
Las redes neuronales en visión artificial se están desarrollando activamente, muchas tareas aún están lejos de resolverse. Para estar de moda en su campo, solo siga a los influencers en Twitter y lea los artículos relevantes en arXiv.org. Pero tuvimos la oportunidad de asistir a la Conferencia Internacional sobre Visión por Computadora (ICCV) 2019. Este año se celebra en Corea del Sur. Ahora queremos compartir con los lectores de Habr lo que vimos y aprendimos.
Había muchos de nosotros de Yandex: desarrolladores de vehículos no tripulados, investigadores y aquellos involucrados en tareas de CV en los servicios llegaron. Pero ahora queremos presentar un punto de vista ligeramente subjetivo de nuestro equipo: el laboratorio de inteligencia artificial (Yandex MILAB). Otros tipos probablemente miraron la conferencia desde su ángulo.
¿Qué hace el laboratorio?Realizamos proyectos experimentales relacionados con la generación de imágenes y música con fines de entretenimiento. Estamos especialmente interesados en las redes neuronales que le permiten cambiar el contenido del usuario (para una foto, esta tarea se denomina manipulación de imágenes).
Un ejemplo del resultado de nuestro trabajo de la conferencia YaC 2019.
Hay muchas conferencias científicas, pero las principales conferencias llamadas A * se destacan de ellas, donde generalmente se publican artículos sobre las tecnologías más interesantes e importantes. No hay una lista exacta de conferencias A *, aquí hay un ejemplo incompleto: NeurIPS (anteriormente NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Los tres últimos se especializan en el tema de CV.
ICCV de un vistazo: carteles, tutoriales, talleres, stands
Se aceptaron 1075 documentos en la conferencia, los participantes fueron 7,500. 103 personas vinieron de Rusia, había artículos de empleados de Yandex, Skoltech, Samsung AI Center Moscow y Samara University. Este año, no muchos investigadores importantes visitaron el ICCV, pero aquí, por ejemplo, Alexey (Alyosha) Efros, que siempre reúne a mucha gente:

En todas esas conferencias, los artículos se presentan en forma de carteles (
más sobre el formato), y los mejores también se presentan en forma de informes breves.
Aquí es parte del trabajo de Rusia En los tutoriales puedes sumergirte en alguna materia, se parece a una conferencia en una universidad. Es leída por una persona, generalmente sin hablar de trabajos específicos. Ejemplo de tutorial genial (
Michael Brown, Comprensión del color y la canalización de procesamiento de imágenes en la cámara para visión artificial ):

En los talleres, por el contrario, hablan de artículos. Por lo general, este es un trabajo en un tema limitado, historias de líderes de laboratorio sobre el último trabajo de los estudiantes o artículos que no fueron aceptados en la conferencia principal.
Las empresas patrocinadoras llegan al ICCV con stands. Este año, llegaron Google, Facebook, Amazon y muchas otras compañías internacionales, así como una gran cantidad de nuevas empresas: coreanas y chinas. Hubo especialmente muchas nuevas empresas que se especializan en el marcado de datos. Hay actuaciones en los stands, puedes llevar mercadería y hacer preguntas. Las empresas patrocinadoras tienen fiestas para cazar. Se las arreglan para seguir adelante si convencen a los reclutadores de que está interesado y que potencialmente puede ser entrevistado. Si publicó un artículo (o, además, realizó una presentación con él), inició o finalizó el doctorado; esto es una ventaja, pero a veces puede ponerse de acuerdo sobre un stand, haciendo preguntas interesantes a los ingenieros de la compañía.
Tendencias
La conferencia le permite echar un vistazo a toda el área de CV. Por la cantidad de carteles de un tema en particular, puede evaluar qué tan caliente es el tema. Algunas conclusiones piden las palabras clave:

Zero-shot, one-shot, pocos disparos, auto-supervisado y semi-supervisado: nuevos enfoques para problemas estudiados durante mucho tiempo
Las personas aprenden a usar los datos de manera más eficiente. Por ejemplo, en
FUNIT, puede generar expresiones faciales de animales que no estaban en el conjunto de entrenamiento (aplicando varias imágenes de referencia en la aplicación). Se han desarrollado las ideas de Deep Image Prior, y ahora las redes
GAN se pueden entrenar en una sola imagen. Hablaremos de esto más adelante
en los aspectos más
destacados . Puede usar la auto-supervisión para la capacitación previa (resolver un problema para el cual puede sintetizar datos alineados, por ejemplo, para predecir el ángulo de rotación de una imagen) o aprender al mismo tiempo de datos marcados y no etiquetados. En este sentido, la corona de la creación puede considerarse un artículo
S4L: Aprendizaje semi-supervisado auto supervisado . Pero la capacitación previa en ImageNet
no siempre ayuda.

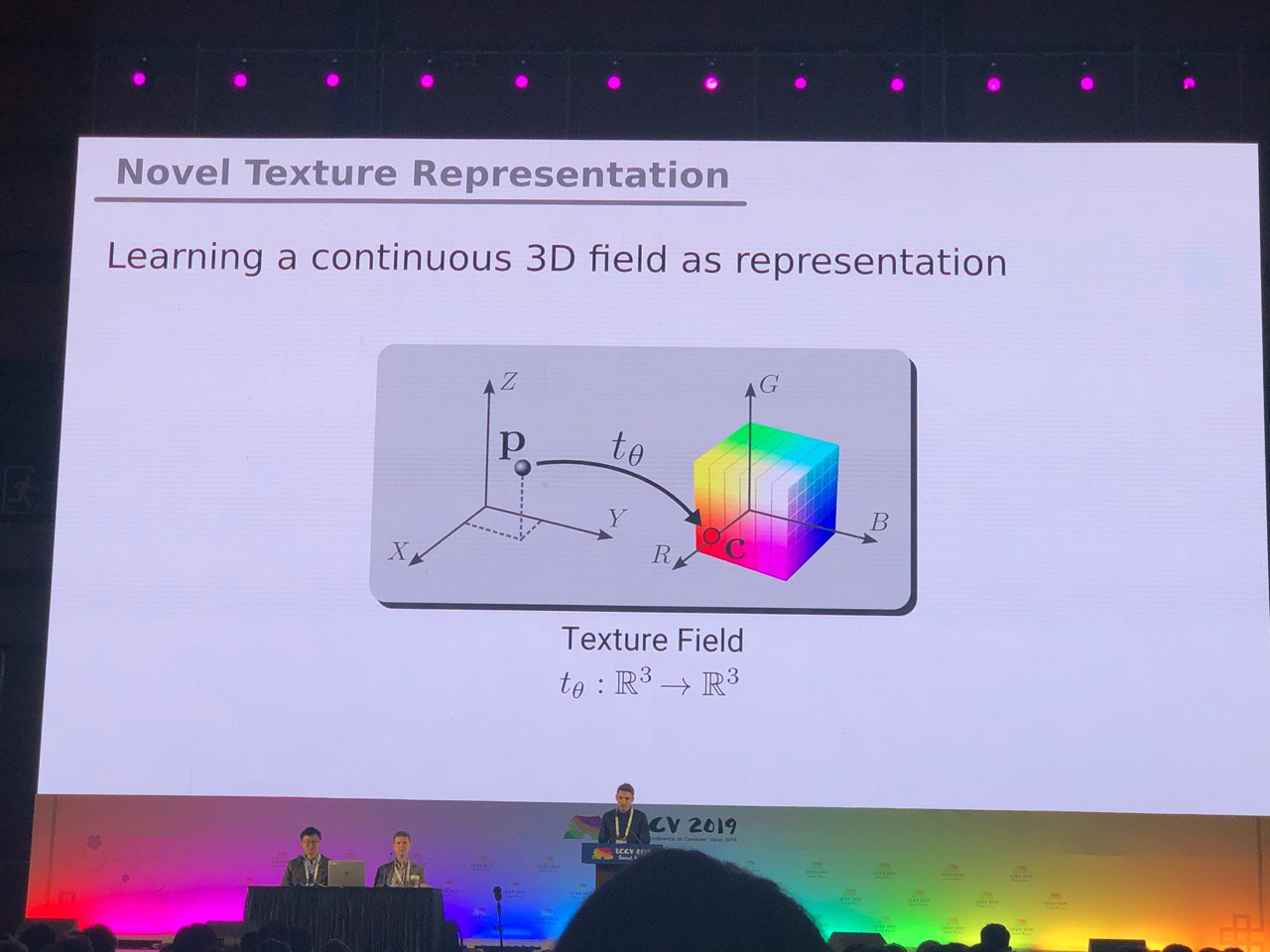
3D y 360 °
Las tareas, en su mayoría resueltas para fotos (segmentación, detección), requieren investigación adicional para modelos 3D y videos panorámicos. Vimos muchos artículos sobre la conversión de RGB y
RGB-D a 3D. Algunas tareas, como determinar la pose de una persona (estimación de pose), se resuelven de forma más natural si vamos a modelos tridimensionales. Pero hasta ahora no hay consenso sobre cómo representar exactamente los modelos 3D, en forma de cuadrícula, nube de puntos,
vóxel o
SDF . Aquí hay otra opción:
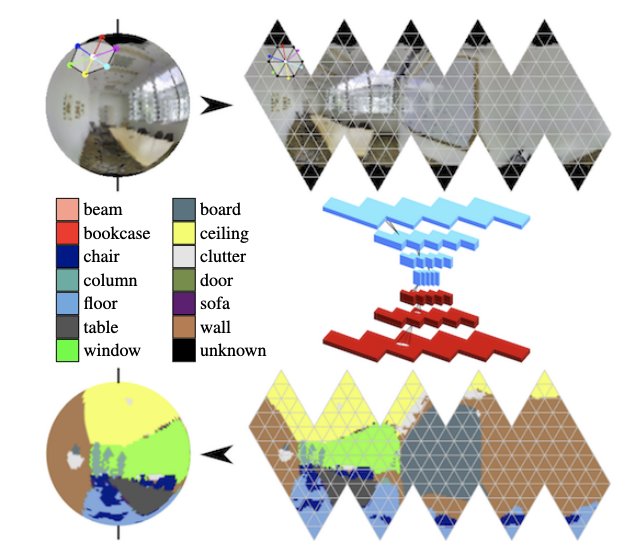
En los panoramas, las convoluciones en la esfera se están desarrollando activamente (ver
Segmentación semántica consciente de la orientación en esferas de icosaedro ) y la búsqueda de objetos clave en el marco.
Definición de postura y predicción de movimientos humanos.
Para determinar la pose en 2D, ya hay éxito: ahora el enfoque se ha desplazado hacia trabajar con múltiples cámaras y en 3D. Por ejemplo, puede determinar el esqueleto a través de la pared, siguiendo los cambios en la señal de Wi-Fi a medida que pasa a través del cuerpo humano.
Se ha realizado mucho trabajo en el área de detección de puntos clave manuales. Aparecieron nuevos conjuntos de datos, incluidos los basados en video con diálogos de dos personas: ¡ahora puede predecir gestos con las manos por audio o texto de una conversación! Se ha hecho el mismo progreso en las tareas de evaluación de la mirada.

También puede resaltar un gran grupo de trabajos relacionados con la predicción del movimiento humano (por ejemplo,
Predicción del movimiento humano a través de la pintura espacio-temporal o
predicción estructurada ayuda al modelado del movimiento humano en 3D ). La tarea es importante y, según las conversaciones con los autores, se usa con mayor frecuencia para analizar el comportamiento de los peatones en la conducción autónoma.
Manipulación de personas en fotos y videos, probadores virtuales
La tendencia principal es cambiar las imágenes faciales en términos de parámetros interpretados. Ideas:
falsificación profunda en una imagen, cambio de expresión mediante renderizado facial (
PuppetGAN ), cambio de parámetros de
avance (por ejemplo,
edad ). Las transferencias de estilo se movieron del título del tema al trabajo de la aplicación. Otra historia: los probadores virtuales, casi siempre funcionan mal,
aquí hay un ejemplo de una demostración.


Bosquejo / Generación de Gráficos
El desarrollo de la idea "Dejar que la cuadrícula genere algo basado en la experiencia previa" se ha vuelto diferente: "Vamos a mostrarle a la cuadrícula qué opción nos interesa".
SC-FEGAN le permite hacer una pintura guiada: el usuario puede dibujar parte de la cara en el área borrada de la imagen y obtener la imagen restaurada dependiendo del renderizado.

En uno de los 25 artículos de Adobe para ICCV, se combinan dos GAN: uno dibuja un boceto para el usuario, el otro genera una imagen fotorrealista a partir del boceto (
página del proyecto ).

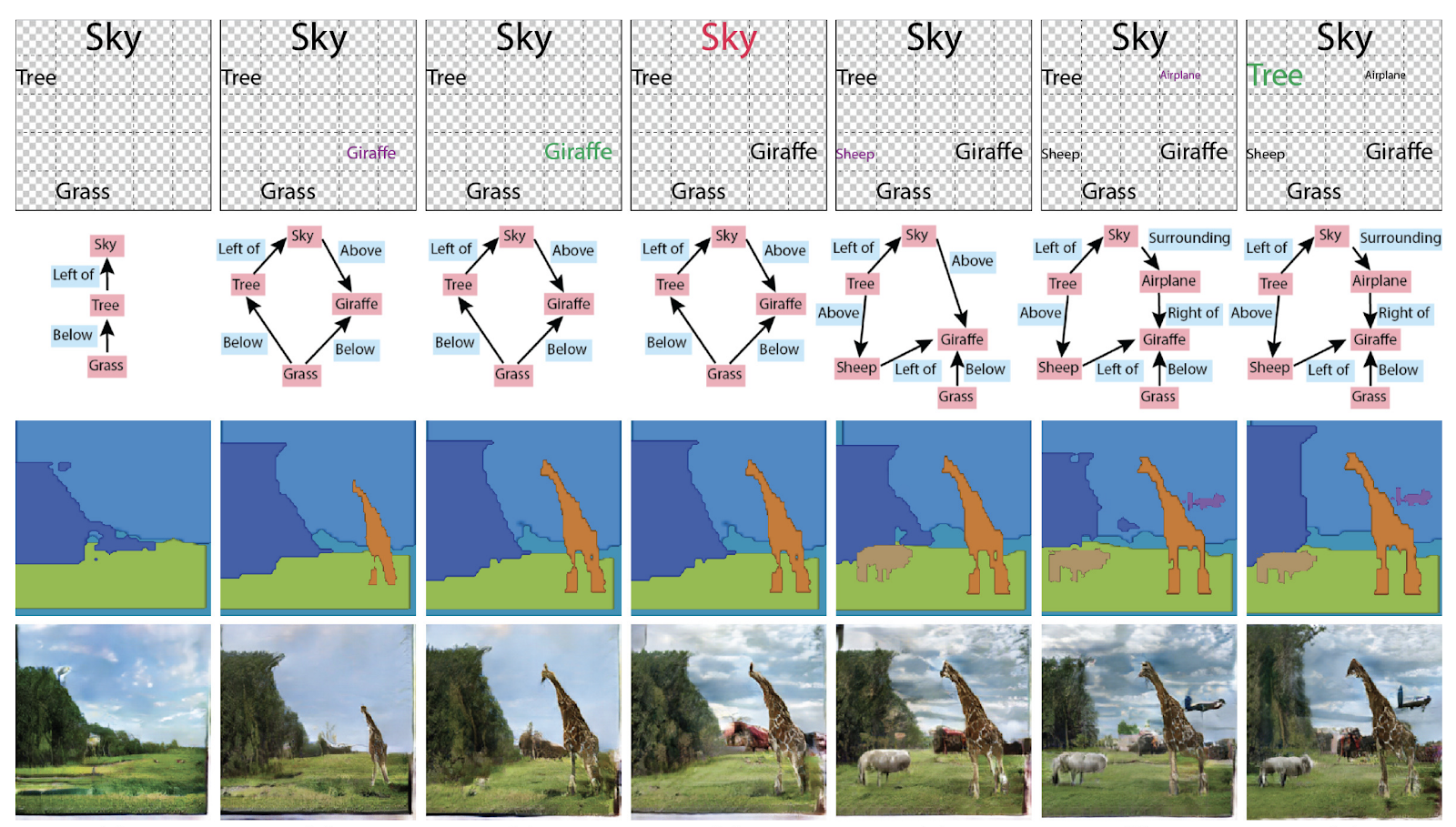
Anteriormente en la generación de imágenes, no se necesitaban gráficos, pero ahora se han convertido en un contenedor de conocimiento sobre la escena. El premio de Menciones de Honor al Mejor Papel del ICCV también se otorgó al artículo
Especificación de atributos y relaciones de objetos en la generación de escenas interactivas . En general, puede usarlos de diferentes maneras: generar gráficos a partir de imágenes o imágenes y textos a partir de gráficos.
Reidentificación de personas y máquinas, contando el número de multitudes (!)
Muchos artículos están dedicados a rastrear personas y
reidentificar personas y máquinas. Pero lo que nos sorprendió fue un montón de artículos sobre contar personas en una multitud, y todos de China.
Pero Facebook, por el contrario, anonimiza la foto. Además, lo hace de una manera interesante: enseña a la red neuronal a generar una cara sin detalles únicos, similar, pero no tanto como para que sea detectada correctamente por los sistemas de reconocimiento facial.

Protección contra ataques adversos
Con el desarrollo de aplicaciones de visión por computadora en el mundo real (en vehículos no tripulados, en reconocimiento facial), surge con mayor frecuencia la cuestión de la confiabilidad de tales sistemas. Para hacer un uso completo de CV, debe asegurarse de que el sistema sea resistente a los ataques adversos, por lo tanto, no hubo menos artículos sobre protección contra ellos que sobre los ataques mismos. Se trabajó mucho para explicar las predicciones de la red (mapa de prominencia) y medir la confianza en el resultado.
Tareas combinadas
En la mayoría de las tareas con un objetivo, las posibilidades de mejorar la calidad están casi agotadas; una de las nuevas áreas de mayor crecimiento de calidad es enseñar a las redes neuronales a resolver varios problemas similares al mismo tiempo. Ejemplos:
- predicción de acciones + predicción de flujo óptico,
- presentación en video + representación en el idioma (
VideoBERT ),
-
Super-resolución + HDR .
¡Y había artículos sobre segmentación, determinación de la postura y reidentificación de animales!

Destacados
Casi todos los artículos se conocían de antemano, el texto estaba disponible en arXiv.org. Por lo tanto, la presentación de obras como Everybody Dance Now, FUNIT, Image2StyleGAN parece bastante extraña: estas son obras muy útiles, pero no son nuevas en absoluto. Parece que el proceso clásico de publicación científica está fallando aquí: la ciencia se está desarrollando demasiado rápido.
Es muy difícil determinar los mejores trabajos: hay muchos de ellos, los temas son diferentes. Varios artículos han recibido
premios y referencias .
Queremos resaltar trabajos que son interesantes en términos de manipulación de imágenes, ya que este es nuestro tema. Resultó ser bastante fresco e interesante para nosotros (no pretendemos ser objetivos).
SinGAN (premio al mejor papel) e InGAN
SinGAN:
página del proyecto ,
arXiv ,
código .
InGAN:
página del proyecto ,
arXiv ,
código .
El desarrollo de la idea de Deep Image Prior por Dmitry Ulyanov, Andrea Vedaldi y Victor Lempitsky. En lugar de entrenar a GAN en un conjunto de datos, las redes aprenden de fragmentos de la misma imagen para recordar las estadísticas que contiene. La red entrenada le permite editar y animar fotos (SinGAN) o generar nuevas imágenes de cualquier tamaño a partir de las texturas de la imagen original, manteniendo la estructura local (InGAN).
SinGAN:

InGAN:

Ver lo que una GAN no puede generar
Página del proyectoLas redes neuronales generadoras de imágenes a menudo reciben un vector de ruido aleatorio como entrada. En una red entrenada, muchos vectores de entrada forman un espacio, pequeños movimientos que conducen a pequeños cambios en la imagen. Usando la optimización, puede resolver el problema inverso: encontrar un vector de entrada adecuado para una imagen del mundo real. El autor muestra que casi nunca es posible encontrar una imagen completamente coincidente en una red neuronal casi nunca. Algunos objetos en la imagen no se generan (aparentemente, debido a la gran variabilidad de estos objetos).
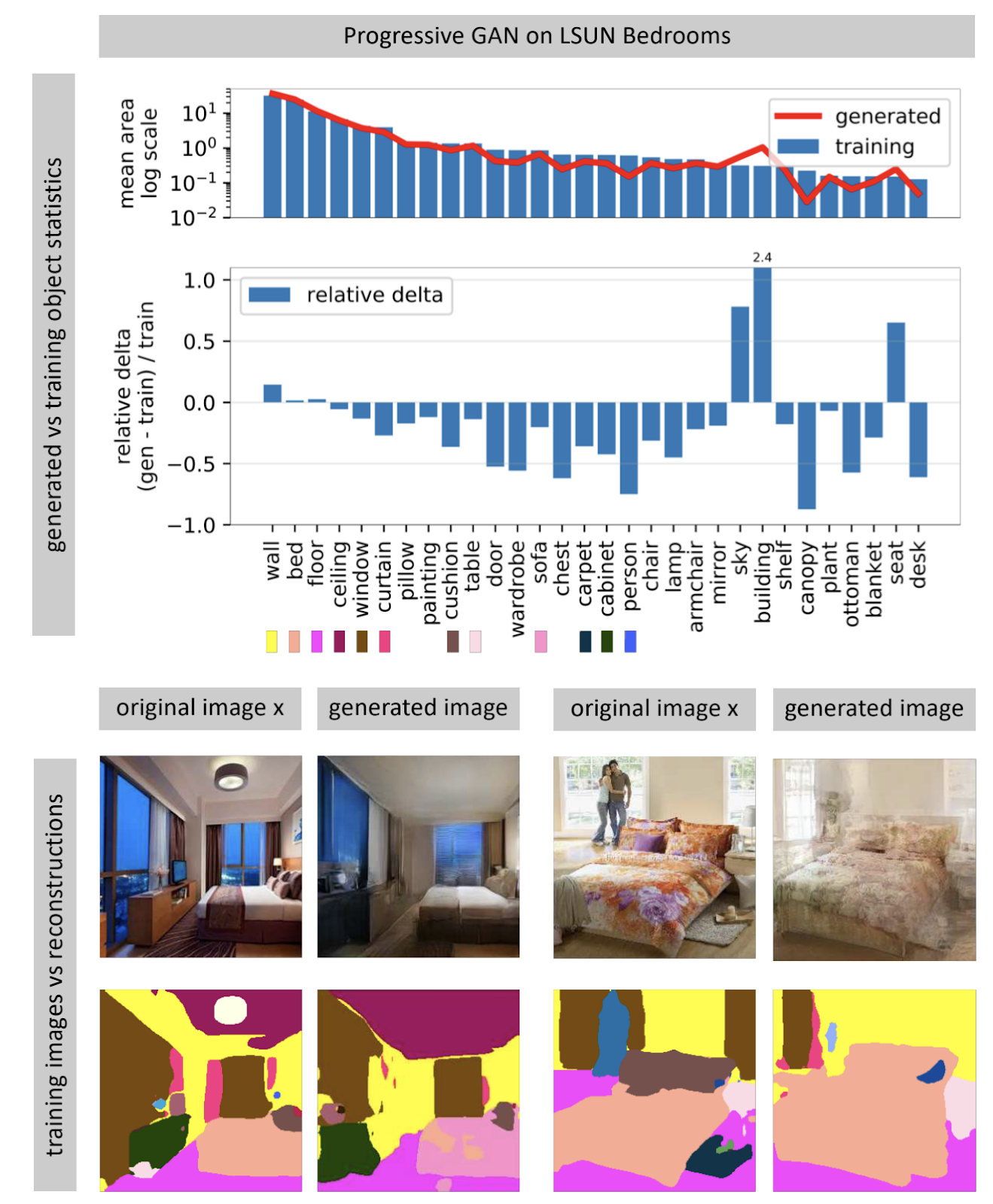
El autor plantea la hipótesis de que la GAN no cubre todo el espacio de las imágenes, sino solo un subconjunto relleno de agujeros, como el queso. Cuando intentamos encontrar fotos del mundo real en él, siempre fallaremos, porque la GAN todavía no genera fotos reales. Puede superar las diferencias entre imágenes reales y generadas solo cambiando el peso de la red, es decir, volviéndola a entrenar para una foto específica.

Cuando la red se vuelve a entrenar para una foto específica, puede intentar realizar varias manipulaciones con esta imagen. En el ejemplo a continuación, se agregó una ventana a la foto, y la red además generó reflejos en el juego de cocina. Esto significa que la red después del reentrenamiento para fotografía no perdió la capacidad de ver la conexión entre los objetos de la escena.

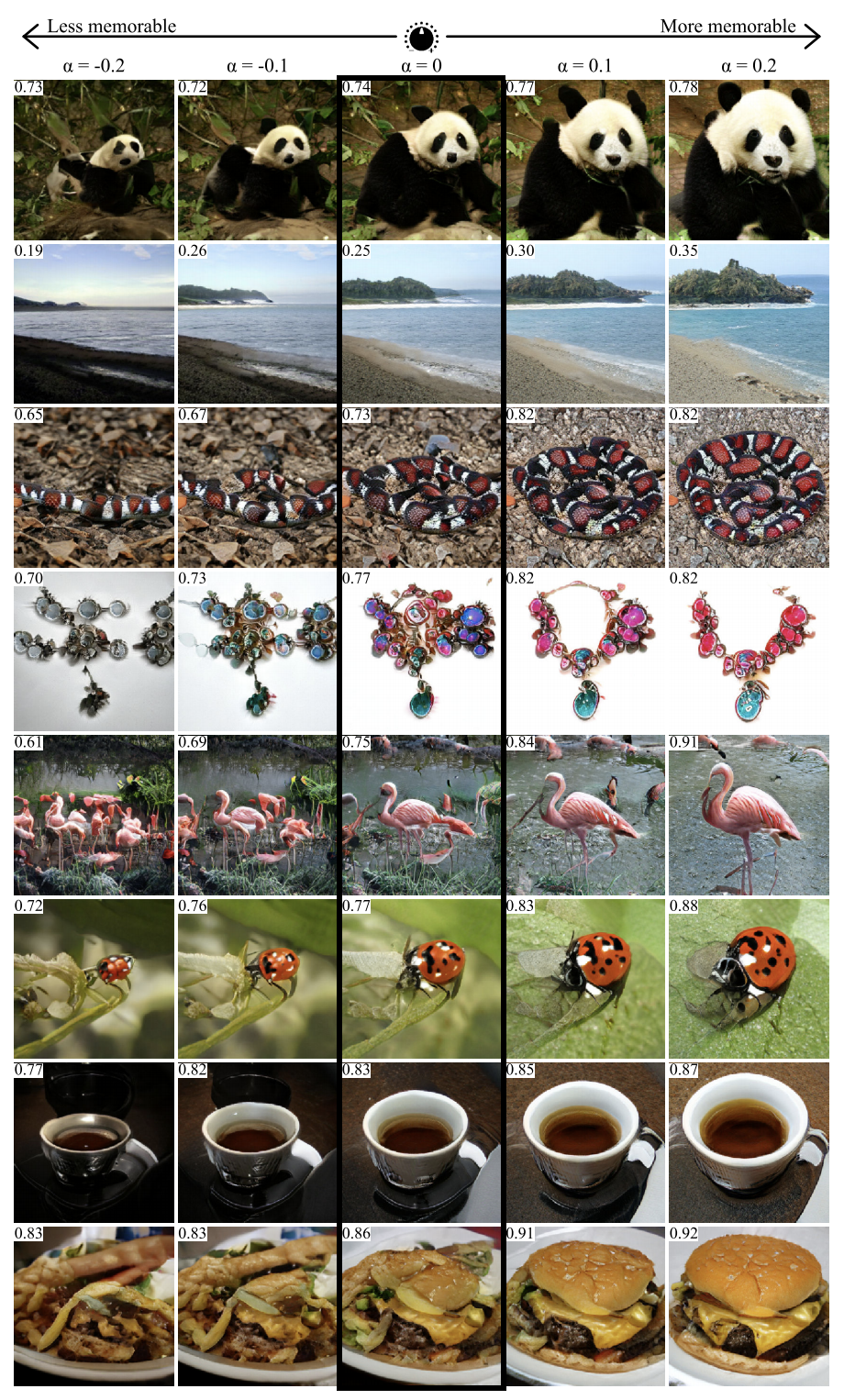
GANalyze: hacia las definiciones visuales de las propiedades de imagen cognitiva
Página del proyecto ,
arXiv .
Usando el enfoque de este trabajo, puede visualizar y analizar lo que la red neuronal ha aprendido. Los autores proponen capacitar a GAN para crear imágenes para las cuales la red generará predicciones dadas. Se usaron varias redes como ejemplos en el artículo, incluida MemNet, que predice la memorabilidad de las fotos. Resultó que para una mejor memorabilidad, el objeto en la foto debería:
- estar más cerca del centro
- tienen una forma redonda o cuadrada y una estructura simple,
- estar en un fondo uniforme,
- contener ojos expresivos (al menos para fotos de perros),
- ser más brillante, más rico, en algunos casos, más rojo.
Liquid Warping GAN: un marco unificado para imitación de movimiento humano, transferencia de apariencia y síntesis de vista novedosa
Página del proyecto ,
arXiv ,
código .
Canalización para generar fotos de personas a partir de una foto. Los autores muestran ejemplos exitosos de transferir el movimiento de una persona a otra, transferir ropa entre personas y generar nuevas perspectivas de una persona, todo desde una fotografía. A diferencia de trabajos anteriores, aquí, para crear condiciones, no se utilizan puntos clave en 2D (pose), sino una malla 3D del cuerpo (pose + forma). Los autores también descubrieron cómo transferir información de la imagen original a la generada (Liquid Warping Block). Los resultados parecen decentes, pero la resolución de la imagen resultante es de solo 256x256. En comparación, vid2vid, que apareció hace un año, es capaz de generar con una resolución de 2048x1024, pero necesita hasta 10 minutos de grabación de video como un conjunto de datos.

FSGAN: Intercambio de rostros agnósticos de sujetos y recreación
Página del proyecto ,
arXiv .
Al principio parece que nada inusual: deepfake con calidad más o menos normal. Pero el logro principal del trabajo es la sustitución de caras en una imagen. A diferencia de trabajos anteriores, se requería capacitación en una variedad de fotografías de una persona en particular. La tubería resultó ser engorrosa (recreación y segmentación, vista de interpolación, pintura, mezcla) y con muchos trucos técnicos, pero el resultado vale la pena.

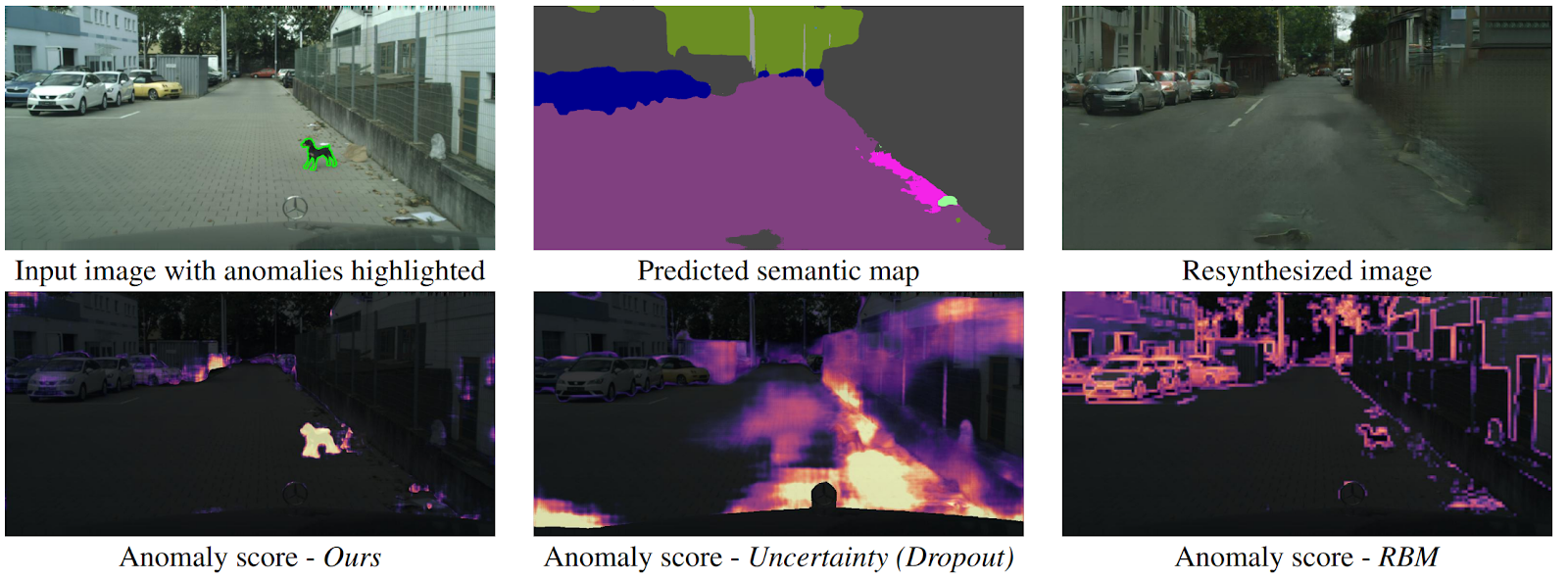
Detectando lo inesperado mediante la resíntesis de imagen
arXiv .
¿Cómo puede un dron comprender que un objeto apareció de repente frente a él que no cae en ninguna clase de segmentación semántica? Existen varios métodos, pero los autores ofrecen un nuevo algoritmo intuitivo que funciona mejor que sus predecesores. La segmentación semántica se predice a partir de la imagen de entrada de la carretera. Se alimenta a la GAN (pix2pixHD), que intenta restaurar la imagen original solo desde el mapa semántico. Las anomalías que no caen en ninguno de los segmentos diferirán significativamente en la fuente y la imagen generada. Luego, tres imágenes (inicial, segmentación y reconstrucción) se envían a otra red, que predice anomalías. El conjunto de datos para esto se generó a partir del conocido conjunto de datos Cityscapes, que cambió accidentalmente las clases de segmentación semántica. Curiosamente, en este contexto, un perro parado en medio del camino, pero correctamente segmentado (lo que significa que hay una clase para eso), no es una anomalía, ya que el sistema pudo reconocerlo.
Conclusión
Antes de la conferencia es importante saber cuáles son sus intereses científicos, a qué discursos me gustaría hablar, con quién hablar. Entonces todo será mucho más productivo.
ICCV es principalmente redes. Entiendes que existen las mejores instituciones y los mejores científicos, comienzas a entender esto, a conocer gente. Y puede leer artículos en arXiv, y por cierto, es genial que no pueda ir a ninguna parte para obtener conocimiento.
Además, en la conferencia puede profundizar en temas que no están cerca de usted, ver tendencias. Bueno, escriba una lista de artículos para leer. Si eres un estudiante, esta es una oportunidad para que te familiarices con un científico potencial, si eres de la industria, luego con un nuevo empleador y, si es la empresa, muéstrate.
¡Suscríbete a
@loss_function_porn ! Este es un proyecto personal: estamos juntos con
Karfly . Todo el trabajo que nos gustó durante la conferencia, lo publicamos aquí:
@loss_function_live .