El registro es una parte importante de cualquier aplicación. Cualquier sistema de registro pasa por tres pasos evolutivos principales. El primero se envía a la consola, el segundo es iniciar sesión en un archivo y la apariencia de un marco para el registro estructurado, y el tercero es el registro distribuido o la recopilación de registros de varios servicios en un solo centro.
Si el registro está bien organizado, le permite comprender qué, cuándo y cómo sale mal, y transmitir la información necesaria a las personas que tienen que corregir estos errores. Para un sistema en el que se envían 100 mil mensajes por segundo en 10 centros de datos en 190 países, y 350 ingenieros implementan algo todos los días, el sistema de registro es especialmente importante.
 Ivan Letenko
Ivan Letenko es líder de equipo y desarrollador en Infobip. Para resolver el problema del procesamiento centralizado y el seguimiento de registros en la arquitectura de microservicios bajo cargas tan enormes, la compañía probó varias combinaciones de la pila ELK, Graylog, Neo4j y MongoDB. Como resultado, después de mucho rastrillo, escribieron su servicio de registro en Elasticsearch, y PostgreSQL fue tomado como una base de datos para obtener información adicional.
Debajo del gato en detalle, con ejemplos y gráficos: la arquitectura y la evolución del sistema, rastrillos, registro y rastreo, métricas y monitoreo, la práctica de trabajar con clusters de Elasticsearch y administrarlos con recursos limitados.
Para presentarle el contexto, le contaré un poco sobre la empresa. Ayudamos a las organizaciones de clientes a enviar mensajes a sus clientes: mensajes de un servicio de taxi, SMS de un banco sobre la cancelación o una contraseña de un solo uso al ingresar VC.
350 millones de mensajes pasan a través de nosotros todos los días para clientes en 190 países. Cada uno de ellos aceptamos, procesamos, facturamos, enrutamos, adaptamos, enviamos a los operadores y, en la dirección opuesta, procesamos informes de entrega y generamos análisis.
Para que todo esto funcione en tales volúmenes, tenemos:
- 36 centros de datos en todo el mundo;
- Más de 5000 máquinas virtuales
- Más de 350 ingenieros;
- Más de 730 microservicios diferentes.
Este es un sistema complejo, y ni un solo gurú puede comprender la escala completa sin ayuda. Uno de los principales objetivos de nuestra empresa es la alta velocidad de entrega de nuevas funciones y lanzamientos para empresas. En este caso, todo debería funcionar y no caerse. Estamos trabajando en esto: 40,000 implementaciones en 2017, 80,000 en 2018, 300 implementaciones por día.
Tenemos 350 ingenieros, resulta que
cada ingeniero implementa algo diariamente . Hace solo unos años, solo una persona en una empresa tenía esa productividad: Kreshimir, nuestro ingeniero principal. Pero nos aseguramos de que cada ingeniero se sienta tan seguro como Kresimir cuando presiona el botón Implementar o ejecuta un script.
¿Qué se necesita para esto? En primer lugar, la
confianza de que entendemos lo que está sucediendo en el sistema y en qué estado se encuentra. La confianza está dada por la capacidad de hacer una pregunta al sistema y descubrir la causa del problema durante el incidente y durante el desarrollo del código.
Para lograr esta confianza, invertimos en
observabilidad . Tradicionalmente, este término combina tres componentes:
Hablaremos de esto. En primer lugar, echemos un vistazo a nuestra solución para el registro, pero también abordaremos métricas y rastreos.
Evolución
Casi cualquier aplicación o sistema de registro, incluido el nuestro, pasa por varias etapas de evolución.
El primer paso es dar
salida a la consola .
Segundo: comenzamos
a escribir registros en un archivo , aparece un
marco para la salida estructurada a un archivo. Usualmente usamos Logback porque vivimos en la JVM. En esta etapa, aparece el registro estructurado en el archivo, entendiendo que los diferentes registros deben tener diferentes niveles, advertencias y errores.
Tan pronto
como haya varias instancias de nuestro servicio o diferentes servicios, aparece la tarea de
acceso centralizado a los registros para desarrolladores y soporte. Pasamos al registro distribuido: combinamos varios servicios en un solo servicio de registro.
Registro distribuido
La opción más famosa es la pila ELK: Elasticsearch, Logstash y Kibana, pero elegimos
Graylog . Tiene una interfaz genial que está orientada al registro. Las alarmas ya vienen de la caja en la versión gratuita, que no está en Kibana, por ejemplo. Para nosotros, esta es una excelente opción en términos de registros, y debajo del capó está el mismo Elasticsearch.
 En Graylog, puede crear alertas, gráficos como Kibana e incluso registrar métricas.
En Graylog, puede crear alertas, gráficos como Kibana e incluso registrar métricas.Los problemas
Nuestra empresa estaba creciendo y, en algún momento, quedó claro que algo estaba mal con Graylog.
Carga excesiva Hubo problemas de rendimiento. Muchos desarrolladores comenzaron a usar las características interesantes de Graylog: crearon métricas y paneles que realizan la agregación de datos. No es la mejor opción para crear análisis complejos en el clúster Elasticsearch, que se encuentra bajo una gran carga de grabación.
Colisiones Hay muchos equipos, no hay un esquema único. Tradicionalmente, cuando una ID golpeó Graylog por primera vez como larga, la asignación se produjo automáticamente. Si otro equipo decide que debe escribirse el UUID como una cadena, esto romperá el sistema.
Primera decisión
Registros de aplicaciones y registros de comunicación separados . Los diferentes registros tienen diferentes escenarios y métodos de aplicación. Hay, por ejemplo, registros de aplicaciones para los que diferentes equipos tienen diferentes requisitos para diferentes parámetros: por el tiempo de almacenamiento en el sistema, por la velocidad de búsqueda.
Por lo tanto, lo primero que hicimos fue separar los registros de aplicaciones y los registros de comunicación. El segundo tipo son los registros importantes que almacenan información sobre la interacción de nuestra plataforma con el mundo exterior y sobre la interacción dentro de la plataforma. Hablaremos más sobre esto.
Reemplazó una parte sustancial de los registros con métricas . En nuestra empresa, la opción estándar es Prometheus y Grafana. Algunos equipos usan otras soluciones. Pero es importante que eliminemos una gran cantidad de paneles con agregaciones dentro de Graylog, que transfiramos todo a Prometheus y Grafana. Esto facilitó enormemente la carga en los servidores.
Veamos los escenarios para aplicar registros, métricas y rastreos.
Registros
Alta dimensionalidad, depuración e investigación . ¿Qué son buenos registros?
Los registros son los eventos que registramos.
Pueden tener una gran dimensión: puede registrar ID de solicitud, ID de usuario, atributos de solicitud y otros datos, cuya dimensión no está limitada. También son buenos para la depuración y la investigación, para hacer preguntas al sistema sobre lo que sucedió y buscar causas y efectos.
Métricas
Baja dimensionalidad, agregación, monitoreo y alertas . Bajo el capó de todos los sistemas de recopilación métrica se encuentran las bases de datos de series temporales. Estas bases de datos hacen un excelente trabajo de agregación, por lo que las métricas son adecuadas para la agregación, el monitoreo y la creación de alertas.
Las métricas son muy sensibles a la dimensión de datos.
Para las métricas, la dimensión de los datos no debe exceder mil. Si agregamos algunos ID de solicitud, en los cuales el tamaño de los valores no está limitado, rápidamente encontraremos problemas serios. Ya hemos pisado este rastrillo.
Correlación y traza
Los registros deben estar correlacionados.
Los registros estructurados no son suficientes para que podamos buscar convenientemente por datos. Debe haber campos con ciertos valores: ID de solicitud, ID de usuario, otros datos de los servicios de los que provienen los registros.
La solución tradicional es asignar una identificación única a la transacción (registro) en la entrada al sistema. Luego, esta ID (contexto) se reenvía a través de todo el sistema a través de una cadena de llamadas dentro de un servicio o entre servicios.
 Correlación y rastreo.
Correlación y rastreo.Hay términos bien establecidos. La traza se divide en tramos y demuestra la pila de llamadas de un servicio en relación con otro, un método en relación con otro en relación con la línea de tiempo. Puede rastrear claramente la ruta del mensaje, todos los tiempos.
Primero usamos Zipkin. Ya en 2015, teníamos una Prueba de concepto (proyecto piloto) de estas soluciones.
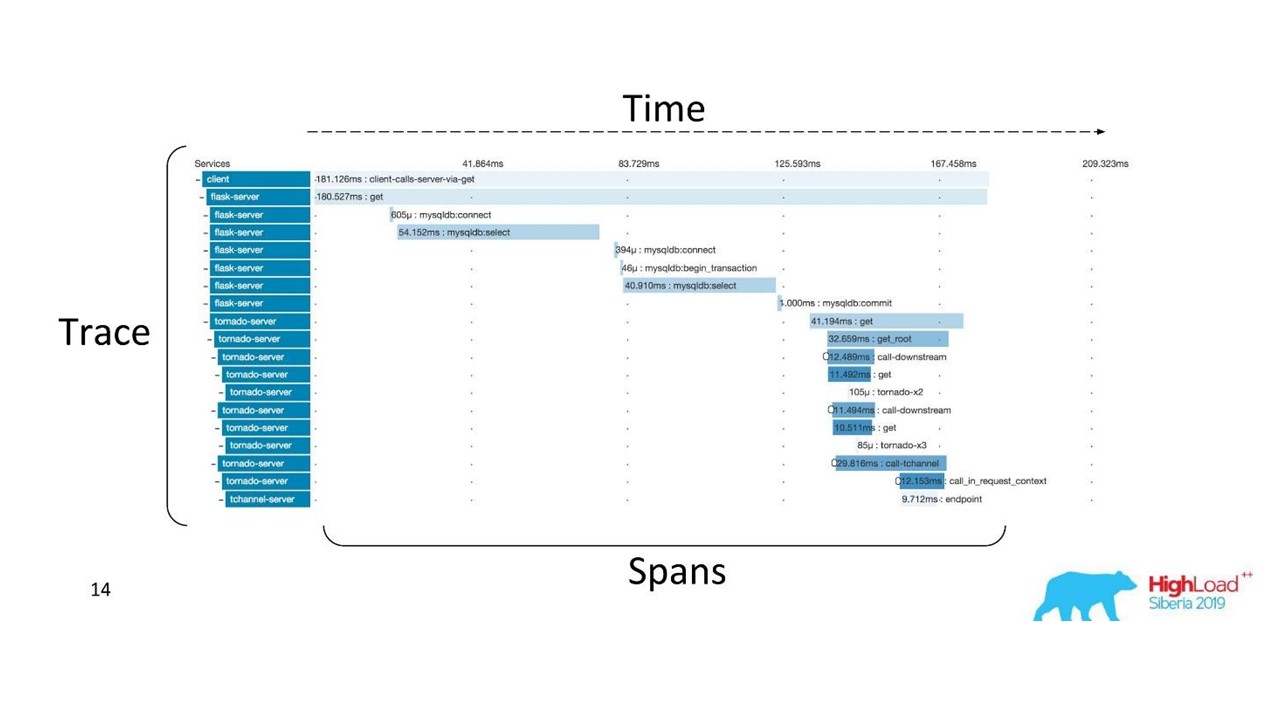 Traza distribuida
Traza distribuidaPara obtener esa imagen, el
código debe ser instrumentado . Si ya está trabajando con una base de código que existe, debe revisarla; requiere cambios.
Para obtener una imagen completa y beneficiarse de los rastros, debe
instrumentar todos los servicios de la cadena , y no solo un servicio en el que esté trabajando actualmente.
Esta es una herramienta poderosa, pero requiere importantes costos de administración y hardware, por lo que cambiamos de Zipkin a otra solución, que es proporcionada por "como servicio".
Informes de entrega
Los registros deben estar correlacionados. Las huellas también deben estar correlacionadas. Necesitamos una identificación única, un contexto común que se pueda reenviar a través de la cadena de llamadas. Pero a menudo esto no es posible: la
correlación ocurre dentro del sistema como resultado de su funcionamiento . Cuando comenzamos una o más transacciones, todavía no sabemos si son parte de un solo todo grande.
Considere el primer ejemplo.
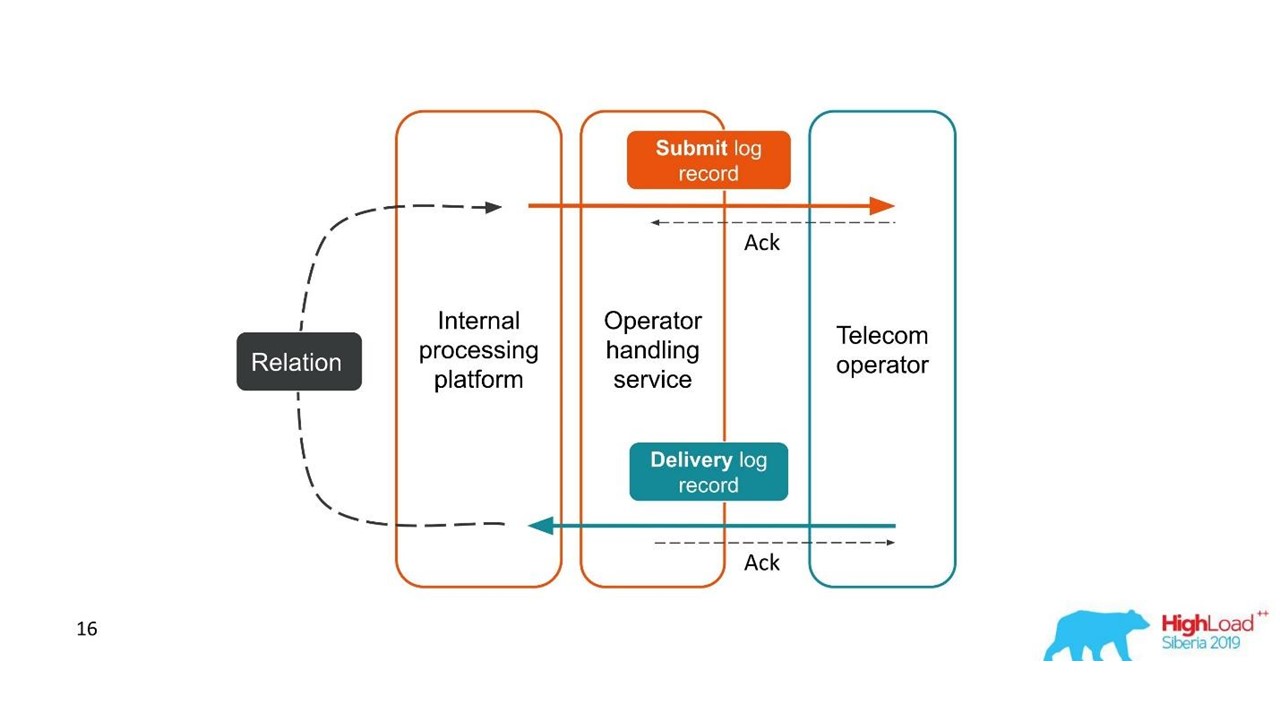 Informes de entrega.
Informes de entrega.- El cliente envió una solicitud de mensaje y nuestra plataforma interna lo procesó.
- El servicio, que interactúa con el operador, envió este mensaje al operador: apareció una entrada en el sistema de registro.
- Más tarde, el operador nos envía un informe de entrega.
- El servicio de procesamiento no sabe a qué mensaje se refiere este informe de entrega. Esta relación se crea más adelante en nuestra plataforma.
Dos transacciones relacionadas son partes de una sola transacción completa. Esta información es muy importante para los ingenieros de soporte y los desarrolladores de integración. Pero esto es completamente imposible de ver en función de un solo rastro o una sola identificación.
El segundo caso es similar: el cliente nos envía un mensaje en un paquete grande, luego los desarmamos, también regresan en lotes. El número de paquetes puede incluso variar, pero luego se combinan todos.
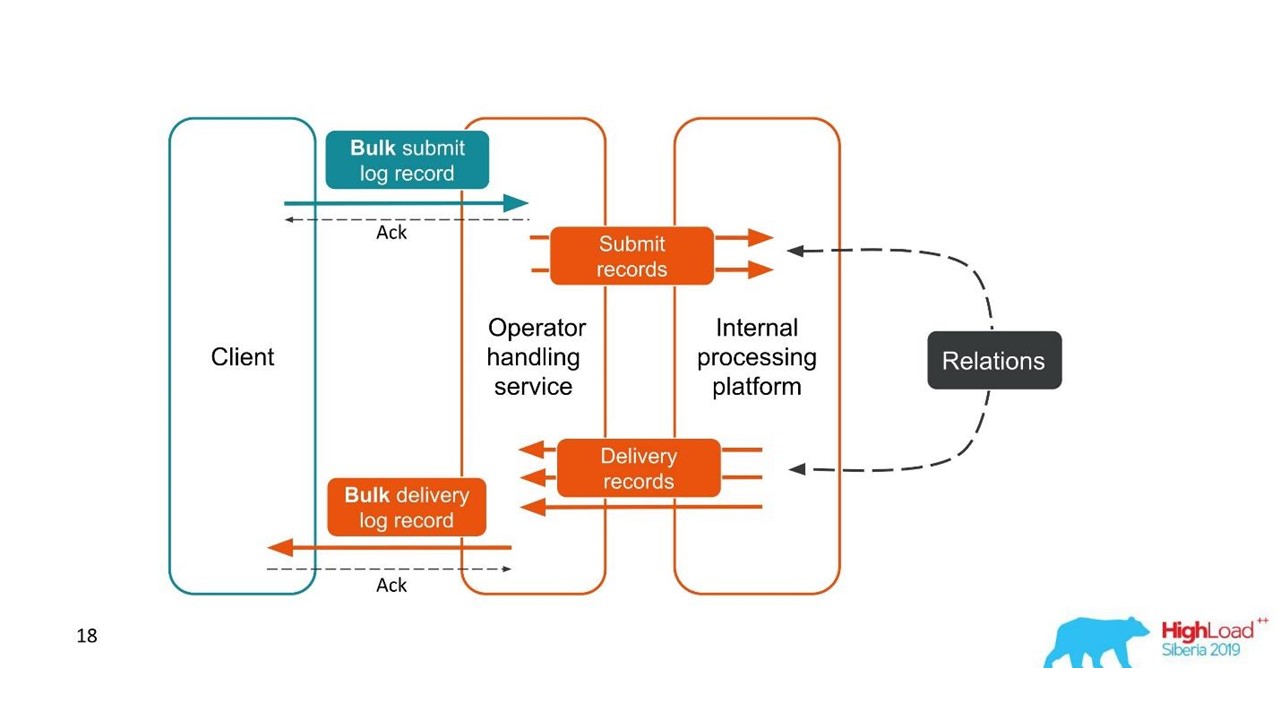
Desde el punto de vista del cliente, envió un mensaje y recibió una respuesta. Pero obtuvimos varias transacciones independientes que deben combinarse. Resulta una relación de uno a muchos, y con un informe de entrega, uno a uno. Esto es esencialmente un gráfico.
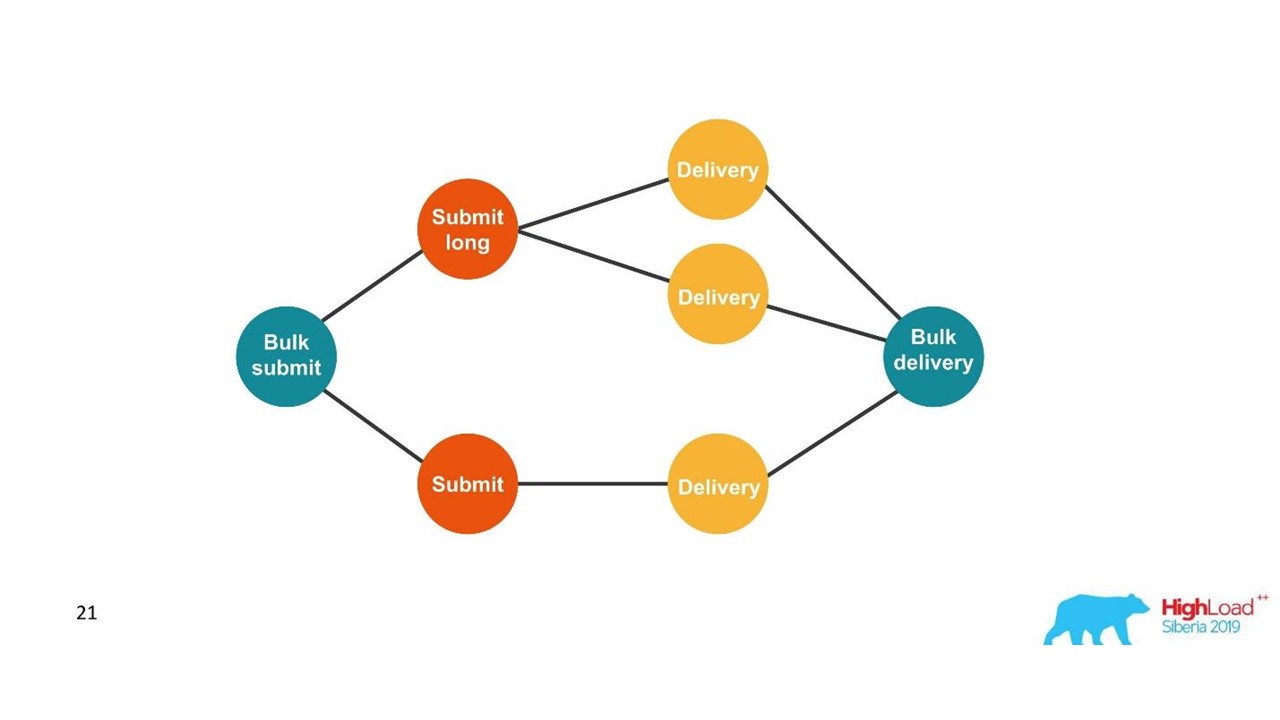 Estamos construyendo un gráfico.
Estamos construyendo un gráfico.Una vez que vemos un gráfico, una opción adecuada son las bases de datos de gráficos, por ejemplo, Neo4j. La elección fue obvia porque Neo4j regala camisetas geniales y libros gratis en las conferencias.
Neo4j
Implementamos Prueba de concepto: un host de 16 núcleos que podría procesar un gráfico de 100 millones de nodos y 150 millones de enlaces. El gráfico ocupaba solo 15 GB de disco, entonces nos convenía.
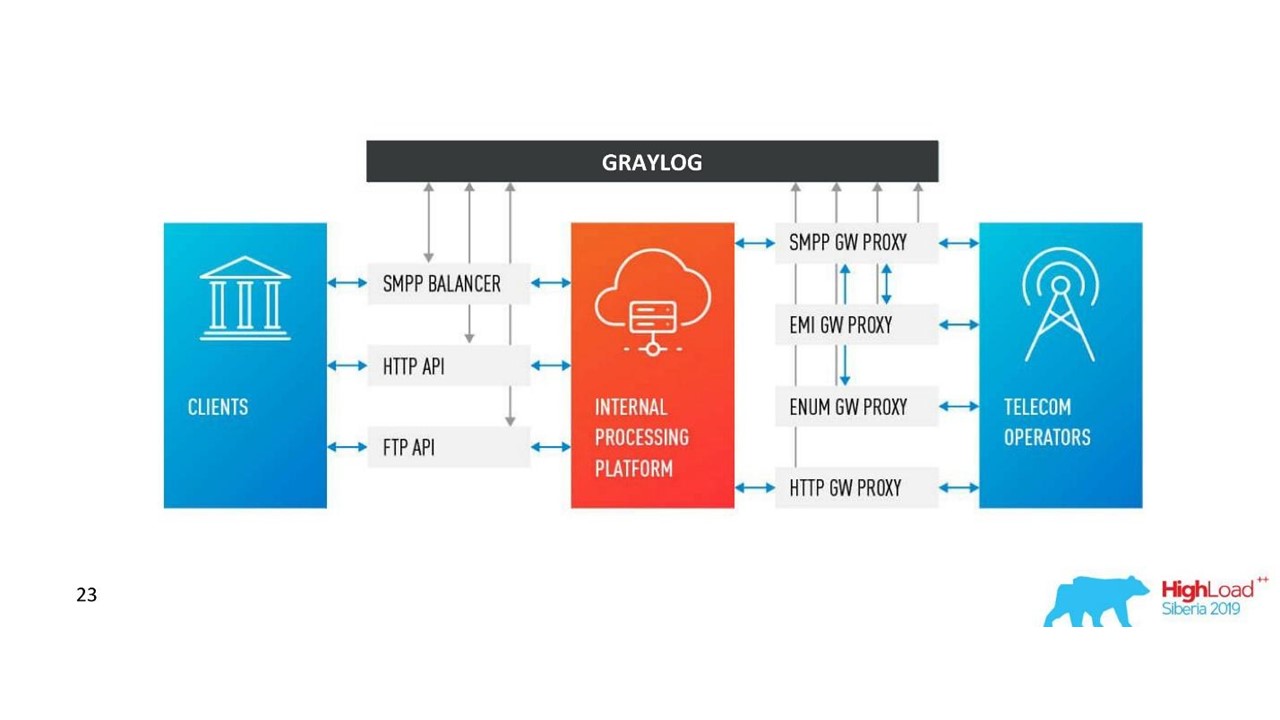 Nuestra decision. Arquitectura de registro.
Nuestra decision. Arquitectura de registro.Además de Neo4j, ahora tenemos una interfaz simple para ver registros relacionados. Con él, los ingenieros ven la imagen completa.
Pero bastante rápido, nos decepcionamos en esta base de datos.
Problemas con Neo4j
Rotación de datos . Tenemos volúmenes potentes y los datos deben rotarse. Pero cuando se elimina un nodo de Neo4j, los datos del disco no se borran. Tuve que construir una solución compleja y reconstruir completamente los gráficos.
Rendimiento Todas las bases de datos de gráficos son de solo lectura. En la grabación, el rendimiento es notablemente menor. Nuestro caso es todo lo contrario: escribimos mucho y leemos relativamente raramente; estas son unidades de solicitudes por segundo o incluso por minuto.
Alta disponibilidad y análisis de conglomerados por una tarifa . En nuestra escala, esto se traduce en costos decentes.
Por lo tanto, fuimos por el otro lado.
Solución con PostgreSQL
Decidimos que, dado que raramente leemos, el gráfico se puede construir sobre la marcha cuando se lee. Por lo tanto, en la base de datos relacional PostgreSQL almacenamos la lista de adyacencia de nuestros ID en forma de una placa simple con dos columnas y un índice en ambas. Cuando llega la solicitud, omitimos el gráfico de conectividad utilizando el algoritmo DFS familiar (recorrido de profundidad) y obtenemos todas las ID asociadas. Pero esto es necesario.
La rotación de datos también es fácil de resolver. Para cada día comenzamos un nuevo plato y después de unos días cuando llegue el momento, lo eliminamos y publicamos los datos. Una solución simple
Ahora tenemos 850 millones de conexiones en PostgreSQL, ocupan 100 GB de disco. Escribimos allí a una velocidad de 30 mil por segundo, y para esto en la base de datos solo hay dos máquinas virtuales con 2 CPU y 6 GB de RAM. Según sea necesario, PostgreSQL puede escribir largos rápidamente.
Todavía hay máquinas pequeñas para el servicio en sí, que giran y controlan.
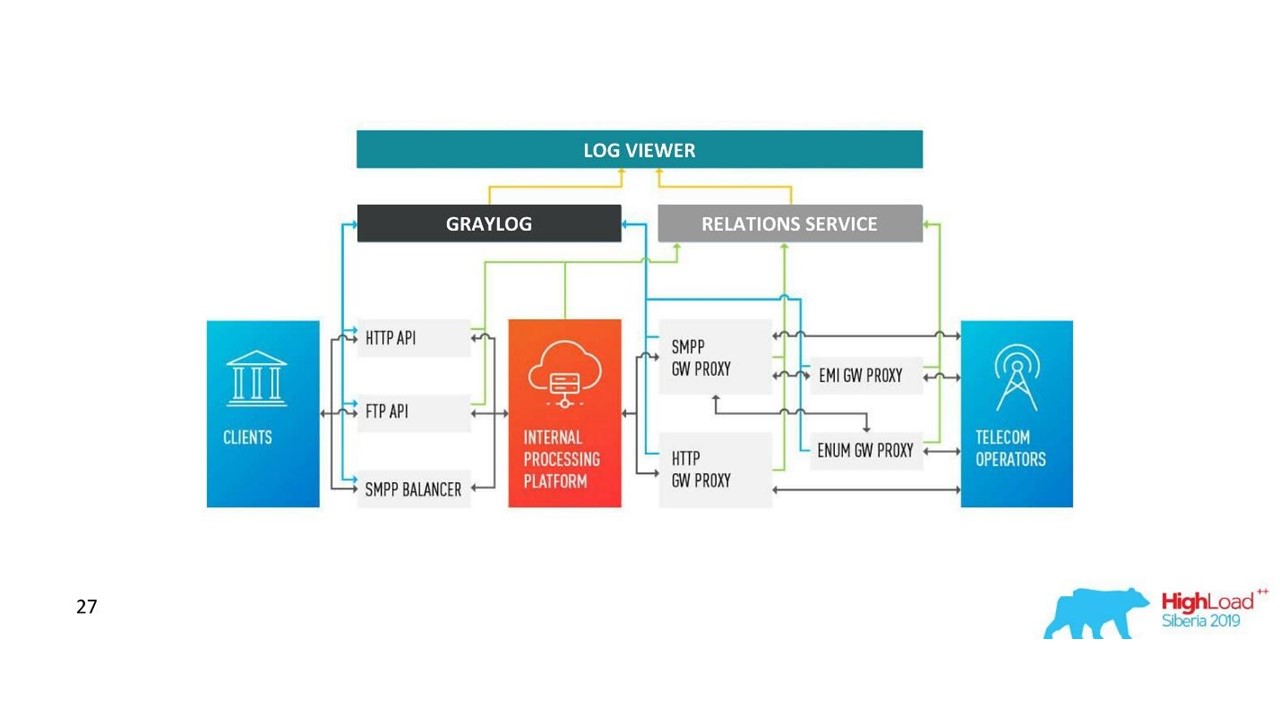 Cómo ha cambiado nuestra arquitectura.
Cómo ha cambiado nuestra arquitectura.Desafíos con Graylog
La compañía creció, aparecieron nuevos centros de datos, la carga aumentó notablemente, incluso con una solución con registros de comunicación. Pensamos que Graylog ya no es perfecto.
Esquema unificado y centralización . Me gustaría tener una única herramienta de administración de clúster en 10 centros de datos. Además, surgió la cuestión de un esquema unificado de mapeo de datos para que no hubiera colisiones.
API Utilizamos nuestra propia interfaz para mostrar las conexiones entre los registros y la API estándar de Graylog no siempre fue conveniente de usar, por ejemplo, cuando necesita mostrar datos de diferentes centros de datos, ordenarlos y marcarlos correctamente. Por lo tanto, queríamos poder cambiar la API a nuestro gusto.
Rendimiento, es difícil evaluar la pérdida . Nuestro tráfico es de 3 TB de registros por día, lo cual es decente. Por lo tanto, Graylog no siempre funcionó de manera estable, fue necesario entrar en su interior para comprender las causas de los fallos. Resultó que ya no lo usábamos como herramienta, teníamos que hacer algo al respecto.
Retrasos en el procesamiento (colas) . No nos gustó la implementación estándar de la cola en Graylog.
La necesidad de apoyar MongoDB . Graylog arrastra MongoDB, también era necesario administrar este sistema.
Nos dimos cuenta de que en esta etapa queremos nuestra propia solución. Quizás haya menos funciones interesantes para alertas que no se hayan utilizado, para paneles, pero las suyas son mejores.
Nuestra decision
Hemos desarrollado nuestro propio servicio de registros.
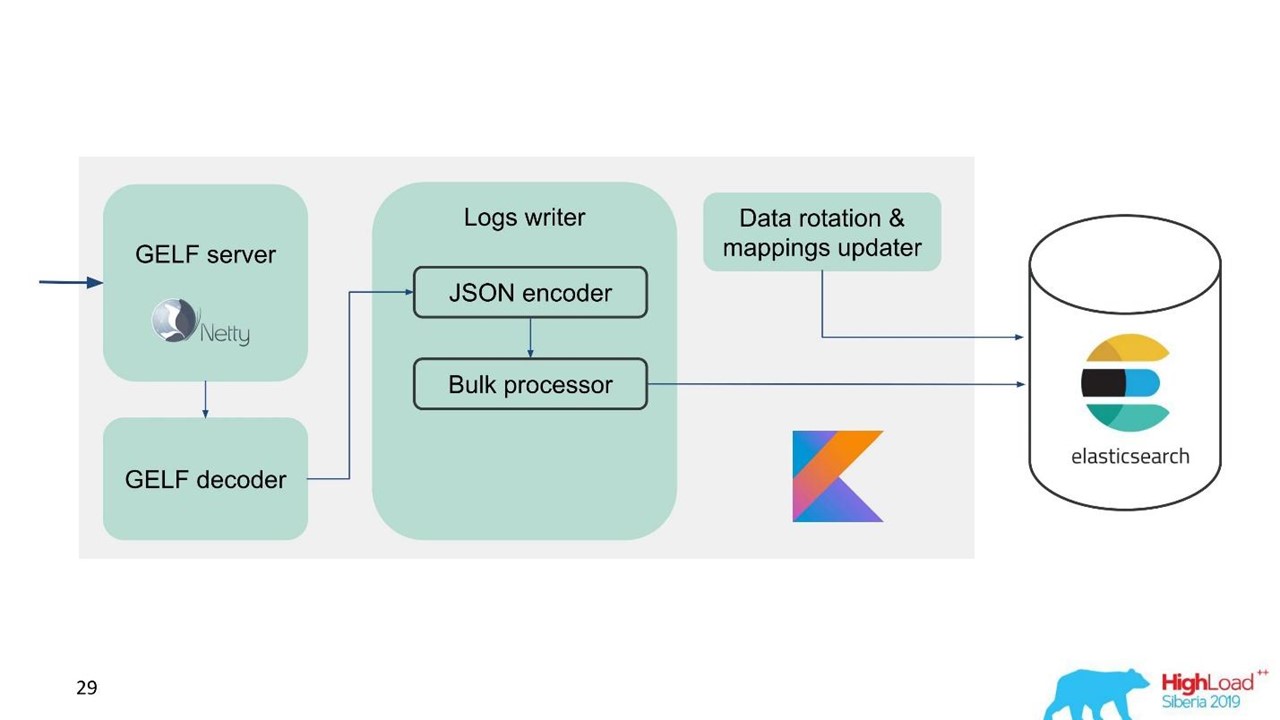 Servicio de registro.
Servicio de registro.En ese momento, ya teníamos experiencia en el servicio y mantenimiento de grandes grupos de Elasticsearch, por lo que tomamos a Elasticsearch como base. La pila estándar en la compañía es JVM, pero para el backend también usamos Kotlin de manera famosa, por lo que tomamos este idioma para el servicio.
La primera pregunta es cómo rotar los datos y qué hacer con el mapeo. Usamos mapeo fijo. En Elasticsearch, es mejor tener índices del mismo tamaño. Pero con tales índices, necesitamos mapear datos de alguna manera, especialmente para varios centros de datos, un sistema distribuido y un estado distribuido. Hubo ideas para sujetar ZooKeeper, pero esto es nuevamente una complicación de mantenimiento y código.
Por lo tanto, decidimos simplemente: escribir a tiempo.
Un índice por una hora, en otros centros de datos 2 índices por una hora, en el tercer índice por 3 horas, pero todo a tiempo. Los índices se obtienen en diferentes tamaños, porque en la noche el tráfico es menor que durante el día, pero en general funciona. La experiencia ha demostrado que no se necesitan complicaciones.
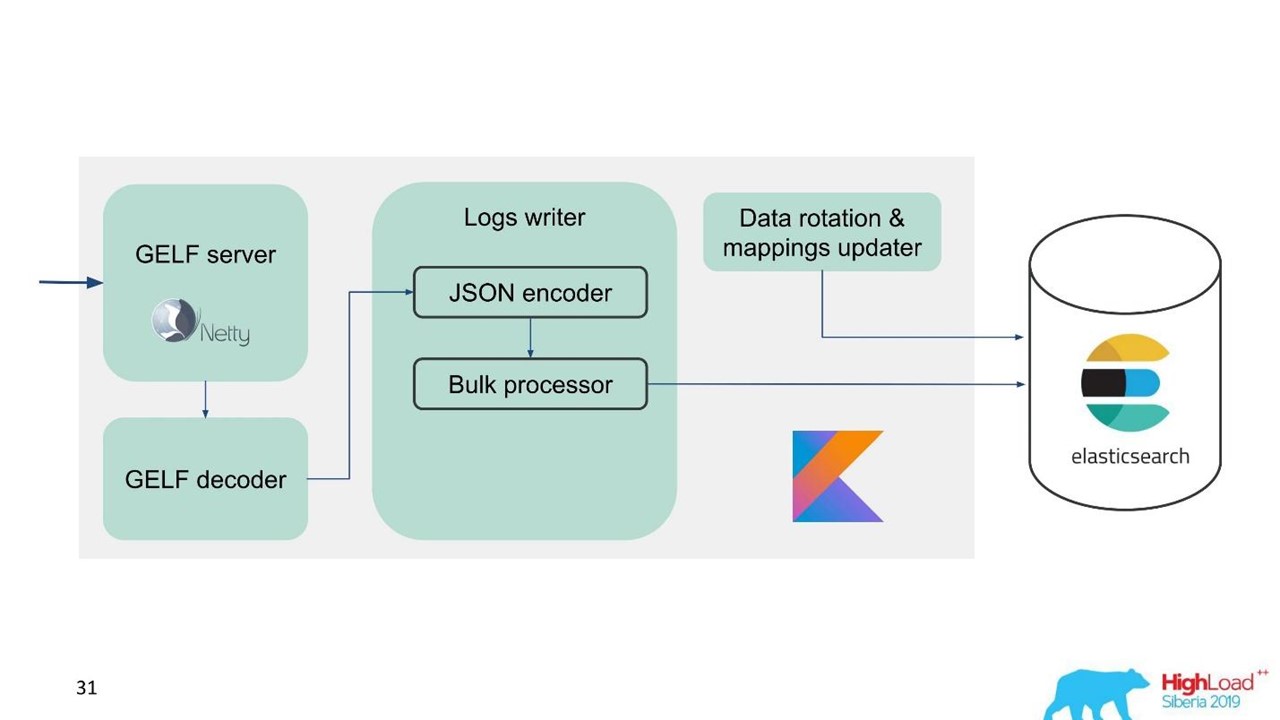
Para facilitar la migración y dada la gran cantidad de datos, elegimos el protocolo GELF, un protocolo Graylog simple basado en TCP. Entonces obtuvimos un servidor GELF para Netty y un decodificador GELF.
Luego, JSON se codifica para escribir en Elasticsearch. Usamos la API oficial de Java de Elasticsearch y escribimos en Bulk.
Para una alta velocidad de grabación necesitas escribir Bulk'ami.
Esta es una optimización importante. La API proporciona un procesador masivo que acumula automáticamente las solicitudes y luego las envía para su grabación en un paquete o con el tiempo.
Problema con el procesador masivo
Todo parece estar bien. Pero comenzamos y nos dimos cuenta de que descansábamos en el procesador Bulk; fue inesperado. No podemos alcanzar los valores con los que contamos: el problema surgió de la nada.
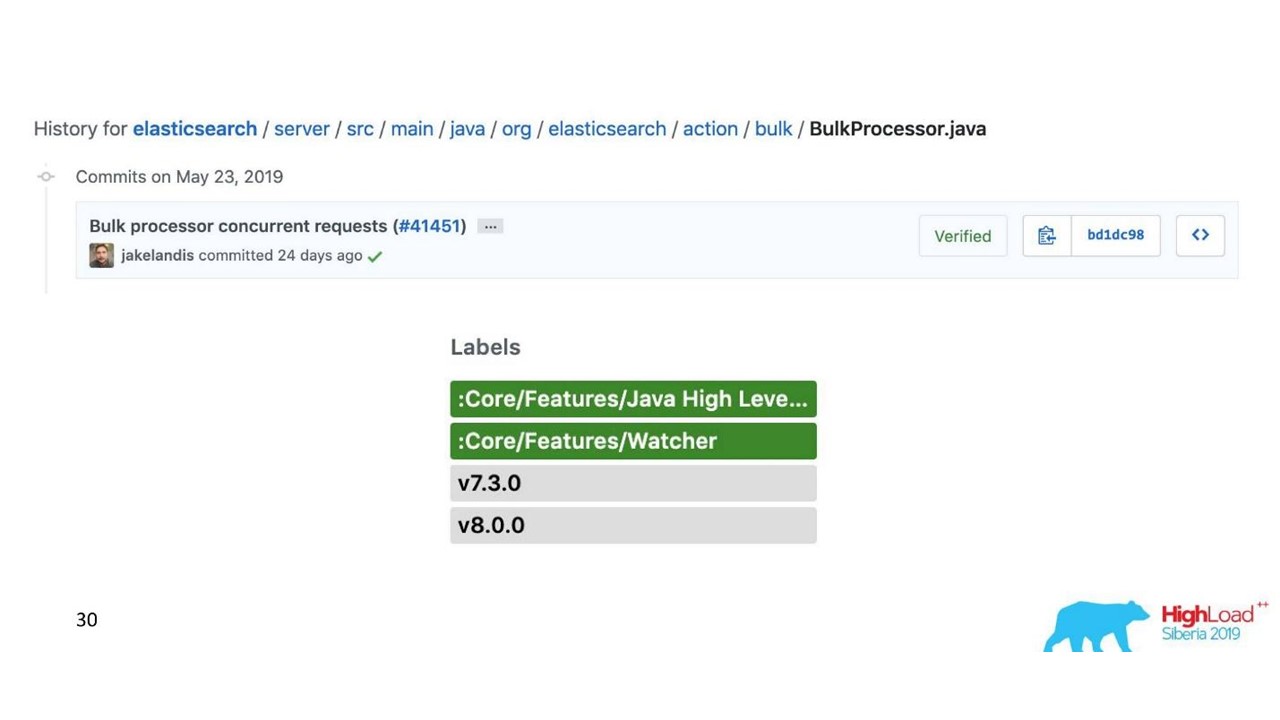
En la implementación estándar, el procesador Bulk es de un solo subproceso, sincrónico, a pesar del hecho de que hay una configuración de paralelismo. Ese fue el problema.
Rebuscamos y resultó que este es un error conocido, pero no resuelto. Cambiamos un poco el procesador Bulk, hicimos un bloqueo explícito a través de ReentrantLock. Solo en mayo, se realizaron cambios similares en el repositorio oficial de Elasticsearch y estarán disponibles solo desde la versión 7.3. El actual es 7.1, y estamos utilizando la versión 6.3.
Si también trabaja con un procesador masivo y desea overclockear una entrada en Elasticsearch, observe estos
cambios en GitHub y vuelva a su puerto. Los cambios afectan solo al procesador masivo. No habrá dificultades si necesita portar a la versión a continuación.
Todo está bien, el procesador Bulk se ha ido, la velocidad se ha acelerado.
El rendimiento de escritura de Elasticsearch es inestable con el tiempo, ya que varias operaciones tienen lugar allí: fusión de índices, vaciado. Además, el rendimiento disminuye durante un tiempo durante el mantenimiento, cuando parte de los nodos se eliminan del clúster, por ejemplo.
En este sentido, nos dimos cuenta de que necesitamos implementar no solo el búfer en la memoria, sino también la cola. Decidimos que solo enviaríamos mensajes rechazados a la cola, solo aquellos que el procesador masivo no podía escribir en Elasticsearch.
Reintentar reserva
Esta es una implementación simple.
- Guardamos los mensajes rechazados en el archivo -
RejectedExecutionHandler .
- Vuelva a enviar en el intervalo especificado en un ejecutor separado.
- Sin embargo, no retrasamos el tráfico nuevo.
Para los ingenieros y desarrolladores de soporte, el nuevo tráfico en el sistema es notablemente más importante que el que, por alguna razón, se retrasó durante el pico o la desaceleración de Elasticsearch. Se demoró, pero vendría más tarde, no es gran cosa. Se prioriza el nuevo tráfico.
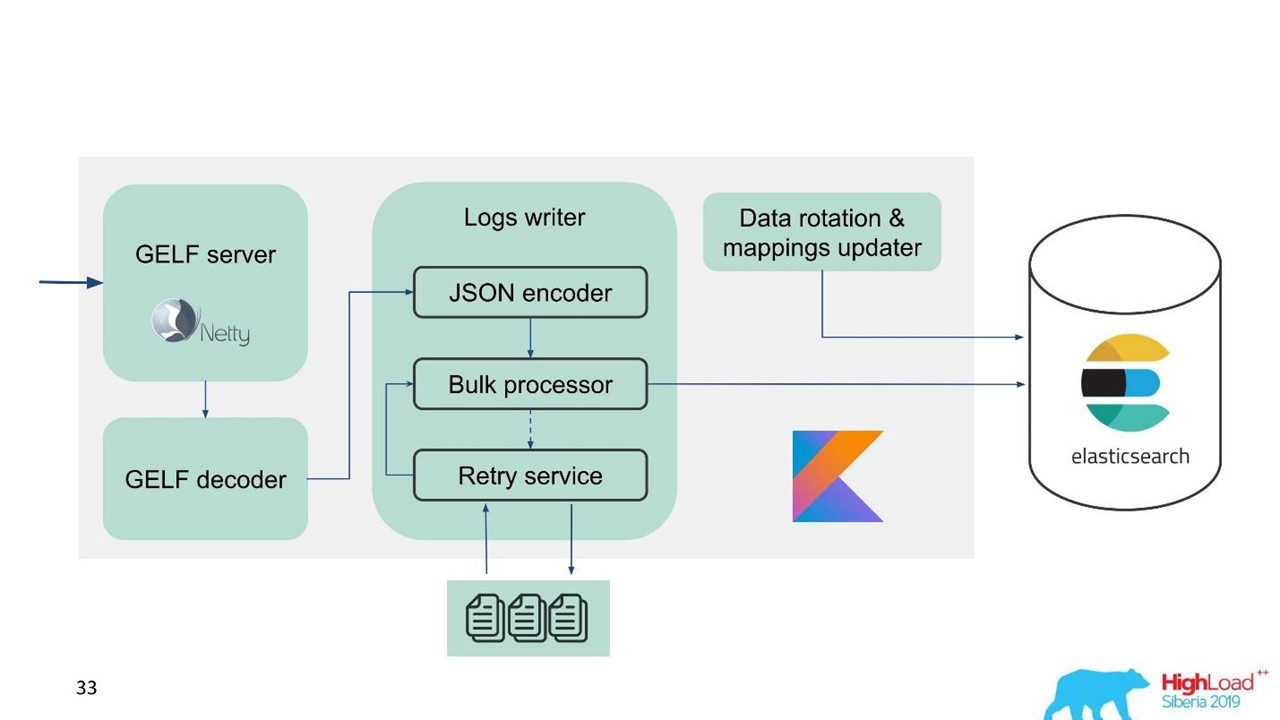 Nuestro esquema comenzó a verse así.
Nuestro esquema comenzó a verse así.Ahora hablemos sobre cómo preparamos Elasticsearch, qué parámetros usamos y cómo lo configuramos.
Configuración de Elasticsearch
El problema al que nos enfrentamos es la necesidad de overclockear Elasticsearch y optimizarlo para escribir, ya que la cantidad de lecturas es notablemente menor.
Utilizamos varios parámetros.
"ignore_malformed": true :
descarta los campos con el tipo incorrecto y no todo el documento . Todavía queremos almacenar los datos, incluso si por alguna razón los campos con una asignación incorrecta se han filtrado allí. Esta opción no está completamente relacionada con el rendimiento.
Para el hierro, Elasticsearch tiene un matiz. Cuando comenzamos a pedir grandes grupos, nos dijeron que las matrices RAID de las unidades SSD para sus volúmenes son terriblemente caras. Pero las matrices no son necesarias porque la tolerancia a fallas y la partición ya están integradas en Elasticsearch. Incluso en el sitio web oficial hay una recomendación para tomar más hierro barato que menos costoso y bueno. Esto se aplica tanto a los discos como a la cantidad de núcleos de procesador, ya que Elasticsearch completo es muy similar.
"index.merge.scheduler.max_thread_count": 1 -
recomendado para HDD .
Si no obtuvo SSD, sino HDD normales, configure este parámetro en uno. Los índices se escriben en piezas, luego estas piezas se congelan. Esto ahorra un poco de disco, pero, sobre todo, acelera la búsqueda. Además, cuando deja de escribir en el índice, puede
force merge . Cuando la carga en el clúster es menor, se congela automáticamente.
"index.unassigned.node_left.delayed_timeout": "5m" :
retraso de la implementación cuando desaparece un nodo . Este es el tiempo después del cual Elasticsearch comenzará a implementar índices y datos si un nodo se reinicia, implementa o retira para mantenimiento. Pero si tiene una gran carga en el disco y la red, entonces la implementación es una operación difícil. Para no sobrecargarlos, este tiempo de espera es mejor para controlar y comprender qué retrasos se necesitan.
"index.refresh_interval": -1 :
no actualice los índices si no hay consultas de búsqueda . Luego, el índice se actualizará cuando aparezca una consulta de búsqueda. Este índice se puede establecer en segundos y minutos.
"index.translogDurability": "async" - con qué frecuencia ejecutar fsync: con cada solicitud o por tiempo. Da ganancias de rendimiento para unidades lentas.
También tenemos una forma interesante de usarlo. El soporte y los desarrolladores desean poder realizar búsquedas de texto completo y usar regexp'ov en todo el cuerpo del mensaje. Pero en Elasticsearch esto no es posible: solo puede buscar por tokens que ya existen en su sistema. Se pueden usar RegExp y comodines, pero el token no puede comenzar con algunos RegExp. Por lo tanto, agregamos
word_delimiter al filtro:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
Divide automáticamente las palabras en tokens:
- "Wi-Fi" → "Wi", "Fi";
- “PowerShot” → “Power”, “Shot”;
- "SD500" → "SD", "500".
De manera similar, se escribe el nombre de la clase, diversa información de depuración. Con él, cerramos algunos de los problemas con la búsqueda de texto completo. Le aconsejo que agregue dicha configuración cuando trabaje con el inicio de sesión.
Sobre el cluster
El número de fragmentos debe ser igual al número de nodos de datos para el equilibrio de carga . El número mínimo de réplicas es 1, luego cada nodo tendrá un fragmento principal y una réplica. Pero si tiene datos valiosos, por ejemplo, transacciones financieras, es mejor 2 o más.
El tamaño del fragmento es de unos pocos GB a varias decenas de GB . El número de fragmentos en un nodo no es más de 20 por 1 GB de cadera Elasticsearch, por supuesto. Además Elasticsearch se ralentiza, también lo atacamos. En aquellos centros de datos donde hay poco tráfico, los datos no giraron en volumen, aparecieron miles de índices y el sistema se bloqueó.
Utilice el allocation awareness , por ejemplo, por el nombre de un hipervisor en caso de servicio. Ayuda a dispersar índices y fragmentos en diferentes hipervisores para que no se superpongan cuando un hipervisor se desconecta.
Crear índices de antemano . Buena práctica, especialmente cuando se escribe a tiempo. El índice está inmediatamente caliente, listo y no hay retrasos.
Limite el número de fragmentos de un índice por nodo .
"index.routing.allocation.total_shards_per_node": 4 es el número máximo de fragmentos de un índice por nodo. En el caso ideal, hay 2 de ellos, ponemos 4 por si acaso, si todavía tenemos menos autos.
¿Cuál es el problema aquí? Utilizamos el
allocation awareness : Elasticsearch sabe cómo distribuir correctamente los índices en los hipervisores. Pero descubrimos que después de que el nodo se apagó durante mucho tiempo, y luego vuelve al clúster, Elasticsearch ve que hay formalmente menos índices y se restauran. Hasta que los datos estén sincronizados, formalmente hay pocos índices en el nodo. Si es necesario, asigne un nuevo índice, Elasticsearch intenta martillar esta máquina lo más densamente posible con nuevos índices. Por lo tanto, un nodo recibe una carga no solo por el hecho de que los datos se replican, sino también por el tráfico nuevo, los índices y los datos nuevos que caen en este nodo. Controlarlo y limitarlo.
Recomendaciones de mantenimiento de Elasticsearch
Quienes trabajan con Elasticsearch están familiarizados con estas recomendaciones.
Durante el mantenimiento programado, aplique las recomendaciones para la actualización continua: deshabilite la asignación de fragmentos, el vaciado sincronizado.
Deshabilitar la asignación de fragmentos . Desactive la asignación de fragmentos de réplicas, deje la capacidad de asignar solo primarios. Esto ayuda notablemente a Elasticsearch: no reasignará datos que no necesita. Por ejemplo, usted sabe que en media hora el nodo se elevará, ¿por qué transferir todos los fragmentos de un nodo a otro? Nada terrible sucederá si vives con el grupo amarillo durante media hora, cuando solo hay fragmentos primarios disponibles.
Rubor sincronizado . En este caso, el nodo se sincroniza mucho más rápido cuando vuelve al clúster.
Con una gran carga al escribir en el índice o la recuperación, puede reducir la cantidad de réplicas.
Si descarga una gran cantidad de datos, por ejemplo, carga máxima, puede desactivar fragmentos y luego dar un comando a Elasticsearch para crearlos cuando la carga ya es menor.
Aquí hay algunos comandos que me gusta usar:
GET _cat/thread_pool?v : le permite ver thread_pool en cada nodo: lo que está de moda ahora, cuáles son las colas de escritura y lectura.
GET _cat/recovery/?active_only=true : qué índices se implementan en dónde, dónde tiene lugar la recuperación.
GET _cluster/allocation/explain - en una forma humana conveniente por qué y qué índices o réplicas no se asignaron.
Para el monitoreo usamos Grafana.
Existe un excelente
exportador y miembro de equipo de Grafana de
Vincent van Hollebeke , que le permite ver visualmente el estado del clúster y todos sus parámetros principales. Lo agregamos a nuestra imagen de Docker y todas las métricas al implementar desde nuestra caja.
Conclusiones de registro
Los registros deben ser:
- centralizado : un único punto de entrada para desarrolladores;
- disponible : la capacidad de buscar rápidamente;
- estructurado - para la extracción rápida y conveniente de información valiosa;
- correlacionado , no solo entre ellos, sino también con otras métricas y sistemas que utiliza.
El concurso sueco
Melodifestivalen se ha celebrado recientemente. Esta es una selección de representantes de Suecia para Eurovisión. Antes de la competencia, nuestro servicio de soporte nos contactó: “Ahora en Suecia habrá una gran carga. El tráfico es bastante sensible y queremos correlacionar algunos datos. Tiene datos en los registros que faltan en el panel de Grafana. Tenemos métricas que se pueden tomar de Prometheus, pero necesitamos datos sobre solicitudes de identificación específicas ".
Agregaron Elasticsearch como la fuente de Grafana y pudieron correlacionar estos datos, cerrar el problema y obtener buenos resultados lo suficientemente rápido.
Explotar sus propias soluciones es mucho más fácil.
Ahora, en lugar de los 10 clústeres de Graylog que funcionaron para esta solución, tenemos varios servicios. Estos son 10 centros de datos, pero ni siquiera tenemos un equipo dedicado y personas que los atiendan. Hay varias personas que trabajaron en ellos y cambian algo según sea necesario. Este pequeño equipo está perfectamente integrado en nuestra infraestructura: la implementación y el mantenimiento son más fáciles y económicos.
Separe los casos y use las herramientas apropiadas.
Estas son herramientas separadas para el registro, rastreo y monitoreo. No existe un "instrumento de oro" que cubra todas sus necesidades.
Para comprender qué herramienta se necesita, qué monitorear, qué registros usar, qué requisitos de registro, definitivamente debe consultar
SLI / SLO - Indicador de nivel de servicio / Objetivo de nivel de servicio. Necesita saber qué es importante para sus clientes y su negocio, qué indicadores observan.
Una semana después, SKOLKOVO presentará HighLoad ++ 2019 . En la noche del 7 de noviembre, Ivan Letenko le contará cómo vive con Redis en la producción, y en total hay 150 informes en el programa sobre diversos temas.
Si tiene problemas para visitar HighLoad ++ 2019 en vivo, tenemos buenas noticias. Este año, la conferencia se llevará a cabo en tres ciudades a la vez: en Moscú, Novosibirsk y San Petersburgo. Al mismo tiempo Cómo será y cómo llegar allí: infórmese en una página de promoción separada del evento.