Decodificación del informe "Implementación típica de monitoreo" por Nikolay Sivko.
Me llamo Nikolai Sivko. También hago monitoreo. Okmeter es el 5 monitoreo que hago. Decidí que salvaría a todas las personas del infierno de la vigilancia y salvaremos a alguien de este sufrimiento. Siempre trato de no anunciar un okmeter en mis presentaciones. Naturalmente, las fotos serán de allí. Pero la idea de lo que quiero decir es que hacemos que el monitoreo sea un enfoque ligeramente diferente de lo que todos usualmente hacen. Hablamos mucho de esto. Cuando tratamos de convencer a cada persona individual en esto, al final se convence. Quiero hablar sobre nuestro enfoque precisamente para que si usted mismo realiza el monitoreo, evite nuestro rastrillo.

Sobre el Okmeter en pocas palabras. Hacemos lo mismo que usted, pero hay todo tipo de fichas. Chips:
- detalles;
- una gran cantidad de disparadores preconfigurados que se basan en los problemas de nuestros clientes;
- Configuración automática

Un cliente típico viene a nosotros. Él tiene dos tareas:
1) comprender que todo se descompuso de la supervisión, cuando no hay nada en absoluto.
2) arreglarlo rápidamente.
Viene a monitorear las respuestas de lo que le está sucediendo.
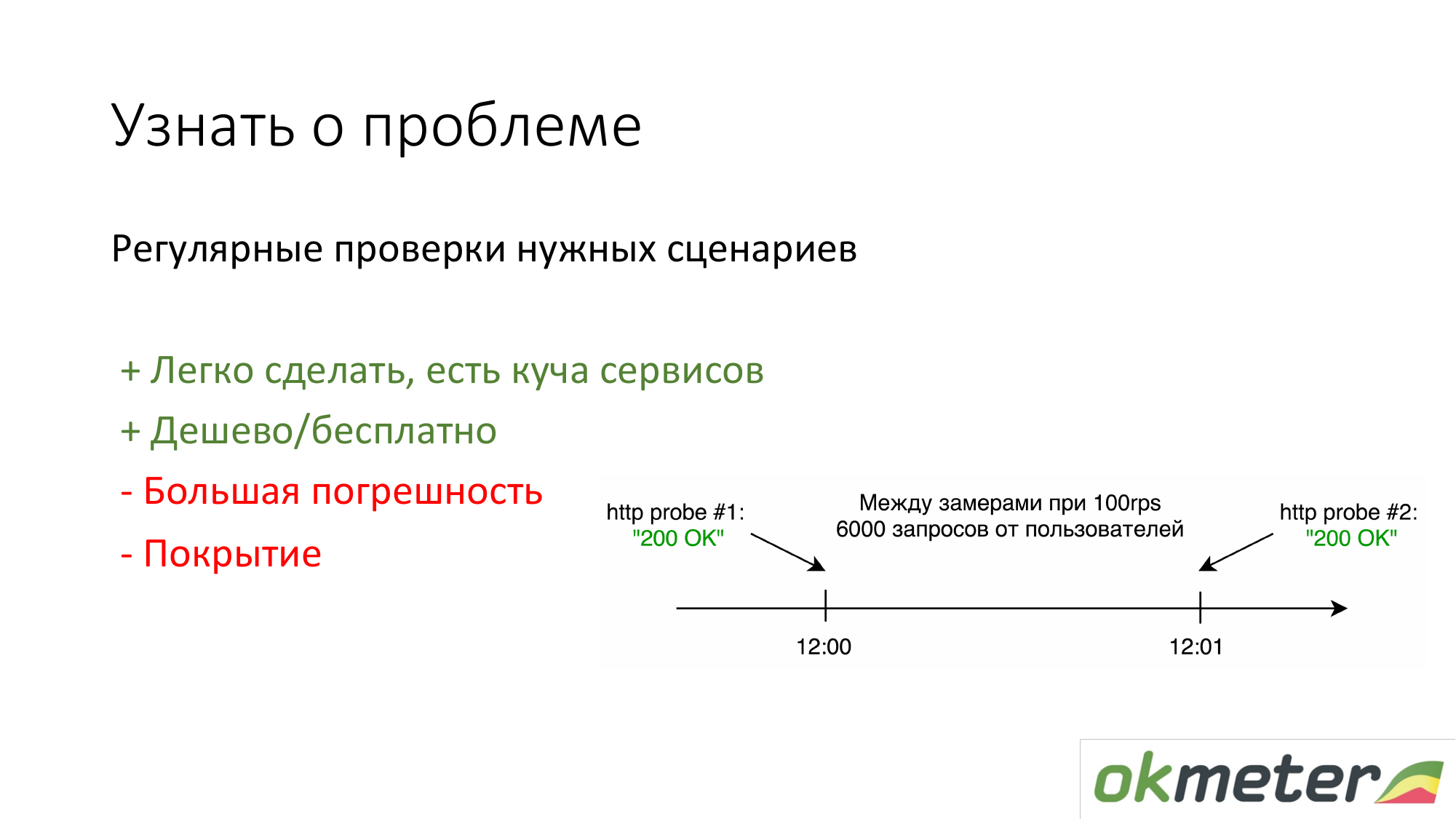
Lo primero que hacen las personas que no tienen nada es poner https://www.pingdom.com/ y otros servicios para su verificación. La ventaja de esta solución es que se puede hacer en 5 minutos. Ya no aprenderá sobre el problema de las llamadas de los clientes. Hay problemas con la precisión para que se salten los problemas. Pero para sitios simples, esto es suficiente.

Lo segundo que recomendamos es contar por los registros de acuerdo con las estadísticas de los usuarios reales. Eso es lo que un usuario en particular obtiene errores 5xx. ¿Cuál es el tiempo de respuesta de los usuarios? Hay desventajas, pero en general, tal cosa funciona.

Acerca de nginx: lo hicimos para que cualquier cliente que venga inmediatamente coloque al agente en la interfaz y todo lo recoja automáticamente, comience a analizarse, comiencen a aparecer errores, etc. No tiene casi nada que configurar.

Pero la mayoría de los clientes no tienen temporizadores en los registros estándar de nginx. Este 90 por ciento de los clientes no quiere saber el tiempo de respuesta de su sitio. Nos enfrentamos a esto todo el tiempo. Es necesario expandir el registro nginx. Luego, fuera de la caja, automáticamente comenzamos a mostrar histogramas fuera de la caja. Este es probablemente un aspecto importante del hecho de que el tiempo debe medirse.

¿Qué estamos sacando de allí? En la práctica, tomamos métricas en tales dimensiones. Estas no son métricas planas. La métrica se llama index.request.rate, el número de consultas por segundo. Se detalla por:
- el host del que eliminó los registros;
- el registro del que se tomaron estos datos;
- http por método;
- estado http;
- estado de caché
Esta NO es cada URL específica con todos los argumentos. No queremos eliminar 100,000 métricas del registro.

Queremos tomar 1000 métricas. Por lo tanto, estamos tratando de normalizar la URL, si es posible. Toma la URL superior. Y para las URL que son significativas, mostramos un gráfico de barras separado, 5xx por separado.

Aquí hay un ejemplo de cómo esta métrica simple se convierte en gráficos utilizables. Este es nuestro DSL en la parte superior. Probé este DSL para explicar la lógica aproximada. Tomamos todas las solicitudes nginx por segundo y las distribuimos en todas las máquinas que tenemos. Conocí cómo lo equilibramos, cuánto tenemos RPS total (solicitud por segundo, solicitudes por segundo).

Por otro lado, podemos filtrar esta métrica y mostrar solo 4xx. En un gráfico 4xx, se pueden diseñar de acuerdo con el estado real. Les recuerdo que esta es la misma métrica.

En el gráfico, puede mostrar 4xx por URL. Esta es la misma métrica.

También disparamos un histograma desde los registros. Un histograma es la métrica response_time.histrogram, que en realidad es RPS con un parámetro de nivel adicional. Esto es solo un límite de tiempo en el que se obtiene la solicitud.
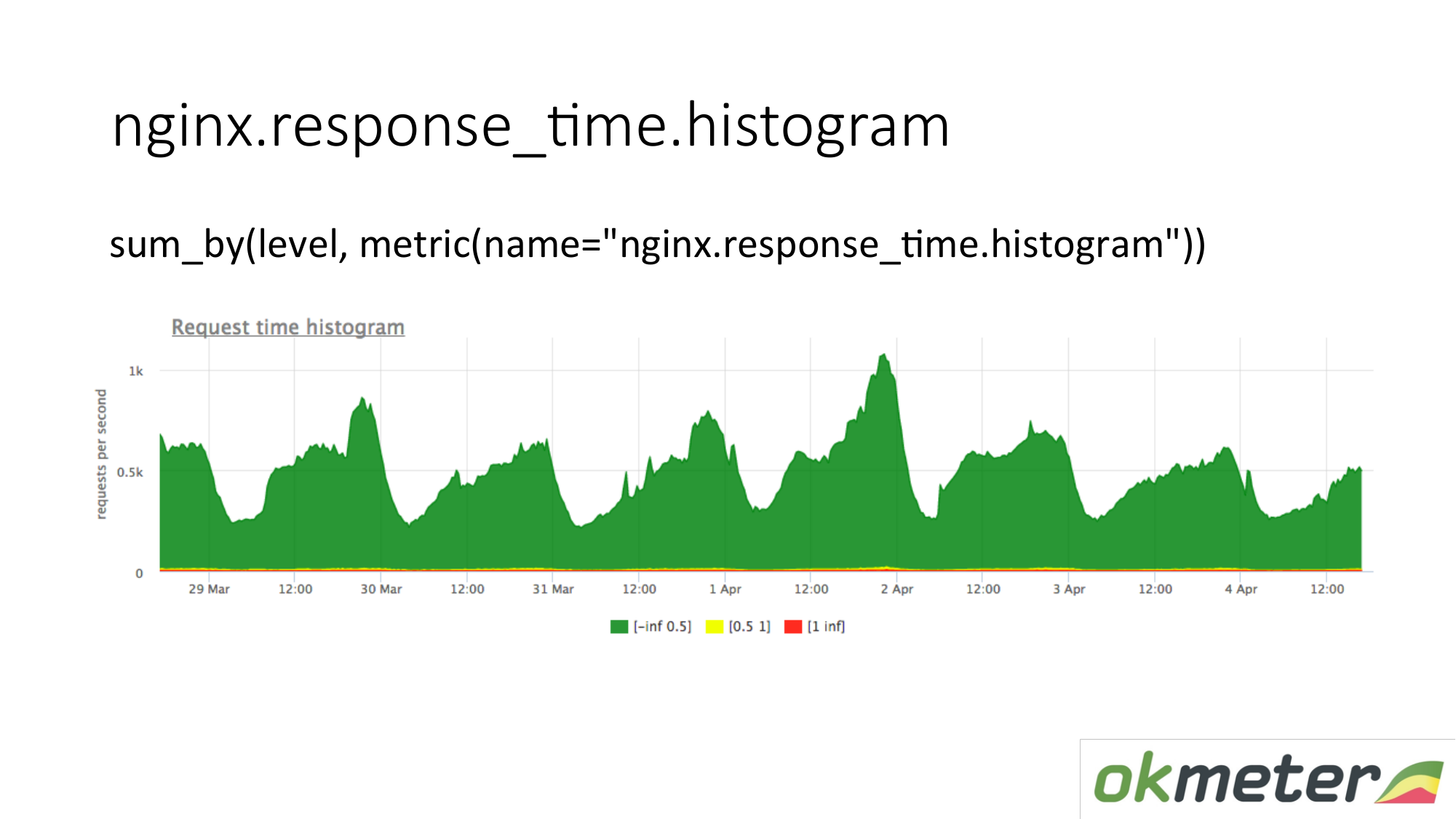
Dibujamos una solicitud: resuma todo el histograma y ordénelo en niveles:
- Solicitudes lentas
- solicitudes rápidas;
- consultas promedio;
Tenemos una imagen que ya ha sido resumida por los servidores. La métrica es la misma. Su significado físico es comprensible. Pero lo aprovechamos de maneras completamente diferentes.
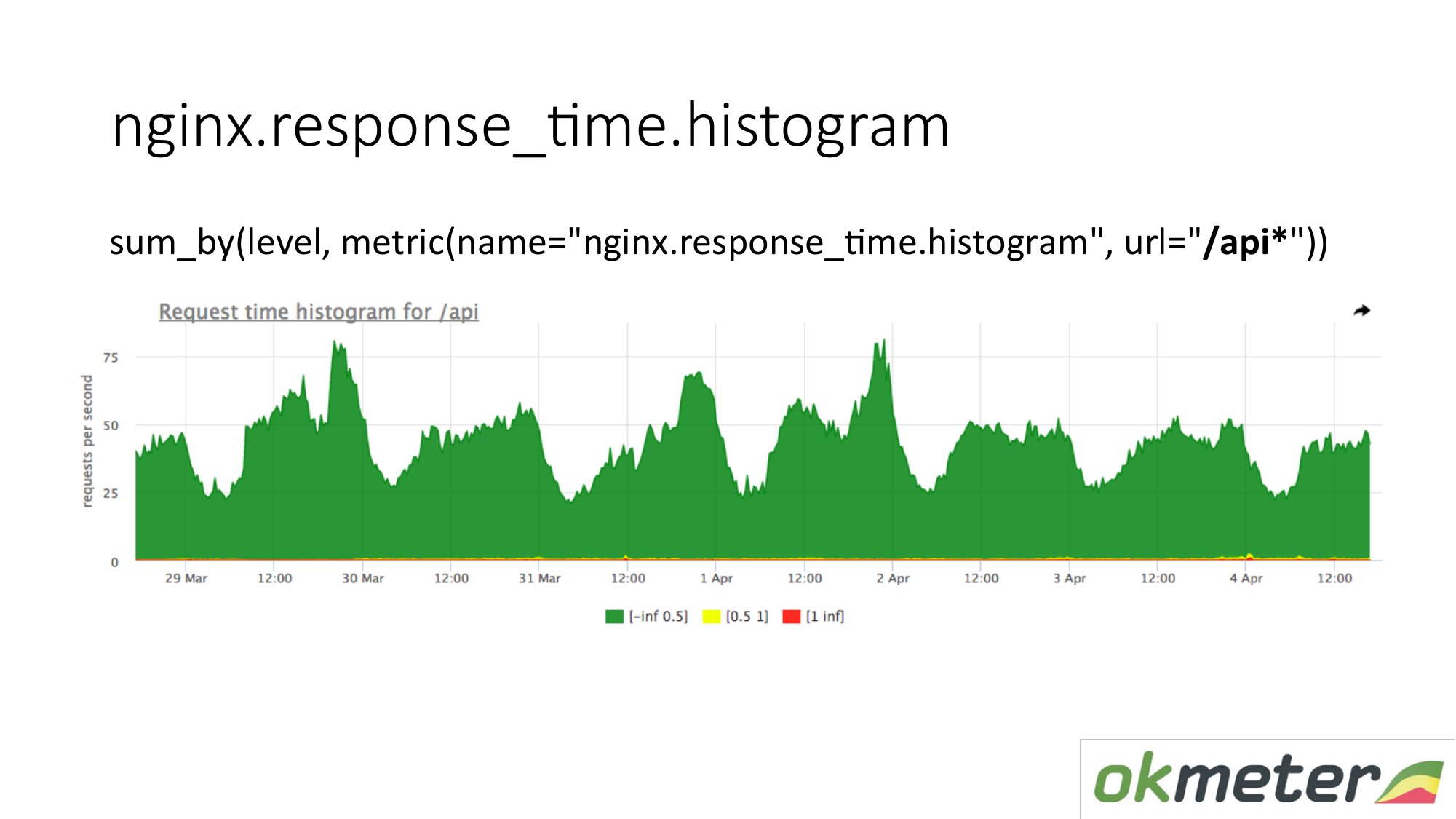
En el gráfico, puede mostrar el histograma solo por URL que comience con "/ api". Por lo tanto, miramos el histograma por separado. Miramos cuánto en este momento. Vemos cuántas RPS había en la URL "/ api". La misma métrica, pero una aplicación diferente.

Algunas palabras sobre tiempos en nginx. Hay request_time, que incluye el tiempo desde el inicio de la solicitud hasta la transferencia del último byte al socket al cliente. Y hay upstream_response_time. Necesitan ser medidos ambos. Si simplemente eliminamos request_time, entonces verá retrasos debido a problemas de conectividad del cliente con su servidor, verá retrasos allí si tenemos configurado el límite de solicitud c burst y el cliente en el baño. No entenderá si necesita reparar el servidor o llamar al proveedor de alojamiento. En consecuencia, eliminamos ambos y queda aproximadamente claro lo que está sucediendo.

Con la tarea de comprender si el sitio funciona o no, creo que lo hemos resuelto más o menos. Hay errores Hay imprecisiones. Los principios generales son los siguientes.
Ahora sobre el monitoreo de la arquitectura multinivel. Porque incluso la tienda en línea más simple tiene al menos una interfaz, seguida de un bitrix y una base. Esto ya es muchos enlaces. El punto general es que necesitas disparar algunos indicadores de cada nivel. Es decir, el usuario está pensando en frontend. Frontend está pensando en el backend. Backend piensa en el backend vecino. Y todos piensan en la base. Entonces, por capas, por dependencias, pasamos. Cubrimos todo con algún tipo de métrica. Tenemos algo en la salida.

¿Por qué no limitarse a una capa? Típicamente, entre las capas hay una red. Una red grande bajo carga es una sustancia extremadamente inestable. Por lo tanto, todo sucede allí. Además, esas medidas que haces en qué capa pueden estar. Si toma medidas en la capa "A" y la capa "B", y si interactúan entre sí a través de la red, puede comparar sus lecturas, encontrar algunas anomalías e inconsistencias.

Sobre el backend. Queremos entender cómo monitorear el backend. Qué hacer con él para comprender rápidamente lo que está sucediendo. Les recuerdo que ya hemos pasado a la tarea de minimizar el tiempo de inactividad. Y sobre el backend, sugerimos de manera estándar la comprensión:
- ¿Cuánto come este recurso?
- ¿Nos topamos con algún límite?
- ¿Qué está pasando con el tiempo de ejecución? Por ejemplo, la plataforma de tiempo de ejecución JVM, el tiempo de ejecución de Golang y otros tiempos de ejecución.
- Cuando ya hemos cubierto todo esto, es interesante para nosotros ya más cerca de nuestro código. Podemos usar la intrumetría automática (statsd, * -metric), que nos mostrará todo esto. O instruirse estableciendo temporizadores, contadores, etc.
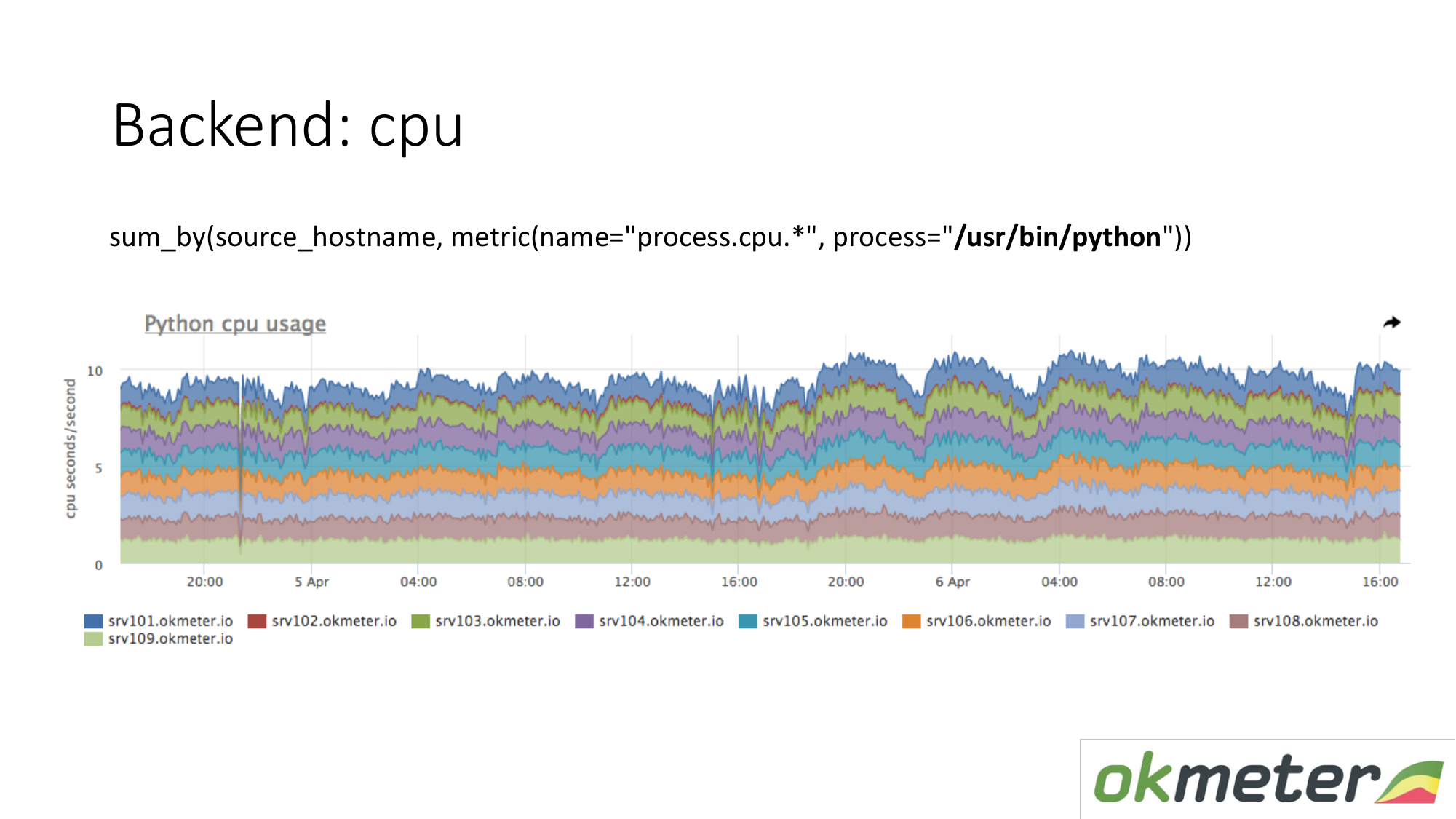
Sobre los recursos. Nuestro agente estándar elimina el consumo de recursos en todos los procesos. Por lo tanto, para el backend, no necesitamos capturar datos por separado. Tomamos y vemos cuánto consume la CPU el proceso, por ejemplo Python en los servidores enmascarados. Mostramos todos los servidores en el clúster en el mismo gráfico, porque queremos entender si tenemos un desequilibrio y si algo explotó en una máquina. Vemos el consumo total de ayer a hoy.
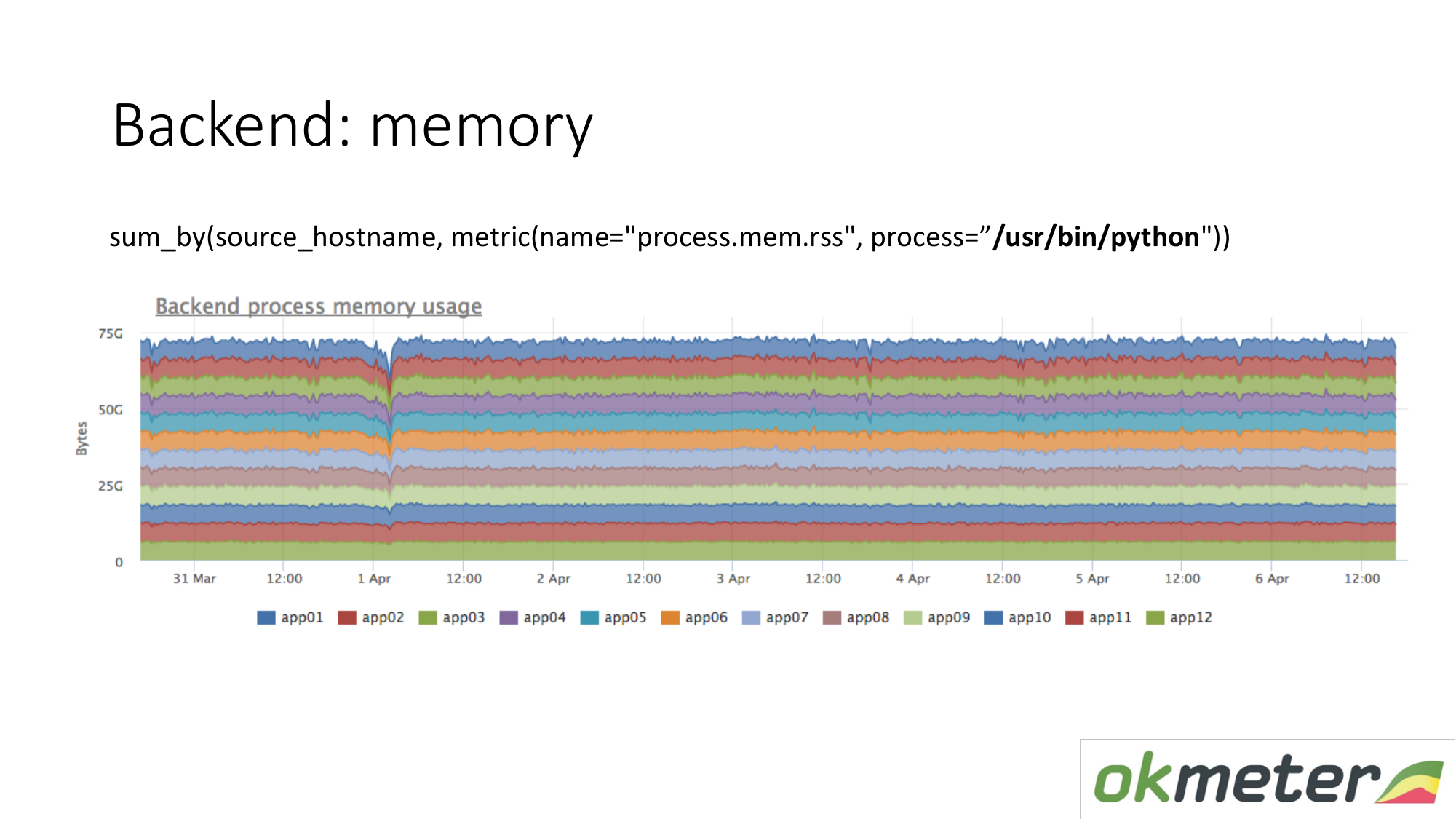
Lo mismo vale para la memoria. Cuando lo dibujamos así. Seleccionamos Python RSS (RSS es el tamaño de las páginas de memoria asignadas al proceso por el sistema operativo y actualmente ubicadas en la RAM). Suma por anfitrión. No miramos a ningún lado la memoria fluye. En todas partes la memoria se distribuye de manera uniforme. En principio, recibimos una respuesta a nuestras preguntas.
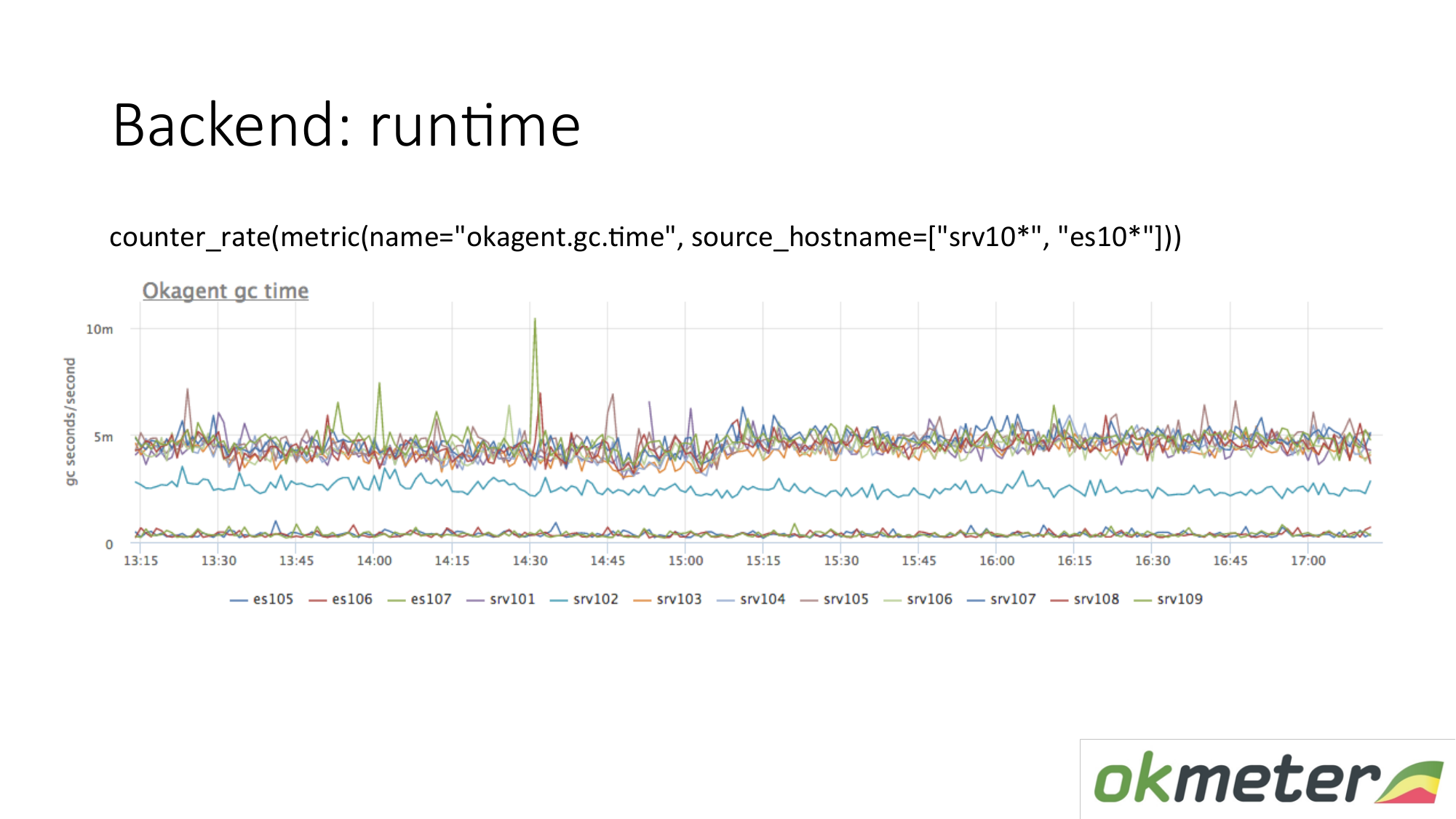
Ejemplo de tiempo de ejecución. Nuestro agente está escrito en Golang. El agente de Golang se envía métricas de su tiempo de ejecución. Esta es, en particular, la cantidad de segundos que el recolector de basura de Golang dedica a la recolección de basura por segundo. Vemos aquí que algunos servidores tienen métricas diferentes de otros servidores. Vimos una anomalía. Estamos tratando de explicar esto.
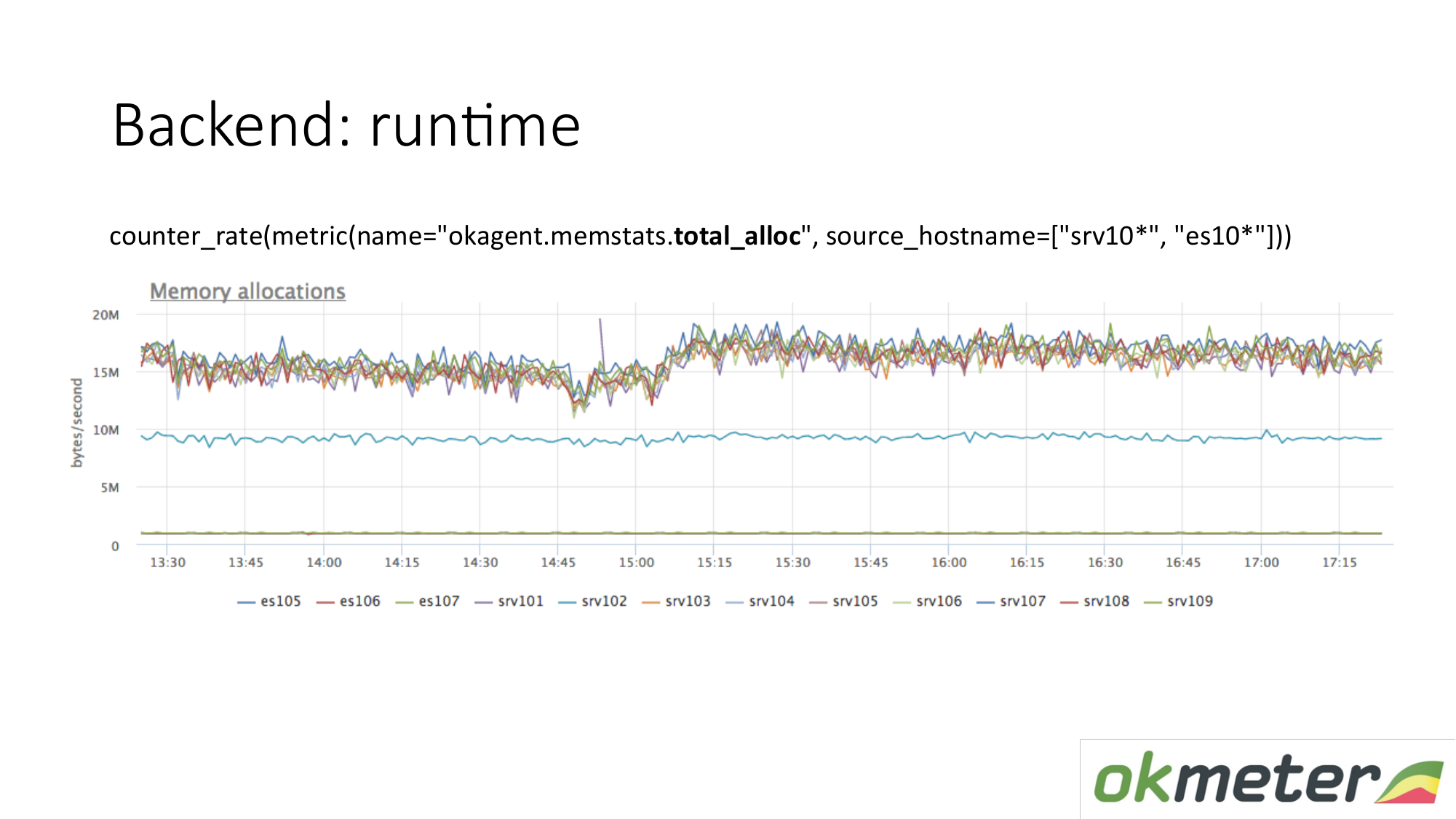
Hay otra métrica de tiempo de ejecución. Cuánta memoria se asigna por unidad de tiempo. Vemos que los agentes con un tipo en la parte superior asignan más memoria que los agentes que disminuyen. A continuación se muestran los agentes con un recolector de basura menos agresivo. Esto es lógico. Cuanta más memoria pase a través de usted, se asigna, se libera, mayor es la carga en el recolector de basura. Además, de acuerdo con nuestras métricas internas, entendemos por qué queremos tanta memoria en esas máquinas y menos en estas máquinas.
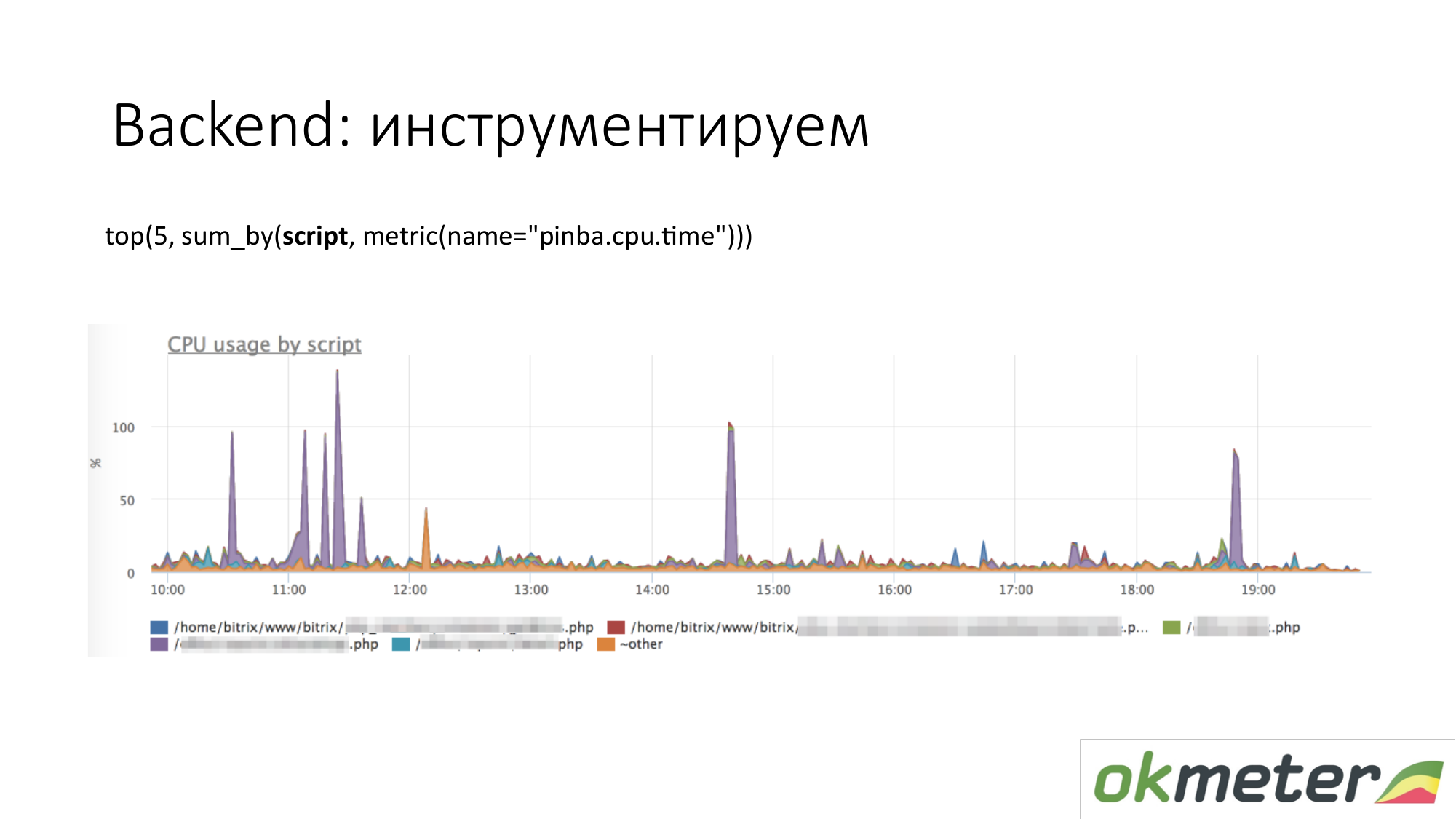
Cuando hablamos de instrumentación, vienen todo tipo de herramientas como http://pinba.org/ para php. Pinba es una extensión para php de Badoo, que instala y conecta a php. Le permite eliminar y enviar protobuf inmediatamente a través de UDP. Tienen un servidor pinba. Pero creamos un servidor Pinba incrustado en el agente. PHP se envía a sí mismo cuánto gastó CPU y memoria para tales scripts, cuánto tráfico es dado por dichos scripts, etc. Aquí hay un ejemplo con Pinba. Mostramos los 5 mejores scripts sobre consumo de CPU. Vemos un valor atípico violeta que es un punto manchado de PHP. Repararemos el punto manchado de PHP o entenderemos por qué consume la CPU. Ya hemos reducido el alcance del problema para que comprendamos los siguientes pasos. Vamos a ver el código y repararlo.

Lo mismo ocurre con el tráfico. Observamos los 5 scripts de tráfico principales. Si esto es importante para nosotros, entonces vamos y entendemos.

Este es un cuadro sobre nuestras herramientas internas. Cuando configuramos el temporizador a través de statsd y medimos las métricas. Lo hicimos para que la cantidad de tiempo total que pasa en la CPU o en anticipación de algún recurso sea establecida por el controlador que estamos procesando actualmente, y por las etapas importantes de su código: esperaron el cassander, esperaron la búsqueda elástica. El gráfico muestra las 5 etapas principales para el manejador / metric / query. En el gráfico, puede mostrar los 5 mejores controladores para el consumo de CPU, por lo que sucede dentro. Está claro qué arreglar.
Sobre el backend puedes ir más profundo. Hay cosas que hacen el rastreo. Es decir, puede ver esta solicitud de usuario en particular con una cookie regular e IP regular que genera tantas solicitudes a la base de datos que esperaron tanto tiempo. No podemos rastrear. No estamos rastreando. Todavía podemos creer que no hacemos aplicaciones y monitoreo del rendimiento.

Sobre la base de datos. Lo mismo Las bases de datos son el mismo proceso. Él consume recursos. Si la base es muy sensible a la latencia, entonces hay características ligeramente diferentes. Sugerimos verificar que no haya menos recursos, ni degradación en los recursos. Es ideal entender que si la base comenzó a consumir más de lo que consumió, entonces entienda qué ha cambiado exactamente en su código.
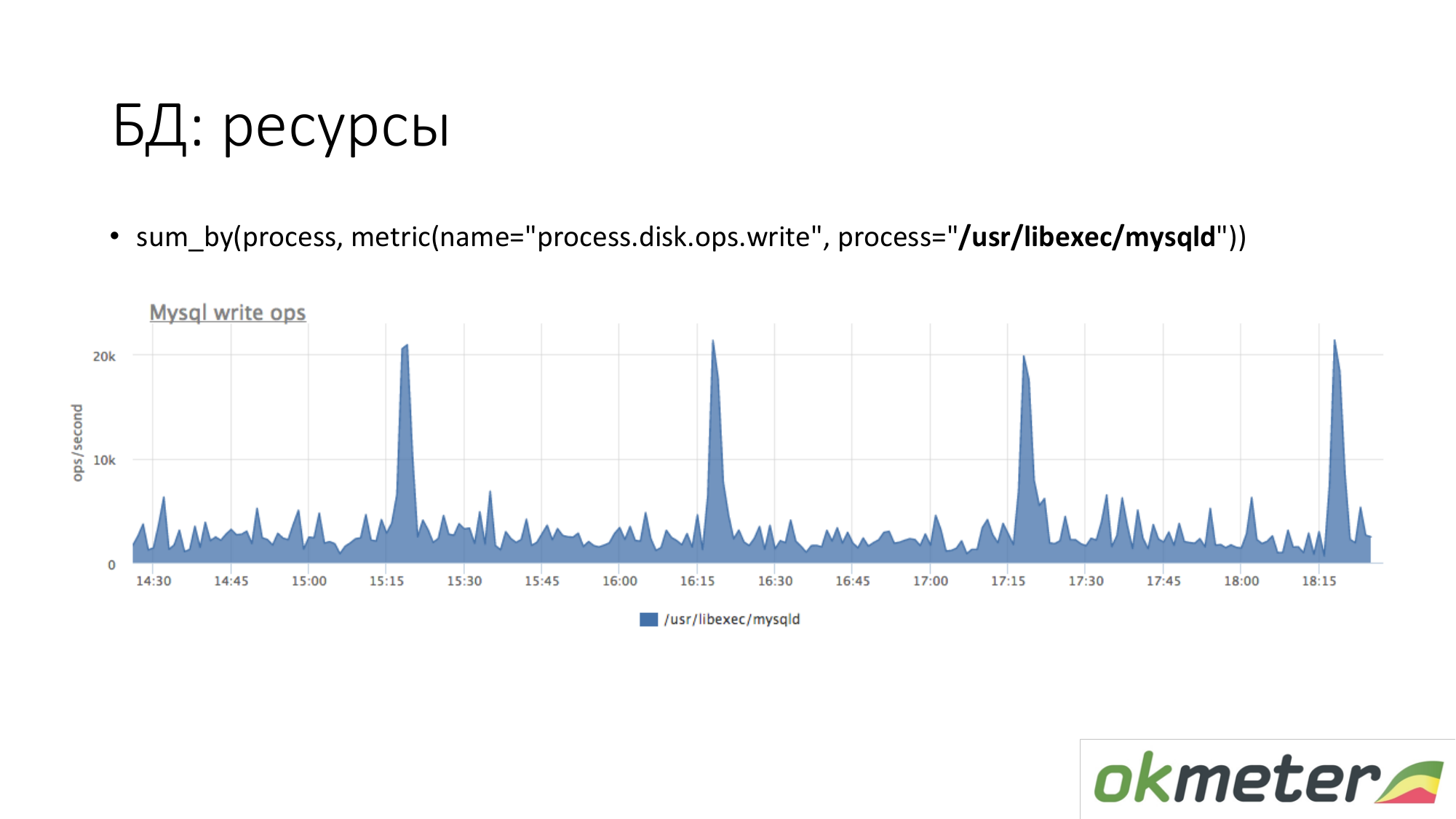
Sobre los recursos. Del mismo modo, observamos cuánto genera el proceso MySQL en nuestro disco. Vemos que en promedio hay mucho, pero ocurren algunos picos. Por ejemplo, entra una gran cantidad de inserción y comienza a escribir en el disco a las 15.15, 16.15, 17.15.
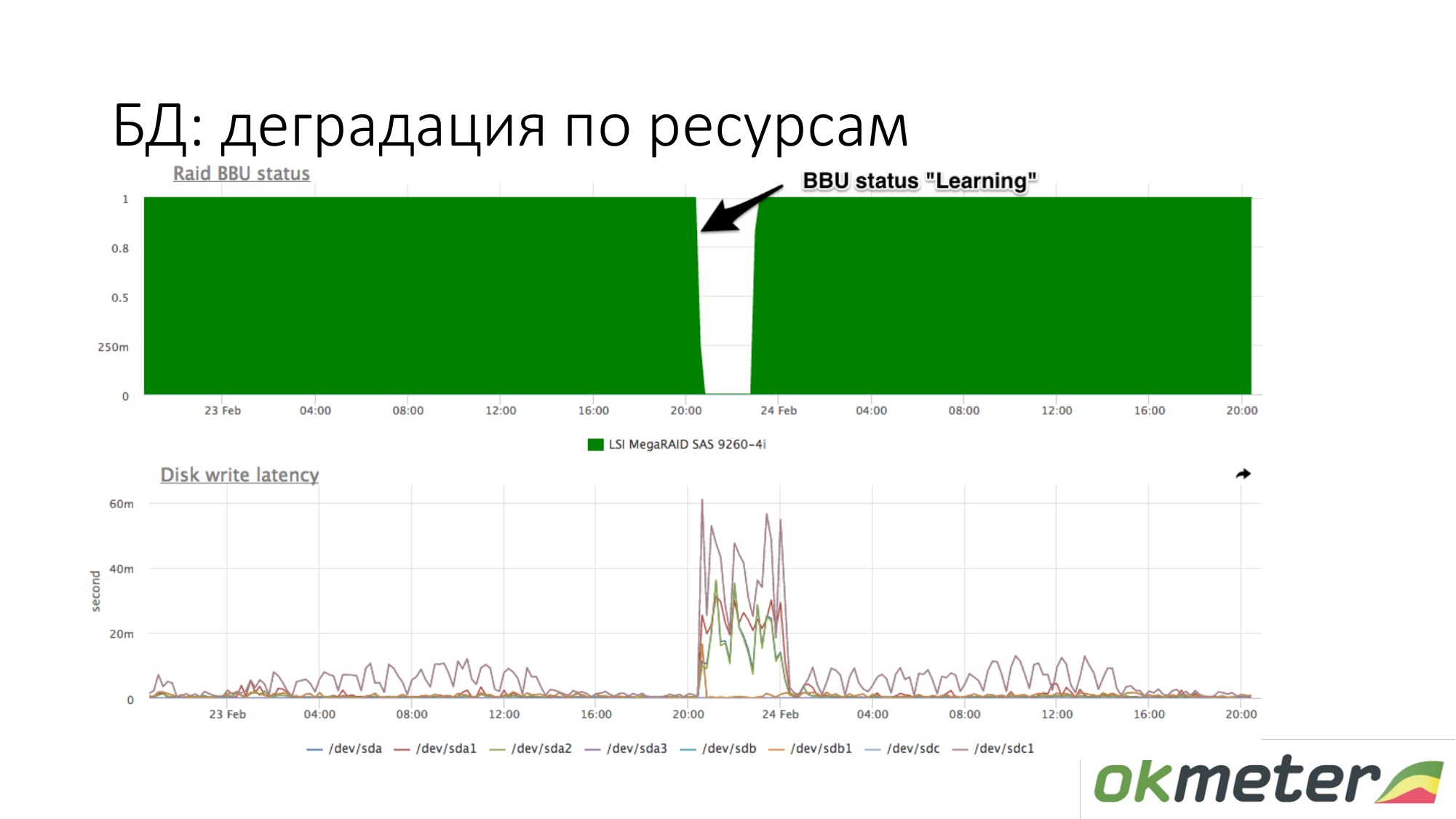
Sobre la degradación de los recursos. Por ejemplo, una batería RAID ha entrado en modo de mantenimiento. Ella dejó de ser un controlador como una batería en vivo. En este punto, la caché de escritura se desconecta, la latencia de los discos de escritura aumenta. En este punto, si la base de datos comenzó a aburrirse mientras esperaba el disco, y usted sabe aproximadamente que con la misma carga en su escritura en el disco la latencia fue diferente, entonces verifique la batería en RAID.

Recursos bajo demanda. No es tan simple aquí. Depende de la base. La base debería poder contar sobre sí misma: qué solicitudes gasta recursos, etc. El líder en esto es PostgreSQL. Tiene pg_stat_statements. Puede comprender qué tipo de solicitud tiene utilizando una gran cantidad de CPU, disco de lectura y escritura y tráfico.
En MySQL, para ser honesto, todo es mucho peor. Tiene performance_schema. De alguna manera funciona desde la versión 5.7. A diferencia de una vista única en PostgreSQL, performance_schema es una tabla de vista del sistema 27 o 23 en MySQL. A veces, si realiza consultas en las tablas incorrectas (en la vista incorrecta), puede malgastar MySQL.
Redis tiene estadísticas del equipo. Verá que cierto comando usa mucha CPU, etc.
Cassandra tiene momentos para consultar tablas específicas. Pero dado que Cassandra está diseñada para que se realice un tipo de consulta en la tabla, esto es suficiente para el monitoreo.
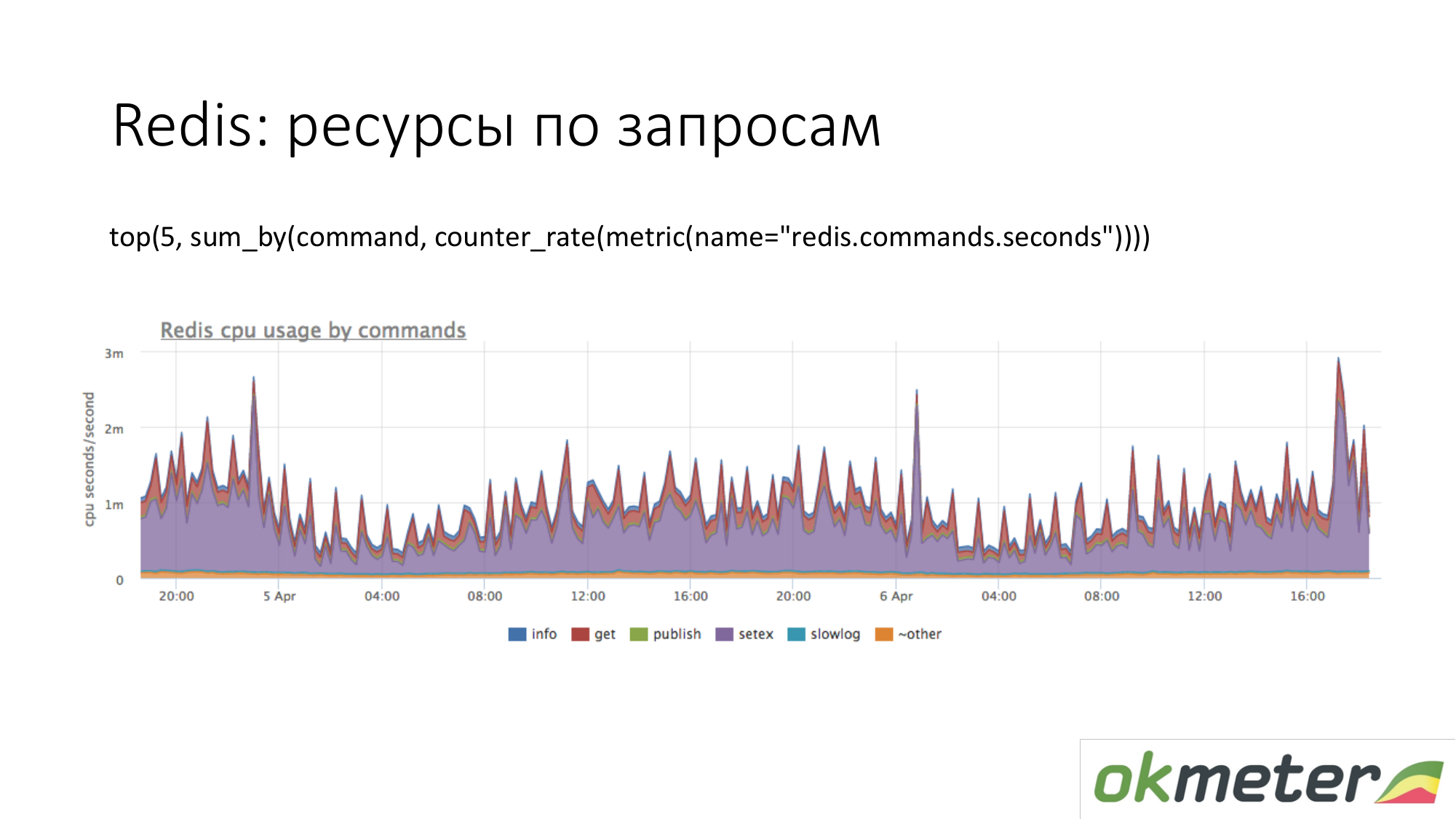
Esta es Redis Vemos que el morado usa mucha CPU. Violet es un setex. Setex - registro de clave con instalación TTL. Si esto es importante para nosotros, vamos a lidiar con eso. Si esto no es importante para nosotros, solo sabemos a dónde van todos los recursos.
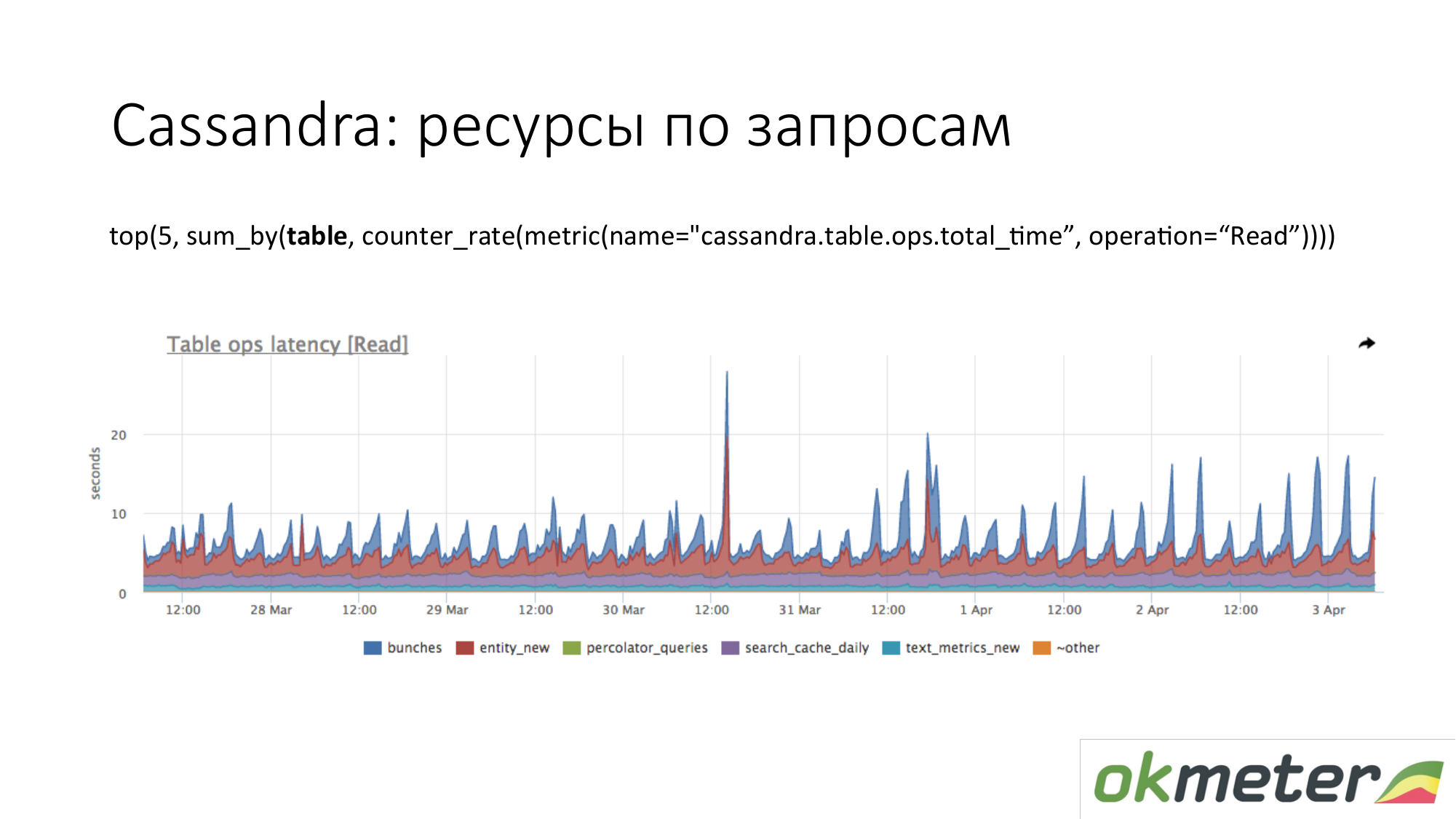
Cassandra Vemos las 5 tablas principales para solicitudes de lectura por el tiempo de respuesta total. Vemos este aumento. Estas son consultas a la tabla, y aproximadamente entendemos que una consulta a esta tabla constituye una pieza de código. Cassandra no es una base de datos SQL en la que podemos hacer diferentes consultas en las tablas. Cassandra se está volviendo cada vez más miserable.

Algunas palabras sobre el flujo de trabajo funcionan con incidentes. Como yo lo veo.
Sobre alerta. Nuestra visión del flujo de trabajo de incidentes es diferente de lo que generalmente se acepta.

Severy crítico. Le notificamos por SMS y todos los canales de comunicación en tiempo real.
Severy Info es una bombilla que puede ayudarlo con algo cuando trabaja con incidentes. La información no se notifica en ningún lado. La información simplemente se cuelga y te dice que algo está sucediendo.
Severy Warning es algo que puede ser notificado, tal vez no.

Ejemplos críticos
El sitio no funciona en absoluto. Por ejemplo, 5xx 100% o el tiempo de respuesta ha aumentado y los usuarios comenzaron a irse.
Errores de lógica de negocios. Lo que es crítico Es necesario medir dinero por segundo. El dinero por segundo es una buena fuente de datos para Critical. Por ejemplo, el número de pedidos, promoción de anuncios y otros.

Flujo de trabajo con Crítico tal que este incidente no puede posponerse. No puede hacer clic en Aceptar e ir a casa. Si se le ocurrió Critical y está tomando el metro, entonces debe salir del metro, salir, tomar un banco y comenzar a reparar. De lo contrario, no es crítico. A partir de estas consideraciones, construimos la gravedad restante para el atributo residual.

Advertencia Ejemplos de advertencia.
- El espacio en disco se agota.
- El servicio interno funciona durante mucho tiempo, pero si no tiene Crítico, significa que está condicionado de todos modos.
- Muchos errores en la interfaz de red.
- Lo más controvertido es que el servidor no está disponible. De hecho, si tiene más de un servidor y el servidor no está disponible, esto es Advertencia. Si no tiene 1 back-end de 100, entonces es estúpido despertarse de un SMS y se pondrá nervioso.
Todos los demás Severy están diseñados para ayudarlo a lidiar con Critical.

Advertencia Abogamos por este enfoque para trabajar con Advertencia. Preferiblemente Advertencia cerrada durante el día. La mayoría de nuestros clientes han deshabilitado la Notificación de advertencia. Por lo tanto, no tienen la llamada ceguera de monitoreo. Esto significa doblar letras en el correo sin leer un directorio separado. Los clientes han deshabilitado la alerta de advertencia.
(Según tengo entendido, el monitoreo puro es alertas innecesarias y desencadenantes agregados a las excepciones - nota del autor de la publicación)
Si utiliza la técnica de monitoreo puro, si tiene 5 Advertencias nuevas, puede repararlas en modo silencioso. No tuvieron tiempo de arreglarlo hoy, pero lo pospusieron hasta mañana, si no de manera crítica. Si la advertencia se enciende y se extingue, entonces esto debe ser torcido en el monitoreo para que nuevamente no se moleste. Entonces serás más tolerante con ellos y, en consecuencia, la vida mejorará.

Ejemplos de información. Es discutible que la alta utilización de CPU de muchos críticos. De hecho, si nada afecta, puede ignorar esta notificación.

Advertencia (tal vez veo información, una nota del autor de la publicación), estas son las luces que se encienden cuando viene a reparar el Crítico. Verá dos señales de advertencia una al lado de la otra (tal vez haya un enlace de información - nota del autor de la publicación). Pueden ayudarlo a resolver el incidente con Critical. Por qué no está claro el alto uso de CPU por separado en SMS o en una carta.
La información sin sentido también es mala. Si los configura como una excepción, le encantará demasiado la información.

Principios generales para el diseño de alertas. La alerta debe mostrar el motivo. Esto es perfecto Pero esto es difícil de lograr. Aquí estamos trabajando a tiempo completo en la tarea y resulta ser una parte del éxito.
Todos hablan de la necesidad de adicción, auto-magia. De hecho, si no recibe notificaciones de algo que no le interesa, entonces no habrá demasiado. En mi práctica, las estadísticas muestran que una persona mirará el momento de un incidente crítico con sus ojos alrededor de cien bombillas en diagonal. Encontrará el correcto allí y no pensará que la dependencia ha ocultado las bombillas que me ayudarían ahora. En la práctica, esto funciona. Todo lo que necesita hacer es limpiar las alertas innecesarias.

(Aquí se saltó el video - nota del autor de la publicación)

Sería bueno clasificar estos tiempos de inactividad para poder trabajar con ellos más adelante. Por ejemplo, sacar conclusiones organizacionales. Necesitas entender por qué estabas mintiendo. Proponemos clasificar / dividir en las siguientes clases:
- hecho por el hombre
- establecimiento de hoster
- vinieron bots
Si los clasificas, todos estarán felices.

SMS ha llegado. Que estamos haciendo Primero corremos para reparar todo. Hasta ahora, nada es importante para nosotros, excepto el final del tiempo de inactividad. Porque estamos motivados para mentir menos. Luego, cuando el incidente se cerró, debería cerrarse al sistema de monitoreo. Creemos que el incidente debe verificarse mediante monitoreo. Si su monitoreo no está configurado, es suficiente para asegurarse de que el problema haya terminado. Esto debe ser retorcido. Una vez cerrado el incidente, en realidad no está cerrado. Él espera mientras llegas al fondo de la razón. Cualquier líder, de hecho, primero debe asegurarse de que los problemas no se repitan. Para que los problemas no se repitan, debe llegar al fondo de la razón. Después de llegar al fondo del motivo, tenemos datos para clasificarlos. Analizamos los motivos. Luego, a medida que llegamos al fondo de la razón, debemos hacerlo en el futuro para que el incidente no vuelva a ocurrir:
- Se necesitan dos personas por trimestre para escribir tal y tal lógica en el backend.
- Necesito poner más réplicas.
Es necesario asegurarse de que no ocurra exactamente el mismo incidente. Cuando trabajas en ese flujo de trabajo a través de N iteraciones, la felicidad te espera, buen tiempo de actividad.
¿Por qué los clasificamos? Podemos tomar las estadísticas del trimestre y comprender qué tiempo de inactividad le dio más. Entonces trabaje en esta dirección. Puede trabajar en todos los frentes no será muy efectivo, especialmente si tiene pocos recursos allí.

Calculamos que quedamos allí por tanto tiempo, por ejemplo, 90% debido al hoster. Cobramos cambiamos este hoster. Si la gente se mete con nosotros, los enviamos a cursos. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
Pregunta: ¿En qué punto y cómo se determina el umbral? ¿Quién está haciendo esto?
Respuesta: vienes a nosotros y dices: queremos hacer algunas críticas de nuestro proyecto. Si pones 10 5xx por segundo ahora, entonces cuántas notificaciones recibirías hace una semana.
Pregunta: ¿Cuál es la carga de todo este buen monitoreo?
Respuesta: En promedio, generalmente es invisible. Pero si analiza 50,000 RPS será del 1% al 10% de una CPU. Como solo estamos monitoreando, optimizamos nuestro agente. Medimos el desempeño del agente. Si no tiene los recursos para monitorear en el servidor, está haciendo algo mal. Siempre debe haber recursos para monitorear. Si no lo hace, estará tan ciego al tacto para administrar su proyecto.