Hola
En septiembre de este año (2019), se celebró la elección del Gobernador de San Petersburgo. Todos los datos de votación están disponibles públicamente en el sitio web de la comisión electoral, no romperemos nada, simplemente visualicemos la información de este sitio web
www.st-petersburg.vybory.izbirkom.ru en la forma que necesitemos, realizaremos un análisis muy simple e identificaremos algunos Patrones "mágicos".
Por lo general, para tales tareas, uso Google Colab. Este es un servicio que le permite ejecutar Jupyter Notebooks y, al tener acceso gratuito a la GPU (NVidia Tesla K80), acelerará significativamente el análisis de datos y el procesamiento posterior. Necesitaba un trabajo preparatorio antes de importar.
%%time !apt update !apt upgrade !apt install gdal-bin python-gdal python3-gdal
Más importaciones.
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt import geopandas as gpd import xlrd
Descripción de bibliotecas usadas
- solicitudes: módulo para una solicitud de conexión a un sitio
- BeautifulSoup - módulo para analizar documentos html y xml; le permite acceder directamente al contenido de cualquier etiqueta en html
- numpy - un módulo matemático con un conjunto básico y necesario de funciones matemáticas
- pandas - biblioteca de análisis de datos
- matplotlib.pyplot: conjunto de módulos de métodos de construcción
- geopandas - módulo para construir un mapa electoral
- xlrd - módulo para leer archivos de tabla
Ha llegado el momento de recopilar los datos en sí, parsim. El comité electoral se encargó de nuestro tiempo y proporcionó informes en las tablas, es conveniente.
Entonces, esto es lo que se discutió. Los datos en Google Colab se recopilan de manera inteligente, pero no tanto.
Antes de construir varios gráficos y mapas, es bueno que tengamos una idea de lo que llamamos un "conjunto de datos".
Análisis de los datos de la comisión electoral.
En la ciudad de San Petersburgo hay 30 comisiones territoriales; a ellas, en la columna 31, nos referimos a los colegios electorales digitales.

Cada comisión territorial tiene varias docenas de PEC (comisiones electorales).

Lo principal que nos interesa es la aparición en cada mesa electoral y qué tipo de dependencias podemos observar. Construiré sobre lo siguiente:
- dependencia de la participación y el número de mesas electorales;
- dependencia del porcentaje de votos para los candidatos en la participación;
- Dependencia de la participación en el número de votantes en el recinto.
Desde la tabla de datos, es bastante difícil rastrear cómo fueron las elecciones y sacar algunas conclusiones, por lo que los gráficos son nuestra salida.
Construyamos lo que se nos ocurrió.
Dependencia de participación y número de mesas electorales. Dependencia del porcentaje de votos de los candidatos en la participación.
Dependencia del porcentaje de votos de los candidatos en la participación.- "Verde" - votos para Amosov
 Dependencia de la participación en el número de votantes en el recinto.
Dependencia de la participación en el número de votantes en el recinto.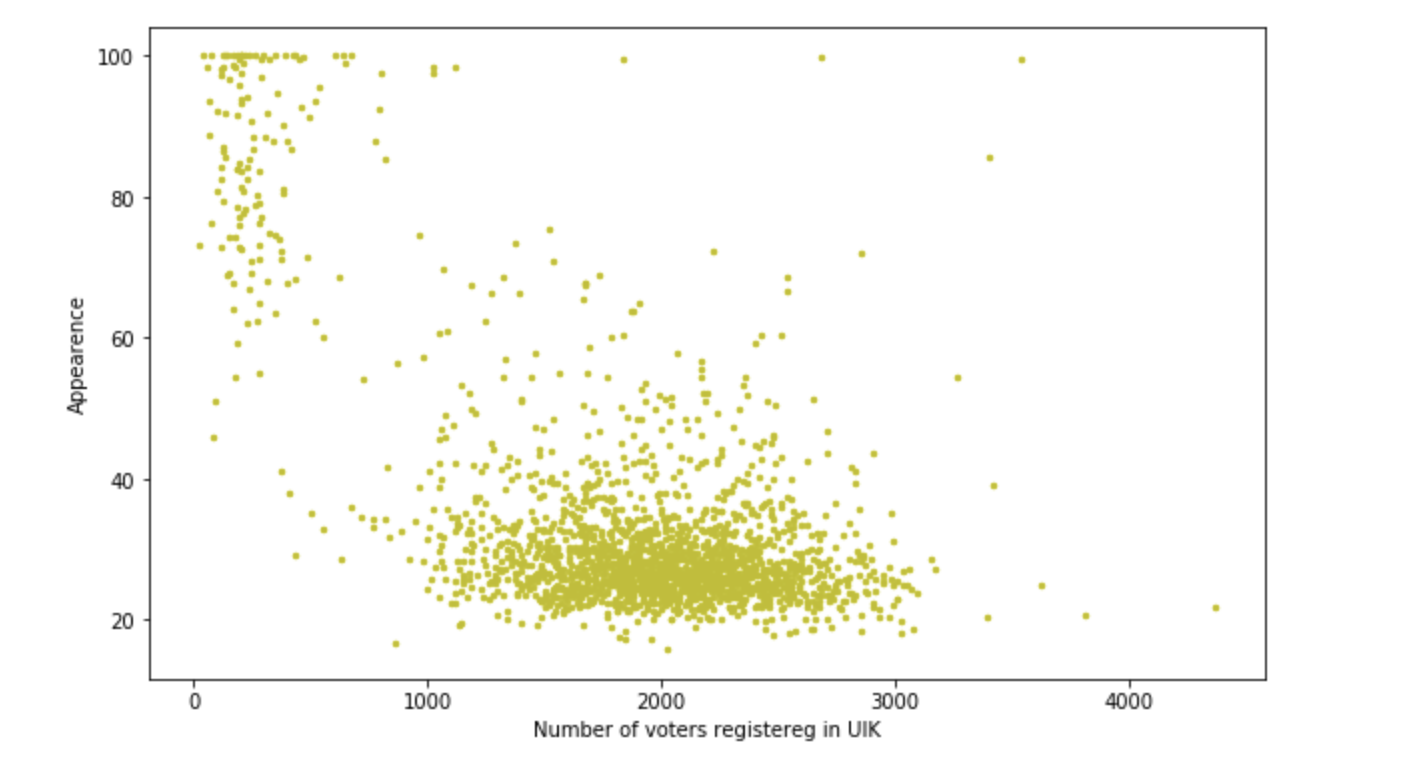
Las construcciones son bastante tolerables, pero en el transcurso del trabajo resultó que en promedio 400 personas en el sitio y el porcentaje de Beglov es de 50 a 70, pero hay dos sitios con una participación> 1200 personas y un porcentaje de 90 + -0.2. Es interesante que esto haya sucedido en estas áreas. ¿Funcionaron algunos agitadores fantásticos? ¿O simplemente condujo autobuses para 10 personas y se vio obligado a votar? De una forma u otra, estamos entusiasmados, se está obteniendo una pequeña investigación de este tipo. Pero todavía tenemos que robar cartas. Vamos a continuar
Representación visual y trabajo con geopandas.
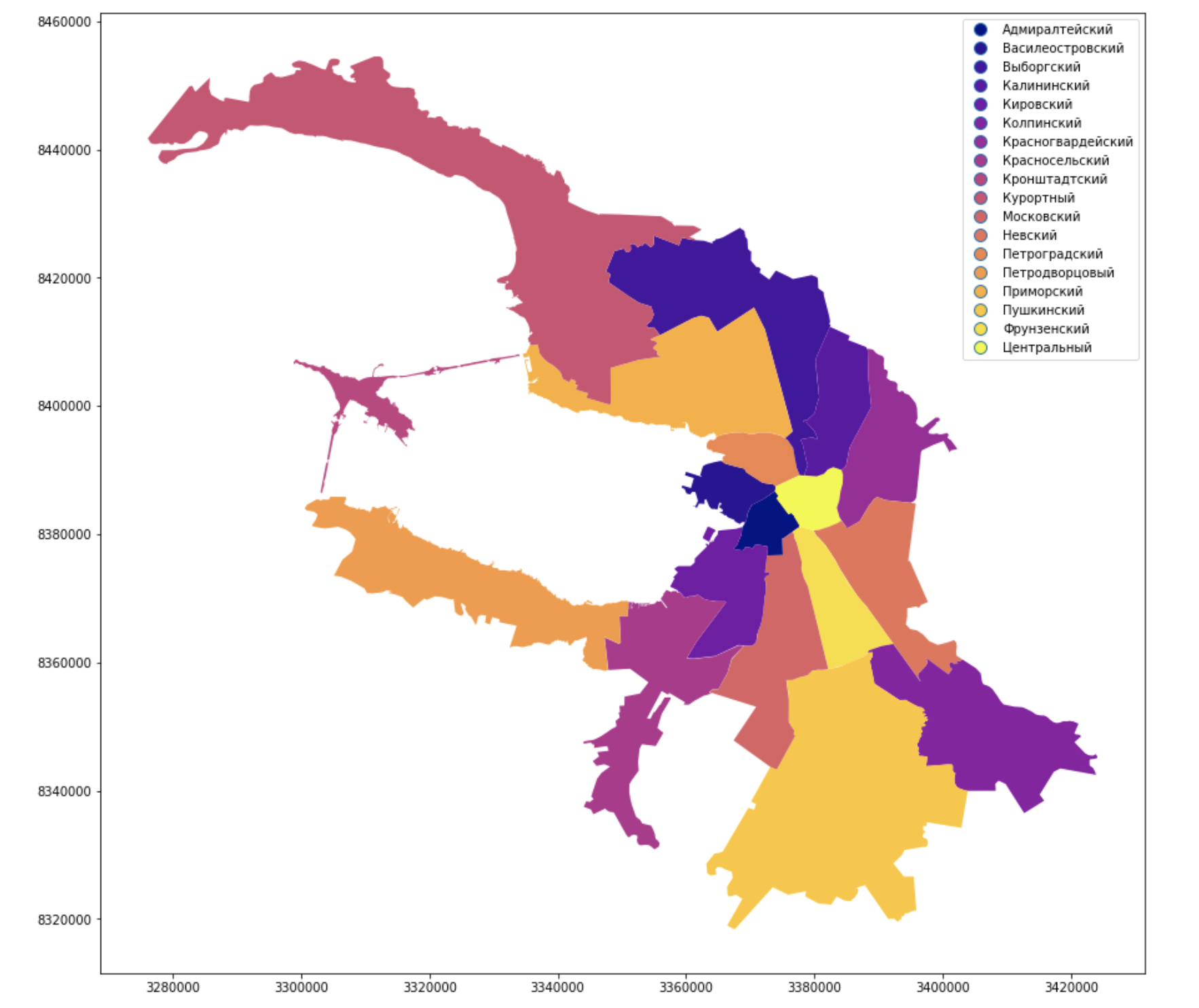
Pintaron los distritos administrativos de la ciudad y los firmaron, parece familiar, se parece a Peter, pero el Neva todavía no es suficiente.
Numero de votantes
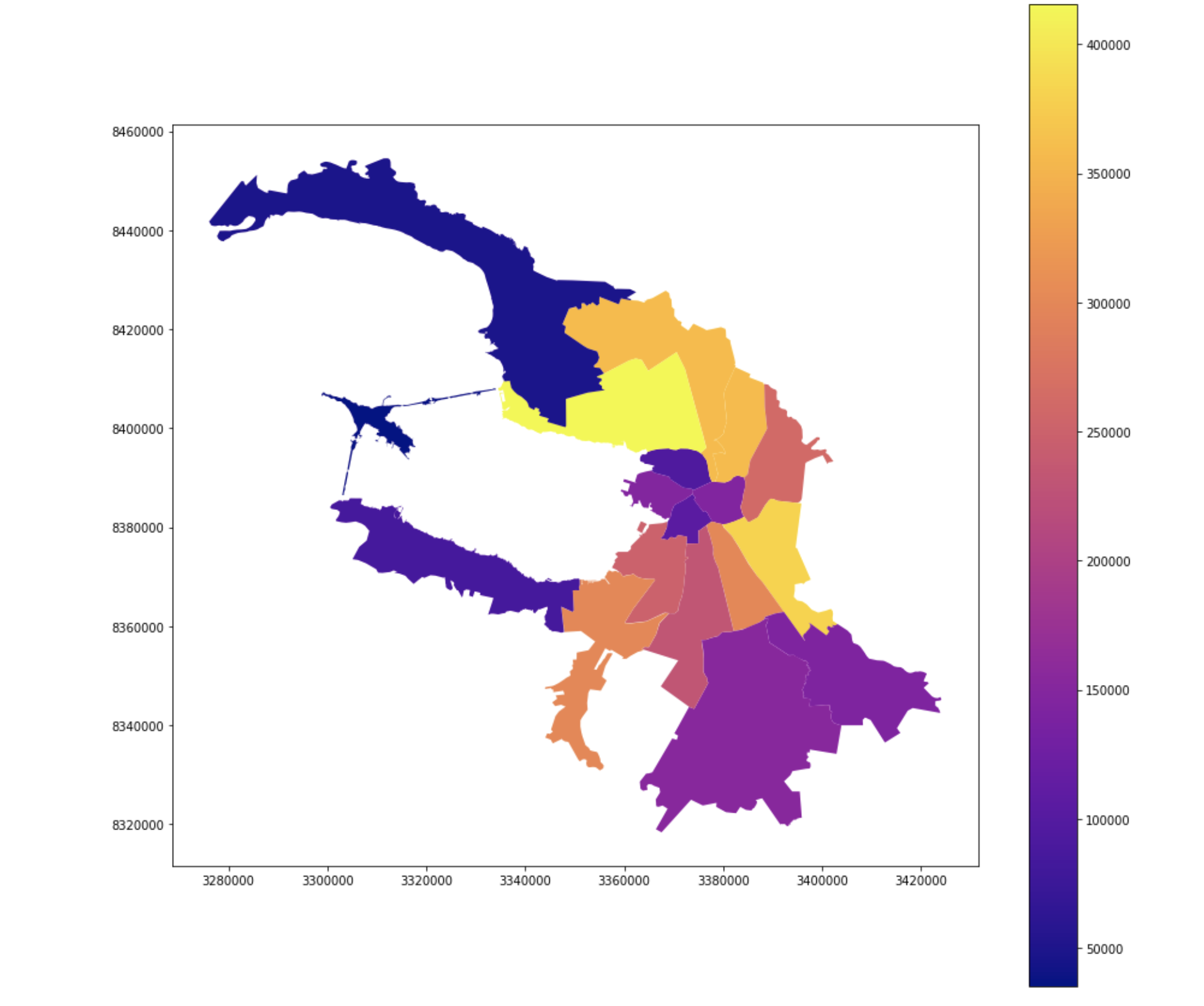 Participación
Participación

Conclusión
Puede divertirse con los datos durante mucho tiempo, usarlos en diferentes campos y, por supuesto, obtener algún beneficio, ya que existen. Las herramientas de visualización de geolocalización simples y sofisticadas pueden hacer grandes cosas. ¡Escribe sobre tu éxito en los comentarios!