Hola a todos! Mi nombre es Vlad y trabajo como científico de datos en el equipo de tecnologías del habla de Tinkoff que se utiliza en nuestro asistente de voz Oleg.
En este artículo, me gustaría dar una breve descripción de las tecnologías de síntesis de voz utilizadas en la industria y compartir la experiencia de nuestro equipo en la construcción de nuestro propio motor de síntesis.

Síntesis de voz
La síntesis de voz es la creación de sonido basado en texto. Este problema hoy se resuelve mediante dos enfoques:
- Selección de unidad [1], o un enfoque concatenativo. Se basa en pegar fragmentos de audio grabado. Desde finales de los 90, se ha considerado durante mucho tiempo el estándar de facto para desarrollar motores de síntesis de voz. Por ejemplo, una voz sonada por el método de selección de unidad se puede encontrar en Siri [2].
- Síntesis de voz paramétrica [3], cuya esencia es construir un modelo probabilístico que prediga las propiedades acústicas de una señal de audio para un texto dado.
El discurso de los modelos de selección de unidades es de alta calidad, baja variabilidad y requiere una gran cantidad de datos para el entrenamiento. Al mismo tiempo, para entrenar modelos paramétricos, se necesita una cantidad mucho menor de datos, generan entonaciones más diversas, pero hasta hace poco sufrían una calidad de sonido general bastante pobre en comparación con el enfoque de selección de unidades.
Sin embargo, con el desarrollo de tecnologías de aprendizaje profundo, los modelos de síntesis paramétrica han logrado un crecimiento significativo en todas las métricas de calidad y pueden crear un habla que es prácticamente indistinguible del habla humana.
Métricas de calidad
Antes de hablar sobre qué modelos de síntesis de voz son mejores, debe determinar las métricas de calidad mediante las cuales se compararán los algoritmos.
Dado que el mismo texto puede leerse de infinitas maneras, a priori no existe la forma correcta de pronunciar una frase específica. Por lo tanto, a menudo las métricas para la calidad de la síntesis del habla son subjetivas y dependen de la percepción del oyente.
La métrica estándar es el MOS (puntaje de opinión promedio), una evaluación promedio de la naturalidad del habla, dada por evaluadores para audio sintetizado en una escala de 1 a 5. Uno significa sonido completamente inverosímil, y cinco significa habla que es indistinguible del humano. Los registros de personas reales generalmente obtienen alrededor de 4.5, y un valor superior a 4 se considera bastante alto.
Cómo funciona la síntesis del habla
El primer paso para construir cualquier sistema de síntesis de voz es recolectar datos para el entrenamiento. Por lo general, estas son grabaciones de audio de alta calidad en las que el locutor lee frases especialmente seleccionadas. El tamaño aproximado del conjunto de datos requerido para los modelos de selección de unidades de entrenamiento es de 10 a 20 horas de discurso puro [2], mientras que para los métodos paramétricos de la red neuronal, el límite superior es de aproximadamente 25 horas [4, 5].
Discutimos ambas tecnologías de síntesis.
Selección de unidad
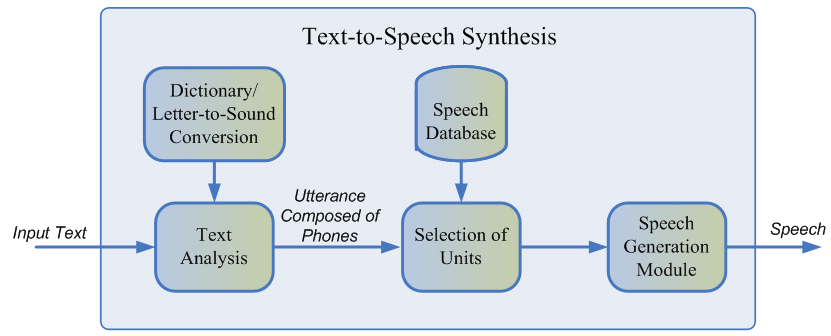
Normalmente, el discurso grabado del hablante no puede cubrir todos los casos posibles en los que se utilizará la síntesis. Por lo tanto, la esencia del método es dividir toda la base de audio en pequeños fragmentos, llamados unidades, que luego se unen usando un procesamiento posterior mínimo. Por lo general, las unidades son unidades mínimas de lenguaje acústico, como los medios teléfonos o los difones [2].
Todo el proceso de generación consta de dos etapas: el frontend de PNL, que es responsable de extraer la representación lingüística del texto, y el backend, que calcula la función de penalización de la unidad para las características lingüísticas dadas. La interfaz de PNL incluye:
- La tarea de normalizar el texto es la traducción de todos los caracteres que no son letras (números, signos de porcentaje, monedas, etc.) en su representación verbal. Por ejemplo, "5%" debe convertirse a "cinco por ciento".
- Extraer características lingüísticas de un texto normalizado: representación de fonemas, estrés, partes del discurso, etc.
Por lo general, la interfaz de PNL se implementa utilizando reglas prescritas manualmente para un idioma específico, pero recientemente ha habido un sesgo creciente hacia el uso de modelos de aprendizaje automático [7].
La penalización estimada por el subsistema de fondo es la suma del costo objetivo, o la correspondencia de la representación acústica de la unidad para un fonema particular, y el costo de concatenación, es decir, la conveniencia de conectar dos unidades vecinas. Para evaluar las funciones finas, se pueden usar las reglas o el modelo acústico ya entrenado de síntesis paramétrica [2]. La selección de la secuencia de unidades más óptima desde el punto de vista de las penalizaciones definidas anteriormente se realiza utilizando el algoritmo de Viterbi [1].
Valores aproximados de los modelos de selección de unidades MOS para el idioma inglés: 3.7-4.1 [2, 4, 5].
Ventajas del enfoque de selección de unidades:
- El sonido natural.
- Generación de alta velocidad.
- Tamaño pequeño de modelos: esto le permite utilizar la síntesis directamente en su dispositivo móvil.
Desventajas
- El discurso sintetizado es monótono, no contiene emociones.
- Artefactos de encolado característicos.
- Requiere una base de entrenamiento de datos de audio lo suficientemente grande como para cubrir todo tipo de contextos.
- En principio, no puede generar sonido que no se encuentra en el conjunto de entrenamiento.
Síntesis paramétrica del habla
El enfoque paramétrico se basa en la idea de construir un modelo probabilístico que estima la distribución de las características acústicas de un texto dado.
El proceso de generación de voz en síntesis paramétrica se puede dividir en cuatro etapas:
- La interfaz de PNL es la misma etapa de preprocesamiento de datos que en el enfoque de selección de unidades, cuyo resultado es una gran cantidad de características lingüísticas sensibles al contexto.
- Modelo de duración que predice la duración del fonema.
- Un modelo acústico que restaura la distribución de las características acústicas sobre las lingüísticas. Las características acústicas incluyen valores de frecuencia fundamentales, representación espectral de la señal, etc.
- Un vocoder que traduce características acústicas en una onda de sonido.
Para la duración del entrenamiento y los modelos acústicos, se pueden utilizar modelos ocultos de Markov [3], redes neuronales profundas o sus variedades recurrentes [6]. Un vocoder tradicional es un algoritmo basado en el modelo de filtro fuente [3], que supone que el habla es el resultado de aplicar un filtro de ruido lineal a la señal original.
La calidad general del habla de los métodos paramétricos clásicos es bastante baja debido a la gran cantidad de suposiciones independientes sobre la estructura del proceso de generación de sonido.
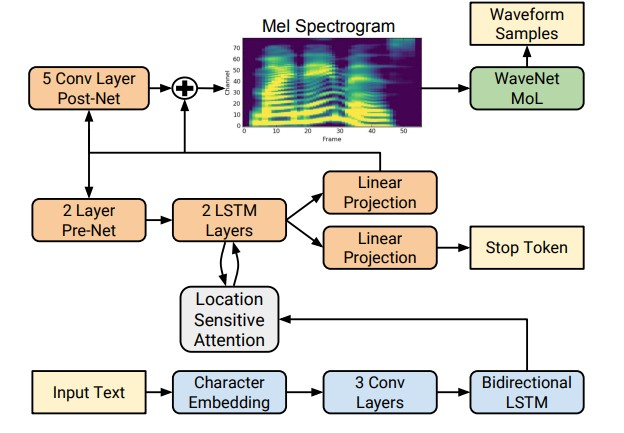
Sin embargo, con el advenimiento de las tecnologías de aprendizaje profundo, ha sido posible entrenar modelos de extremo a extremo que predicen directamente los signos acústicos por letra. Por ejemplo, las redes neuronales Tacotron [4] y Tacotron 2 [5] ingresan una secuencia de letras y devuelven el espectrograma de tiza utilizando el algoritmo seq2seq [8]. Por lo tanto, los pasos 1-3 del enfoque clásico se reemplazan por una única red neuronal. El siguiente diagrama muestra la arquitectura de la red Tacotron 2, que logra una calidad de sonido bastante alta.
Otro factor de crecimiento significativo en la calidad del habla sintetizada fue el uso de vocoders de redes neuronales en lugar de algoritmos de procesamiento de señales digitales.
El primer vocoder de este tipo fue la red neuronal WaveNet [9], que secuencialmente, paso a paso, predijo la amplitud de la onda de sonido.
Debido al uso de una gran cantidad de capas convolucionales con espacios para capturar más contexto y omitir la conexión en la arquitectura de red, fue posible lograr una mejora de aproximadamente el 10% en MOS en comparación con los modelos de selección de unidades. El siguiente diagrama muestra la arquitectura de la red WaveNet.

La principal desventaja de WaveNet es la baja velocidad asociada con un circuito de muestreo de señal en serie. Este problema se puede resolver utilizando la optimización de ingeniería para una arquitectura de hierro particular o reemplazando el esquema de muestreo por uno más rápido.
Ambos enfoques se han implementado con éxito en la industria. El primero está en Tinkoff.ru, y como parte del segundo enfoque, Google introdujo la red Parallel WaveNet [10] en 2017, cuyos logros se utilizan en el Asistente de Google.
Valores aproximados de MOS para métodos de redes neuronales: 4.4–4.5 [5, 11], es decir, el habla sintetizada prácticamente no es diferente del habla humana.
Ventajas de la síntesis paramétrica:
- Sonido natural y suave cuando se utiliza el enfoque de extremo a extremo.
- Mayor variedad en entonación.
- Use menos datos que los modelos de selección de unidades.
Desventajas
- Baja velocidad en comparación con la selección de unidades.
- Gran complejidad computacional.
Cómo funciona la síntesis de voz de Tinkoff
Como se desprende de la revisión, los métodos de síntesis de voz paramétrica basados en redes neuronales son actualmente de calidad significativamente superior al enfoque de selección de unidades y son mucho más simples de desarrollar. Por lo tanto, para construir nuestro propio motor de síntesis, los usamos.
Para los modelos de entrenamiento, se utilizaron aproximadamente 25 horas de discurso puro de un orador profesional. La lectura de textos se seleccionó especialmente para cubrir más completamente la fonética del habla coloquial. Además, para agregar más variedad a la síntesis en la entonación, le pedimos al locutor que lea los textos con una expresión según el contexto.
La arquitectura de nuestra solución conceptualmente se ve así:
- Interfaz de PNL, que incluye la normalización del texto de la red neuronal y un modelo para colocar pausas y tensiones.
- Tacotron 2 aceptando letras como entrada.
- WaveNet autorregresivo, trabajando en tiempo real en la CPU.
Gracias a esta arquitectura, nuestro motor genera voz expresiva de alta calidad en tiempo real, no requiere la construcción de un diccionario de fonemas y permite controlar el estrés en palabras individuales. Se pueden escuchar ejemplos de audio sintetizado haciendo clic en el enlace .
Referencias
[1] AJ Hunt, AW Black. Selección de unidades en un sistema de síntesis de voz concatenativo utilizando una gran base de datos de voz, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio , R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Sistema de texto a voz de selección de unidad guiada por aprendizaje profundo en dispositivo Siri, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Síntesis estadística paramétrica del habla, Speech Communication, vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Hacia la síntesis de voz de extremo a extremo.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Síntesis natural de TTS por condicionamiento WaveNet en predicciones de espectrograma de Mel.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Síntesis estadística paramétrica del habla utilizando redes neuronales profundas.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Modelos neuronales de normalización de texto para aplicaciones de voz.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Secuencia a secuencia de aprendizaje con redes neuronales.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: un modelo generativo para audio sin formato.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman , Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Síntesis de voz rápida de alta fidelidad.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Generación de ondas paralelas en texto a voz de extremo a extremo.
[12] Dario Rethage, Jordi Pons, Xavier Serra. Una red de ondas para el discurso de Denoising.