Redash recientemente comenzó a cambiar de un sistema de ejecución de tareas a otro. A saber, comenzaron la transición de Celery a RQ. En la primera etapa, solo aquellas tareas que no realizan solicitudes directamente se transfirieron a la nueva plataforma. Entre estas tareas se encuentran enviar correos electrónicos, averiguar qué solicitudes deben actualizarse, registrar eventos de usuarios y otras tareas de soporte.

Después de implementar todo esto, se notó que los trabajadores de RQ requieren muchos más recursos informáticos para resolver el mismo volumen de tareas que Celery solía resolver.
El material, cuya traducción publicamos hoy, está dedicado a la historia de cómo Redash descubrió la causa del problema y lo enfrentó.
Algunas palabras sobre las diferencias entre el apio y el RQ
Apio y RQ tienen el concepto de trabajadores de procesos. Tanto allí como allí para la organización de la ejecución paralela de tareas utilizando la creación de horquillas. Cuando el trabajador de Apio comienza, se crean varios procesos de horquilla, cada uno de los cuales procesa tareas de forma autónoma. En el caso de RQ, la instancia del trabajador contiene solo un subproceso (conocido como el "caballo de batalla"), que realiza una tarea y luego se destruye. Cuando el trabajador descarga la siguiente tarea de la cola, crea un nuevo "caballo de batalla".
Al trabajar con RQ, puede lograr el mismo nivel de paralelismo que cuando trabaja con Celery, simplemente ejecutando más procesos de trabajo. Sin embargo, hay una sutil diferencia entre Apio y RQ. En Celery, un trabajador crea muchas instancias de subprocesos en el inicio y luego los usa repetidamente para completar muchas tareas. Y en el caso de RQ, para cada trabajo necesita crear una nueva bifurcación. Ambos enfoques tienen sus pros y sus contras, pero aquí no hablaremos de esto.
Medida de rendimiento
Antes de comenzar a crear perfiles, decidí medir el rendimiento del sistema descubriendo cuánto tiempo necesita el contenedor de trabajadores para procesar 1000 trabajos. Decidí centrarme en la tarea
record_event , ya que esta es una operación ligera común. Para medir el rendimiento, utilicé el comando de
time . Esto requirió un par de cambios en el código del proyecto:
- Para medir el rendimiento de realizar 1000 tareas, decidí usar el modo por lotes RQ, en el que, después de procesar las tareas, se cierra el proceso.
- Quería evitar influir en mis mediciones con otras tareas que podrían haber sido programadas para el momento en que medía el rendimiento del sistema. Entonces moví
record_event a una cola separada llamada benchmark , reemplazando @job('default') con @job('benchmark') . Esto se hizo justo antes de la record_event en record_event tasks/general.py .
Ahora era posible comenzar las mediciones. Para empezar, quería saber cuánto tiempo se tarda en iniciar y detener a un trabajador sin carga. Este tiempo podría restarse de los resultados finales obtenidos más tarde.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
Me llevó 14.7 segundos inicializar al trabajador en mi computadora. Lo recuerdo
Luego puse 1000
record_event prueba
record_event en la cola de
benchmark :
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
Después de eso, comencé el sistema de la misma manera que lo hice antes, y descubrí cuánto tiempo lleva procesar 1000 trabajos.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
Restando 14.7 segundos de lo que sucedió, descubrí que 4 trabajadores procesan 1000 tareas en 102 segundos. Ahora intentemos averiguar por qué es así. Para hacer esto, nosotros, mientras los trabajadores están ocupados, los investigaremos usando
py-spy .
Perfilado
Agregamos otras 1,000 tareas a la cola (esto debe hacerse debido al hecho de que durante las mediciones anteriores se procesaron todas las tareas), ejecutar a los trabajadores y espiarlos.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
Sé que el equipo anterior fue muy largo. Idealmente, para mejorar su legibilidad, valdría la pena dividirlo en fragmentos separados, dividiéndolo en aquellos lugares donde se encuentran secuencias de caracteres
&& . Pero los comandos deben ejecutarse secuencialmente dentro de la misma sesión
docker-compose exec worker bash , por lo que todo se ve así. Aquí hay una descripción de lo que hace este comando:
- Lanza 4 trabajadores por lotes en segundo plano.
- Espera 15 segundos (se necesita aproximadamente tanto para completar su descarga).
- Instala
py-spy . - Ejecuta
rq-info y descubre el PID de uno de los trabajadores. - Registra información sobre el trabajo del trabajador con el PID recibido anteriormente durante 10 segundos y guarda los datos en el archivo
profile.svg
Como resultado, se obtuvo el siguiente "horario ardiente".
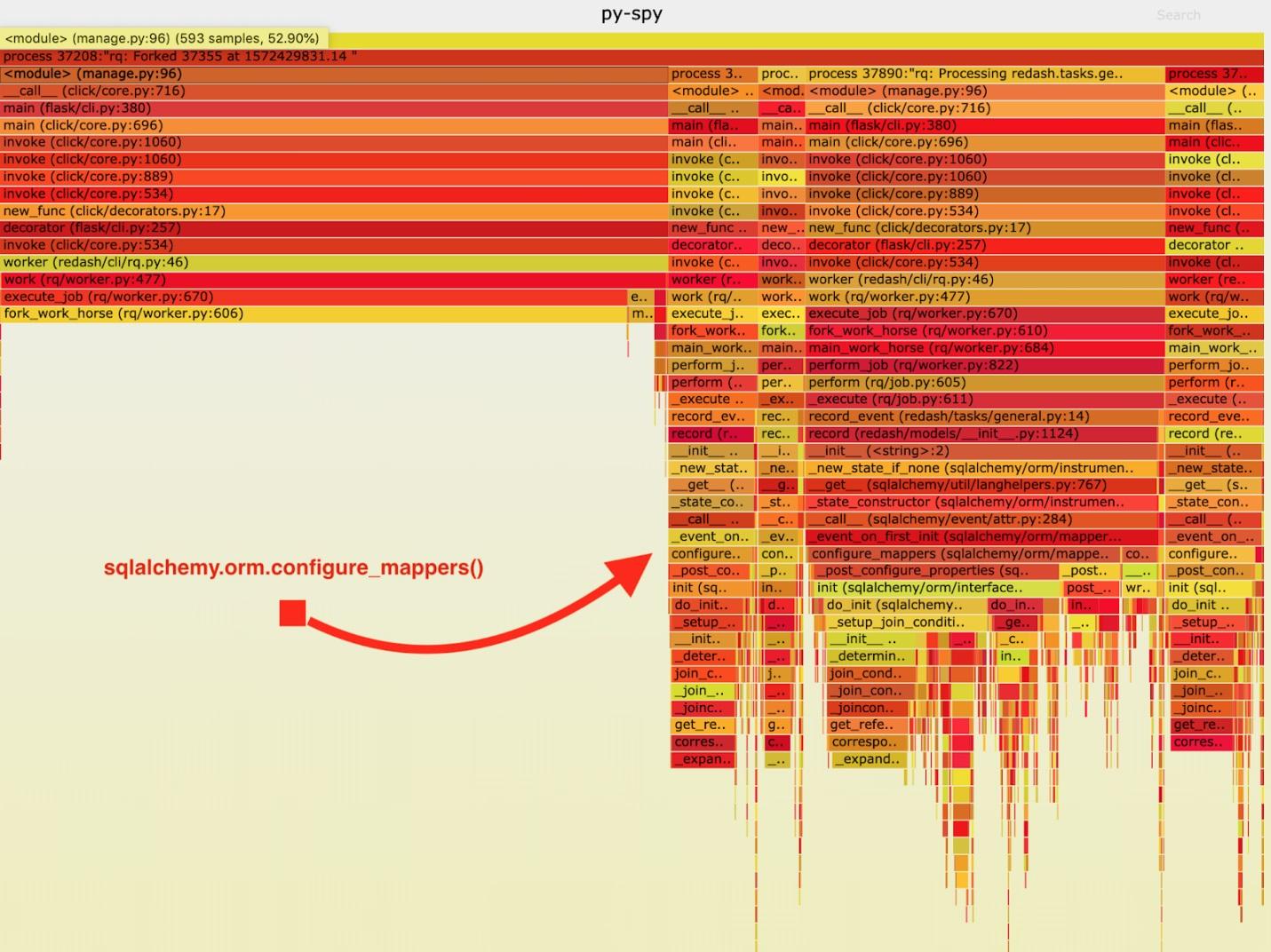 Visualización de datos recopilados por py-spy.
Visualización de datos recopilados por py-spy.Después de analizar estos datos, noté que la tarea
record_event pasa mucho tiempo ejecutándola en
sqlalchemy.orm.configure_mappers . Esto sucede durante cada tarea. De la documentación aprendí que en el momento que me interesa, se inicializan las relaciones de todos los mapeadores creados previamente.
No se requiere que tales cosas sucedan con cada tenedor. Podemos inicializar la relación una vez en el trabajador principal y evitar repetir esta tarea en los "caballos de batalla".
Como resultado, agregué una llamada a
sqlalchemy.org.configure_mappers() al código antes de comenzar el "caballo de batalla" y tomé medidas nuevamente.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
Si resta 14.7 segundos de estos resultados, resulta que hemos mejorado el tiempo requerido para que 4 trabajadores procesen 1000 tareas de 102 segundos a 24.6 segundos. ¡Esta es una mejora de rendimiento cuádruple! Gracias a esta solución, pudimos cuadruplicar los recursos de producción de RQ y mantener el mismo ancho de banda del sistema.
Resumen
De todo esto, llegué a la siguiente conclusión: vale la pena recordar que la aplicación se comporta de manera diferente si es el único proceso y si se trata de bifurcaciones. Si durante cada tarea es necesario resolver algunas tareas oficiales difíciles, entonces es mejor resolverlas con anticipación, una vez hecho esto antes de completar la bifurcación. Tales cosas no se detectan durante las pruebas y el desarrollo, por lo tanto, después de haber sentido que algo anda mal con el proyecto, mida su velocidad y llegue al final mientras busca las causas de los problemas con su rendimiento.
Estimados lectores! ¿Ha encontrado problemas de rendimiento en proyectos de Python que podría resolver analizando cuidadosamente un sistema de trabajo?
