En los primeros dos artículos, planteé el tema de la automatización y esbocé su marco, en el segundo hice una digresión sobre la virtualización de la red, como el primer enfoque para automatizar la configuración de los servicios.
Y ahora es el momento de dibujar un diagrama de red física.
Si no está muy cerca del dispositivo de las redes de centros de datos, le recomiendo comenzar con un
artículo sobre ellas .
Todos los problemas:
Las prácticas descritas en esta serie deberían ser aplicables a una red de cualquier tipo, cualquier escala, con cualquier variedad de proveedores (no). Sin embargo, no se puede describir un ejemplo universal de la aplicación de estos enfoques. Por lo tanto, me enfocaré en la arquitectura moderna de la red DC:
Klose Factory .
DCI lo hará en MPLS L3VPN.
Una red Overlay del host se ejecuta sobre la red física (puede ser OpenStack VXLAN o Tungsten Fabric o cualquier otra cosa que requiera solo conectividad IP básica de la red).
En este caso, obtenemos un escenario relativamente simple para la automatización, porque tenemos muchos equipos configurados de la misma manera.
Elegiremos un DC esférico en el vacío:
- Una versión del diseño está en todas partes.
- Dos vendedores que forman dos planos de la red.
- Un DC es como otro como dos gotas de agua.
Contenido
- Topología física
- Enrutamiento
- Plan de propiedad intelectual
- Laba
- Conclusión
- Enlaces utiles
Deje que nuestro proveedor de servicios LAN_DC, por ejemplo, organice videos de capacitación sobre la supervivencia en ascensores atascados.
En las megaciudades, esto es muy popular, por lo que hay muchas máquinas físicas.
Primero, describiré la red aproximadamente como me gustaría verla. Y luego lo simplificaré para el laboratorio.
Topología física
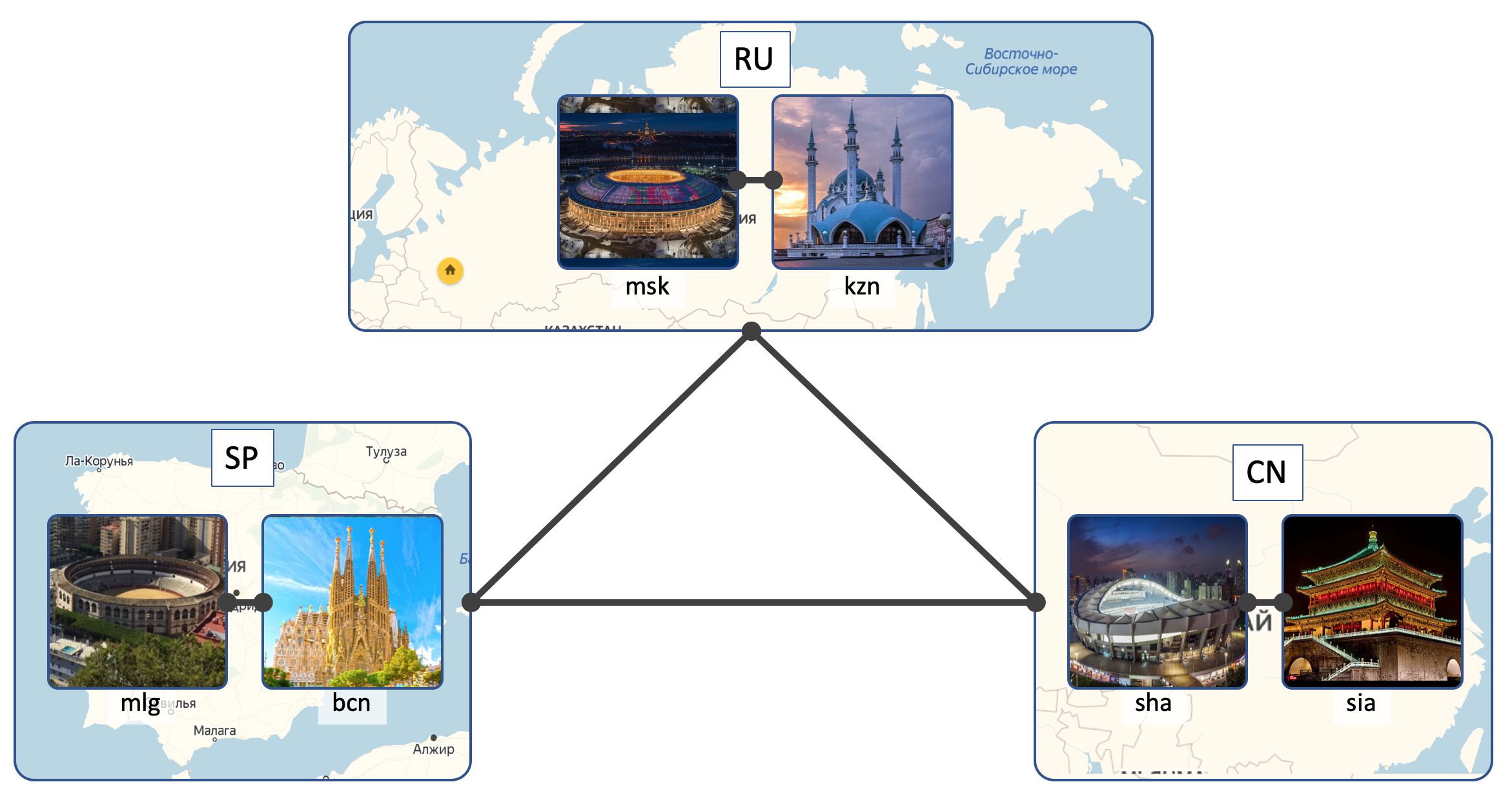
Localizaciones
LAN_DC tendrá 6 DC:
- Rusia ( RU ):
- Moscú ( msk )
- Kazán ( kzn )
- España ( SP ):
- Barcelona ( bcn )
- Málaga ( mlg )
- China ( CN ):
- Shangai ( sha )
- Xi'an ( sia )
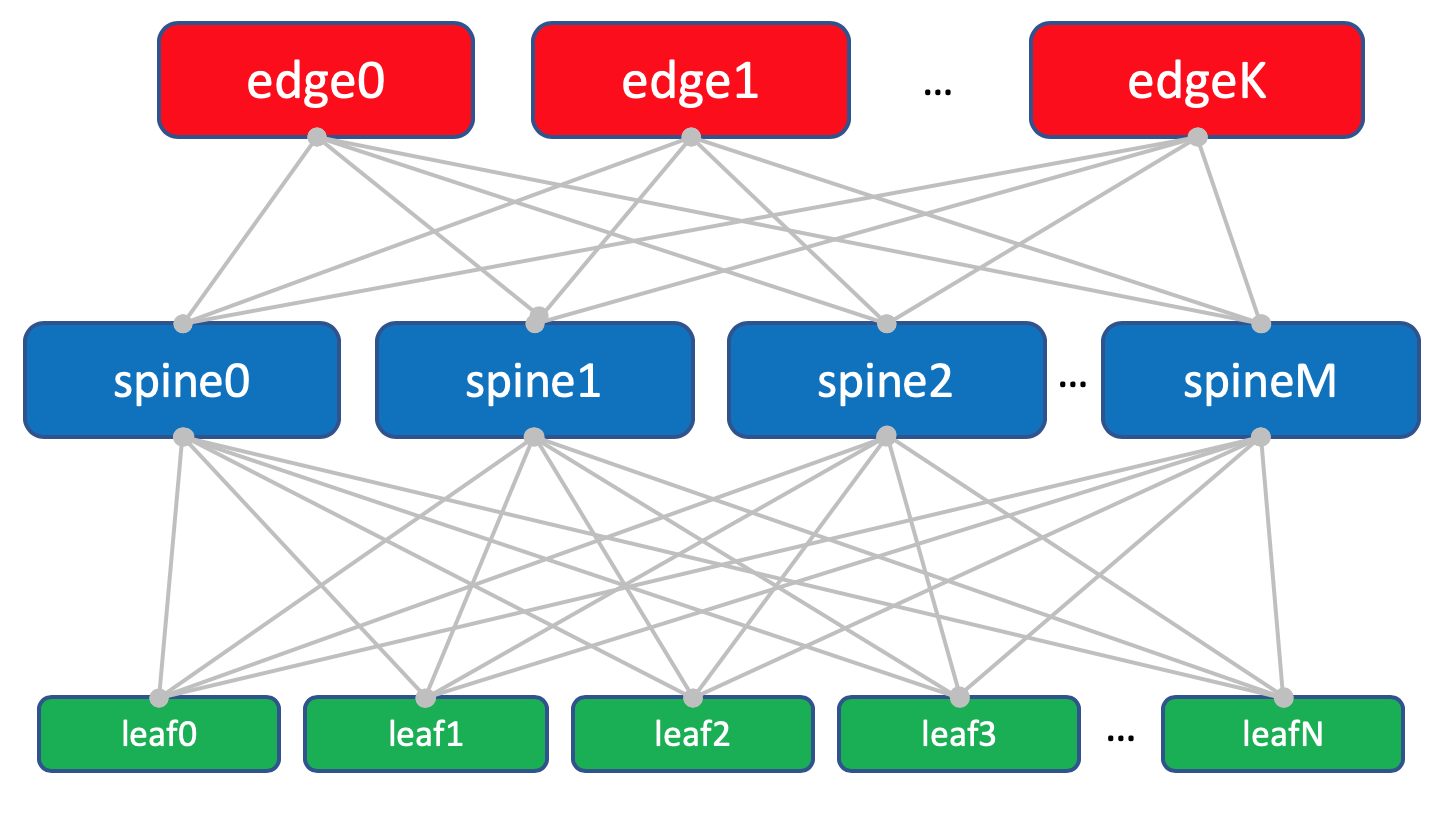
DC interior (Intra-DC)
En todos los DC, redes de conectividad interna idénticas basadas en la topología de Clos.
¿Qué tipo de redes son Klose y por qué están en un
artículo separado?
En cada DC hay 10 bastidores con automóviles, se numerarán como
A ,
B ,
C , etc.
Cada estante tiene 30 autos. No nos interesarán.
Además, en cada bastidor hay un interruptor al que están conectadas todas las máquinas; este es
el interruptor de la parte superior del bastidor: ToR o, en términos de la fábrica de Klose, lo llamaremos
Leaf .
 El esquema general de la fábrica.
El esquema general de la fábrica.Los denominaremos
XXX -leaf Y , donde
XXX es la abreviatura de tres letras DC, e
Y es el número de serie. Por ejemplo,
kzn-leaf11 .
En los artículos me permito usar los términos Leaf y ToR de manera bastante frívola, como sinónimos. Sin embargo, uno debe recordar que esto no es así.
ToR es un interruptor montado en bastidor al que se conectan las máquinas.
Leaf es el papel de un dispositivo en una red física o un conmutador de primer nivel en términos de topología de Clos.
Es decir, Leaf! = ToR.
Entonces Leaf puede ser un interruptor EndofRaw, por ejemplo.
Sin embargo, dentro del marco de este artículo, nos referiremos a ellos como sinónimos.
Cada interruptor ToR está conectado a su vez a cuatro interruptores de agregación aguas arriba:
columna vertebral . Bajo Spine'y asignó un bastidor en el DC. Lo
nombraremos de la misma manera:
XXX -spine Y.En el mismo bastidor habrá equipos de red para la conectividad entre DC - 2 enrutadores con MPLS a bordo. Pero en general, estos son los mismos ToR. Es decir, desde el punto de vista de los interruptores de columna, no importa si hay un ToR habitual con máquinas conectadas o un enrutador para DCI: una cosa maldita.
Tales ToR especiales se denominan
Edge-leaf . Los llamaremos
XXX- edge Y.Se verá así.

En el diagrama sobre el borde y la hoja que realmente puse en el mismo nivel.
Las redes clásicas de tres niveles nos han enseñado a considerar el enlace ascendente (el término es en realidad de aquí), como enlaces ascendentes. Y aquí resulta que el "enlace ascendente" de DCI vuelve a bajar, lo que rompe un poco la lógica habitual. En el caso de redes grandes, cuando los centros de datos se dividen en unidades más pequeñas:
POD (Punto de entrega), se asignan
Edge-POD separados para DCI y acceso a redes externas.
Por conveniencia, en el futuro aún dibujaré Edge on Spine, mientras tenemos en cuenta que no hay inteligencia sobre Spine y diferencias al trabajar con Leaf y Edge-leaf ordinarios (aunque puede haber matices, pero en general es así)
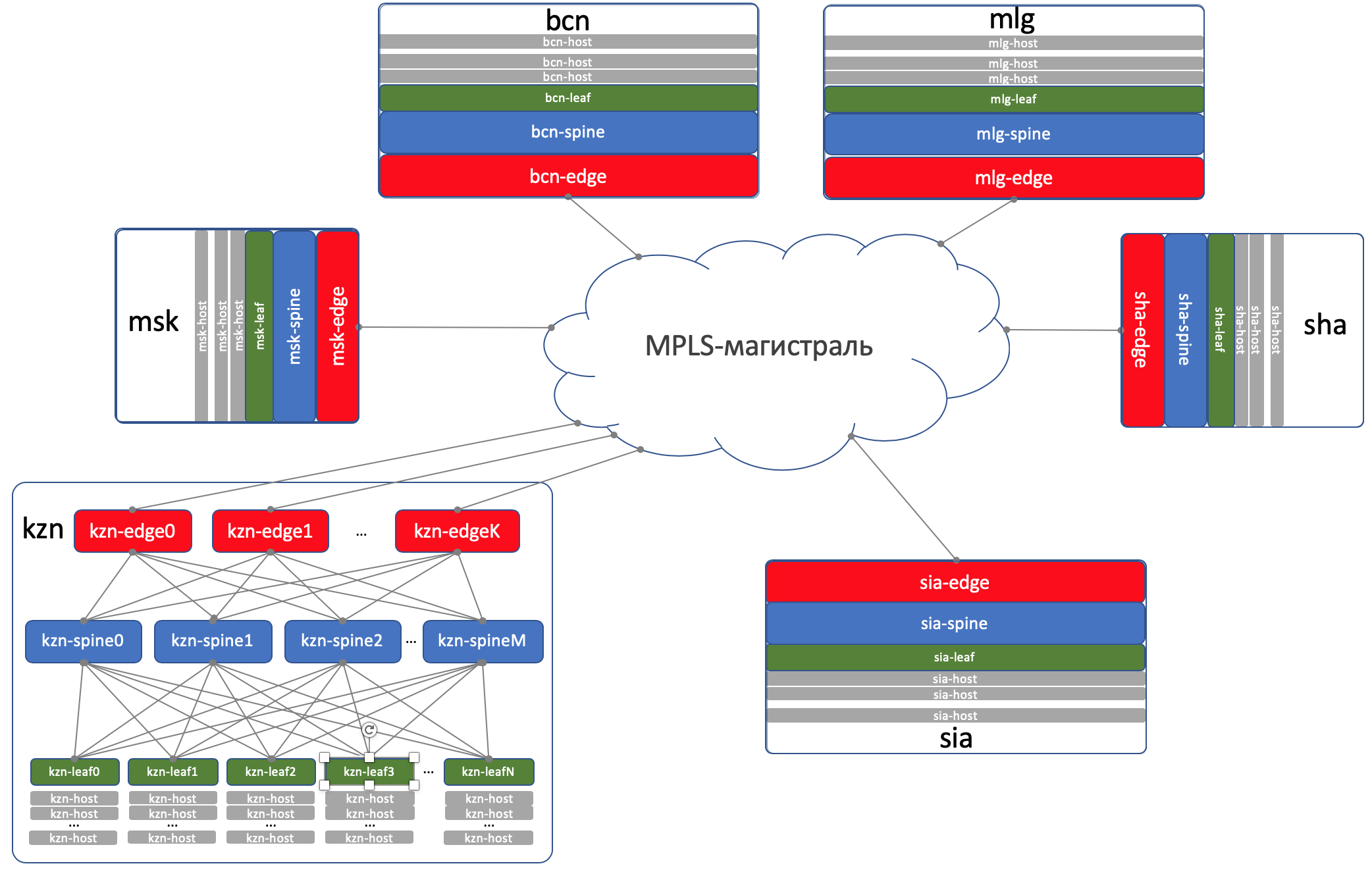
 Diseño de fábrica con hojas de borde.
Diseño de fábrica con hojas de borde.Trinity Leaf, Spine y Edge forman una red o fábrica de Underlay.
La tarea de la fábrica de red (leer Underlay), como ya hemos determinado en el
número anterior , es muy, muy simple: proporcionar conectividad IP entre máquinas tanto dentro de la misma DC como entre ellas.
Es por eso que la red se llama fábrica, al igual que, por ejemplo, una fábrica de conmutación dentro de cajas de red modular, que se puede encontrar con más detalle en
SDSM14 .
En general, dicha topología se denomina fábrica, porque la tela en traducción es una tela. Y es difícil no estar de acuerdo:

Fábrica completamente L3. Sin VLAN, sin transmisión: estos son excelentes programadores en LAN_DC, pueden escribir aplicaciones que viven en el paradigma L3, y las máquinas virtuales no requieren Live Migration para guardar la dirección IP.
Y de nuevo: la respuesta a la pregunta por qué la fábrica y por qué L3 - en un
artículo separado.
DCI - Interconexión del centro de datos (Inter-DC)
DCI se organizará utilizando Edge-Leaf, es decir, son nuestro punto de salida a la autopista.
Para simplificar, asumimos que los DC están conectados por enlaces directos.
Excluimos la conectividad externa de la consideración.
Soy consciente de que cada vez que elimino un componente, simplifico enormemente la red. Y con la automatización de nuestra red abstracta, todo estará bien, pero aparecerán muletas en la red real.
Eso es asi. Sin embargo, el objetivo de esta serie es pensar y trabajar en enfoques, y no resolver heroicamente problemas imaginarios.
En Edge-Leafs, la capa subyacente se coloca en la VPN y se transmite a través de la red troncal MPLS (el mismo enlace directo).
Aquí hay un esquema de alto nivel.
Enrutamiento
Para el enrutamiento dentro de DC usaremos BGP.
En OSPF + LDP MPLS Trunk
Para DCI, es decir, la organización de la conectividad en la parte inferior es BGP L3VPN sobre MPLS.
 Esquema general de enrutamiento
Esquema general de enrutamientoNo hay OSPF e ISIS en la fábrica (el protocolo de enrutamiento está prohibido en la Federación de Rusia).
Y esto significa que no habrá Autodescubrimiento y cálculos de ruta más corta, solo configuraciones de protocolo, vecindad y políticas manuales (de hecho automáticas, estamos aquí sobre la automatización).
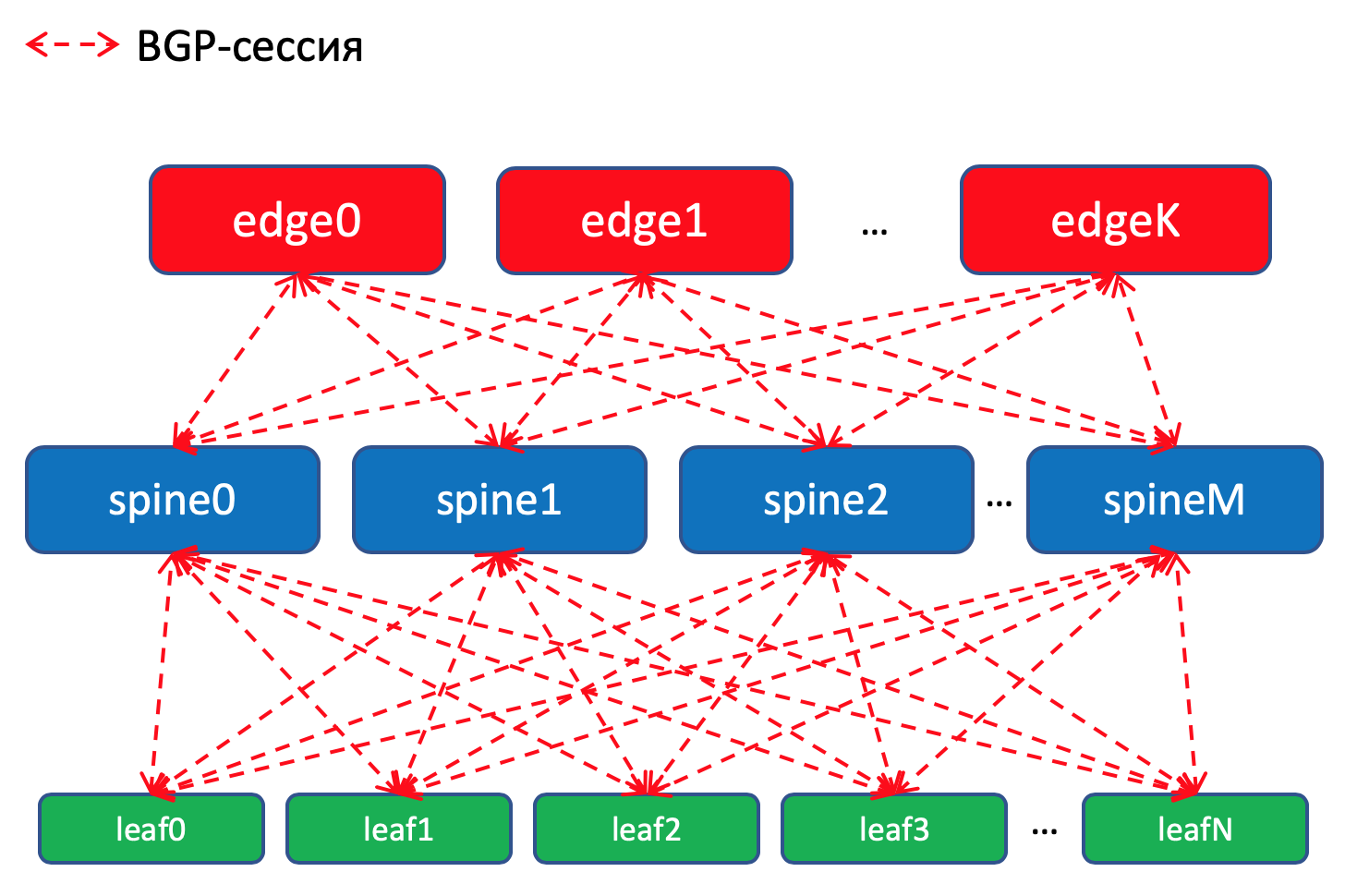 Esquema de enrutamiento BGP dentro del DC¿Por qué BGP?
Esquema de enrutamiento BGP dentro del DC¿Por qué BGP?Hay
un RFC completo llamado Facebook y Arista sobre este tema, que explica cómo construir redes
muy grandes de centros de datos utilizando BGP. Se lee casi como un arte, muy recomendable para una noche lánguida.
Y toda una sección de mi artículo está dedicada a esto. ¿A dónde te estoy
enviando?Pero aún así, en resumen, ningún IGP es adecuado para redes de grandes centros de datos, donde cuentan miles de dispositivos de red.
Además, el uso de BGP en todas partes le permite no rociar el soporte de varios protocolos diferentes y la sincronización entre ellos.
Mano a mano, en nuestra fábrica, que con un alto grado de probabilidad no crecerá rápidamente, OSPF sería suficiente para los ojos. Estos son en realidad los problemas de los megaescalers y los titanes en la nube. Pero imaginemos algunos problemas que necesitamos, y usaremos BGP, como legó Peter Lapukhov.
Políticas de enrutamiento
En los conmutadores Leaf, importamos en prefijos BGP desde interfaces Underlay con redes.
Tendremos una sesión de BGP entre
cada par Leaf-Spine en el que estos prefijos de Underlay se anunciarán en una red de charcos.

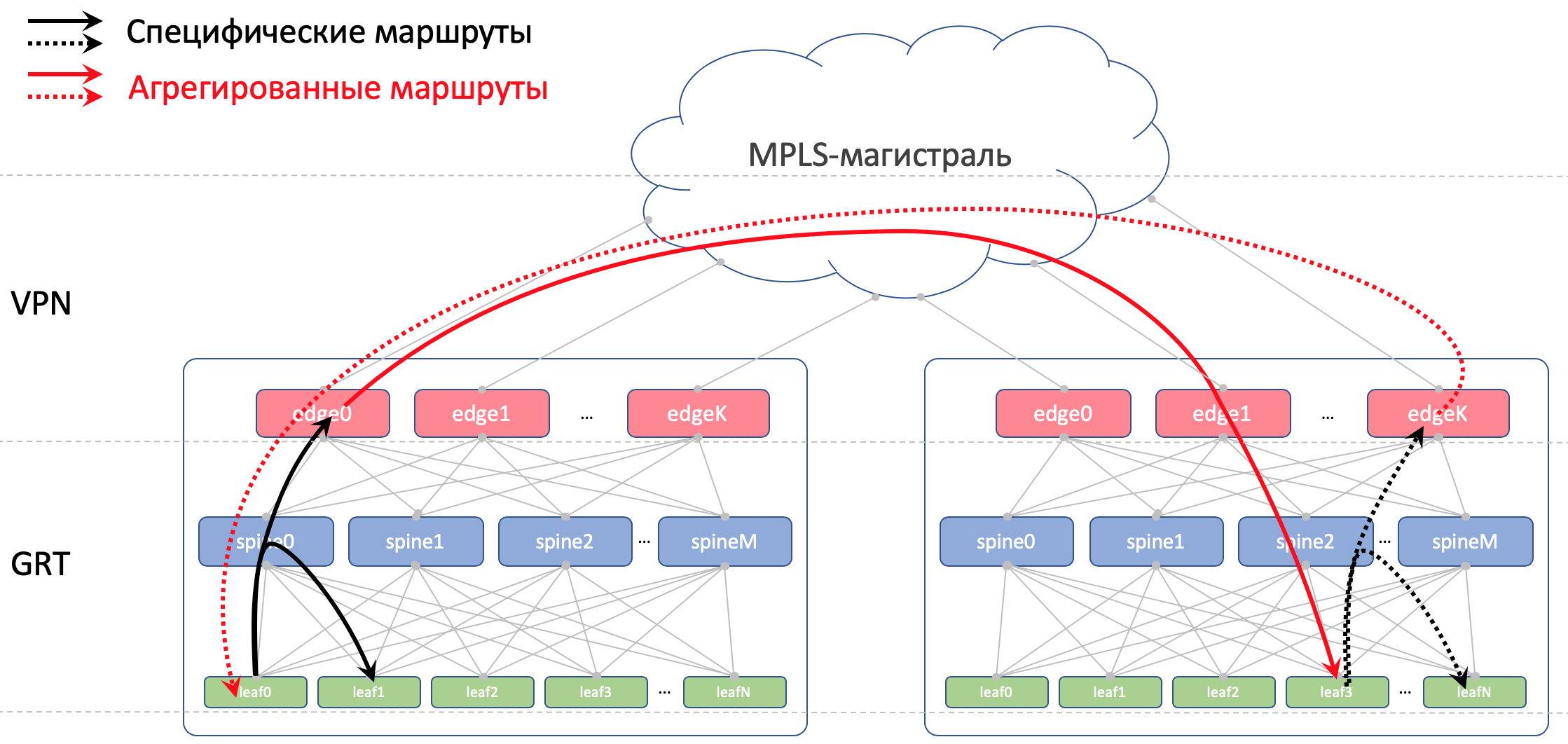
Dentro de un centro de datos, distribuiremos los detalles que se importaron a ToRe. En Edge-Leafs los agregaremos y anunciaremos en DC remotos y los reduciremos a ToR. Es decir, cada ToR sabrá exactamente cómo llegar a otro ToR en el mismo DC y dónde está el punto de entrada para llegar al ToR en otro DC.
En DCI, las rutas se transmitirán como VPNv4. Para hacer esto, en Edge-Leaf, la interfaz de la fábrica se colocará en VRF, llamémosla UNDERLAY, y el vecindario con Spine on the Edge-Leaf se elevará dentro del VRF, y entre Edge-Leafs en la familia VPNv4.
Y también prohibiremos volver a anunciar rutas recibidas de las espinas, de regreso a ellas.
En Leaf and Spine, no importaremos Loopbacks. Solo los necesitamos para determinar la ID del enrutador.
Pero en Edge-Leafs lo importamos a Global BGP. Entre las direcciones de bucle invertido, Edge Leafs establecerá una sesión BGP en la familia VPN IPv4 entre sí.
Entre los dispositivos EDGE, tendremos una red troncal OSPF + LDP. Todo en una zona. Configuración extremadamente simple.
Aquí hay una imagen de enrutamiento.
BGP ASN
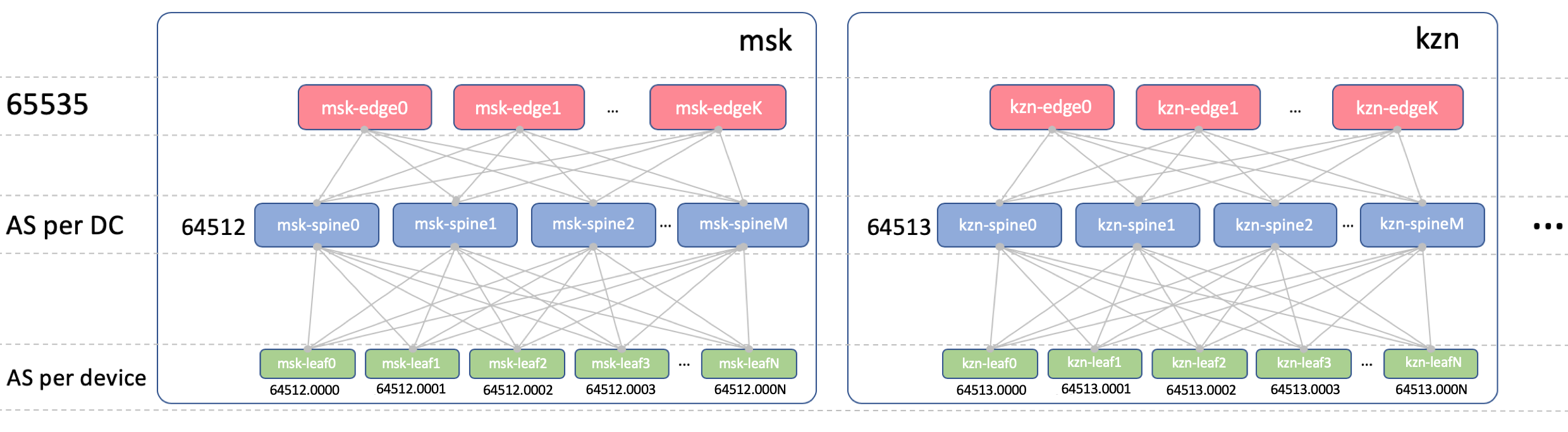
Edge-Leaf ASN
En Edge-Leafs habrá un ASN en todos los DC. Es importante que haya iBGP entre Edge-Leafs y que no nos encontremos con los matices de eBGP. Sea 65535. En realidad, podría ser un número AS público.
Columna vertebral ASN
En Spine, tendremos un ASN por DC. Comencemos aquí desde el primer número del rango AS privado: 64512, 64513, etc.
¿Por qué está ASN en DC?
Descomponemos esta pregunta en dos:
- ¿Por qué hay los mismos ASN en todas las espinas del mismo DC?
- ¿Por qué son diferentes en diferentes DC?
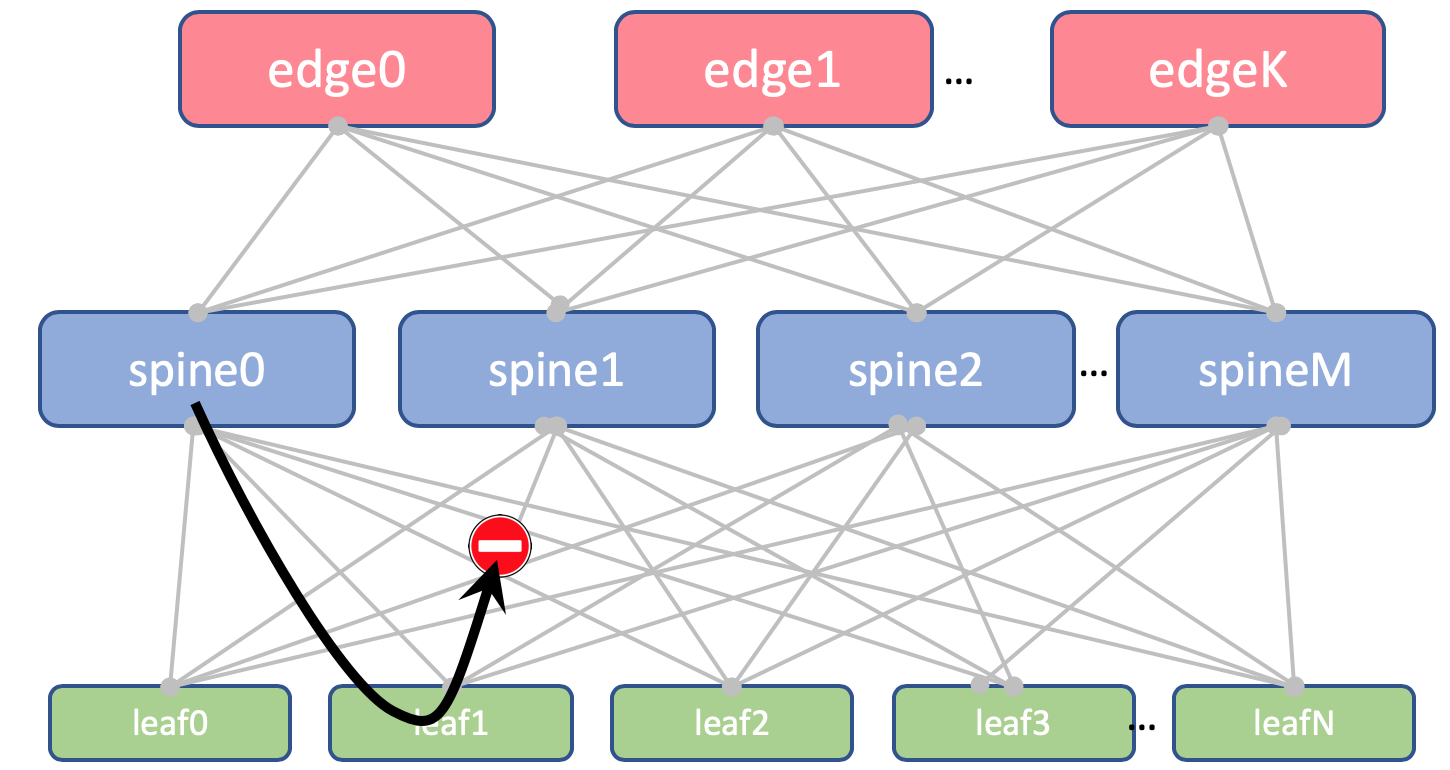
¿Por qué son los mismos ASN en todas las espinas de un DCAsí se verá la ruta AS-Path Anderlay en Edge-Leaf:
[leafX_ASN, spine_ASN , edge_ASN]Si intenta anunciarlo nuevamente a Spine, lo descartará porque su AS (Spine_AS) ya está en la lista.
Sin embargo, dentro de DC estamos completamente satisfechos de que las rutas de Underlay que subieron a Edge no podrán descender. Toda comunicación entre hosts dentro del DC debe ocurrir dentro del nivel de la columna vertebral.
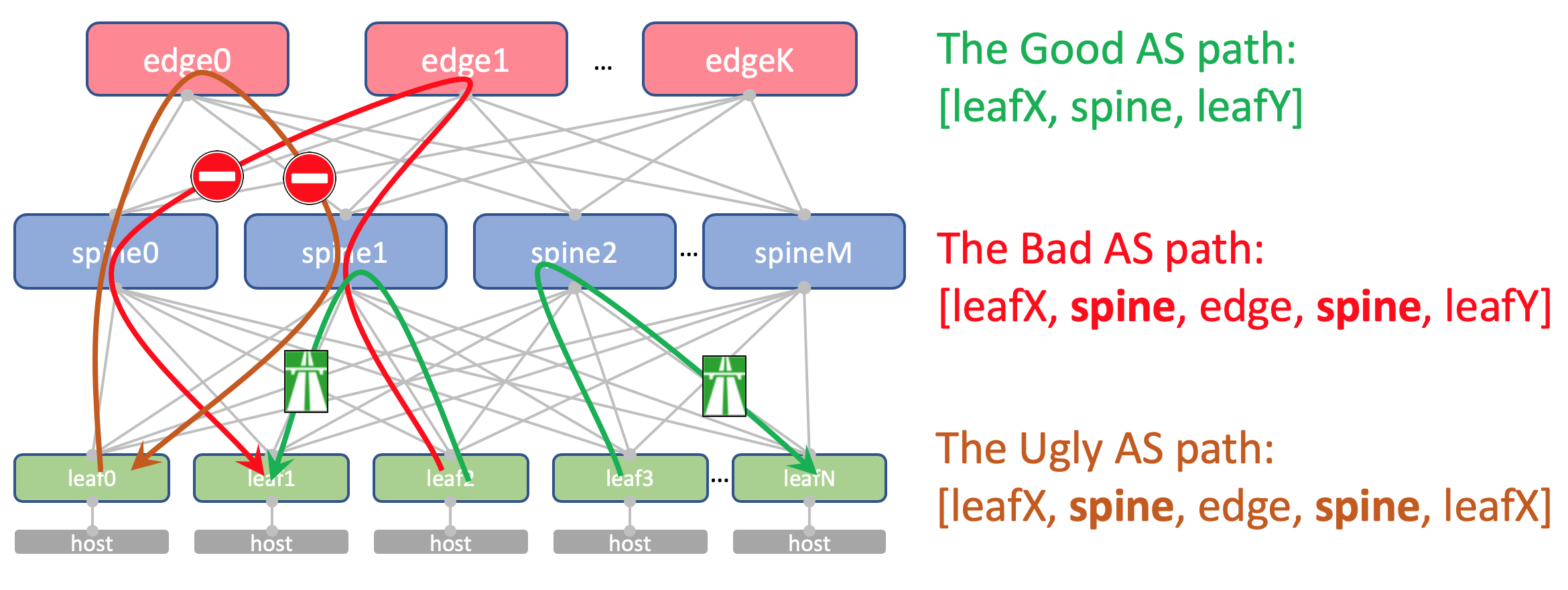
Al mismo tiempo, las rutas agregadas de otros DC en cualquier caso alcanzarán libremente los ToR: en su AS-Path solo habrá ASN 65535, el número de AS Edge-Leafs, porque fue sobre ellos que fueron creados.
¿Por qué son diferentes en diferentes DC?Teóricamente, podríamos necesitar arrastrar Loopbacks y algunas máquinas virtuales de servicio entre los DC.
Por ejemplo, en un host, ejecutaremos un Reflector de ruta o
el mismo VNGW (Virtual Network Gateway), que estará bloqueado con ToR a través de BGP y anunciará su loopback, que debería estar disponible en todos los DC.
Así que aquí está cómo se verá su AS-Path:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN , edge_ASN, spine_DC2_ASN , leafY_DC2_ASN]Y aquí no debería haber ASN duplicados en ningún lado.
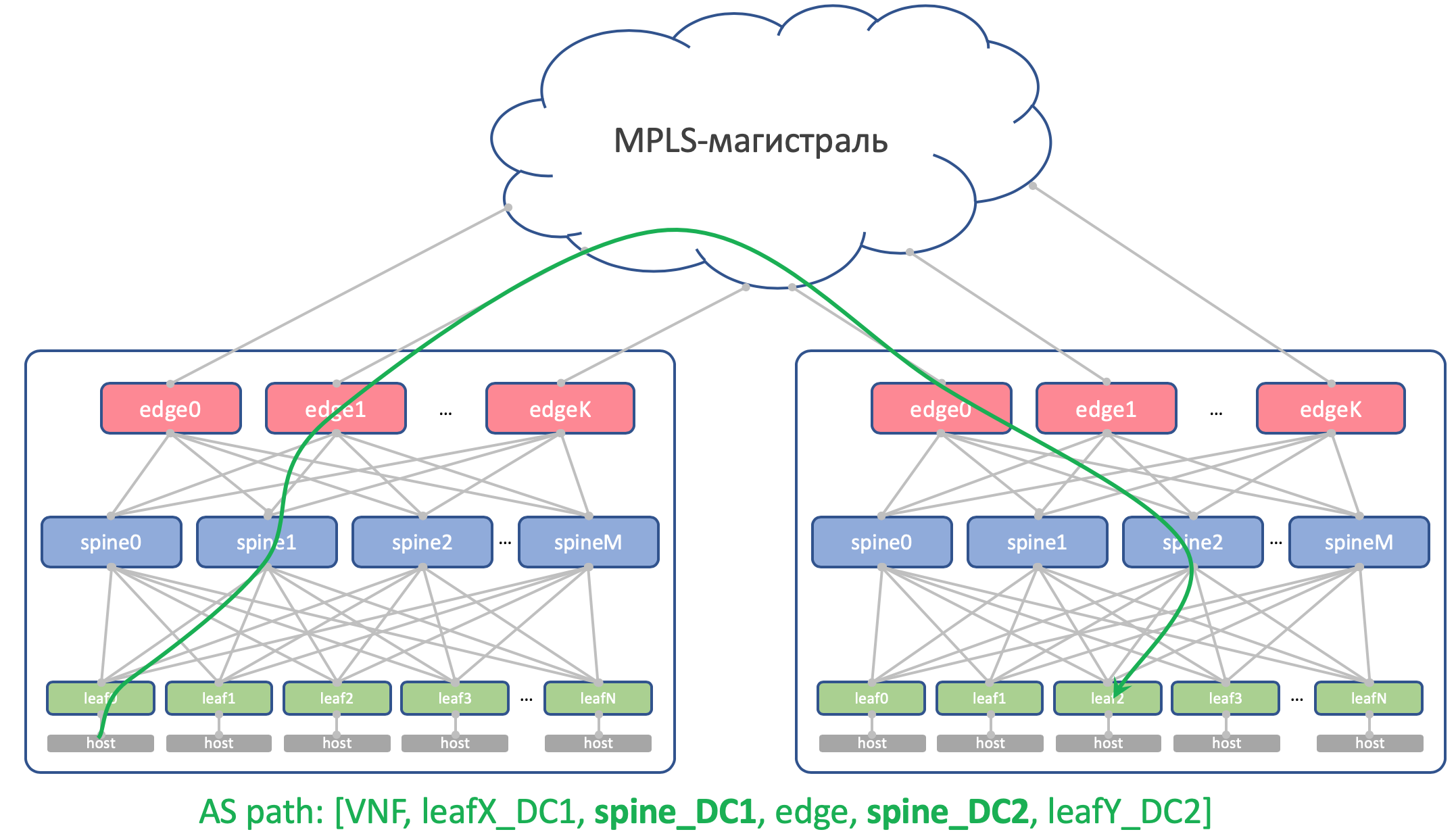
Es decir, Spine_DC1 y Spine_DC2 deberían ser diferentes, al igual que leafX_DC1 y leafY_DC2, que es exactamente a lo que nos estamos acercando.
Como probablemente sepa, hay hacks que le permiten aceptar rutas con ASN repetidos a pesar del mecanismo de prevención de bucle invertido de Cisco. E incluso tiene usos bastante legítimos. Pero esta es una brecha potencial en la resistencia de la red. Y personalmente caí en ello un par de veces.
Y si tenemos la oportunidad de no usar cosas peligrosas, lo usaremos.
Hoja asn
Tendremos un ASN individual en cada conmutador Leaf en toda la red.
Hacemos esto por las razones indicadas anteriormente: AS-Path sin bucles, configuración BGP sin marcadores.
Para que las rutas entre Leafs pasen sin obstáculos, AS-Path debería verse así:
[leafX_ASN, spine_ASN, leafY_ASN]donde leafX_ASN y leafY_ASN sería bueno ser diferente.
Esto también es necesario para la situación con el anuncio del loopback VNF entre DC:
[VNF_ASN, leafX_DC1_ASN , spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN ]Utilizaremos un ASN de 4 bytes y lo generaremos en función del ASN de Spine y el número de cambio de hoja, es decir, así:
Spine_ASN.0000X .
Aquí hay una foto con ASN.
Plan de propiedad intelectual
Básicamente, necesitamos asignar direcciones para las siguientes conexiones:
- Calibre las direcciones de red entre ToR y la máquina. Deben ser únicos en toda la red para que cualquier máquina pueda comunicarse con cualquier otra. Genial para 10/8 . Para cada estante / 26 con un margen. Asignaremos / 19 para DC y / 17 para la región.
- Direcciones de enlace entre Leaf / Tor y Spine.
Me gustaría asignarlos algorítmicamente, es decir, calcular a partir de los nombres de los dispositivos que deben conectarse.
Deja que sea ... 169.254.0.0/16.
A saber, 169.254.00X.Y / 31 , donde X es el número de la columna vertebral, Y es la red P2P / 31.
Esto le permitirá ejecutar hasta 128 bastidores y hasta 10 Spine en DC. Las direcciones de enlace pueden (y serán) repetidas de DC a DC. - Organizamos la unión Spine - Edge-Leaf en las subredes 169.254.10X.Y / 31 , donde de la misma manera X es el número de Spine, Y es la red P2P / 31.
- Vincular direcciones de Edge-Leaf a la red troncal MPLS. Aquí la situación es algo diferente: el lugar de conectar todas las piezas en un solo pastel, por lo que reutilizar las mismas direcciones no funcionará, debe seleccionar la siguiente subred libre. Por lo tanto, tomaremos 192.168.0.0/16 como base y eliminaremos a los libres.
- Direcciones de bucle invertido. Dales todo el rango 172.16.0.0/12 .
- Hoja - a / 25 por DC - los mismos 128 bastidores. Asignar por / 23 a la región.
- Spine - by / 28 en DC - hasta 16 Spine. Asignar por / 26 a la región.
- Edge-Leaf - por / 29 en DC - hasta 8 cajas. Asignar por / 27 a la región.
Si en DC no tenemos suficientes rangos seleccionados (pero no estarán allí, pretendemos ser hyper-skeylerostvo), simplemente seleccione el siguiente bloque.
Aquí hay una imagen con direccionamiento IP.

Loopbacks:
| Prefijo | Rol del dispositivo | Región | DC |
| 172.16.0.0/23 | borde | | |
| 172.16.0.0/27 | ru | |
| 172.16.0.0/29 | msk |
| 172.16.0.8/29 | kzn |
| 172.16.0.32/27 | sp | |
| 172.16.0.32/29 | bcn |
| 172.16.0.40/29 | mlg |
| 172.16.0.64/27 | cn | |
| 172.16.0.64/29 | sha |
| 172.16.0.72/29 | sia |
| 172.16.2.0/23 | columna vertebral | | |
| 172.16.2.0/26 | ru | |
| 172.16.2.0/28 | msk |
| 172.16.2.16/28 | kzn |
| 172.16.2.64/26 | sp | |
| 172.16.2.64/28 | bcn |
| 172.16.2.80/28 | mlg |
| 172.16.2.128/26 | cn | |
| 172.16.2.128/28 | sha |
| 172.16.2.144/28 | sia |
| 172.16.8.0/21 | hoja | | |
| 172.16.8.0/23 | ru | |
| 172.16.8.0/25 | msk |
| 172.16.8.128/25 | kzn |
| 172.16.10.0/23 | sp | |
| 172.16.10.0/25 | bcn |
| 172.16.10.128/25 | mlg |
| 172.16.12.0/23 | cn | |
| 172.16.12.0/25 | sha |
| 172.16.12.128/25 | sia |
Underlay:
| Prefijo | Región | DC |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk |
| 10.0.32.0/19 | kzn |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn |
| 10.0.160.0/19 | mlg |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha |
| 10.1.32.0/19 | sia |
Laba
Dos vendedores Una red ADSM
Enebro + Arista. Ubuntu Buena vieja Eva.
La cantidad de recursos en nuestro virtual en Miran todavía es limitada, por lo que para la práctica usaremos una red tan simplificada hasta el límite.
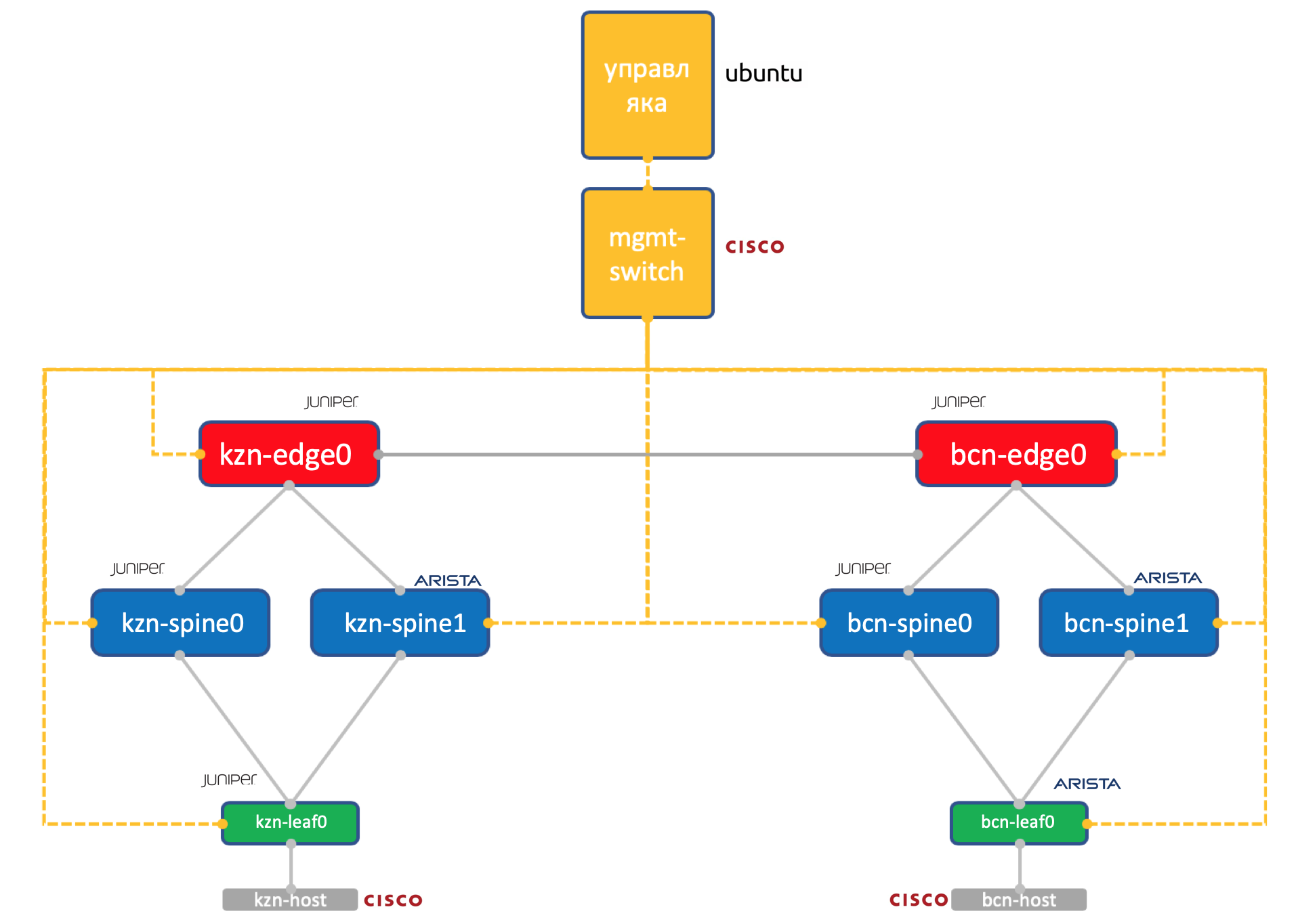
Dos centros de datos: Kazán y Barcelona.
- Dos espinas en cada una: Juniper y Arista.
- Un toro (Hoja) en cada uno: Juniper y Arista, con un host conectado (tomemos el ligero Cisco IOL para esto).
- Un nodo Edge-Leaf (solo Juniper hasta ahora).
- Un interruptor de Cisco para gobernarlos a todos.
- Además de las cajas de red, se lanzó una máquina virtual de administración. Ejecutando Ubuntu.
Ella tiene acceso a todos los dispositivos, sistemas IPAM / DCIM, un montón de scripts de Python, ansible y todo lo que necesitemos estará girando sobre él.
La configuración completa de todos los dispositivos de red que intentaremos reproducir utilizando la automatización.
Conclusión
¿También aceptado? Debajo de cada artículo para hacer una breve conclusión?
Por lo tanto, elegimos la red Klose de
tres niveles dentro del DC, porque esperamos mucho tráfico Este-Oeste y queremos ECMP.
Dividimos la red en física (subyacente) y virtual (superpuesta). En este caso, la superposición comienza desde el host, lo que simplifica los requisitos para la superposición.
Elegimos BGP como protocolo de enrutamiento para las redes no retransmitidas por su escalabilidad y flexibilidad de políticas.
Tendremos nodos separados para la organización DCI - Edge-leaf.
Habrá OSPF + LDP en el tronco.
DCI se implementará en base a MPLS L3VPN.
Para enlaces P2P, calcularemos las direcciones IP algorítmicamente en función de los nombres de los dispositivos.
Los Lupbacks serán asignados por el rol de los dispositivos y su ubicación en secuencia.
Prefijos subyacentes: solo en los conmutadores Leaf secuencialmente según su ubicación.
Supongamos que no tenemos el equipo instalado en este momento.
Por lo tanto, nuestros próximos pasos serán llevarlos a los sistemas (IPAM, inventario), organizar el acceso, generar una configuración e implementarla.
En el próximo artículo, trataremos con Netbox, el sistema de gestión de inventario y espacio IP en DC.
Gracias
- Andrey Glazkov, alias @glazgoo, para revisión y edición
- Alexander Klimenko, alias @ v00lk, para revisión y edición
- Artyom Chernobay para KDPV