Recientemente, he encontrado más y más información sobre el
marco de aprendizaje automático Ml.NET . El número de referencias a él se convirtió en calidad, y decidí mirar al menos con un solo vistazo de qué tipo de animal era.
Anteriormente tratamos de resolver el problema de predicción más simple utilizando la regresión lineal en el ecosistema .NET. Para esto, utilizamos el marco Accord.NET. Para estos fines, se preparó un pequeño conjunto de datos a
partir de datos abiertos sobre los llamamientos de los ciudadanos a las autoridades ejecutivas y personalmente
al alcalde de Moscú .
Después de un par de años con
un conjunto de datos actualizado, intentaremos resolver el
problema más simple . Usando el modelo de regresión en Ml.NET Framework, predecimos cuántas solicitudes por mes obtienen una solución positiva. En el camino, compararemos Ml.NET con Accord. Bibliotecas NET y Python.
¿Quieres dominar la fuerza y el poder del predictor? Entonces eres bienvenido bajo cat.
PS Let S.S. Sobyanin, el artículo no dirá una palabra sobre política.Contenido:
Parte I: introducción y un poco sobre datosParte II: escribir código C #Parte III: ConclusiónCreo que es necesario advertirle de inmediato que no soy un profesional en análisis de datos y programación en general, ni estoy comprometido con el Ayuntamiento de Moscú. Por lo tanto, el artículo es más probable de principiante a principiante. Pero a pesar de mi conocimiento limitado, espero que el artículo te sea útil.Las personas que ya están familiarizadas con artículos anteriores del ciclo pueden recordar que ya hemos tratado de resolver el problema de predecir el número de problemas resueltos positivamente a partir de los llamamientos de los ciudadanos dirigidos a la rama ejecutiva de Moscú. Para esto, utilizamos
Python y
Accord.Net Framework .
Otros artículos de ciclo1. Aprende lo básico:
2. Practicamos las primeras habilidades.
En cualquier caso, no será superfluo analizar nuevamente el conjunto de datos utilizado.
Todos los materiales del artículo, incluido el código y el conjunto de datos, están
disponibles gratuitamente en GitHub .
Los datos sobre GitHub se presentan en formato csv, contienen 44 entradas y, en principio, pueden (y deberían) usarse no solo para el análisis del ejemplo.
Las columnas de datos significan lo siguiente:
- num - índice de registro
- año - año de registro
- mes - mes de grabación
- total_appeals: número total de visitas por mes
- appeals_to_mayor - número total de apelaciones al alcalde
- res_positive- número de decisiones positivas
- res_explained - número de llamadas para aclaración
- res_negative: número de llamadas con una decisión negativa
- El_form_to_mayor - el número de apelaciones al alcalde en forma electrónica
- Pap_form_to_mayor: el número de apelaciones al alcalde en papel to_10K_total_VAO ... to_10K_total_YUZAO: el número de apelaciones por cada 10.000 habitantes en varios distritos de Moscú
- to_10K_mayor_VAO ... to_10K_mayor_YUZAO– el número de llamamientos al alcalde y al gobierno de Moscú por cada 10.000 habitantes en varios distritos de la ciudad
No encontré una manera de automatizar el proceso de recopilación de datos y los recopilé manualmente, por lo que podría estar un poco equivocado. De lo contrario, la fiabilidad de los datos se dejará a la conciencia de los autores.
Actualmente, los datos en el sitio web del gobierno en Moscú se presentan en su totalidad desde enero de 2016 hasta agosto de 2019 (faltan algunos datos en septiembre). Por lo tanto, tendremos 44 entradas. Un poco, por supuesto, pero para demostrarnos esto será suficiente.
Antes de comenzar, solo unas pocas palabras sobre el héroe de nuestro artículo.
ML.NET Framework : desarrollo de código abierto de Microsoft. Según la publicidad en redes sociales, esta es su respuesta a las bibliotecas de aprendizaje automático de Python. El marco es multiplataforma y le permite resolver una amplia gama de tareas, desde la simple regresión y clasificación hasta el aprendizaje profundo. En Habr, los camaradas ya llevaron a cabo el análisis de ML.NET y las bibliotecas en Python. A quién le importa, aquí está el
enlace .
No daré una guía detallada para instalar y usar Ml.NET porque, en esencia, todo fue "adaptado" basado en un
libro de texto del sitio web oficial de Microsoft .
Allí, se resolvió el problema con los precios de un viaje en taxi, y para ser sincero, hay más beneficios.Pero creo que las pequeñas explicaciones no serán superfluas.
Usé Visual Studio 2017 con las últimas actualizaciones.
El proyecto se basó en la plantilla de aplicación de consola .NET Core (versión 2.1).
El proyecto tuvo que instalar los paquetes NuGet Microsoft.ML, Microsoft.ML.FastTree. Eso, de hecho, es toda la preparación.
Procedemos directamente al código.
Primero, creé la clase MayorAppel, en la que describí en orden las columnas con datos de archivos csv.
Cómo no es difícil de adivinar [LoadColumn (0)]
- nos dice qué columna del archivo csv tomamos.
Luego, siguiendo el tutorial, creé la clase MayorAppelPrediction - para resultados de predicción
A pesar de que casi todas las columnas del conjunto de datos tienen valores enteros, para evitar errores en la etapa de pegado de datos en la tubería, tuve que asignarles un tipo flotante (para que todos los tipos de datos sean iguales).
La lista es lo suficientemente grande, así que póngala debajo del spoiler.
Código de clase para descripción de datosusing Microsoft.ML.Data; namespace app_to_mayor_mlnet { class MayorAppel { [LoadColumn(0)] public float Year; [LoadColumn(1)] public string Month; [LoadColumn(2)] public float TotalAppeals; [LoadColumn(3)] public float AppealsToMayor; [LoadColumn(4)] public float ResPositive; [LoadColumn(5)] public float ResExplained; [LoadColumn(6)] public float ResNegative; [LoadColumn(7)] public float ElFormToMayor; [LoadColumn(8)] public float PapFormToMayor; [LoadColumn(9)] public float To10KTotalVAO; [LoadColumn(10)] public float To10KMayorVAO; [LoadColumn(11)] public float To10KTotalZAO; [LoadColumn(12)] public float To10KMayorZAO; [LoadColumn(13)] public float To10KTotalZelAO; [LoadColumn(14)] public float To10KMayorZelAO; [LoadColumn(6)] public float To10KTotalSAO; [LoadColumn(15)] public float To10KMayorSAO; [LoadColumn(16)] public float To10KTotalSVAO; [LoadColumn(17)] public float To10KMayorSVAO; [LoadColumn(18)] public float To10KTotalSZAO; [LoadColumn(19)] public float To10KMayorSZAO; [LoadColumn(20)] public float To10KTotalTiNAO; [LoadColumn(21)] public float To10KMayorTiNAO; [LoadColumn(22)] public float To10KTotalCAO; [LoadColumn(23)] public float To10KMayorCAO; [LoadColumn(24)] public float To10KTotalYUAO; [LoadColumn(25)] public float To10KMayorYUAO; [LoadColumn(26)] public float To10KTotalYUVAO; [LoadColumn(27)] public float To10KMayorYUVAO; [LoadColumn(28)] public float To10KTotalYUZAO; [LoadColumn(29)] public float To10KMayorYUZAO; } public class MayorAppelPrediction { [ColumnName("Score")] public float ResPositive; } }
Pasemos al código del programa principal.
No olvides agregar al principio:
using System.IO; using Microsoft.ML;
La siguiente es una descripción de los campos de datos.
namespace app_to_mayor_mlnet { class Program { static readonly string _trainDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "train_data.csv"); static readonly string _testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "test_data.csv"); static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "Model.zip");
En estos campos, de hecho, se almacenan las rutas a los archivos de datos, esta vez decidí separarlos por adelantado (a diferencia del caso con Accord.NET)
Por cierto, si está haciendo su proyecto, no olvide configurar la opción "Copiar versión posterior" en las propiedades de los archivos de datos para evitar un error debido a la falta de archivos de ensamblaje.
Luego viene el desafío de los métodos que forman el modelo, realizan su evaluación y nos dan una predicción.
static void Main(string[] args) { MLContext mlContext = new MLContext(seed: 0); var model = Train(mlContext, _trainDataPath); Evaluate(mlContext, model); TestSinglePrediction(mlContext, model); }
Vamos en orden
El método Train es necesario para entrenar el modelo.
public static ITransformer Train(MLContext mlContext, string dataPath) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(dataPath, hasHeader: true, separatorChar: ','); var pipeline = mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "ResPositive") .Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "MonthEncoded", inputColumnName: "Month")) .Append(mlContext.Transforms.Concatenate("Features", "Year", "MonthEncoded", "TotalAppeals", "AppealsToMayor", "ResExplained", "ResNegative", "ElFormToMayor", "PapFormToMayor", "To10KTotalVAO", "To10KMayorVAO", "To10KTotalZAO", "To10KMayorZAO", "To10KTotalZelAO", "To10KMayorZelAO", "To10KTotalSAO", "To10KMayorSAO" , "To10KTotalSVAO", "To10KMayorSVAO", "To10KTotalSZAO", "To10KMayorSZAO", "To10KTotalTiNAO", "To10KMayorTiNAO" , "To10KTotalCAO", "To10KMayorCAO", "To10KTotalYUAO", "To10KMayorYUAO", "To10KTotalYUVAO", "To10KMayorYUVAO" , "To10KTotalYUZAO", "To10KMayorYUZAO")).Append(mlContext.Regression.Trainers.FastTree()); var model = pipeline.Fit(dataView); return model; }
Al principio leemos los datos de la muestra de entrenamiento. Luego en la cadena determinamos el parámetro que predecirá (etiqueta).
En nuestro caso, este es el número de problemas resueltos con éxito en relación con las apelaciones de los ciudadanos por mes.
Dado que en este caso se utiliza el modelo de impulso de árboles de decisión basado en la regresión, necesitamos llevar todos los signos a valores numéricos.
A diferencia del caso con Accord.NET, la solución OneHotEncoding lista para usar se presenta inmediatamente aquí en la documentación.
Después de que queda por formar las columnas, como dije anteriormente, todas deberían ser del mismo tipo de datos, en este caso, flotantes.
En conclusión, formamos y devolvemos el modelo terminado.
A continuación, evaluamos la calidad de la predicción por nuestro modelo.
private static void Evaluate(MLContext mlContext, ITransformer model) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(_testDataPath, hasHeader: true, separatorChar: ','); var predictions = model.Transform(dataView); var metrics = mlContext.Regression.Evaluate(predictions, "Label", "Score"); Console.WriteLine(); Console.WriteLine($"*************************************************"); Console.WriteLine($"* Model quality metrics evaluation "); Console.WriteLine($"*------------------------------------------------"); Console.WriteLine($"* RSquared Score: {metrics.RSquared:0.##}"); Console.WriteLine($"* Root Mean Squared Error: {metrics.RootMeanSquaredError:#.##}"); }
Cargamos nuestra muestra de prueba (los últimos 4 meses del conjunto), obtenemos la predicción de nuestros datos de prueba en el modelo entrenado utilizando el método Transform (). Luego calculamos las métricas e las imprimimos. En este caso, es el coeficiente de determinación y la desviación estándar. El primero idealmente debería tender a 1, y el segundo esencialmente a cero.
En principio, para hacer una predicción no necesitábamos este método, pero es bueno entender cuán mal nuestro modelo predice algo.
El último método permanece: la predicción misma.
También lo ocultaremos debajo del spoiler.
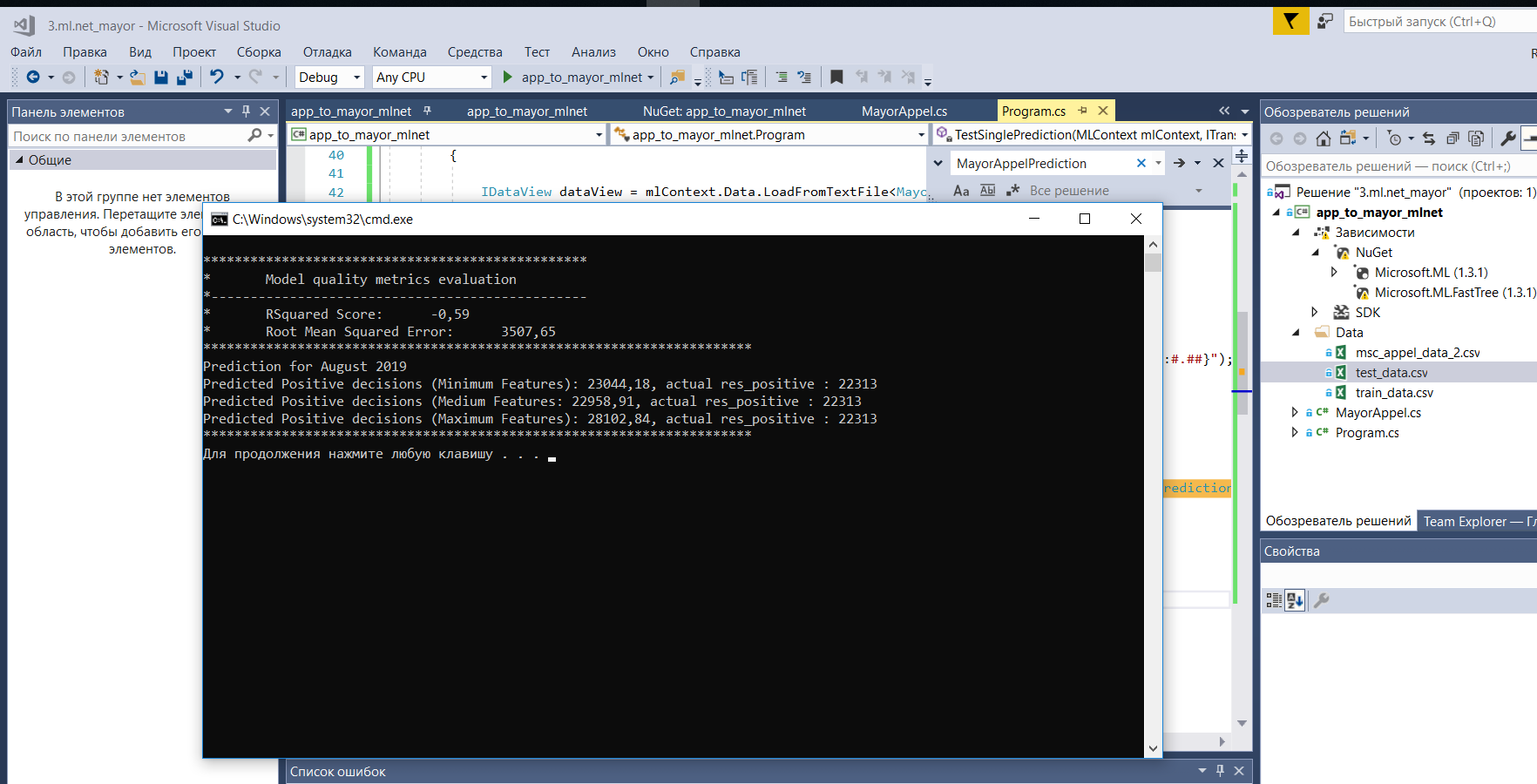
método de predicción y datos private static void TestSinglePrediction(MLContext mlContext, ITransformer model) { var predictionFunction = mlContext.Model.CreatePredictionEngine<MayorAppel, MayorAppelPrediction>(model); var MayorAppelSampleMinData = new MayorAppel() { Year = 2019, Month = "August", ResPositive = 0 }; var MayorAppelSampleMediumData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, ResPositive = 0 }; var MayorAppelSampleMaxData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, To10KTotalVAO = 67, To10KMayorVAO = 13, To10KTotalZAO = 57, To10KMayorZAO = 13, To10KTotalZelAO = 49, To10KMayorZelAO = 9, To10KTotalSAO = 71, To10KMayorSAO = 14, To10KTotalSVAO = 86, To10KMayorSVAO = 27, To10KTotalSZAO = 68, To10KMayorSZAO = 12, To10KTotalTiNAO = 93, To10KMayorTiNAO = 36, To10KTotalCAO = 104, To10KMayorCAO = 24, To10KTotalYUAO = 56, To10KMayorYUAO = 12, To10KTotalYUVAO = 59, To10KMayorYUVAO = 13, To10KTotalYUZAO = 78, To10KMayorYUZAO = 23, ResPositive = 0 }; var predictionMin = predictionFunction.Predict(MayorAppelSampleMinData); var predictionMed = predictionFunction.Predict(MayorAppelSampleMediumData); var predictionMax = predictionFunction.Predict(MayorAppelSampleMaxData); Console.WriteLine($"**********************************************************************"); Console.WriteLine($"Prediction for August 2019"); Console.WriteLine($"Predicted Positive decisions (Minimum Features): {predictionMin.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Medium Features: {predictionMed.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Maximum Features): {predictionMax.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"**********************************************************************"); }
En el ejemplo, utilizamos la clase PredictionEngine, que nos permite obtener una única predicción basada en el modelo entrenado y el conjunto de datos de prueba.
Crearemos tres "sondas" con datos para la predicción.
El primero con un conjunto mínimo de datos (solo un mes y un año), el segundo con un promedio y el tercero con un conjunto completo de atributos, respectivamente.
Obtenemos tres predicciones diferentes y las imprimimos.
Como puede ver en la captura de pantalla (Windows 10 x64), agregar datos sobre la cantidad de llamadas por cada 10,000 residentes en los distritos, en este caso, solo arruina todo, pero agregar el resto de los datos aumenta la precisión de la predicción.
Bajo Linux, Mint 19 también se compila maravillosamente en Mono.
Resulta que el marco es bastante multiplataforma.
En conclusión, como prometí, haré un pequeño análisis comparativo subjetivo de ML.NET con las bibliotecas de aprendizaje automático Accord.NET y Python.
1. Se cree que los desarrolladores están tratando de cumplir con las tendencias en el campo del aprendizaje automático. Por supuesto, en
Python con un montón de bibliotecas instaladas en Anaconda, esta tarea podría resolverse de manera más compacta y dedicar menos tiempo al desarrollo. Pero en general, me parece que el enfoque para resolver problemas con ML.NET es amigable para las personas que están acostumbradas a resolver problemas de aprendizaje automático utilizando Python.
2. En comparación con el
Marco Accord.NET , ML.NET parece más conveniente y prometedor para una persona que ha intentado el aprendizaje automático en Python. Recuerdo que cuando intenté escribir algo en Accord.NET hace dos años, me faltaban terriblemente explicaciones y ejemplos para algunas clases y métodos. En este sentido, a Ml.NET con documentación le está yendo un poco mejor, a pesar de que el marco es mucho más joven que Accord.NET. Otro factor importante es que ML.NET, a juzgar por la actividad en GitHub, se está desarrollando mucho más intensamente que Accord.NET y tiene más materiales de capacitación en ruso.
Como resultado, a primera vista, ML.NET parece una herramienta conveniente que
complementa su arsenal si no puede usar Python o R (por ejemplo, cuando trabaja con API CAD ejecutadas en .NET).
¡Que tengas una buena semana laboral!