
Hola Habr Recientemente hubo una competencia de Tinkoff y McKinsey. La competencia se llevó a cabo en dos etapas: la primera: calificación, en formato kaggle, es decir, enviar predicciones: obtenga una evaluación de la calidad de la predicción; El ganador es el que tiene la mejor puntuación. El segundo es el hackathon in situ en Moscú, que alberga a los 20 mejores equipos de la primera etapa. En este artículo hablaré sobre la etapa de calificación, donde logré tomar el primer lugar y ganar el MacBook. El equipo en la clasificación se llamaba "los hijos de Lesha".
La competencia se realizó del 19 de septiembre al 12 de octubre. Empecé a resolver exactamente una semana antes del final y decidí casi a tiempo completo.
Breve descripción de la competencia:
En el verano, aparecieron historias en la aplicación bancaria Tinkoff (como en Instagram). En la historia, puede reaccionar como, no me gusta, saltar o ver hasta el final. La tarea es predecir la reacción del usuario a la historia.
La competencia es principalmente tabular, pero las historias en sí tienen texto e imágenes.
Plan de historia

Métrica
El pronóstico de reacción puede tomar un valor de -1 a 1 inclusive: cuanto más se acerca a 1, mayor es la probabilidad de obtener un me gusta. Y con un valor de -1, es mejor eliminar esta historia de los ojos del usuario.
Para verificar la precisión de las soluciones, se utiliza una fórmula, normalizada al máximo resultado posible:
\ begin {array} {l} {\ text {weight (event)} = \ left \ {\ begin {array} {ll} {- 10} & {\ text {dislike}} \\ {-0.1} & {\ text {skip}} \\ {0.1} & {\ text {view}} \\ {0.5} & {\ text {like}} \ end {array} \ right.} \\ [15pt] {\ text {Métrica} \ left (y _ {\ text {pred}} \ right) = \ sum_ {i = 1} ^ {n} \ left (\ text {weight} \ left (\ text {event} _ {i} \ right) \ cdot y _ {\ text {pred,} i} \ right)} \ end {array}
Qué datos hay:
- Información básica del usuario
- Transacciones de usuario
- Información sobre la historia (json desde la cual puedes construirla)
- Historia de las reacciones de los usuarios a las historias.
A continuación, hablaré en detalle sobre cada dato, cómo lo procesé y qué características (en adelante denominadas características) extraje.

lo que es originalmente:
- ID de usuario
- Productos bancarios anónimos que el usuario ha abierto (OPN), utiliza (UTL) o cierra (CLS)
- sexo, edad binarizada, estado civil, primera entrada en la solicitud
- job_title: lo que la gente escribe sobre sí misma
- job_position_cd - título del trabajo de una persona, como una de las 22 categorías
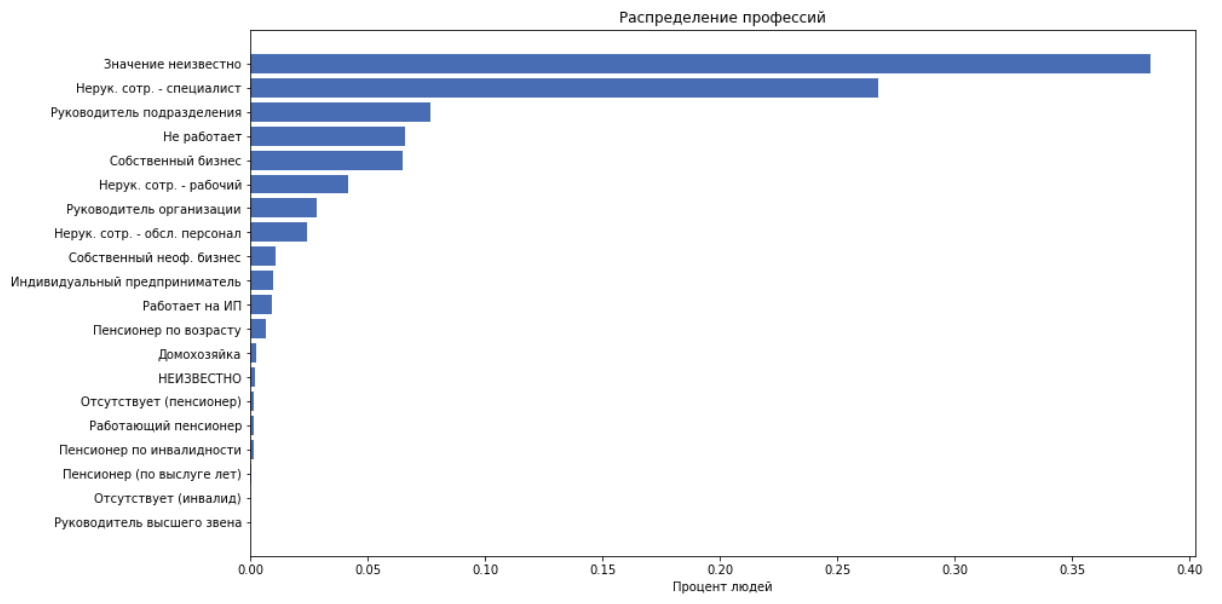
como características usamos todo lo anterior excepto job_title, porque suponemos que job_position_cd normalmente describe la posición de una persona.
Transacciones

lo que es originalmente:
- ID de usuario
- día, mes de transacción
- monto de la transacción (binario en incrementos de 250)
- merchant_id: identificación bancaria interna de la caja registradora. Además no se utiliza.
- merchant_mcc
MCC: código de categoría de comerciante. Este es el código de servicio estandarizado proporcionado por el destinatario. Esta información está abierta, aquí hay una transcripción . Estos códigos se pueden dividir convenientemente en categorías, por ejemplo: entretenimiento, hoteles, etc.
Para cada customer_id, comparamos las siguientes características:
- calcular la cantidad de gastos, verificación promedio, desviación estándar
- cantidad de transacciones
- Dividimos los códigos mcc en 20 categorías, calculamos cuántas personas gastaron dinero en esta categoría. Obtén 20 funciones
- obtendremos otras 20 funciones dividiendo los gastos en la categoría por la cantidad de gastos. Es decir Obtenga el porcentaje de dinero gastado en la categoría.
Cuentos
En total, tenemos 959 historias.
lo que es originalmente:
json se ve así:

Este es un árbol de elementos en el que cada elemento se describe mediante claves: ['guid', 'type', 'description', 'properties', 'content']. El 'contenido' contiene una lista de hijos. La historia consta de páginas. El fondo, el texto y las imágenes aparecen en la página. No teníamos un constructor de historias, y dibujar todo esto es bastante difícil y no un hecho, lo que será de gran ayuda en el futuro.
Los habituales extraen todo el texto y el tamaño de fuente correspondiente. Extraemos las siguientes características:
- número de páginas, enlaces, elementos totales
- tamaño de fuente de texto promedio
- cantidad de elementos de texto
- "volumen de texto" es una heurística para considerar cuidadosamente la longitud del texto dependiendo del tamaño de la fuente.
Código de recuento de volumendef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Ahora tomemos todo el texto, usando dostoievski definimos la semántica del texto: ['neutral', 'negativo', 'omitir', 'discurso', 'positivo']. Y agregue esto como 5 características
Reacciones

lo que es originalmente:
- ID de usuario e historial
- el tiempo
- reacción
Procesamos el tiempo y agregamos características como características:
- dia de la semana
- hora minuto
A continuación, se agregará un grupo de características basadas en los datos de las reacciones, pero por ahora, vamos a luchar con este arsenal de características para hacer una línea de base.
El mejor enfoque que ha utilizado toda la parte superior es el siguiente: reducimos el problema a una clasificación multiclase, es decir, predecir la probabilidad de cada reacción. Consideramos la expectativa de una evaluación para esta historia :
Binarizar :
- nuestra respuesta para el objeto que puede tomar valor
Modelo
Desde el principio hasta el final, usé CatBoost. Esto se debe al hecho de que CatBoost crea estadísticas útiles para funciones categóricas. Y las estadísticas sobre el usuario, cuánto se inclina a qué reacciones, y las estadísticas sobre el historial, cómo no reaccionan con mayor frecuencia, son las características más poderosas en esta tarea.
El funcionamiento de CatBoost con características categóricas está bien explicado en la documentación .
TLDR:
- genera múltiples permutaciones de datos
- va en orden y crea una codificación de destino media (mte) en aquellos objetos que ya vio
brevemente sobre mte en nuestro ejemplotomamos el valor del signo, por ejemplo, uno de customer_id, consideramos el porcentaje de casos en que este cliente reaccionó como, disgusto, omitido o visto. Obtenemos 4 números. Reemplazamos customer_id con estos 4 números y los usamos como signos. Hacemos esto para cada customer_id.
Resultado actual
Con las características actuales, con una catbust no optimizada, en la tabla de clasificación pública en ese momento ocupé el 11º lugar con un resultado de 0.31209
Características asesinas
En algún momento, apareció una hipótesis de que la aplicación puede mostrar historias con más frecuencia o menos dependiendo de cómo reaccionó el usuario antes. A continuación, agreguemos características que dirán:
- cuántas veces el usuario vio el historial correspondiente en el pasado / futuro, durante el mes / día / hora / total
- tiempo desde la última vez que se vio la misma historia
- tiempo después del cual el usuario la próxima vez mira la misma historia
- de hecho, el usuario carga varias historias a la vez en un segundo, generalmente alrededor de 5-7. Llame a este conjunto de historias un grupo . Agregué este número de historias en el grupo como una característica, lo que dio un gran aumento en la calidad.
Por supuesto, estas características no se pueden usar en la producción, porque no serán cursi en el momento de la aplicación del modelo, pero en la competencia cualquier medio es bueno.
Entonces, se dice - hecho. Obtuve 0.35657 en la clasificación.
Modelo de optimización
Revisé los parámetros usando la optimización bayesiana
De lo interesante, podemos mencionar el parámetro max_ctr_complexity, que es responsable del número máximo de características categóricas que se pueden combinar. Ejemplo bajo el spoiler.
Extracto de la documentación.Suponga que los objetos en el conjunto de entrenamiento pertenecen a dos características categóricas: el género musical ("rock", "indie") y el estilo musical ("danza", "clásico"). Estas características pueden ocurrir en diferentes combinaciones. CatBoost puede crear una nueva característica que es una combinación de las mencionadas ("dance rock", "rock clásico", "dance indie" o "indie clásico").
Observaciones interesantes
CatBoost puede ser entrenado en la GPU, esto acelera significativamente el aprendizaje, pero también introduce muchas restricciones, especialmente con respecto a las características categóricas. En esta tarea, el entrenamiento en la GPU dio un resultado mucho peor que en la CPU.
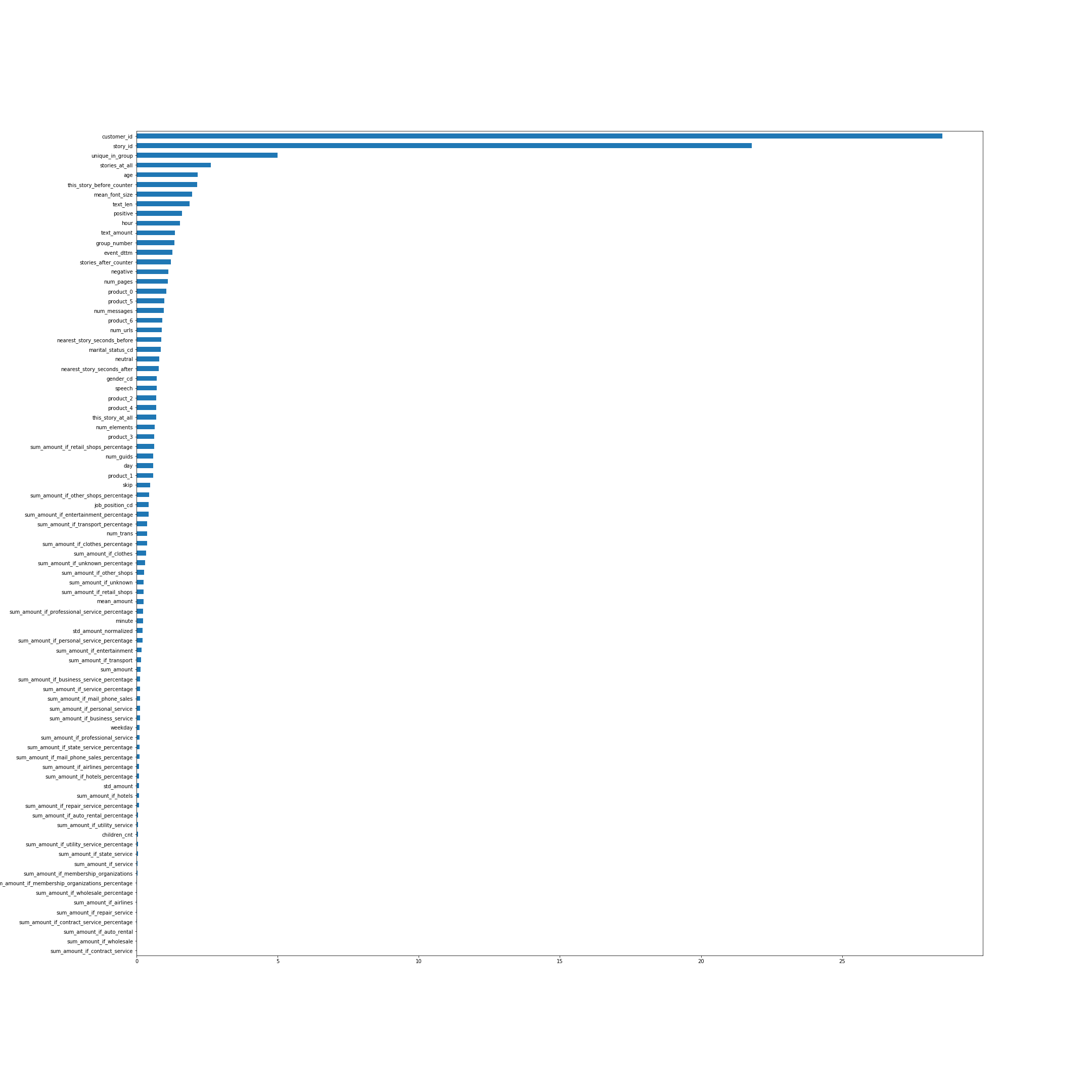
La importancia de las características según CatBoost. En muchos sentidos, los nombres de las características hablan por sí mismos, pero algunos, no los más obvios desde arriba, explicaré:
- unique_in_group: la cantidad de historias en el grupo. (Dentro del grupo siempre son únicos, justo en el momento en que se creó la función, no lo sabía)
- stories_at_all: la cantidad de historias que una persona vio en el futuro y en el pasado.
- this_story_before_counter: cuántas veces la gente ha visto esta historia antes.
- text_amount: esa heurística con el volumen de texto.
- group_number: número de serie del grupo.
- arest_story_seconds_before / after - esencialmente este es el tiempo hasta que se muestra el siguiente grupo.
Se puede hacer clic en la imagen.
Veamos la distribución de reacciones a lo largo del tiempo:

Es decir en algún momento, la distribución de reacciones varía mucho.
A continuación, quiero obtener alguna confirmación de que la distribución en la prueba es la misma que al final de la muestra de entrenamiento. Enviemos como predicción todos, obtenemos el resultado 0.00237. Predecimos todos los de la última parte del tren, obtenemos aproximadamente 0.009, en la primera parte, aproximadamente -0.22. Por lo tanto, la distribución en la prueba probablemente sea la misma que al final del tren y definitivamente no se parece a la parte principal. Esto da lugar a la hipótesis de que si la distribución se corrige en nuestras predicciones, el resultado en la tabla de clasificación mejorará en gran medida, porque Las distribuciones en el tren y en la prueba son diferentes.
Predicciones de umbral
En el último paso para obtener las predicciones finales, agregue un thrashhold:
En el último modelo, tenía algo sobre el 66% de las unidades, si se binarizaba con un basurero igual a 0. Resultó que, de hecho, una disminución en el número de +1 dio un fuerte aumento en la calidad. Solo se evaluaron las últimas 3 premisas, por lo que envié las predicciones del mejor modelo con diferentes basureros para que el porcentaje más uno fuera aproximadamente 62, 58 y 54.
Como resultado, en una tabla de clasificación pública, mi mejor resultado fue 0.37970 .
Resultados de la competencia
sobre tabla de clasificación pública / privadaComo es habitual en las competencias de aprendizaje automático, cuando envía predicciones al sistema, el resultado solo se evalúa para una parte de la muestra de prueba completa. Por lo general, alrededor del 30%. Los resultados de esta parte se reflejan en la tabla de clasificación pública. Para el resto de la prueba, se evalúa el resultado final, que se muestra después del final de la competencia en una tabla de clasificación privada.
Al final de la competencia en la clasificación pública, la situación era la siguiente:
- 0.382 - HereCould BeYourAdvertising
- 0.379 - Los hijos de Lesha
- 0.372 - Jardineros
- 0.35 - perezoso y akulov
En una tabla de clasificación privada, según la cual se consideraron los resultados finales, tuve suerte y los muchachos, por alguna razón, cayeron del cuarto lugar al cuarto. Aquí está la posición final.
- 0.45807 hijos de Lesha
- 0.45264 Jardineros
- 0.44136 Zhuk
- 0.43704 Aquí podría ser su publicidad
- 0.43474 perezoso y akulov
Lo que no funcionó
- Traté de traducir todo el texto de la historia a un vector usando texto rápido, luego agrupé los vectores y usé el número de grupo como una característica categórica. Esta característica estaba en el top 3 (después de story_id y customer_id) en la importancia de las características de CatBoost, pero por alguna razón era estable y empeoró significativamente el resultado de la validación.
- Gracias a los grupos, se podían encontrar historias relacionadas con la Copa del Mundo y solo estaban presentes en el conjunto de entrenamiento.
Sin embargo, expulsar tales objetos del conjunto de datos no mejoró el resultado. - de forma predeterminada, CatBoost genera permutaciones aleatorias de objetos y considera signos para características categóricas basadas en ellos. Pero podemos decirle al katbust que tenemos tiempo en los datos: has_time = True. Luego irá en orden, sin mezclar el conjunto de datos. En este problema, a pesar del hecho de que tenemos tiempo, el resultado con has_time fue mucho peor.
En el caso general, si hay tiempo, pero no debe tenerse en cuenta al construir la codificación de objetivo media, el modelo utilizará información sobre las respuestas correctas del futuro y puede volver a capacitarse para ello. En este problema, aparentemente, esto no tuvo mucho efecto y fue más importante repasar varias veces en diferentes permutaciones. - Hubo una idea de asignar más peso a los objetos al final del tren, es decir para tener en cuenta más objetos con la distribución correcta de reacciones. Pero tanto en la validación como en la tabla de clasificación pública esto dio un resultado peor.
- Puede tener en cuenta diferentes reacciones con diferentes pesos durante el entrenamiento. Aunque esto no mejoró para mí, ayudó a algunos equipos.
Conclusiones
La competencia resultó ser interesante, ya que reunió muchos componentes, como datos tabulares, textos e imágenes. Había mucho espacio para la investigación, mucho con lo que todavía se podía experimentar. En general, no tuve que aburrirme.
Gracias a los organizadores del concurso!
Todo el código se publica en el github .