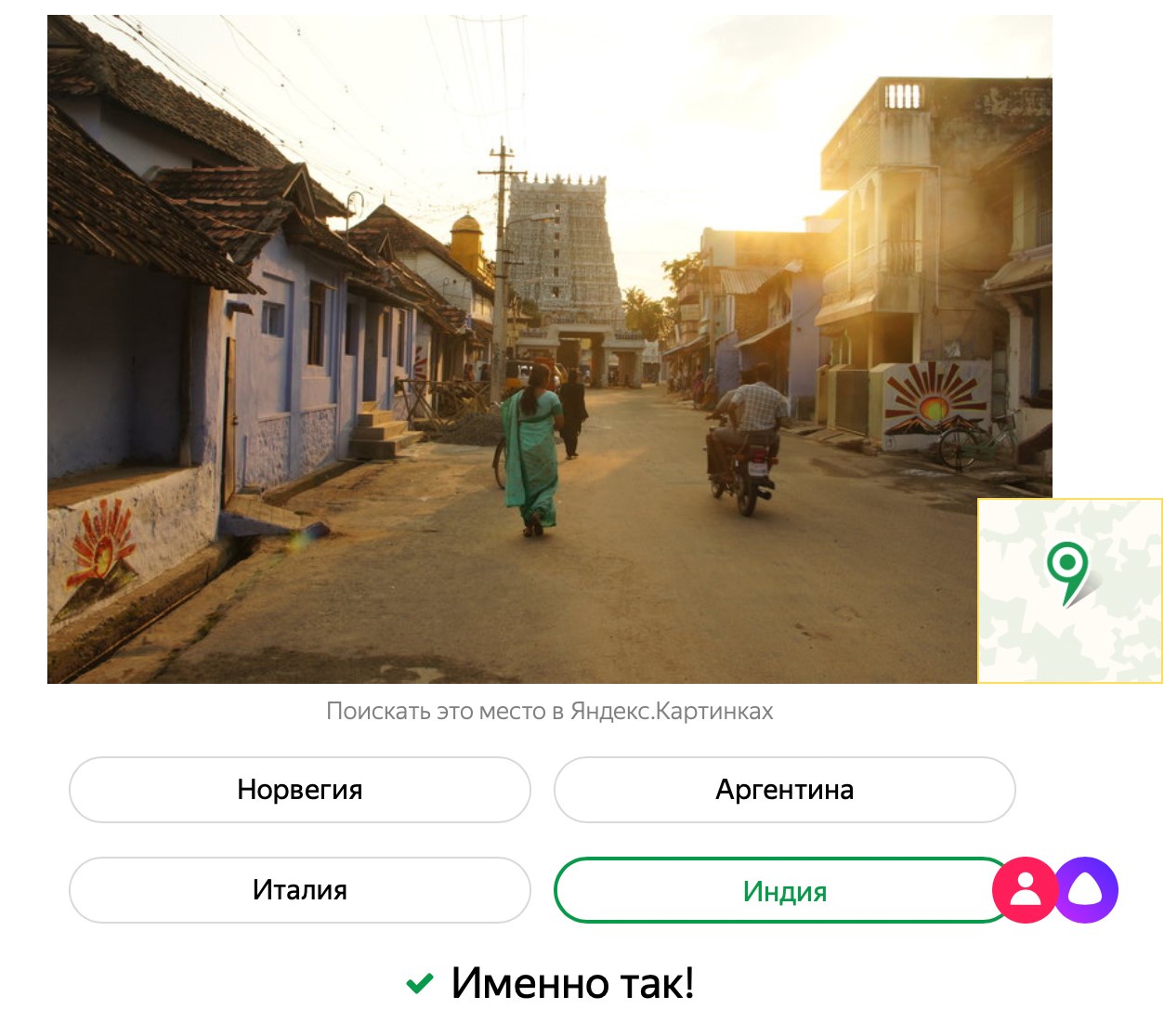
Hola Mi nombre es Evgeny Kashin y trabajo en el laboratorio de inteligencia de máquinas Yandex. Recientemente lanzamos un juego en el que los usuarios compiten con Alice para adivinar los países a partir de fotografías.
Es comprensible cómo actúan las personas: reconocen los lugares que han visto en viajes o en películas, confían en la erudición y el sentido común. La red neuronal no tiene nada de esto. Nos preguntamos qué detalles en las fotos le dan la respuesta. Realizamos un estudio, cuyos resultados hoy compartiremos con Habr.
Esta publicación será interesante tanto para los especialistas en el campo de la visión por computadora, como para todos los que deseen mirar dentro de la "inteligencia artificial" y comprender la lógica de su trabajo.

Algunas palabras sobre el juego "
Adivina el país por foto ". En resumen, tomamos fotos de Yandex.Maps y las dividimos en dos grupos. El primer grupo fue mostrado por redes neuronales, diciendo dónde se tomó cada disparo. Después de revisar miles de fotografías, la red neuronal hizo una idea de cada país, es decir, identificó de forma independiente combinaciones de signos por los cuales se puede reconocer. Usamos el segundo grupo de imágenes en el juego, Alice no las vio y no las recuerda durante el juego. Alice juega bien, pero la gente tiene una ventaja: no entrenamos la red neuronal para reconocer números de máquina, textos de signos y signos, banderas de estados.
Para el juego, entrenamos al modelo para predecir el país a partir de una fotografía. Tomamos un modelo de visión por computadora
SE-ResNeXt-101 , previamente
capacitado en muchas tareas. Los signos obtenidos de la imagen usando esta red neuronal convolucional son bastante universales, por lo que para el clasificador de país fue necesario agregar solo unas pocas capas adicionales (la llamada cabeza). Se utilizaron datos Yandex.Mart para el entrenamiento: aproximadamente 2.5 millones de fotos. Muchas imágenes no se ajustaban al juego según el criterio de belleza y se filtraron. La belleza se entiende como una combinación de factores: la calidad de la foto, la presencia de personas, texto, bosque, mar. Se eliminaron imágenes similares del mismo lugar para que el modelo no recordara vistas específicas. Después de todo el filtrado, quedaban aproximadamente 1 millón de fotos. Habiendo entrenado el modelo en estos datos, obtuvimos un clasificador bastante preciso, que determina el país solo por foto, sin usar información adicional.
Dado que la clasificación se lleva a cabo utilizando una red neuronal, no podemos obtener fácilmente una interpretación de las predicciones, en contraste con modelos lineales más simples o árboles de decisión. Pero queríamos descubrir cómo una red neuronal determina a partir de una fotografía regular de una calle o una casa de qué país es. Y los casos más interesantes son sin atracciones en el marco.
Para hacer esto, entrenamos la red neuronal desde cero, alimentándola no con imágenes enteras, sino solo pequeños trozos de recorte (para que el modelo no recuerde lugares específicos u objetos grandes).
Por lo tanto, la tarea para el modelo se ha vuelto notablemente más difícil (intente adivinar el país por un pedazo de cielo), la precisión del reconocimiento ha disminuido considerablemente. Pero, por otro lado, la red neuronal tuvo que prestar más atención a los pequeños detalles: mampostería inusual, patrones específicos, tipo de techo, plantas. El tamaño del cultivo aplicado al modelo cambió, y se obtuvieron varios modelos que observaron la foto en diferentes niveles de abstracción: cuanto más pequeño es el cultivo, más difícil es la tarea y más atento al modelo.

Los algoritmos para interpretar predicciones se pueden aplicar a modelos que fueron entrenados en tamaños de cultivos de diferentes tamaños. Me gustaría interpretar las predicciones en las fotografías fuente. La mayoría de las redes de convolución modernas usan la
Agrupación promedio global (GAP) antes de la última capa, esto permite entrenar la red en un tamaño y aplicarlo en otro. Esto se debe al hecho de que antes de la última capa, las entidades espaciales, distribuidas en ancho y alto, se promedian en un número para cada canal (mapa de entidades). Por lo tanto, los modelos entrenados en recorte (por ejemplo, 160 × 160 píxeles) se pueden usar en las imágenes grandes originales (800 × 800).
De hecho, la capa GAP es necesaria no solo para usar el modelo a diferentes resoluciones o para la regularización. También ayuda a la red neuronal a almacenar información sobre la posición de los objetos hasta la última capa (justo lo que necesitamos).
El primer método que probamos es el
mapeo de activación de clase (CAM).
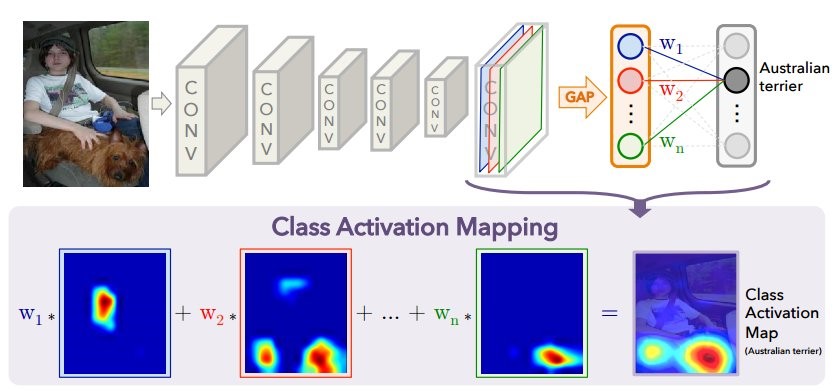
Cuando la imagen se alimenta a la entrada de la red neuronal, luego en la penúltima capa, se obtiene una "imagen" reducida (en realidad el tensor de activación) con los signos más importantes para cada clase predicha. Usando el método CAM, puede cambiar las últimas capas para que la salida sea la probabilidad de cada clase en cada región. Por ejemplo, si desea predecir 60 clases (países), para una imagen de entrada de 800 × 800, la imagen final consistirá en 60 tarjetas de activación de 25 × 25 de tamaño. Esto se ilustra bien en la publicación
original .
El diagrama anterior muestra el modelo habitual con GAP: las características espaciales se comprimen a un número para cada canal (mapa de características), después de lo cual hay una capa completamente conectada que predice las clases que encuentran los pesos óptimos para cada canal. A continuación se muestra cómo cambiar la arquitectura para obtener el método CAM: se elimina la capa GAP y los pesos de la última capa completamente conectada obtenida durante el entrenamiento con GAP (arriba en el diagrama) se utilizan para cada canal en cada punto. Para cada imagen, se obtienen N mapas de activación para todas las clases predichas. Para cada país, cuanto más brillante sea el área en el "mapa", mayor será la contribución de esta sección de la imagen a la decisión de elegir un determinado país. Lo que es interesante: si después de esta operación promediamos cada mapa de activación (en esencia, aplicamos GAP), entonces obtenemos solo la predicción inicial para cada clase.

En la imagen, verá un mapa de activación para la clase más probable (según el modelo). Se obtuvo estirando el mapa de activación 25 × 25 al tamaño de la imagen original 800 × 800.
Habiendo recibido un mapa para cada imagen, podemos agregar el cultivo más importante para países de diferentes imágenes. Esto le permite ver la colección de cultivos, describiendo el país de la mejor manera.
El segundo método, con el que decidimos comparar el primero, es una búsqueda exhaustiva simple. ¿Qué sucede si tomamos un modelo entrenado en cultivos pequeños (por ejemplo, 160 × 160 píxeles) y predecimos cada pieza en una imagen grande de 800 × 800? Al pasar una ventana deslizante que superpone cada área de la imagen, obtenemos otra versión del mapa de activación, que muestra la probabilidad de que cada parte de la imagen pertenezca a la clase del país predicho.

La imagen se corta en pequeños cropes con una superposición de 160 × 160. Para cada recorte, la red neuronal hace predicciones, el número por encima del recorte es la probabilidad de pertenecer a la clase que el modelo finalmente predijo.
Como en el primer método, nuevamente podemos elegir las piezas más probables para cada país. Pero las imágenes obtenidas por ambos métodos para el país pueden ser uniformes (por ejemplo, un edificio desde diferentes ángulos o una versión de la textura). Por lo tanto, la mejor cosecha para el país se agrupa adicionalmente, luego la mayoría de las imágenes similares se reunirán en un grupo. Después de eso, será suficiente tomar una foto de cada grupo con la máxima probabilidad: para cada país habrá tantas imágenes como grupos especificados. Hicimos clustering basado en las características obtenidas de la última capa de clasificador. La agrupación aglomerativa en nuestro caso resultó ser la mejor.

Después de haber recibido una canalización bastante similar para los dos métodos, puede iterar sobre los parámetros de los algoritmos para encontrar la combinación óptima. Por ejemplo, seleccionamos el tamaño del cultivo y nos decidimos por dos opciones: 160 y 256 píxeles. Los cultivos de menos de 160 dieron signos demasiado pequeños, según los cuales una persona a menudo no entiende lo que se representa. Y recortar más de 256 a veces contenía varios objetos a la vez. Es necesario seleccionar varios parámetros en la etapa de agrupación: la elección del algoritmo principal, así como las características por las cuales se realiza la agrupación. Para muchas combinaciones de parámetros, quedó claro de inmediato que dan un cultivo insuficientemente "interesante". Pero para seleccionar el algoritmo final, realizamos experimentos paralelos en Tolok para comprender qué opción, según las personas, describe el país específico de manera más "apropiada".
Resultó ser poco intuitivo que un método más simple para encontrar un recorte en la imagen (búsqueda normal) encuentra más objetos "interesantes". Esto puede deberse al hecho de que en el segundo método (enumeración) la red neuronal no ve la parte vecina de la imagen, y en el método CAM, el entorno del punto afecta el resultado. Como resultado, recibimos una visualización de las características de cada país en modo automático.
Entonces, ahora sabemos qué partes del marco son de importancia decisiva para la red neuronal, y podemos ver qué cayó sobre ellas. Por ejemplo, los Países Bajos reconocen una red neuronal por la combinación de paredes de ladrillo oscuro y contornos de ventanas blancas, los Emiratos Árabes Unidos, por rascacielos específicos contra el fondo de palmeras e Irán, por los arcos y adornos característicos en las fachadas.