Foto de Dugan Arnett en Boston Globe
¿Sigues buscando un piso nuevo? ¿Listo para hacer el último intento? Si es así, sígueme y te mostraré cómo llegar a la línea de meta.
Breve introducción y referencias
Es la tercera parte del ciclo dirigida a explicar cómo podría encontrar el piso óptimo en el mercado inmobiliario. En pocas palabras, la idea principal: encontrar la mejor oferta entre los apartamentos en Ekaterimburgo, donde vivía antes. Pero creo que la misma idea puede considerarse en el contexto de otra ciudad.
Si no ha leído las partes anteriores, sería una buena idea leerlas Parte1 y Parte2 .
Además, puede encontrar portátiles Ipython allí .
Esta parte tenía que ser mucho más corta que las anteriores, pero el diablo está en los detalles.
Consecuencias
Como resultado de todas las acciones, obtuvimos un modelo ML (Random Forest) que funciona bastante bien. No es tan bueno como esperábamos (el puntaje es superior al 87%), pero para datos reales, es lo suficientemente bueno. Y ... déjame ser sincero, que los pensamientos sobre el resultado me afectaron de manera extraña. Quería más puntaje, la brecha entre el resultado esperado y la predicción real era menor al 3%. El optimismo mezclado con la codicia se me ha subido a la cabeza

Quiero mas oro precisión
Es ampliamente conocido, si desea mejorar algo, probablemente habrá enfoques opuestos. Por lo general, parece una elección entre:
- Evolución vs revolución
- Cantidad vs calidad
- Extenso vs intensivo
Y debido a la falta de voluntad para cambiar de caballo a mitad de camino, decidí usar RF (Random Forest) con algunas nuevas características.
Parecía una idea, "solo necesitamos más funciones" para mejorar la puntuación. Al menos eso es lo que pensaba.
Per aspera ad astra (a través de las dificultades para las estrellas)
Tratemos de pensar en las características relacionadas, que podrían influir en el precio de un piso. Hay características de piso como balcón o edad de la casa y características relacionadas con la geografía, como la distancia a la estación de metro / autobús más cercana. ¿Qué podría ser el próximo para el mismo enfoque con RF?
Idea # 1. Distancia al centro
Podríamos reutilizar longitud y latitud (coordenadas planas). Basándonos en esta información, podríamos contar la distancia al centro de la ciudad. La misma idea se utilizó para los distritos, cuanto más lejos estuviéramos del centro, más barato debería ser. Y adivina qué ... ¡funciona! No es un gran crecimiento ( + 1% del puntaje), pero es mejor que nada.
Solo hay un problema, la misma idea no tiene sentido para los distritos que están muy lejos. Si viviste fuera de una ciudad, podrías saber que hay otras reglas para el precio.
No será fácil de interpretar si extrapolamos ese enfoque.
Idea # 2. Cerca del metro
El metro tiene una influencia significativa en el precio. Especialmente cuando se coloca en una zona de poca distancia. Pero el significado de "a poca distancia" no está claro. Cada persona puede interpretar ese parámetro de diferentes maneras. Podría establecer el límite manualmente, pero un aumento de la puntuación no sería superior al 0.2%
Al mismo tiempo, no funciona con flat desde la idea anterior. No hay metro cerca.
Idea # 3. Racionalidad y equilibrio del mercado.
El equilibrio del mercado es una combinación de demanda y oferta. Adam Smith habló sobre eso. Por supuesto, el mercado puede ser exagerado. Pero en general, esta idea funciona bien. Al menos para casas que en proceso de construcción.
En otras palabras: cuantos más competidores tenga, menos probabilidades hay de que la gente compre su piso (si todo lo demás es igual). Y esto produce una suposición: "si a mi alrededor se colocan otros pisos, necesito disminuir el precio para obtener más compradores".
Y suena como una conclusión bastante lógica, ¿no?
Entonces conté pisos SIMILARES cerca de cada uno de ellos, en la misma casa y dentro de un radio de 200 metros. Las medidas fueron hechas para la fecha de venta. ¿Qué resultado esperarías tomar? Solo 0.1% en validación cruzada. Triste pero cierto.
Repensando
Dejar de fumar es ... a veces dar un paso hacia atrás para dar dos pasos hacia adelante.
- una persona sabia desconocida
De acuerdo, un ataque frontal no funciona. Consideremos esta situación desde otro ángulo.
Supongamos que usted es una persona que quiere comprar un piso cerca del río lejos de la ruidosa ciudad. Tiene tres variantes de publicidad que son similares entre sí y tienen el mismo precio (más o menos). Las métricas formales que describen plano no le dan nada sobre el medio ambiente, solo son métricas en una pantalla. Pero hay algo importante.
Una descripción de un piso es una excelente oportunidad.
Una descripción plana podría proporcionar todo lo que necesita. Podría contarle una historia sobre un piso, sobre vecinos y oportunidades increíbles relacionadas con ese lugar de vida específico. Y en algún momento una descripción podría tener más sentido que los números aburridos.
Pero en la vida real es ligeramente diferente de nuestras expectativas. Déjame mostrarte qué funcionará / no funcionará y por qué.
¿Qué no funcionará y por qué?
Expectativas : "¡Vaya! Puedo intentar clasificar el texto y encontrar planos" buenos "y" malos ". Usaré el mismo método que usualmente se usa para analizar los sentimientos".
Realidad : "No, no lo harás. La gente no escribe nada malo contra su apartamento. Puede pasar por alto una situación real o mentir"
Expectativas : "Está bien. Entonces puedo intentar encontrar patrones y encontrar el público objetivo para un piso. Por ejemplo, podrían ser personas mayores o estudiantes".
Realidad : "No, no lo harás. A veces un anuncio tiene una mención sobre diferentes edades y grupos sociales, es solo marketing"
Lo que probablemente funcionaría y por qué
Algunas palabras clave : hay palabras que señalan cosas o momentos específicos relacionados con el plano. Por ejemplo, cuando se trata de un estudio, el precio sería más bajo. En general, los verbos son inútiles, pero los sustantivos y los adverbios pueden dar más contexto.
La fuente alternativa de información : usar la descripción para llenar valores vacíos o NaN más correctos. A veces, la descripción contiene más información que las características formales de la publicidad.
Sospecho que se basa en la pereza humana para llenar campos no obligatorios como "balcón". Poner todo en la descripción parece una idea más preferible
Me salto la descripción del proceso típico de tokenización / lematización / derivación. Además, creo que hay autores capaces de describirlo mejor que yo.
Aunque creo que debería mencionarse el conjunto de herramientas utilizado para extraer funciones. En pocas palabras, parece.

separación-> coincidencia por parte del discurso
Después del procesamiento previo del texto publicitario, obtuve un conjunto de palabras rusas como estas.

El texto original se coloca https://pastebin.com/Pxh8zVe3
Traté de usar el enfoque de Word2Vec, pero no había un diccionario especial para pisos y anuncios, por lo que la imagen general parecía extraña
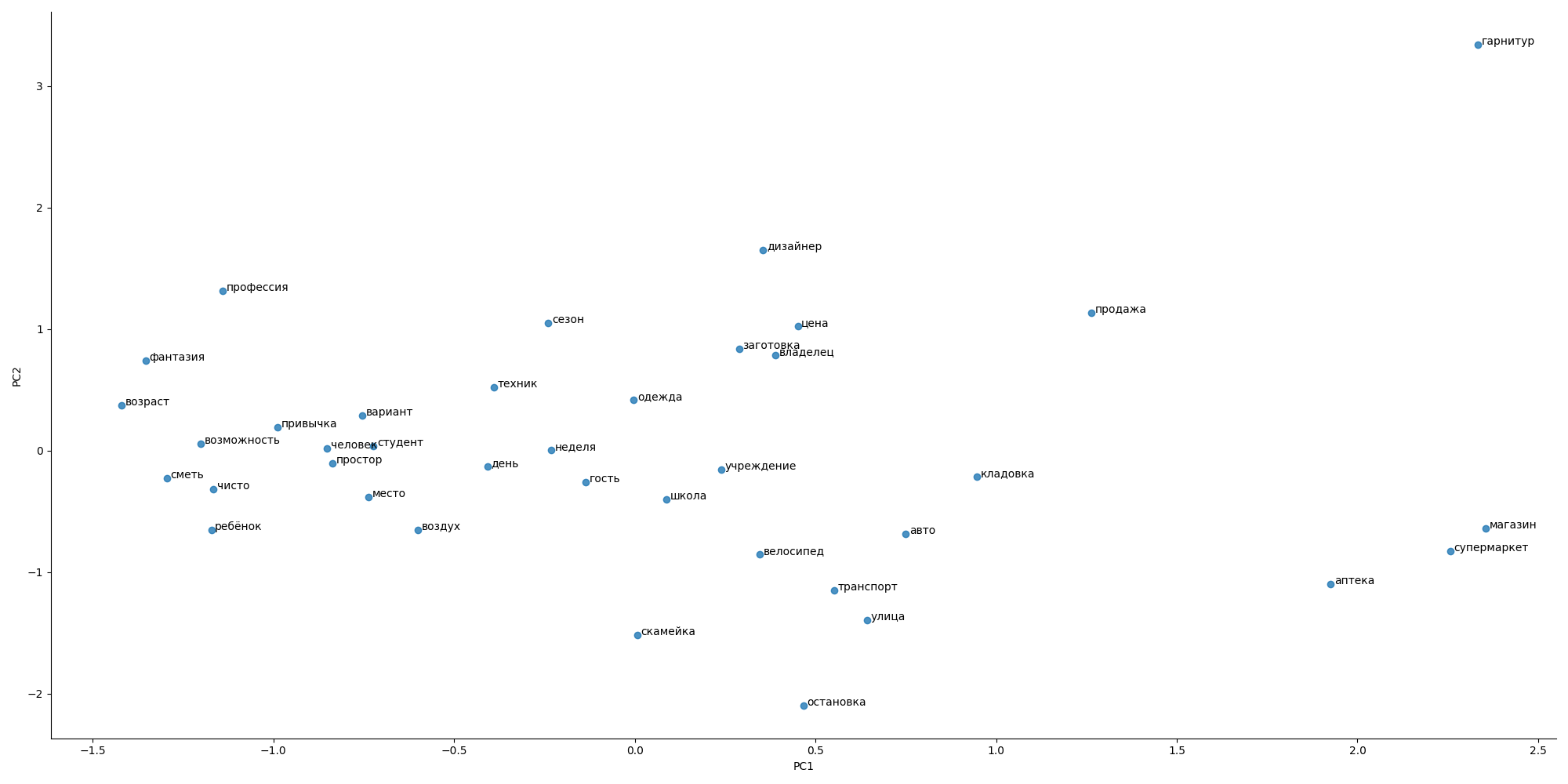
la distancia entre palabras no se ajusta a las expectativas
Por lo tanto, lo mantuve lo más simple posible y decidí hacer varias columnas nuevas para el conjunto de datos
Un poco menos de conversación, un poco más de acción.
Es hora de ensuciarse las manos y hacer algunas cosas prácticas. Descubre nuevas características. Varios factores importantes fueron separados por una influencia en el precio.
impacto positivo
- muebles : a veces las personas pueden dejar una cama, una lavadora, etc.
- lujo - pisos con cosas lujosas como jacuzzi o un interior exclusivo
- control de video : hace que las personas se sientan seguras, con frecuencia lo considera una ventaja
impacto negativo
- dormitorio : sí, a veces es un piso en un dormitorio. No tan popular, pero significativamente más barato que un piso promedio
- prisa : cuando las personas se apresuran a vender su piso, generalmente están listas para bajar el precio.
- estudio , como dije antes, son más baratos que sus análogos de pisos.
Vamos a recogerlos en algo universal.
df3 = pd.read_csv('flats3.csv') positive_impact = ['', 'luxury',''] negative_impact = ['studio', 'rush','dorm'] geo_features = ['metro','num_of_stops_1km','num_of_shops_1km','num_of_kindergarden_1km', 'num_of_medical_1km','center_distance'] flat_features=['total_area', 'repair','balcony_y', 'walls_y','district_y', 'age_y'] competitors_features = ['distance_200m', 'same_house'] cols = ['cost'] cols+=flat_features cols+=geo_features cols+=competitors_features cols+=positive_impact cols+=negative_impact df3 = df3[cols]
impacto general
Es solo una combinación de características negativas y positivas. Inicialmente, para cada piso, es igual a 0. Por ejemplo, un estudio con control de video seguirá teniendo un impacto general igual a 0 ( 1 [positivo] –1 [negativo] = 0 )
df3['impact'] = 0 for i, row in df3.iterrows(): impact = 0 for positive in positive_impact: if row[positive]: impact+=1 for negative in negative_impact: if row[negative]: impact-=1 df3.at[i, 'impact'] = impact
De acuerdo, tenemos datos, nuevas características y un objetivo anterior con un 10% de error medio para la predicción. Haga una operación típica como lo hicimos antes
y = df3.cost X = df3.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Enfoque antiguo (amplio crecimiento de características)
Haremos un nuevo modelo basado en viejas ideas.
data = [] max_features = int(X.shape[1]/2) for x in range(1,20): regressor = RandomForestRegressor(verbose=0, n_estimators=128, max_features=max_features, max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score - {max_result.score}\nDepth {max_result.max_depth} ')
Y el resultado fue un poco ... inesperado.
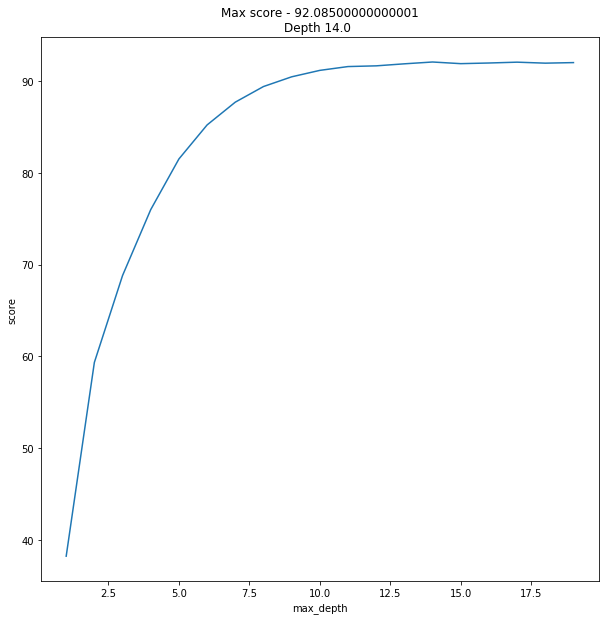
92% es un resultado abrumador. Quiero decir, decir que me sorprendió sería quedarse corto.
¿Pero por qué funcionó tan bien? Echemos un vistazo a las nuevas características.
regressor = RandomForestRegressor(random_state=42, max_depth=max_result.max_depth, n_estimators=128, max_features=max_features) rf3 = regressor.fit(X_train, y_train) feat_importances = pd.Series(rf3.feature_importances_, index=X.columns) feat_importances.nlargest(X.shape[1]).plot(kind='barh')
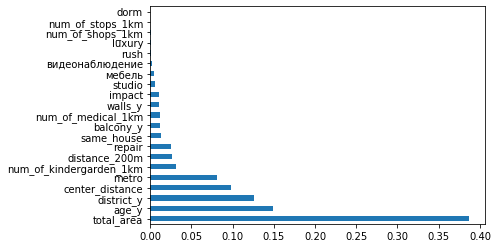
Importancia de todas las funciones para nuestro modelo.
La importancia no brinda información sobre la contribución de las características (esa es una historia diferente), solo muestra cómo el modelo activo usa una u otra característica. Pero para la situación actual, parece informativo. Algunas de las nuevas características son más importantes que las anteriores, otras casi inútiles.
Nuevo enfoque (trabajo intensivo con datos)
Bueno ... se cruza la línea de meta, se logra el resultado. ¿Podría ser mejor?
Respuesta corta: "Sí, podría"
- Primero, podríamos reducir la profundidad de un árbol. También llevará a un menor tiempo para el entrenamiento y la predicción.
- En segundo lugar, podríamos aumentar un poco el puntaje de predicción.
Para ambos momentos usaremos XGBoost . A veces las personas prefieren usar otros potenciadores como LightGBM o CatBoost , pero mi humilde opinión: el primero es lo suficientemente bueno cuando tienes muchos datos, el segundo es mejor si trabajas con variables categóricas. Y como beneficio adicional, XGBoost parece más rápido
from xgboost import XGBRegressor,plot_importance data = [] for x in range(3,10): regressor = XGBRegressor(verbose=0, reg_lambda=10, n_estimators=1000, objective='reg:squarederror', max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score-{max_result.score}\nDepth {max_result.max_depth} ')

El resultado es mejor que el anterior.
Por supuesto, no es la gran diferencia entre Random Forest y XGBoost. Y cada uno de ellos podría usarse como una buena herramienta para resolver nuestro problema con la predicción. Depende de usted.
Conclusión
¿Se logra el resultado? Definitivamente si.
La solución está disponible allí y se puede usar cualquiera de forma gratuita. Si está interesado en la evaluación de un apartamento utilizando este enfoque, no dude y contácteme.
Como prototipo lo colocó allí
Gracias por leer! .