejemplos más sofisticados para hacer que la red sea resistente a situaciones como gemelos, máscaras, etc.
¿Cuál es la ventaja final de este enfoque? En el hecho de que finalmente tiene un modelo plug and play que puede reconocer a diferentes usuarios sin ninguna preparación adicional, sino simplemente calcular la ubicación de la cara del usuario en un mapa de cara oculto formado después de configurar FaceID. Además, FaceID puede adaptarse a los cambios en su apariencia: repentina (por ejemplo, anteojos, sombrero, maquillaje) y "gradual" (crecimiento del cabello). Esto se realiza agregando vectores de soporte facial calculados en función de su nueva apariencia al mapa.

Implementando FaceID con Keras
Para todos los proyectos de aprendizaje automático, lo primero que necesitamos son datos. Crear su propio conjunto de datos requerirá tiempo y cooperación de muchas personas, por lo que esto puede ser difícil. Hay un sitio web
con un conjunto de datos de caras RGB-D. Consiste en una serie de fotos RGB-D de personas paradas en diferentes poses y haciendo diferentes expresiones faciales, como sería el caso con el iPhone X. Para ver la implementación final, aquí hay un enlace a
GitHub.Se crea una red de convolución basada en la arquitectura
SqueezeNet . Como entrada, la red acepta imágenes RGBD de pares de caras e imágenes de 4 canales, y muestra las diferencias entre los dos archivos adjuntos. La red aprende con una pérdida significativa, lo que minimiza la diferencia entre imágenes de la misma persona y maximiza la diferencia entre imágenes de diferentes caras.
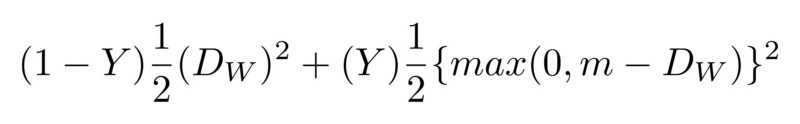
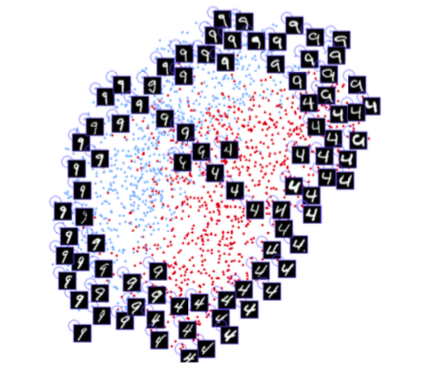
Después del entrenamiento, la red puede convertir caras en matrices de 128 dimensiones, de modo que las fotos de la misma persona se agrupan. Esto significa que para desbloquear el dispositivo, la red neuronal simplemente calcula la diferencia entre la imagen que se requiere durante el desbloqueo con las imágenes almacenadas durante la fase de registro. Si la diferencia coincide con un valor específico, el dispositivo está desbloqueado.
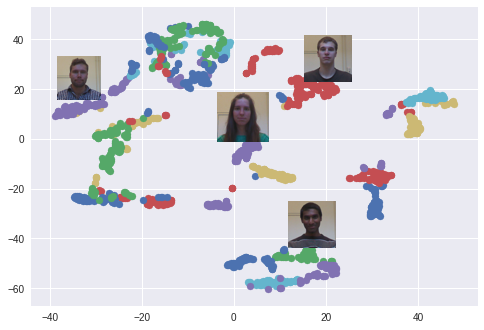
Se utiliza el algoritmo t-SNE. Cada color corresponde a una persona: como puede ver, la red ha aprendido a agrupar estas fotos con bastante fuerza. También surge un gráfico interesante cuando se utiliza el algoritmo PCA para reducir la dimensión de datos.

Un experimento
Ahora intentemos ver cómo funciona este modelo, simulando un bucle FaceID normal. Primero, registre a la persona. Luego lo desbloquearemos tanto en nombre del usuario como de otras personas que no deberían desbloquear el dispositivo. Como se mencionó anteriormente, la diferencia entre la persona que "ve" el teléfono y la persona registrada tiene un cierto umbral.
Comencemos con el registro. Tome una serie de fotografías de la misma persona del conjunto de datos y simule la fase de registro. Ahora el dispositivo calcula los archivos adjuntos para cada una de estas poses y los guarda localmente.


Veamos qué sucede si el mismo usuario intenta desbloquear el dispositivo. Las diferentes poses y expresiones faciales del mismo usuario logran una baja diferencia, un promedio de aproximadamente 0,30.

Por otro lado, las imágenes de diferentes personas obtienen una diferencia promedio de aproximadamente 1.1.

Por lo tanto, un valor umbral de aproximadamente 0.4 debería ser suficiente para evitar que extraños desbloqueen el teléfono.
En esta publicación, mostré cómo implementar el concepto de prueba de mecánica de desbloqueo de FaceID basado en incrustar caras y redes de convolución siamesas. Espero que la información te haya sido útil. Puede encontrar
todo el código de Python
relativo aquí.
Más análisis de nuevas tecnologías - en el
canal Telegram .
Todo el conocimiento!