
¡Hola Khabrovchans! Continuamos familiarizándolo con el sistema ruso hiperconvergente AERODISK vAIR. Este artículo se centrará en la arquitectura de este sistema. En el último artículo, analizamos nuestro sistema de archivos ARDFS, y en este artículo revisaremos todos los componentes principales de software que componen vAIR y sus tareas.
Comenzamos la descripción de la arquitectura de abajo hacia arriba, desde el almacenamiento hasta la administración.
Sistema de archivos ARDFS + Raft Cluster Driver
La base de vAIR es el sistema de archivos distribuido ARDFS, que combina los discos locales de todos los nodos del clúster en un solo grupo lógico, sobre la base de los cuales los discos virtuales con uno u otro esquema de tolerancia a fallas (factor de replicación o codificación de borrado) se forman a partir de bloques virtuales de 4 MB. Una descripción más detallada del trabajo de ARDFS se da en el artículo anterior.
Raft Cluster Driver es un servicio ARDFS interno que resuelve el problema del almacenamiento distribuido y confiable de los metadatos del sistema de archivos.
Los metadatos ARDFS se dividen convencionalmente en dos clases.
- notificaciones: información sobre operaciones con objetos de almacenamiento e información sobre los objetos mismos;
- información de servicio: configuración de bloqueos e información de configuración para nodos de almacenamiento.
El servicio RCD se utiliza para distribuir estos datos. Asigna automáticamente un nodo con el papel de un líder cuya tarea es obtener y difundir metadatos entre los nodos. Un líder es la única fuente verdadera de esta información. Además, el líder organiza un latido del corazón, es decir comprueba la disponibilidad de todos los nodos de almacenamiento (esto no tiene relación con la disponibilidad de máquinas virtuales, RCD es solo un servicio de almacenamiento).
Si por alguna razón el líder no está disponible para uno de los nodos ordinarios durante más de un segundo, este nodo ordinario organiza una reelección del líder, solicitando la disponibilidad del líder de otros nodos ordinarios. Si hay quórum, el líder es reelegido. Después de que el antiguo líder "despertó", se convierte automáticamente en un nodo ordinario, porque El nuevo líder le envía el equipo apropiado.
La lógica del RCD en sí no es nueva. Muchas soluciones de terceros y comerciales y gratuitas también se guían por esta lógica, pero estas soluciones no nos convenían (como el FS de código abierto existente), porque son bastante pesadas y es muy difícil optimizarlas para nuestras tareas simples, así que simplemente escribimos las nuestras. Servicio de RCD.
Puede parecer que el líder es un "cuello estrecho" que puede ralentizar el trabajo en grandes grupos de cientos de nodos, pero esto no es así. El proceso descrito ocurre casi instantáneamente y "pesa" muy poco ya que lo escribimos nosotros mismos e incluimos solo las funciones más necesarias. Además, ocurre de forma completamente automática, dejando solo mensajes en los registros.
MasterIO - Servicio de gestión de E / S multiproceso
Una vez que se organiza un grupo ARDFS con discos virtuales, se puede usar para E / S. En este punto, la pregunta surge específicamente para los sistemas hiperconvergentes, a saber: ¿cuántos recursos del sistema (CPU / RAM) podemos donar para IO?
En los sistemas de almacenamiento clásicos, esta pregunta no es tan aguda, porque la tarea de almacenamiento es solo almacenar datos (y la mayoría de los recursos de almacenamiento del sistema se pueden proporcionar de manera segura bajo IO), y las tareas de hiperconvergencia, además del almacenamiento, también incluyen la ejecución de máquinas virtuales. En consecuencia, el GCS requiere el uso de recursos de CPU y RAM principalmente para máquinas virtuales. Bueno, ¿qué hay de E / S?
Para resolver este problema, vAIR utiliza el servicio de administración de E / S: MasterIO. La tarea del servicio es simple: "Toma todo y comparte" se garantiza que recoge el enésimo número de recursos del sistema para entrada y salida y, a partir de ellos, comienza el enésimo número de flujos de entrada / salida.
Inicialmente, queríamos proporcionar un mecanismo "muy inteligente" para asignar recursos para IO. Por ejemplo, si no hay carga en el almacenamiento, los recursos del sistema pueden usarse para máquinas virtuales, y si aparece la carga, estos recursos se eliminan "suavemente" de las máquinas virtuales dentro de límites predeterminados. Pero este intento terminó en un fracaso parcial. Las pruebas mostraron que si la carga se incrementa gradualmente, entonces todo está bien, los recursos (marcados para una posible eliminación) se retiran gradualmente de la VM a favor de E / S. Pero estallidos bruscos de cargas de almacenamiento provocan una retirada no tan "suave" de los recursos de las máquinas virtuales y, como resultado, se acumulan colas en los procesadores y, como resultado, y los lobos tienen hambre y las ovejas están muertas y virtualka cuelgan, y no hay IOPS.
Quizás en el futuro volvamos a este problema, pero por ahora hemos implementado la emisión de recursos para IO de la manera del viejo abuelo: las manos.
Según los datos de dimensionamiento, el administrador asigna previamente el enésimo número de núcleos de CPU y RAM para el servicio MasterIO. A estos recursos se les asigna el monopolio, es decir no se pueden usar de ninguna manera para las necesidades de VM hasta que el administrador lo permita. Los recursos se asignan de manera uniforme, es decir Se toma la misma cantidad de recursos del sistema de cada nodo del clúster. En primer lugar, los recursos del procesador son de interés para MasterIO (la RAM es menos importante), especialmente si utilizamos la codificación Erasure.
Si se produjo un error con el tamaño y le dimos demasiados recursos a MasterIO, entonces la situación se resuelve fácilmente eliminando estos recursos al grupo de recursos de VM. Si los recursos están inactivos, regresarán casi de inmediato al grupo de recursos de VM, pero si se eliminan estos recursos, tendrá que esperar un tiempo para que MasterIO los libere suavemente.
La situación inversa es más complicada. Si necesitáramos aumentar el número de núcleos para MasterIO, y están ocupados con los virtuales, entonces tenemos que "negociar" con los virtuales, es decir, seleccionarlos con asas, porque en modo automático en una situación de fuerte explosión de carga, esta operación está cargada de congelaciones de VM y otros comportamientos caprichosos.
En consecuencia, se debe prestar mucha atención al dimensionamiento del rendimiento de los sistemas hiperconvergentes de E / S (no solo los nuestros). Un poco más adelante, en uno de los artículos, prometemos considerar este tema con más detalle.
Hipervisor
Hypervisor Aist es responsable de ejecutar máquinas virtuales en vAIR. Este hipervisor se basa en el hipervisor KVM probado con el tiempo. En principio, se ha escrito mucho sobre el trabajo de KVM, por lo que no hay necesidad particular de pintarlo, solo indique que todas las funciones estándar de KVM están almacenadas en Stork y funcionan bien.
Por lo tanto, aquí describiremos las principales diferencias con el KVM estándar, que implementamos en Stork. La cigüeña forma parte del sistema (hipervisor preinstalado) y se controla desde la consola vAIR común a través de la GUI web (versiones en ruso e inglés) y SSH (obviamente, solo inglés).
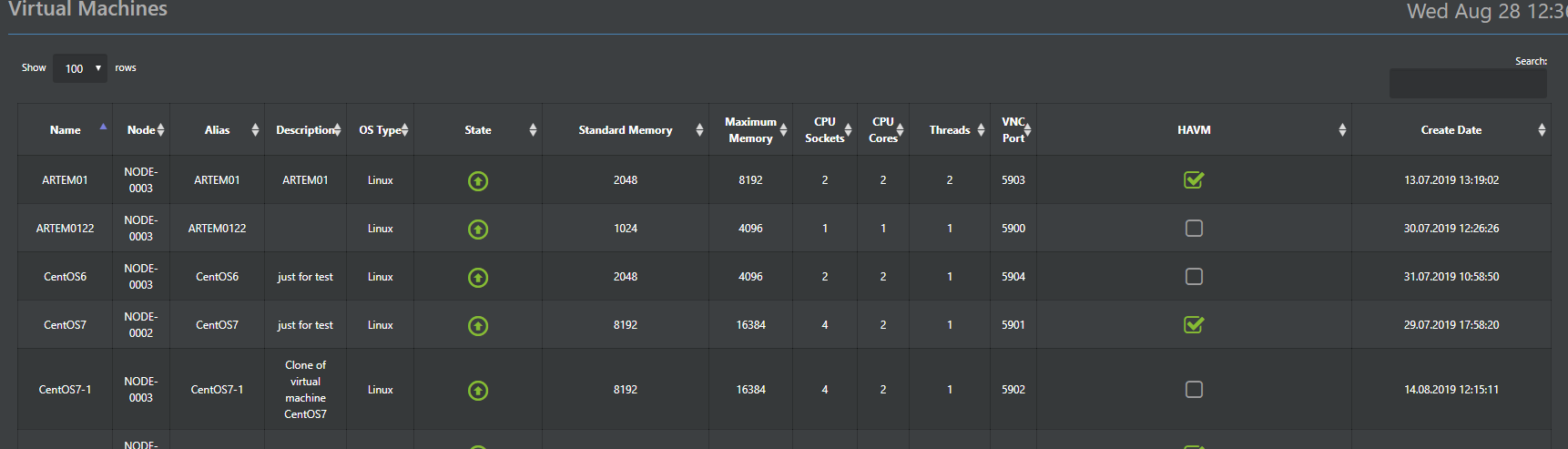
Además, las configuraciones del hipervisor se almacenan en la base de datos distribuida de ConfigDB (sobre esto un poco más tarde), que también es un único punto de control. Es decir, puede conectarse a cualquier nodo en el clúster y administrar todo sin la necesidad de un servidor de administración separado.
Una adición importante a la funcionalidad estándar de KVM es el módulo HA que desarrollamos. Esta es la implementación más simple de un clúster de máquinas virtuales de alta disponibilidad, que le permite reiniciar automáticamente la máquina virtual en otro nodo del clúster en caso de falla del nodo.
Otra característica útil es el despliegue masivo de máquinas virtuales (relevante para entornos VDI), que automatizará el despliegue de máquinas virtuales con distribución automática entre nodos dependiendo de la carga en ellos.
La distribución de VM entre nodos es la base para el equilibrio de carga automático (ala DRS). Esta función aún no está disponible en la versión actual, pero estamos trabajando activamente en ella y definitivamente aparecerá en una de las próximas actualizaciones.
El hipervisor VMware ESXi tiene soporte opcional, actualmente se implementa utilizando el protocolo iSCSI, y el soporte NFS también está planeado en el futuro.
Interruptores virtuales
Para la implementación del software de los conmutadores, se proporciona un componente separado: Fractal. Al igual que en nuestros otros componentes, pasamos de simple a complejo, por lo que en la primera versión se implementa un cambio simple, mientras que el enrutamiento y el firewall se otorgan a dispositivos de terceros. El principio de funcionamiento es estándar. La interfaz física del servidor está conectada por un puente al objeto Fractal, un grupo de puertos. Un grupo de puertos, a su vez, con las máquinas virtuales deseadas en el clúster. Se admite la organización de VLAN, y en una de las próximas versiones se agregará soporte de VxLAN. Todos los conmutadores creados se distribuyen por defecto, es decir distribuidos en todos los nodos del clúster, por lo que las máquinas virtuales a las que los conmutadores se conectan a la VM no dependen del nodo de ubicación, esto es solo una decisión del administrador.
Monitoreo y estadísticas
El componente responsable del monitoreo y las estadísticas (título de trabajo Mónica) es, de hecho, un clon rediseñado del sistema de almacenamiento ENGINE. En un momento, se recomendó bien y decidimos usarlo con vAIR con un ajuste fácil. Al igual que todos los demás componentes, Mónica se ejecuta y se almacena en todos los nodos del clúster al mismo tiempo.
Las difíciles responsabilidades de Mónica pueden resumirse de la siguiente manera:
Recolección de datos:
- de sensores de hardware (que pueden dar hierro sobre IPMI);
- de objetos lógicos vAIR (ARDFS, Stork, Fractal, MasterIO y otros objetos).
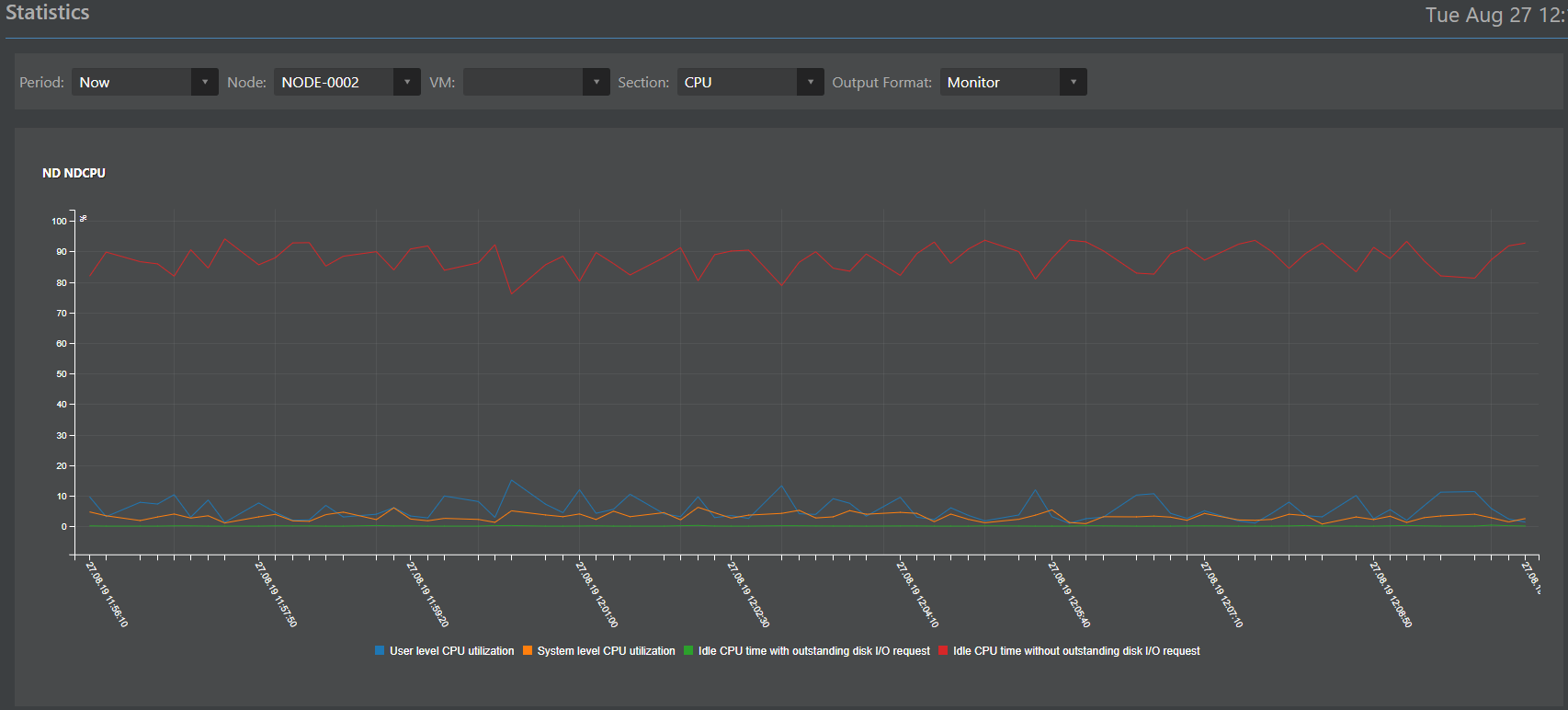
Recopilación de datos en una base de datos distribuida;
Interpretación de datos en forma de:
Interacción externa con sistemas de terceros a través de los protocolos SMTP (envío de alertas por correo electrónico) y SNMP (interacción con sistemas de monitoreo de terceros).
Base de configuración distribuida
En los párrafos anteriores, se mencionó que muchos datos se almacenan en todos los nodos del clúster al mismo tiempo. Para organizar este método de almacenamiento, se proporciona una base de datos distribuida especial de ConfigDB. Como su nombre lo indica, la base de datos almacena las configuraciones de todos los objetos del clúster: hipervisor, máquinas virtuales, módulo HA, conmutadores, sistema de archivos (que no debe confundirse con la base de datos de metadatos FS, esta es otra base de datos), así como estadísticas. Estos datos se almacenan sincrónicamente en todos los nodos y la coherencia de estos datos es un requisito previo para el funcionamiento estable de vAIR.
Un punto importante: aunque el funcionamiento de ConfigDB es vital para la operación de vAIR, su falla, aunque detendrá el clúster, no afecta la consistencia de los datos almacenados en ARDFS, lo que en nuestra opinión es una ventaja para la confiabilidad de la solución en su conjunto.
ConfigDB también es un único punto de administración, por lo que puede ir a cualquier nodo del clúster por dirección IP y administrar completamente todos los nodos del clúster, lo cual es bastante conveniente.
Además, para acceder a sistemas externos, ConfigDB proporciona una API Restful a través de la cual puede configurar la integración con sistemas de terceros. Por ejemplo, recientemente realizamos una integración piloto con varias soluciones rusas en los campos de VDI y seguridad de la información. Cuando se completen los proyectos, estaremos encantados de escribir detalles técnicos aquí.
Toda la imagen
Como resultado, tenemos dos versiones de la arquitectura del sistema.
En el primer caso principal, se utilizan nuestro hipervisor Aist basado en KVM y los conmutadores de software Fractal.
Escenario 1. Verdadero
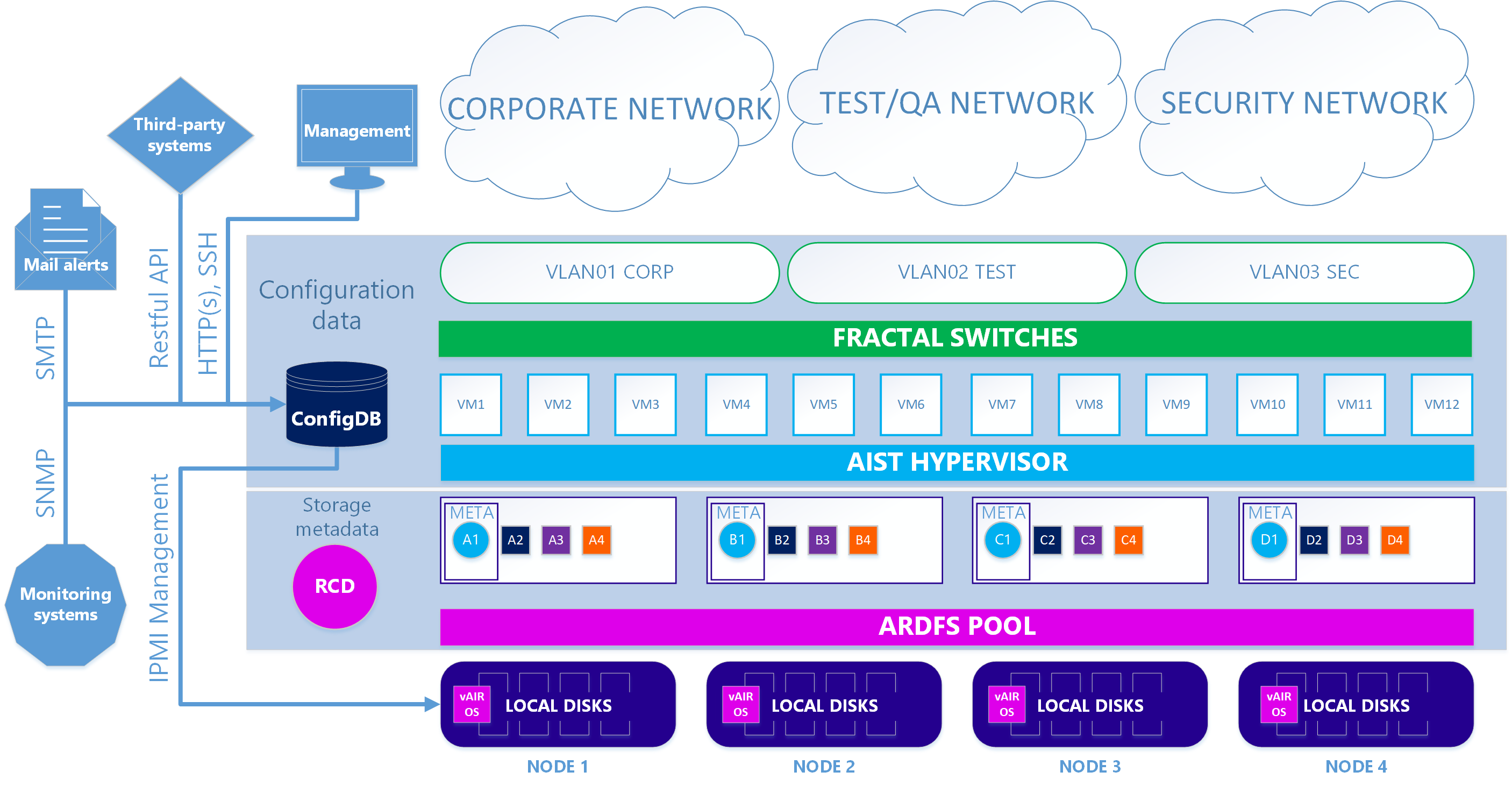
En la segunda opción opcional, cuando desea utilizar el hipervisor ESXi, el esquema es algo complicado. Para utilizar ESXi, debe instalarse de forma estándar en las unidades locales del clúster. A continuación, en cada nodo ESXi, se instala la máquina virtual vAIR MasterVM, que contiene una distribución especial vAIR para ejecutarse como una máquina virtual VMware.
ESXi ofrece todos los discos locales gratuitos mediante reenvío directo a MasterVM. Dentro de MasterVM, estos discos ya están formateados de manera estándar en ARDFS y entregados al exterior (o más bien, de vuelta a ESXi) utilizando el protocolo iSCSI (y en el futuro también habrá NFS) a través de las interfaces dedicadas en ESXi. En consecuencia, las máquinas virtuales y la red de software en este caso son proporcionadas por ESXi.
Escenario 2. ESXi
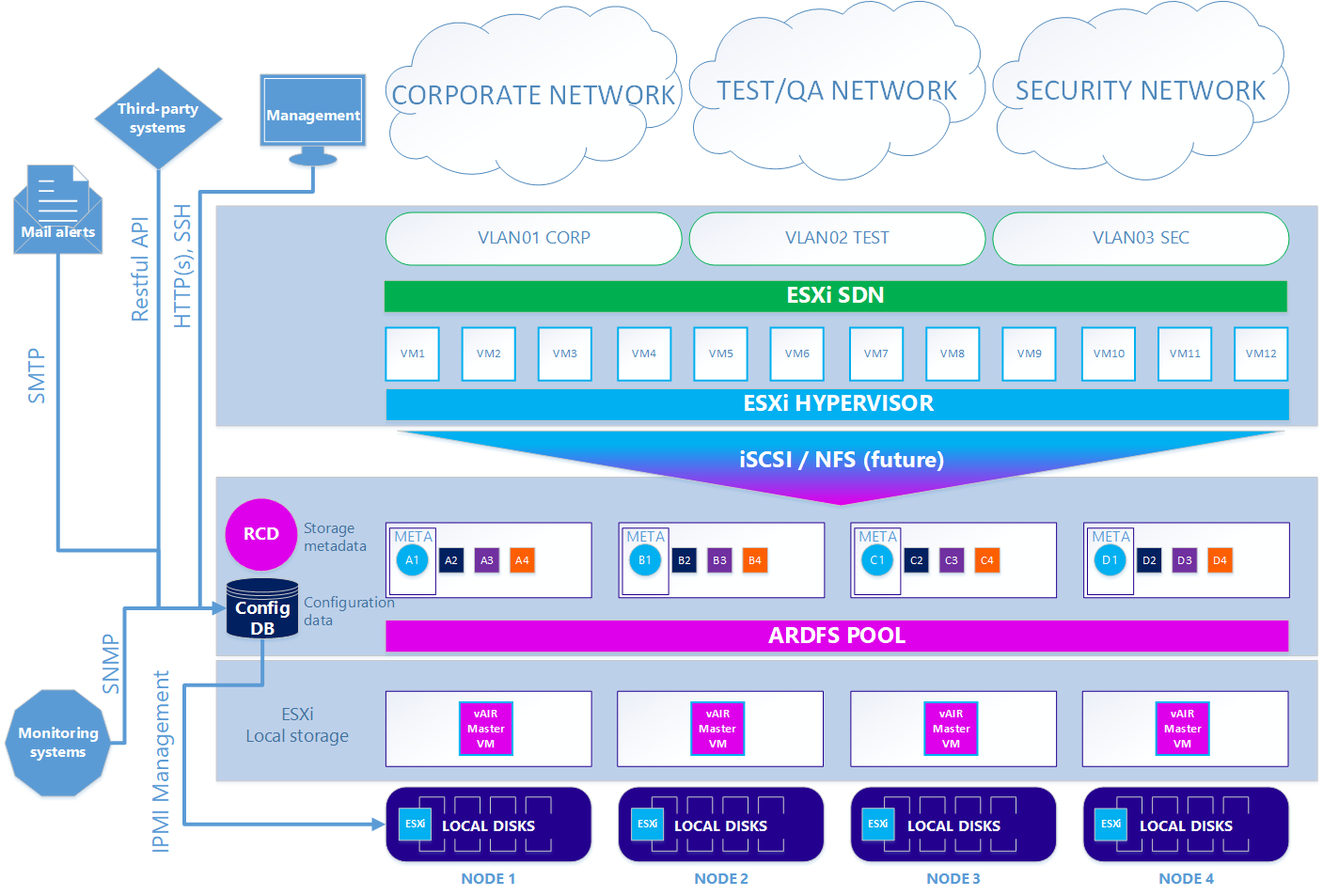
Por lo tanto, hemos desmontado todos los componentes principales de la arquitectura vAIR y sus tareas. En el próximo artículo hablaremos sobre la funcionalidad y los planes ya implementados para el futuro cercano.
Estamos a la espera de comentarios y sugerencias.