En 2015, escribí sobre las herramientas que proporciona Ruby para
detectar fugas de memoria administrada . En su mayoría, el artículo hablaba de fugas fácilmente manejables. Esta vez hablaré sobre herramientas y trucos que puedes usar para eliminar fugas que no son tan fáciles de analizar en Ruby. En particular, hablaré sobre mwrap, heaptrack, iseq_collector y chap.
Pérdidas de memoria no administradas
Este pequeño programa provoca una fuga con una llamada directa a malloc. Comienza con un consumo de 16 MB de RSS y termina con 118 MB. El código coloca en la memoria 100 mil bloques de 1024 bytes y elimina 50 mil de ellos.
require 'fiddle' require 'objspace' def usage rss = `ps -p
Aunque RSS es de 118 MB, nuestro objeto Ruby solo tiene en cuenta tres megabytes. En el análisis, vemos solo una parte muy pequeña de esta pérdida de memoria muy grande.
Oleg Dashevsky describe un ejemplo real de tal fuga. Recomiendo leer este maravilloso artículo.
Aplicar Mwrap
Mwrap es un generador de perfiles de memoria para Ruby que monitorea todas las asignaciones de datos en la memoria al interceptar malloc y otras funciones de esta familia. Intercepta llamadas a ese lugar y libera memoria usando
LD_PRELOAD . Utiliza
liburcu para contar y puede rastrear contadores de asignación y eliminación para cada punto de llamada, en código C y Ruby. Mwrap es de tamaño pequeño, aproximadamente el doble de grande que RSS para un programa perfilado, y aproximadamente el doble de lento.
Se diferencia de muchas otras bibliotecas en su tamaño muy pequeño y soporte de Ruby. Rastrea ubicaciones en archivos Ruby y no se limita a valgrind + masif backtracks de nivel C y perfiladores similares. Esto simplifica enormemente el aislamiento de las fuentes de problemas.
Para usar el generador de perfiles, debe ejecutar la aplicación a través del shell Mwrap, implementará el entorno LD_PRELOAD y ejecutará el binario Ruby.
Agreguemos Mwrap a nuestro script:
require 'mwrap' def report_leaks results = [] Mwrap.each do |location, total, allocations, frees, age_total, max_lifespan| results << [location, ((total / allocations.to_f) * (allocations - frees)), allocations, frees] end results.sort! do |(_, growth_a), (_, growth_b)| growth_b <=> growth_a end results[0..20].each do |location, growth, allocations, frees| next if growth == 0 puts "#{location} growth: #{growth.to_i} allocs/frees (#{allocations}/#{frees})" end end GC.start Mwrap.clear leak_memory GC.start
Ahora ejecute el script con el contenedor Mwrap:
% gem install mwrap % mwrap ruby leak.rb leak.rb:12 growth: 51200000 allocs/frees (100000/50000) leak.rb:51 growth: 4008 allocs/frees (1/0)
Mwrap detectó correctamente una fuga en el script (50,000 * 1024). Y no solo se determinó, sino que también se aisló una línea específica (
i = Fiddle.malloc(1024) ), lo que provocó una fuga. El generador de perfiles lo vinculó correctamente a las llamadas a
Fiddle.free .
Es importante tener en cuenta que estamos tratando con una evaluación. Mwrap monitorea la memoria compartida asignada por el par de marcado y luego monitorea la memoria libre. Pero si tiene un punto de llamada que asigna bloques de memoria de diferentes tamaños, el resultado será inexacto. Tenemos acceso a la evaluación:
((total / allocations) * (allocations - frees))Además, para simplificar el seguimiento de fugas, Mwrap rastrea
age_total , que es la suma de la vida útil de cada objeto liberado, y también rastrea
max_lifespan , la vida útil del objeto más antiguo en el punto de llamada. Si
age_total / frees grande, el consumo de memoria aumenta a pesar de las numerosas recolecciones de basura.
Mwrap tiene varios ayudantes para reducir el ruido.
Mwrap.clear borrará todo el almacenamiento interno.
Mwrap.quiet {} obligará a Mwrap a rastrear el bloque de código.
Otra característica distintiva de Mwrap es el seguimiento del número total de bytes asignados y liberados. Elimine
clear del script y ejecútelo:
usage puts "Tracked size: #{(Mwrap.total_bytes_allocated - Mwrap.total_bytes_freed) / 1024}"
El resultado es muy interesante, porque a pesar del tamaño RSS de 130 MB, Mwrap solo ve 91 MB. Esto sugiere que hemos inflado nuestro proceso. La ejecución sin Mwrap muestra que en una situación normal el proceso toma 118 MB, y en este caso simple la diferencia fue de 12 MB. El patrón de asignación / liberación condujo a la fragmentación. Este conocimiento puede ser muy útil, en algunos casos, los procesos glibc malloc no configurados fragmentan tanto que la gran cantidad de memoria utilizada en RSS es realmente libre.
¿Puede Mwrap aislar una fuga de alfombra roja vieja?
En
su artículo, Oleg analiza una forma muy completa de aislar una fuga muy delgada en la alfombra roja. Hay muchos detalles Es muy importante tomar medidas. Si no está creando una línea de tiempo para el proceso RSS, es poco probable que pueda deshacerse de las fugas.
Entremos en una máquina del tiempo y demostremos lo fácil que es usar Mwrap para tales fugas.
def red_carpet_leak 100_000.times do markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML, extensions = {}) markdown.render("hi") end end GC.start Mwrap.clear red_carpet_leak GC.start
Redcarpet 3.3.2:
redcarpet.rb:51 growth: 22724224 allocs/frees (500048/400028) redcarpet.rb:62 growth: 4008 allocs/frees (1/0) redcarpet.rb:52 growth: 634 allocs/frees (600007/600000)
Redcarpet 3.5.0:
redcarpet.rb:51 growth: 4433 allocs/frees (600045/600022) redcarpet.rb:52 growth: 453 allocs/frees (600005/600000)
Si puede darse el lujo de ejecutar el proceso a la mitad de la velocidad simplemente reiniciándolo en el producto Mwrap con el registro del resultado en un archivo, entonces puede identificar una amplia gama de pérdidas de memoria.
Fuga misteriosa
Recientemente, Rails se actualizó a la versión 6. En general, la experiencia fue muy positiva, el rendimiento se mantuvo aproximadamente igual. Rails 6 tiene algunas características muy buenas que usaremos (por ejemplo,
Zeitwerk ). Los rieles cambiaron la forma en que se representaron las plantillas, lo que requirió algunos cambios para la compatibilidad. Unos días después de la actualización, notamos un aumento en RSS para el ejecutante de tareas de Sidekiq.
Mwrap informó un fuerte aumento en el consumo de memoria debido a su asignación (
enlace ):
source.encode!
Al principio estábamos muy perplejos. Estábamos tratando de entender por qué no estamos satisfechos con Mwrap? Tal vez se rompió? A medida que el consumo de memoria creció, los montones en Ruby se mantuvieron sin cambios.
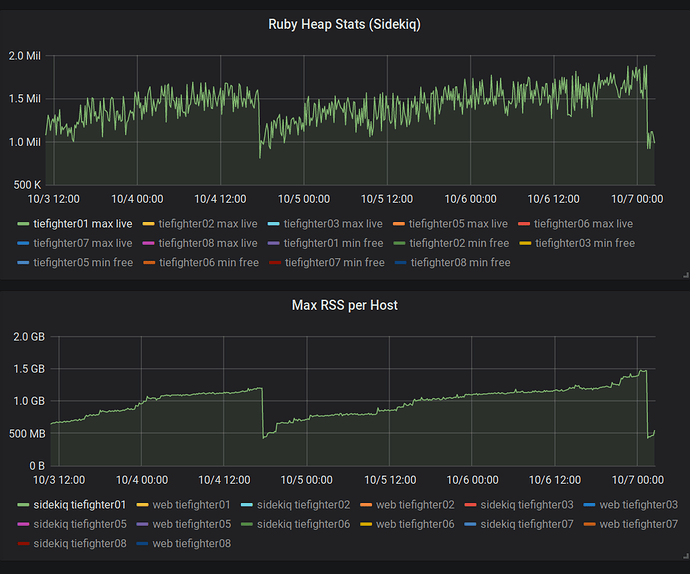
Dos millones de ranuras en el montón consumieron solo 78 MB (40 bytes por ranura). Las líneas y las matrices pueden ocupar más espacio, pero aún así no explicaron el consumo anormal de memoria que observamos. Esto se confirmó cuando
rbtrace -p SIDEKIQ_PID -e ObjectSpace.memsize_of_all .
¿A dónde fue el recuerdo?
Heaptrack
Heaptrack es un generador de perfiles de memoria de almacenamiento dinámico para Linux.
Milian Wolff
explicó perfectamente cómo funciona el perfilador y habló sobre ello en varios discursos (
1 ,
2 ,
3 ). De hecho, es un generador de perfiles de montón nativo muy eficiente que, con la ayuda de
libunwind, recopila las trazas de las aplicaciones perfiladas. Funciona notablemente más rápido que
Valgrind / Massif y tiene la capacidad de hacerlo mucho más conveniente para la creación de perfiles temporales en el producto. ¡Se puede adjuntar a un proceso ya en ejecución!
Al igual que con la mayoría de los perfiladores de montón, al llamar a todas las funciones de la familia malloc, Heaptrack debe contar. Este procedimiento definitivamente ralentiza un poco el proceso.
En mi opinión, la arquitectura aquí es la mejor de todas. La intercepción se realiza utilizando
LD_PRELOAD o
GDB para cargar el generador de perfiles. Usando un
archivo FIFO especial, transfiere datos del proceso perfilado lo más rápido posible. El contenedor
heaptrack es un script de shell simple que facilita la búsqueda de un problema. El segundo proceso lee información de FIFO y comprime sobre la marcha los datos de seguimiento. Dado que Heaptrack funciona con "fragmentos", puede analizar el perfil solo unos segundos después del inicio de la creación de perfiles, justo en el medio de la sesión. Simplemente copie el archivo de perfil en otra ubicación e inicie la GUI de Heaptrack.
Este
boleto de GitLab me habló sobre la posibilidad misma de lanzar Heaptrack. Si podían ejecutarlo, entonces yo puedo.
Nuestra aplicación se ejecuta en un contenedor, y necesito reiniciarla con
--cap-add=SYS_PTRACE , esto permite que GDB use
ptrace , que es necesario para que Heaptrack se inyecte. También necesito un
pequeño truco para que el archivo de shell aplique
root al perfil del proceso no
root (lanzamos nuestra aplicación Discourse en el contenedor con una cuenta limitada).
Una vez hecho todo, solo queda ejecutar
heaptrack -p PID y esperar a que aparezcan los resultados. Heaptrack resultó ser una excelente herramienta, fue muy fácil rastrear todo lo que sucede con pérdidas de memoria.
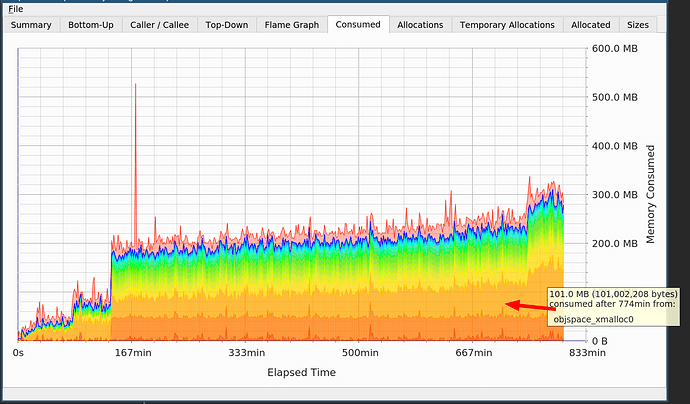
En el gráfico, ve dos saltos, uno debido a
cppjieba , el otro debido a
objspace_xmalloc0 en Ruby.
Sabía sobre
cppjieba . La segmentación del idioma chino es costosa, necesita grandes diccionarios, por lo que esto no es una fuga. Pero ¿qué pasa con la asignación de memoria en Ruby, que todavía no me dice eso?
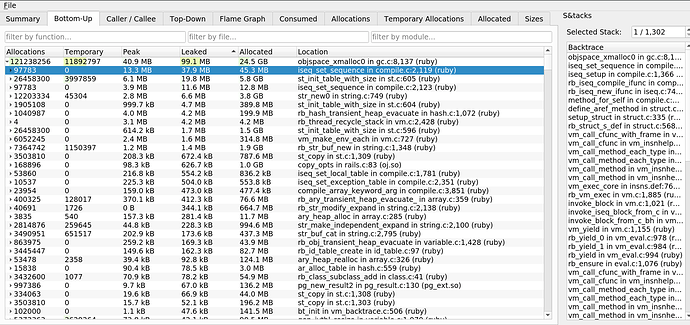
La ganancia principal está relacionada con
iseq_set_sequence en
compile.c . Resulta que la fuga se debe a secuencias de instrucciones. Esto aclaró la fuga descubierta por Mwrap. Su causa fue
mod.module_eval(source, identifier, 0) , que creó secuencias de instrucciones que no se eliminaron de la memoria.
Si, en un análisis retrospectivo, considerara cuidadosamente un volcado de pila de Ruby, entonces habría notado todos estos IMEMO, ya que están incluidos en este volcado. Son simplemente invisibles durante el diagnóstico en proceso.
A partir de este momento, la depuración fue bastante simple. Seguí todas las llamadas al módulo eval y volqué lo que evaluó. Descubrí que estamos agregando métodos a una clase grande una y otra vez. Aquí hay una vista simplificada del error que encontramos:
require 'securerandom' module BigModule; end def leak_methods 10_000.times do method = "def _#{SecureRandom.hex}; #{"sleep;" * 100}; end" BigModule.module_eval(method) end end usage # RSS: 16164 ObjectSpace size 2869 leak_methods usage
Ruby tiene una clase para almacenar secuencias de instrucciones
RubyVM::InstructionSequence :
RubyVM::InstructionSequence . Sin embargo, Ruby es demasiado vago para crear estos objetos envolventes, porque almacenarlos innecesariamente es ineficiente. Koichi
Sasada creó la dependencia
iseq_collector . Si agregamos este código, podemos encontrar nuestra memoria oculta:
require 'iseq_collector' puts "#{ObjectSpace.memsize_of_all_iseq / 1024}"
materializa cada secuencia de instrucciones, lo que puede aumentar ligeramente el consumo de memoria del proceso y darle al recolector de basura un poco más de trabajo.
Si, por ejemplo, calculamos el número de ISEQ antes y después de iniciar el recopilador, veremos que después de iniciar
ObjectSpace.memsize_of_all_iseq nuestro contador de la clase
RubyVM::InstructionSequence aumentará de 0 a 11128 (en este ejemplo):
def count_iseqs ObjectSpace.each_object(RubyVM::InstructionSequence).count end
Estos envoltorios permanecerán durante toda la vida del método, deberán ser visitados con un recorrido completo del recolector de basura. Nuestro problema se resolvió reutilizando la clase responsable de representar las plantillas de correo electrónico (
hotfix 1 ,
hotfix 2 ).
cap
Durante la depuración, utilicé una herramienta muy interesante. Hace unos años, Tim Boddy sacó una herramienta interna utilizada por VMWare para analizar las pérdidas de memoria e hizo que su código se abriera. Aquí está el único video sobre esto que pude encontrar:
https://www.youtube.com/watch?v=EZ2n3kGtVDk . A diferencia de la mayoría de las herramientas similares, esta no tiene ningún efecto en el proceso ejecutable. Simplemente se puede aplicar a los archivos del volcado principal, mientras que glibc se usa como un asignador (no hay soporte para jemalloc / tcmalloc, etc.).
Con chap, es muy fácil detectar la fuga que tuve. Pocas distribuciones tienen un cap binario, pero puede
compilarlo fácilmente
desde el código fuente . Él es muy activamente apoyado.
# 444098 is the `Process.pid` of the leaking process I had sudo gcore -p 444098 chap core.444098 chap> summarize leaked Unsigned allocations have 49974 instances taking 0x312f1b0(51,573,168) bytes. Unsigned allocations of size 0x408 have 49974 instances taking 0x312f1b0(51,573,168) bytes. 49974 allocations use 0x312f1b0 (51,573,168) bytes. chap> list leaked ... Used allocation at 562ca267cdb0 of size 408 Used allocation at 562ca267d1c0 of size 408 Used allocation at 562ca267d5d0 of size 408 ... chap> summarize anchored .... Signature 7fbe5caa0500 has 1 instances taking 0xc8(200) bytes. 23916 allocations use 0x2ad7500 (44,922,112) bytes.
Chap puede usar firmas para buscar ubicaciones de memoria diferente, y puede complementar GDB. Al depurar en Ruby, puede ser de gran ayuda para determinar qué memoria está usando el proceso. Muestra la memoria total utilizada, a veces glibc malloc puede fragmentarse tanto que el volumen utilizado puede ser muy diferente del RSS real. Puede leer la discusión:
Característica # 14759: [PATCH] estableció M_ARENA_MAX para glibc malloc - Ruby master - Ruby Issue Issue Tracking System . Chap puede contar correctamente toda la memoria utilizada y proporcionar un análisis en profundidad de su asignación.
Además, chap puede integrarse en flujos de trabajo para detectar automáticamente fugas y marcar dichos ensamblajes.
Trabajo de seguimiento
Esta ronda de depuración me hizo plantear algunas preguntas relacionadas con nuestros kits de herramientas de ayuda:
Resumen
¡Nuestro kit de herramientas de hoy para depurar fugas de memoria muy complejas es mucho mejor de lo que era hace 4 años! Mwrap, Heaptrack y chap son herramientas muy poderosas para resolver problemas de memoria que surgen durante el desarrollo y la operación.
Si está buscando una pérdida de memoria simple en Ruby, le recomiendo leer
mi artículo de 2015 , en su mayor parte es relevante.
Espero que le resulte más fácil la próxima vez que comience a depurar una pérdida de memoria nativa compleja.