Hola a todos! Hace unos meses, lanzamos nuestro nuevo proyecto de código abierto, el complemento Grafana para monitorear kubernetes, llamado
DevOpsProdigy KubeGraf, en producción . El código fuente del complemento está disponible en el
repositorio público en GitHub . Y en este artículo queremos compartir con ustedes una historia sobre cómo creamos el complemento, qué herramientas utilizamos y qué dificultades encontramos durante el proceso de desarrollo. Vamos!
Parte 0 - introductoria: ¿cómo llegamos a esto?
La idea de escribir nuestro propio complemento para Grafan nació por casualidad. Nuestra empresa ha estado monitoreando proyectos web de varios niveles de complejidad durante más de 10 años. Durante este tiempo, hemos adquirido una gran experiencia, casos interesantes y experiencia en el uso de diversos sistemas de monitoreo. Y en algún momento nos preguntamos: "¿Existe una herramienta mágica para monitorear Kubernetes de modo que, como dicen," configurar y olvidar ""? Promstandart para monitorear k8s, por supuesto, ha sido durante mucho tiempo un montón de Prometheus + Grafana. Y como soluciones listas para usar para esta pila, hay un gran conjunto de varios tipos de herramientas: prometheus-operator, conjunto de paneles kubernetes-mixin, grafana-kubernetes-app.
El complemento grafana-kubernetes-app parecía ser la opción más interesante para nosotros, pero no ha sido compatible durante más de un año y, además, no sabe cómo trabajar con nuevas versiones de exportador de nodos y métricas de estado de kube. Y en algún momento, decidimos: "¿Pero no tomamos nuestra propia decisión?"
Qué ideas decidimos implementar en nuestro complemento:
- visualización del "mapa de aplicación": presentación conveniente de aplicaciones en el clúster, agrupadas por espacio de nombres, despliegue ...;
- visualización de conexiones de la forma "despliegue - servicio (+ puertos)".
- visualización de la distribución de aplicaciones de clúster por nodos de clúster.
- recolectando métricas e información de varias fuentes: Prometheus y el servidor k8s api.
- monitoreo tanto de la parte de infraestructura (uso del tiempo del procesador, memoria, subsistema de disco, red) como de la lógica de la aplicación: pods de estado de salud, el número de réplicas disponibles, información sobre el paso de muestras de vida / preparación.
Parte 1: ¿Qué es el complemento Grafana?
Desde un punto de vista técnico, el complemento para Grafana es un controlador angular, que se almacena en el directorio de datos de
Grafan (
/var/grafana/plugins/<your_plugin_name>/dist/module.js ) y se puede cargar como un módulo SystemJS. También en este directorio debe haber un archivo plugin.json que contenga toda la metainformación sobre su complemento: nombre, versión, tipo de complemento, enlaces al repositorio / sitio / licencia, dependencias, etc.
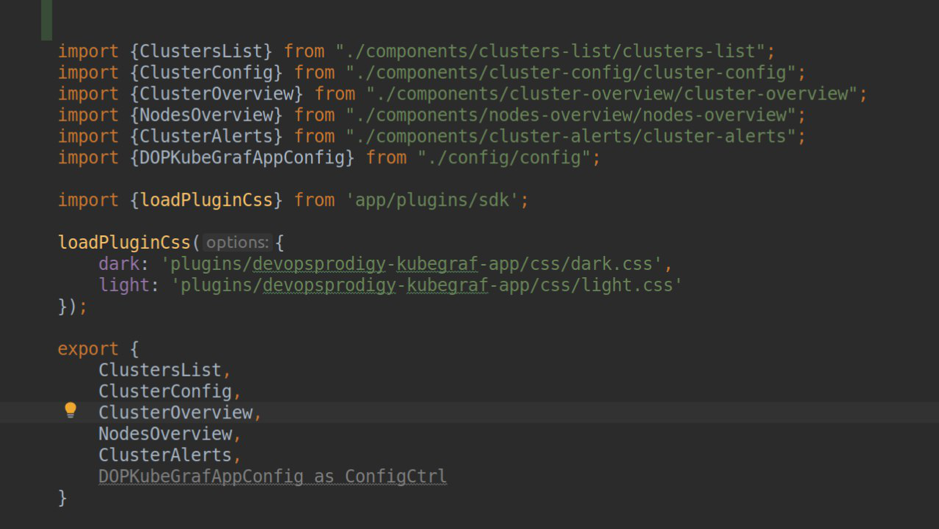 module.ts
module.ts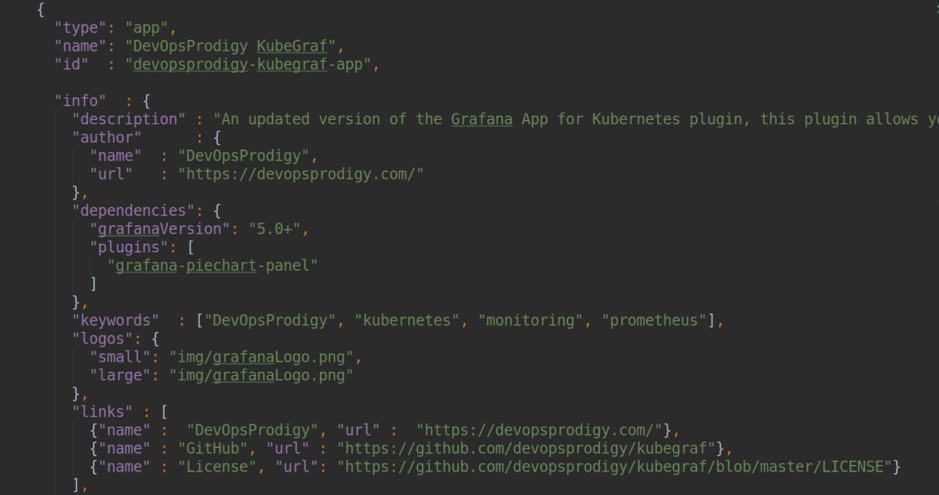 plugin.json
plugin.jsonComo puede ver en la captura de pantalla, especificamos plugin.type = app. Los complementos para Grafana pueden ser de tres tipos:
panel : el tipo más común de complemento: es un panel para visualizar cualquier métrica, se usa para construir varios paneles.
fuente de
datos : conector enchufable a cualquier fuente de datos (por ejemplo, Prometheus-datasource, ClickHouse-datasource, ElasticSearch-datasource).
aplicación : un complemento que le permite crear su propia aplicación frontend dentro de Grafana, crear sus propias páginas html y acceder manualmente a la fuente de datos para visualizar diversos datos. Además, los complementos de otros tipos (fuente de datos, panel) y varios paneles se pueden usar como dependencias.
 Un ejemplo de dependencias de complementos con type = app
Un ejemplo de dependencias de complementos con type = app .
Como lenguaje de programación, puede usar JavaScript y TypeScript (optamos por él). Puede
encontrar los espacios en blanco para los complementos de hello-world de cualquier tipo
aquí : en este repositorio hay una gran cantidad de paquetes de inicio (incluso hay un ejemplo experimental de un complemento en React) con constructores preinstalados y configurados.
Parte 2: prepara tu entorno local
Para trabajar en el complemento, naturalmente necesitamos un clúster de kubernetes con todas las herramientas preinstaladas: prometeo, exportador de nodos, métricas de estado de kube, grafana. El entorno debe configurarse rápida, fácil y naturalmente, y para proporcionar datos de recarga en caliente, el directorio Grafana debe montarse directamente desde la máquina del desarrollador.
La forma más conveniente, en nuestra opinión, de trabajar localmente con kubernetes es
minikube . El siguiente paso es configurar el paquete Prometheus + Grafana usando el operador prometheus.
Este artículo detalla el proceso de instalación de prometheus-operator en minikube. Para habilitar la persistencia, debe establecer el parámetro
persistence: true en el archivo chart / grafana / values.yaml, agregar su propio PV y PVC y especificarlos en el parámetro persistence.existingClaim
El script de lanzamiento final de minikube se ve así:
minikube start --kubernetes-version=v1.13.4 --memory=4096 --bootstrapper=kubeadm --extra-config=scheduler.address=0.0.0.0 --extra-config=controller-manager.address=0.0.0.0 minikube mount /home/sergeisporyshev/Projects/Grafana:/var/grafana --gid=472 --uid=472 --9p-version=9p2000.L
Parte 3: desarrollo en sí
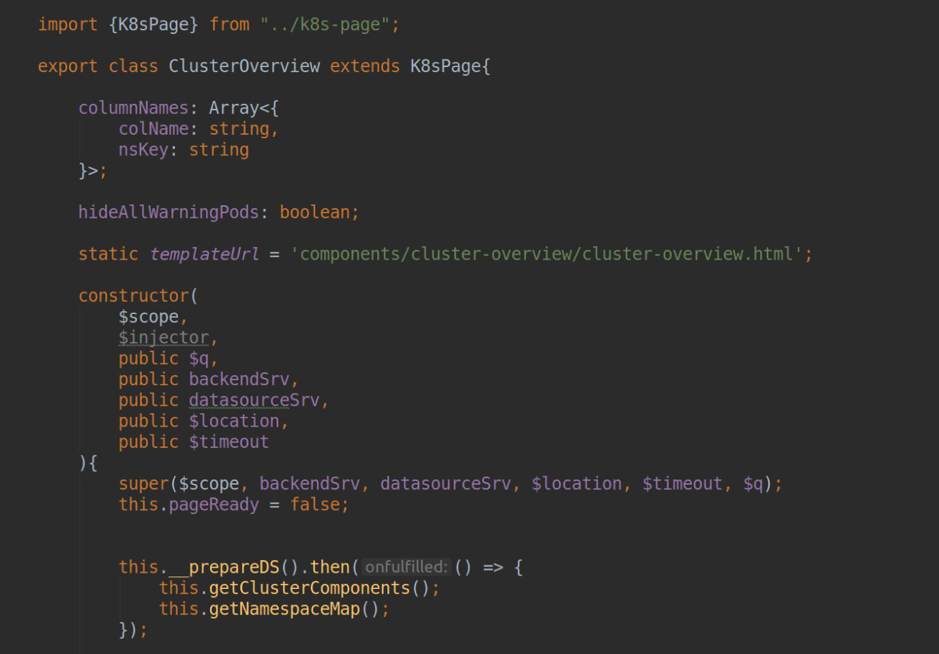
Modelo de objetoEn preparación para la implementación del complemento, decidimos describir todas las entidades básicas de Kubernetes con las que trabajaremos como clases TypeScript: pod, implementación, daemonset, statefulset, job, cronjob, service, node, namespace. Cada una de estas clases hereda de la clase BaseModel común, que describe el constructor, el destructor, los métodos para actualizar y cambiar la visibilidad. Cada una de las clases describe relaciones anidadas con otras entidades, por ejemplo, una lista de pods para una entidad de tipo despliegue.
import {Pod} from "./pod"; import {Service} from "./service"; import {BaseModel} from './traits/baseModel'; export class Deployment extends BaseModel{ pods: Array<Pod>; services: Array<Service>; constructor(data: any){ super(data); this.pods = []; this.services = []; } }
Con getters y setters, podemos mostrar o establecer las métricas de las entidades que necesitamos de una manera conveniente y legible. Por ejemplo, la salida formateada de los nodos de CPU asignables:
get cpuAllocatableFormatted(){ let cpu = this.data.status.allocatable.cpu; if(cpu.indexOf('m') > -1){ cpu = parseInt(cpu)/1000; } return cpu; }
PáginasUna lista de todas las páginas de nuestro complemento se describe inicialmente en nuestro pluing.json en la sección de dependencia:
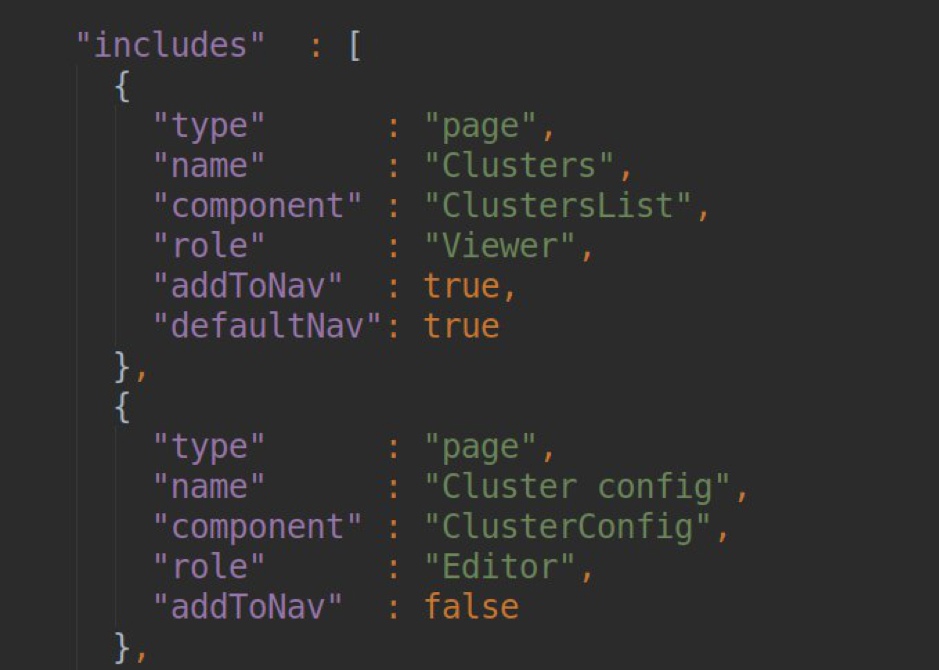
En el bloque de cada página, debemos indicar el TÍTULO DE LA PÁGINA (luego se convertirá en slug, por lo que esta página estará disponible); nombre del componente responsable del funcionamiento de esta página (la lista de componentes se exporta a module.ts); especificando el rol del usuario para quien el acceso a esta página está disponible y la configuración de navegación para la barra lateral.
En el componente responsable del funcionamiento de la página, debemos instalar templateUrl, pasando allí la ruta al archivo html con marcado. Dentro del controlador, a través de la inyección de dependencia, podemos acceder a hasta 2 servicios angulares importantes:
- backendSrv: un servicio que proporciona interacción con el grafana api-server;
- datasourceSrv: un servicio que proporciona interacción local con todas las fuentes de datos instaladas en su Grafana (por ejemplo, el método .getAll () devuelve una lista de todas las fuentes de datos instaladas; .get (<nombre>): devuelve un objeto de instancia de una fuente de datos particular.
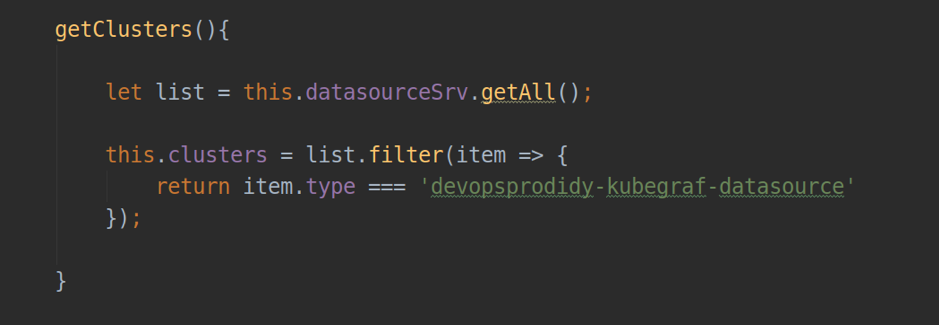
Parte 4: fuente de datos
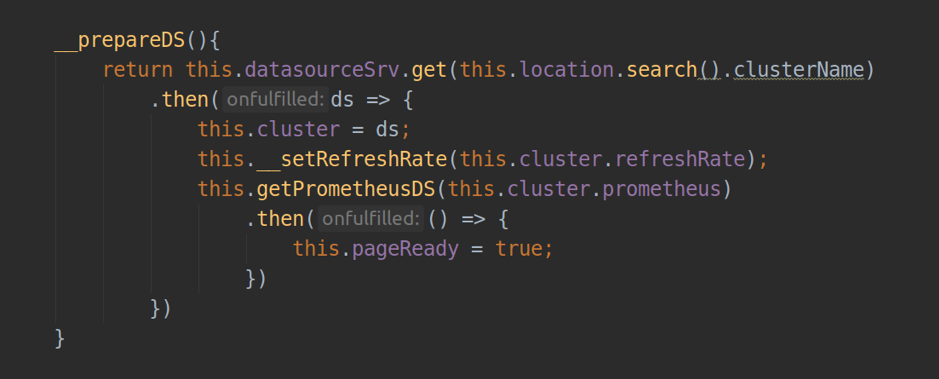
Desde el punto de vista de Grafana, el origen de datos es exactamente el mismo complemento que todos los demás: tiene su propio punto de entrada module.js, hay un archivo con metainformación plugin.json. Al desarrollar un complemento con type = app, podemos interactuar con la fuente de datos existente (por ejemplo, prometheus-datasource), así como con la nuestra, que podemos almacenar directamente en el directorio de complementos (dist / datasource / *) o establecer como una dependencia. En nuestro caso, la fuente de datos viene con el código del complemento. También es necesario tener la plantilla config.html y el controlador ConfigCtrl que se utilizará para la página de configuración de la instancia de fuente de datos y el controlador de fuente de datos, que implementa la lógica de su fuente de datos.
En el complemento KubeGraf, desde el punto de vista de la interfaz de usuario, la fuente de datos es una instancia del clúster kubernetes en el que se implementan las siguientes características (el código fuente está disponible
por referencia ):
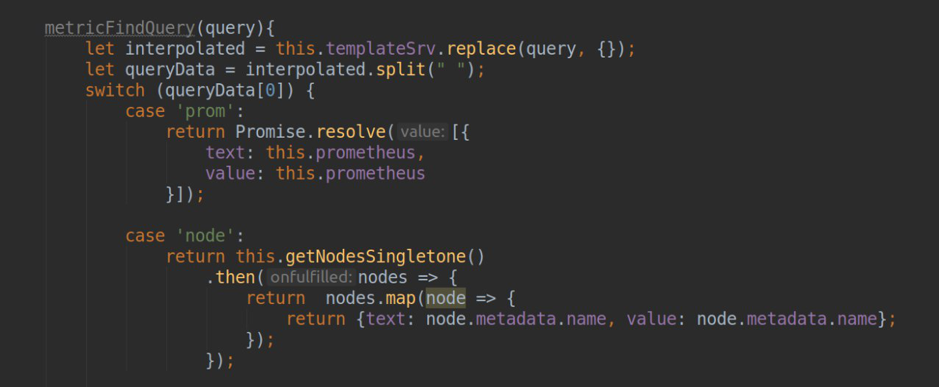
- recopilación de datos del servidor de API k8s (obtener una lista de namespace'ov, despliegue'ov ...)
- solicitudes de representación en prometheus-datasource (que se selecciona en la configuración del complemento para cada clúster específico) y formateando respuestas para usar datos tanto en páginas estáticas como en paneles.
- actualizar datos en páginas estáticas del complemento (con la frecuencia de actualización establecida).
- procesar solicitudes para generar una lista de plantillas en grafana-dashboards (método .metriFindQuery ())
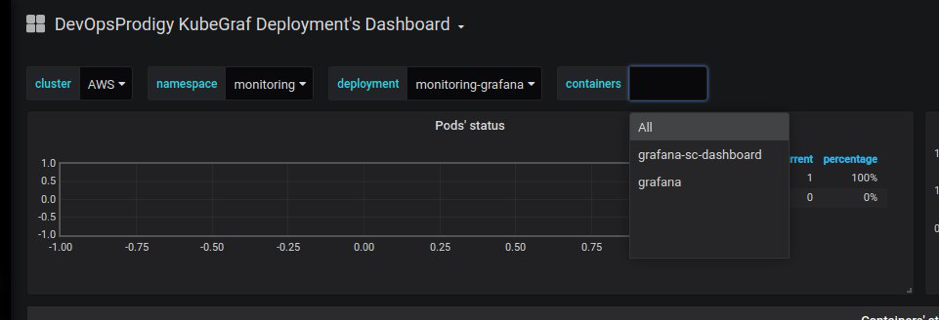
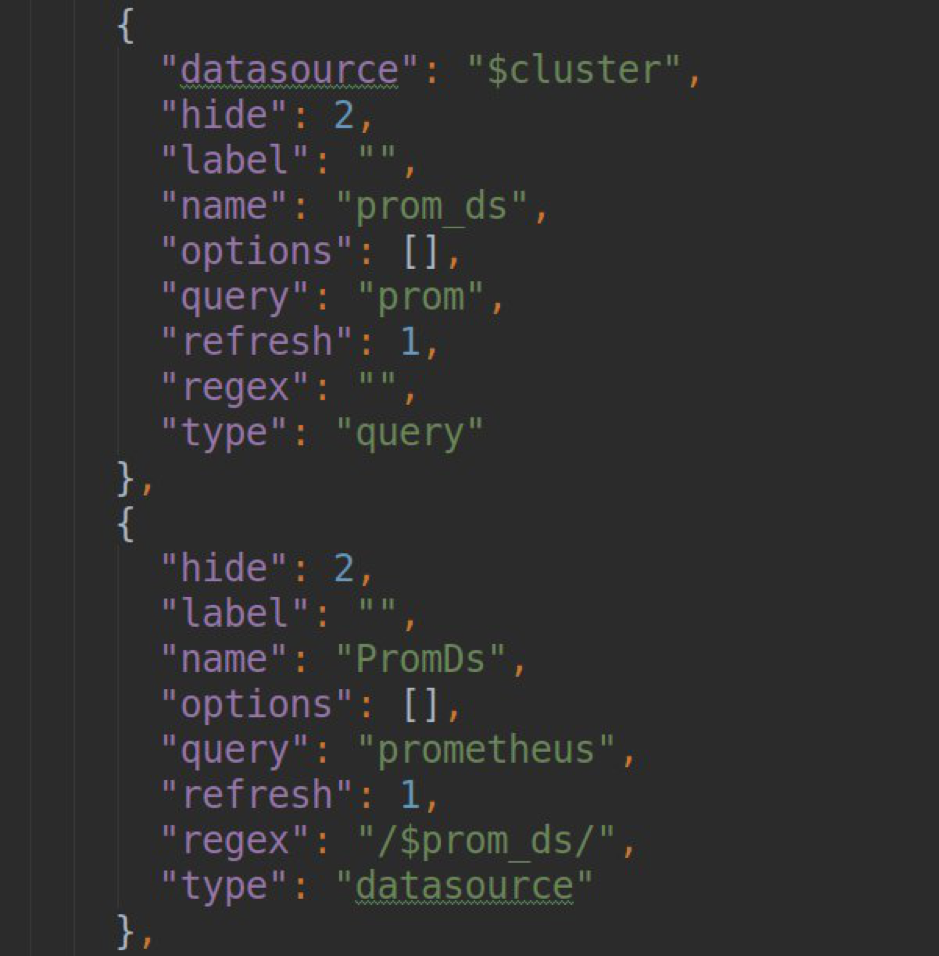
- prueba de conexión con el clúster k8s final.
testDatasource(){ let url = '/api/v1/namespaces'; let _url = this.url; if(this.accessViaToken) _url += '/__proxy'; _url += url; return this.backendSrv.datasourceRequest({ url: _url, method: "GET", headers: {"Content-Type": 'application/json'} }) .then(response => { if (response.status === 200) { return {status: "success", message: "Data source is OK", title: "Success"}; }else{ return {status: "error", message: "Data source is not OK", title: "Error"}; } }, error => { return {status: "error", message: "Data source is not OK", title: "Error"}; }) }
Un punto interesante separado, en nuestra opinión, es la implementación del mecanismo de autenticación y autorización para la fuente de datos. Como regla, fuera de la caja para configurar el acceso a la fuente de datos final, podemos usar el componente Grafana incorporado: datasourceHttpSettings. Con este componente, podemos configurar el acceso al origen de datos http especificando la url y la configuración básica de autenticación / autorización: contraseña de inicio de sesión o clave de cliente / certificado de cliente. Para darme cuenta de la capacidad de configurar el acceso utilizando un token de portador (de facto el estándar para k8s), tuve que hacer un poco de "química".
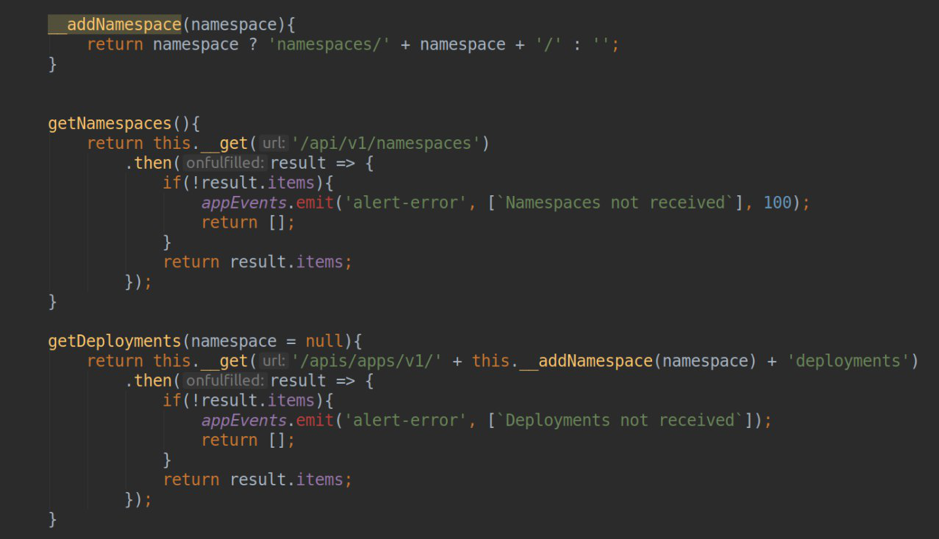
Para resolver este problema, puede utilizar el mecanismo integrado de "Rutas de complementos" de Grafana (más información en la
página de documentación oficial ). En la configuración de nuestra fuente de datos, podemos declarar un conjunto de reglas de enrutamiento que serán procesadas por el servidor proxy grafana. Por ejemplo, para cada punto final individual existe la posibilidad de colocar encabezados o URL con la capacidad de crear plantillas, cuyos datos se pueden tomar de los campos jsonData y secureJsonData (para almacenar contraseñas o tokens en forma cifrada). En nuestro ejemplo, las solicitudes del formulario
/ __ proxy / api / v1 / namespaces se enviarán a la url del formulario
<your_k8s_api_url> / api / v1 / namespaces con la Autorización: encabezado de portador.
Naturalmente, para trabajar con el servidor de api k8s, necesitamos un usuario con acceso de solo lectura, el manifiesto para crear que también puede encontrar en el
código fuente del complemento .
Parte 5: lanzamiento

Después de escribir su propio complemento para Grafana, naturalmente querrá ponerlo en el dominio público. Grafana es una biblioteca de complementos disponible en
grafana.com/grafana/pluginsPara que su complemento esté disponible en la tienda oficial, debe hacer relaciones públicas en
este repositorio agregando los siguientes contenidos al archivo repo.json:
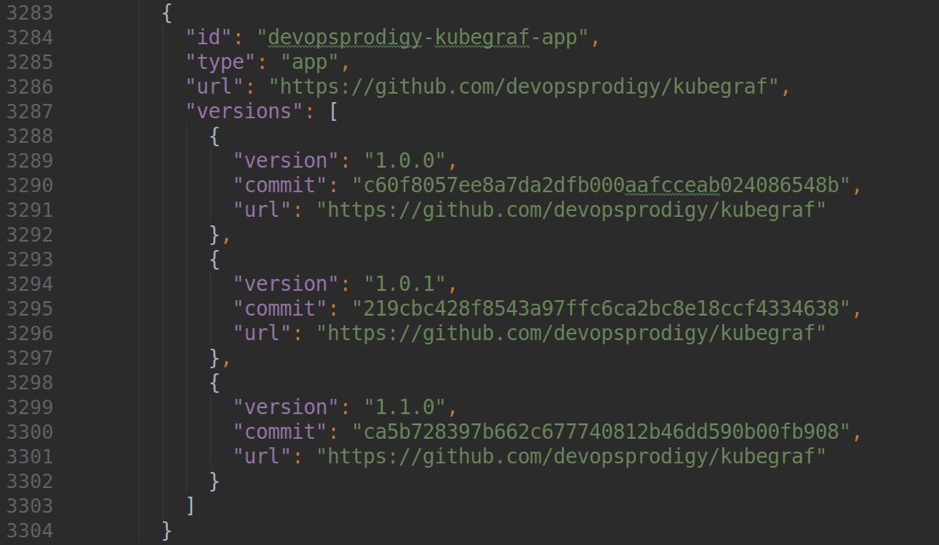
donde version es la versión de su complemento, url es un enlace al repositorio, y commit es un hash del commit, mediante el cual estará disponible una versión específica del complemento.
Y a la salida verá una imagen maravillosa de la forma:
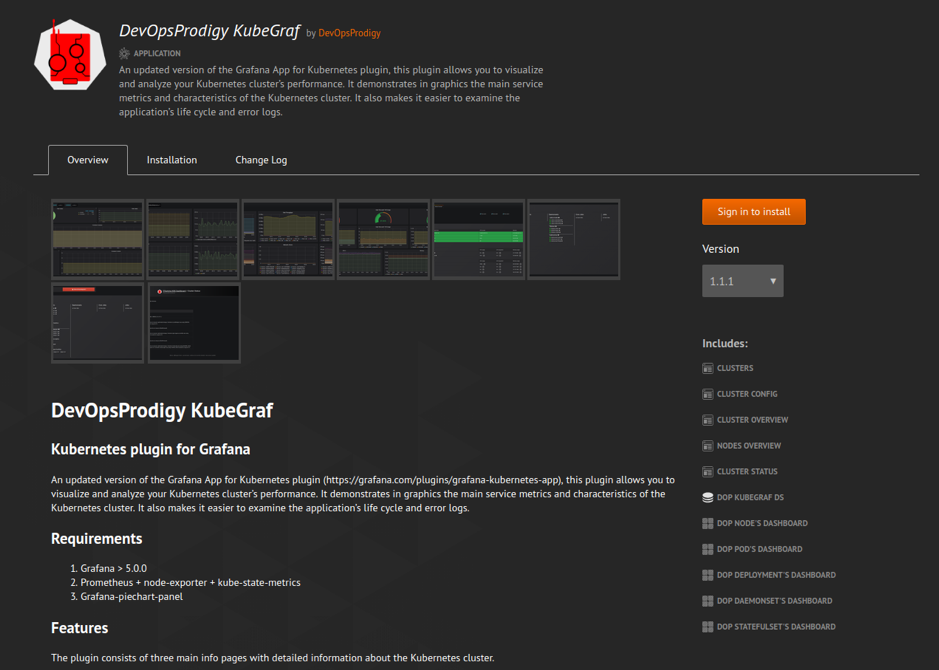
Los datos se tomarán automáticamente de su archivo Readme.md, Changelog.md y el archivo plugin.json con la descripción del complemento.
Parte 6: en lugar de conclusiones
No dejamos de desarrollar nuestro complemento después del lanzamiento. Y ahora estamos trabajando en el monitoreo correcto del uso de los recursos de los nodos del clúster, la introducción de nuevas características para aumentar la experiencia de usuario, y también estamos acumulando una gran cantidad de comentarios recibidos después de instalar el complemento tanto por parte de nuestros clientes como del ishui en el github (si deja su problema o solicitud de extracción, yo Estaré muy feliz :-)).
Esperamos que este artículo lo ayude a comprender una herramienta tan excelente como Grafana y, posiblemente, a escribir su propio complemento.
Gracias!)