El resultado acumulativo (acumulativo) se ha considerado durante mucho tiempo una de las llamadas SQL. Sorprendentemente, incluso después de la aparición de funciones de ventana, sigue siendo un espantapájaros (en cualquier caso, para principiantes). Hoy nos fijamos en la mecánica de las 10 soluciones más interesantes para este problema, desde funciones de ventana hasta hacks muy específicos.
En hojas de cálculo como Excel, el total acumulado se calcula de manera muy simple: el resultado en el primer registro coincide con su valor:
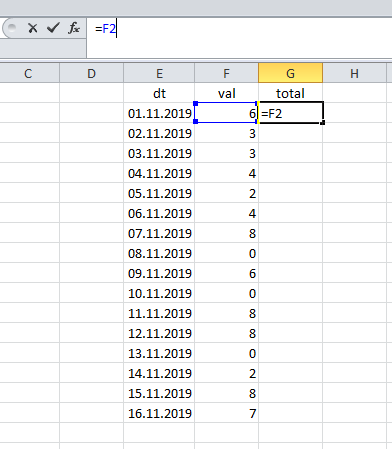
... y luego resumimos el valor actual y el total anterior.

En otras palabras
... o:
La aparición de dos o más grupos en la tabla complica un poco la tarea: ahora contamos varios resultados (para cada grupo por separado). Sin embargo, aquí la solución yace en la superficie: cada vez es necesario verificar a qué grupo pertenece el registro actual.
Haga clic y arrastre , y el trabajo está hecho:
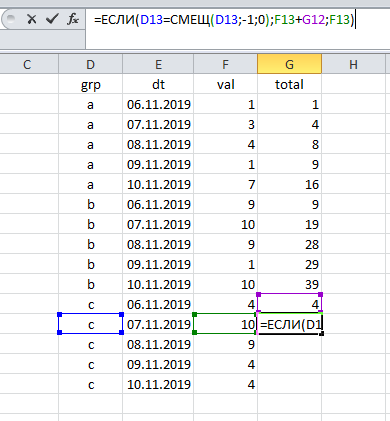
Como puede ver, el cálculo del total acumulado está asociado con dos componentes sin cambios:
(a) ordenar datos por fecha y
(b) refiriéndose a la línea anterior.
¿Pero qué es SQL? Durante mucho tiempo no hubo funcionalidad necesaria en él. Una herramienta necesaria, funciones de ventana, apareció por primera vez solo en el estándar
SQL: 2003 . En este punto, ya estaban en Oracle (versión 8i). Pero la implementación en otros DBMS se retrasó de 5 a 10 años: SQL Server 2012, MySQL 8.0.2 (2018), MariaDB 10.2.0 (2017), PostgreSQL 8.4 (2009), DB2 9 para z / OS (2007 año) e incluso SQLite 3.25 (2018).
1. Funciones de ventana
Las funciones de ventana son probablemente la forma más fácil. En el caso base (tabla sin grupos) consideramos los datos ordenados por fecha:
order by dt
... pero solo nos interesan las líneas anteriores a la actual:
rows between unbounded preceding and current row
En última instancia, necesitamos una suma con estos parámetros:
sum(val) over (order by dt rows between unbounded preceding and current row)
Una solicitud completa se vería así:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
En el caso de un total acumulativo para grupos (campo
grp ) solo necesitamos una pequeña edición. Ahora consideramos los datos divididos en "ventanas" según el grupo:

Para tener en cuenta esta separación, debe usar la
partition by palabra clave:
partition by grp
Y, en consecuencia, considere la cantidad para estas ventanas:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
Luego, toda la consulta se convierte así:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
El rendimiento de las funciones de la ventana dependerá de los detalles de su DBMS (y su versión), el tamaño de la tabla y la disponibilidad de índices. Pero en la mayoría de los casos, este método será el más efectivo. Sin embargo, las funciones de ventana no están disponibles en versiones anteriores del DBMS (que todavía están en uso). Además, no están en DBMS como Microsoft Access y SAP / Sybase ASE. Si se necesita una solución independiente del proveedor, se deben considerar alternativas.
2. Subconsulta
Como se mencionó anteriormente, las funciones de ventana se introdujeron muy tarde en el DBMS principal. Este retraso no debería ser sorprendente: en la teoría relacional, los datos no están ordenados. Mucho más al espíritu de la teoría relacional corresponde a una solución a través de una subconsulta.
Tal subconsulta debe considerar la suma de valores con una fecha anterior a la actual (e incluyendo la actual):
.
Lo que en el código se ve así:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
Una solución un poco más eficiente será en la que la subconsulta considera el total hasta la fecha actual (pero no lo incluye), y luego lo resume con el valor en la fila:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
En el caso de un resultado acumulativo para varios grupos, necesitamos usar una subconsulta correlacionada:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
La condición
g.grp = t2.grp verifica la inclusión de las líneas en el grupo (que, en principio, es similar al trabajo de
partition by grp en las funciones de la ventana).
3. Conexión interna
Dado que las subconsultas y las uniones son intercambiables, podemos reemplazar fácilmente una por otra. Para hacer esto, debe usar Self Join, conectando dos instancias de la misma tabla:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Como puede ver, la condición de filtrado en la subconsulta
t2.dt <= s.dt ha convertido en una condición de unión. Además, para usar la función de agregación
sum() necesitamos agrupar por fecha y valor por
group by s.dt, s.val .
Del mismo modo, puede hacerlo para el caso con diferentes grupos de
grp :
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. Producto cartesiano
Dado que reemplazamos la subconsulta con join, ¿por qué no probar el producto cartesiano? Esta solución requerirá solo ediciones mínimas:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
O para el caso de grupos:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
Las soluciones enumeradas (subconsulta, unión interna, unión cartesiana) corresponden a
SQL-92 y
SQL: 1999 , y por lo tanto estarán disponibles en casi cualquier DBMS. El principal problema con todas estas soluciones es el bajo rendimiento. Esto no es un gran problema si materializamos una tabla con el resultado (¡pero aún así quieres más velocidad!). Otros métodos son mucho más efectivos (ajustados para los detalles de DBMS específicos y sus versiones ya especificadas, tamaño de tabla, índices).
5. Solicitud recursiva
Uno de los enfoques más específicos es una consulta recursiva en una expresión de tabla común. Para hacer esto, necesitamos un "ancla", una consulta que devuelve la primera línea:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
Luego, con la ayuda de
union all , los resultados de una consulta recursiva se agregan al "ancla". Para hacer esto, puede confiar en el campo de fecha
dt , agregando un día:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
La parte del código que agrega un día no es universal. Por ejemplo, esto es
r.dt = dateadd(day, 1, cte.dt) para SQL Server,
r.dt = cte.dt + 1 para Oracle, etc.
Combinando el "ancla" y la solicitud principal, obtenemos el resultado final:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
La solución para el caso con grupos no será mucho más complicada:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6. row_number() recursiva con la función row_number()
La decisión anterior se basó en la continuidad del campo de fecha
dt con un aumento secuencial de 1 día.
row_number() esto usando la función de ventana
row_number() , que numera las filas. Por supuesto, esto es injusto, porque vamos a considerar alternativas a las funciones de la ventana. Sin embargo, esta solución puede ser una especie de
prueba de concepto : en la práctica, puede haber un campo que reemplace los números de línea (id de registro). Además, en SQL Server, la función
row_number() apareció antes de que se introdujera el soporte completo para las funciones de ventana (incluida
sum() ).
Entonces, para una consulta recursiva con
row_number() necesitamos dos STE. En el primero, solo numeramos las líneas:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... y si el número de fila ya está en la tabla, puede prescindir de él. En la siguiente consulta, ya nos
cte1 a
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
Y toda la solicitud se ve así:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... o para el caso de grupos:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY LATERAL / LATERAL
Una de las formas más exóticas de calcular un total acumulado es usar la instrucción
CROSS APPLY (SQL Server, Oracle) o su equivalente
LATERAL (MySQL, PostgreSQL). Estos operadores aparecieron bastante tarde (por ejemplo, en Oracle solo desde la versión 12c). Y en algunos DBMS (por ejemplo,
MariaDB ) no lo son en absoluto. Por lo tanto, esta decisión es de interés puramente estético.
Funcionalmente, usar
CROSS APPLY o
LATERAL idéntico a la subconsulta: adjuntamos el resultado del cálculo a la solicitud principal:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... que se ve así:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
La solución para el caso con grupos será similar:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
Total: examinamos las principales soluciones independientes de la plataforma. ¡Pero hay soluciones específicas para DBMS específicos! Dado que hay muchas opciones aquí, analicemos algunas de las más interesantes.
8. Declaración MODEL (Oracle)
La declaración
MODEL en Oracle proporciona una de las soluciones más elegantes. Al comienzo del artículo, examinamos la fórmula general del total acumulado:
MODEL permite implementar esta fórmula literalmente uno a uno! Para hacer esto, primero llenamos el campo
total con los valores de la fila actual
select dt, val, val as total from test_simple
... luego calculamos el número de fila como
row_number() over (order by dt) as rn (o usar el campo terminado con el número, si lo hay). Y finalmente, presentamos una regla para todas las líneas excepto la primera:
total[rn >= 2] = total[cv() - 1] + val[cv()] .
La función
cv() aquí es responsable del valor de la línea actual. Y toda la solicitud se verá así:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. Cursor (SQL Server)
Un total acumulado es uno de los pocos casos en los que el cursor en SQL Server no solo es útil, sino también preferible a otras soluciones (al menos hasta la versión 2012, donde aparecieron las funciones de ventana).
La implementación a través del cursor es bastante trivial. Primero debe crear una tabla temporal y llenarla con fechas y valores desde el principal:
create table
Luego establecemos las variables locales a través de las cuales tendrá lugar la actualización:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
Después de eso, actualizamos la tabla temporal a través del cursor:
declare cur cursor local static read_only forward_only for select dt, val from
Y finalmente, obtenemos el resultado deseado:
select dt, val, total from
10. Actualización a través de una variable local (SQL Server)
La actualización a través de una variable local en SQL Server se basa en un comportamiento no documentado, por lo que no puede considerarse confiable. Sin embargo, esta es quizás la solución más rápida, y esto es interesante.
Creemos dos variables: una para totales acumulativos y una variable de tabla:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
Primero, complete
@tv datos de la tabla principal
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
Luego actualizamos la variable de tabla
@tv usando
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... después de lo cual obtenemos el resultado final:
select * from @tv order by dt;
Resumen: revisamos las 10 formas principales de calcular los totales acumulados en SQL. Como puede ver, incluso sin funciones de ventana, este problema es completamente solucionable, y la mecánica de la solución no se puede llamar complicada.