No hace mucho tiempo, vimos cómo se organizan los experimentos A / B en la búsqueda. El jefe del equipo de desarrollo para la versión iOS de Yandex. El navegador Andrei Sikerin
sav42 en la última reunión de CocoaHeads Rusia también habló sobre la infraestructura de prueba A / B, solo en su proyecto.
- Hola, mi nombre es Andrey Sikerin, estoy desarrollando Yandex.Browser para iOS. Quiero decirle cuál es la plataforma de experimentación del navegador para iOS, cómo aprendimos a usarla, admitió sus funciones más avanzadas, cómo diagnosticar y depurar las características implementadas utilizando el sistema de experimento, y también cuál es la fuente de entropía y dónde La moneda está almacenada.
Entonces comencemos. Nosotros en el navegador para iOS nunca lanzamos la función a los usuarios a la vez. Primero, llevamos a cabo pruebas A / B, analizamos las métricas técnicas y de productos para comprender cómo la función de rol afecta al usuario, si le gusta o no, si malgasta algunas métricas técnicas. Para esto usamos análisis. Nuestro análisis se parece a esto:
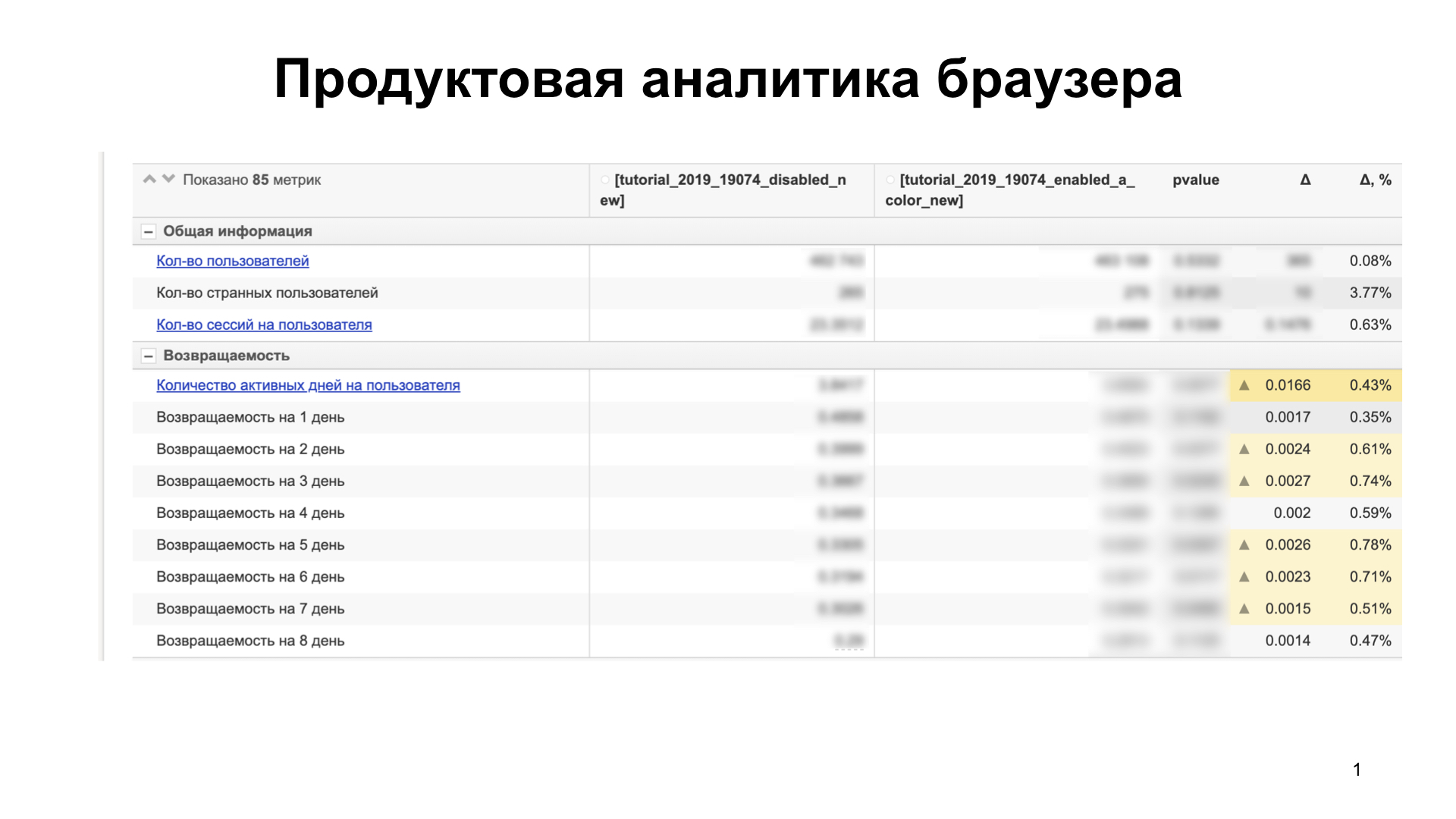
Hay alrededor de 85 métricas. Comparamos varios grupos de usuarios. Supongamos que esto aumenta nuestras métricas, por ejemplo, la capacidad del producto para retener a los usuarios (retención) y no desperdicia a otros que no están en la diapositiva. Esto significa que a los usuarios les gusta la función y se pueden transferir a un gran grupo de usuarios.
Si, sin embargo, desperdiciamos algo, entonces entendemos por qué. Construimos hipótesis, las confirmamos. Si dibujamos métricas técnicas, este es un bloqueador. Los arreglamos y volvemos a ejecutar el experimento nuevamente. Y así hasta que pintamos todo. Por lo tanto, implementamos una función que no es una fuente de regresión.
Hablemos sobre el sistema de experimento original que utilizamos. Ella ya estaba bastante desarrollada. Entonces te diré lo que no nos convenía.

Primero, se basa en el sistema de experimento Chromium y no era totalmente compatible con iOS. En segundo lugar, originalmente fue capaz de implementar funciones para diferentes grupos de usuarios y tenía un sistema de filtro en el que era posible establecer requisitos para los dispositivos. Es decir, la versión de la aplicación desde la cual está disponible la función, la configuración regional del dispositivo, digamos que queremos un experimento solo para la configuración regional rusa. La versión de iOS en la que estará disponible esta función o la fecha en que este experimento será válido, por ejemplo, si queremos realizar un experimento solo hasta una fecha determinada. En general, había muchas etiquetas y era bastante conveniente.
El sistema del experimento en sí consiste en un archivo que contiene descripciones de las configuraciones de los experimentos. Es decir, para un experimento puede haber varias configuraciones a la vez. Este archivo es un archivo de texto, se compila en protobuf y se presenta en el servidor.
Cada configuración consta de grupos. Hay un experimento, tiene varias configuraciones, y en cada una de ellas hay varios grupos. La función en el código se adjunta al nombre del grupo activo de la configuración activa. Puede parecer bastante complicado, pero ahora explicaré en detalle de qué se trata.

¿Cómo funciona técnicamente? Se carga un archivo con descripciones de todas las configuraciones en el servidor. Al inicio, el navegador lo descarga del servidor y se guarda en el disco. La próxima vez que comencemos, decodificaremos este archivo el primero en la cadena de inicialización de la aplicación. Y para cada experimento único, encontramos una configuración que estará activa.
La configuración adecuada para las condiciones especificadas y descritas en ella puede activarse. Si hay varias configuraciones activas que se ajustan a las condiciones especificadas, se activará la configuración que será más alta en el archivo.
Además en la configuración activa, se lanza una moneda. La moneda se arroja localmente, y de acuerdo con esta moneda de una manera determinada, que discutiremos más adelante, se selecciona el grupo activo del experimento. Y es precisamente al nombre del grupo activo del experimento que estamos adjuntos en el código, verificando si nuestra función está disponible o no.
Una característica clave de este sistema es que no almacena nada por sí mismo. Es decir, ella no tiene ningún almacenamiento en el disco. Cada lanzamiento: tomamos el archivo, comenzamos a calcularlo, encontramos la configuración activa. Dentro de la configuración, de acuerdo con la moneda, encontramos el grupo activo, y el sistema de experimento para este experimento dice: este grupo está seleccionado. Es decir, todo se calcula, no se almacena nada.

Permítame, de hecho, mostrarle un archivo con descripciones de experimentos. El navegador tiene esa característica: traductor. Ella se lanzó en un experimento. El archivo comienza con el bloque de estudio. La configuración de cualquier experimento comienza con este bloque. El experimento se llama traductor. Puede haber varios bloques de estudio con este nombre. Y dentro del bloque de estudio, hay muchos bloques de experimento a los que se les asignan diferentes nombres. En este caso, vemos el grupo de experimentos habilitado. Y hay un bloque de filtro que, de hecho, describe en qué condiciones puede activarse esta configuración, es decir, sus criterios.
Aquí hay dos etiquetas: channel y ya_min_version. Canal significa vista de ensamblaje. BETA se indica aquí, lo que significa que esta configuración en el archivo puede activarse solo para aquellos ensamblados que enviamos a TestFlight. Para la compilación de App Store, esta configuración según el criterio del canal no puede activarse.
ya_min_version significa que con la versión mínima de la aplicación 19.3.4.43 esta configuración puede activarse. En realidad, en esta versión de la aplicación, la función ya ha adquirido una forma tal que puede habilitarla.
Esta es la descripción más simple del grupo de configuración del experimento del traductor. Puede haber muchos bloques de estudio en un archivo. Usando etiquetas en el bloque de filtro, las configuramos para diferentes canales, para ensamblajes internos, para ensamblajes BETA, para varios criterios.
Aquí hay un grupo de experimento llamado habilitado, y tiene una etiqueta de peso de probabilidad, el peso del grupo de experimento. Este es un número entero no negativo utilizado para determinar el grupo activo en el momento en que aparece la moneda.
Imaginemos que esta configuración en la diapositiva se haya activado. Es decir, realmente instalamos la aplicación con beta pública, y realmente tenemos la versión 19.3.4.43 en adelante. ¿Cómo se lanza la moneda? Una moneda es un número aleatorio que se genera localmente de cero a uno.
Para que durante el próximo lanzamiento caigamos en el mismo grupo, se almacena en el disco. Si bien lo consideraremos así. A continuación, le diré cómo asegurarse de que no esté almacenado. La moneda es arrojada. Supongamos que se arroja 0.5. Esta moneda se escala en un segmento de cero a la suma de grupos de experimentos. En este caso, tenemos un grupo habilitado, su peso es 1000, es decir, la suma de todos los grupos será 1000. "0.5" escala a 500. En consecuencia, todos los grupos de experimentos dividen el intervalo de cero a la cantidad de experimentos y brechas. Y el grupo se activa en cuyo intervalo indicará el valor escalado de la moneda.
Podemos preguntar el nombre del grupo activo de experimentos en el código y así determinar la accesibilidad. ¿Necesitamos habilitar la función o no?
Además, veremos configuraciones experimentales más complejas que usamos en la producción. En primer lugar, está claro que es estúpido implementar una función al 100%, solo la usamos para beta o para ensamblaje interno. Para la producción, utilizamos la siguiente mecánica.
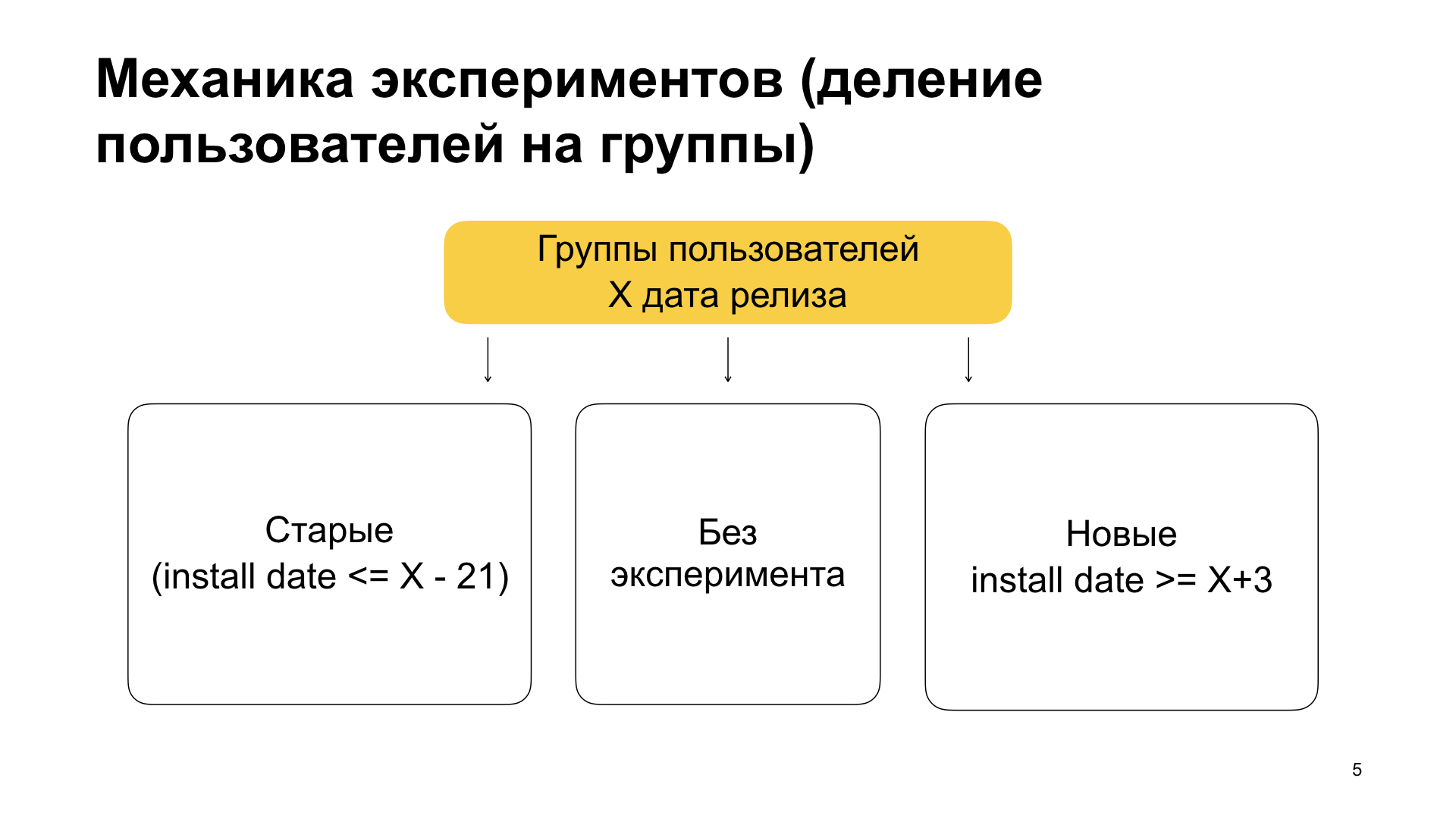
Dividimos a los usuarios en tres grupos: usuarios antiguos, usuarios sin experimento y usuarios nuevos. En significado, esto significa lo siguiente. Los antiguos usuarios son aquellos que ya han usado nuestra aplicación e instalada la aplicación con características además de la versión anterior. Es decir, ya lo usaban, no tenían características, se acostumbraron a todo y de repente actualizan la aplicación, en la que hay algún tipo de experimento, nueva funcionalidad. Luego, usuarios sin experimento y nuevos usuarios. Los nuevos son los que limpian la aplicación. Es decir, nunca usaron Yandex.Browser, de repente decidieron usarlo e instalaron la aplicación.
¿Cómo logramos esta partición? En el bloque de filtro, establecemos las condiciones para las etiquetas min_install_date y max_install_date. Supongamos que X es el 14 de marzo de 2019: esta es la fecha de lanzamiento de la compilación de características. Entonces max_install_date para usuarios antiguos será X menos 21 días, antes del lanzamiento del ensamblaje con características. Si la aplicación tiene una fecha de instalación de este tipo, es muy probable que su primer lanzamiento haya sido anterior al lanzamiento. Y antes del lanzamiento había una versión sin características. Y si ahora tiene, condicionalmente, una versión con características, significa que recibió la aplicación con la ayuda de una actualización.
Y para los nuevos usuarios, configuramos min_install_date. Lo exponemos como X más unos días. Esto significa: si tiene esa fecha de instalación, es decir, realizó el primer lanzamiento después de la fecha de lanzamiento de la versión con características, entonces tuvo una instalación limpia. Ahora tiene una versión con características, pero la fecha de instalación fue posterior a esta versión con características.
Por lo tanto, dividimos a los usuarios en viejos, sin experimento y nuevos. Hacemos esto porque vemos: el comportamiento de los usuarios antiguos es diferente del comportamiento de los usuarios nuevos. En consecuencia, podemos, por ejemplo, no pintar en un grupo con usuarios antiguos, sino pintar en un grupo con nuevos usuarios, o viceversa. Si hacemos un experimento en toda la masa, es posible que no veamos esto.

Veamos este experimento. Vemos la siguiente configuración de experimento: traductor para App Store, nuevos usuarios. Estudio de bloque, traductor de nombres, grupo habilitado_nuevo. El prefijo nuevo significa que describimos la configuración para muchos usuarios que son nuevos. Peso 500 (si la suma de todos los pesos es 1000, entonces la potencia de este conjunto es 50%). Control_new, peso 500, este es el segundo grupo. Y lo más interesante son los filtros para el canal ESTABLE, es decir, para conjuntos ensamblados para producción. Versión en la que apareció la función: 19.4.1. Y aquí está la etiqueta min_install_date. Aquí, en formato de hora Unix, se cifra el 18 de abril de 2019. Esto es unos días después del lanzamiento de la versión 19.4.1.
Hay una parte más aquí además del nuevo prefijo, está habilitado y controlado. Aquí está el prefijo de control; no es accidental. Y además del hecho de dividir a los usuarios en nuevos y viejos, los dividimos en grupos dentro del experimento en varias partes.
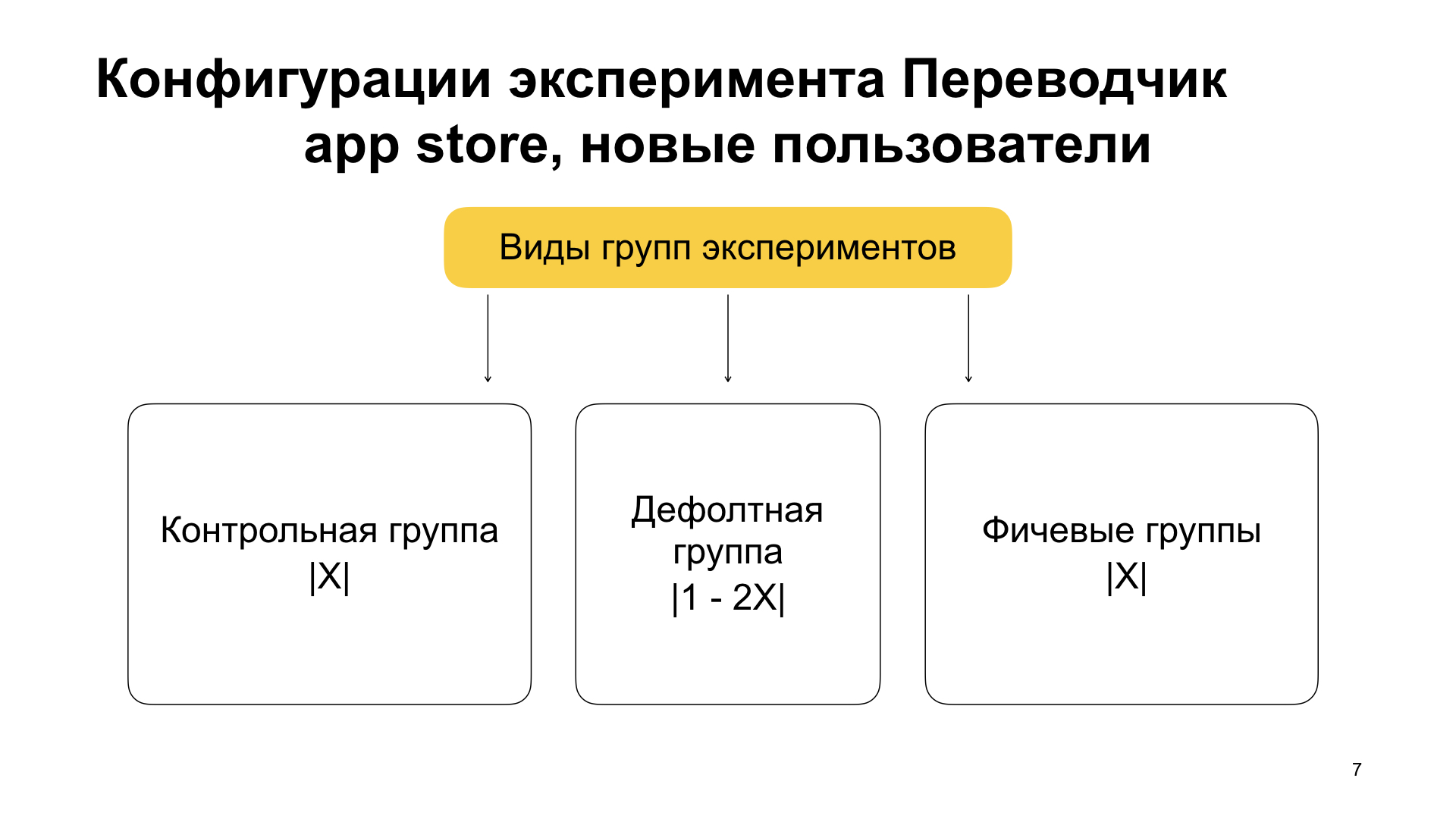
La primera parte de los usuarios es un grupo de control, uno que tiene el prefijo de control. No hay características en él. Ella tiene un peso X. También tiene un grupo de características, generalmente llamado habilitado. También tiene un peso X, y esto es importante: allí la función debería activarse. Y hay un grupo predeterminado que tiene un peso de 1 menos 2X (1000 menos 2X, ya que 1000 es el valor del peso total de todos los grupos dentro de la misma configuración, que se acepta por defecto). El grupo predeterminado tampoco incluye ninguna función. Simplemente almacena los usuarios que permanecieron después de dividirse en control y funciones. También puede volver a ejecutar el experimento desde él, si es necesario.

Veamos, digamos, la configuración para usuarios antiguos. Veremos una característica y un grupo de control aquí. enabled_old - destacado. control_old, - control, 10%. default_old: predeterminado, 80%.
Filtro de notas, ya_min_version 19.4.1, max_install_date 28 de marzo de 2019. Esta es una fecha anterior a la fecha de lanzamiento. En consecuencia, esta es una configuración con una lista de usuarios que recibieron la versión 19.4.1 después de la actualización. Usaron la aplicación y ahora usan la nueva versión.
¿Por qué se necesitan grupos de funciones y control? En el análisis que mostré en la primera diapositiva, comparamos el grupo de control y el grupo de características. Deben tener el mismo poder para poder comparar las métricas de sus productos.
Por lo tanto, comparamos el control y los grupos de características en análisis para diferentes grupos de usuarios, antiguos y nuevos. Si pintamos todo, entonces rodamos la característica en un 100%.

¿Cómo funciona un desarrollador de código con este sistema? Él conoce los nombres de los grupos de características, la fecha en que la característica debe habilitarse y escribe alguna capa de acceso, este es un seudocódigo, que solicita un grupo activo por el nombre del experimento. Puede que no sea. En realidad, todas las configuraciones pueden no ajustarse a las condiciones del dispositivo. Entonces la cadena vacía volverá.
Después de eso, si aparece el nombre del grupo activo, debe habilitar la función; de lo contrario, desactívela. Además, esta función ya se usa en el código, que incluye la funcionalidad en el código del navegador.

Así que vivimos con este sistema de experimentos durante varios años. Todo estaba bien, pero reveló una serie de deficiencias. El primer inconveniente de este enfoque es que es imposible agregar nuevos grupos de experimentos sin corregir el código. Es decir, si es poco probable que el nombre del experimento cambie para una característica, entonces agregar un par más de grupos adicionales, puede ser fácilmente. Pero su código de accesibilidad de funciones no conoce dichos grupos, porque no lo previó de antemano. En consecuencia, debe rodar la versión, experimentar con esta versión, lo cual es un problema. Es decir, es necesario, al cambiar el código, reconstruir y publicar en la App Store.
En segundo lugar, no puede desplegar partes de una característica o dividir una característica en partes después de comenzar el experimento. Es decir, si de repente decidiste que algunas de las características podrían implementarse, y algunas aún quedarían en el experimento, entonces no puedes hacer esto, tenías que pensar de antemano y dividir esta característica en dos, y aceptarlas independientemente en el experimento.
En tercer lugar, no puede configurar una función o comparar configuraciones. En Translator, por ejemplo, hay un parámetro: tiempo de espera para la API de Translator. Es decir, si no logramos traducir en unos pocos milisegundos, entonces decimos que, intente nuevamente, un error, sin suerte.
Es imposible establecer este tiempo de espera en el experimento, porque necesitamos arreglar los grupos e inmediatamente por adelantado, tengamos los siguientes grupos por adelantado: enabled_with_300_ms, enabled_with_600_ms en cuyos nombres está codificado el valor del parámetro. Pero es imposible establecer el parámetro numéricamente de alguna manera. Si no lo hemos pensado antes, entonces ya no podemos comparar varias configuraciones.
Cuarto, los analistas y desarrolladores se ven obligados a acordar los nombres de los grupos de antemano. Es decir, para que un desarrollador comience a desarrollar una característica, generalmente comienza, de hecho, con la política de disponibilidad de esta característica. Y necesita saber los nombres de los grupos de características. Y para esto, el analista debe explicar la mecánica del experimento: si dividiremos a los usuarios en nuevos y viejos o si todos los usuarios estarán en el mismo grupo sin división.
O podría ser un experimento inverso. Por ejemplo, podemos considerar de inmediato que la función está habilitada, pero podemos desactivarla. Esto no es muy interesante para el analista, porque la función no está lista. Él determinará la mecánica del experimento cuando esté listo. Pero el desarrollador necesita de antemano los nombres de los grupos y la mecánica del experimento, de lo contrario tendrá que realizar cambios constantemente en el código.
Consultamos y decidimos que era suficiente para aguantar. Así nació el proyecto Make Experiments Great Again.

La idea clave de este proyecto es la siguiente. Si antes estábamos unidos a un código, un código, a los nombres de los grupos activos que el analista nos pasó, ahora hemos agregado dos entidades adicionales. Esta característica (Característica) y parámetro de característica (FeatureParam). Y así, el programador inventa características y parámetros de características de forma independiente, eligiendo identificadores para ellos, eligiendo valores predeterminados para ellos y programando la disponibilidad de características para ellos.
Después de eso, pasa estos identificadores al analista, y el analista, pensando en la mecánica de los experimentos, los especifica de una manera especial en los grupos de experimentos utilizando la etiqueta feature_association. Si este grupo se activa, recuerde habilitar o deshabilitar la función con el identificador tal y tal, y establezca los parámetros con dichos identificadores.

¿Cómo se ve en el archivo de configuración del experimento? Aquí nos fijamos en el grupo de experimentos. El nombre está habilitado, se agrega una etiqueta opcional feature_association, en esta etiqueta de comando enable_feature o disable_feature, y se agregan identificadores.
También hay un bloque de parámetros, del cual puede haber varios. Aquí también hay un nombre: tiempo de espera y se agrega el valor que debe establecerse.

¿Cómo se ve esto desde el código? El programador declara las entidades de las clases Feature y FeatureParam. Y escribe valores de estas primitivas en la capa de acceso a características. Luego, pasa este identificador al analista, y ya en el archivo de configuración establece los identificadores en el bloque del grupo de experimento utilizando la etiqueta feature_association. Tan pronto como el grupo de experimentos se active, los valores de las características y parámetros con estos identificadores en el código se establecen desde el archivo. Si no hay parámetros y características en el grupo, se utilizan los valores predeterminados, que se indican en el código.
Parecería que esto nos dio? Primero, al agregar un nuevo grupo, el analista no necesita pedirle al programador que agregue un nuevo grupo de características al código, porque la capa de acceso a datos opera con identificadores que no cambian cuando se agrega un nuevo grupo al sistema de experimento.
-, , , , . , , , , .
. , , translator, , , . TranslateServiceAPITimeout, , timeout API . , , , , : 300 600.
. . (FeatureParam).
, , , . , , . , , . . ?

, : Feature FeatureParam. Feature FeatureParam . , Feature FeatureParam, , . . - , , .
-, Feature&FeatureParam. , «», , , . FeatureParam , , API — 300 600 ?
. . - , . public beta, . , .
, : .

? , , .
: . URL, , .
: browser://version — show-variations-cmd. : cheat-, . : .
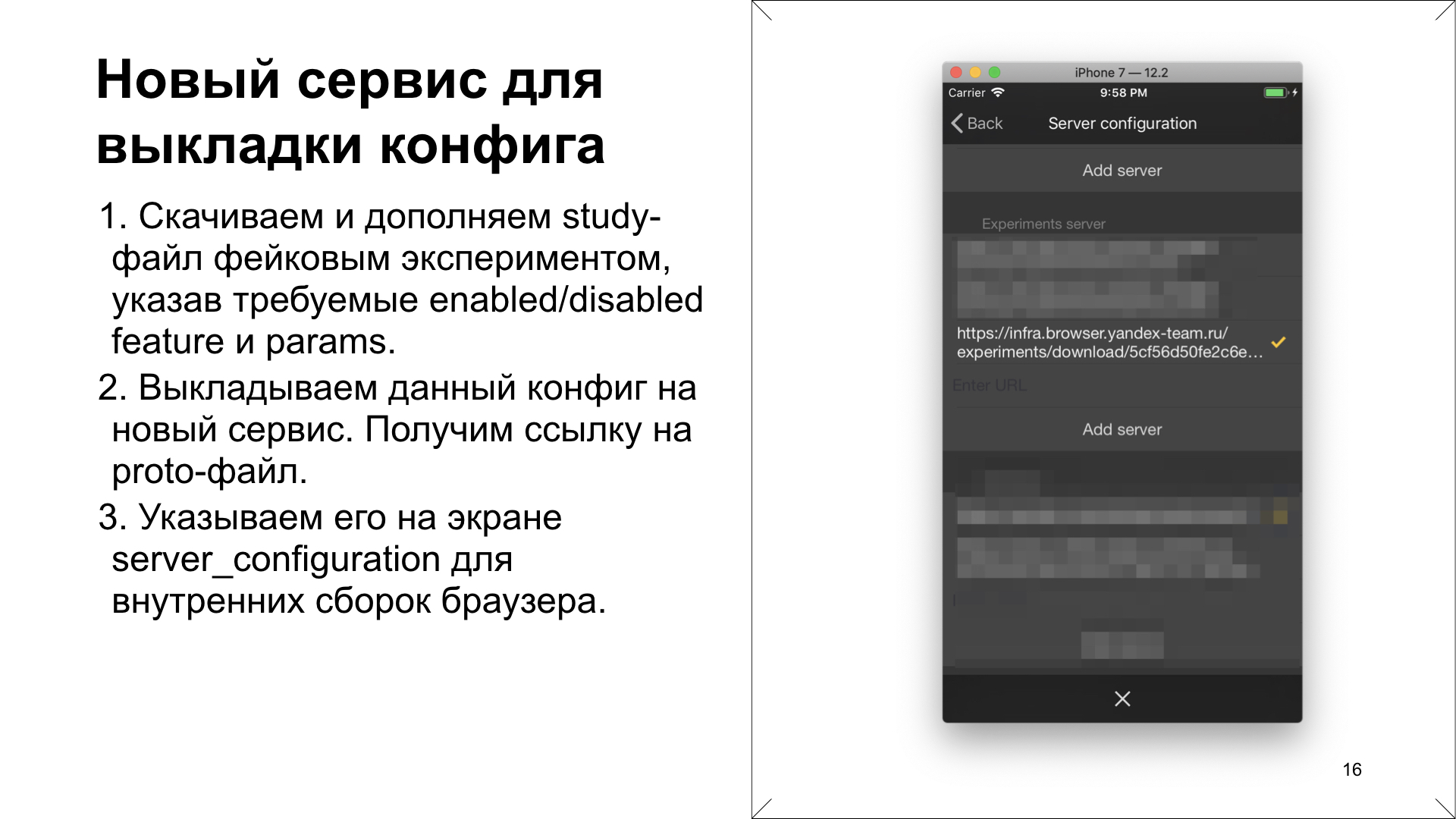
. , . proto- - , study-, . , . Feature&FeatureParam, . , , . , , Feature&FeatureParam .
. proto- . . , . , , .

El segundo Feature&FeatureParam? Chromium, . Chromium browser://version, show-variations-cmd.
: enabled-features, force-fieldtrials force-fieldtrials-params, . , . ? , . , Feature1 trial1. Feature2 trial2. Feature3 .
trial1 group1. trial2 group2. force-fieldtrials-params, , trial1 group1, p1 v1, p2 v2. trial2 group2, p3 v3, p4 v4.
, . Chromium, iOS. , .
. --force-fieldtrials=translator/enabled_new/ enabled_new translator.
--force-fieldtrial-params==translator.enablew_new:timeout/5000, translator enabled_new, , , translator, enabled_new timeout, 5 000 .
--enabled-features=TranslateServiceAPITimeout<translator , - translator translator , , , TranslateServiceAPITimeout. , , , , .

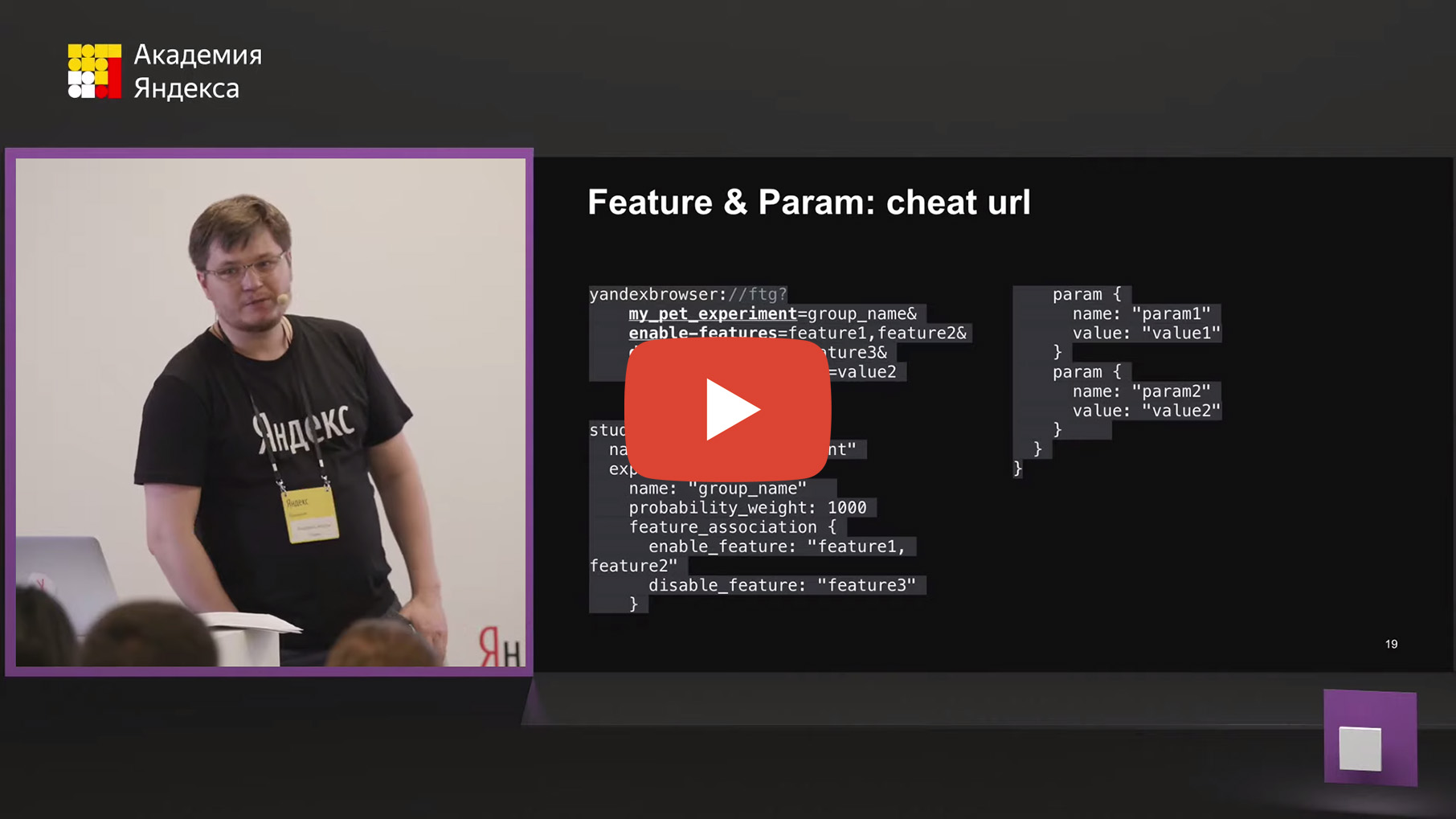
(cheat urls). , , , , , , . . . .
yandexbrowser:// (.), , . . my_pet_experiment=group_name. , enable-features=, , disable-features=, . , &.
(cheat url), . , , , . , , . filter, my_pet_experiment , . 1000, feature_association, , .
, . , , . , — my_pet_experiment — , , . , , study .
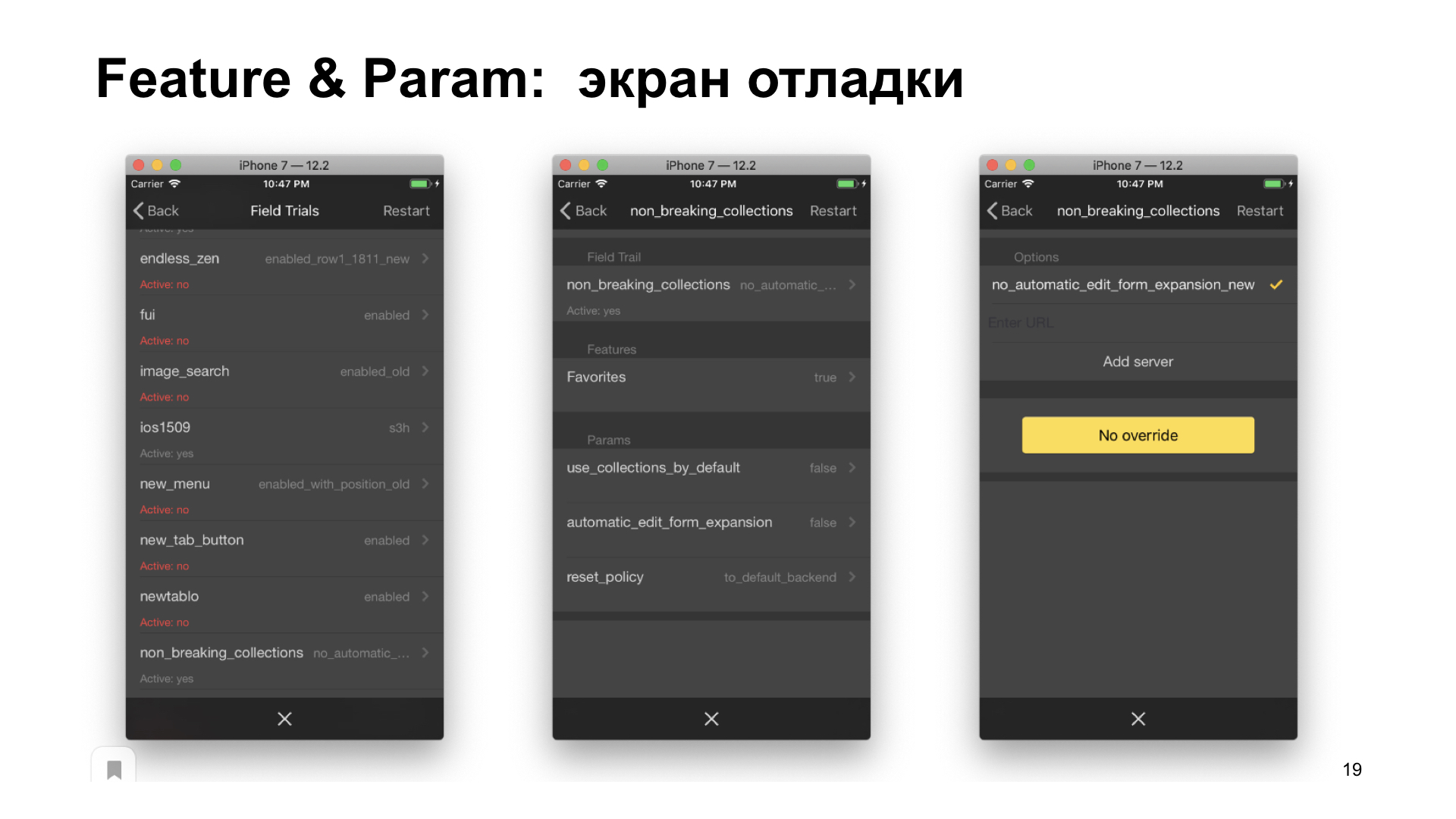
, . — , . . , .
, .

, , , , . , . , .
. . , , ? , . , ?
. .

, . , , UUID, application Identifier, . . hash .
? ? , , UUID, . ? , , . . ? hash hash , . ,
Google, An Efficient Low-Entropy Provider.
, — UUID, , , . , , Chromium.
, , ? ? :
- : , -. .
- . , , , .
- Probable Debe tener mecanismos que le permitan redefinir los valores de grupos, características, parámetros u otras entidades que necesite.
- Uno donde se utilizan diferentes primitivas para análisis y programación.
- Ampliable Debería poder ver cómo funciona y adaptarlo a sus necesidades (consulte el servicio de variación de Chromium ).
El sistema Chromium, que estamos ampliando en Yandex.Browser para iOS, tiene tales criterios. Realice sus experimentos, analícelos y mejore las aplicaciones. Gracias