Rendimiento en .NET Core

Hola a todos! Este artículo es una colección de mejores prácticas, que yo y mis colegas hemos estado utilizando durante mucho tiempo al trabajar en diferentes proyectos.
Información sobre la máquina en la que se realizaron los cálculos:BenchmarkDotNet = v0.11.5, OS = Windows 10.0.18362
Intel Core i5-8250U CPU 1.60GHz (Kaby Lake R), 1 CPU, 8 núcleos lógicos y 4 físicos
.NET Core SDK = 3.0.100
[Host]: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT de 64 bits
Core: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT de 64 bits
[Host]: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT de 64 bits
Núcleo: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT de 64 bits
Trabajo = Core Runtime = Core
ToList vs ToArray and Cycles
Planeé preparar esta información con el lanzamiento de .NET Core 3.0, pero se adelantaron a mí, no quiero robar la fama de otra persona y copiar la información de otra persona, así que solo señalaré un
enlace a un buen artículo donde se detalla la comparación .
Por mi parte, solo quiero presentarles mis medidas y resultados, les agregué bucles inversos para los fanáticos del "estilo C ++" de los ciclos de escritura.
Código:public class Bench { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random random = new Random(); _list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForListFromEnd() { int total = 0;t for (int i = _list.Count-1; i > 0; i--) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } [Benchmark] public int ForArrayFromEnd() { int total = 0; for (int i = _array.Length-1; i > 0; i--) { total += _array[i]; } return total; } }
El rendimiento en .NET Core 2.2 y 3.0 es casi idéntico. Esto es lo que logré obtener en .NET Core 3.0:
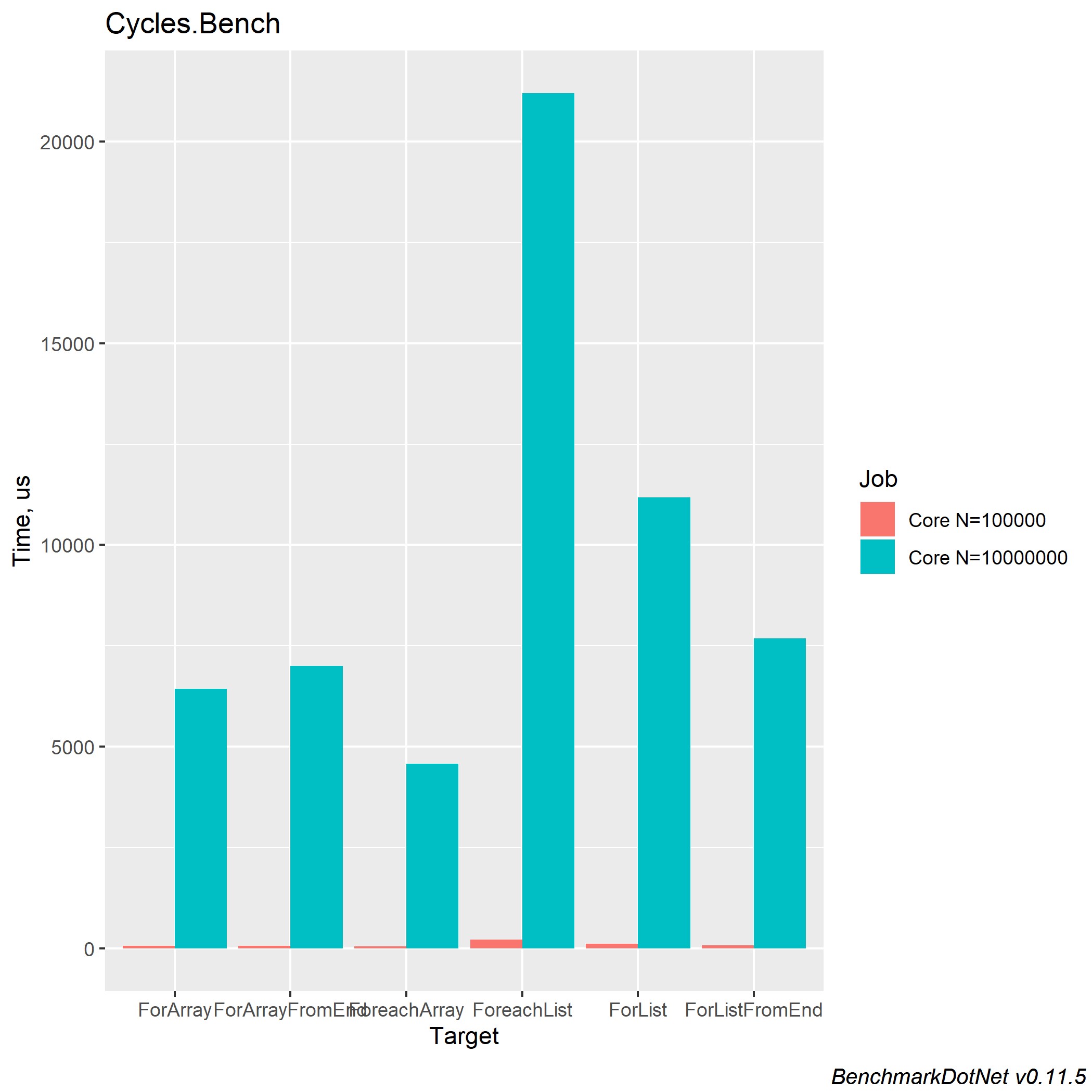
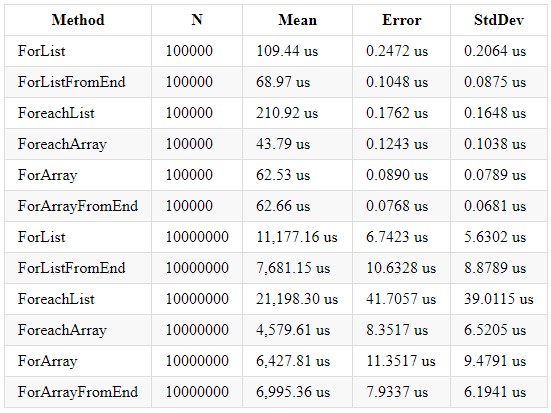
Podemos concluir que el procesamiento en bucle de una colección de tipo Array es más rápido, debido a sus optimizaciones internas y la asignación explícita del tamaño de la colección. También vale la pena recordar que una colección de tipo Lista tiene sus ventajas y debe usar la colección deseada dependiendo de los cálculos necesarios. Incluso si escribe la lógica de trabajar con ciclos, no olvide que este es un ciclo ordinario y también está sujeto a una posible optimización de los ciclos. Un artículo apareció en habr durante mucho tiempo:
https://habr.com/en/post/124910/ . Sigue siendo relevante y recomendado para la lectura.
Tirar
Hace un año, trabajé en una empresa en un proyecto heredado, en ese proyecto estaba dentro del alcance normal manejar la validación de campo a través de una construcción try-catch-throw. Ya entendí que esta era una lógica comercial poco saludable del proyecto, por lo que intenté no usar ese diseño si es posible. Pero veamos cuál es el mal enfoque para manejar errores con tal diseño. Escribí un pequeño código para comparar los dos enfoques y disparé los "bancos" para cada opción.
Código: public bool ContainsHash() { bool result = false; foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } return result; } public bool ContainsHashTryCatch() { bool result = false; try { foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } if(!result) throw new Exception("false"); } catch (Exception e) { result = false; } return result; }
Los resultados en .NET Core 3.0 y Core 2.2 tienen un resultado similar (.NET Core 3.0):
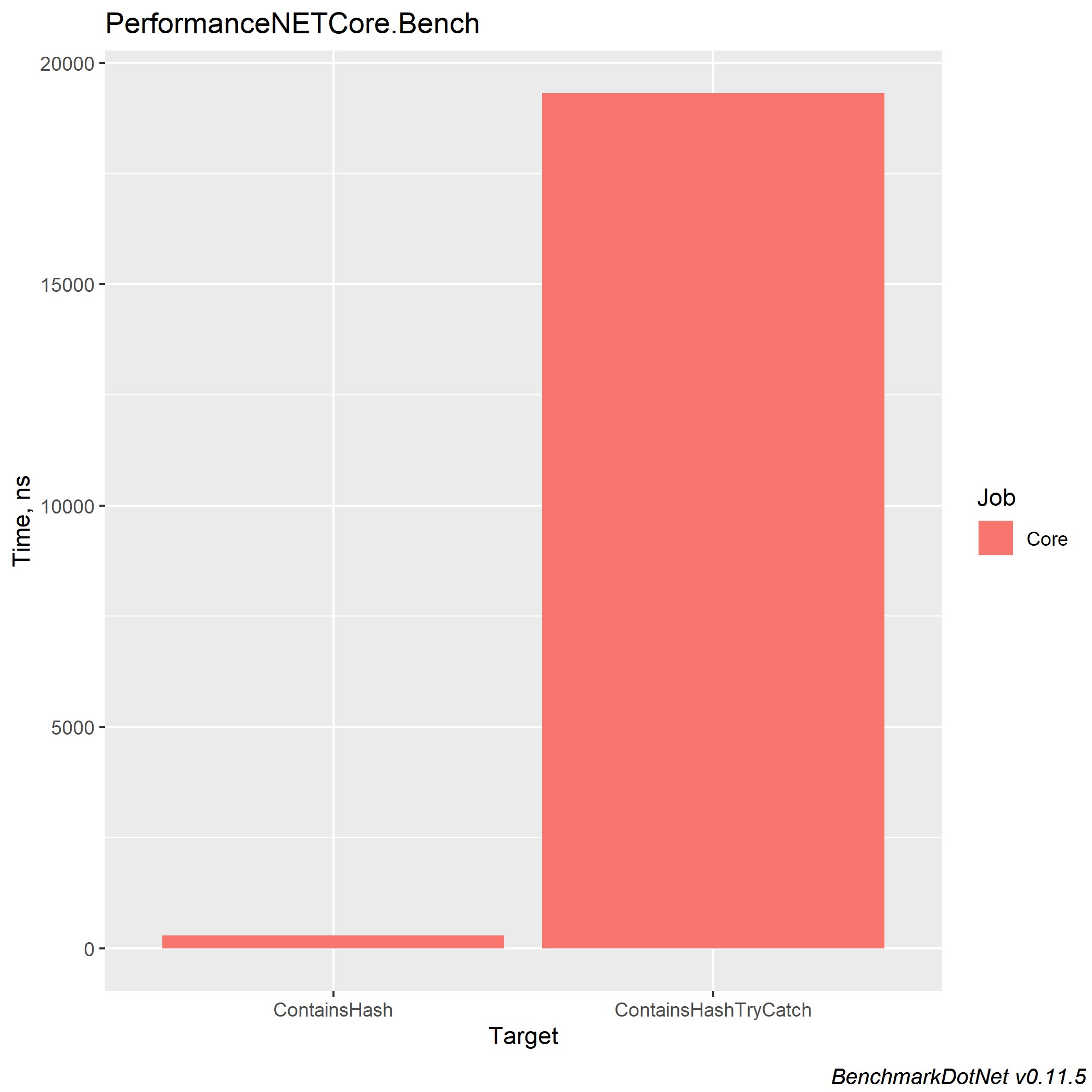
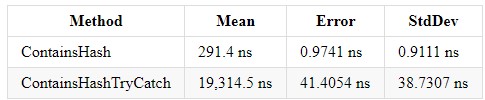
Try catch complica la comprensión del código y aumenta el tiempo de ejecución de su programa. Pero si necesita esta construcción, no debe insertar esas líneas de código desde las cuales no se espera el manejo de errores; esto facilitará la comprensión del código. De hecho, no es tanto el manejo de excepciones lo que está cargando el sistema como lanzar los propios errores a través de la nueva construcción de excepción de lanzamiento.
Lanzar excepciones es más lento que cualquier clase que recopile un error en el formato deseado. Si está procesando un formulario o algún dato y obviamente sabe qué error debería ser, entonces ¿por qué no procesarlo?
No debe escribir throw new Exception () si esta situación no es excepcional.
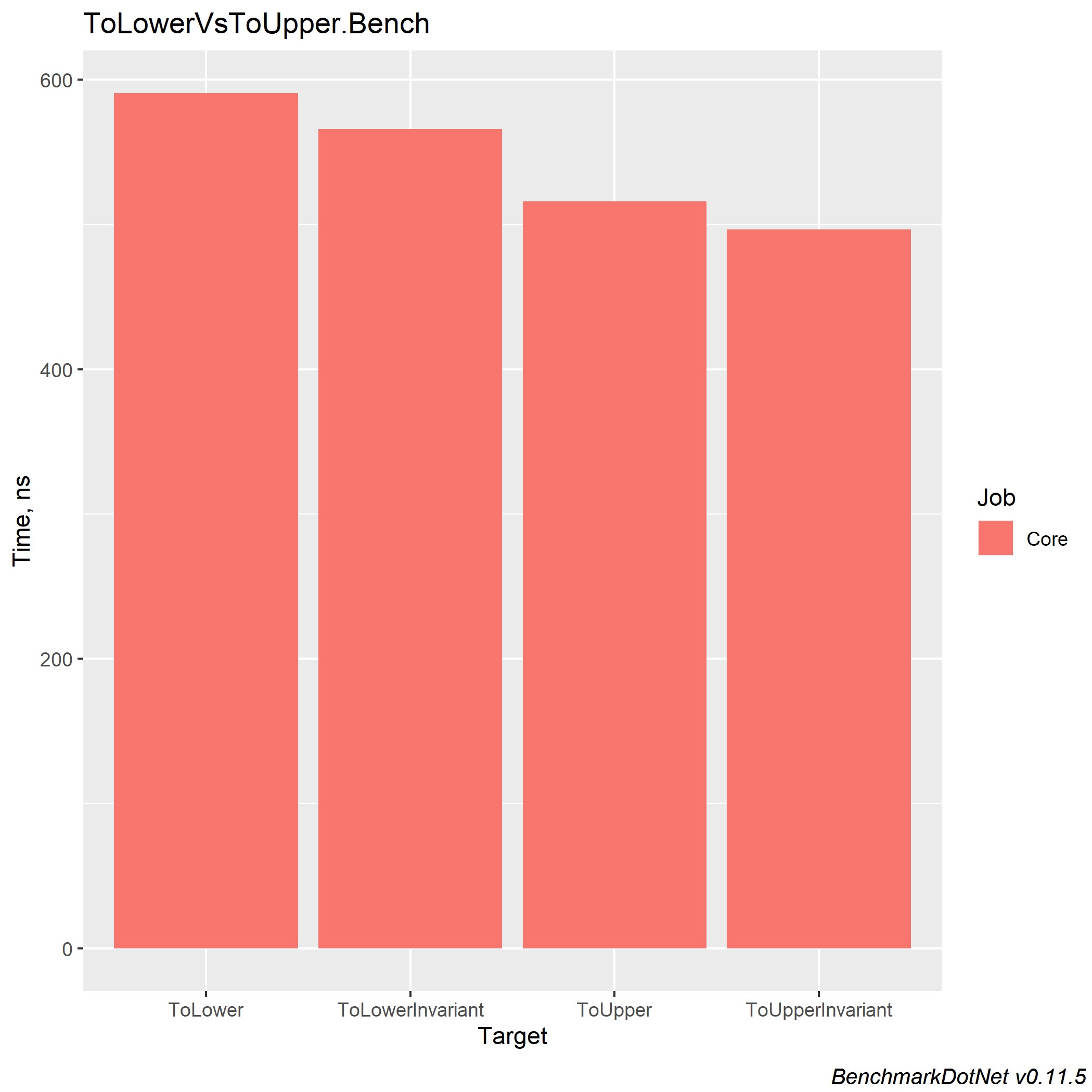
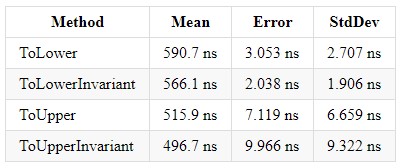
¡Manejar y lanzar una excepción es muy costoso!ToLower, ToLowerInvariant, ToUpper, ToUpperInvariant
Durante sus 5 años de experiencia en la plataforma .NET, ha conocido muchos proyectos que utilizan la coincidencia de cadenas. También vi la siguiente imagen: había una solución Enterprise con muchos proyectos, cada uno de los cuales realizaba comparaciones de cadenas de diferentes maneras. Pero, ¿qué vale la pena usar y cómo unificarlo? En el CLR de Richter a través de C #, leí que ToUpperInvariant () es más rápido que ToLowerInvariant ().
Recorte del libro:

Por supuesto, no lo creía y decidí realizar algunas pruebas en ese momento en .NET Framework y el resultado me sorprendió: más del 15% de aumento de rendimiento. Más adelante, al llegar al trabajo a la mañana siguiente, mostré estas medidas a mis superiores y les di acceso a la fuente. Después de eso, 2 de 14 proyectos fueron cambiados para nuevas mediciones, y dado que estos dos proyectos existían para procesar grandes tablas de Excel, el resultado fue más que significativo para el producto.
También les presento medidas para diferentes versiones de .NET Core, para que cada uno pueda elegir en la dirección de la solución más óptima. Y solo quiero agregar que en la empresa donde trabajo, utilizamos ToUpper () para comparar cadenas.
Código: public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); } ; public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); }
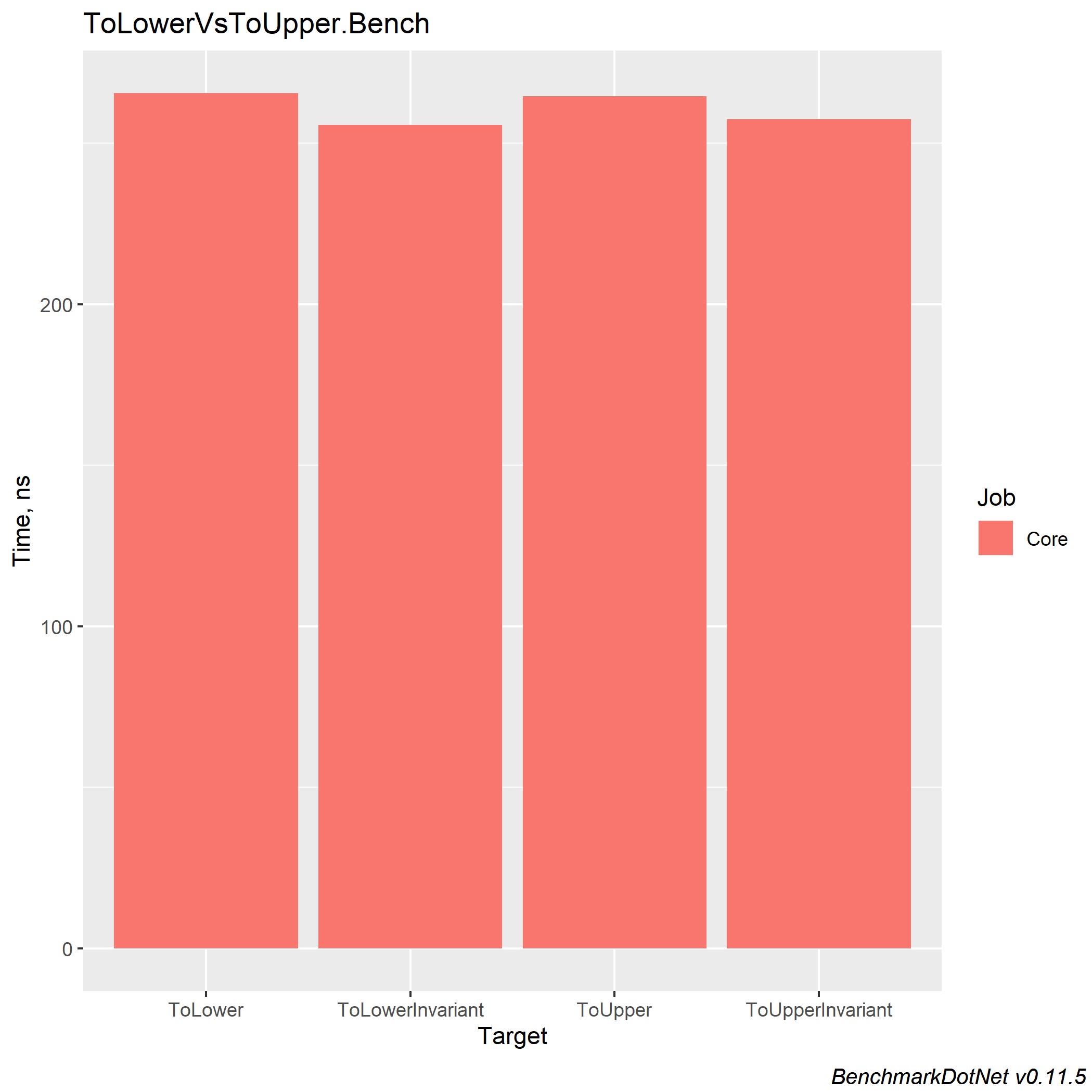
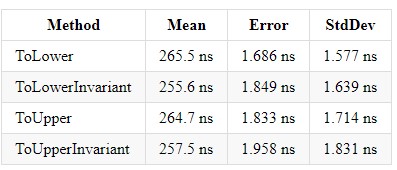
En .NET Core 3.0, la ganancia para cada uno de estos métodos es ~ x2 y equilibra las implementaciones entre ellos.
Compilación de niveles
En mi último artículo describí brevemente esta funcionalidad, me gustaría corregir y complementar mis palabras. La compilación multinivel acelera el tiempo de lanzamiento de su solución, pero sacrifica partes de su código para compilar en una versión más optimizada en segundo plano, lo que puede generar una pequeña sobrecarga. Con la llegada de NET Core 3.0, el tiempo de compilación de proyectos con compilación de niveles permitió errores disminuidos y corregidos relacionados con esta tecnología. Anteriormente, esta tecnología provocaba errores en las primeras solicitudes en ASP.NET Core y se congelaba durante la primera compilación en modo de compilación multinivel. Actualmente, está habilitado de manera predeterminada en .NET Core 3.0, pero puede deshabilitarlo como lo desee. Si está en la posición de líder de equipo, senior, intermedio o jefe del departamento, debe comprender que el desarrollo rápido del proyecto aumenta el valor del equipo y esta tecnología le permitirá ahorrar tanto el tiempo de los desarrolladores como el tiempo del proyecto.
.NET subir de nivel
Actualice su .NET Framework / .NET Core. A menudo, cada nueva versión proporciona un aumento de rendimiento adicional y agrega nuevas características.
Pero, ¿cuáles son exactamente los beneficios? Veamos algunos de ellos:
- En .NET Core 3.0, se han introducido imágenes R2R que reducirán el tiempo de inicio de las aplicaciones .NET Core.
- La versión 2.2 introdujo la compilación de niveles, gracias a la cual los programadores pasarán menos tiempo lanzando un proyecto.
- Soporte para el nuevo estándar .NET.
- Soporte para la nueva versión del lenguaje de programación.
- Optimización, con cada nueva versión, la optimización se mejora mediante las bibliotecas base Colección / Estructura / Transmisión / Cadena / Regex y mucho más. Si actualiza de .NET Framework a .NET Core, obtendrá un gran aumento de rendimiento de fábrica. Por ejemplo, adjunto un enlace a una parte de las optimizaciones que se agregaron en .NET Core 3.0: https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-core-3-0/

Conclusión
Al escribir código, debe prestar atención a varios aspectos de su proyecto y utilizar las funciones de su lenguaje de programación y plataforma para lograr el mejor resultado. Me alegrará si comparte su conocimiento relacionado con la optimización en .NET.
Enlace de Github