El 26 de octubre, Linz am Rhein (Alemania) organizó la mini conferencia HaxeUp Sessions 2019 dedicada a Haxe y tecnologías relacionadas. Y su evento más significativo fue, por supuesto, el lanzamiento final de Haxe 4.0.0 (en el momento de la publicación, es decir, después de aproximadamente una semana, se lanzó la actualización 4.0.1 ). En este artículo, me gustaría presentarle una traducción del primer informe de la conferencia: un informe sobre el trabajo realizado por el equipo de Haxe para 2019.

Un poco sobre el autor del informe:
Simon ha estado trabajando con Haxe desde 2010, cuando todavía era estudiante y escribió un trabajo sobre simulaciones fluidas en Flash. La implementación de tal simulación requirió acceso constante a los datos que describen el estado de las partículas (en cada paso se realizaron más de 100 consultas a conjuntos de datos sobre el estado de cada celda en la simulación), mientras que trabajar con conjuntos en ActionScript 3 no es tan rápido. Por lo tanto, la implementación inicial fue simplemente inoperante y necesaria para encontrar una solución a este problema. En su búsqueda, Simon se encontró con un artículo de Nicolas Kannass (creador de Haxe) sobre los códigos de operación de Alchemy que no estaban documentados y que no estaban disponibles con ActionScript, pero Haxe permitió que se usaran. ¡Reescribiendo la simulación en Haxe usando códigos de operación, Simon obtuvo una simulación que funciona! Y así, gracias a las matrices lentas en ActionScript, Simon aprendió sobre Haxe.
Desde 2011, Simon se unió al desarrollo de Haxe, comenzó a estudiar OCaml (en el que está escrito el compilador) y a hacer varias correcciones al compilador.
Y desde 2012, se convirtió en el principal desarrollador de compiladores. En el mismo año, se creó la Fundación Haxe (una organización cuyos objetivos principales son desarrollar y mantener el ecosistema Haxe, ayudar a la comunidad a organizar conferencias y servicios de consultoría), y Simon se convirtió en uno de sus cofundadores.

En 2014-2015, Simon invitó a Josephine Pertosa a la Fundación Haxe, que con el tiempo se hizo responsable de organizar conferencias y relaciones con la comunidad.
En 2016, Simon hizo su primera presentación sobre Haxe , y en 2018 organizó las primeras Sesiones HaxeUp .

Entonces, ¿qué pasó en el mundo de Haxe durante el pasado 2019?
En febrero y marzo, salieron 2 candidatos de lanzamiento (4.0.0-rc1 y 4.0.0-rc2)
En abril, Aurel Bili (como pasante) y Alexander Kuzmenko (como desarrollador del compilador) se unieron al equipo de la Fundación Haxe.
En mayo, se celebró la Haxe US Summit 2019 .
En junio, se lanzó Haxe 4.0.0-rc3. Y en septiembre: Haxe 4.0.0-rc4 y Haxe 4.0.0-rc5.

Haxe no solo es un compilador, sino también un conjunto completo de varias herramientas, y durante todo el año también se trabajó constantemente en ellas:
Gracias a los esfuerzos de Andy Lee, Haxe ahora usa Azure Pipelines en lugar de Travis CI y AppVeyor. Esto significa que el ensamblaje y las pruebas automatizadas ahora son mucho más rápidas.
Hugh Sanderson continúa trabajando en hxcpp (una biblioteca para soportar C ++ en Haxe).
De repente, los usuarios de Github terurou y takashiski se unieron al trabajo en exteriores para Node.js.
Rudy Ges trabajó en soluciones y mejoras para soportar el objetivo de C #.
George Corney continúa apoyando el generador externo HTML.
Jens Fisher está trabajando en vshaxe (una extensión para VS Code para trabajar con Haxe) y en muchos otros proyectos relacionados con Haxe.

Y el evento principal del año, por supuesto, fue el esperado lanzamiento de Haxe 4.0.0 (así como neko 2.3.0), que coincidió accidentalmente con el HaxeUp 2019 Linz :)

Simon dedicó la mayor parte del informe a las nuevas características en Haxe 4.0.0 (también puede aprender sobre ellas a partir del informe de Alexander Kuzmenko de la última Cumbre de Estados Unidos Haxe 2019).

El nuevo intérprete de macros eval es varias veces más rápido que el anterior. Simon habló de él en detalle en su discurso en la Haxe Summit EU 2017 . Pero desde entonces ha mejorado las capacidades de depuración del código, corrigió muchos errores, rediseñó la implementación de cadenas.
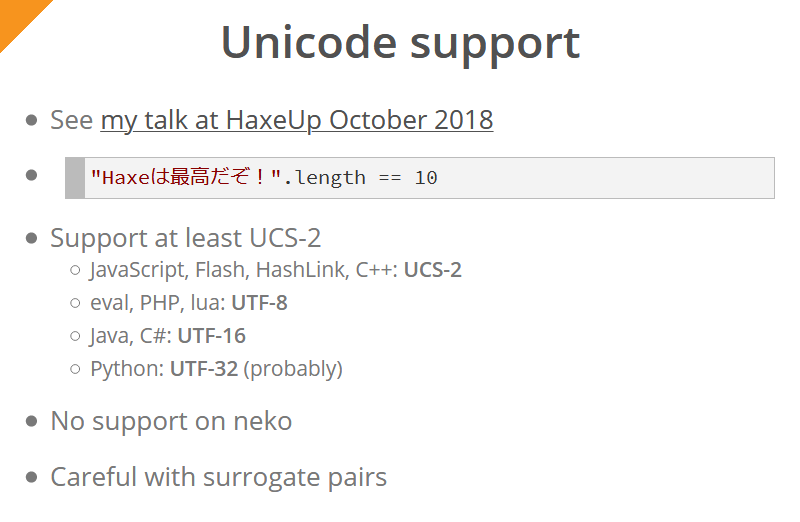
Haxe 4 presenta soporte Unicode para todas las plataformas (excepto Neko). Simon describió esto en detalle en su discurso del año pasado . Para el usuario final del compilador, esto significa que la expresión "Haxeは最高だぞ!".length para todas las plataformas siempre devolverá 10 (de nuevo, excepto Neko).
La codificación UCS-2 es mínimamente compatible (se utiliza una codificación nativa para cada plataforma / idioma; sería poco práctico tratar de admitir la misma codificación en todas partes):
- JavaScript, Flash, HashLink y C ++ usan codificación UCS-2
- para eval, PHP, lua - UTF-8
- para Java y C # - UTF-16
- para Python - UTF-32
Todos los caracteres que están fuera del plano multilingüe principal (incluidos los emoji) se representan como "pares sustitutos"; dichos caracteres se representan con dos bytes. Por ejemplo, si en Java / C # / JavaScript (es decir, para cadenas en codificaciones UTF-16 y UCS-2) solicita la longitud de una cadena que consta de un emoji, el resultado será "2". Este hecho debe tenerse en cuenta al trabajar con tales cadenas en estas plataformas.
Haxe 4 presenta un nuevo tipo de iterador: clave-valor:

Funciona con contenedores de tipo Map (diccionarios) y cadenas (usando la clase StringTools), el soporte para matrices aún no se ha implementado. También es posible implementar dicho iterador para clases personalizadas, para esto es suficiente implementar el método keyValueIterator():KeyValueIterator<K, V> para ellos keyValueIterator():KeyValueIterator<K, V> .
La nueva metaetiqueta @:using permite asociar extensiones estáticas con tipos en el lugar de su declaración.
En el ejemplo que se muestra en la diapositiva siguiente, la enumeración MyOption asociada con MyOptionTools , por lo que expandimos estáticamente esta enumeración (que es imposible en la situación habitual) y tenemos la oportunidad de llamar al método get() , refiriéndolo como un método de objeto.

En este ejemplo, el método get() está en línea, lo que también permite que el compilador optimice aún más el código: en lugar de llamar al MyOptionTools.get(myOption) , el compilador sustituirá el valor almacenado, es decir, 12 .
Si el método no se declara como incrustable, entonces otra herramienta de optimización disponible para el programador es incrustar las funciones en el lugar de su llamada (línea del sitio de la llamada). Para hacer esto, al llamar a la función, debe usar adicionalmente la inline :

Gracias al trabajo de Daniil Korostelev , Haxe ahora tiene la oportunidad de generar clases de ES6 para JavaScript. Todo lo que necesita hacer es agregar el indicador de compilación -D js-es=6 .
Actualmente, el compilador genera un archivo js para todo el proyecto (puede ser posible en el futuro generar archivos js separados para cada una de las clases, pero hasta ahora esto solo se puede hacer usando herramientas adicionales ).

Para enumeraciones abstractas, los valores ahora se generan automáticamente.
En Haxe 3, era necesario establecer valores manualmente para cada constructor. En Haxe 4, las enumeraciones abstractas creadas encima de Int comportan de acuerdo con las mismas reglas que en C. Las enumeraciones abstractas creadas encima de las cadenas se comportan de manera similar; para ellos, los valores generados coincidirán con los nombres de los constructores.

También vale la pena mencionar algunas mejoras de sintaxis:
- Las enumeraciones abstractas y las funciones externas se han convertido en miembros completos de Haxe y ahora no necesita usar las metaetiquetas
@:enum y @:extern para declararlas. - 4th Haxe utiliza un nuevo tipo de sintaxis de intersección que refleja mejor la esencia de las estructuras en expansión. Dichas construcciones son más útiles cuando se declaran estructuras de datos: la expresión
typedef T = A & B significa que la estructura T tiene todos los campos que están en los tipos A y B - de manera similar, las cuatro restricciones del parámetro de tipo de declaración: la entrada
<T:A & B> indica que el tipo de parámetro T debe ser tanto A como B - la sintaxis anterior funcionará (excepto la sintaxis para restricciones de tipo, porque entrará en conflicto con la nueva sintaxis para describir los tipos de función)

La nueva sintaxis para describir los tipos de función (sintaxis de tipo de función) es más lógica: usar paréntesis alrededor de los tipos de argumentos de función es visualmente más fácil de leer. Además, la nueva sintaxis le permite definir nombres de argumentos, que se pueden usar como parte de la documentación del código (aunque no afecta la escritura en sí).

En este caso, la sintaxis anterior sigue siendo compatible y no está en desuso, ya que de lo contrario, requeriría demasiados cambios en el código existente (Simon mismo constantemente se encuentra fuera de hábito y continúa usando la sintaxis anterior).
¡Haxe 4 finalmente tiene funciones de flecha (o expresiones lambda)!

Las características de las funciones de flecha en Haxe son:
return implícito Si el cuerpo de la función consta de una expresión, esta función devuelve implícitamente el valor de esta expresión- Es posible establecer los tipos de argumentos de función, porque el compilador no siempre puede determinar el tipo requerido (por ejemplo,
Float o Int ) - si el cuerpo de la función consta de varias expresiones, entonces necesita rodearlo con llaves
- pero no hay forma de establecer explícitamente el tipo de retorno de la función
En general, la sintaxis de las funciones de flecha es muy similar a la utilizada en Java 8 (aunque funciona de manera algo diferente).
Y como mencionamos Java, debería decirse que en Haxe 4 se hizo posible generar bytecode JVM directamente. Para hacer esto, al compilar un proyecto en Java, simplemente agregue el indicador -D jvm .
Generar un código de bytes JVM significa que no hay necesidad de usar un compilador Java, y el proceso de compilación es mucho más rápido.

Hasta ahora, el objetivo JVM tiene un estado experimental por las siguientes razones:
- en algunos casos, el código de bytes es un poco más lento que el resultado de traducir Haxe en Java y luego compilarlo con javac. Pero el equipo compilador es consciente del problema y sabe cómo solucionarlo, solo requiere trabajo adicional.
- Hay problemas con MethodHandle en Android, que también requiere trabajo adicional (Simon se alegrará si se le ayuda a resolver estos problemas).

Una comparación general de generar bytecode directamente (genjvm) y compilar Haxe en código Java, que luego se compila en bytecode (genjava):
- como ya se mencionó, en términos de velocidad de compilación, genjvm es más rápido que genjava
en términos de velocidad de ejecución, bytecode genjvm sigue siendo inferior a genjava - hay algunos problemas al usar parámetros de tipo y genjava
- genJvm usa MethodHandle para referirse a funciones, y genjava usa las llamadas "funciones Waneck" (en honor a Kaui Vanek , gracias a las cuales Java y C # aparecieron en Haxe). Aunque el código obtenido usando las funciones Waneck no se ve hermoso, funciona y funciona lo suficientemente rápido.
Consejos generales para trabajar con Java en Haxe:
- Debido al hecho de que el recolector de basura en Java es rápido, los problemas asociados con él son raros. Por supuesto, crear objetos nuevos constantemente no es una buena idea, pero Java hace un buen trabajo al administrar la memoria y la necesidad de ocuparse constantemente de las asignaciones no es tan grave como en algunas otras plataformas compatibles con Haxe (por ejemplo, en HashLink)
- Acceder a los campos de una clase en un destino jvm puede funcionar muy lentamente en el caso cuando esto se hace a través de una estructura (
typedef ), mientras que el compilador no puede optimizar dicho código - Se debe evitar el uso excesivo de la palabra clave en
inline : el compilador JIT hace un trabajo bastante bueno - Evite usar
Null<T> , especialmente cuando se trata de cálculos matemáticos complejos. De lo contrario, aparecerán muchas declaraciones condicionales en el código generado, lo que afectará negativamente la velocidad de su código.
La nueva función Haxe 4, Seguridad nula, puede ayudar a evitar el uso de Null<T> . Alexander Kuzmenko habló en detalle sobre ella en el HaxeUp del año pasado .

En el ejemplo de la diapositiva anterior, el método static safe() tiene habilitado el modo Estricto para verificar la seguridad nula, y este método tiene un parámetro arg opcional, que puede tener un valor nulo. Para que esta función se compile con éxito, el programador deberá agregar una verificación del valor del argumento arg (de lo contrario, el compilador mostrará un mensaje sobre la imposibilidad de llamar al método charAt() en un objeto potencialmente nulo).
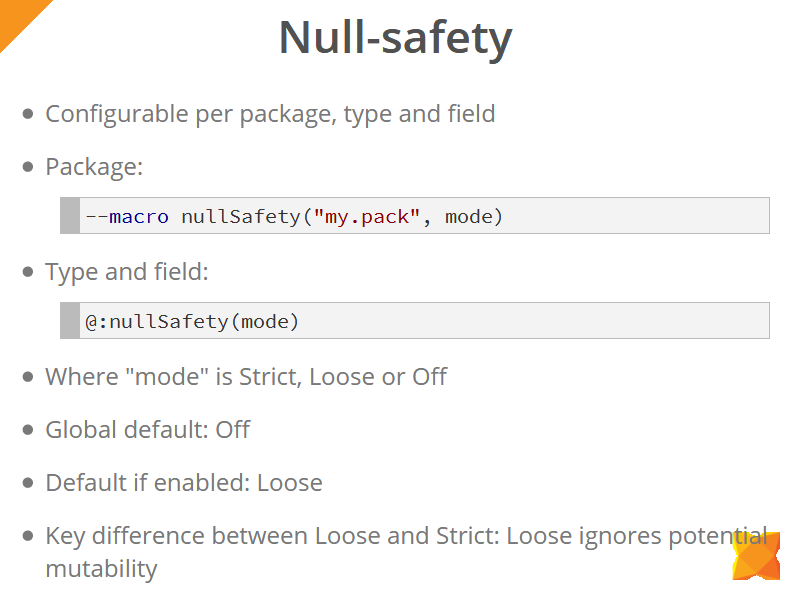
La seguridad nula se puede configurar tanto a nivel de paquete (usando una macro) como a tipos y campos individuales de objetos (usando la metaetiqueta @:nullSafety ).
Los modos en que funcionan las comprobaciones de seguridad nula son: estricto, suelto y desactivado. Globalmente, estas comprobaciones están deshabilitadas (modo desactivado). Cuando están activados, el modo Loose se usa de manera predeterminada (a menos que especifique explícitamente el modo). La diferencia clave entre los modos Loose y Strict es que el modo Loose ignora la posibilidad de cambiar los valores entre operaciones para acceder a estos valores. En el ejemplo de la diapositiva a continuación, vemos que se ha agregado una verificación null para la variable x . Sin embargo, en modo estricto, este código no se compila, porque antes de trabajar directamente con la variable x , se sideEffect() método sideEffect() , que potencialmente puede anular el valor de esta variable, por lo que deberá agregar otra verificación o copiar el valor de la variable a una variable local, con la que continuaremos trabajando.

Haxe 4 presenta una nueva palabra clave final , que tiene un significado diferente según el contexto:
- si lo usa en lugar de la palabra clave
var , al campo declarado de esta manera no se le puede asignar un nuevo valor. Solo puede configurarlo directamente al declarar (para campos estáticos) o en el constructor (para campos no estáticos) - si lo usa al declarar una clase, prohibirá la herencia de ella
- si lo usa como modificador para acceder a la propiedad de un objeto, esto prohíbe la redefinición de getter / setter en las clases herederas.

Teóricamente, el compilador, después de cumplir con la palabra clave final , puede intentar optimizar el código, suponiendo que el valor de este campo no cambia. Pero por ahora, esta posibilidad solo se está considerando y no se implementa en el compilador.

Y un poco sobre el futuro de Haxe:
- actualmente trabajando en API de E / S asíncrona
El apoyo de rutina está planeado, pero hasta ahora, el trabajo en ellos está estancado en la etapa de planificación. Quizás aparezcan en Haxe 4.1, y quizás más tarde. - la optimización de la cola aparecerá en el compilador
- y posiblemente las funciones disponibles a nivel de módulo . Aunque la prioridad de esta función cambia constantemente