Por más de 20 años, hemos estado viendo páginas web usando el protocolo HTTP. La mayoría de los usuarios no piensan en absoluto sobre qué es y cómo funciona. Otros saben que en algún lugar bajo HTTP hay TLS, y debajo hay TCP, bajo el cual IP, etc. Y el tercero, los herejes, creen que TCP es el siglo pasado, quieren algo más rápido, más confiable y más seguro. Pero en sus intentos de inventar un nuevo protocolo ideal, volvieron a las tecnologías de los años 80 y están tratando de construir su nuevo mundo valiente sobre ellos.

Un poco de historia: HTTP / 1.1
En 1997, el protocolo de intercambio de texto HTTP versión 1.1 ganó su RFC. En ese momento, los navegadores utilizaron el protocolo durante varios años, y el nuevo estándar duró otros quince. El protocolo funcionó solo sobre una base de solicitud-respuesta y estaba destinado principalmente a transmitir información textual.
HTTP fue diseñado para funcionar sobre el protocolo TCP, lo que garantiza la entrega confiable de paquetes al destino. TCP se basa en establecer y mantener una conexión confiable entre puntos finales y segmentar el tráfico. Los segmentos tienen su propio número de secuencia y suma de verificación. Si de repente uno de los segmentos no viene o viene con la suma de verificación incorrecta, la transmisión se detendrá hasta que se restablezca el segmento perdido.
En HTTP / 1.0, la conexión TCP se cerró después de cada solicitud. Fue extremadamente derrochador desde Establecer una conexión TCP (3-Way-Handshake) no es un proceso rápido. HTTP / 1.1 introdujo el mecanismo keep-alive, que le permite reutilizar una única conexión para múltiples solicitudes. Sin embargo, dado que puede convertirse fácilmente en un cuello de botella, se permiten múltiples conexiones TCP / IP al mismo host en diferentes implementaciones HTTP / 1.1. Por ejemplo, en Chrome y en versiones recientes de Firefox, se permiten hasta seis conexiones.

También se suponía que el cifrado se dejaba a otros protocolos, y para esto, el protocolo TLS se usó a través de TCP, que protegía de manera confiable los datos, pero aumentó aún más el tiempo requerido para establecer una conexión. Como resultado, el proceso de apretón de manos comenzó a verse así:
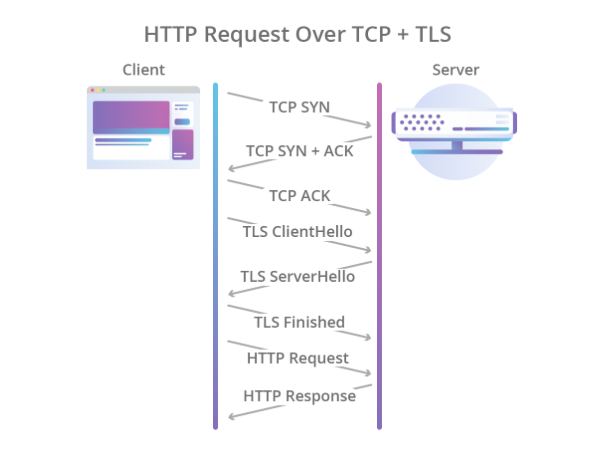 Ilustración de Cloudflare
Ilustración de CloudflarePor lo tanto, HTTP / 1.1 tuvo una serie de problemas:
- Configuración de conexión lenta.
- Se utiliza una conexión TCP para una solicitud, lo que significa que el resto de las solicitudes deben encontrar otra conexión o esperar hasta que la solicitud actual la libere.
- Solo se admite el modelo de extracción. No hay nada en el estándar sobre server-push.
- Los encabezados se transmiten en texto.
Si el empuje del servidor se implementa de alguna manera usando el protocolo WebSocket, entonces el resto de los problemas tuvieron que ser tratados de manera más radical.
Un poco de modernidad: HTTP / 2
En 2012, el trabajo sobre el protocolo SPDY (pronunciado "velocidad") comenzó en las entrañas de Google. El protocolo fue diseñado para resolver los problemas básicos de HTTP / 1.1 y al mismo tiempo tenía que mantener la compatibilidad con versiones anteriores. En 2015, el grupo de trabajo IETF introdujo la especificación HTTP / 2 basada en el protocolo SPDY. Estas son las diferencias en HTTP / 2:
- Serialización binaria.
- Multiplexar múltiples solicitudes HTTP en una sola conexión TCP.
- Servidor-empuje fuera de la caja (sin WebSocket).
El protocolo fue un gran paso adelante.
Supera ampliamente
a la primera versión y no requiere la creación de varias conexiones TCP: todas las solicitudes a un host se multiplexan en una. Es decir, en una conexión hay varias llamadas secuencias, cada una de las cuales tiene su propia ID. El bono es un servidor en caja.
Sin embargo, la multiplicación conduce a otro problema fundamental. Imagine que ejecutamos asincrónicamente 5 solicitudes a un servidor. Cuando se utiliza HTTP / 2, todas estas solicitudes se ejecutarán dentro de la misma conexión TCP, lo que significa que si uno de los segmentos de cualquier solicitud se pierde o llega incorrectamente, la transmisión de todas las solicitudes y respuestas se detendrá hasta que se restablezca el segmento perdido. Obviamente, cuanto peor es la calidad de la conexión, más lento funciona HTTP / 2.
Según Daniel Stenberg , en una situación en la que los paquetes perdidos representan el 2% de todos, HTTP / 1.1 en un navegador funciona mejor que HTTP / 2 debido al hecho de que abre 6 conexiones, y no una.
Este problema se llama "bloqueo de cabecera de línea" y, desafortunadamente, no es posible resolverlo usando TCP.
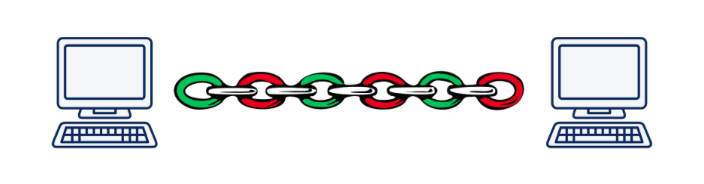 Ilustración de Daniel Steinberg
Ilustración de Daniel SteinbergComo resultado, los desarrolladores del estándar HTTP / 2 hicieron un gran trabajo e hicieron casi todo lo que se podía hacer a nivel de aplicación del modelo OSI. Es hora de bajar al nivel de transporte e inventar un nuevo protocolo de transporte.
Necesitamos un nuevo protocolo: UDP vs TCP
Rápidamente se hizo evidente que introducir un protocolo de capa de transporte completamente nuevo es una tarea sin solución en las realidades de hoy. El hecho es que las glándulas o cajas intermedias (enrutadores, cortafuegos, servidores NAT ...) conocen el nivel de transporte, y enseñarles algo nuevo es una tarea extremadamente difícil. Además, el soporte para los protocolos de transporte está conectado al núcleo de los sistemas operativos, y los núcleos también cambian no tan voluntariamente.
Y aquí uno podría darse por vencido y decir "Nosotros, por supuesto, inventaremos un nuevo HTTP / 3 con preferencia y cortesanas, pero se implementará en 10-15 años (después de este tiempo, la mayoría de las glándulas serán reemplazadas)", pero hay una más, no la mayoría opción obvia: usar el protocolo UDP. Sí, sí, el mismo protocolo según el cual lanzamos archivos en una LAN a fines de los noventa y principios de cero. Casi todas las piezas de hierro de hoy en día saben cómo trabajar con él.
¿Cuáles son las ventajas de UDP sobre TCP? En primer lugar, no tenemos una sesión de nivel de transporte que el hierro conozca. Esto nos permite determinar la sesión en los puntos finales nosotros mismos y resolver los conflictos que surjan allí. Es decir, no estamos limitados a una o varias sesiones (como en TCP), pero podemos crearlas todo lo que necesitemos. En segundo lugar, la transmisión de datos a través de UDP es más rápida que a través de TCP. Por lo tanto, en teoría, podemos superar el límite de velocidad actual alcanzado en HTTP / 2.
Sin embargo, UDP no garantiza una transmisión de datos confiable. De hecho, simplemente enviamos paquetes, con la esperanza de que se reciban en el otro extremo. No recibió? Bueno, no hubo suerte ... Esto fue suficiente para transmitir video para adultos, pero para cosas más serias necesitas confiabilidad, lo que significa que tienes que enrollar algo más sobre UDP.
Al igual que con HTTP / 2, el trabajo para crear un nuevo protocolo comenzó en Google en 2012, es decir, aproximadamente al mismo tiempo que el inicio del trabajo en SPDY. En 2013, Jim Roskind presentó
el protocolo QUIC (Quick UDP Internet Connections) al público en general, y ya en 2015 se introdujo Internet Draft para estandarizar el IETF. Ya en ese momento, el protocolo desarrollado por Roskind en Google era muy diferente del estándar, por lo que la versión de Google se llamaba gQUIC.
¿Qué es QUIC?
Primero, como ya se mencionó, este es un contenedor sobre UDP. La conexión QUIC se eleva por encima de UDP, en la que, por analogía con HTTP / 2, pueden existir varias secuencias. Estas secuencias solo existen en los puntos finales y se sirven de forma independiente. Si la pérdida de paquetes se produjo en una secuencia, no afectará a las demás de ninguna manera.
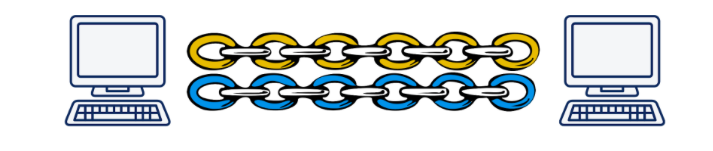 Ilustración de Daniel Steinberg
Ilustración de Daniel SteinbergEn segundo lugar, el cifrado ahora se implementa no en un nivel separado, sino que se incluye en el protocolo. Esto le permite establecer una conexión e intercambiar claves públicas en un único protocolo de enlace, y también le permite utilizar el complicado mecanismo de protocolo de enlace 0-RTT y, en general, evitar retrasos en el intercambio de manos. Además, los paquetes de datos individuales ahora se pueden cifrar. Esto le permite no esperar la finalización de la recepción de datos de la transmisión, sino descifrar los paquetes recibidos de forma independiente. Este modo de operación no era posible en absoluto en TCP, porque TLS y TCP funcionaban independientemente el uno del otro, y TLS no podía saber en qué partes se cortarían los datos TCP. Y, por lo tanto, no pude preparar mis segmentos para que encajen en los segmentos TCP uno a uno y puedan descifrarse de forma independiente. Todas estas mejoras permiten que QUIC reduzca la latencia en comparación con TCP.

En tercer lugar, el concepto de transmisiones fáciles le permite desvincular la conexión de la dirección IP del cliente. Esto es importante, por ejemplo, cuando un cliente cambia de un punto de acceso Wi-Fi a otro, cambiando su IP. En este caso, cuando se usa TCP, se produce un largo proceso durante el cual las conexiones TCP existentes se caen en el tiempo de espera y se crean nuevas conexiones desde la nueva IP. En el caso de QUIC, el cliente simplemente continúa enviando paquetes desde la nueva IP al servidor con la ID de flujo anterior. Porque Stream ID ahora es único y no se reutiliza, el servidor comprende que el cliente ha cambiado la dirección IP, envía los paquetes perdidos y continúa la comunicación a la nueva dirección.
Cuarto, QUIC se implementa a nivel de aplicación, no en el sistema operativo. Esto, por un lado, permite cambios más rápidos en el protocolo, ya que Para obtener una actualización, simplemente actualice la biblioteca, en lugar de esperar una nueva versión del sistema operativo. Por otro lado, esto conduce a un fuerte aumento en el consumo del procesador.
Y finalmente, los titulares. La compresión de encabezado solo se refiere a puntos que difieren en QUIC y gQUIC. No veo ninguna razón para dedicar mucho tiempo a esto, solo puedo decir que en la versión presentada para la estandarización, la compresión del encabezado se hizo lo más similar posible a la compresión del encabezado en HTTP / 2. Más detalles se pueden leer
aquí .
¿Cuánto más rápido es?
Esta es una pregunta difícil. El hecho es que si bien no tenemos un estándar, no hay nada especial para medir. Quizás las únicas estadísticas que tenemos son las estadísticas de Google, que ha estado usando gQUIC desde 2013 y en 2016
informó al IETF que alrededor del 90% del tráfico que va a sus servidores desde el navegador Chrome ahora usa QUIC. En la misma presentación, informan que a través de gQUIC, las páginas se cargan aproximadamente un 5% más rápido, y la transmisión de video tiene un 30% menos de congelaciones en comparación con TCP.
En 2017, un grupo de investigadores dirigido por Arash Molavi Kakhki publicó un
gran trabajo sobre el estudio del rendimiento de gQUIC en comparación con TCP.
El estudio reveló varias debilidades de gQUIC, como la inestabilidad en la mezcla de paquetes de red, la injusticia en la capacidad del canal y la transferencia más lenta de objetos pequeños (hasta 10 kb). Sin embargo, este último puede compensarse por usar el 0-RTT. En todos los demás casos investigados, gQUIC mostró un aumento en la velocidad en comparación con TCP. Es difícil hablar de números específicos. Es mejor leer
el estudio en sí o una
breve publicación .
Aquí hay que decir que estos datos son específicamente sobre gQUIC, y son irrelevantes para el estándar que se está desarrollando. Qué sucederá con QUIC: hasta ahora, el misterio está detrás de siete sellos, pero existe la esperanza de que las debilidades identificadas por gQUIC se tengan en cuenta y se corrijan.
Un pequeño futuro: ¿qué pasa con HTTP / 3?
Y aquí todo está claro: la API no cambiará de ninguna manera. Todo permanecerá exactamente igual que en HTTP / 2. Bueno, si la API sigue siendo la misma, la transición a HTTP / 3 deberá decidirse utilizando la última versión de la biblioteca que admite el transporte a través de QUIC en el back-end. Es cierto que durante mucho tiempo todavía tiene que mantener el respaldo de las versiones anteriores de HTTP, porque Internet ahora no está listo para un cambio completo a UDP.
Quien ya esta apoyando
Aquí hay una
lista de implementaciones QUIC existentes. A pesar de la falta de un estándar, la lista no es mala.
Actualmente, ningún navegador admite QUIC en la versión. Recientemente hubo información de que Chrome incluía soporte HTTP / 3, pero hasta ahora solo en Canarias.
De los backends, HTTP / 3 solo es compatible con
Caddy y
Cloudflare , pero hasta ahora de forma experimental. NGINX
anunció a fines de la primavera de 2019 que habían comenzado a trabajar en el soporte HTTP / 3, pero aún no lo habían completado.
Cuales son los problemas
Vivimos en el mundo real, donde ni una sola gran tecnología puede llegar a las masas sin encontrar resistencia, y QUIC no es una excepción.
Lo que es más importante, debe explicar de alguna manera al navegador que "https: //" ya no es un hecho que conduce al puerto TCP 443. Puede que no haya TCP en absoluto. Para hacer esto, use el encabezado Alt-Svc. Permite que el navegador sea informado de que este sitio web también está disponible en dicho protocolo en tal dirección. En teoría, esto debería funcionar como un reloj, pero en la práctica, nos topamos con el hecho de que UDP puede, por ejemplo, deshabilitarse en el firewall para evitar ataques DDoS.
Pero incluso si UDP no está prohibido, el cliente puede estar detrás de un enrutador NAT que está configurado para mantener una sesión TCP por dirección IP, como usamos UDP, en el que no hay sesión de hardware, NAT no mantendrá la conexión y la sesión QUIC
siempre finalizará .
Todos estos problemas están relacionados con el hecho de que UDP no se utilizó anteriormente para transmitir contenido de Internet, y los fabricantes de hardware no podrían haber previsto que esto sucedería alguna vez. Del mismo modo, los administradores aún no entienden cómo configurar adecuadamente sus redes para QUIC. Esta situación cambiará lentamente y, en cualquier caso, dichos cambios tomarán menos tiempo que la introducción de un nuevo protocolo de capa de transporte.
Además, como ya se describió, QUIC aumenta en gran medida la utilización del procesador. Daniel Stenberg
calificó el crecimiento en el procesador hasta tres veces.
Cuando viene HTTP / 3
Quieren adoptar el estándar para mayo de 2020, pero dado que los documentos programados para julio de 2019 permanecen sin terminar, podemos decir que la fecha probablemente se posponga.
Bueno, Google ha estado utilizando su implementación de gQUIC desde 2013. Si observa la solicitud HTTP que se envía al motor de búsqueda de Google, puede ver esto:

Conclusiones
QUIC ahora parece una tecnología bastante cruda, pero muy prometedora. Teniendo en cuenta que en los últimos 20 años, todas las optimizaciones de los protocolos de la capa de transporte relacionadas principalmente con TCP, QUIC, que en la mayoría de los casos gana en rendimiento, ahora se ven extremadamente bien.
Sin embargo, todavía hay problemas sin resolver que deben abordarse en los próximos años. El proceso puede retrasarse debido al hecho de que el hardware está involucrado, lo que a nadie le gusta actualizar, pero sin embargo, todos los problemas parecen bastante solucionables, y tarde o temprano todos tendremos HTTP / 3.
¡El futuro no está lejos!