Hay muchas formas de probar las API y las interfaces. En relación con la apertura de un amplio acceso a la plataforma cibernética de Acronis, nos vimos obligados a buscar formas de evaluar la durabilidad de los servicios desde una variedad de posiciones. En esta publicación, el arquitecto principal de software de Acronis, Dmitry Salomatin, habla sobre cómo elegimos el marco para las pruebas, qué dificultades encontramos y qué mejoras tuvimos que hacer nosotros mismos.

Debo decir de inmediato que nosotros en Acronis somos especialmente cuidadosos al probar las API. El hecho es que nuestros propios productos acceden a los servicios a través de las mismas API que se utilizan para conectar sistemas externos. Por lo tanto, se requieren pruebas de rendimiento de cada interfaz. Probamos el funcionamiento de la API y probamos el funcionamiento de la interfaz de usuario de forma aislada. Los resultados de la prueba le permitirán evaluar si la API funciona bien, así como las interfaces de usuario. Confirme el desarrollo exitoso o formule una tarea para un mayor desarrollo.
Pero las pruebas difieren. Algunas veces un servicio no muestra degradación de inmediato. Incluso si ejecutamos un servicio similar a los productos ya lanzados en el lanzamiento, para la verificación puede cargarlo con los mismos datos que se utilizan "en producción". En este caso, puede ver la regresión, pero es absolutamente imposible evaluar la perspectiva. Simplemente no sabe qué sucederá si la cantidad de datos aumenta bruscamente o aumenta la frecuencia de las solicitudes.
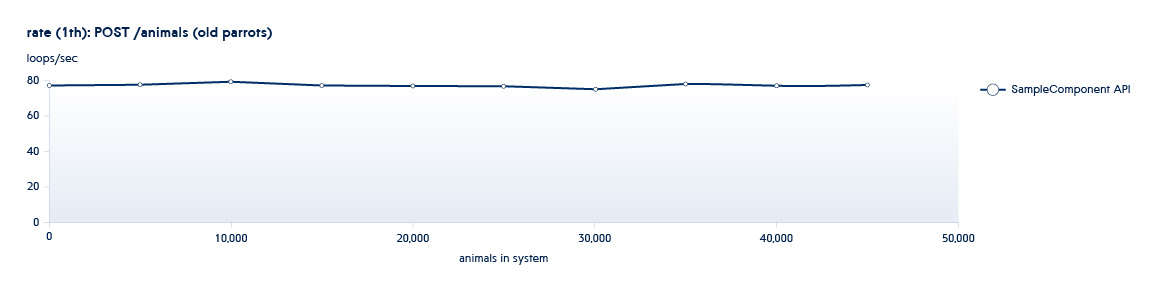
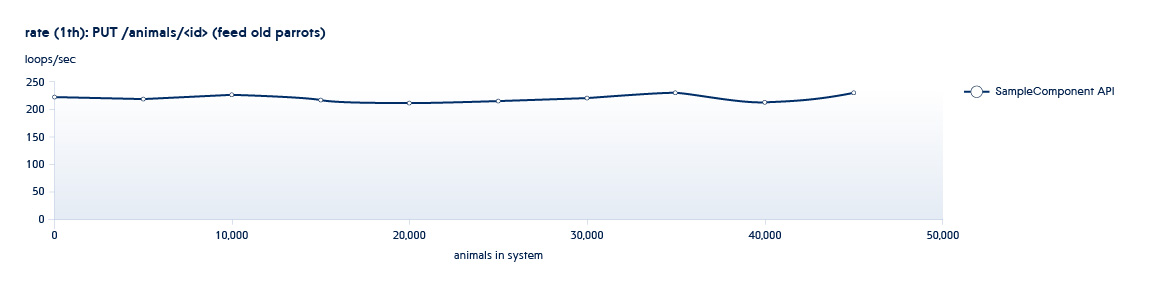
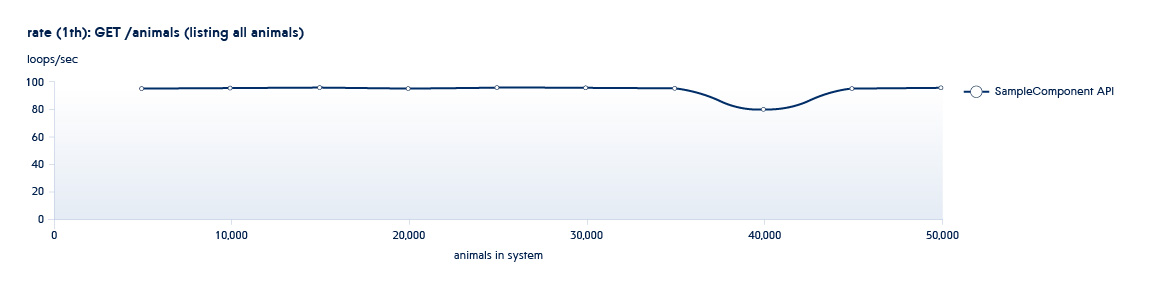
A continuación se muestra un gráfico que muestra cómo cambia el número de API procesadas por el backend por segundo con el crecimiento de los datos en el sistema

Suponga que el servicio que estamos probando se encuentra en un estado típico del comienzo de este programa. En este caso, incluso con un pequeño crecimiento del sistema, la velocidad de esta API disminuirá considerablemente.
Para excluir tales situaciones, aumentamos la cantidad de datos varias veces, aumentamos el número de subprocesos paralelos para comprender cómo se comportará el servicio si la carga aumenta dramáticamente.
Pero hay un matiz más. Si el trabajo de un servicio "familiar" cambia de acuerdo con el crecimiento en la cantidad de datos, su desarrollo, la aparición de nuevas funciones, con nuevos servicios la situación es aún más complicada. Cuando un servicio conceptual nuevo aparece en un producto, debe considerarse desde muchos ángulos diferentes. Para esta situación, debe preparar conjuntos de datos especiales, realizar pruebas de carga, sugiriendo posibles casos de uso.
Características de las pruebas de rendimiento en Acronis
Por lo general, nuestros procesos de prueba tienen lugar en un "patrón en espiral". Una de las fases de prueba involucra el uso de la API para aumentar el número de entidades (dimensionamiento), y la segunda realiza nuevas operaciones en conjuntos de datos existentes (uso). Todas las pruebas se ejecutan en un número diferente de subprocesos. Por ejemplo, tenemos el servicio Animals, y tiene las siguientes API:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1 y 2 son API llamadas en pruebas de dimensionamiento: aumentan el número de nuevas entidades en el sistema.
3 son API llamadas en la fase de uso. Esta API tiene un montón de opciones de filtrado. En consecuencia, habrá más de una prueba.
Por lo tanto, al ejecutar pruebas de dimensionamiento y uso iterativas, obtenemos una imagen del cambio en el rendimiento del sistema con su crecimiento

Marco necesario ...
Para realizar pruebas a gran escala de una gran cantidad de servicios nuevos y actualizados, necesitábamos un marco flexible que nos permitiera ejecutar diferentes scripts. Y lo principal es probar realmente la API, y no solo crear una carga en los servicios con operaciones repetitivas.
Las pruebas de rendimiento pueden llevarse a cabo tanto en una carga sintética como en un patrón de carga registrado desde la producción. Ambos enfoques tienen sus pros y sus contras. Un método con una carga real se puede caracterizar más como prueba de esfuerzo: obtenemos una imagen real del rendimiento del sistema bajo dicha carga, pero no tenemos la capacidad de identificar fácilmente áreas problemáticas, medir el rendimiento de los componentes individualmente, no obtenemos los números exactos que pueden soportar los componentes individuales. En el caso del enfoque sintético, obtenemos números exactos, tenemos una gran flexibilidad y podemos solucionar fácilmente áreas problemáticas, y al ejecutar varios scripts de prueba en paralelo, podemos reproducir la carga de estrés. Las principales desventajas del segundo enfoque son los altos costos de mano de obra para escribir guiones de prueba, así como el riesgo creciente de perder algunos guiones importantes. Por lo tanto, decidimos ir por el camino más difícil.
Entonces, la elección de un marco fue determinada por la tarea. Y nuestra tarea es:
- Encontrar cuellos de botella API
- Verificar resistencia a altas cargas
- Evaluar la efectividad del servicio con el crecimiento de los volúmenes de datos.
- Identificar errores acumulativos que ocurren con el tiempo.
Hay tantos marcos de rendimiento en el mercado que pueden disparar una gran cantidad de solicitudes idénticas. Muchos de ellos no permiten cambiar nada dentro (por ejemplo, Apache Benchmark) o con capacidades limitadas para describir scripts (por ejemplo, JMeter).
Usualmente usamos scripts más complejos en las pruebas. A menudo, las llamadas a la API deben realizarse secuencialmente, una tras otra, o para cambiar los parámetros de la solicitud de acuerdo con algún tipo de lógica. El ejemplo más simple cuando queremos probar una API REST del formulario
PUT /endpoint/resource/<id>
En este caso, debe conocer de antemano el <id> del recurso que queremos cambiar para medir el tiempo de ejecución de la consulta neta.
Por lo tanto, necesitamos la capacidad de crear scripts para ejecutar consultas de prueba complejas.
Mas rapido
Debido a que los productos Acronis están diseñados para alta carga, estamos probando API en decenas de miles de solicitudes por segundo. Resultó que no todos los marcos pueden permitir que esto se haga. Por ejemplo, Python no siempre es posible y no siempre es posible usarlo para las pruebas, porque debido a las peculiaridades del lenguaje, la capacidad de crear una gran carga multiproceso es limitada.
Otro problema es el uso de los recursos. Por ejemplo, primero miramos el marco Locust, que puede ejecutarse desde múltiples nodos de hardware a la vez y obtener un buen rendimiento. Pero al mismo tiempo, se gastan muchos recursos en el trabajo del sistema de prueba y resulta costoso operarlo.
Como resultado, elegimos el marco K6, que nos permite describir los scripts en Javascript completo y proporciona un rendimiento superior al promedio. Este marco está escrito en Go y está ganando popularidad rápidamente. Por ejemplo, en Github, ¡el proyecto ya recibió casi 5.5 mil estrellas! K6 se está desarrollando activamente, y la comunidad ya ha propuesto casi 3 mil confirmaciones, y el proyecto cuenta con 50 contribuyentes que crearon 36 ramas de código. Por supuesto, K6 todavía está lejos de ser ideal, pero gradualmente el marco está mejorando, y puede leer sobre su comparación con Jmeter
aquí .
Dificultades y sus soluciones.
Dada la "juventud" de K6, incluso después de una elección equilibrada del marco, enfrentamos una serie de problemas. Por ejemplo, antes de probar una API como / endpoint /, primero debe encontrar estos puntos finales de alguna manera. No podemos usar los mismos valores, porque debido al almacenamiento en caché los resultados serán incorrectos.
Puede obtener los datos que necesita de diferentes maneras:
- Puedes solicitarlos a través de API
- Puede usar el acceso directo a la base de datos.
El segundo método funciona más rápido, y cuando se utilizan bases de datos relacionales, a menudo resulta mucho más conveniente, ya que le permite ahorrar un tiempo considerable durante pruebas prolongadas. El único "pero" es que puede usarlo solo si el código de servicio y las pruebas están escritos por las mismas personas. Porque para trabajar a través de la base de datos, las pruebas siempre deben estar actualizadas. Sin embargo, en el caso de K6, el marco no tiene mecanismos de acceso a las bases de datos. Por lo tanto, tuve que escribir el módulo apropiado yo mismo.
Otro problema surge cuando se prueban API no idempotentes. En este caso, es importante que se llamen solo una vez con los mismos parámetros (por ejemplo, la API DELETE). En nuestras pruebas, preparamos los datos de prueba por adelantado, en la fase de configuración, cuando el sistema está configurado y preparado. Y durante la prueba, se realizan mediciones de llamadas API puras, ya que ya no se requieren tiempo y recursos para preparar los datos. Sin embargo, esto plantea el problema de distribuir datos preparados previamente a través de flujos no sincronizados de la prueba principal. Este problema se resolvió correctamente escribiendo una cola de datos interna. Pero este es un gran tema, que discutiremos en las próximas publicaciones.
Marco listo
En resumen, me gustaría señalar que no fue fácil encontrar un marco completamente listo, y todavía tenía que terminar algunas cosas con mis manos. Sin embargo, hoy tenemos una herramienta adecuada para nosotros que, teniendo en cuenta las mejoras, nos permite realizar pruebas complejas, creando una simulación de altas cargas para garantizar el rendimiento de la API y la GUI en diferentes condiciones.
En la próxima publicación, hablaré sobre cómo resolvimos el problema de probar un servicio que admite la conexión simultánea de cientos de miles de conexiones utilizando recursos mínimos.