Los desarrolladores de la Universidad de Edimburgo introdujeron un nuevo algoritmo para crear movimientos de personajes realistas en los juegos. Formada en trayectorias de captura de movimiento, la red neuronal está tratando de copiar los movimientos de personas reales, pero al mismo tiempo los adapta a los personajes de los videojuegos.
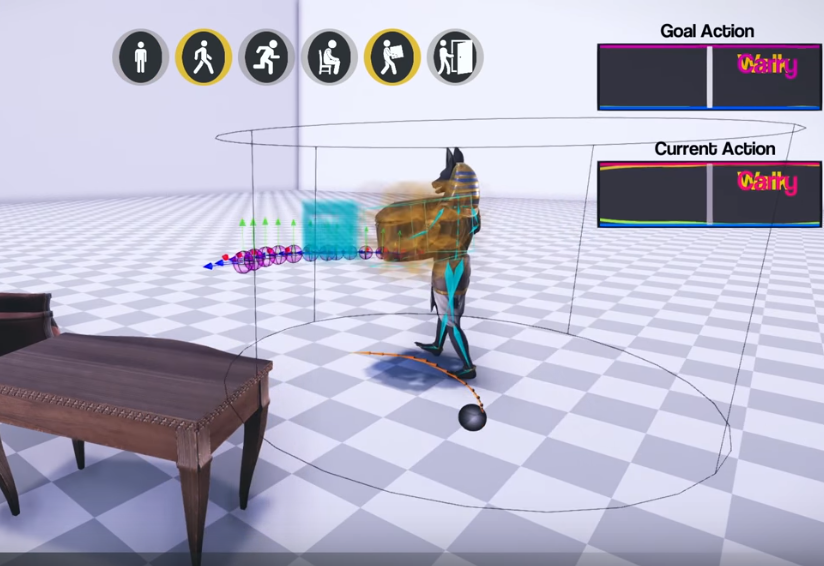
Una red neuronal es capaz de gestionar varias acciones en el juego a la vez. Abrir puertas, mover objetos, usar muebles. Al mismo tiempo, cambia dinámicamente la posición de las piernas y los brazos para que el personaje pueda sostener de manera realista cajones de diferentes tamaños, sentarse en sillas de diferentes tamaños y también gatear en pasajes de diferentes alturas.
Por lo general, bajo el control de los personajes en los juegos que usan IA, significa un control completo de los esfuerzos en las extremidades, basado en algún tipo de motor físico que imita las leyes de la física. Este es el dominio del aprendizaje automático llamado aprendizaje por refuerzo. Desafortunadamente, de esta manera, aún
no se
pueden lograr movimientos realistas.
Por otro lado, puede intentar entrenar la red neuronal para simular los movimientos de personas reales capturadas con Motion Capture. De esta manera, hace aproximadamente un año, se logró un progreso significativo en la animación realista de personajes en 3D.


Hubo varios trabajos científicos consecutivos sobre este tema, pero la descripción más completa se puede encontrar en el trabajo de
Towards a Virtual Stuntman en la red neuronal DeepMimic (
https://www.youtube.com/watch?v=vppFvq2quQ0 ).
La idea principal es simular movimientos humanos durante el entrenamiento para comenzar el episodio no desde el comienzo de la pista de Captura de movimiento, como lo hicieron antes, sino desde puntos aleatorios a lo largo de todo el camino. Los algoritmos de aprendizaje por refuerzo existentes exploran la vecindad del punto de partida, por lo que con mayor frecuencia no llegaron al final de la trayectoria. Pero si cada episodio comienza a lo largo de toda la pista, entonces aumenta la posibilidad de que la red neuronal aprenda a repetir toda la trayectoria.
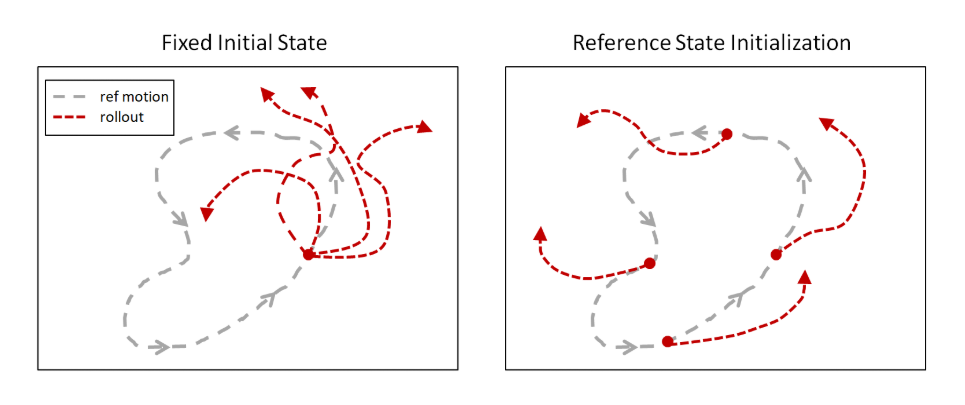
Más tarde, esta idea fue recogida en áreas completamente diferentes. Por ejemplo, al enseñar a las personas a jugar una red neuronal en los juegos, y también al comenzar episodios no desde el principio, sino desde puntos aleatorios (específicamente en este caso, desde el final y gradualmente avanzando hacia el principio), OpenAI enseñó a la red neuronal
a jugar la venganza de Montezuma . Lo cual no cedió a los algoritmos habituales de aprendizaje por refuerzo antes.
Sin este truco, los intentos de entrenar a la red neuronal para copiar movimientos complejos terminaron en fracaso porque la red neuronal encontró un camino más corto. Aunque no daba una recompensa tan grande como para toda la trayectoria, todavía había algún tipo de recompensa. Por ejemplo, en lugar de dar un salto mortal hacia atrás, la red neuronal simplemente rebotó ligeramente y se dejó caer sobre su espalda.

Pero con este enfoque, la red neuronal sin problemas estudia la trayectoria de casi cualquier complejidad.

El principal problema de DeepMimic, que impedía aplicarlo directamente a los videojuegos, es que no era posible entrenar a la red neuronal para realizar varias animaciones diferentes a la vez. Era necesario entrenar una red neuronal separada para cada animación. Los autores intentaron combinarlos de diferentes maneras, pero no se pudieron combinar más de 3-4 animaciones.
En el nuevo trabajo, este problema tampoco se resuelve por completo, pero se ha avanzado mucho hacia una transición fluida entre diferentes animaciones.
Cabe señalar que este problema afecta a todas las redes neuronales de animación similares actualmente existentes. Por ejemplo,
esta red neuronal , también entrenada en imitación de Motion Capture, puede controlar honestamente una gran cantidad de músculos (¡326!) De un personaje humanoide en un motor físico. Adaptación a diferentes pesos de pesos levantados y diversas lesiones articulares. Pero al mismo tiempo, para cada animación, se necesita una red neuronal entrenada por separado.
Debe entenderse que el objetivo de tales redes neuronales no es solo repetir la animación humana. Y repítelo en el motor de física. Al mismo tiempo, los algoritmos de aprendizaje por refuerzo hacen que este entrenamiento sea confiable y resistente a las interferencias. Entonces, dicha red neuronal se puede transferir a un robot físico que difiere en geometría o masa de una persona, pero seguirá repitiendo de manera realista los movimientos de las personas (comenzando desde cero, como ya se mencionó, este efecto aún no se ha logrado). O, como en el trabajo anterior, puede explorar virtualmente cómo se moverá una persona con lesiones en las piernas para desarrollar prótesis más cómodas.
Incluso en el primer DeepMimic hubo el comienzo de tal adaptación. Era posible mover la bola roja, y el personaje le arrojó la pelota cada vez. Apuntar y medir la fuerza de lanzamiento para alcanzar el objetivo exactamente. Aunque fue entrenado en la única pista de Motion Capture, que no brinda esa oportunidad.

Por lo tanto, esto puede considerarse un entrenamiento de IA completo, y la imitación de los movimientos humanos simplemente le permite acelerar el aprendizaje y hacer que los movimientos sean visualmente más atractivos y familiares para nosotros (aunque desde el punto de vista de la red neuronal pueden no ser los más óptimos al mismo tiempo).
El nuevo trabajo ha ido aún más lejos en esta dirección.
No hay motor físico, es un sistema puramente de animación para videojuegos. Pero el énfasis está en el cambio realista entre múltiples animaciones. Y para interactuar con los elementos del juego: mover elementos, usar muebles, abrir puertas.

La arquitectura de la red neuronal consta de dos partes. Una (Red de compuerta), basada en el estado actual del estado y el objetivo actual, elige qué animación usar, y la otra (Red de predicción de movimiento) predice los siguientes cuadros de la animación.

Todo esto fue entrenado en un conjunto de pistas de Captura de movimiento utilizando el aprendizaje de refuerzo de simulación.
Pero el logro principal de este trabajo es diferente. En cómo los desarrolladores enseñaron a la red neuronal a trabajar con objetos de diferentes tamaños y exprimir en pasajes de diferentes anchos o alturas. Para que las posiciones de los brazos y las piernas se vean realistas y correspondan al tamaño del objeto con el que el personaje interactúa en el juego.
El secreto era simple: ¡aumento!
Primero, a partir de la pista de Captura de movimiento, determinaron los puntos de contacto de las manos con los reposabrazos de la silla. Luego reemplazaron el modelo de la silla por uno más ancho y volvieron a calcular la trayectoria de la captura de movimiento para que las manos tocaran los reposabrazos en los mismos puntos, pero en una silla más ancha. Y obligaron a la red neuronal a simular esta nueva trayectoria generada por Motion Capture. De manera similar con las dimensiones de las cajas, la altura de los pasillos, etc.
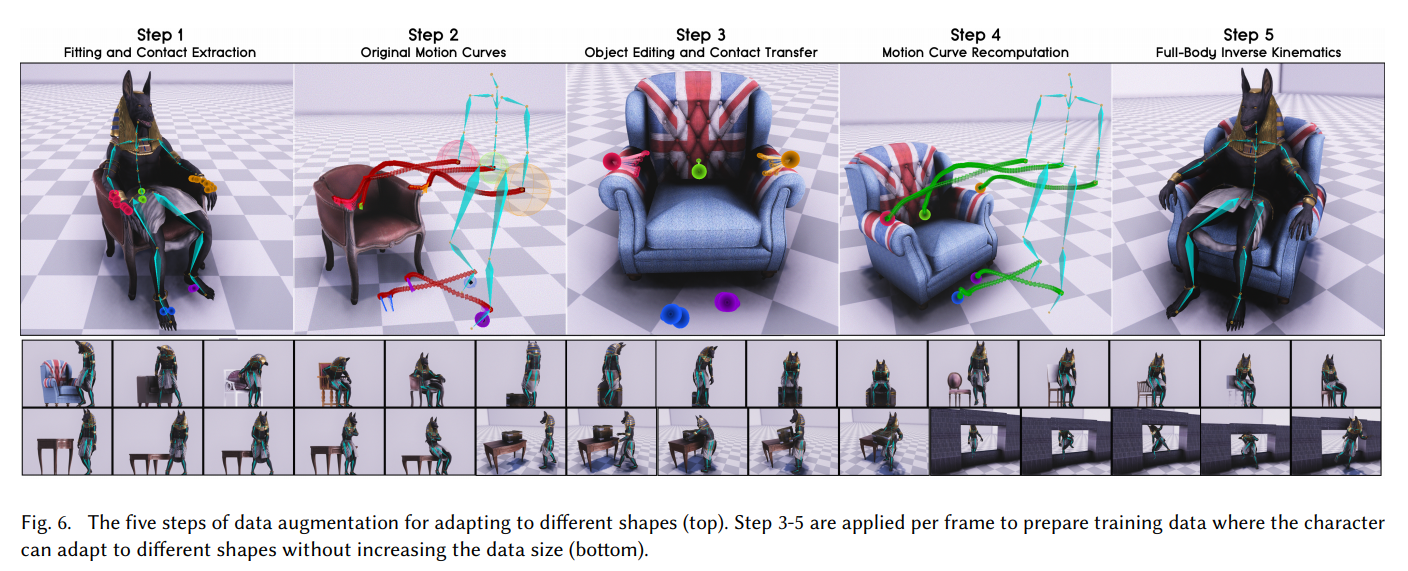
Repitiendo esto muchas veces con varios modelos 3D del entorno con el que interactuará el jugador, la red neuronal ha aprendido a manejar de manera realista objetos de diferentes tamaños.

Para interactuar con el entorno en el juego en sí, también era necesario voxelizar los objetos a su alrededor para que funcionaran como sensores en la entrada de la red neuronal.

El resultado fue una muy buena animación para los personajes del juego. Con transiciones suaves entre acciones y con la capacidad de interactuar de manera realista con objetos de varios tamaños.
Recomiendo ver el video si alguien aún no lo ha hecho. Describe con gran detalle cómo lograron esto.
Este enfoque se puede utilizar para la animación, incluidos los animales de cuatro patas, obteniendo la calidad y el realismo sin igual de los movimientos de animales y monstruos:
Referencias
VideoPágina del proyecto con fuenteArchivo PDF con una descripción detallada del trabajo:
SIGGRAPH_Asia_2019 / Paper.pdf