A continuación del tema, examinaremos los tipos de protocolo y el código generalizado.
Los siguientes problemas serán considerados en el camino:
- implementación de polimorfismo sin herencia y tipos de referencia
- cómo se almacenan y usan los objetos de tipo de protocolo
- cómo funciona el envío de métodos con ellos
Tipos de protocolo
Implementación de polimorfismo sin herencia y tipos de referencia:
protocol Drawable { func draw() } struct Point: Drawable { var x, y: Int func draw() { ... } } struct Line: Drawable { var x1, x2, y1, y2: Int func draw() { ... } } var drawbles = [Drawable]() for d in drawbles { d.draw() }
- Denote el protocolo Drawable, que tiene un método de dibujo.
- Implementamos este protocolo para Punto y Línea: ahora puede manejarlos como con Drawable (llame al método de dibujo)
Todavía tenemos un código polimórfico. El elemento d de la matriz dibujable tiene una interfaz, que se indica en el protocolo Drawable, pero tiene diferentes implementaciones de sus métodos, que se indican en Línea y Punto.
El principio principal (ad-hoc) del polimorfismo: "Interfaz común - muchas implementaciones"
Despacho dinámico sin mesa virtual
Recuerde que la definición de la implementación correcta del método cuando se trabaja con clases (tipos de referencia) se logra a través de la Presentación dinámica y una tabla virtual. Cada tipo de clase tiene una tabla virtual; almacena implementaciones de sus métodos. El despacho dinámico define la implementación del método para un tipo examinando su tabla virtual. Todo esto es necesario debido a la posibilidad de herencia y anulación de métodos.
En el caso de las estructuras, la herencia, así como la redefinición de métodos, es imposible. Entonces, a primera vista, no hay necesidad de una mesa virtual, pero ¿cómo funcionará el despacho dinámico? ¿Cómo puede un programa entender qué método se llamará en d.draw ()?
Vale la pena señalar que el número de implementaciones de este método es igual al número de tipos que se ajustan al protocolo Drawable.
Tabla de testigos de protocolo
es la respuesta a esta pregunta Cada tipo que implementa un protocolo tiene esta tabla. Al igual que una tabla virtual para clases, almacena implementaciones de los métodos que requiere el protocolo.
en lo sucesivo, la Tabla de Testigos de Protocolo se denominará "tabla de métodos de protocolo"
Ok, ahora sabemos dónde buscar implementaciones de métodos. Solo quedan dos preguntas:
- ¿Cómo encontrar la tabla de protocolo-método apropiada para un objeto que implementó este protocolo? ¿Cómo en nuestro caso encontrar esta tabla para el elemento d de la matriz de drawables?
- Los elementos de la matriz deben ser del mismo tamaño (esta es la esencia de la matriz). Entonces, ¿cómo puede una matriz dibujable cumplir con este requisito si puede almacenar tanto Línea como Punto, y tienen diferentes tamaños?
MemoryLayout.size(ofValue: Line(...))
Contenedor existencial
Para abordar estos dos problemas, Swift utiliza un esquema de almacenamiento especial para instancias de tipos de protocolo llamado contenedor existencial. Se ve así:

Toma 5 palabras de máquina (en el sistema x64 bit 5 * 8 = 40 bits). Se divide en tres partes:
valor buffer - espacio para la instancia en sí
vwt: puntero a la tabla Testigo de valor
pwt: puntero a la tabla de testigos de protocolo
Considere las tres partes con más detalle:
Buffer de contenido
Solo tres palabras de máquina para almacenar una instancia. Si la instancia puede caber en el búfer de contenido, entonces se almacena en ella. Si la instancia tiene más de 3 palabras de máquina, entonces no cabe en el búfer y el programa se ve obligado a asignar memoria en el montón, colocar la instancia allí y colocar un puntero a esta memoria en el búfer de contenido. Considere un ejemplo:
let point: Drawable = Point(...)
Point () ocupa 2 palabras de máquina y encaja perfectamente en el búfer de valores: el programa lo colocará allí:

let line: Drawable = Line(...)
Line () ocupa 4 palabras de máquina y no puede caber en un búfer de valor: el programa asignará memoria para el montón y agregará un puntero a esta memoria en el búfer de valor:

ptr apunta a una instancia de Line () colocada en el montón:

Tabla del ciclo de vida
Además de la tabla de método de protocolo, cada tabla que tiene el protocolo tiene esta tabla. Contiene una implementación de cuatro métodos: asignar, copiar, destruir, desasignar. Estos métodos controlan todo el ciclo de vida de un objeto. Considere un ejemplo:
- Al crear un objeto (Punto (...) como Dibujable), el método de asignación de T.Zh. este objeto El método de asignación decide dónde se debe colocar el contenido del objeto (en el búfer de valor o en el montón), y si se debe colocar en el montón, asignará la cantidad de memoria requerida
- El método de copia colocará el contenido del objeto en el lugar apropiado.
- Después de terminar el trabajo con el objeto, se llamará al método de destrucción, que reducirá todos los recuentos de enlaces, si corresponde.
- Después de la destrucción, se llamará al método de desasignación, que liberará la memoria asignada en el montón, si la hay.
Tabla de métodos de protocolo
Como se describió anteriormente, contiene implementaciones de los métodos requeridos por el protocolo para el tipo al que está vinculada esta tabla.
Contenedor Existencial - Respuestas
Por lo tanto, respondimos dos preguntas planteadas:
- La tabla de método de protocolo se almacena en el contenedor Existencial de este objeto y se puede obtener fácilmente de él.
- Si el tipo de un elemento de matriz es un protocolo, cualquier elemento de esta matriz toma un valor fijo de 5 palabras de máquina; esto es exactamente lo que se necesita para un contenedor existencial. Si el contenido del elemento no se puede colocar en el búfer de valor, se colocará en el montón. Si puede, todo el contenido se colocará en el búfer de valores. En cualquier caso, obtenemos que el tamaño del objeto con el tipo de protocolo es de 5 palabras de máquina (40 bits), y se deduce que todos los elementos de la matriz tendrán el mismo tamaño.
let line: Drawable = Line(...) MemoryLayout.size(ofValue: line)
Contenedor existencial - Ejemplo
Considere el comportamiento de un contenedor existencial en este código:
func drawACopy(local: Drawable) { local.draw() } let val: Drawable = Line(...) drawACopy(val)
Un contenedor existencial puede representarse así:
struct ExistContDrawable { var valueBuffer: (Int, Int, Int) var vwt: ValueWitnessTable var pwt: ProtocolWitnessTable }
Pseudocódigo
Detrás de escena, la función drawACopy incluye ExistContDrawable:
func drawACopy(val: ExistContDrawable) { ... }
El parámetro de función se crea manualmente: crea un contenedor, llena sus campos del argumento recibido:
func drawACopy(val: ExistContDrawable) { var local = ExistContDrawable() let vwt = val.vwt let pwt = val.pwt local.type = type local.pwt = pwt ... }
Decidimos dónde se almacenará el contenido (en el búfer o el montón). Llamamos vwt.allocate y vwt.copy para llenar los contenidos locales con val:
func drawACopy(val: ExistContDrawable) { ... vwt.allocateBufferAndCopy(&local, val) }
Llamamos al método de dibujo y le pasamos un puntero a self (el método projectBuffer decidirá dónde está ubicado self, en el búfer o en el montón, y devolverá el puntero correcto):
func drawACopy(val: ExistContDrawable) { ... pwt.draw(vwt.projectBuffer(&local)) }
Terminamos de trabajar con locales. Limpiamos todos los enlaces modernos de local. La función devuelve un valor: borramos toda la memoria asignada para drawACopy (marco de pila):
func drawACopy(val: ExistContDrawable) { ... vwt.destructAndDeallocateBuffer(&local) }
Contenedor existencial - Propósito
El uso de un contenedor existencial requiere mucho trabajo, el ejemplo anterior lo confirmó, pero ¿por qué es necesario, cuál es el propósito? El objetivo es implementar el polimorfismo utilizando protocolos y los tipos que los implementan. En OOP, usamos clases abstractas y heredamos de ellas mediante métodos de anulación. En EPP, utilizamos protocolos e implementamos sus requisitos. Una vez más, incluso con protocolos, implementar el polimorfismo es un trabajo grande y que consume mucha energía. Por lo tanto, para evitar el trabajo "innecesario", debe comprender cuándo se necesita el polimorfismo y cuándo no.
El polimorfismo en la implementación de EPP gana en el hecho de que, usando estructuras, no necesitamos un conteo de referencia constante, no hay herencia de clase. Sí, todo es muy similar, las clases usan una tabla virtual para determinar la implementación de un método, los protocolos usan el método de protocolo. Las clases se colocan en el montón, las estructuras a veces también se pueden colocar allí. Pero el problema es que cualquier clase de punteros se puede dirigir a la clase colocada en el montón, y el recuento de referencias es necesario, pero solo un puntero a las estructuras colocadas en el montón y se almacena en un contenedor existencial.
De hecho, es importante tener en cuenta que una estructura que se almacena en un contenedor existencial retendrá la semántica de los tipos de valor, independientemente de si se coloca en la pila o el montón. La tabla del ciclo de vida es responsable de la preservación de la semántica, ya que describe los métodos que determinan la semántica.
Contenedor existencial - Propiedades almacenadas
Examinamos cómo una variable de tipo protocolo se pasa y se usa por una función. Consideremos cómo se almacenan tales variables:
struct Pair { init(_ f: Drawable, _ s: Drawable) { first = f second = s } var first: Drawable var second: Drawable } var pair = Pair(Line(), Point())
¿Cómo se almacenan estas dos estructuras dibujables dentro de la estructura de pares? ¿Cuál es el contenido de par? Consiste en dos contenedores existenciales: uno para el primero y otro para el segundo. La línea no puede caber en el búfer y se coloca en el montón. Punto de ajuste en el búfer. También permite que la estructura de pares almacene objetos de diferentes tamaños:
pair.second = Line()
Ahora, el contenido del segundo también se coloca en el montón, ya que no cabe en el búfer. Considere a qué puede conducir esto:
let aLine = Line(...) let pair = Pair(aLine, aLine) let copy = pair
Después de ejecutar este código, el programa recibirá el siguiente estado de memoria:
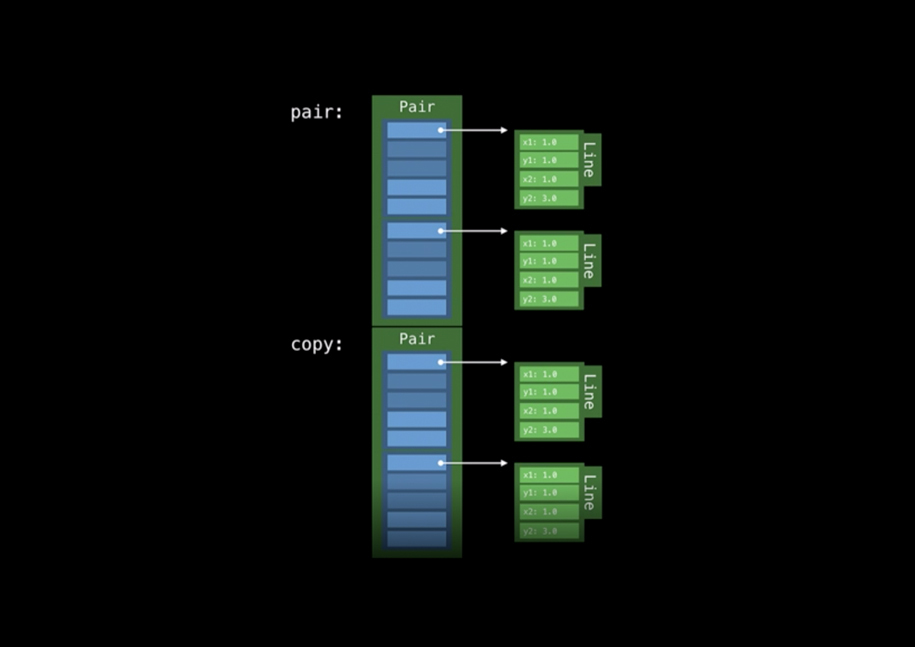
Tenemos 4 asignaciones de memoria en el montón, lo que no es bueno. Intentemos arreglarlo:
- Crear una línea de clase analógica
class LineStorage: Drawable { var x1, y1, x2, y2: Double func draw() {} }
- Lo usamos en pareja
let lineStorage = LineStorage(...) let pair = Pair(lineStorage, lineStorage) let copy = pair
Obtenemos una ubicación en el montón y 4 punteros:

Pero estamos tratando con un comportamiento referencial. Cambiar copy.first afectará a pair.first (lo mismo para .second), que no siempre es lo que queremos.
Almacenamiento indirecto y copia en cambio (copia en escritura)
Antes de eso, se mencionó que String es una estructura de copia en escritura (almacena su contenido en el montón y lo copia cuando cambia). Considere cómo puede implementar su estructura, que se copia al cambiar:
struct BetterLine: Drawable { private var storage: LineStorage init() { storage = LineStorage((0, 0), (10, 10)) } func draw() -> Double { ... } mutating func move() { if !isKnownUniquelyReferenced(&storage) { storage = LineStorage(self.storage) }
- BetterLine almacena todas las propiedades en el almacenamiento, y el almacenamiento es una clase y se almacena en el montón.
- El almacenamiento solo se puede cambiar utilizando el método de movimiento. En él, verificamos que solo un puntero apunta al almacenamiento. Si hay más punteros, entonces este BetterLine comparte el almacenamiento con alguien, y para que BetterLine se comporte completamente como una estructura, el almacenamiento debe ser individual: hacemos una copia y trabajamos con él en el futuro.
Veamos cómo funciona en la memoria:
let aLine = BetterLine() let pair = Pair(aLine, aLine) let copy = pair copy.second.x1 = 3.0
Como resultado de ejecutar este código, obtenemos:
En otras palabras, tenemos dos instancias de Pair que comparten el mismo almacenamiento: LineStorage. Al cambiar el almacenamiento en uno de sus usuarios (primer / segundo), se creará una copia de almacenamiento separada para este usuario para que su cambio no afecte a otros. Esto resuelve el problema de violación de la semántica de los tipos de valor del ejemplo anterior.
Tipos de protocolo: resumen
- Pequeños valores . Si trabajamos con objetos que ocupan poca memoria y se pueden colocar en el búfer de un contenedor existencial, entonces:
- no habrá colocación en el montón
- sin recuento de referencias
- polimorfismo (envío dinámico) usando una tabla de protocolo
- Gran valor Si trabajamos con objetos que no caben en el búfer, entonces:
- colocación del montón
- Recuento de referencias si los objetos contienen enlaces.
Se han demostrado los mecanismos de uso de la reescritura para el cambio y el almacenamiento indirecto y pueden mejorar significativamente la situación con recuento de referencias en caso de un gran número de ellos.
Descubrimos que los tipos de protocolo, como las clases, son capaces de realizar el polimorfismo. Esto sucede almacenando en un contenedor existencial y utilizando tablas de protocolo: tablas de ciclo de vida y tablas de método de protocolo.