
En un
artículo anterior, examinamos la agrupación RabbitMQ para determinar la tolerancia a fallas y la alta disponibilidad. Ahora profundicemos en Apache Kafka.
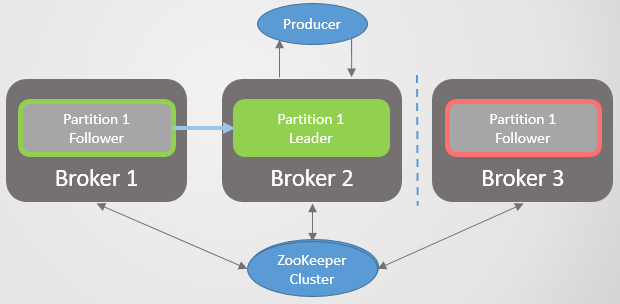
Aquí, la unidad de replicación es una partición. Cada tema tiene una o más secciones. Cada sección tiene un líder con o sin seguidores. Al crear un tema, se indica el número de particiones y la tasa de replicación. El valor habitual es 3, lo que significa tres comentarios: un líder y dos seguidores.
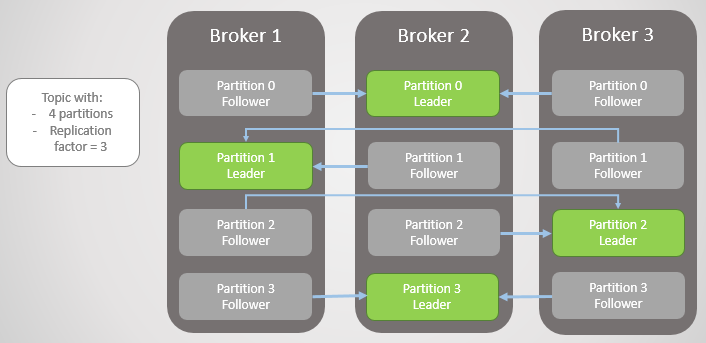 Fig. 1. Cuatro secciones se distribuyen entre tres corredores
Fig. 1. Cuatro secciones se distribuyen entre tres corredoresTodas las solicitudes de lectura y escritura van al líder. Los seguidores envían periódicamente solicitudes al líder para recibir los últimos mensajes. Los consumidores nunca recurren a los seguidores, estos últimos solo existen por redundancia y tolerancia a fallas.

Sección fallida
Cuando un corredor se cae, los líderes de varias secciones a menudo fallan. En cada uno de ellos, el seguidor de otro nodo se convierte en el líder. De hecho, este no es siempre el caso, ya que el factor de sincronización también afecta: si hay seguidores sincronizados, y si no, se permite la transición a una réplica no sincronizada. Pero por ahora, no lo compliquemos.
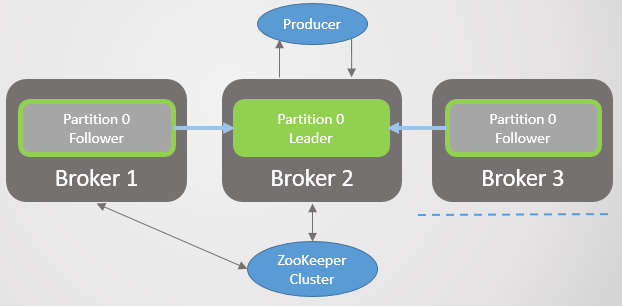
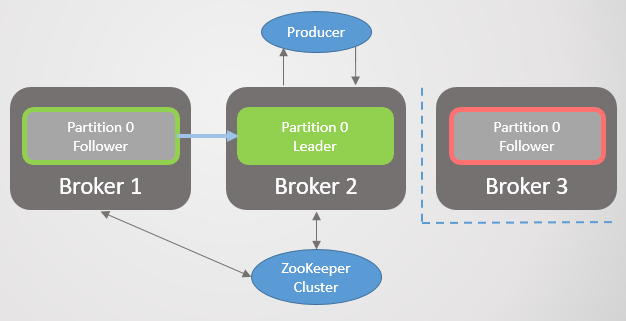
El corredor 3 abandona la red, y para la sección 2 se elige un nuevo líder en el corredor 2.
 Fig. 2. El corredor 3 muere y su seguidor en el corredor 2 es elegido como el nuevo líder de la sección 2
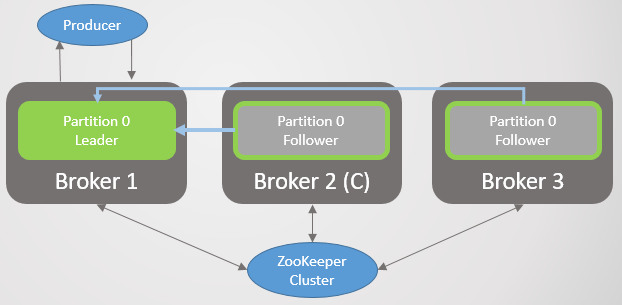
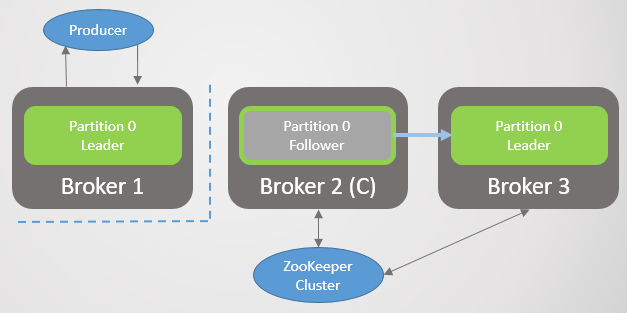
Fig. 2. El corredor 3 muere y su seguidor en el corredor 2 es elegido como el nuevo líder de la sección 2Entonces el corredor 1 se va y la sección 1 también pierde a su líder, cuyo papel va al corredor 2.
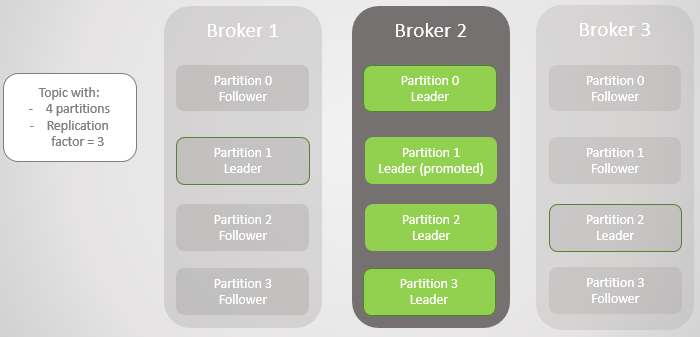 Fig. 3. Solo queda un corredor. Todos los líderes están en el mismo corredor de cero redundancia.
Fig. 3. Solo queda un corredor. Todos los líderes están en el mismo corredor de cero redundancia.Cuando el corredor 1 regresa a la red, agrega cuatro seguidores, proporcionando redundancia a cada sección. Pero todos los líderes seguían en el corredor 2.
 Fig. 4. Los líderes permanecen en el corredor 2
Fig. 4. Los líderes permanecen en el corredor 2Cuando el corredor 3 sube, volvemos a tres réplicas por sección. Pero todos los líderes todavía están en el corredor 2.
 Fig. 5. Colocación desequilibrada de líderes después de la restauración de los corredores 1 y 3
Fig. 5. Colocación desequilibrada de líderes después de la restauración de los corredores 1 y 3Kafka tiene una herramienta para mejorar el equilibrio de los líderes que RabbitMQ. Allí tuvo que usar un complemento o script de un tercero que cambió las políticas para migrar el nodo principal al reducir la redundancia durante la migración. Además, para grandes colas tuvieron que soportar la inaccesibilidad durante la sincronización.
Kafka tiene un concepto de "señales preferidas" para el papel de liderazgo. Cuando se crean las secciones de temas, Kafka intenta distribuir uniformemente los líderes entre los nodos y marca a estos primeros líderes como preferidos. Con el tiempo, debido a reinicios del servidor, fallas y fallas de conectividad, los líderes pueden terminar en otros nodos, como en el caso extremo descrito anteriormente.
Para solucionar esto, Kafka ofrece dos opciones:
- La opción auto .
- Un administrador puede ejecutar el script kafka-preferred-replica-election.sh para reasignarlo manualmente.
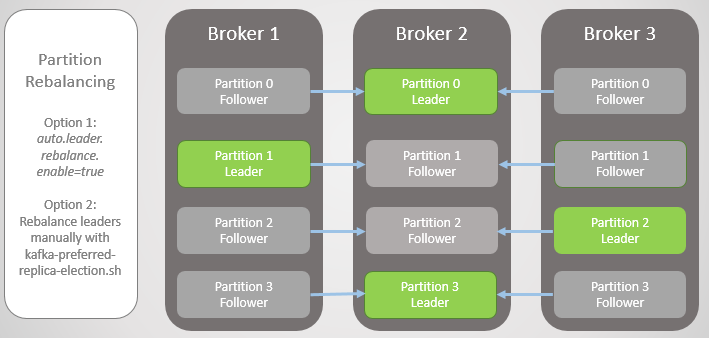 Fig. 6. Réplicas después del reequilibrio
Fig. 6. Réplicas después del reequilibrioEra una versión simplificada del fracaso, pero la realidad es más compleja, aunque no hay nada demasiado complicado aquí. Todo se reduce a réplicas sincronizadas (réplicas sincronizadas, ISR).
Réplicas sincronizadas (ISR)
ISR es un conjunto de réplicas de una partición que se considera "sincronizada" (sincronizada). Hay un líder, pero puede que no haya seguidores. Un seguidor se considera sincronizado si realizó copias exactas de todos los mensajes de líder antes del vencimiento del intervalo
replica.lag.time.max.ms .
El seguidor se elimina del conjunto ISR si:
- no realizó una solicitud de muestreo para el intervalo replica.lag.time.max.ms (considerado muerto)
- no tuvo tiempo de actualizar para el intervalo replica.lag.time.max.ms (considerado lento)
Los seguidores realizan solicitudes de búsqueda en el intervalo
replica.fetch.wait.max.ms , que por defecto es de 500 ms.
Para explicar claramente el propósito de ISR, debe mirar las confirmaciones del productor (productor) y algunos escenarios de falla. Los productores pueden elegir cuándo un corredor envía una confirmación:
- acks = 0, la confirmación no se envía
- acks = 1, la confirmación se envía después de que el líder ha escrito un mensaje en su registro local
- acks = all, la confirmación se envía después de que todas las réplicas en el ISR hayan escrito un mensaje en los registros locales
En la terminología de Kafka, si el ISR ha guardado el mensaje, está "comprometido". Acks = all es la opción más segura, pero también un retraso adicional. Veamos dos ejemplos de fallas y cómo las diferentes opciones de 'acks' interactúan con el concepto de ISR.
Acks = 1 e ISR
En este ejemplo, veremos que si el líder no espera a que se guarde cada mensaje de todos los seguidores, entonces si el líder falla, los datos pueden perderse. Ir a un seguidor no sincronizado puede habilitarse o deshabilitarse configurando
unclean.leader.election.enable .
En este ejemplo, el fabricante se establece en acks = 1. La sección se distribuye entre los tres corredores. El corredor 3 está detrás, se sincronizó con el líder hace ocho segundos y ahora está detrás con 7456 mensajes. El corredor 1 está solo un segundo detrás. Nuestro productor envía un mensaje y rápidamente recibe un reconocimiento, sin gastos generales para seguidores lentos o muertos que el líder no espera.
 Fig. 7. ISR con tres réplicas
Fig. 7. ISR con tres réplicasEl intermediario 2 falla y el fabricante recibe un error de conexión. Después de la transición de liderazgo al corredor 1, perdemos 123 mensajes. El seguidor del corredor 1 era parte del ISR, pero no se sincronizó completamente con el líder cuando cayó.
 Fig. 8. Al fallar, los mensajes se pierden
Fig. 8. Al fallar, los mensajes se pierdenEn la configuración
bootstrap.servers , el fabricante enumera varios corredores, y puede preguntar a otro corredor que se convirtió en el nuevo líder de la sección. Luego establece una conexión con el corredor 1 y continúa enviando mensajes.
 Fig. 9. El envío de mensajes se reanuda después de un breve descanso
Fig. 9. El envío de mensajes se reanuda después de un breve descansoBroker 3 retrasos aún más. Realiza solicitudes de búsqueda, pero no puede sincronizar. Esto puede deberse a una conexión de red lenta entre corredores, un problema de almacenamiento, etc. Se elimina del ISR. Ahora ISR consiste en una réplica: ¡el líder! El fabricante continúa enviando mensajes y recibiendo confirmación.
 Fig. 10. El seguidor del corredor 3 se elimina del ISR
Fig. 10. El seguidor del corredor 3 se elimina del ISREl corredor 1 cae, y el papel del líder pasa al corredor 3 con la pérdida de 15286 mensajes. El fabricante recibe un mensaje de error de conexión. Ir al líder fuera del ISR solo fue posible debido a la configuración
unclean.leader.election.enable = true . Si se establece en
falso , entonces la transición no habría ocurrido, y todas las solicitudes de lectura y escritura serían rechazadas. En este caso, estamos esperando el regreso del broker 1 con sus datos intactos en la réplica, que nuevamente tomará la delantera.
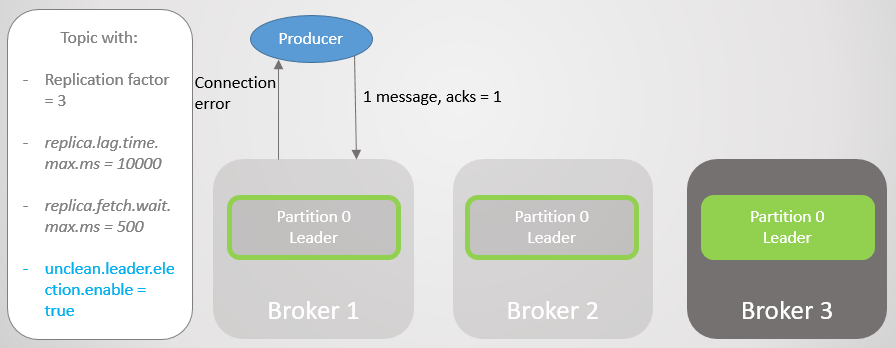 Fig. 11. Broker 1 gotas. Se pierde una gran cantidad de mensajes en caso de falla
Fig. 11. Broker 1 gotas. Se pierde una gran cantidad de mensajes en caso de fallaEl fabricante establece una conexión con el último corredor y ve que ahora él es el líder de la sección. Comienza a enviar mensajes al corredor 3.
 Fig. 12. Después de un breve descanso, los mensajes se envían nuevamente a la sección 0
Fig. 12. Después de un breve descanso, los mensajes se envían nuevamente a la sección 0Vimos que, además de breves interrupciones para establecer nuevas conexiones y buscar un nuevo líder, el fabricante enviaba mensajes constantemente. Esta configuración proporciona accesibilidad a través de la coherencia (seguridad de datos). Kafka perdió miles de mensajes, pero continuó aceptando nuevas entradas.
Acks = todo e ISR
Repitamos este escenario nuevamente, pero con
acks = all . Retrasar el corredor 3 un promedio de cuatro segundos. El fabricante envía un mensaje con
acks = all , y ahora no recibe una respuesta rápida. El líder espera hasta que todos los mensajes en el ISR almacenen el mensaje.
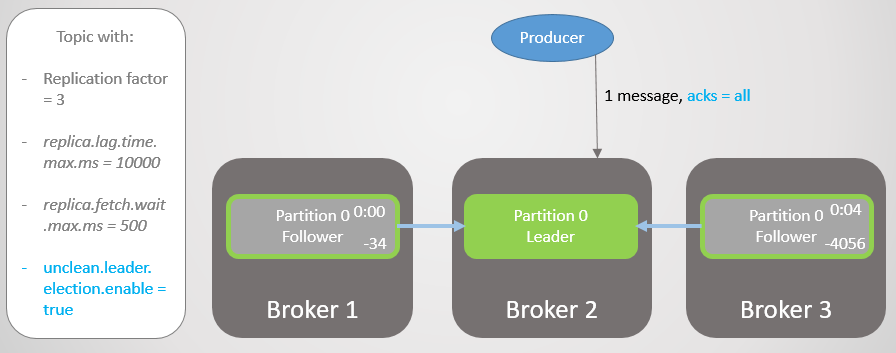 Fig. 13. ISR con tres réplicas. Uno es lento, lo que provoca un retraso en la grabación
Fig. 13. ISR con tres réplicas. Uno es lento, lo que provoca un retraso en la grabaciónDespués de cuatro segundos de retraso adicional, el corredor 2 envía un reconocimiento. Todas las réplicas ahora están completamente actualizadas.
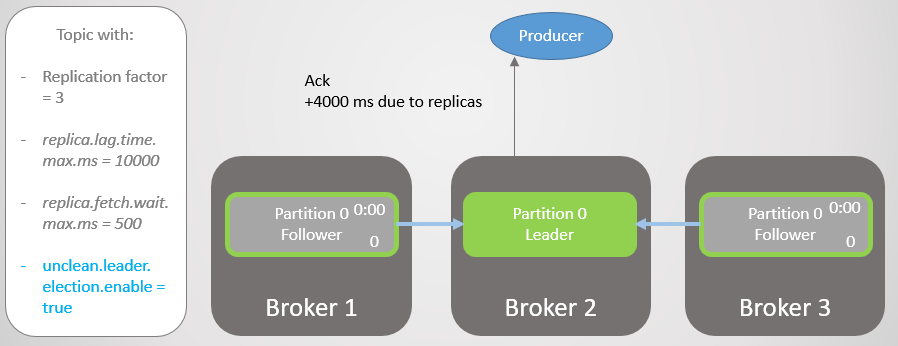 Fig. 14. Todas las réplicas guardan mensajes y se envía ack
Fig. 14. Todas las réplicas guardan mensajes y se envía ackBroker 3 ahora está aún más atrás y está siendo eliminado del ISR. El retraso se reduce significativamente porque no quedan réplicas lentas en el ISR. El corredor 2 ahora solo espera al corredor 1, y tiene un retraso promedio de 500 ms.
 Fig. 15. La réplica en el corredor 3 se elimina del ISR
Fig. 15. La réplica en el corredor 3 se elimina del ISREntonces el corredor 2 cae, y el liderazgo pasa al corredor 1 sin perder mensajes.
 Fig. 16. El corredor 2 está cayendo
Fig. 16. El corredor 2 está cayendoEl fabricante encuentra un nuevo líder y comienza a enviarle mensajes. El retraso aún se reduce, ¡porque ahora el ISR consiste en una réplica! Por lo tanto, la opción
acks = all no agrega redundancia.
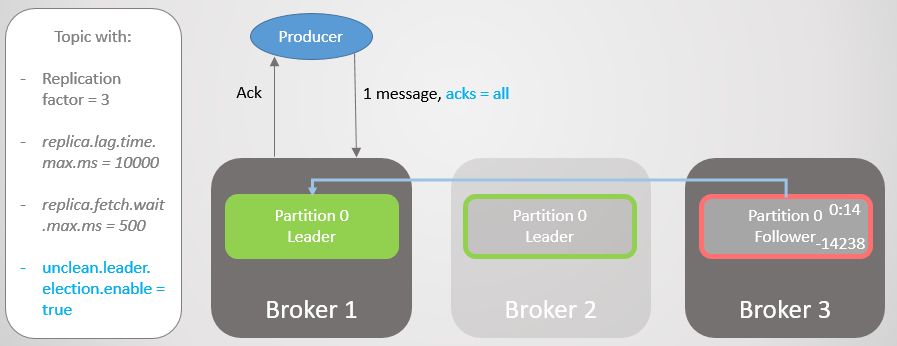 Fig. 17. La réplica en el corredor 1 toma la delantera sin perder mensajes
Fig. 17. La réplica en el corredor 1 toma la delantera sin perder mensajes¡Entonces el corredor 1 cae, y el liderazgo pasa al corredor 3 con la pérdida de 14,238 mensajes!
 Fig. 18. El corredor 1 muere, y la transición de liderazgo con una configuración impura conduce a una pérdida de datos extensa
Fig. 18. El corredor 1 muere, y la transición de liderazgo con una configuración impura conduce a una pérdida de datos extensaNo pudimos establecer la opción
unclean.leader.election.enable en
true . Por defecto, es
falso . Establecer
acks = all con
unclean.leader.election.enable = true proporciona accesibilidad con cierta seguridad de datos adicional. Pero, como puede ver, aún podemos perder mensajes.
Pero, ¿qué pasa si queremos aumentar la seguridad de los datos? Puede configurar
unclean.leader.election.enable = false , pero esto no necesariamente nos protege de la pérdida de datos. Si el líder cayó con fuerza y se llevó los datos consigo, entonces los mensajes aún se pierden, y se pierde la accesibilidad hasta que el administrador recupere la situación.
Es mejor garantizar la redundancia de todos los mensajes y, de lo contrario, negarse a grabar. Entonces, al menos desde el punto de vista del corredor, la pérdida de datos es posible solo con dos o más fallas simultáneas.
Acks = all, min.insync.replicas e ISR
Con la
configuración del tema
min.insync.replicas, aumentamos la seguridad de los datos. Veamos la última parte del último escenario una vez más, pero esta vez con
min.insync.replicas = 2 .
Entonces, el corredor 2 tiene un líder de réplica, y el seguidor del corredor 3 se elimina del ISR.
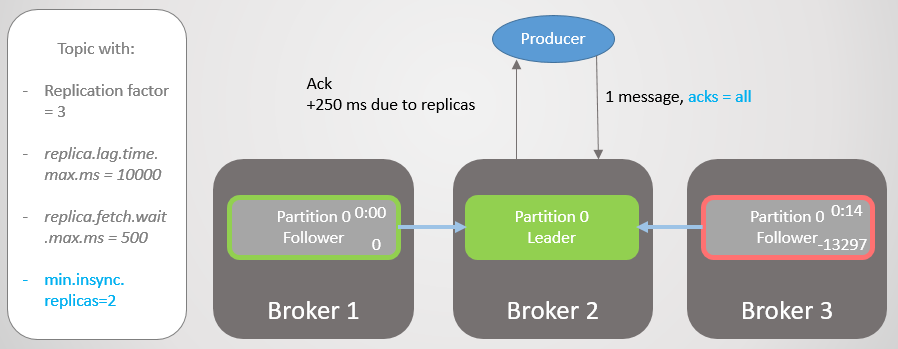 Fig. 19. ISR de dos réplicas
Fig. 19. ISR de dos réplicasEl corredor 2 cae, y el liderazgo pasa al corredor 1 sin perder mensajes. Pero ahora ISR consta de una sola réplica. Esto no corresponde al número mínimo para recibir registros y, por lo tanto, el intermediario responde al intento de grabar con el error
NotEnoughReplicas .
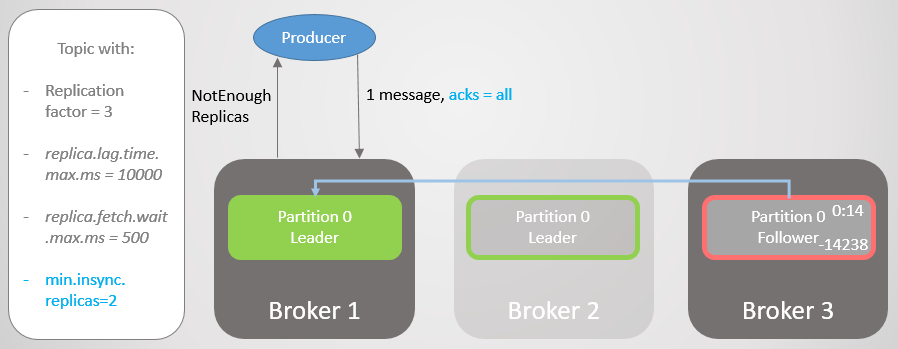 Fig. 20. El número de ISR es uno menor que el especificado en min.insync.replicas
Fig. 20. El número de ISR es uno menor que el especificado en min.insync.replicasEsta configuración sacrifica la disponibilidad por coherencia. Antes de confirmar un mensaje, garantizamos que está grabado en al menos dos réplicas. Esto le da al fabricante mucha más confianza. Aquí, la pérdida de mensajes es posible solo si dos réplicas fallan simultáneamente en un intervalo corto, hasta que el mensaje se replica a un seguidor adicional, lo cual es poco probable. Pero si usted es un superparanoide, puede establecer la relación de replicación en 5, y las
réplicas mínimas de
sincronización en 3. ¡Entonces tres corredores a la vez deben caer al mismo tiempo para perder el registro! Por supuesto, para tal confiabilidad pagará un retraso adicional.
Cuando se necesita accesibilidad para la seguridad de los datos
Al igual que
con RabbitMQ , a veces la accesibilidad es necesaria para la seguridad de los datos. Tienes que pensar en esto:
- ¿Puede un editor simplemente devolver un error y un servicio superior o un usuario intentarlo más tarde?
- ¿Puede un editor guardar un mensaje localmente o en una base de datos para volver a intentarlo más tarde?
Si la respuesta es no, entonces optimizar la accesibilidad mejora la seguridad de los datos. Perderá menos datos si elige la disponibilidad en lugar de descartar la grabación. Por lo tanto, todo se reduce a encontrar un equilibrio, y la decisión depende de la situación específica.
El significado de ISR
La suite ISR le permite elegir el equilibrio óptimo entre la seguridad de los datos y la latencia. Por ejemplo, para asegurar que la mayoría de las réplicas sean accesibles en caso de falla, minimizando el impacto de las réplicas muertas o lentas en términos de retraso.
Nosotros mismos elegimos el valor de
replica.lag.time.max.ms de acuerdo con nuestras necesidades. En esencia, este parámetro significa qué retraso estamos listos para aceptar con
acks = all . El valor predeterminado es diez segundos. Si esto es demasiado largo para usted, puede reducirlo. Luego, la frecuencia de los cambios en el ISR aumentará, ya que los seguidores se eliminarán y agregarán con mayor frecuencia.
RabbitMQ es solo una colección de espejos que necesitan ser replicados. Los espejos lentos introducen un retraso adicional, y se puede esperar la respuesta de los espejos muertos antes de la expiración de los paquetes que verifican la disponibilidad de cada nodo (tick neto). Los ISR son una forma interesante de evitar estos problemas con una mayor latencia. Pero corremos el riesgo de perder la redundancia, ya que ISR solo puede reducirse a un líder. Para evitar este riesgo, use la configuración
min.insync.replicas .
Garantía de conectividad del cliente
En la configuración de
bootstrap.servers del fabricante y el consumidor, puede especificar varios intermediarios para conectar clientes. La idea es que cuando desconecta un nodo, hay varios nodos de repuesto con los que el cliente puede abrir una conexión. Estos no son necesariamente líderes de sección, sino simplemente un trampolín para el arranque. El cliente puede preguntarles en qué nodo se encuentra el líder de la sección de lectura / escritura.
En RabbitMQ, los clientes pueden conectarse a cualquier host, y el enrutamiento interno envía una solicitud cuando es necesario. Esto significa que puede instalar un equilibrador de carga frente a RabbitMQ. Kafka requiere que los clientes se conecten al host que aloja al líder de la partición correspondiente. En esta situación, el equilibrador de carga no se entrega. La lista
bootstrap.servers es crítica para que los clientes puedan acceder a los nodos correctos y encontrarlos después de un bloqueo.
Arquitectura del consenso de Kafka
Hasta ahora, no hemos considerado cómo el grupo se entera de la caída del corredor y cómo se elige un nuevo líder. Para comprender cómo funciona Kafka con las particiones de red, primero debe comprender la arquitectura de consenso.
Cada clúster Kafka se implementa con el clúster Zookeeper: es un servicio de consenso distribuido que permite que el sistema llegue a un consenso en un estado determinado con prioridad de coherencia sobre la disponibilidad. La aprobación de las operaciones de lectura y escritura requiere el consentimiento de la mayoría de los nodos de Zookeeper.
Zookeeper almacena el estado del clúster:
- Lista de temas, secciones, configuración, réplicas líderes actuales, réplicas preferidas.
- Miembros del grupo. Cada corredor hace ping en un clúster de Zookeeper. Si no recibe ping durante un período de tiempo determinado, Zookeeper escribe que el corredor es inaccesible.
- La elección de nodos primarios y secundarios para el controlador.
El nodo controlador es uno de los intermediarios de Kafka que es responsable de elegir líderes de réplica. Zookeeper envía al controlador notificaciones de membresía del clúster y cambios de tema, y el controlador debe actuar de acuerdo con estos cambios.
Por ejemplo, tome un nuevo tema con diez secciones y un coeficiente de replicación de 3. El controlador debe seleccionar el líder de cada sección, tratando de distribuir de manera óptima los líderes entre los corredores.
Para cada sección, el controlador:
- actualiza la información en Zookeeper sobre ISR y el líder;
- envía un comando LeaderAndISRCommand a cada agente que publica una réplica de esta sección, informando a los agentes sobre el ISR y el líder.
Cuando un corredor con un líder cae, Zookeeper envía una notificación al controlador y este selecciona un nuevo líder. Nuevamente, el controlador primero actualiza Zookeeper, y luego envía un comando a cada corredor, notificándoles un cambio en el liderazgo.
Cada líder es responsable de reclutar ISR. La
configuración replica.lag.time.max.ms determina quién irá allí. Cuando el ISR cambia, el líder pasa la nueva información a Zookeeper.
Zookeeper siempre está informado de cualquier cambio, de modo que en caso de falla, la gerencia se traslada sin problemas al nuevo líder.
 Fig. 21. Consenso Kafka
Fig. 21. Consenso KafkaProtocolo de replicación
Comprender los detalles de la replicación lo ayuda a comprender mejor los posibles escenarios de pérdida de datos.
Solicitudes de muestra, desplazamiento de fin de registro (LEO) y Highwater Mark (HW)
Hemos considerado que los seguidores envían periódicamente solicitudes de búsqueda al líder. El intervalo predeterminado es de 500 ms. Esto difiere de RabbitMQ en que en RabbitMQ, la replicación no se inicia por el espejo de la cola, sino por el asistente. El maestro empuja los cambios a los espejos.
El líder y todos los seguidores conservan la etiqueta Log End Offset (LEO) y Highwater (HW). La marca LEO almacena el desplazamiento del último mensaje en la réplica local, y HW almacena el desplazamiento de la última confirmación. Recuerde que para el estado de confirmación, el mensaje debe guardarse en todas las réplicas de ISR. Esto significa que LEO generalmente está ligeramente por delante de HW.
Cuando un líder recibe un mensaje, lo guarda localmente. El seguidor hace una solicitud de búsqueda, pasando su LEO. El líder luego envía un paquete de mensajes que comienzan con este LEO, y también transmite el HW actual. Cuando el líder recibe información de que todas las réplicas han guardado el mensaje en un desplazamiento determinado, mueve la marca HW. Solo el líder puede mover el HW, por lo que todos los seguidores sabrán el valor actual en las respuestas a su solicitud. Esto significa que los seguidores pueden ir a la zaga del líder tanto en informes como en conocimiento de HW. Los consumidores reciben mensajes solo hasta el HW actual.
Tenga en cuenta que "persistente" significa escrito en la memoria, no en el disco. Para el rendimiento, Kafka se sincroniza con el disco en un intervalo especificado. RabbitMQ también tiene ese intervalo, pero enviará una confirmación al editor solo después de que el maestro y todos los espejos hayan escrito el mensaje en el disco. Los desarrolladores de Kafka por razones de rendimiento decidieron enviar un reconocimiento tan pronto como el mensaje se escribe en la memoria. Kafka se basa en el hecho de que la redundancia compensa el riesgo de almacenamiento a corto plazo de mensajes confirmados solo en la memoria.
Fracaso del líder
Cuando un líder cae, Zookeeper notifica al controlador y selecciona una nueva réplica del líder. El nuevo líder establece una nueva marca HW en línea con su LEO. Entonces los seguidores reciben información sobre el nuevo líder. Dependiendo de la versión de Kafka, el seguidor elegirá uno de dos escenarios:
- Trunca el registro local al famoso HW y envía un mensaje al nuevo líder después de esta marca.
- , HW , . , .
:
- , ISR, Zookeeper, . ISR, «», . , . Kafka , . , , HW . , acks=all .
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
1. , Zookeeper
 . 22. 1. ISR
. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
 . 23. 1. ISR, replica.lag.time.max.ms
. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 . 24. 2.
. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 . 25. 2. ISR
. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
 . 26. 3.
. 26. 3.4. , Zookeeper
 . 27. 4.
. 27. 4.Zookeeper, .
 . 28. 4. Zookeeper
. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 . 29. 4. 1
. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
 . 30. 5. ISR
. 30. 5. ISR6. Kafka, Zookeeper
 . 31. 6.
. 31. 6., Zookeeper.
acks=1 .
 . 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
 . 33. 6.
. 33. 6., . 60 . .
 . 34. 6.
. 34. 6., . , Zookeeper , . HW .
 . 35. 6.
. 35. 6.,
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync cada pocos cientos de milisegundos
- Los espejos solo se pueden detectar después de la vida útil de los paquetes que verifican la disponibilidad de cada nodo (tic de red). Si el espejo se ralentiza o cae, esto agrega un retraso.
Kafka se basa en el hecho de que si el mensaje se almacena en varios nodos, puede confirmar los mensajes tan pronto como estén en la memoria. Debido a esto, existe el riesgo de perder mensajes de cualquier tipo (incluso
acks = all ,
min.insync.replies = 2 ) en caso de una falla simultánea.
En general, Kafka demuestra un mejor rendimiento y fue diseñado originalmente para clústeres. El número de seguidores se puede aumentar a 11, si es necesario para la confiabilidad. Un factor de replicación de 5 y un número mínimo de réplicas en un estado sincronizado de
min.insync.replicas = 3 harán que la pérdida de mensajes sea un evento muy raro. Si su infraestructura es capaz de proporcionar dicha tasa de replicación y un nivel de redundancia, puede elegir esta opción.
La agrupación RabbitMQ es buena para colas pequeñas. Pero incluso las colas pequeñas pueden crecer rápidamente con mucho tráfico. Una vez que las colas se vuelven grandes, tendrá que tomar una decisión difícil entre disponibilidad y confiabilidad. La agrupación RabbitMQ es más adecuada para situaciones no típicas en las que las ventajas de la flexibilidad de RabbitMQ superan cualquiera de las desventajas de agruparla.
Uno de los antídotos para la vulnerabilidad de la cola grande de RabbitMQ es dividirlos en muchos más pequeños. Si no requiere un pedido completo de toda la cola, sino solo mensajes relevantes (por ejemplo, mensajes de un cliente específico), o nada en absoluto, entonces esta opción es aceptable: mire mi proyecto
Rebalanser para dividir la cola (el proyecto aún está en una etapa temprana).
Finalmente, no se olvide de una serie de errores en los mecanismos de agrupación y replicación de RabbitMQ y Kafka. Con el tiempo, los sistemas se han vuelto más maduros y estables, ¡pero ni un solo mensaje estará 100% protegido contra pérdidas! Además, los accidentes a gran escala ocurren en los centros de datos.
Si me perdí algo, cometí un error o no está de acuerdo con ninguno de los puntos, no dude en escribir un comentario o contactarme.
La gente a menudo me pregunta: "¿Qué elegir, Kafka o RabbitMQ?", "¿Qué plataforma es mejor?". La verdad es que realmente depende de su situación, experiencia actual, etc. No me atrevo a expresar mi opinión, ya que sería una simplificación excesiva recomendar cualquier plataforma para todos los casos de uso y posibles limitaciones. Escribí esta serie de artículos para que puedas formarte tu propia opinión.
Quiero decir que ambos sistemas son líderes en este campo. Tal vez soy un poco parcial, porque por la experiencia de mis proyectos estoy más inclinado a apreciar cosas tales como la garantía y el orden de los mensajes.
Veo otras tecnologías que carecen de esta confiabilidad y pedidos garantizados, luego miro RabbitMQ y Kafka, y entiendo el increíble valor de ambos sistemas.