Recientemente,
se llevó a cabo el Desafío de voz de I + D ID Antispoofing , cuya tarea principal era crear un algoritmo que pueda distinguir una voz humana de un registro sintetizado (parodia). Soy investigador de ML en Dasha AI y trabajo mucho en el reconocimiento de voz, así que decidí participar. Junto con el equipo tomamos el primer lugar. Debajo del corte, hablaré sobre nuevos enfoques geniales para el procesamiento de sonido, así como sobre las dificultades y rarezas que tuvimos que enfrentar.
Participaron 98 personas en la competencia: hay muy poca gente porque se trata de una competencia de procesamiento de sonido en una plataforma rusa, e incluso en un acoplador. Estaba en un equipo con Dmitry Danevsky, maestro de Kaggle, a quien conocimos y acordamos participar mientras discutíamos los enfoques en otra competencia.
Desafío
Nos dieron 5 GB de archivos de audio, divididos en clases falsas / humanas, y tuvimos que predecir la probabilidad de la clase, envolverla en una ventana acoplable y enviarla al servidor. Se suponía que la solución debía funcionar en 30 minutos y pesar menos de 100 MB. Según la información oficial, era necesario distinguir entre la voz de una persona y la que se genera automáticamente, aunque personalmente me pareció que la clase de parodia también incluía casos en los que el sonido se generaba al llevar el altavoz al micrófono (como hacen los atacantes al robar una grabación de la voz de otra persona para su identificación).
La métrica era
EER :
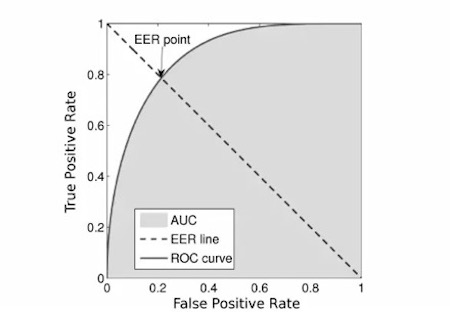
Tomamos el
primer código que surgió de la red, porque el
código de los organizadores parecía estar sobrecargado.
Competencia
Los organizadores proporcionaron la línea de base y al mismo tiempo el enigma principal de la competencia. Era tan simple como un palo: tomamos archivos de audio, contamos
espectrogramas de tiza , entrenamos MobileNetV2 y nos encontramos en algún lugar alrededor del duodécimo lugar o menos. Debido a esto, muchos habrían pensado que una docena de personas participaron en la competencia, pero esto no fue así. Durante toda la primera etapa de la competencia, nuestro equipo no pudo romper esta línea de base. El código idealmente idéntico dio el resultado mucho peor, y cualquier mejora (como reemplazar con cuadrículas más pesadas y predicciones
OOF ) ayudó, pero no lo acercó a la línea base.
Y luego sucedió lo inesperado: aproximadamente una semana antes del final de la competencia, resultó que la implementación del conteo de las métricas de los organizadores contenía un error y dependía del orden de las predicciones. Casi al mismo tiempo, se descubrió que en los contenedores acoplables los organizadores no apagaban amablemente Internet, por lo que muchos descargaban la muestra de prueba. Luego, el concurso se congeló durante 4 días, corrigió la métrica, actualizó los datos, apagó Internet y comenzó nuevamente durante otras 2 semanas. Después del recuento, estábamos en el séptimo lugar con una de nuestras primeras presentaciones. Esto sirvió como una poderosa motivación para continuar participando en la competencia.
Hablando de modelo
Utilizamos una cuadrícula de convolución similar a la de una resnet entrenada sobre espectrogramas de tiza.
- Hubo 5 de esos bloques en total. Después de cada uno de estos bloques, hicimos una supervisión profunda y aumentamos el número de filtros una vez y media.
- Durante la competencia, pasamos de una clasificación binaria a una de varias clases para utilizar de manera más eficiente la técnica de mezcla , en la que mezclamos dos sonidos y resumimos sus etiquetas de clase. Además, después de tal transición, pudimos aumentar artificialmente la probabilidad de la clase de parodia multiplicándola por 1.3. Esto nos ayudó, ya que existía la suposición de que el balance de clases en la muestra de prueba puede ser diferente al de entrenamiento, y por lo tanto mejoramos la calidad de los modelos.
- Se entrenaron modelos de pliegue y se promediaron las predicciones de varios modelos.
- La técnica de codificación de frecuencia también fue útil. La conclusión es: las convoluciones 2D son invariantes de posición, y en los espectrogramas los valores a lo largo del eje vertical tienen significados físicos muy diferentes, por lo que nos gustaría transferir esta información al modelo. Para hacer esto, concatenamos el espectrograma y la matriz, que consta de números en un segmento de -1 a 1 de abajo hacia arriba.
Para mayor claridad, le daré el código:
n, d, h, w = x.size() vertical = torch.linspace(-1, 1, h).view(1, 1, -1, 1) vertical = vertical.repeat(n, 1, 1, w) x = torch.cat([x, vertical], dim=1)
- Entrenamos todo esto, incluso en datos pseudo etiquetados de la muestra de prueba filtrada de la primera etapa.
Validación
Desde el comienzo de la competencia, todos los participantes fueron atormentados por la pregunta: ¿por qué la validación local da EER 0.01 y menor, y la tabla de clasificación 0.1 y no se correlaciona particularmente? Teníamos 2 hipótesis: o había duplicados en los datos, o los datos de entrenamiento se recopilaron en un conjunto de altavoces y los datos de prueba en otro.
La verdad estaba en algún punto intermedio. En los datos de entrenamiento, aproximadamente el 5% de los datos resultaron ser duplicados, y esto solo cuenta duplicados completos de los hashes (por cierto, también podría contener diferentes cultivos del mismo archivo, pero no es tan fácil de verificar, por eso no lo hicimos).
Para probar la segunda hipótesis, entrenamos una cuadrícula de identificación del hablante, recibimos incrustaciones para cada hablante, agrupamos todo con k-medias y los doblamos para estratificarlos. A saber, capacitamos en altavoces de un grupo y pronosticamos altavoces de otros. Este método de validación ya ha comenzado a correlacionarse con la tabla de clasificación, aunque mostró una puntuación 3-4 veces mejor. Como alternativa, tratamos de validar solo en predicciones en las que el modelo era al menos un poco inseguro, es decir, la diferencia entre la predicción y la etiqueta de clase era> 10 ** - 4 (0.0001), pero ese esquema no arrojó resultados.
¿Y qué no funcionó?
En Internet, basta con encontrar miles de horas de discurso humano. Además, una competencia similar ya se celebró hace varios años. Por lo tanto, parecía una idea obvia descargar muchos datos (descargamos ~ 300 GB) y entrenar al clasificador en esto. En algunos casos, el entrenamiento sobre dichos datos resultó un poco si enseñamos sobre datos adicionales y sobre el tren antes de alcanzar una meseta, y luego solo entrenamos sobre datos de entrenamiento. Pero con este esquema, el modelo convergió en aproximadamente 2 días, lo que significó 10 días para todos los pliegues. Por lo tanto, abandonamos esta idea.
Además, muchos participantes notaron una correlación entre la longitud del archivo y la clase; esta correlación no se notó en la muestra de prueba. Las cuadrículas de imágenes comunes como resnext, nasnet-mobile, mobileNetV3 no se mostraron muy bien.
Epílogo
No fue fácil y a veces extraño, pero aún así tuvimos una experiencia genial y salimos a la cabeza. A través de prueba y error, me di cuenta de qué enfoques funcionan bastante bien y cuáles no son muy buenos. Ahora usaré estas ideas con nosotros cuando procese el sonido. Trabajo duro para llevar la IA conversacional a un nivel indistinguible del humano y, por lo tanto, siempre en la búsqueda de tareas y chips interesantes. Espero que también hayas aprendido algo nuevo.
Bueno, finalmente, publico
nuestro código .