Les presento la traducción de otro informe de HaxeUp Sessions 2019 Linz , creo que es un buen complemento al anterior , porque continúa el tema de los cambios en Haxe que ocurrieron en 2019, así como una pequeña charla sobre su futuro.
Un poco sobre el autor del informe: Aurel Bili se reunió con Haxe , participando en varios juegos, y continúa participando en ellos (por ejemplo, aquí está su juego del último Ludum Dare 45 ).

Aurel actualmente está completando estudios en el Imperial College de Londres, lo que implica pasantías obligatorias. La primera pasantía que realizó fue en una oficina remota, cuyo camino tomó mucho tiempo. Por lo tanto, esperaba que la próxima práctica fuera posible de forma remota.

Sucedió que la Fundación Haxe durante mucho tiempo no pudo encontrar un empleado para el puesto de desarrollador del compilador. Aurel decidió probar suerte y envió una carta solicitando trabajo remoto. Tuvo suerte: fue aceptado para una pasantía de seis meses con la oportunidad de trabajar desde Londres.
Al configurar el dispositivo, se acordó la gama de tareas que Aurel abordará (aunque no todo se realizó finalmente).

¿Qué hizo él?
En primer lugar, la documentación , que estaba en un estado triste: se describieron todos los cambios en la sintaxis, las nuevas características del lenguaje y el compilador, se complementaron las secciones sobre cadenas, literales y constantes.
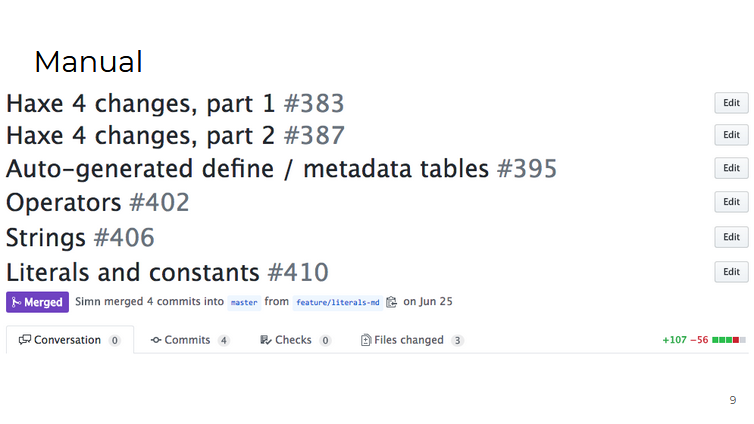
¡Toda la documentación ha sido traducida de LaTeX a Markdown !
En segundo lugar, el formato del código de la biblioteca estándar se llevó a un solo estilo (ya que diferentes personas con diferentes estilos de diseño de código trabajaron en él durante más de 10 años). Por lo tanto, en el repositorio del compilador Haxe, Aurel ocupó el séptimo lugar en el número de líneas de código agregadas :)
En tercer lugar, Aurel también trabajó en la biblioteca y el compilador estándar:
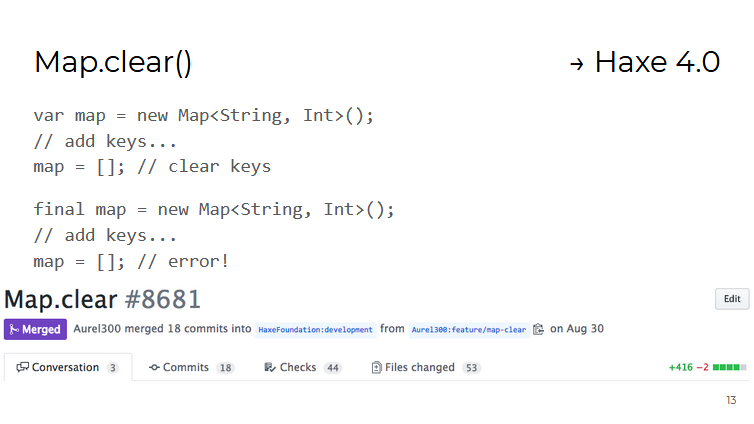
Por ejemplo, el contenedor Map tiene un nuevo método clear() que elimina todos los valores almacenados. Esto se realizó principalmente por la conveniencia de trabajar con contenedores creados como variables final (es decir, no se les puede asignar un nuevo valor, pero se pueden modificar):
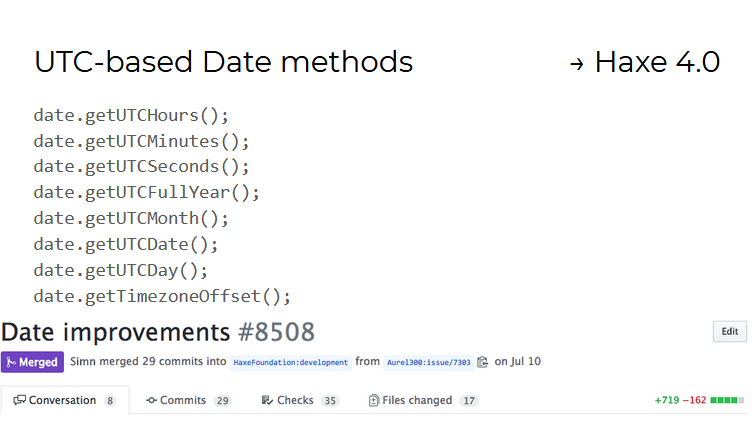
Para los objetos de tipo Date , han aparecido métodos para trabajar con fechas en el formato UTC (hora universal universal). Trabajar en ellos mostró lo difícil que es implementar una única API que funcione igualmente en los 11 idiomas / plataformas compatibles con Haxe.
En el compilador anterior, las definiciones y metaetiquetas se definían en OCaml, pero ahora se describen en el formato JSON, lo que debería simplificar su análisis mediante utilidades externas (por ejemplo, para generar documentación automáticamente):

También puede notar que en proyectos grandes, el servidor de compilación comienza a usar mucha memoria.
Para resolver este problema, Simon Kraevsky y Aurel desarrollaron el formato binario hxb, que se utiliza para serializar el AST escrito. Ahora el servidor de compilación puede cargar el módulo en la memoria, trabajar con él hasta que sea necesario, y luego descargarlo de la memoria a un archivo en formato hxb y liberar la memoria ocupada.

La especificación del formato hxb está disponible en un repositorio separado , y su implementación actual en el compilador (con serializador / deserializador) se encuentra en una rama Haxe separada . El trabajo en esta función aún no se ha completado, y tal vez aparecerá en Haxe 4.1.

El cuarto y principal enfoque del trabajo de Aurel durante la pasantía fue la creación de un nuevo sistema asíncrono API - asys.

La necesidad de su creación se debe al hecho de que la API existente no proporciona formas fáciles de realizar operaciones del sistema de forma asincrónica. Por ejemplo, para trabajar con archivos de forma asincrónica, deberá crear un subproceso separado en el que se realizarán las operaciones necesarias y controlar manualmente su estado. Además, la API actual no tiene todas las funciones para trabajar con sockets UDP, que están en bibliotecas estándar en otros idiomas, no hay soporte para sockets IPC.

Al crear e implementar una nueva API, surgen muchas preguntas:
¿Cómo diseñar una API? ¿Quizás valga la pena tomar uno existente como ejemplo? Después de todo, no queremos crear todo desde cero, porque tomará más tiempo y puede que no sea del gusto del resto del equipo y cause mucho debate.
Y, como ya se mencionó, el problema real para Haxe es la implementación de una única API para todas las plataformas compatibles.

API Node.js. fue elegido como muestra. Está bien pensado, admite las funciones necesarias del sistema y es muy adecuado para crear aplicaciones de servidor.

Pero al mismo tiempo, la API Node.js es una API de Javascript sin tipeo fuerte. Por ejemplo, las funciones del módulo fs para trabajar con el sistema de archivos pueden tomar como rutas cadenas u objetos como Buffer e incluso URL . Y esto no es tan bueno para Haxe.

Node.js, a su vez, usa la biblioteca libuv escrita en C. Trabajar con la API libuv de Haxe directamente no sería tan conveniente: por ejemplo, para cambiar el nombre del archivo de forma asincrónica, necesitaría crear objetos adicionales como uv_loop_t (estructura para administrar evento loop en libuv) y uv_fs_t (estructura para describir una solicitud al sistema de archivos):

Como resultado, las API Node.js y libuv se integraron de la siguiente manera (utilizando el intérprete de macros eval y el método de rename como ejemplo):
- tomaron el método API de Node.js, lo convirtieron a Haxe, tratando de estandarizar los tipos de argumentos y deshacerse de los argumentos que son redundantes para Haxe. Por ejemplo, los argumentos de ruta (de tipo
FilePath ) son resúmenes sobre cadenas:

- luego creó carpetas OCaml para este método:

- OCaml y C vinculados (usando la interfaz CFFI - C Foreign Function):

- y finalmente escribió C-binders para llamar a funciones libuv C desde OCaml:

Del mismo modo, se hizo para HashLink y Neko (por ahora, la API de asys se implementa solo para estas tres plataformas). Como puede suponer, tomó mucho trabajo.
Aurel mostró algunas aplicaciones pequeñas que demuestran cómo funciona la API de asys.
El primer ejemplo es una demostración de lectura asíncrona del contenido de un archivo. Hasta ahora, el código llama explícitamente a los métodos para inicializar libuv ( hl.Uv.init() ) e iniciar el ciclo de aplicación ( hl.Uv.run() ), debido a que el trabajo en la API no se ha completado (pero en el futuro se agregarán automáticamente):
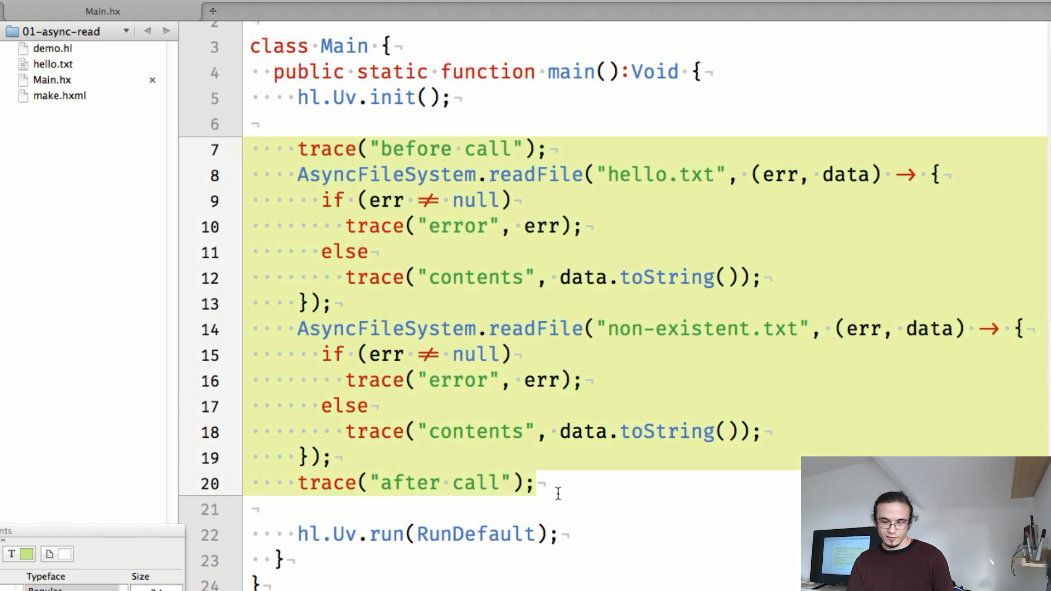
El resultado del código mostrado:
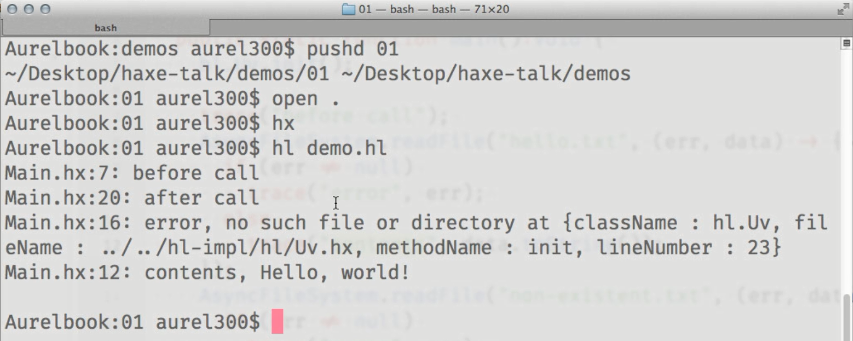
Vemos que los resultados de los AsyncFileSystem.readFile() llamados AsyncFileSystem.readFile() se muestran en la consola después del seguimiento "después de la llamada", que se AsyncFileSystem.readFile() en el código después de intentar leer el contenido de los archivos.
El segundo ejemplo es una demostración de operación asincrónica con direcciones DNS e IP.
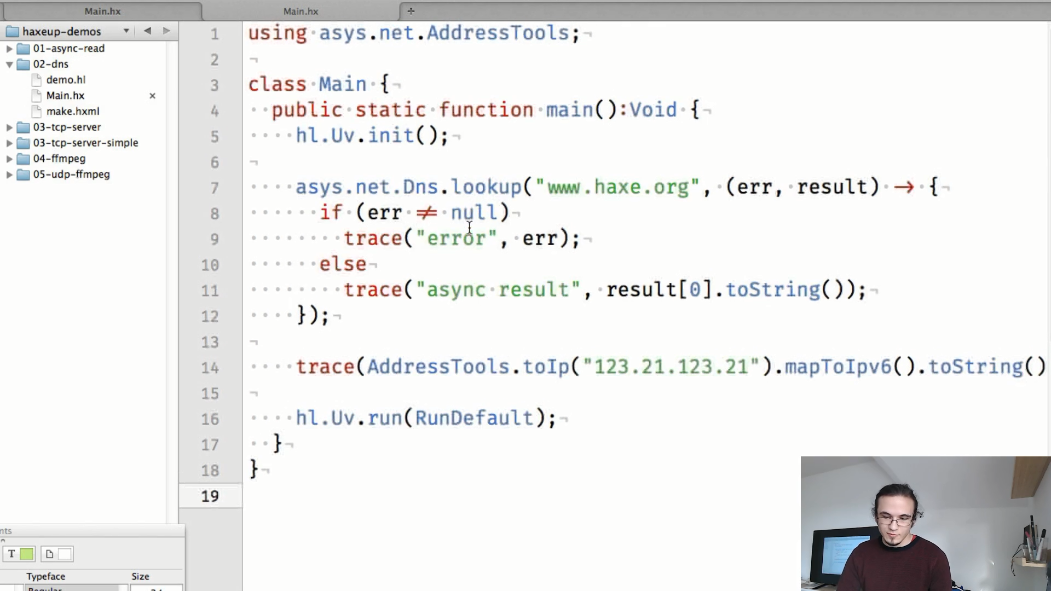
En la nueva API, será mucho más fácil determinar el nombre de host, así como los métodos auxiliares para trabajar con direcciones IP.
El tercer ejemplo es un servidor de eco TCP simple, que requiere solo tres líneas de código para crear:

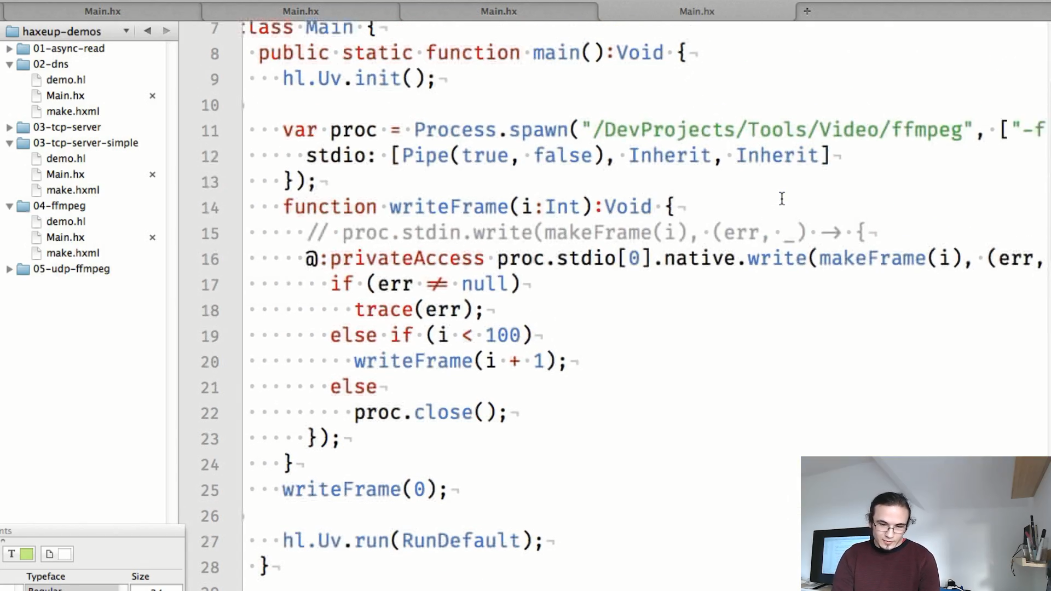
Un cuarto ejemplo es una demostración del intercambio de información entre procesos:
El makeFrame() estático makeFrame() en este ejemplo crea imágenes png separadas:

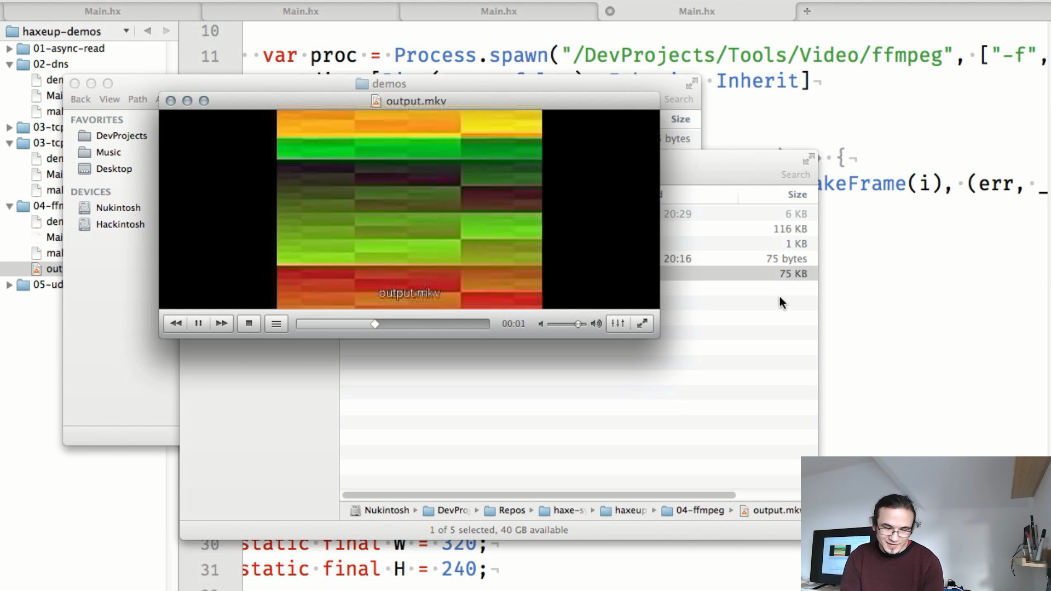
y en el método main , comenzamos el proceso ffmpeg, en el cual transferiremos los marcos generados en makeFrame() :
y la salida será un archivo de video:
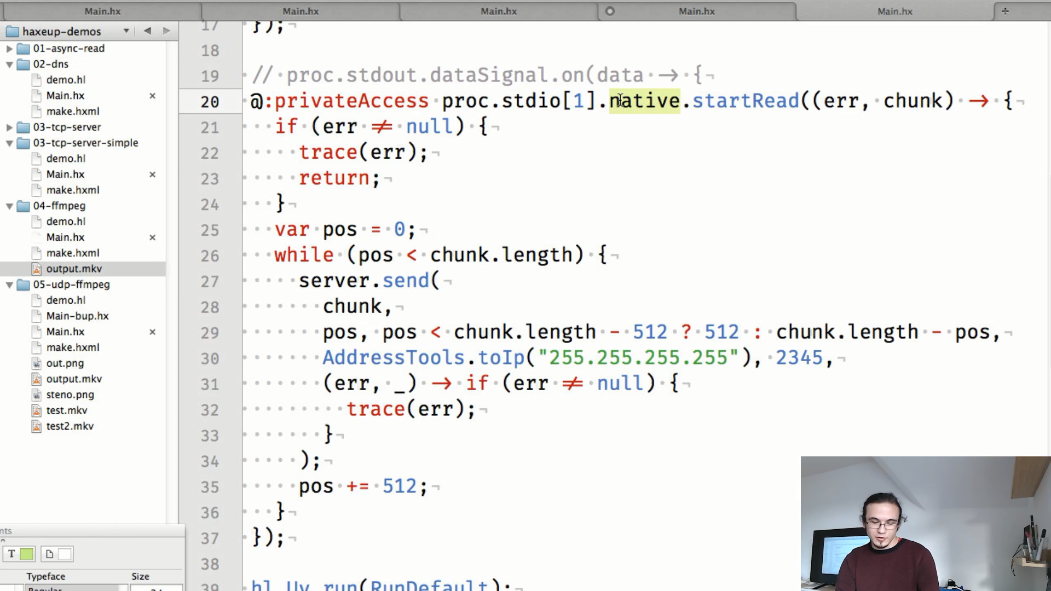
Y el quinto ejemplo es la transmisión de video UDP. Aquí, como en el ejemplo anterior, se inicia el proceso ffmpeg, pero esta vez reproduce el video y envía sus datos al flujo de salida estándar. También se crea un socket UDP que traducirá los datos del proceso ffmpeg.

Y finalmente, dividimos los datos recibidos de ffmpeg en "porciones" más pequeñas y las traducimos al puerto especificado:
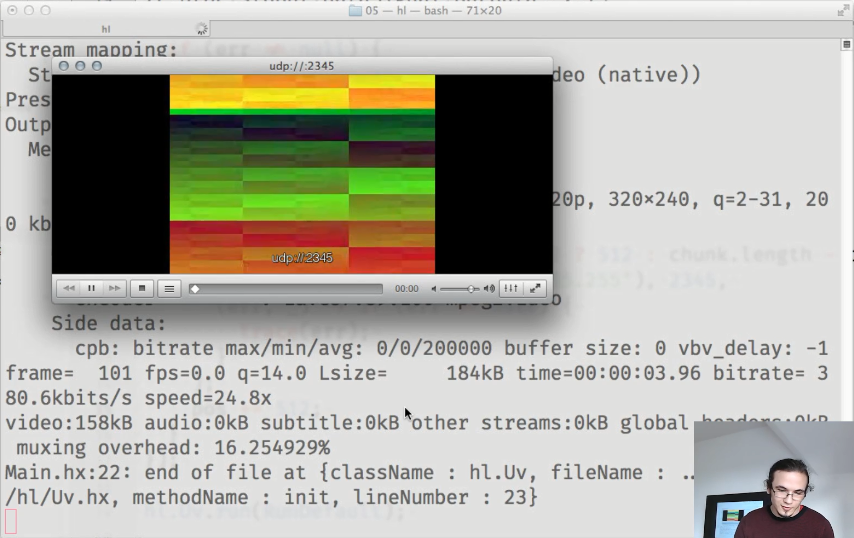
Y como resultado, obtenemos una transmisión de video en funcionamiento:
Resumiendo lo anterior, la nueva API de asys incluye:
- métodos para trabajar con el sistema de archivos, incluidas nuevas funciones que no estaban en la biblioteca estándar (por ejemplo, para cambiar los permisos), así como versiones asincrónicas de todas las funciones disponibles en la biblioteca estándar anterior
- Soporte para operación asincrónica con sockets TCP / UDP / IPC
- métodos para trabajar con DNS (hasta ahora 2 métodos:
lookup e reverse ) - así como métodos para trabajo asincrónico con procesos.

El trabajo en la API de asys aún no se ha completado; actualmente hay algunos problemas con el recolector de basura cuando se trabaja con la biblioteca libuv. La solicitud de extracción con los cambios correspondientes aún no se ha incorporado a la sucursal principal de Haxe, los comentarios al respecto agradecen las opiniones sobre los nombres de los nuevos métodos, sus firmas y documentación.
Como ya se mencionó, el soporte para la API de asys se implementa solo para HashLink, Eval y Neko (en forma de tres solicitudes de extracción separadas). Aurel ya formó un plan sobre cómo agregar soporte para la nueva API para C ++ y Lua. La implementación para otras plataformas requerirá investigación adicional.

Es posible que la API de asys esté disponible en Haxe 4.1 (pero solo en algunas plataformas).
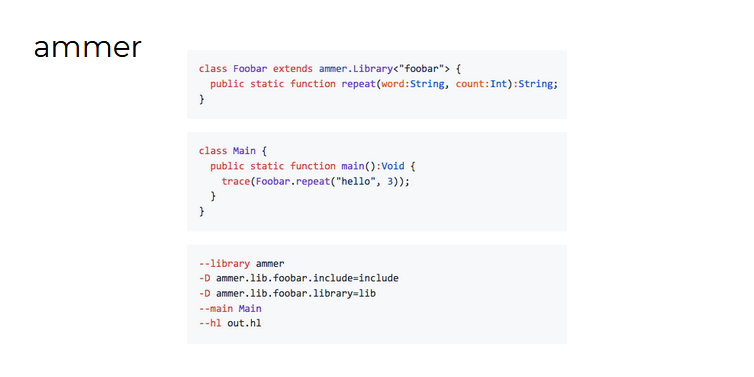
Aurel también habló sobre su proyecto paralelo: la biblioteca ammer (que sin embargo está asociada con su trabajo en la Fundación Haxe).

El objetivo de Ammer es automatizar la creación de carpetas para las bibliotecas C para que puedan usarse tanto en HashLink como en HXCPP (en octubre de 2018, Lars Duse estableció una tarifa por resolver este problema).
¿Por qué fue relevante esta tarea? El hecho es que aunque el proceso de creación de carpetas para HashLink y HXCPP es similar, para cada plataforma tendrá que escribir su propio código de pegamento.
Aurel hizo más o menos lo mismo cuando integró la biblioteca libuv en Haxe: para Eval, Neko y HashLink tuvo que escribir el mismo código que solo difería en detalles (llamadas de función, diferencias en el trabajo de FFI, etc.):

Se requería un trabajo similar en el lado de Haxe para poder llamar a las funciones nativas:

Y la idea de ammer es tomar la versión Haxe de la API, no saturada de información redundante, y hacer que este código funcione de alguna manera para todas las plataformas:

Qué ammer ahora se requiere para usar bibliotecas C externas:
- crear la especificación Haxe para la biblioteca, que es esencialmente externa a la biblioteca utilizada
- escribir código de aplicación
- compilar el proyecto especificando rutas a los archivos de encabezado y archivos de la biblioteca C
- ...
- beneficio
Debajo del capó, ammer hace lo siguiente:
- coincide con los tipos según la plataforma de destino
- genera automáticamente código C para llamar a funciones nativas
- genera un archivo MAKE que se utiliza para crear archivos HDLL y NDLL

Ammer actualmente admite:
- funciones simples
- definido a partir de los archivos de encabezado (en el código Hax, se puede acceder a ellos como constantes)
- punteros
Apoyo planeado:
- devoluciones de llamada (todavía son escasas)
- y estructuras (muy necesarias para trabajar con C-API)

Ahora ammer funciona con C ++, HashLink y Eval. Y Aurel está seguro de que puede agregar soporte para otras plataformas de sistema.

Para demostrar las capacidades de ammer, Aurel mostró una pequeña aplicación que ejecuta el intérprete Lua:
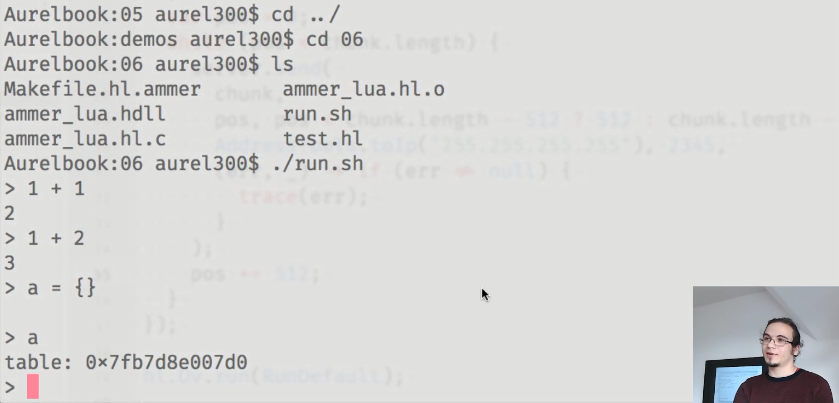
Los aglutinantes utilizados son los siguientes:
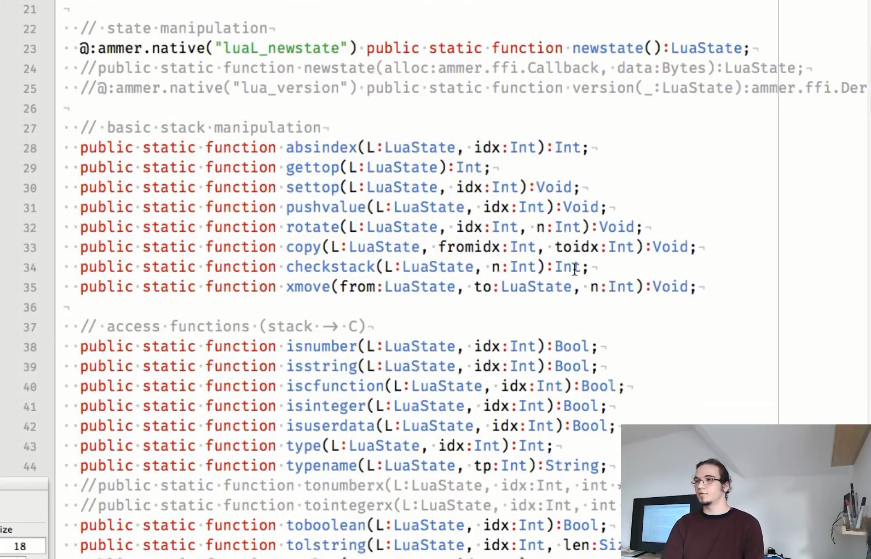
Como puede ver, algunos métodos están comentados, porque usan devoluciones de llamada, cuyo soporte aún no se ha realizado, pero Aurel espera que pueda solucionarlo pronto.

Entonces, ¿qué ammer se puede utilizar para:
- incrustando una máquina virtual Lua
- crear aplicaciones en SDL
- La automatización del trabajo con libuv es posible (como se mostró anteriormente, ahora se necesita mucho código escrito a mano para trabajar con libuv)
- y, por supuesto, simplificará enormemente el uso de muchas otras bibliotecas C útiles (como OpenAL, Dear-imgui, etc.)

Aunque la pasantía de Aurel en la Fundación Haxe ha finalizado, planea continuar trabajando con Haxe, ya que su educación universitaria aún no se ha completado y todavía tiene que escribir su trabajo final. Aurel ya sabe a qué se dedicará: mejorar el trabajo del recolector de basura en HashLink. Bueno, será interesante!