La topología de los centros de datos y dispositivos modernos en ellos ya no nos permite estar contentos exclusivamente con el
monitoreo de whitebox . Con el tiempo, necesitaba una herramienta que mostrara el rendimiento de dispositivos específicos, en función de la situación real con la transferencia de tráfico (plano de datos) en cualquier parte de la
red de Clos . Hace unas semanas en la conferencia
Next Hop , el ingeniero de red de Yandex, Alexander Klimenko, compartió su experiencia para resolver este problema.
- Trabajo en el departamento de operación y desarrollo de la red Yandex, y a veces me veo obligado a resolver algunos problemas, en lugar de dibujar nubes hermosas en las hojas o inventar un futuro brillante. La gente viene y dice que algo no les funciona. Si se monitorea este asunto, si nuestros ingenieros de servicio ven que no funciona, entonces será más fácil para mí. Entonces, esta media hora se dedicará al monitoreo.

Tarde o temprano, a todos se les ocurre la idea del monitoreo. Es decir, al principio puede recopilar apelaciones de los propios usuarios, lo llamarán y le dirán que algo no funciona para ellos. Pero está claro que tal sistema no escala bien. Si tiene más de un conmutador, si tiene una red suficientemente grande, con esta opción de monitoreo no puede ir muy lejos.
Y tarde o temprano todos llegan a la conclusión de que es necesario recopilar algunos datos del equipo. Este es el primer paso. Pueden ser registros, varios datos sobre SNMP, caídas, puede crear topologías de acuerdo con LLDP, etc. Hay un claro inconveniente: el dispositivo en sí mismo le proporciona toda esta información. Puede no decir nada, engañarte, etc.
La etapa lógica en el desarrollo de su monitoreo es el monitoreo en hosts. Podemos decir que hay una pequeña rama. Si tiene suerte, o no, de tener una red en un proveedor, el proveedor puede ofrecerle algunas de sus propias opciones de monitoreo. Pero el año pasado en Next Hop, Dima Ershov
dijo que nuestra fábrica fue creada a partir de dos proveedores básicos y que no podemos permitirnos ese lujo. O podemos, pero solo parcialmente.
Finalmente, la última opción, que todos de alguna manera alcanzan con el desarrollo de la red. Esto es monitoreo en hosts finales. Yandex tiene tal monitoreo. Se llama Netmon.

En la parte inferior de la diapositiva
hay un enlace con una presentación detallada sobre cómo funciona Netmon. Lo diré literalmente dentro de una diapositiva. Si alguien quiere, lea la charla de otra conferencia de Netmon.
Netmon son agentes que se instalan en casi todos los hosts de la red. La tarea llega a los agentes: enviar algunos paquetes a algún nodo de red. Pueden ser completamente diferentes: UDP, TCP, ICMP. Puede ser como pinturas diferentes, es decir, DSCP y destino. Los puertos de origen y destino también pueden ser diferentes.
Estos datos se agregan, se cargan en un almacenamiento separado, y obtenemos aquí un segmento como el de la derecha en la figura. Una porción puede estar más agregada o menos agregada, dependiendo de lo que queramos ver. Por ejemplo, aquí, hasta donde veo, tenemos una porción de toda la conectividad del centro de datos, es decir, entre todos nuestros centros de datos. Podemos caer más en los cuadrados: ver la conectividad entre el POD o dentro del edificio de un centro de datos; aún más profundo: dentro del POD entre los bastidores; e incluso más profundo, incluso dentro del estante.

¿Qué podría salir mal aquí? Una pequeña digresión para aquellos que no vieron el próximo salto del año pasado.
Usamos 400 gigabits por ToR, y en el primer momento de implementación de esta fábrica incluimos solo 200, porque había tareas más importantes. No importa por qué Encendieron 200, llegaron los servicios y dijeron: ¿por qué 200? ¡Queremos 400! Comenzó a encenderlo. Y así sucedió que la segunda parte de la fábrica, que incluimos, tenía algún tipo de matrimonio en la memoria de las tarjetas. Como resultado, encendemos la fábrica y vemos esta imagen:

Este Netmon, los cuadrados rojos, está en llamas. Entendemos que todo está perdido. Nos agarramos de la cabeza, como Homero, e intentamos empujar algo frenéticamente. Y qué presionar, qué apagar, no lo entendemos. Es decir, Netmon nos muestra la presencia de un problema, pero no muestra dónde, de hecho, el problema se encuentra en la red.

Hemos llegado a la tarea que debemos completar. ¿Qué hay que hacer? Determine con qué dispositivo en la red hay un problema y retírelo del servicio, ya sea automáticamente o por fuerzas, por ejemplo, ingenieros en servicio.
Además, las condiciones iniciales son tales que tenemos una topología bastante regular, es decir, no hay vínculos extraños entre giros de segundo nivel o entre toros. Tenemos la mayor parte del tráfico: TCP, hay un lugar central, ya nos han informado, y los servidores se administran más o menos centralmente. Podemos llegar a este lugar central y declarar razonablemente: chicos, queremos hacerlo, por favor hágalo.
¿Qué opciones hemos considerado?

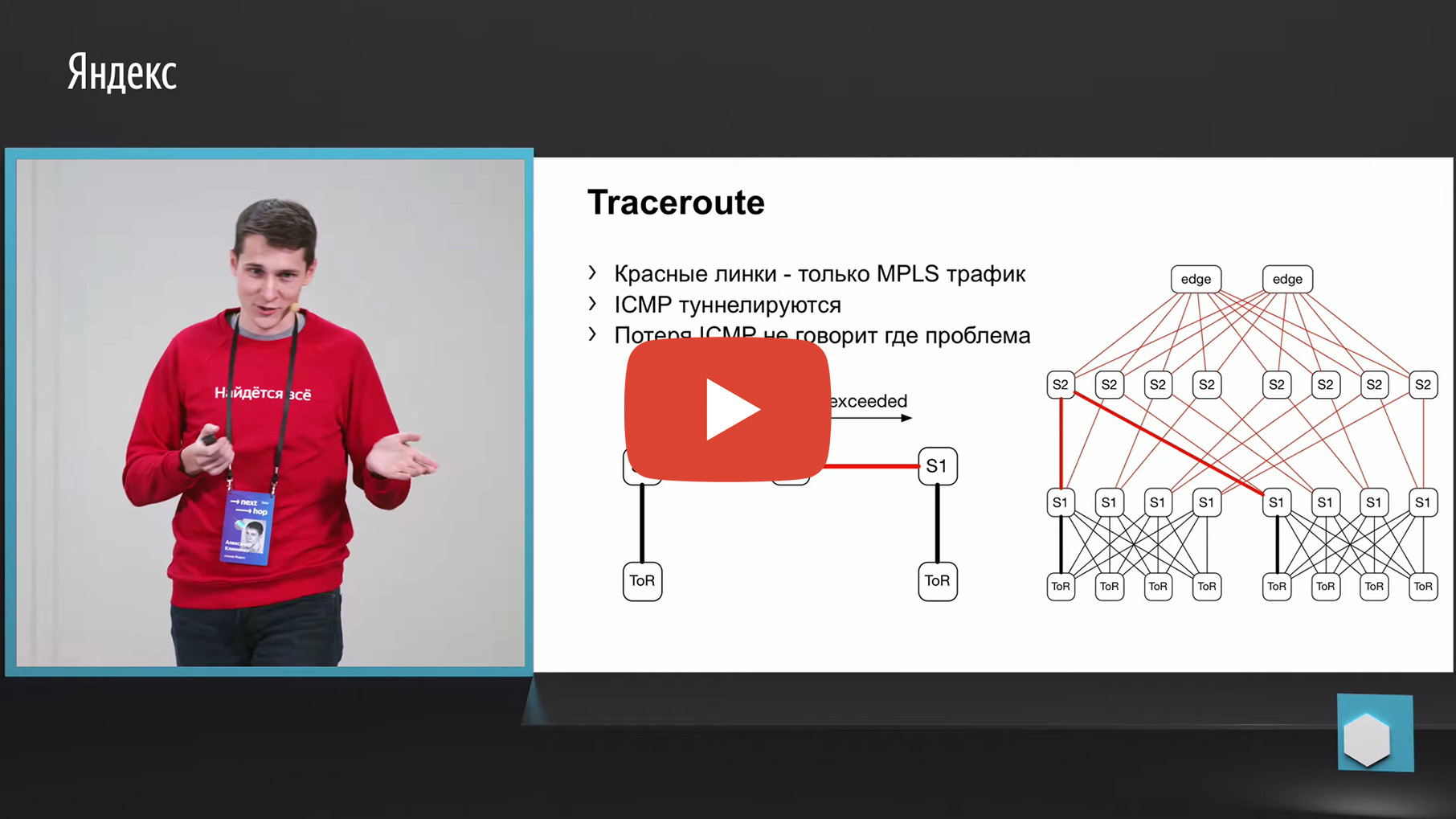
Lo primero que viene a la mente es el rastreo. Por qué Porque el mismo Netmon descarga los pares de origen y destino fallidos en un recopilador separado. En consecuencia, podemos tomar esta tupla de 5, mirarla y hacer un seguimiento con los mismos parámetros. Y para agregar datos sobre qué enlace o por qué dispositivos pasa la mayor cantidad de rastros.
Pero desafortunadamente, MPLS se usa en nuestra fábrica (ahora nos estamos moviendo en la dirección opuesta a MPLS, pero también necesitamos monitorear las viejas fábricas de alguna manera, pero no las descarte, en realidad). Tenemos MPLS en la fábrica, y el problema con MPLS y el rastreo es que necesita tunelizar el mensaje ICMP excedido por TTL, que subyace al rastreo. Habiendo perdido tal mensaje de entrada a salida, podemos perder la supervisión misma. Es decir, no entenderemos a través de qué nodos pasó este mensaje. Esto no nos convenía para el monitoreo.
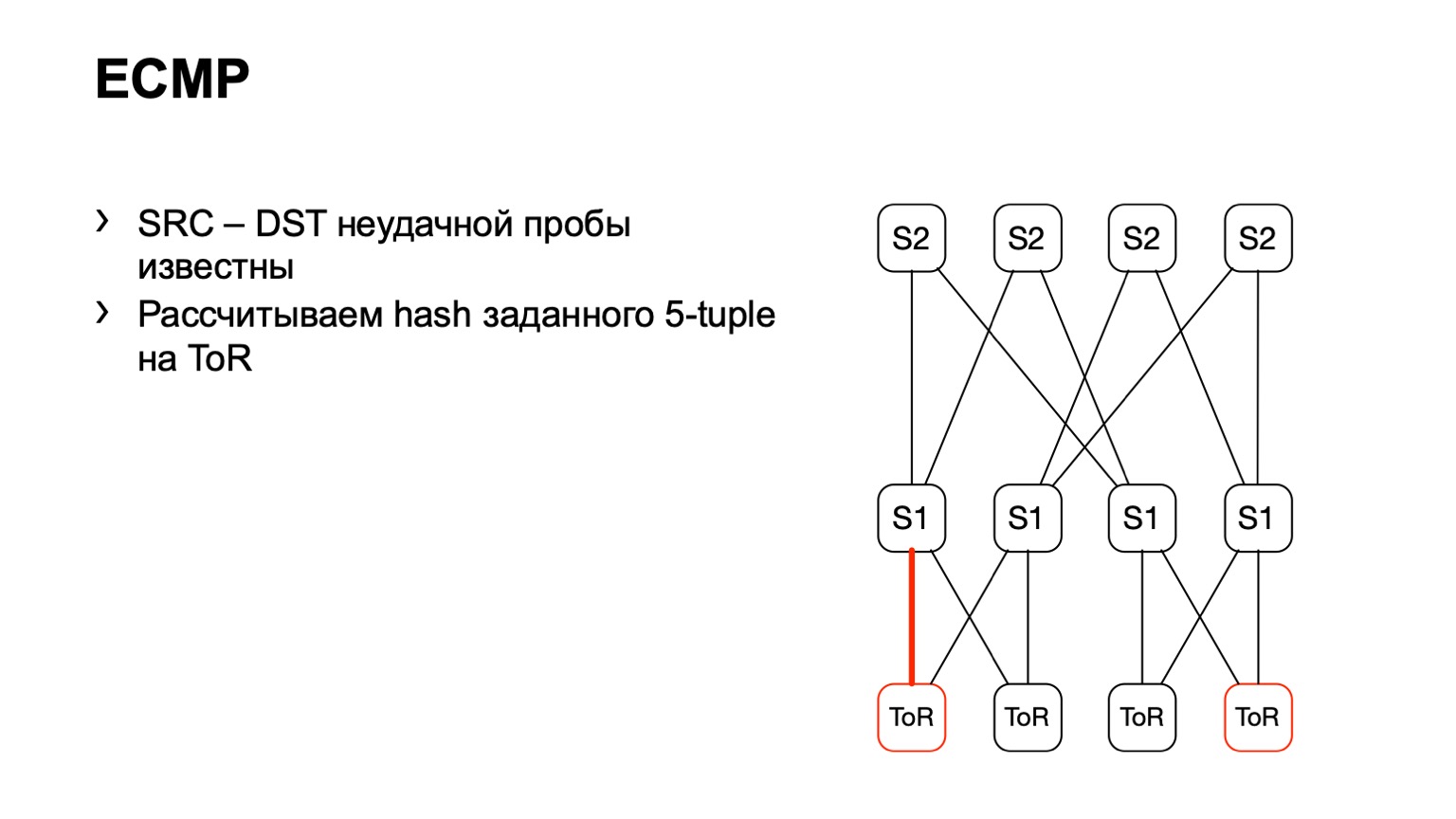
Hay una segunda opción relacionada con ECMP. Tomamos el mismo par de origen y destino, además de puerto de origen puerto de destino. Llegamos a una pieza de hierro, a través de la API o de la CLI, alimentamos esta pieza de hierro a la pieza de hierro, y obtenemos la interfaz de salida. Muchos dispositivos admiten este tipo de salida.
Llegamos a ToR, vemos que ToR ha elegido un enlace izquierdo o derecho. En este caso, el enlace izquierdo está hacia la izquierda S1.
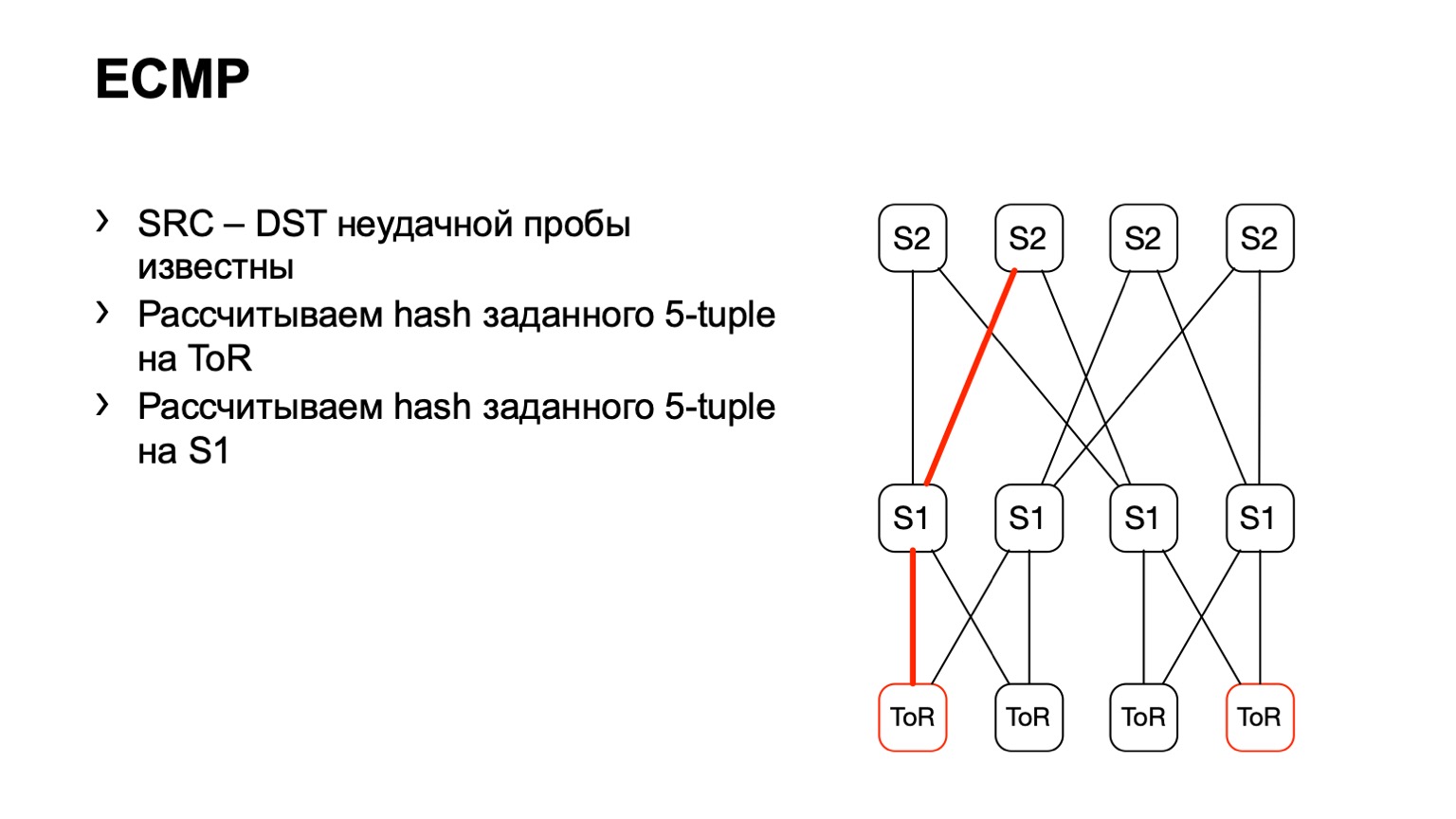
Llegamos a este S1, miramos, a la derecha S2, y de esta manera se formó un camino listo.
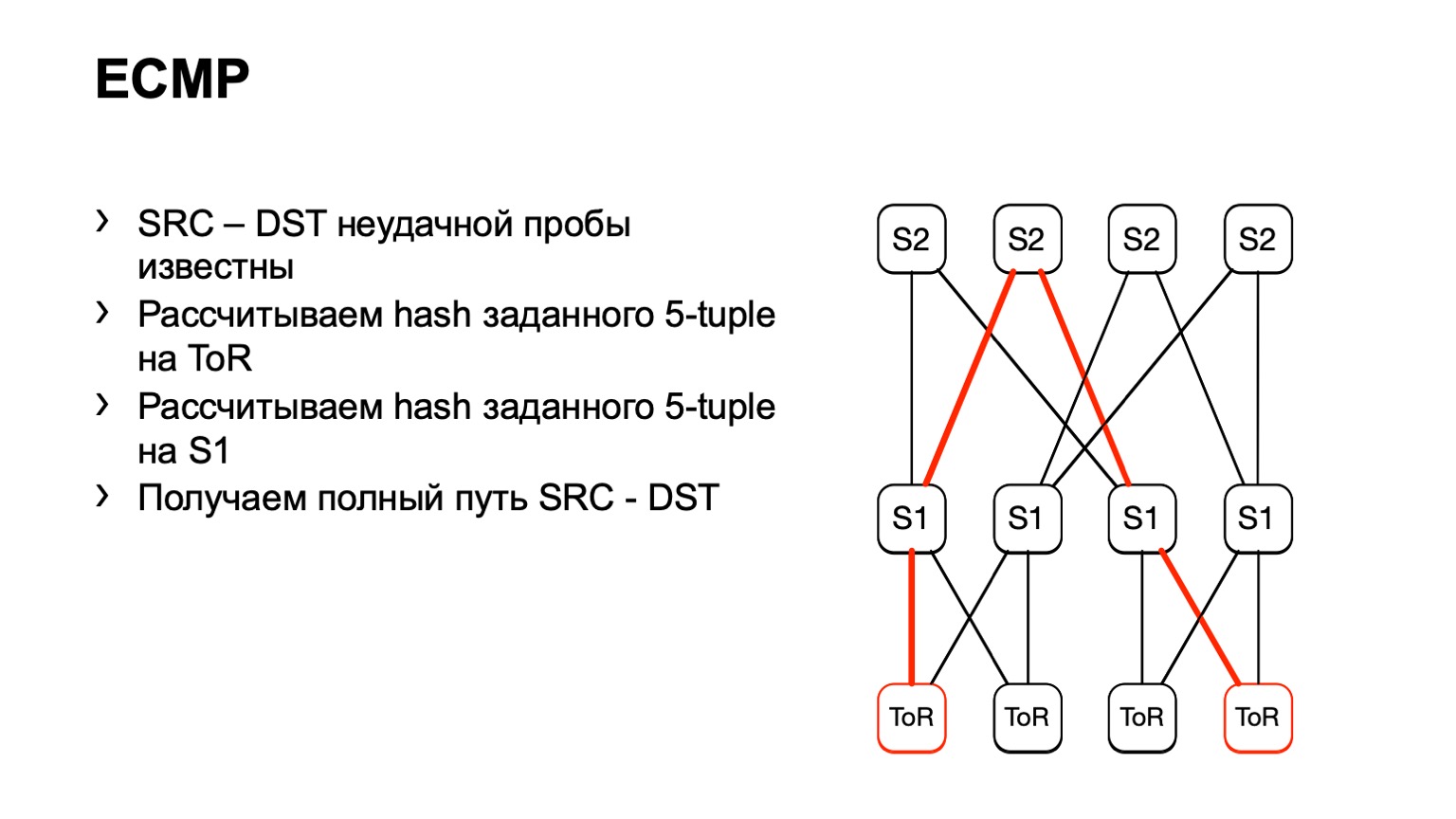
Hay algunas desventajas. En primer lugar, no todos los dispositivos pueden aceptar normalmente estos datos de entrada que les damos. Esto se debe al hecho de que tenemos IPv6 y MPLS, así como al hecho de que algunos proveedores simplemente no implementaron esto. El segundo inconveniente de esta solución: confiamos en lo que el trozo de hierro nos dirá nuevamente, en lugar de mirar lo que está sucediendo en los hosts. Y finalmente, el tercer inconveniente: durante el tiempo que va y ve lo que sucede allí, algo ya puede cambiar en la red y sus datos no serán relevantes.

Luego nos encontramos con una interesante presentación hecha por Facebook. Nos gustó la idea que propuso Facebook, decidimos intentar hacer algo similar.
¿Cuál fue la idea principal? Use un programa eBPF en el host para colorear la retransmisión TCP y luego calcule el número de dichos paquetes. Desafortunadamente, no pudimos hacerlo en Facebook, tuvimos que inventar nuestra propia bicicleta. Trataré de contarte sobre el camino del dolor y el sufrimiento por el que hemos pasado.
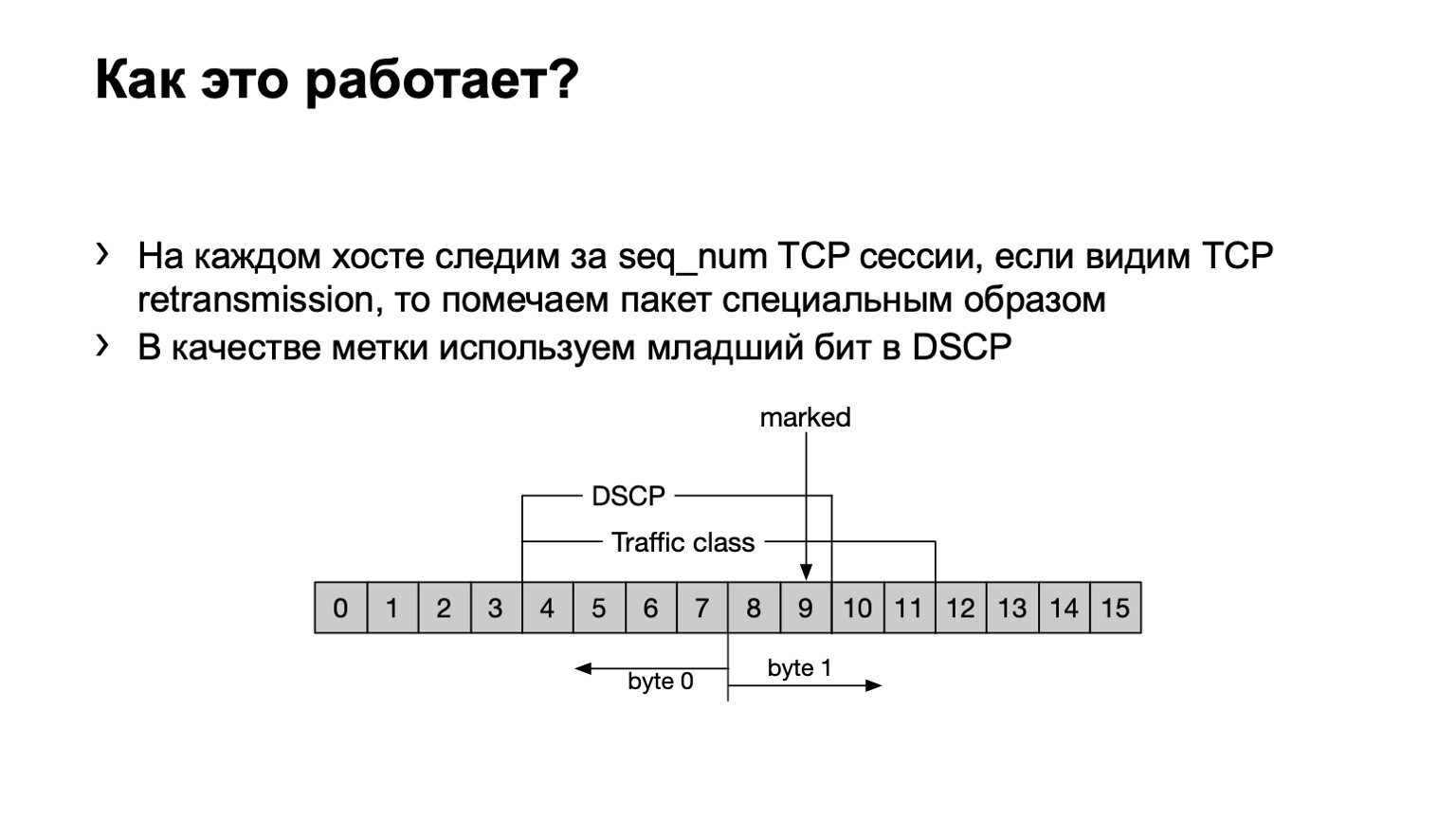
Que hemos hecho Por si acaso, señalaré que la retransmisión de TCP son mensajes TCP que se repiten varias veces debido a que no se confirmó su recepción. Tenemos un programa eBPF instalado en el host y analiza si este mensaje TCP se retransmite o no. Lo hace cursi, por número de secuencia. Si se transmite el mismo número de secuencia en una sesión TCP, entonces esto es retransmitir.
¿Qué hacemos con tales paquetes? Establecimos el último bit en el campo DSCP en uno para calcular aún más todo.
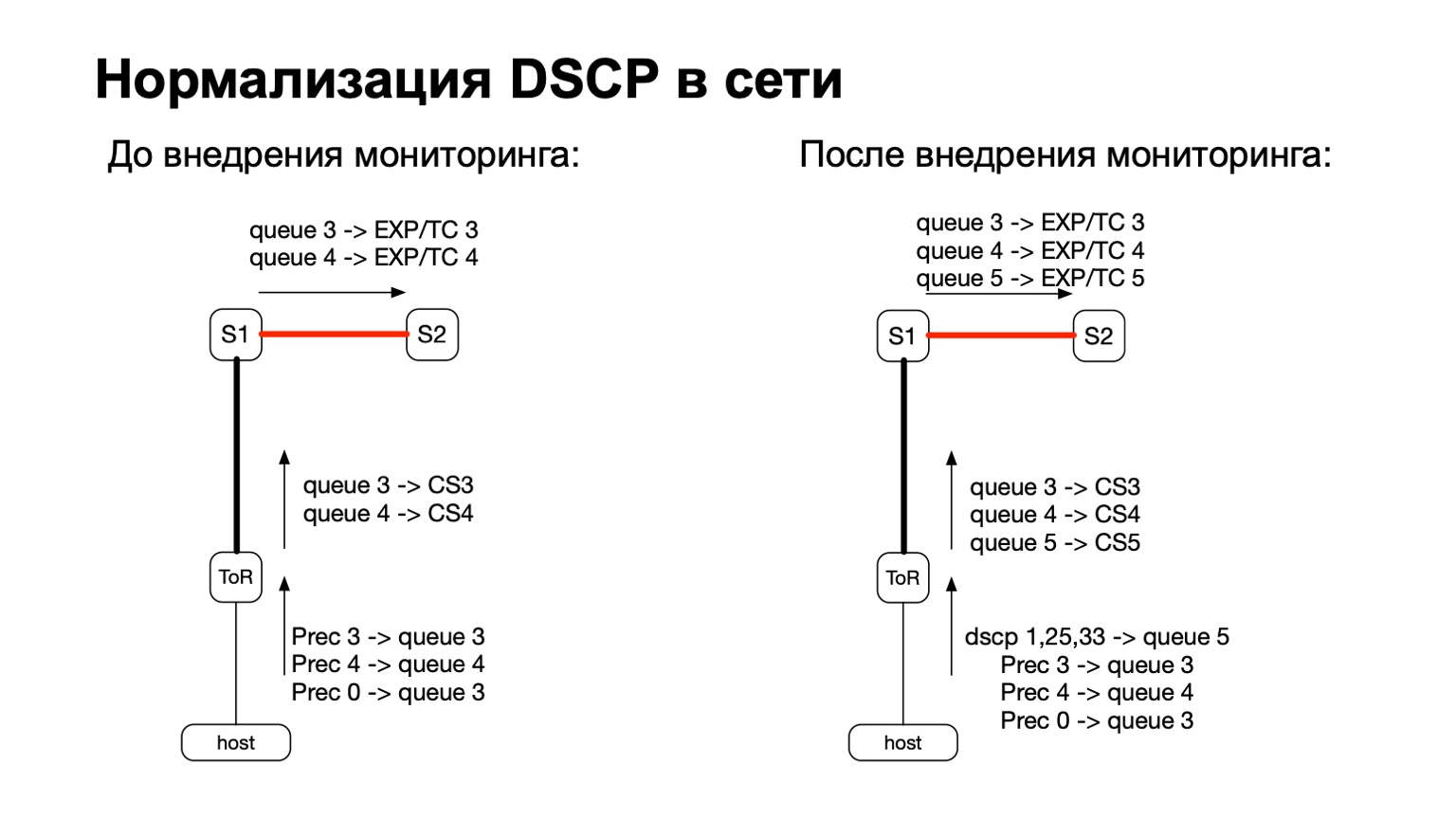
En términos generales, DSCP está relacionado de alguna manera con QoS, ¿verdad? Y con QoS, la historia en nuestra red es bastante complicada y antigua. Tenemos ciertas políticas que se supervisan en los conmutadores ToR. A estas políticas, acabamos de agregar la necesidad de contar más y estos paquetes de colores.
Por lo tanto, para paquetes de colores (léase: para paquetes de retransmisión de TCP desde el host), simplemente agregamos otra cola de QoS. Esto fue bastante fácil de hacer, porque todavía teníamos líneas libres. Además, esto es conveniente, porque en la etapa de transición entre IPv6 y MPLS en la fábrica, es decir, en la etapa en que el paquete vuela S1 y sale a nuestra parte MPLS de la fábrica, es conveniente tomar y volver a pintar EXP / TC en el encabezado del paquete MPLS para cada cola específica. .
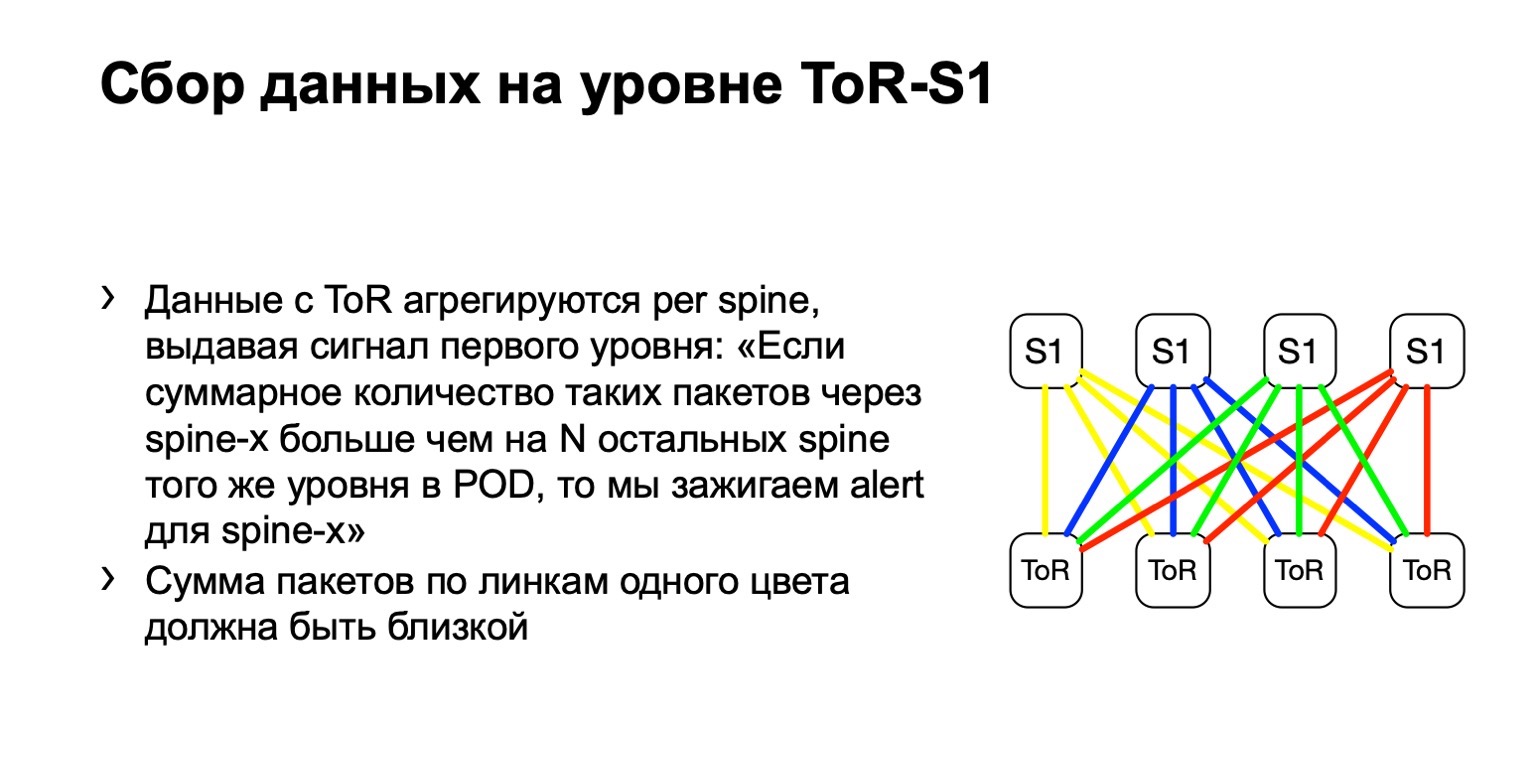
¿Qué hacemos con estos datos? Los recopilamos con filtros ACL estándar, clase de tráfico. Es decir, funciona, en principio, en cualquier proveedor. Podemos recopilar y calcular el número de dichos paquetes en todas partes.
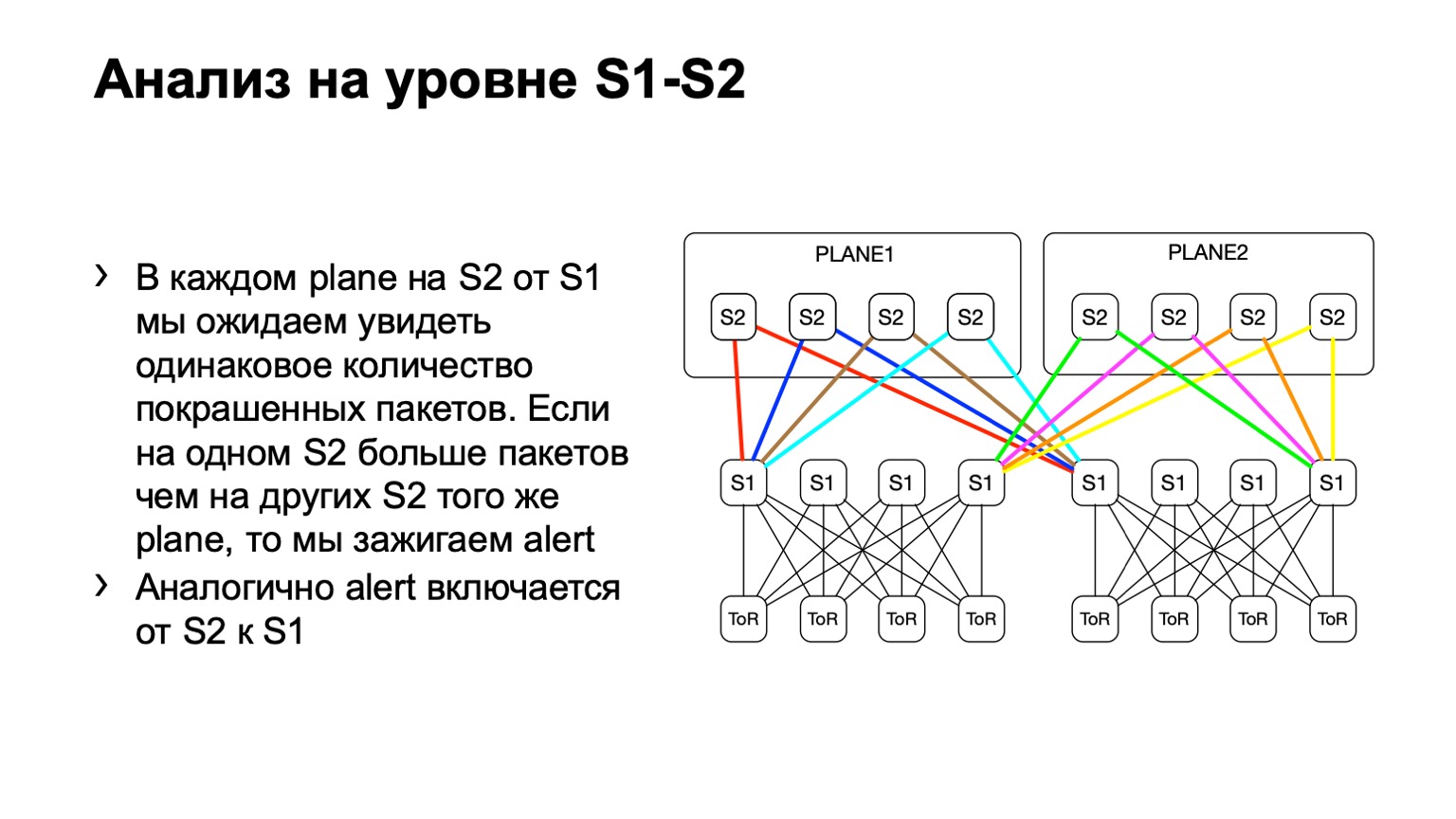
A continuación, observamos la distribución desigual de dichos paquetes en el POD. En ella, por ejemplo, cuatro espinas, como en la imagen. Si el número de paquetes en los enlaces amarillos, en azul, en verde y en rojo es el mismo, entonces creemos que todo es más o menos bueno. Si en algún momento vemos un aumento, por ejemplo, en la columna vertebral más a la derecha del primer nivel, entendemos que este dispositivo atrae retransmisión, algo está mal. Luego tratamos de desmantelarlo o, al menos, arrendarlo. Al menos cuando veamos problemas en Netmon, sabremos con qué dispositivo pueden surgir.
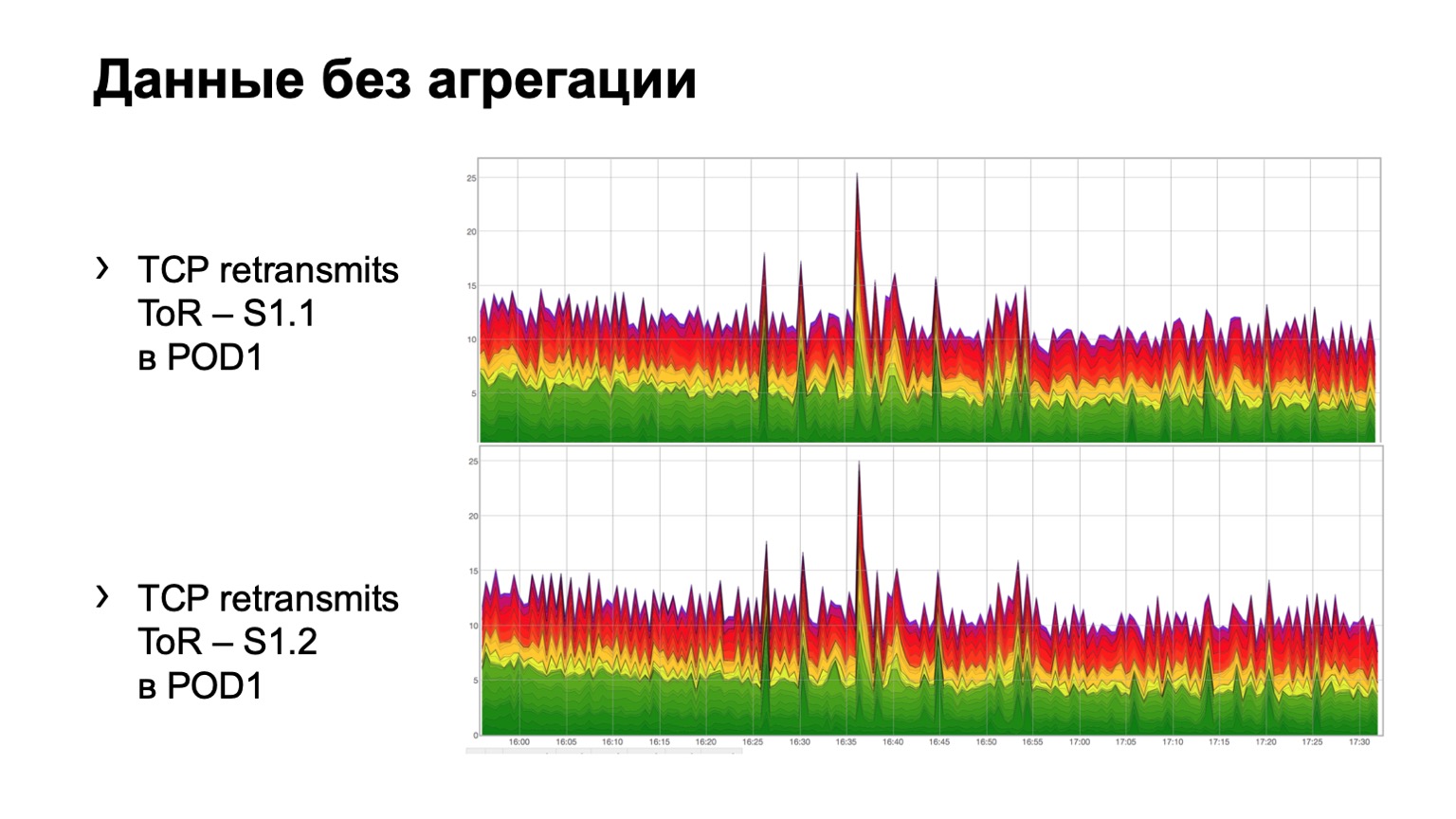
¿Cómo se ve en los datos sin procesar simples? Aquí hay dos gráficos. De hecho, estos son cuadros de retransmisión con ToR hacia la columna vertebral de primer nivel. En el ejemplo, dos espinas en el módulo. El gráfico superior es la agregación de la primera columna vertebral, el gráfico inferior es la segunda columna vertebral. Ver esto en este formulario no es muy conveniente, por lo que hemos agregado la agregación de esta información.
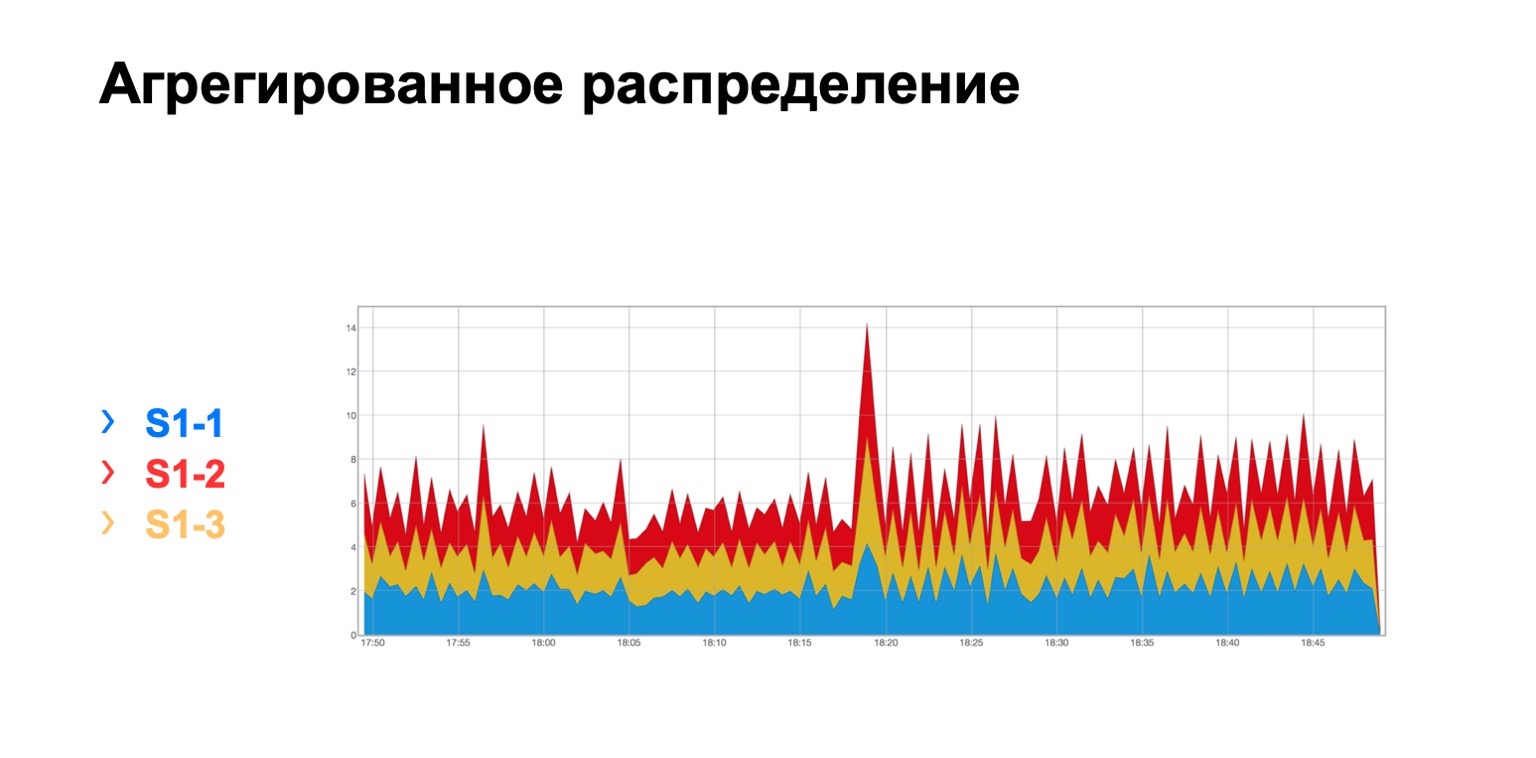
Se ve así. Hay un módulo en el que tres espinas, por alguna razón, no importa cuál, y vemos aquí una distribución total de retransmisiones a tres espinas. Es, en principio, bastante uniforme.
Para la columna vertebral de segundo nivel, podemos tener varias desviaciones, llamémoslas así. La topología sigue siendo regular, pero dependiendo del centro de datos, podemos o no usar una arquitectura tipo placa. El punto aquí es exactamente el mismo. En un nivel, deberíamos tener aproximadamente la misma distribución de paquetes de colores.
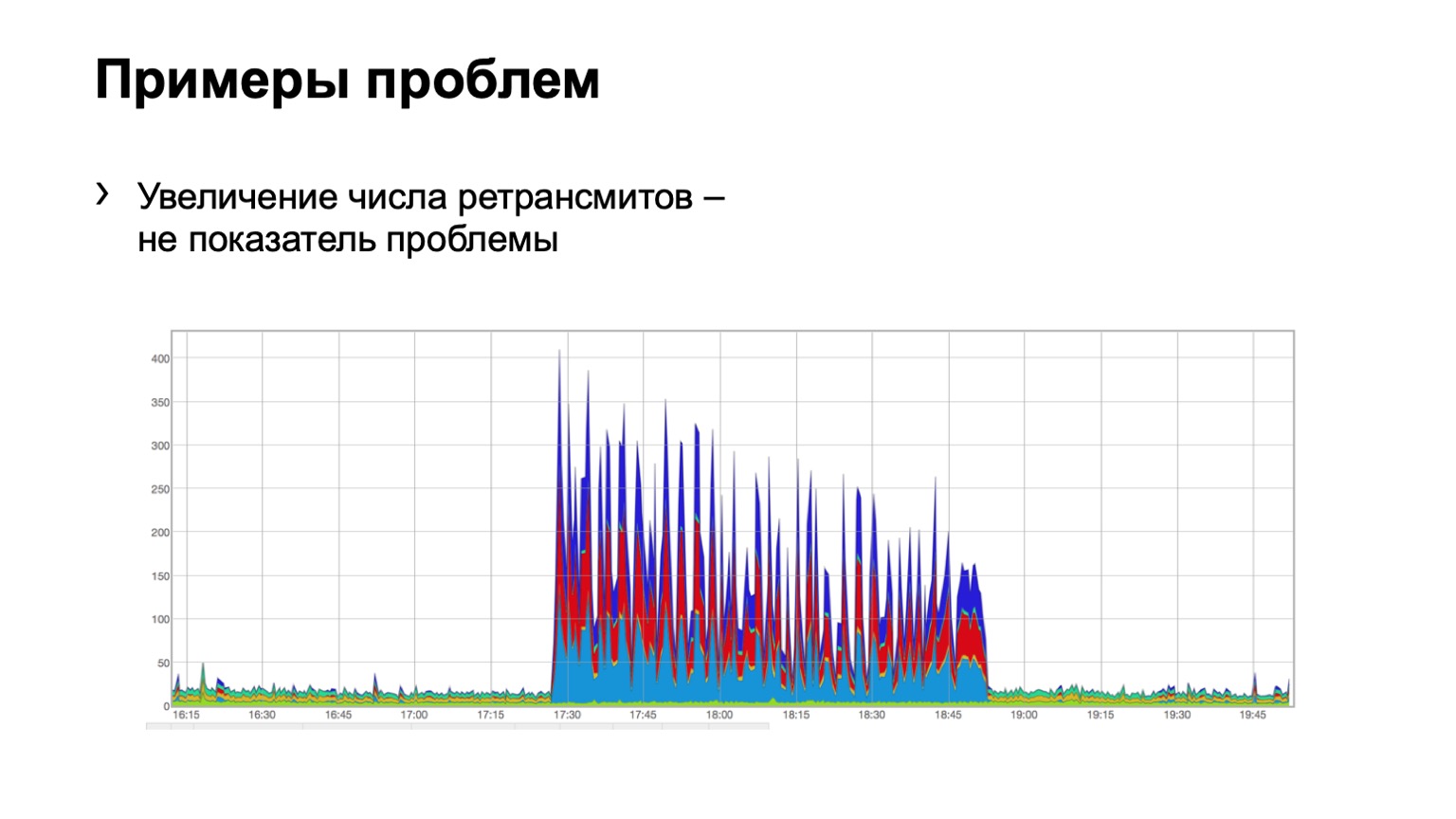
Veamos algunos ejemplos. ¿Alguien ve un problema en ese gráfico? Hay un problema aquí, pero no está allí al mismo tiempo. Sí, este es el problema de Schrödinger. ¿Por qué está ella allí y no? Debido a que vemos un aumento en el número de retransmisiones, es directamente obvio que algo nos sucedió. Pero al mismo tiempo, vemos que este crecimiento es bastante uniforme. Es decir, tres espinas azules, rojos, azules, incluso distribución sobre ellos. ¿Qué significa esto? Que hubo algún tipo de problema en la red, pero no está relacionado con este nivel de agregación de datos. Ella esta en otro lugar.
Tal vez alguien cerró el puerto en los firewalls, desconectó algún clúster, es decir, algo sucedió. Pero no nos interesa en absoluto lo que estaba allí y por qué. Es decir, ni siquiera consideramos tal problema.
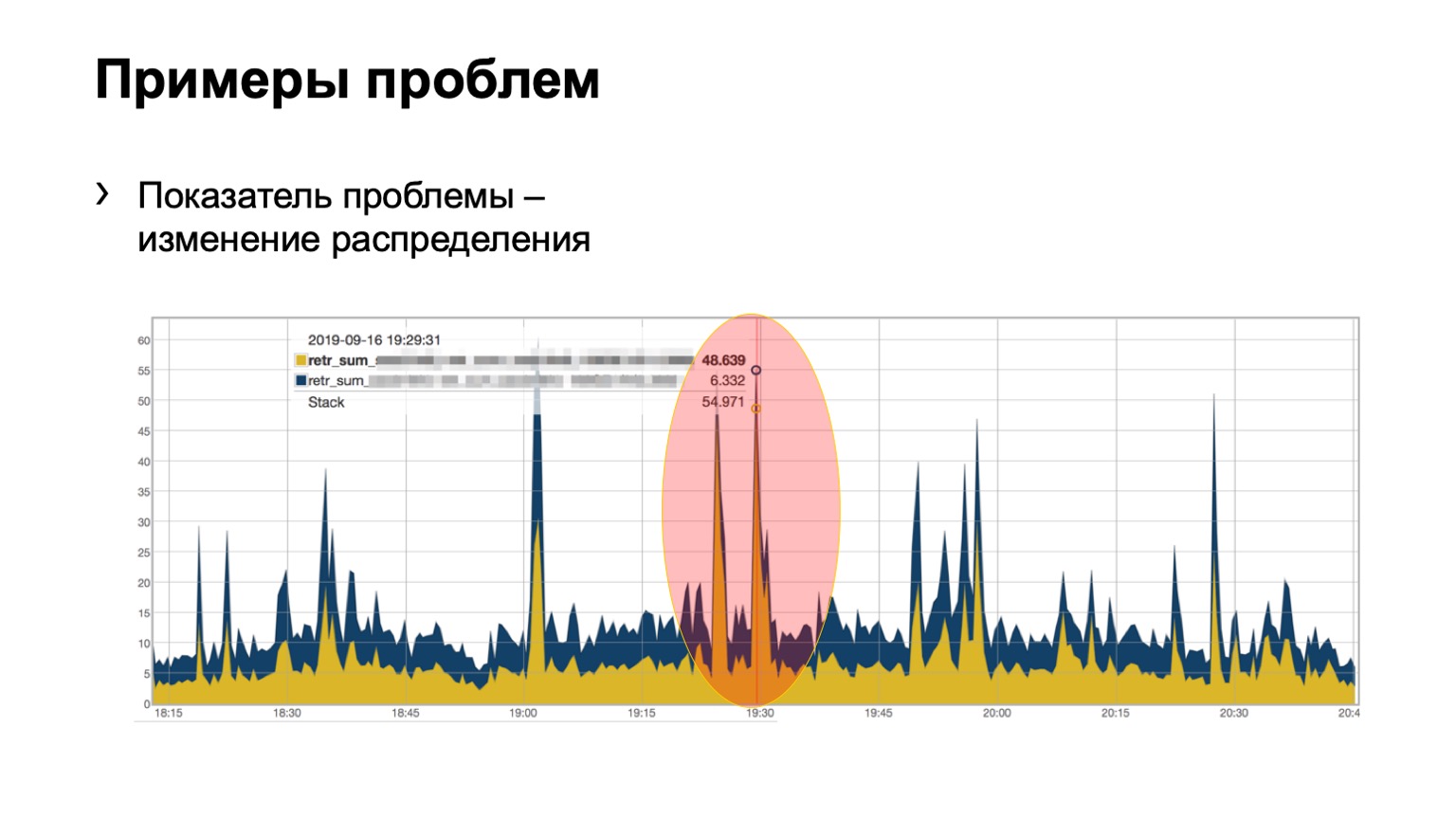
Y aquí, tal vez, no tan claramente, pero el problema es visible. Dos espinas en el módulo, 46 paquetes pintados volaron en uno y un poco en el segundo. Entendemos que tenemos un problema con algún tipo de columna vertebral en la red, tenemos que hacer algo al respecto.
¿Por qué hablé primero sobre el camino del dolor y el sufrimiento? Porque hay muchos problemas con tal solución. El problema principal es, por supuesto, el problema de cualquier monitoreo, esto es falso positivo. Falso positivo fue bastante. Principalmente debido al hecho de que usamos DSCP y generalmente estamos vinculados a QoS.

Descubrimos que los paquetes de otras personas vuelan en nuestra pintura y nos alertan sobre nuestro monitoreo. Es decir, creemos que esto es una retransmisión, y alguien más coloca sus paquetes allí y, en general, nos estropea la imagen. Naturalmente, comenzamos a comprender, encontramos muchos lugares donde pensábamos que funcionaba, pero en realidad no funciona de la manera en que pensamos. Por ejemplo, el tráfico que ingresa a la red aparentemente debería repintarse, el tráfico con la clase CS6 y CS7 en los internos no debería ingresar a nuestra red. Pero en algunos lugares hubo, digamos, defectos, y los tratamos con éxito.
Algunos fabricantes presentaron sorpresas en forma de contadores en la dirección de salida de dichos paquetes, y el chip funciona de tal manera que, de hecho, para procesar la lista de acceso saliente envuelve el tráfico nuevamente, mordiendo la mitad del ancho de banda del chip . Fue de 900 gigabits por chip, se convirtió en la mitad.
E hicimos algunas mejoras debido al hecho de que la configuración en el host puede ser diferente. Es decir, algún host puede enviar retransmisiones con más frecuencia, algunos host pueden con menos frecuencia, algunos dos, algunos cinco, y todo esto alerta nuestra supervisión, todo esto es falso positivo.
Primero, abandonamos la idea de pintar cada retransmisión TCP. Nos dimos cuenta de que, en principio, no necesitamos cada retransmisión para comprender dónde está el problema. Comenzamos a pintar solo SYN-retransmit. SYN es el primer paquete de la sesión, esto es suficiente para que recibamos una señal. También pintamos SYN-ACL.
De todos modos, dio algunos falsos positivos. Fuimos un poco más lejos. Comenzamos a pintar solo la primera retransmisión de SYN TCP en la sesión. Es decir, en realidad hay varios de ellos enviados, pintamos cada uno, solo uno comenzó a pintarse. Así que hemos llegado a lo que tenemos ahora.
En total, hay Netmon, hay agentes en los hosts que colorean la primera retransmisión SYN en la sesión, y contamos estas retransmisiones en cada dispositivo, en casi todos los enlaces de nuestra red.

Pero mirar con los ojos la imagen que solía mostrar no es muy conveniente. Es decir, no puede venderlo a un oficial de servicio, porque en cada sección debe evaluarlo todo con sus ojos. Y llegamos al hecho de que quiero tener una alerta. Quiero que se encienda una luz: un dispositivo tal o cual es un problema; Otro dispositivo es un problema.
Recordemos algunas estadísticas matemáticas. La idea con alerta es que cada dispositivo es esencialmente una canasta. Tenemos una probabilidad de éxito y una probabilidad de falla para cuatro dispositivos. La probabilidad de que la retransmisión llegue a la canasta, es decir, el éxito, es ¼. Resulta una distribución binomial.
¿Cuál es la dificultad de hacer una alerta aquí? El hecho de que no podamos hacer que los umbrales sean estáticos, no podemos decir: si llegan diez retransmisiones en un dispositivo y nueve en el otro, entonces no hay problema. Y si diez y cinco, entonces hay un problema. Porque si lo escalamos a mil PPS, esos datos ya no serán relevantes. 1000 PPS y 800 PPS entre diferentes dispositivos es definitivamente un problema.
No podemos establecer umbrales estáticos en PPS o bytes, no podemos establecerlos como un porcentaje, el mismo problema con ellos. Por lo tanto, necesitamos una solución que haga que este umbral sea más o menos dinámico, dependiendo de la cantidad de paquetes.
Y el encanto de la distribución binomial es que al aumentar el PPS tiende a ser normal, y para una distribución normal, ya podemos calcular la expectativa, la varianza y calcular el intervalo de confianza, lo cual hicimos. El intervalo de confianza para nosotros es 3NPQ, es decir, depende de la cantidad de paquetes a través del dispositivo. Como resultado, tenemos un umbral de cambio dinámico.
Así es como se ve nuestra señal en la imagen. Si algún dispositivo queda fuera de la distribución, levantamos una bandera, algo está mal.

¿Dónde queremos desarrollar más, qué queremos mejorar aquí, además de, por supuesto, la lucha contra los falsos positivos? En primer lugar, ¿estaríamos interesados en ver qué había en el momento del problema? Para hacer esto, tenemos una opción en el agente: Depuración. Podemos cargar exactamente lo que se retransmitió, es decir, un paquete de 5 tuplas, por ejemplo, en un recopilador separado, y luego mirarlo. Pero esto genera cierta carga en los hosts, por lo que a veces se nos prohíbe hacerlo. Queremos fijar ERSPAN y descargar dichos paquetes en el recopilador desde el hardware en sí, porque nadie nos prohíbe hacer esto en el hardware.
Dima Afanasyev
dijo cómo desarrollaremos nuestras fábricas, y uno de los puntos fue la transición de la fábrica MPLS a IPv6 solamente. ¿Qué nos da esto? MPLS tiene tres bits para el marcado de QoS. En IPv6, al menos seis. En este momento, solo se utilizan tres bits en nuestra red. Es decir, todavía tenemos tres bits más en los que podemos poner, de hecho, cualquier información del host.
Por ejemplo, ahora estamos pintando solo la primera retransmisión SYN de la sesión. Y podemos colorear el segundo bit, por ejemplo, si el paquete va a una red externa. Y podemos retransmitir, es decir, resaltar otra señal, que luego consideraremos por separado.
Además, la transición al diseño con edge pod, cuando hemos realizado DCI en algún lugar en particular, nos amenaza con el hecho de que en este lugar podemos controlar con mayor precisión nuestro dominio diffserv. Es decir, volver a pintar y hacer algo con pinturas para cortar el falso positivo.
Como resultado, hacer todo lo anterior resultó ser bastante doloroso, pero interesante. No había nada de qué preocuparse. Nosotros, de hecho, hemos desarrollado una solución que todos pueden usar. Se prueba en prácticamente todos los proveedores, funciona, no es difícil. Y realmente muestra qué dispositivo en la red hay un problema. Por lo tanto, mi mensaje es: no tengas miedo de hacer lo mismo y deja que tu monitoreo permanezca verde. Gracias por escuchar