El artículo discutirá la clasificación de la tonalidad de los mensajes de texto en ruso (y esencialmente cualquier clasificación de textos que use la misma tecnología). Tomaremos
este artículo como base, en el que se consideró la clasificación de la tonalidad en la arquitectura CNN utilizando el modelo Word2vec. En nuestro ejemplo, resolveremos el mismo problema de separar los tweets en positivo y negativo en el mismo conjunto de datos utilizando el modelo
ULMFit . El resultado del artículo (puntaje promedio F1 = 0.78142) será aceptado como línea de base.
Introduccion
El modelo ULMFIT fue presentado por los desarrolladores de fast.ai (Jeremy Howard, Sebastian Ruder) en 2018. La esencia del enfoque es utilizar el aprendizaje de transferencia en las tareas de PNL cuando utiliza modelos pre-entrenados, reduciendo el tiempo para entrenar sus modelos y reduciendo los requisitos para el tamaño de la muestra de prueba etiquetada.
El esquema de entrenamiento en nuestro caso se verá así:

El significado del modelo de lenguaje es poder predecir la siguiente palabra en secuencia. Es problemático obtener textos largos conectados de esta manera, pero, sin embargo, los modelos de lenguaje pueden capturar las propiedades del lenguaje, comprender el contexto del uso de palabras, por lo tanto, es el modelo de lenguaje (y no, por ejemplo, la visualización vectorial de palabras) la base de la tecnología. Para la tarea de modelar el lenguaje, ULMFit utiliza la arquitectura
AWD-LSTM , que implica el uso activo del abandono siempre que sea posible y tiene sentido. El tipo de capacitación en modelos de lenguaje a veces se denomina aprendizaje semi-supervisado, porque la etiqueta aquí es la siguiente palabra y no es necesario marcar nada con las manos.
Como modelo de lenguaje pre-entrenado, usaremos casi el único
disponible públicamente.
Repasemos el algoritmo de aprendizaje desde el principio.
Cargamos bibliotecas (verificamos la versión de Fast.ai en caso de incompatibilidades):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
Preparamos datos para el entrenamiento.
Por analogía, llevaremos a cabo una capacitación sobre el
cuerpo de textos cortos RuTweetCorp de Yulia Rubtsova , formada a partir de mensajes en ruso de Twitter. El cuerpo contiene 114,991 tweets positivos y 111,923 tweets negativos en formato CSV. Además, hay una base de datos de tweets no asignados con un volumen de 17 639 674 registros en formato SQL. La tarea de nuestro clasificador será determinar si el tweet es positivo o negativo.
Como
fue mucho tiempo volver a entrenar el modelo de lenguaje en 17 millones de tweets y la tarea de mostrar el aprendizaje de transferencia fue
flojera , volveremos a entrenar el modelo de idioma en un texto del conjunto de datos de entrenamiento, ignorando por completo la base de los tweets no asignados. Probablemente, utilizando esta base para "afilar" el modelo de lenguaje, puede mejorar el resultado general.
Formamos conjuntos de datos para capacitación y pruebas con procesamiento de texto preliminar. Tomamos el código del artículo
original :
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
Nos fijamos en lo que pasó:
df_train.groupby('Label').count()
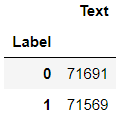
df_val.groupby('Label').count()
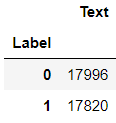
df_test.groupby('Label').count()

Aprendiendo un modelo de lenguaje
Cargando datos:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
Nos fijamos en los contenidos:
data_lm.show_batch()

Proporcionamos enlaces a los pesos almacenados del modelo
previamente entrenado y un diccionario:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
Creamos aprendices, pero antes de eso, una muleta para fast.ai. El modelo previamente entrenado se entrenó en una versión anterior de la biblioteca, por lo que debe ajustar el número de nodos en la capa oculta de la red neuronal.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
Estamos buscando la tasa de aprendizaje óptima:
learn_lm.lr_find() learn_lm.recorder.plot()

Entrenamos el modelo de la tercera era (en el modelo, solo el último grupo de capas está descongelado).
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
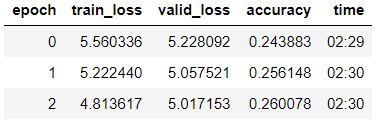
Descongelar el modelo y enseñar 5 eras más con una tasa de aprendizaje más baja:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
Intentamos generar texto en un modelo entrenado.
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
Ya vemos, algo que hace el modelo. Pero nuestra tarea principal es la clasificación, y para su solución tomaremos un codificador del modelo.
learn_lm.save_encoder('ft_enc')
Nosotros entrenamos el clasificador
Descargar datos para entrenamiento
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
Veamos los datos, vemos que las etiquetas se contaron con éxito (0 significa negativo y 1 significa un comentario positivo):
data_clas.show_batch()

Crea un alumno con una muleta similar:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
Cargamos el codificador entrenado en la etapa anterior y congelamos el modelo, excepto el último grupo de pesas:
learn.load_encoder('ft_enc') learn.freeze()
Estamos buscando la tasa de aprendizaje óptima:
learn.lr_find() learn.recorder.plot(skip_start=0)

Entrenamos el modelo con el deshielo gradual de las capas.
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
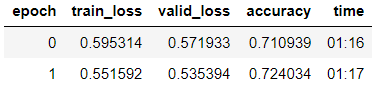
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
Vemos que en la muestra de validación lograron precisión = 80.1%.
Probaremos el modelo en el comentario de
ZlodeiBaal en mi artículo anterior:
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
Vemos que el modelo atribuyó este comentario a negativo :-)
Comprobación del modelo en una muestra de prueba
La tarea principal en esta etapa es probar la capacidad de generalización del modelo. Para hacer esto, validamos el modelo en el conjunto de datos almacenado en el DataFrame df_test, que hasta ese momento no estaba disponible para el modelo de idioma o para el clasificador.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
Vemos que la precisión en la muestra de prueba resultó ser del 79,7%.
Echa un vistazo a la matriz de confusión:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
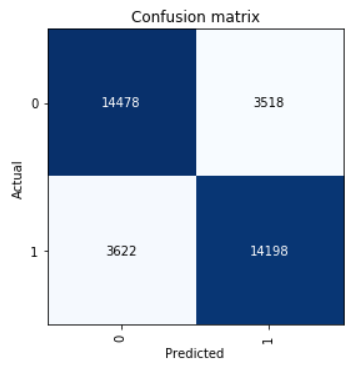
Calculamos los parámetros de precisión, recuperación y puntaje f1.
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
El resultado que se muestra en la muestra de prueba promedio F1-score = 0.80064.
Los pesos de modelos guardados se pueden tomar
aquí .