Para preguntas al estilo de "¿por qué?" Hay un artículo más antiguo, Natural Geektimes, que hace que el espacio sea más limpio .
Muchos artículos, por razones subjetivas, a algunos no les gusta, y otros, por el contrario, es una pena perderse. Quiero optimizar este proceso y ahorrar tiempo.
El artículo anterior sugirió un enfoque con scripts en el navegador, pero realmente no me gustó (a pesar de que lo usé antes) por las siguientes razones:
- Para diferentes navegadores en su computadora / teléfono, debe configurarlo nuevamente, si es posible.
- El filtrado duro por parte de los autores no siempre es conveniente.
- El problema con los autores cuyos artículos no quieren perderse, incluso si se publican una vez al año, no se resuelve.
Filtrar por calificación de artículo integrado en el sitio no siempre es conveniente, ya que los artículos altamente especializados, por todo su valor, pueden recibir una calificación bastante modesta.
Inicialmente, quería generar un feed rss (o incluso algunos), dejando solo lo interesante allí. Pero al final resultó que leer rss no parecía muy conveniente: en cualquier caso, para comentar / votar un artículo / agregarlo a favoritos, debe pasar por el navegador. Por lo tanto, escribí un bot para un telegrama que me arroja artículos interesantes en PM. Telegram en sí mismo los convierte en hermosas vistas previas, que en combinación con información sobre el autor / calificación / vistas parece bastante informativo.
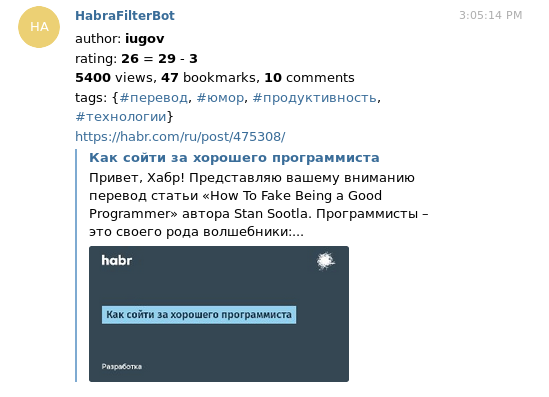
Debajo del corte, detalles como características de trabajo, proceso de escritura y soluciones técnicas.
Brevemente sobre el bot
Repositorio: https://github.com/Kright/habrahabr_reader
Telegram bot: https://t.me/HabraFilterBot
El usuario establece una calificación adicional para etiquetas y autores. Después de eso, se aplica un filtro a los artículos: se agrega la calificación del artículo en Habré, la calificación del autor del usuario y el promedio de las calificaciones del usuario por etiquetas. Si la cantidad es mayor que el valor umbral definido por el usuario, el artículo pasa el filtro.
Un objetivo secundario de escribir un bot era divertirse y experimentar. Además, regularmente me recordaba a mí mismo que no era Google y, por lo tanto, muchas cosas se hacían de la manera más simple e incluso primitiva posible. Sin embargo, esto no impidió que el proceso de escritura del bot se alargara durante tres meses.
Fuera de la ventana era verano
Julio terminó y decidí escribir un bot. Y no solo, sino con un amigo que dominaba la escala y quería escribir algo sobre ella. El comienzo parecía prometedor: el código será aserrado "equipo", la tarea parecía fácil y pensé que en un par de semanas o un mes el bot estará listo.
A pesar de que yo mismo he estado escribiendo código en la roca durante los últimos años, generalmente nadie ve ni mira este código: proyectos favoritos, verificar algunas ideas, preprocesamiento de datos, dominar algunos conceptos del FP. Estaba realmente interesado en cómo se ve el código en el equipo, porque el código en la roca se puede escribir de maneras muy diferentes.
¿Qué pudo haber ido así ? Sin embargo, no apuraremos las cosas.
Todo lo que sucede puede ser rastreado por la historia de los commits.
Un amigo creó el repositorio el 27 de julio, pero no hizo nada más, así que comencé a escribir código.
30 de julio
Brevemente: escribí analizando rss feeds de Habr.
com.github.pureconfig para leer archivos de configuración de typesafe directamente en clases de caso (resultó ser muy conveniente)scala-xml para leer xml: dado que originalmente quería escribir mi implementación para rss tape y rss tape en formato xml, utilicé esta biblioteca para analizar. En realidad, el análisis rss también apareció.scalatest para pruebas. Incluso para proyectos pequeños, escribir pruebas ahorra tiempo; por ejemplo, al depurar el análisis XML es mucho más fácil descargarlo en un archivo, escribir pruebas y corregir errores. Cuando más tarde apareció un error al analizar un extraño html con caracteres utf-8 no válidos, resultó ser más conveniente volver a colocarlo en un archivo y agregar una prueba.- actores de Akka. Objetivamente, no eran necesarios en absoluto, pero el proyecto fue escrito por diversión, quería probarlos. Como resultado, estoy listo para decir que me gustó. Uno puede ver la idea de OOP desde el otro lado: hay actores que intercambian mensajes. Lo que es más interesante: es posible (y necesario) escribir código de tal manera que el mensaje no llegue o no pueda procesarse (en términos generales, cuando una cuenta se ejecuta en una sola computadora, los mensajes no deberían perderse). Al principio me estaba estrujando el cerebro y había una basura en el código con actores que se suscribían entre sí, pero al final logré crear una arquitectura bastante simple y elegante. El código dentro de cada actor puede considerarse de un solo subproceso, cuando el actor se bloquea, Akka lo reinicia, se obtiene un sistema bastante tolerante a fallas.
9 de agosto
scala-scrapper proyecto scala-scrapper para analizar páginas html del Habr (para extraer información como la calificación del artículo, el número de marcadores, etc.).
Y gatos. Los que están en la roca.
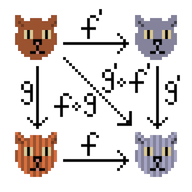
Luego leí un libro sobre bases de datos distribuidas, me gustó la idea de CRDT (tipo de datos replicados sin conflictos, https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type , habr ), así que filmé la clase de tipo del semigrupo conmutativo para información sobre el artículo sobre Habré.
De hecho, la idea es muy simple: tenemos contadores que cambian de manera monótona. El número de promotores está creciendo sin problemas, el número de ventajas también (sin embargo, así como el número de desventajas). Si tengo dos versiones de información sobre un artículo, puede "fusionarlas en una": considere el estado del contador que sea más relevante.
Un semigrupo significa que dos objetos con información sobre un artículo pueden fusionarse en uno. Conmutativo significa que puede fusionar A + B y B + A, el resultado no depende del orden, como resultado, la versión más reciente permanece. Por cierto, la asociatividad también está aquí.
Por ejemplo, por diseño, rss después del análisis proporcionó información ligeramente amortiguada sobre el artículo, sin métricas como el número de vistas. Un actor especial tomó información sobre los artículos y corrió a las páginas html para actualizarlo y fusionarlo con la versión anterior.
En términos generales, como akka, no había necesidad de esto, solo era posible almacenar updateDate para el artículo y tomar uno más nuevo sin ninguna fusión, pero el camino de la aventura me llevó.
12 de agosto
Comencé a sentirme más libre y, por interés, hice de cada conversación un actor separado. Teóricamente, un actor por sí solo pesa unos 300 bytes y puede crearse al menos por millones, por lo que este es un enfoque completamente normal. Resultó, me parece, una solución bastante interesante:
Un actor fue el puente entre el servidor de telegramas y el sistema de mensajes en Akka. Simplemente recibió mensajes y los envió al actor de chat deseado. El chat de actores en respuesta podría enviar algo de regreso, y fue enviado de vuelta a telegramas. Lo que era muy conveniente: este actor resultó ser lo más simple posible y contenía solo la lógica de la respuesta a los mensajes. Por cierto, la información sobre nuevos artículos llegó a cada chat, pero de nuevo no veo ningún problema en esto.
En general, el bot ya estaba funcionando, respondiendo mensajes, manteniendo una lista de artículos enviados al usuario, y ya pensaba que el bot estaba casi listo. Lentamente terminé pequeños chips como normalizar los nombres de autores y etiquetas (reemplazando "sd f" con "s_d_f").
Solo había un pequeño pero : el estado no persistía en ninguna parte.
Todo salió mal
Puede que hayas notado que escribí el bot principalmente solo. Entonces, el segundo participante se unió al desarrollo y aparecieron los siguientes cambios en el código:
- Para almacenar el estado apareció mongoDB. Al mismo tiempo, los registros se rompieron en el proyecto, porque por alguna razón la monga comenzó a enviarles correos no deseados y algunas personas simplemente los desactivaron a nivel mundial.
- El puente del actor en telegrama se transformó más allá del reconocimiento y comenzó a analizar los mensajes en sí.
- Los actores de los chats estaban borrachos sin piedad, en lugar de ellos apareció un actor que escondió en sí mismo toda la información sobre todos los chats a la vez. Por cada estornudo, este actor se metió en mongu. Bueno, sí, es difícil enviarlo a todos los actores de chat cuando se actualiza la información sobre un artículo (somos como Google, millones de usuarios esperan un millón de artículos en un chat para todos), pero es normal entrar en una monga cada vez que actualiza un chat. Como lo entendí mucho después, la lógica de trabajo de los chats también se cortó por completo y apareció algo inoperante.
- No queda rastro de las clases.
- Una lógica poco saludable apareció en los actores con sus suscripciones entre sí, lo que condujo a una condición de carrera.
- Las estructuras de datos con campos de tipo
Option[Int] convirtieron en Int con valores mágicos predeterminados de tipo -1. Más tarde, me di cuenta de que mongoDB almacena json y que no hay nada de malo en almacenar Option allí, o al menos analizar -1 como None, pero en ese momento no lo sabía y creía la palabra "es necesario". Ese código no fue escrito por mí, y no me molesté en cambiarlo por el momento. - Descubrí que mi dirección IP pública tiene la propiedad de cambiar, y cada vez que tenía que agregarla a la lista blanca. Comencé el bot localmente, la monga estaba en algún lugar de los servidores monga como compañía.
- De repente, la normalización de las etiquetas y el formato de los mensajes para un telegrama desaparecieron. (Hmm, ¿por qué lo haría?)
- Me gustó que el estado del bot se almacena en una base de datos externa, y al reiniciar, continúa funcionando como si nada hubiera pasado. Sin embargo, esta fue la única ventaja.
La segunda persona no tenía prisa, y todos estos cambios aparecieron en un gran montón ya a principios de septiembre. No aprecié de inmediato la magnitud del daño y comencé a entender el trabajo de la base de datos, porque nunca había tratado con ellos antes. Solo entonces me di cuenta de cuánto código de trabajo se cortó y cuántos errores se agregaron a cambio.
Septiembre
Al principio, pensé que sería útil dominar Mongu y hacer todo bien. Luego, lentamente comencé a comprender que organizar la comunicación con la base de datos también es un arte en el que puedes hacer carreras y solo cometer errores. Por ejemplo, si dos mensajes del tipo /subscribe llegan del usuario, y en respuesta a cada uno, crearemos una entrada en la placa, porque al momento de procesar esos mensajes, el usuario no está firmado. Tenía la sospecha de que la comunicación con la monga en la forma existente no estaba escrita de la mejor manera. Por ejemplo, la configuración del usuario se creó en el momento en que se registró. Si trató de cambiarlos antes del hecho de la suscripción ... el bot no respondió, porque el código en el actor subió a la base de datos para la configuración, no pudo encontrarlo y se bloqueó. A la pregunta: ¿por qué no crear las configuraciones según sea necesario? Descubrí que no hay nada que las cambie si el usuario no se ha suscrito ... De alguna manera, el sistema de filtrado de mensajes no se hizo evidente, e incluso después de mirar detenidamente el código no pude entender si fue concebido originalmente o hay un error
No había una lista de artículos enviados al chat; en cambio, se sugirió que los escribiera yo mismo. Esto me sorprendió, en general, no me opuse a arrastrar todo tipo de piezas al proyecto, pero sería lógico tirar de estas cosas y atornillarlas. Pero no, el segundo participante parece haber olvidado todo, pero dijo que la lista dentro del chat supuestamente es una mala decisión, y que necesita hacer una placa con eventos como "el artículo x fue enviado al usuario x". Luego, si el usuario solicitaba enviar nuevos artículos, era necesario enviar una solicitud a la base de datos, cuál de los eventos seleccionaría eventos relacionados con el usuario, aún así obtener una lista de nuevos artículos, filtrarlos, enviarlos al usuario y lanzar eventos al respecto en la base de datos.
El segundo participante en algún lugar sufrió en la dirección de las abstracciones, cuando el bot no solo recibirá artículos de Habr y no solo se enviará a telegramas.
De alguna manera implementé los eventos en forma de una tableta separada para la segunda mitad de septiembre. No es óptimo, pero el bot al menos funcionó y comenzó a enviarme artículos nuevamente, y lentamente descubrí lo que estaba sucediendo en el código.
Ahora puede volver primero y recordar que el repositorio no fue creado originalmente por mí. ¿Qué pudo haber ido así? Mi solicitud de grupo fue rechazada. Resultó que tenía un código corto, que no sabía cómo trabajar en un equipo y que tenía que editar errores en la curva de implementación actual, y no modificarlo a un estado utilizable.
Estaba molesto, miré el historial de confirmaciones, la cantidad de código escrito. Miré los momentos que originalmente estaban bien escritos, y luego volví a analizar ...
A la mierda
Me acordé del artículo No eres Google .
Pensé que nadie realmente necesita una idea sin implementación. Pensé que quiero tener un bot que funcione que funcione en una sola copia en una sola computadora como un simple programa java. Sé que mi bot funcionará durante meses sin reinicios, ya que en el pasado escribí tales bots. Si de repente se cae y no envía el siguiente artículo al usuario, el cielo no caerá sobre la tierra y no ocurrirá nada catastrófico.
¿Por qué necesito un docker, mongoDB y otro software de culto de carga "serio", si el código no funciona de manera estúpida o funciona de forma torcida?
Bifurqué el proyecto e hice todo lo que quería.
Casi al mismo tiempo, cambié mi trabajo y faltaba mucho tiempo libre. En la mañana me desperté exactamente en el tren, regresé tarde en la noche y no quería hacer nada más. No hice nada por un tiempo, luego superé el deseo de terminar el bot y comencé a reescribir lentamente el código mientras conducía al trabajo por la mañana. No puedo decir que haya sido productivo: no es muy conveniente sentarse en un tren tembloroso con una computadora portátil en su regazo y mirar el desbordamiento de la pila desde su teléfono. Sin embargo, el tiempo detrás de escribir el código pasó completamente desapercibido, y el proyecto comenzó a moverse lentamente a un estado de funcionamiento.
En algún lugar en el fondo había un gusano de duda que mongoDB quería usar, pero pensé que hay desventajas notables además de las ventajas con el almacenamiento de estado "confiable":
- La base de datos se convierte en otro punto de falla.
- El código se está volviendo más difícil y lo escribiré por más tiempo.
- El código se vuelve lento e ineficiente; en lugar de cambiar el objeto en la memoria, los cambios se envían a la base de datos y se retiran si es necesario.
- Existen restricciones sobre el tipo de almacenamiento de eventos en una placa separada, que están asociadas con las características de la base de datos.
- En la versión de prueba de monga hay algunas restricciones, y si te topas con ellas, tendrás que iniciar y configurar el mongu para algo.
Bebí Mongu, ahora el estado del bot simplemente se almacena en la memoria del programa y de vez en cuando se guarda en un archivo en forma de json. Quizás en los comentarios escriban que estoy equivocado, porque aquí es donde debes usarlo, etc. Pero este es mi proyecto, el enfoque con el archivo es lo más simple posible y funciona de manera transparente.
Arrojé valores mágicos como -1 y devolví la Option normal, agregué almacenamiento de una placa hash con los artículos enviados de vuelta al objeto con información de chat. Se agregó la eliminación de información sobre artículos de más de cinco días, para no almacenar todo en una fila. Puso el registro en condiciones de trabajo: los registros en cantidades razonables se escriben tanto en el archivo como en la consola. Se agregaron varios comandos de administración como guardar estado u obtener estadísticas como la cantidad de usuarios y artículos.
Arreglé un montón de cosas pequeñas: por ejemplo, los artículos ahora indican la cantidad de vistas, me gusta, disgustos y comentarios en el momento en que se pasó el filtro de usuario. En general, es sorprendente cuántas pequeñas cosas tuvieron que arreglarse. Mantuve una lista, anoté todas las "asperezas" allí y las corregí lo más posible.
Por ejemplo, agregué la capacidad de establecer todas las configuraciones directamente en un mensaje:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
Y el comando /settings muestra en este formulario, puede tomar texto y enviar todos los ajustes a un amigo.
Parece ser un poco, pero hay docenas de matices similares.
Se implementó el filtrado de artículos en forma de un modelo lineal simple: el usuario puede establecer una calificación adicional para autores y etiquetas, así como un valor umbral. Si la suma de la calificación del autor, la calificación promedio de las etiquetas y la calificación real del artículo es mayor que el valor umbral, entonces el artículo se muestra al usuario. Puede solicitar artículos al bot con el comando / new, o suscribirse al bot y arrojará artículos en PM en cualquier momento del día.
En términos generales, tuve una idea para cada artículo para dibujar más signos (centros, la cantidad de comentarios, marcadores, la dinámica de los cambios de calificación, la cantidad de texto, imágenes y código en el artículo, palabras clave) y el usuario para mostrar el voto ok / not ok debajo de cada artículo y para cada usuario para entrenar el modelo, pero me volví demasiado vago.
Además, la lógica del trabajo no será tan obvia. Ahora puedo poner manualmente una calificación de +9000 para el paciente Zero y con una calificación de umbral de +20 se me garantizará recibir todos sus artículos (a menos, por supuesto, pongo -100500 para cualquier etiqueta).
La arquitectura resultante fue bastante simple:
- Un actor que almacena el estado de todos los chats y artículos. Carga su estado desde un archivo en el disco y de vez en cuando lo guarda de nuevo, cada vez en un nuevo archivo.
- Un actor que ocasionalmente se encuentra con el feed RSS aprende sobre nuevos artículos, mira los enlaces, analiza y envía estos artículos al primer actor. Además, a veces le pide al primer actor una lista de artículos, selecciona aquellos que no tienen más de tres días, pero que no se han actualizado durante mucho tiempo, y los actualiza.
- Un actor que se comunica con un telegrama. Todavía tomé el análisis de los mensajes completamente aquí. En el buen sentido, quiero dividirlo en dos, para que uno analice los mensajes entrantes y el segundo trate con problemas de transporte, como el reenvío de mensajes no enviados. Ahora no hay reenvío, y el mensaje que no llegó debido a un error simplemente se perderá (excepto que se marcará en los registros), pero hasta ahora esto no causa problemas. Quizás surjan problemas si un grupo de personas se suscribe al bot y alcanzo el límite para enviar mensajes).
Lo que me gustó: gracias a Akka, la caída de los actores 2 y 3 en general no afecta el rendimiento del bot. Quizás algunos artículos no se actualicen a tiempo o algunos mensajes no lleguen al telegrama, pero Akka reinicia al actor y todo continúa funcionando aún más. Guardo la información de que el artículo se muestra al usuario solo cuando el actor de telegramas responde que entregó el mensaje con éxito. Lo peor que me amenaza es enviar un mensaje varias veces (si se entrega, pero la confirmación se pierde de alguna manera desconocida). En principio, si el primer actor no mantuvo el estado en sí mismo, sino que se comunicó con algún tipo de base de datos, entonces también podría caer silenciosamente y volver a la vida. También podría intentar la persistencia akka para restaurar el estado de los actores, pero la implementación actual me conviene con su simplicidad. No es que mi código se bloquee a menudo, por el contrario, me esfuerzo mucho para que esto sea imposible. Pero sucede una mierda, y la capacidad de dividir el programa en piezas aisladas-actores me pareció realmente conveniente y práctica.
Se agregó circle-ci para saber de inmediato cuando se rompe el código. Al menos que el código ha dejado de compilarse. Inicialmente, quería agregar travis, pero solo mostraba mis proyectos sin bifurcaciones. En general, ambas cosas se pueden usar libremente en repositorios abiertos.
Resumen
Ya es noviembre. El bot está escrito, lo usé durante las últimas dos semanas y me gustó. Si tiene ideas para mejorar, escriba. No veo el punto de monetizarlo, déjelo funcionar y envíe artículos interesantes.
Enlace al bot: https://t.me/HabraFilterBot
Github: https://github.com/Kright/habrahabr_reader
Pequeñas conclusiones:
- Incluso un proyecto pequeño puede llevar mucho tiempo.
- No eres Google No tiene sentido disparar a un gorrión desde un cañón. Una solución simple puede funcionar igual de bien.
- Los proyectos de mascotas son muy adecuados para experimentar con nuevas tecnologías.
- Los bots de Telegram están escritos de manera bastante simple. Si no fuera por "trabajo en equipo" y experimentos con tecnologías, el bot habría sido escrito en una semana o dos.
- El modelo de actor es una cosa interesante que combina bien con subprocesos múltiples y resistencia de código.
- Parece que siento por mí mismo por qué la comunidad de código abierto ama los tenedores.
- Las bases de datos son buenas porque el estado de la aplicación ya no depende de los bloqueos / reinicios de la aplicación, pero trabajar con la base de datos complica el código e impone restricciones en la estructura de datos.