
Hola Mi nombre es Askhat Nuryev, soy un ingeniero de automatización líder en DINS.
He estado trabajando en Dino Systems durante los últimos 7 años. Durante este tiempo, tuve que lidiar con varias tareas: desde escribir pruebas funcionales automatizadas hasta probar el rendimiento y la alta disponibilidad. Gradualmente, me involucré más en organizar pruebas y optimizar procesos en general.
En este artículo te diré:
- ¿Qué pasa si los errores ya se han filtrado a la producción?
- ¿Cómo competir por la calidad del sistema, si no puede contar los errores con las manos y no revisa los ojos?
- ¿Cuáles son las dificultades en el manejo automático de errores?
- ¿Qué bonificaciones puedo obtener al analizar las estadísticas de consultas?
DINS es el centro de desarrollo de RingCentral, un líder del mercado entre los proveedores de nube de Comunicaciones Unificadas. Ringentral ofrece todo para las comunicaciones comerciales, desde telefonía clásica, SMS, reuniones hasta la funcionalidad de centros de contacto y productos para trabajo en equipo complejo (a la Slack). Esta solución en la nube se encuentra en sus propios centros de datos, y el cliente solo necesita suscribirse al sitio.
El sistema, en cuyo desarrollo participamos, atiende a 2 millones de usuarios activos y procesa más de 275 millones de solicitudes por día. El equipo en el que estoy trabajando está desarrollando la API.
El sistema tiene una API bastante complicada. Con él, puede enviar SMS, realizar llamadas, recopilar videoconferencias, configurar cuentas e incluso enviar faxes (hola, 2019). De forma simplificada, el esquema de interacción de servicios se parece a esto. No estoy bromeando

Está claro que un sistema tan complejo y altamente cargado crea una gran cantidad de errores. Por ejemplo, hace un año recibimos decenas de miles de errores por semana. Estas son milésimas de porcentaje en relación con el número total de solicitudes, pero aún así muchos errores son un desastre. Los detectamos gracias al servicio de soporte desarrollado, sin embargo, estos errores afectan a los usuarios. Además, el sistema está en constante evolución, el número de clientes está creciendo. Y la cantidad de errores también.
Primero, tratamos de resolver el problema de una manera clásica.
Nos reunimos, pedimos registros de producción, corregimos algo, olvidamos algo, creamos tableros en Kibana y Sumologic. Pero en general no ayudó. Los errores se filtraron de todos modos, los usuarios se quejaron. Quedó claro que algo iba mal.
Automatización
Por supuesto, comenzamos a comprender y vimos que el 90% del tiempo que se dedica a corregir el error se dedica a recopilar información sobre él. Esto es lo que exactamente:
- Obtenga la información que falta de otros departamentos.
- Examinar los registros del servidor.
- Investigue el comportamiento de nuestro sistema.
- Comprenda si este o aquel comportamiento del sistema es erróneo.
Y solo el 10% restante lo gastamos directamente en desarrollo.
Pensamos, pero ¿qué pasa si hacemos un sistema que encuentra errores, les da prioridad y muestra todos los datos necesarios para solucionarlo?
Debo decir que la idea misma de tal servicio causó algunas preocupaciones.
Alguien dijo: "Si encontramos todos los errores nosotros mismos, ¿por qué necesitamos control de calidad?"
Otros dijeron lo contrario: "¡Te ahogarás en este montón de insectos!".
En una palabra, valía la pena hacer un servicio aunque solo fuera para entender cuál de ellos es el correcto.
spoiler(ambos grupos de escépticos se equivocaron)
Soluciones confeccionadas
En primer lugar, decidimos ver cuáles de los sistemas similares ya están en el mercado. Resultó que hay muchos de ellos. Puede resaltar Raygun, Sentry, Airbrake, hay otros servicios.
Pero ninguno de ellos nos convenía, y he aquí por qué:
- Algunos servicios nos obligaron a realizar cambios demasiado grandes en la infraestructura existente, incluidos los cambios en el servidor. Airbrake.io tendría que refinar docenas, cientos de componentes del sistema.
- Otros recopilaron datos sobre nuestros propios errores y los enviaron a un lado. Nuestra política de seguridad no permite esto: los datos de usuario y error deben permanecer con nosotros.
- Bueno, también son bastante caros.
Hacemos nuestro
Se hizo evidente que deberíamos hacer nuestro servicio, especialmente porque ya habíamos construido una infraestructura muy buena para ello:
- Todos los servicios ya han escrito registros en un único repositorio: Elastic. En los registros se arrojaron identificadores uniformes de las solicitudes a través de todos los servicios.
- Las estadísticas de rendimiento también se registraron en Hadoop. Trabajamos con registros utilizando Impala y Metabase.
De todos los errores del servidor (de
acuerdo con la clasificación de los códigos de estado HTTP ), el código 500 es el más prometedor en términos de análisis de errores. En respuesta a los errores 502, 503 y 504, en algunos casos simplemente puede repetir la solicitud después de un tiempo sin siquiera mostrar la respuesta al usuario. Y de acuerdo con las recomendaciones de la API de la Plataforma RC, los usuarios deben contactar al soporte técnico si reciben el código de estado 500 en respuesta a una llamada.
La primera versión del sistema recopiló registros de ejecución de consultas, todos los rastros de pila que surgieron, datos de usuario y colocaron el error en el rastreador, en nuestro caso fue JIRA.
Justo después de la ejecución de la prueba, notamos que el sistema crea un número significativo de errores duplicados. Sin embargo, entre estos duplicados, muchos tenían casi los mismos rastros de pila.
Era necesario cambiar el método para identificar los mismos errores. A partir del análisis de datos puramente estadísticos, proceda a encontrar la causa raíz del error. Las trazas de pila caracterizan bien el problema, pero son bastante difíciles de comparar entre sí: los números de línea cambian de una versión a otra, los datos del usuario y otros ruidos entran en ellos. Además, no siempre entran en el registro; para algunas solicitudes descartadas, simplemente no existen.
En su forma más pura, los seguimientos de pila son inconvenientes para el seguimiento de errores.
Era necesario seleccionar patrones, plantillas de trazas de pila y borrarlos de la información que a menudo cambiaba. Después de una serie de experimentos, decidimos usar expresiones regulares para borrar los datos.
Como resultado, lanzamos una nueva versión, en la que se identificaron errores mediante estas plantillas únicas, si los seguimientos de pila estaban disponibles. Y si no estaban disponibles, entonces de la manera anterior, por el método http y el grupo API.
Y después de eso prácticamente no hubo duplicados. Sin embargo, se encontraron muchos errores únicos.
El siguiente paso es comprender cómo priorizar los errores, cuáles de ellos deben repararse antes. Priorizamos por:
- La frecuencia del error.
- El número de usuarios que le preocupan.
Según las estadísticas recopiladas, comenzamos a publicar informes semanales. Se ven así:
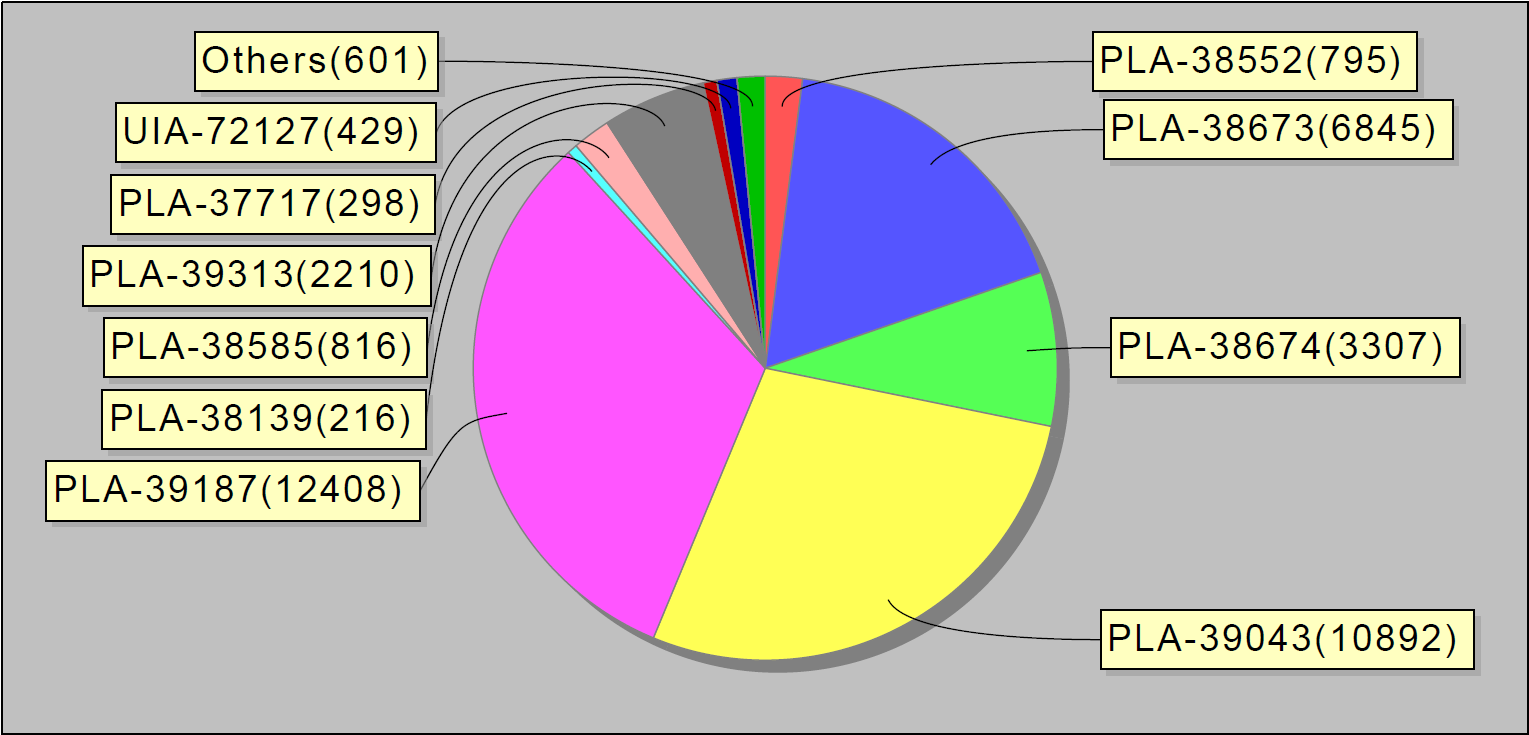
O, por ejemplo, los 10 errores principales por semana. Curiosamente, estos 10 errores en jira representaron el 90% de los errores de servicio:
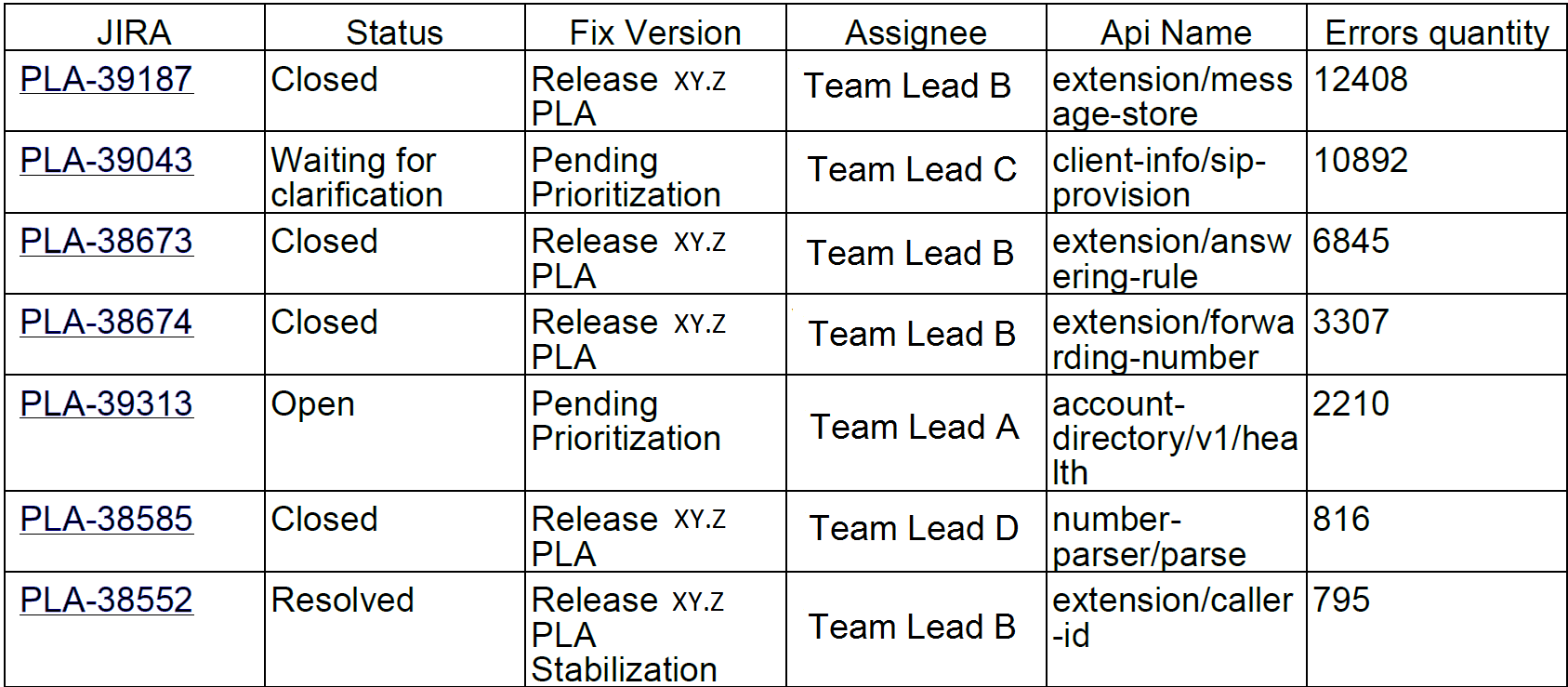
Enviamos dichos informes a desarrolladores y líderes de equipo.
Un par de meses después de que lanzamos el sistema, la cantidad de problemas disminuyó notablemente. Incluso nuestro pequeño MVP (producto mínimamente viable) ayudó a resolver mejor los errores.
El problema
Quizás nos detendríamos aquí, si no fuera por un accidente.
Una vez que vine a trabajar y noté que el sistema repara los errores como los hot cakes: uno por uno. Después de una breve investigación, quedó claro que docenas de estos errores provenían de un servicio. Para averiguar cuál es el problema, fui a la sala de chat del equipo de implementación. Había muchachos involucrados en la instalación de nuevas versiones de servicios en producción y en asegurarse de que funcionaran como se esperaba.
Le pregunté: "Chicos, ¿qué pasó con este servicio?".
Y ellos responden: "Hace una hora instalamos una nueva versión allí".
Paso a paso, identificamos el problema y encontramos una solución temporal, en otras palabras, reiniciamos el servidor.
Quedó claro que el sistema "erróneo" es necesario no solo por los desarrolladores e ingenieros responsables de la calidad. Los ingenieros que son responsables del estado de los servidores en producción, así como los chicos que instalan nuevas versiones en los servidores, también están interesados en ello. El servicio que estamos desarrollando mostrará exactamente qué errores ocurren en la producción durante los cambios del sistema, como la instalación de servidores, la aplicación de una nueva configuración, etc.
Y decidimos hacer otra iteración de desarrollo.
En el proceso de manejo de errores, agregamos un registro de estadísticas de reproducción de problemas a la base de datos y paneles en Grafana. Así es como se ve la distribución gráfica de errores por día en todo el sistema:

Y así, errores en servicios individuales.

También atornillamos disparadores con escalamientos a los equipos de ingeniería responsables, en caso de que haya muchos errores. También configuramos la recopilación de datos una vez cada 30 minutos (en lugar de una vez al día, como antes).
El proceso de nuestro sistema comenzó a verse así:
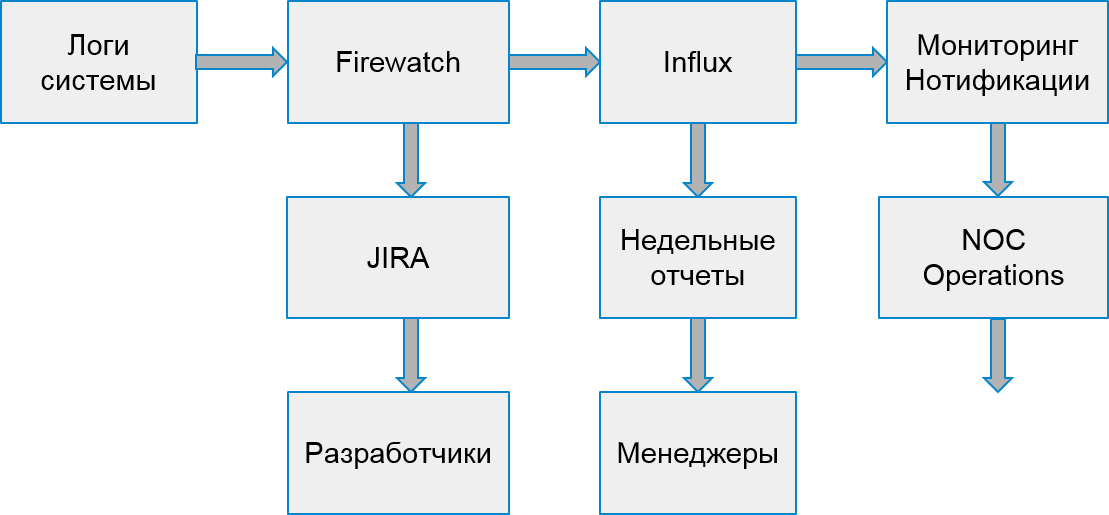
Errores del cliente
Sin embargo, los usuarios no solo sufrieron errores del servidor. También sucedió que el error ocurrió debido a la implementación de aplicaciones cliente.
Para manejar los errores del cliente, decidimos construir otro proceso de búsqueda y análisis. Para hacer esto, elegimos 2 tipos de errores que afectan a las empresas: errores de autorización y errores de limitación.
El estrangulamiento es una forma de proteger el sistema contra sobrecargas. Si la aplicación o el usuario excede su cuota de solicitud, el sistema devuelve un código de error 429 y un encabezado Retry-After, el valor del encabezado indica el tiempo después del cual la solicitud debe repetirse para una ejecución exitosa.
Las aplicaciones pueden permanecer limitadas indefinidamente si dejan de enviar nuevas solicitudes. Los usuarios finales no pueden distinguir estos errores de otros. Como resultado, esto causa quejas al servicio de soporte.
Afortunadamente, la infraestructura y el sistema de estadísticas permiten rastrear incluso los errores del cliente. Podemos hacer esto porque los desarrolladores de aplicaciones que usan nuestra API deben registrarse previamente y recibir su clave única. Cada solicitud del cliente debe contener un token de autorización; de lo contrario, el cliente recibirá un error. Usando este token, calculamos la aplicación.
Así es como se ve la supervisión de errores de aceleración. Los picos de error corresponden a los días de semana y los fines de semana; por el contrario, no hay errores:

Del mismo modo que en el caso de errores internos, basados en estadísticas de Hadoop, encontramos aplicaciones sospechosas. Primero, en relación con la cantidad de solicitudes exitosas y la cantidad de solicitudes que se completaron con el código 429. Si recibimos más de la mitad de dichas solicitudes, pensamos que la aplicación no funcionaba correctamente.
Más tarde comenzamos a analizar el comportamiento de aplicaciones individuales con usuarios específicos. Entre las aplicaciones sospechosas, encontramos el dispositivo específico en el que se ejecuta la aplicación y observamos con qué frecuencia ejecuta solicitudes después de recibir el primer error de aceleración. Si la frecuencia de la solicitud no disminuyó, la aplicación no manejó el error como se esperaba.
Parte de las aplicaciones se desarrolló en nuestra empresa. Por lo tanto, pudimos encontrar inmediatamente ingenieros responsables y corregir rápidamente los errores. Y decidimos enviar los errores restantes a un equipo que contactó a desarrolladores externos y los ayudó a corregir su aplicación.
Para cada aplicación, nosotros:
- Creamos una tarea en JIRA.
- Registramos estadísticas en Influx.
- Estamos preparando desencadenantes para la intervención quirúrgica en caso de un fuerte aumento en el número de errores.
El sistema para trabajar con errores del cliente se ve así:
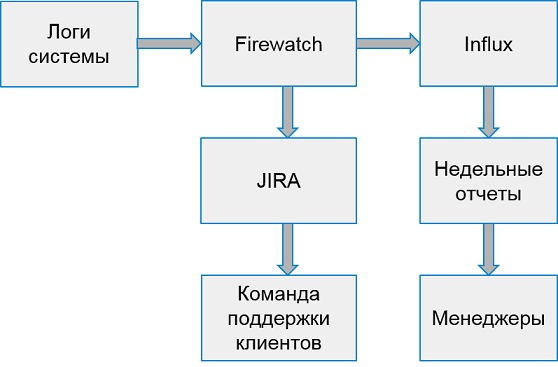
Una vez a la semana recopilamos informes de las 10 peores aplicaciones principales por la cantidad de errores.
No atrapar, pero advertir
Entonces, aprendimos cómo encontrar errores en el sistema de producción, aprendimos a trabajar con los errores del servidor y los errores del cliente. Todo parece estar bien, pero ...
Pero, de hecho, respondemos demasiado tarde: ¡los errores ya afectan a los usuarios!
¿Por qué no tratar de encontrar errores antes?
Por supuesto, sería genial encontrar todo en entornos de prueba. Pero los entornos de prueba son espacios de ruido blanco. Están en desarrollo activo, todos los días funcionan varias versiones diferentes de servidores. Detectar errores centralmente en ellos es demasiado pronto. Hay demasiados errores en ellos, con demasiada frecuencia todo cambia.
Sin embargo, la compañía tiene entornos especiales donde todos los ensambles estables están integrados para verificar el rendimiento, la regresión manual centralizada y las pruebas de alta disponibilidad. Como regla, tales entornos aún no son lo suficientemente estables. Sin embargo, hay equipos interesados en analizar problemas con estos entornos.
Pero hay un obstáculo más: ¡Hadoop no recopila datos de estos entornos! No podemos usar el mismo método para detectar errores; necesitamos buscar una fuente de datos diferente.
Después de una breve búsqueda, decidimos procesar la transmisión de estadísticas, leyendo los datos de la cola en la que nuestros servicios escriben para transferirlos a Hadoop. Fue suficiente para acumular errores únicos y procesarlos en lotes, por ejemplo, una vez cada 30 minutos. Es fácil establecer un sistema de colas que entregue datos; todo lo que quedaba era refinar el recibo y el procesamiento.
Comenzamos a observar cómo se comportan los errores encontrados después de la detección. Resultó que la mayoría de los errores encontrados y no corregidos aparecen más tarde en la producción. Entonces, los encontramos correctamente.
Por lo tanto, creamos un prototipo del sistema, las instituciones y los errores de seguimiento. Ya en su forma actual, le permite mejorar la calidad del sistema, notar y corregir errores antes de que los usuarios se enteren de ellos. Si antes procesábamos decenas de miles de solicitudes erróneas por semana, ahora solo son 2-3 mil. Y los corregimos mucho más rápido.
Que sigue
Por supuesto, no nos detendremos allí y continuaremos mejorando el sistema de búsqueda y seguimiento de errores. Tenemos planes:
- Análisis de más errores de API.
- Integración con pruebas funcionales.
- Funciones adicionales para investigar incidentes en nuestro sistema.
Pero más sobre eso la próxima vez.