Echemos un vistazo más de cerca al tema de la programación orientada al protocolo. Por conveniencia, el material se dividió en tres partes.
Este material es una traducción comentada de la presentación de WWDC 2016 . Contrariamente a la creencia común de que las cosas "bajo el capó" deben permanecer allí, a veces es extremadamente útil descubrir qué está sucediendo allí. Esto ayudará a usar el artículo correctamente y para el propósito para el que fue diseñado.
Esta parte abordará problemas clave en la programación orientada a objetos y cómo POP los resuelve. Todo se considerará en las realidades del lenguaje Swift, los detalles se considerarán "compartimento del motor" de los protocolos.
Problemas de OOP y por qué necesitamos POP
Se sabe que en OOP hay una serie de debilidades que pueden "sobrecargar" la ejecución del programa. Considere lo más explícito y común:
- Asignación: ¿Pila o montón?
- Recuento de referencias: ¿más o menos?
- Despacho de método: ¿estático o dinámico?
1.1 Asignación - Pila
La pila es una estructura de datos bastante simple y primitiva. Podemos poner en la parte superior de la pila (push), podemos tomar desde la parte superior de la pila (pop). La simplicidad es que esto es todo lo que podemos hacer con él.
Para simplificar, supongamos que cada pila tiene una variable (puntero de pila). Se utiliza para rastrear la parte superior de la pila y almacena un número entero (Entero). De esto se deduce que la velocidad de las operaciones con la pila es igual a la velocidad de reescribir Integer en esta variable.
Empujar: colocar en la parte superior de la pila, aumentar el puntero de la pila;
pop: reduce el puntero de la pila.
Tipos de valor
Consideremos los principios de la operación de pila en Swift usando estructuras (struct).
En Swift, los tipos de valor son estructuras (estructura) y enumeraciones (enumeración), y los tipos de referencia son clases (clase) y funciones / cierres (func). Los tipos de valor se almacenan en la Pila, los tipos de referencia se almacenan en el Montón.
struct Point { var x, y: Double func draw() {...} } let point1 = Point(...)

- Colocamos la primera estructura en Stack
- Copie el contenido de la primera estructura.
- Cambiar la memoria de la segunda estructura (la primera permanece intacta)
- Fin de uso. Memoria libre
1.2 Asignación - Montón
El montón es una estructura de datos en forma de árbol. El tema de implementación del montón no se verá afectado aquí, pero intentaremos compararlo con la pila.
¿Por qué, si es posible, vale la pena usar Stack en lugar de Heap? He aquí por qué:
- recuento de referencia
- administración de memoria libre y su búsqueda de asignación
- reescritura de memoria para desasignación
Todo esto es solo una pequeña parte de lo que hace que Heap funcione y claramente lo sopesa en comparación con Stack.
Por ejemplo, cuando necesitamos memoria libre en Stack, simplemente tomamos el valor de stack-pointer y lo incrementamos (porque todo lo que está encima del stack-pointer en Stack es memoria libre): O (1) es una operación que es constante en el tiempo.
Cuando necesitamos memoria libre en el montón, comenzamos a buscarla usando el algoritmo de búsqueda apropiado en la estructura del árbol de datos; en el mejor de los casos, tenemos una operación O (logn), que no es constante en el tiempo y depende de implementaciones específicas.
De hecho, Heap es mucho más complicado: su trabajo es proporcionado por una serie de otros mecanismos que viven en las entrañas de los sistemas operativos.
También vale la pena señalar que el uso de Heap en modo de subprocesamiento múltiple agrava significativamente la situación, ya que es necesario garantizar la sincronización del recurso compartido (memoria) para diferentes subprocesos. Esto se logra mediante el uso de bloqueos (semáforos, spinlocks, etc.).
Tipos de referencia
Veamos cómo funciona Heap en Swift usando clases.
class Point { var x, y: Double func draw() {...} } let point1 = Point(...)
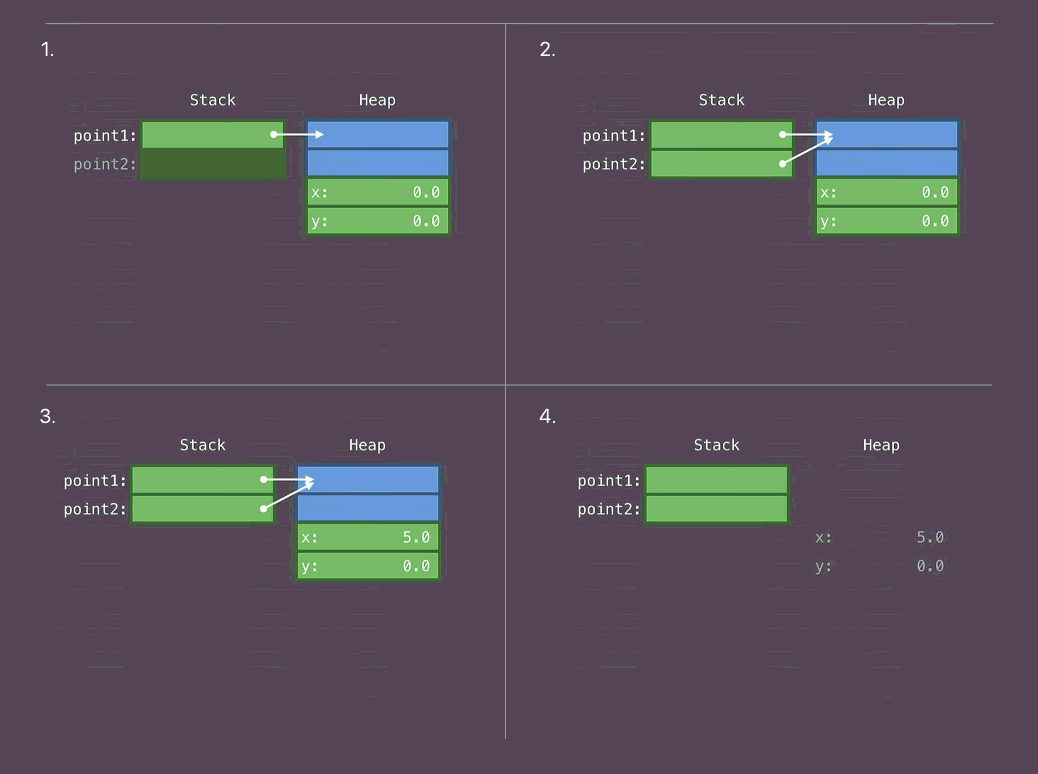
1. Coloque el cuerpo de la clase en el montón. Coloque el puntero a este cuerpo en la pila.
- Copie el puntero que se refiere al cuerpo de la clase.
- Cambiamos un cuerpo de clase
- Fin de uso. Memoria libre
1.3 Asignación: un ejemplo pequeño y "real"
En algunas situaciones, elegir Stack no solo simplifica el manejo de la memoria, sino que también mejora la calidad del código. Considere un ejemplo:
enum Color { case red, green, blue } enum Orientation { case left, right } enum Tail { case none, tail, bubble } var cache: [String: UIImage] = [] func makeBalloon(_ color: Color, _ orientation: Orientation, _ tail: Tail) -> UIImage { let key = "\(color):\(orientation):\(tail)" if let image = cache[key] { return image } ... }
Si el diccionario de caché tiene un valor con la tecla clave, entonces la función simplemente devolverá el UIImage en caché.
Los problemas de este código son:
No es una buena práctica usar String como clave en la memoria caché, porque String al final "puede resultar ser cualquier cosa".
String es una estructura de copia en escritura, para implementar su dinamismo, almacena todos sus Character-s en Heap. Por lo tanto, String es una estructura y se almacena en Stack, pero almacena todo su contenido en Heap.
Esto es necesario para proporcionar la posibilidad de cambiar la línea (eliminar parte de la línea, agregar una nueva línea a esta línea). Si todos los caracteres de la cadena se almacenaran en la Pila, entonces tales manipulaciones serían imposibles. Por ejemplo, en C, las cadenas son estáticas, lo que significa que el tamaño de una cadena no se puede aumentar en tiempo de ejecución ya que todo el contenido se almacena en la Pila. Para copiar y escribir y analizar más detalladamente las líneas en Swift, haga clic aquí .
Solución:
Use la estructura bastante obvia aquí en lugar de la cadena:
struct Attributes: Hashable { var color: Color var orientation: Orientation var tail: Tail }
Cambiar diccionario a:
var cache: [Attributes: UIImage] = []
Deshazte de String
let key = Attributes(color: color, orientation: orientation, tail: tail)
En la estructura de Atributos, todas las propiedades se almacenan en la Pila, ya que la enumeración se almacena en la Pila. Esto significa que no hay un uso implícito de Heap aquí, y ahora las claves para el diccionario de caché están definidas con mucha precisión, lo que aumentó la seguridad y la claridad de este código. También nos deshicimos del uso implícito de Heap.
Veredicto: Stack es mucho más fácil y rápido que Heap: la elección para la mayoría de las situaciones es obvia.
2. Recuento de referencias
Para que?
Swift debe saber cuándo es posible liberar un trozo de memoria en Heap, ocupado, por ejemplo, por una instancia de una clase o función. Esto se implementa a través de un mecanismo de conteo de enlaces: cada instancia (clase o función) alojada en Heap tiene una variable que almacena el número de enlaces. Cuando no hay enlaces a una instancia, Swift decide liberar una pieza de memoria asignada para ello.
Cabe señalar que para una implementación de "alta calidad" de este mecanismo se necesitan muchos más recursos que para aumentar y disminuir el puntero de pila. Esto se debe al hecho de que el valor del número de enlaces puede aumentar desde diferentes subprocesos (porque puede referirse a una clase o función desde diferentes subprocesos). Además, no olvide la necesidad de garantizar la sincronización de un recurso compartido (número variable de enlaces) para diferentes subprocesos (spinlocks, semáforos, etc.).
Pila: encontrar memoria libre y liberar memoria usada - operación de puntero de pila
Montón: búsqueda de memoria libre y liberación de memoria usada: algoritmo de búsqueda de árbol y conteo de referencias.
En la estructura de Atributos, todas las propiedades se almacenan en la Pila, ya que la enumeración se almacena en la Pila. Esto significa que no hay un uso implícito de Heap aquí, y ahora las claves para el diccionario de caché están definidas con mucha precisión, lo que aumentó la seguridad y la claridad de este código. También nos deshicimos del uso implícito de Heap.
Pseudocódigo
Considere una pequeña pieza de pseudocódigo para demostrar cómo funciona el conteo de enlaces:
class Point { var refCount: Int var x, y: Double func draw() {...} init(...) { ... self.refCount = 1 } } let point1 = Point(x: 0, y: 0) let point2 = point1 retain(point2)
Estructura
Cuando se trabaja con estructuras, simplemente no se necesita un mecanismo como el conteo de referencias:
- estructura no almacenada en el montón
- struct - copiado en la asignación, por lo tanto, no hay referencias
Copiar enlaces
Una vez más, la estructura y cualquier otro tipo de valor en Swift se copian en la asignación. Si la estructura almacena enlaces en sí misma, también se copiarán:
struct Label { let text: String let font: UIFont ... init() { ... text.refCount = 1 font.refCount = 1 } } let label = Label(text: "Hi", font: font) let label2 = label retain(label2.text._storage)
label y label2 comparten instancias comunes alojadas en Heap:
- contenido de texto
- y fuente
Por lo tanto, si la estructura almacena enlaces en sí misma, al copiar esta estructura, el número de enlaces se duplica, lo que, si no es necesario, afecta negativamente la "facilidad" del programa.
Y de nuevo el ejemplo "real":
struct Attachment { let fileUrl: URL
Los problemas de esta estructura son que tiene:
- 3 asignación de montón
- Como String puede ser cualquier string, la seguridad y la claridad del código se ven afectadas.
Al mismo tiempo, uuid y mimeType son cosas estrictamente definidas:
uuid es una cadena de formato xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
mimeType es una cadena de formato de tipo / extensión.
Solución
let uuid: UUID
En el caso de mimeType, enum funciona bien:
enum MimeType { init?(rawValue: String) { switch rawValue { case "image/jpeg": self = .jpeg case "image/png": self = .png case "image/gif": self = .gif default: return nil } } case jpeg, png, gif }
O mejor y más fácil:
enum MimeType: String { case jpeg = "image/jpeg" case png = "image/png" case gif = "image/gif" }
Y no olvides cambiar:
let mimeType: MimeType
3.1 Despacho del método
- este es un algoritmo que busca el código del método que se llamó
Antes de hablar sobre la implementación de este mecanismo, vale la pena determinar qué son un "mensaje" y un "método" en este contexto:
- Un mensaje es el nombre que enviamos al objeto. Todavía se pueden enviar argumentos junto con el nombre.
circle.draw(in: origin)
El mensaje es dibujar: el nombre del método. El objeto receptor es un círculo. El origen también es un argumento pasado.
- El método es el código que se devolverá en respuesta al mensaje.
Luego, Method Dispatch es un algoritmo que decide qué método se debe dar a un mensaje en particular.
Más específicamente sobre Despacho de métodos en Swift
Como podemos heredar de la clase principal y anular sus métodos, Swift debe saber exactamente qué implementación de este método debe llamarse en una situación específica.
class Parent { func me() { print("parent") } } class Child: Parent { override func me() { print("child") } }
Cree un par de instancias y llame al método me:
let parent = Parent() let child = Child() parent.me()
Un ejemplo bastante obvio y simple. Y que pasa si:
let array: [Parent] = [Child(), Child(), Parent(), Child()] array.forEach { $0.me()
Esto no es tan obvio y requiere recursos y un cierto mecanismo para determinar la implementación correcta del método me. Los recursos son el procesador y la RAM. Un mecanismo es un método de envío.
En otras palabras, Method Dispatch es cómo el programa determina qué implementación de método invocar.
Cuando se llama a un método en el código, se debe conocer su implementación. Si ella es conocida por
En el momento de la compilación, este es el envío estático. Si la implementación se determina inmediatamente antes de la llamada (en tiempo de ejecución, en el momento de la ejecución del código), esto es Dynamic Dispatch.
3.2 Despacho de método - Despacho estático
El más óptimo, ya que:
- El compilador sabe qué bloque de código (implementación del método) se llamará. Gracias a esto, puede optimizar este código tanto como sea posible y recurrir a un mecanismo como la inline.
- Además, en el momento de la ejecución del código, el programa simplemente ejecutará este bloque de código conocido por el compilador. No se emplearán recursos ni tiempo para determinar la implementación correcta del método, lo que acelerará la ejecución del programa.
3.3 Despacho de métodos - Despacho dinámico
No es el más óptimo, ya que:
- La implementación correcta del método se determinará en el momento de la ejecución del programa, lo que requiere recursos y tiempo
- No hay optimizaciones del compilador fuera de discusión
3.4 Despacho de método - En línea
Se mencionó un mecanismo como la alineación, pero ¿qué es? Considere un ejemplo:
struct Point { var x, y: Double func draw() {
- El método point.draw () y la función drawAPoint se procesarán a través del envío estático, ya que no hay dificultad para determinar la implementación correcta para el compilador (ya que no hay herencia y la redefinición es imposible)
- Como el compilador sabe lo que se hará, puede optimizar esto. Primero optimiza drawAPoint, simplemente reemplazando la llamada de función con su código:
let point = Point(x: 0, y: 0) point.draw()
- luego optimiza point.draw, ya que también se conoce la implementación de este método:
let point = Point(x: 0, y: 0)
Creamos un punto, ejecutamos el código del método de dibujo: el compilador simplemente sustituyó el código necesario para estas funciones en lugar de llamarlas. En Dynamic Dispatch, esto será un poco más complicado.
3.5 Despacho de método: polimorfismo basado en herencia
¿Por qué necesito Dynamic Dispatch? Sin ella, es imposible definir métodos anulados por clases secundarias. El polimorfismo no sería posible. Considere un ejemplo:
class Drawable { func draw() {} } class Point: Drawable { var x, y: Double override func draw() { ... } } class Line: Drawable { var x1, y1, x2, y2: Double override func draw() { ... } } var drawables: [Drawable] for d in drawables { d.draw() }
- La matriz de elementos dibujables puede contener Punto y Línea
- intuitivamente, el envío estático no es posible aquí. d en el bucle for puede ser Line, o quizás Point. El compilador no puede determinar esto, y cada tipo tiene su propia implementación de draw
Entonces, ¿cómo funciona Dynamic Dispatch? Cada objeto tiene un campo de tipo. Entonces Point (...). Type será igual a Point, y Line (...). Type será igual a Line. También en algún lugar de la memoria (estática) del programa hay una tabla (tabla virtual), donde para cada tipo hay una lista con sus implementaciones de métodos.
En Objective-C, el campo de tipo se conoce como el campo isa. Está presente en cada objeto Objective-C (NSObject).
El método de clase se almacena en una tabla virtual y no tiene idea de sí mismo. Para usar self dentro de este método, debe pasarse allí (self).
Por lo tanto, el compilador cambiará este código a:
class Point: Drawable { ... override func draw(_ self: Point) { ... } } class Line: Drawable { ... override func draw(_ self: Line) { ... } } var drawables: [Drawable] for d in drawables { vtable[d.type].draw(d) }
En el momento de la ejecución del código, debe buscar en la tabla virtual, encontrar la clase d allí, tomar el método de dibujo de la lista resultante y pasarle un objeto de tipo d como propio. Este es un trabajo decente para una invocación de método simple, pero es necesario asegurarse de que el polimorfismo funcione. Se utilizan mecanismos similares en cualquier lenguaje OOP.
Despacho de método - Resumen
- Los métodos de clase se procesan de forma predeterminada a través de Dynamic Dispatch. Pero no todos los métodos de clase deben manejarse a través de Dynamic Dispatch. Si el método no se anula, puede encabezarlo con la palabra clave final, y luego el compilador sabrá que este método no puede anularse y lo procesará a través del Despacho estático
- los métodos que no son de clase no se pueden anular (ya que struct y enum no admiten herencia) y se procesan a través del envío estático
Problemas OOP - Resumen
Es necesario prestar atención a pequeños detalles como:
- Al crear una instancia: ¿dónde se ubicará?
- Al trabajar con esta instancia: ¿cómo funcionará el conteo de enlaces?
- Al llamar a un método: ¿cómo se procesará?
Si pagamos por el dinamismo sin darnos cuenta y sin necesidad de ello, esto afectará negativamente el programa que se está implementando.
El polimorfismo es una cosa muy importante y útil. Por el momento, todo lo que se sabe es que el polimorfismo en Swift está directamente relacionado con clases y tipos de referencia. Nosotros, a su vez, decimos que las clases son lentas y pesadas, y la estructura es simple y fácil. ¿Es posible el polimorfismo a través de estructuras posibles? La programación orientada al protocolo puede proporcionar una respuesta a esta pregunta.