El poder de JavaScript y la API del navegadorEl mundo está cada vez más interconectado: el número de personas con acceso a Internet ha aumentado a
4.500 millones .
Pero estos datos no reflejan la cantidad de personas que tienen una conexión a Internet lenta o interrumpida. Incluso en los Estados Unidos,
4.9 millones de hogares no pueden acceder a Internet por cable a velocidades de más de 3 megabits por segundo.
El resto del mundo, aquellos con acceso confiable a Internet, aún es propenso a perder conectividad.
Algunos factores que pueden afectar la calidad de su conexión de red incluyen:
- Mala cobertura del proveedor.
- Condiciones climáticas extremas.
- Cortes de energía.
- Usuarios que caen en zonas muertas, como edificios que bloquean sus conexiones de red.
- Viaje en tren y viaje en túnel.
- Conexiones controladas por un tercero y con tiempo limitado.
- Prácticas culturales que requieren acceso limitado o nulo a Internet en momentos o días específicos.
Dado esto, está claro que debemos tener en cuenta la experiencia autónoma al desarrollar y crear aplicaciones.

Este artículo fue traducido con el apoyo de EDISON Software, una compañía que realiza excelentes pedidos desde el sur de China , y también desarrolla aplicaciones y sitios web .
Recientemente tuve la oportunidad de agregar autonomía a una aplicación existente utilizando trabajadores de servicios, almacenamiento en caché e IndexedDB. El trabajo técnico necesario para que la aplicación funcione sin conexión se redujo a cuatro tareas separadas, que analizaré en esta publicación.
Trabajadores de servicio
Las aplicaciones creadas para uso sin conexión no deben depender mucho de la red. Conceptualmente, esto solo es posible si, en caso de falla, existen opciones de respaldo.
Si la aplicación web no se carga, debemos tomar los recursos para el navegador en algún lugar (HTML / CSS / JavaScript). ¿De dónde provienen estos recursos, si no es de una solicitud de red? ¿Qué tal un caché? La mayoría de la gente estaría de acuerdo en que es mejor proporcionar una interfaz de usuario potencialmente desactualizada que una página en blanco.
El navegador consulta constantemente los datos. El servicio de almacenamiento en caché de datos como respaldo todavía requiere que interceptemos de alguna manera las solicitudes del navegador y escribamos reglas de almacenamiento en caché. Aquí es donde entran en juego los trabajadores de servicios: piense en ellos como un intermediario.
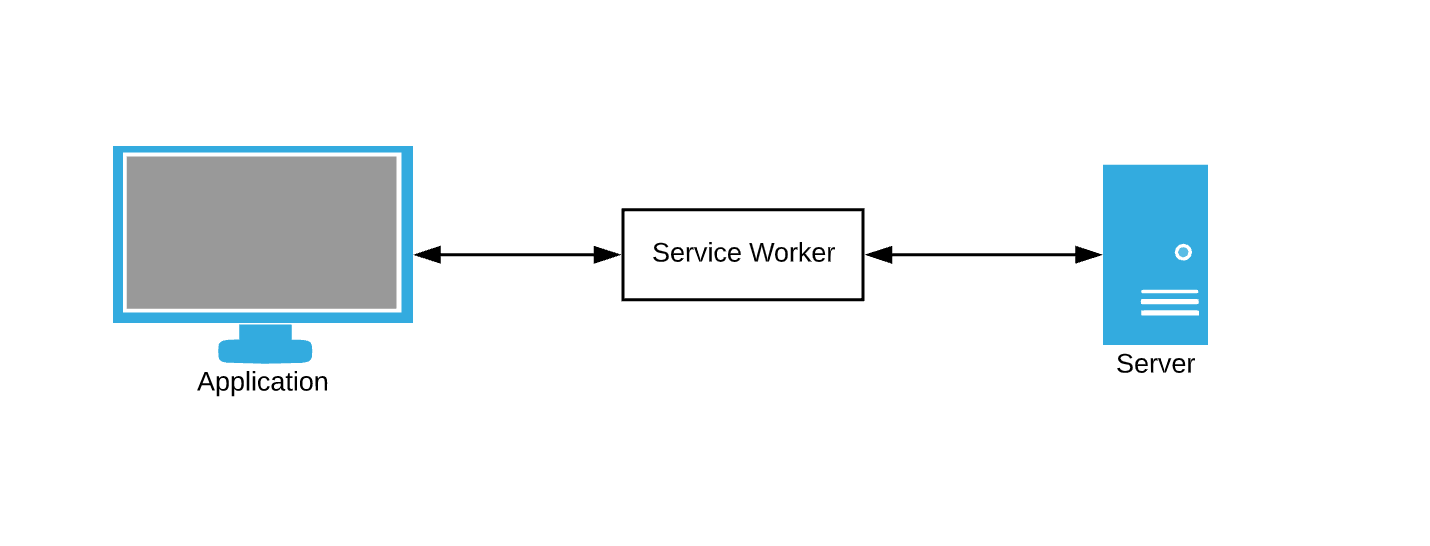
Service Worker es solo un archivo JavaScript en el que podemos suscribirnos a eventos y escribir nuestras propias reglas para el almacenamiento en caché y el manejo de fallas de red.
Empecemos
Tenga en cuenta: nuestra aplicación de demostraciónA lo largo de esta publicación, agregaremos funciones independientes a la aplicación de demostración. La aplicación de demostración es una página simple para tomar / alquilar libros en la biblioteca. El progreso se presentará como una serie de GIF y el uso de simulaciones fuera de línea de Chrome DevTools.
Aquí está el estado inicial:
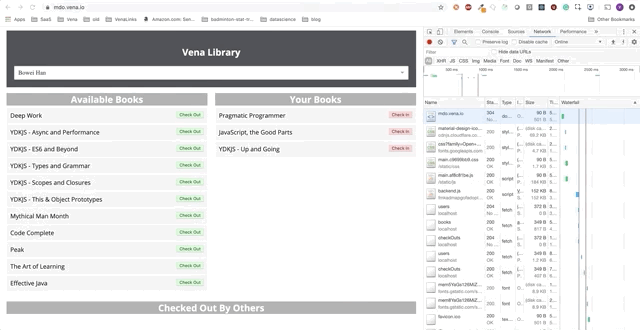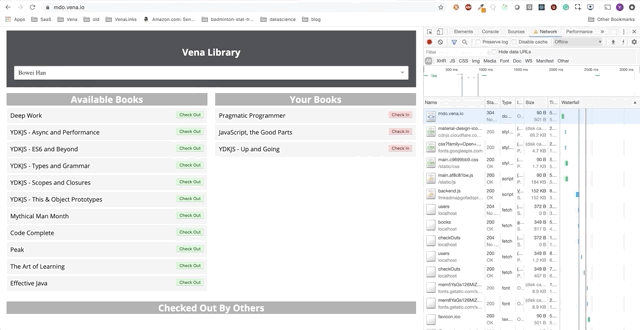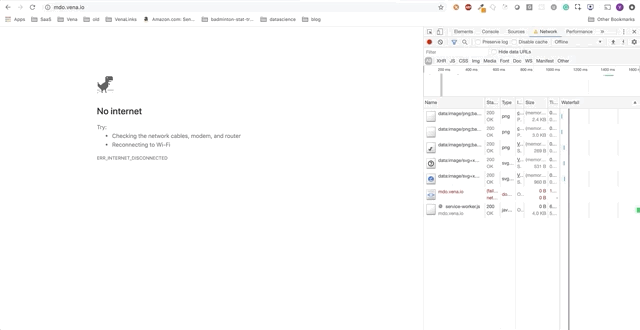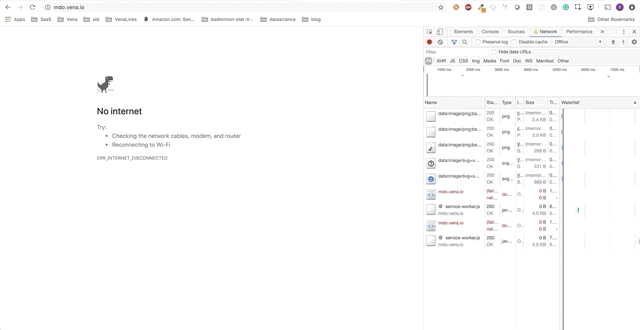
Tarea 1: almacenamiento en caché de recursos estáticos
Los recursos estáticos son recursos que no cambian con frecuencia. HTML, CSS, JavaScript e imágenes pueden entrar en esta categoría. El navegador intenta cargar recursos estáticos utilizando solicitudes que pueden ser interceptadas por el trabajador del servicio.
Comencemos por registrar a nuestro trabajador de servicio.
if ('serviceWorker' in navigator) { window.addEventListener('load', function() { navigator.serviceWorker.register('/sw.js'); }); }
Los trabajadores de servicios son trabajadores
web bajo el capó y, por lo tanto, deben importarse desde un archivo JavaScript separado. El registro se realiza utilizando el método de
register después de cargar el sitio.
Ahora que tenemos un trabajador de servicio cargado, guardemos en caché nuestros recursos estáticos.
var CACHE_NAME = 'my-offline-cache'; var urlsToCache = [ '/', '/static/css/main.c9699bb9.css', '/static/js/main.99348925.js' ]; self.addEventListener('install', function(event) { event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { return cache.addAll(urlsToCache); }) ); });
Como controlamos las URL de los recursos estáticos, podemos almacenarlas en caché inmediatamente después de la inicialización del trabajador del servicio mediante
Cache Storage .
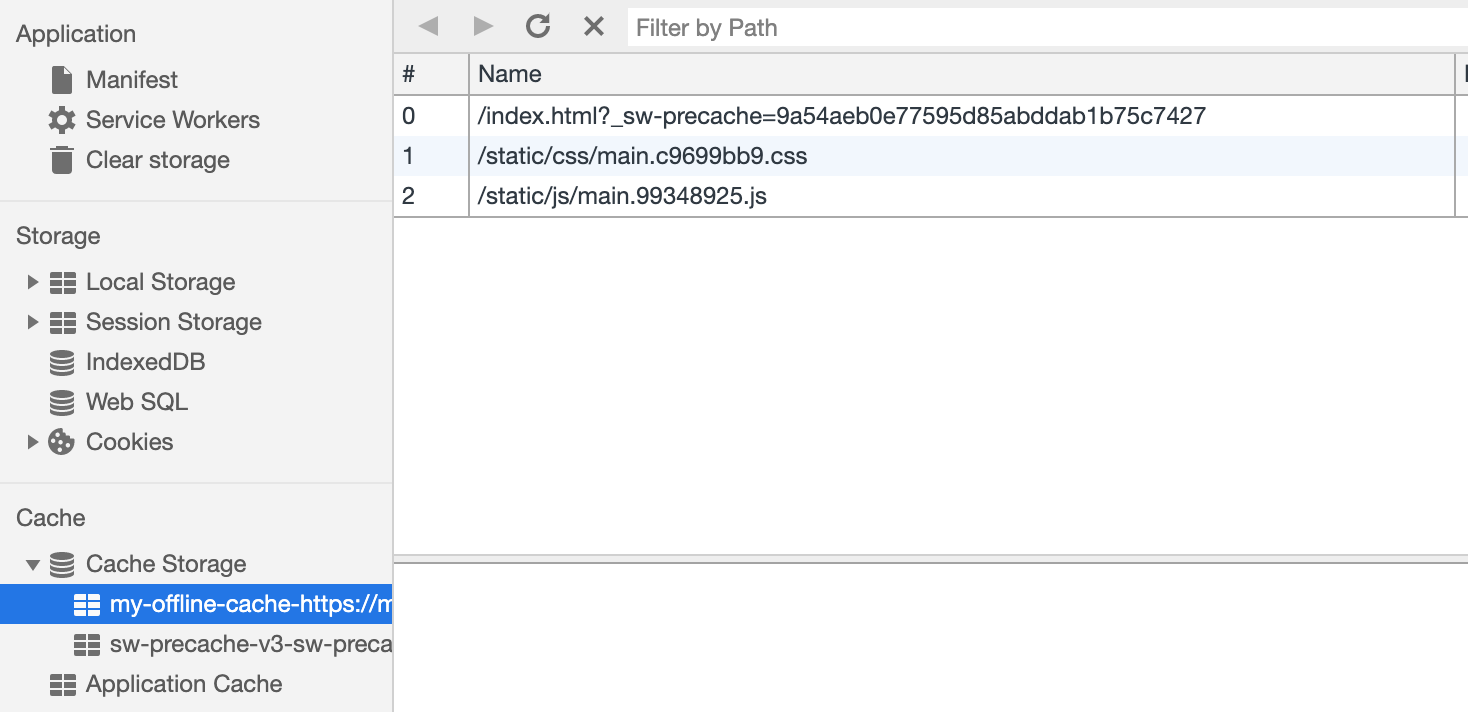
Ahora que nuestro caché está lleno de los recursos estáticos solicitados más recientemente, carguemos estos recursos del caché en caso de que se produzca un error en la solicitud.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
El evento de
fetch se activa cada vez que el navegador realiza una solicitud. Nuestro nuevo controlador de eventos de
fetch ahora tiene una lógica adicional para devolver respuestas almacenadas en caché en caso de interrupciones de la red.
Demo número 1
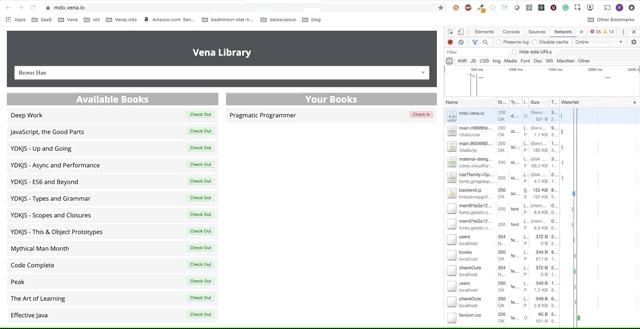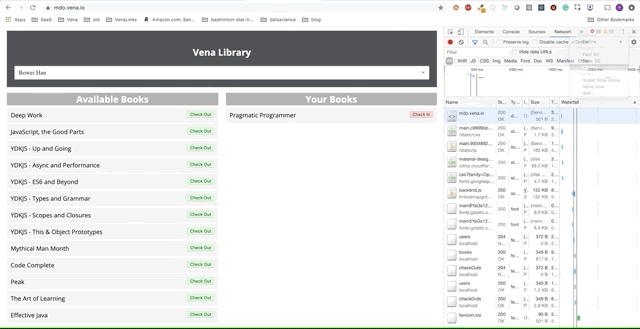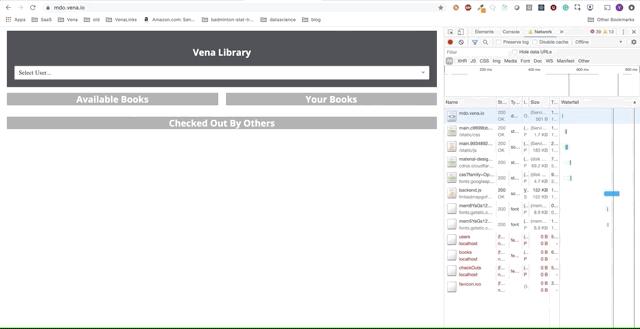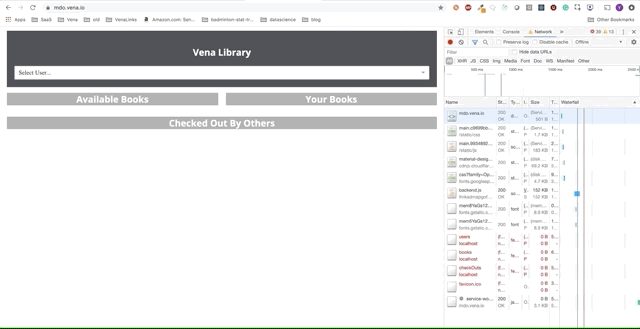
¡Nuestra aplicación de demostración ahora puede servir recursos estáticos sin conexión! ¿Pero dónde están nuestros datos?
Tarea 2: almacenamiento en caché de recursos dinámicos
Las aplicaciones de una sola página (SPA) generalmente solicitan datos gradualmente después de la carga inicial de la página, y nuestra aplicación de demostración no es una excepción: la lista de libros no se carga de inmediato. Estos datos generalmente provienen de solicitudes XHR que devuelven respuestas que cambian con frecuencia para proporcionar un nuevo estado para la aplicación, por lo que son dinámicas.
El almacenamiento en caché de recursos dinámicos es en realidad muy similar al almacenamiento en caché de recursos estáticos; la principal diferencia es que necesitamos actualizar el caché con más frecuencia. Generar una lista completa de todas las solicitudes dinámicas de XHR posibles también es bastante difícil, por lo que las almacenaremos en caché a medida que lleguen, en lugar de tener una lista predefinida, como lo hicimos con los recursos estáticos.
Echa un vistazo a nuestro controlador de
fetch :
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Podemos personalizar esta implementación agregando un código que almacena en caché las solicitudes y respuestas exitosas. Esto garantiza que constantemente agreguemos nuevas solicitudes a nuestra memoria caché y que actualicemos constantemente los datos en caché.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request) .then(function(response) { caches.open(CACHE_NAME).then(function(cache) { cache.put(event.request, response); }); }) .catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Nuestro
Cache Storage actualmente tiene varias entradas.

Demo número 2
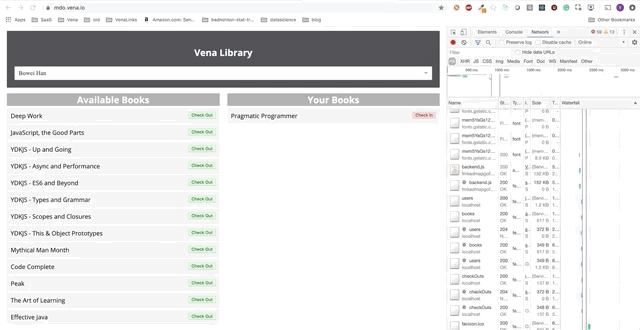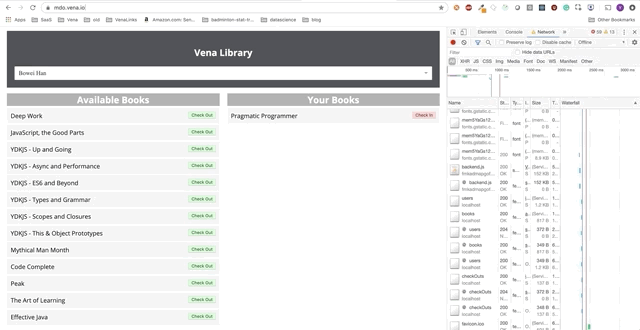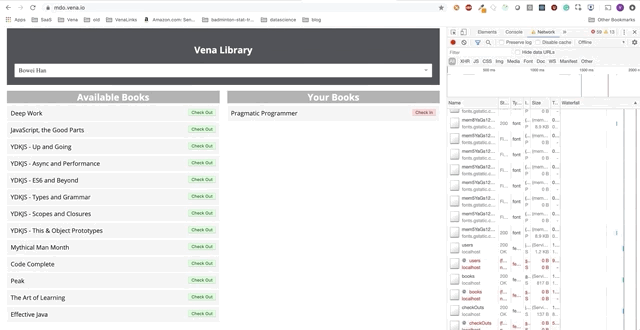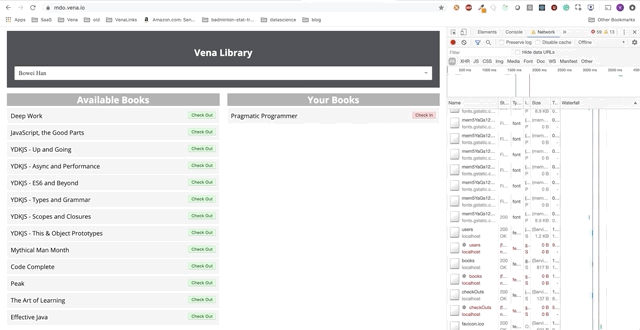
¡Nuestra demostración ahora se ve igual en el arranque, independientemente del estado de nuestra red!
Genial Ahora tratemos de usar nuestra aplicación.
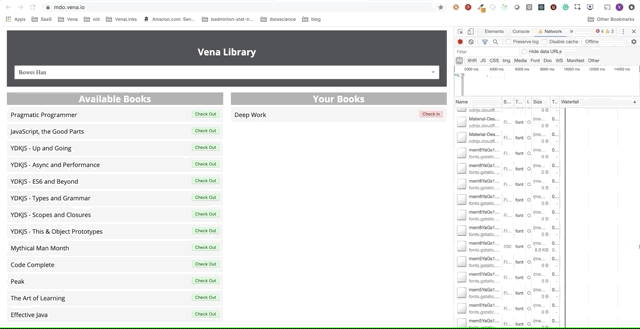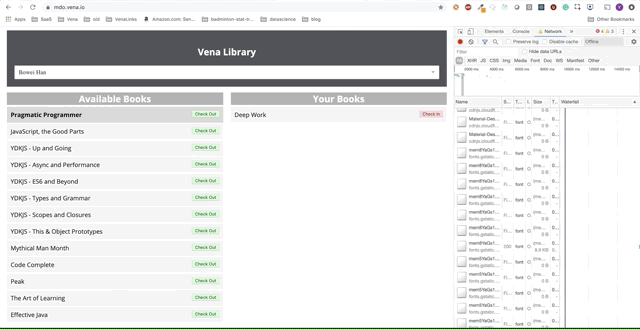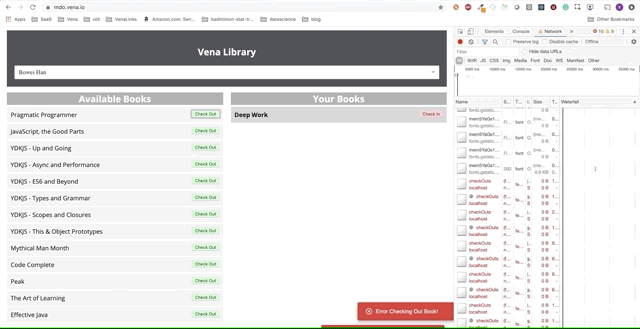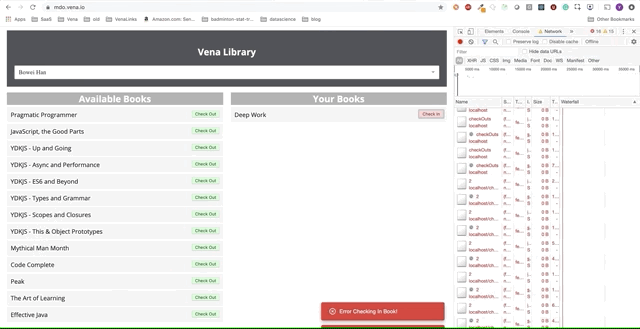
Lamentablemente, los mensajes de error están en todas partes. Parece que todas nuestras interacciones con la interfaz no funcionan. ¡No puedo elegir ni entregar el libro! ¿Qué necesita ser arreglado?
Tarea 3: crear una interfaz de usuario optimista
Por el momento, el problema con nuestra aplicación es que nuestra lógica de recopilación de datos todavía depende en gran medida de las respuestas de la red. La acción de entrada o salida envía una solicitud al servidor y espera una respuesta exitosa. Esto es excelente para la consistencia de los datos, pero es malo para nuestra experiencia independiente.
Para que estas interacciones funcionen sin conexión, necesitamos que nuestra aplicación sea más
optimista . Las interacciones optimistas no requieren una respuesta del servidor y muestran de buena gana una vista actualizada de los datos. La operación optimista habitual en la mayoría de las aplicaciones web es
delete : ¿por qué no darle al usuario comentarios instantáneos si ya tenemos toda la información necesaria?
Desconectar nuestra aplicación de la red utilizando un enfoque optimista es relativamente fácil de implementar.
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
La clave es manejar las acciones del usuario de la misma manera, independientemente de si la solicitud de red es exitosa o no. El fragmento de código anterior se toma del reductor redux de nuestra aplicación,
FAILURE lanzan
SUCCESS y
FAILURE dependiendo de la disponibilidad de la red. Independientemente de cómo se complete la solicitud de red, vamos a actualizar nuestra lista de libros.
Demo número 3
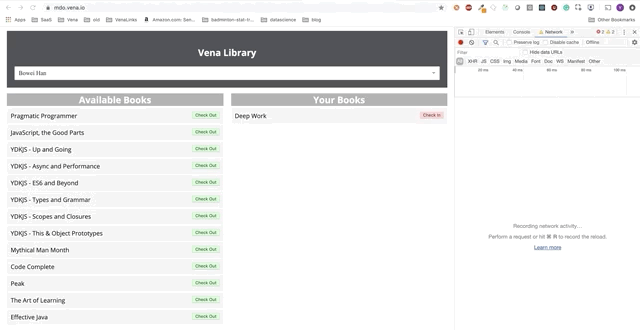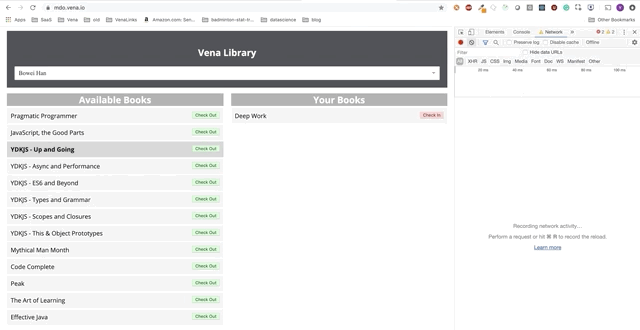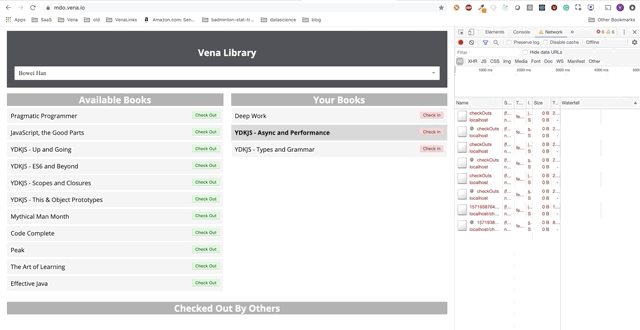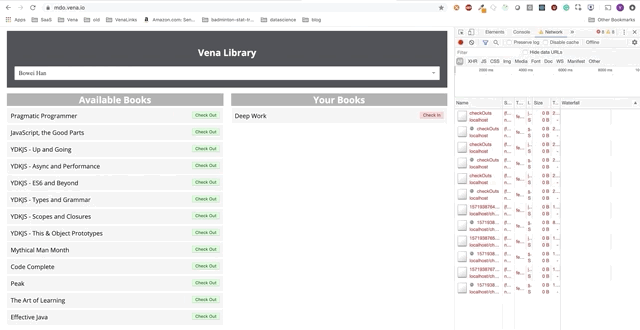
La interacción del usuario ahora ocurre en línea (no literalmente). Los botones "check-in" y "check-out" actualizan la interfaz en consecuencia, aunque los mensajes rojos de la consola muestran que las solicitudes de red no se están ejecutando.
Bueno! Solo hay un pequeño problema con el renderizado optimista fuera de línea ...
¿No perdemos nuestro cambio?

Tarea 4: poner en cola las acciones del usuario para la sincronización
Necesitamos rastrear las acciones realizadas por el usuario cuando estaba desconectado, para poder sincronizarlas con nuestro servidor cuando el usuario regrese a la red. Hay varios mecanismos de almacenamiento en el navegador que pueden actuar como una cola de acciones, y vamos a usar IndexedDB. IndexedDB proporciona algunas cosas que no obtendrá de LocalStorage:
- Operaciones asincrónicas sin bloqueo
- Límites de almacenamiento significativamente más altos
- Gestión de transacciones
Mira nuestro antiguo código reductor:
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Modifíquelo para almacenar los eventos de entrada y salida en IndexedDB durante el evento
FAILURE .
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); addToDB(action);
Aquí está la implementación de la creación de IndexedDB junto con el
addToDB addToDB.
let db = indexedDB.open('actions', 1); db.onupgradeneeded = function(event) { let db = event.target.result; db.createObjectStore('requests', { autoIncrement: true }); }; const addToDB = action => { var db = indexedDB.open('actions', 1); db.onsuccess = function(event) { var db = event.target.result; var objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.add(action); }; };
Ahora que todas nuestras acciones de usuario sin conexión se almacenan en la memoria del navegador, podemos usar el detector de eventos del navegador en
online para sincronizar los datos cuando se restablece la conexión.
window.addEventListener('online', () => { const db = indexedDB.open('actions', 1); db.onsuccess = function(event) { let db = event.target.result; let objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.getAll().onsuccess = function(event) { let requests = event.target.result; for (let request of requests) { send(request);
En esta etapa, podemos borrar la cola de todas las solicitudes que enviamos correctamente al servidor.
Demo número 4
La demostración final parece un poco más complicada. A la derecha, en la ventana oscura del terminal, se registra toda la actividad de la API. La demostración implica desconectarse, seleccionar varios libros y volver a conectarse.
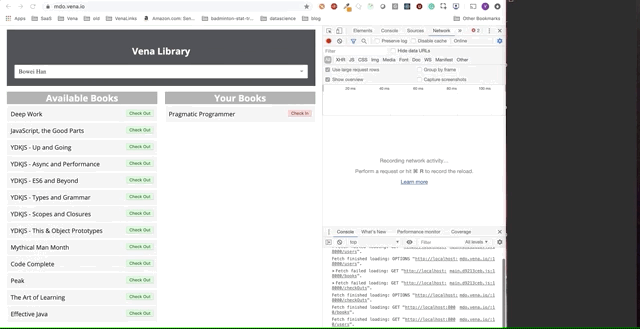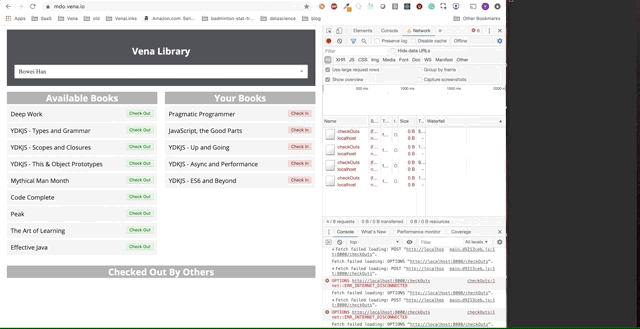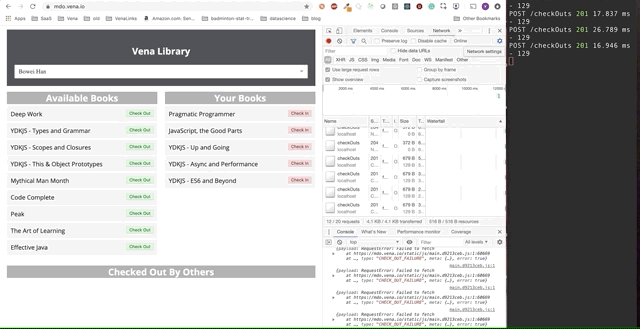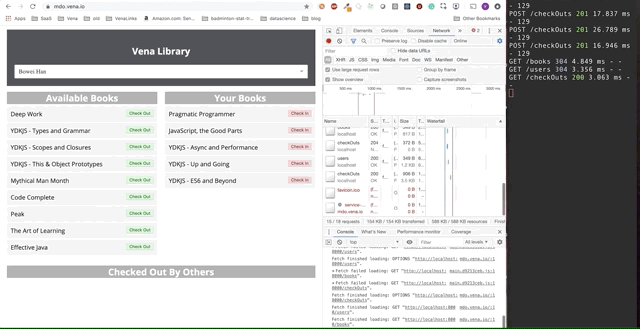
Está claro que las solicitudes realizadas sin conexión se pusieron en cola y se enviaron de inmediato cuando el usuario vuelve a conectarse.
Este enfoque de "juego" es un poco ingenuo; por ejemplo, probablemente no necesitemos hacer dos solicitudes si tomamos y devolvemos el mismo libro. Tampoco funcionará si varias personas usan la misma aplicación.
Eso es todo
¡Salga y haga que sus aplicaciones web estén fuera de línea! Esta publicación muestra algunas de las muchas cosas que puede hacer para agregar funciones independientes a sus aplicaciones, y definitivamente no es exhaustiva.
Para obtener más información, consulte
Fundamentos web de Google . Para ver otra implementación fuera de línea, consulte
esta charla .

Lee también el blog
Empresa EDISON:
20 bibliotecas para
espectacular aplicación para iOS