Hoy queremos hablar sobre el concepto Insight-Driven y cómo ponerlo en práctica usando DataOps y ModelOps. El enfoque Insight-Driven es un tema integral del que hablamos en detalle en nuestra biblioteca recientemente creada de materiales útiles sobre gestión de datos (el enlace se encuentra a continuación). En la habratopica de hoy, nos concentraremos en las etapas clave del ciclo de vida de los modelos de aprendizaje automático, como Este es uno de los temas principales dentro del concepto.

¿Cuál es la esencia del enfoque basado en la percepción?
Muchos expertos han estado hablando sobre la importancia de
Data-Driven durante mucho tiempo, lo que, por supuesto, es absolutamente correcto en general, porque este enfoque implica tomar decisiones de gestión más eficientes mediante el análisis de datos, y no solo la intuición y la experiencia de liderazgo personal. Los analistas de Forrester
señalan que las empresas que dependen del análisis de datos en sus actividades crecen en promedio un 30% más rápido que sus competidores.
Pero todos entendemos que la empresa está avanzando no desde la disponibilidad de datos como tal, sino desde la capacidad de trabajar con ellos, es decir, para encontrar ideas que puedan monetizarse y para las cuales valga la pena acumular, procesar y analizar datos. Por lo tanto, estamos hablando específicamente sobre el enfoque Insight-Driven, como una versión más avanzada de Data-Driven.
Muy a menudo, cuando se trata de trabajar con datos, la mayoría de los especialistas se refieren principalmente a información estructurada dentro de la empresa, sin embargo, no hace mucho tiempo hablamos de por qué la gran mayoría de las empresas no utilizan alrededor del 80% de los datos potencialmente disponibles. Insight-Driven solo crea la base para complementar la imagen con información externa no estructurada, así como los resultados de la interpretación de datos para buscar dependencias implícitas entre ellos.
El enlace prometido a una biblioteca completa de materiales sobre gestión de datos , donde se encuentra el video mencionado sobre datos no utilizados.
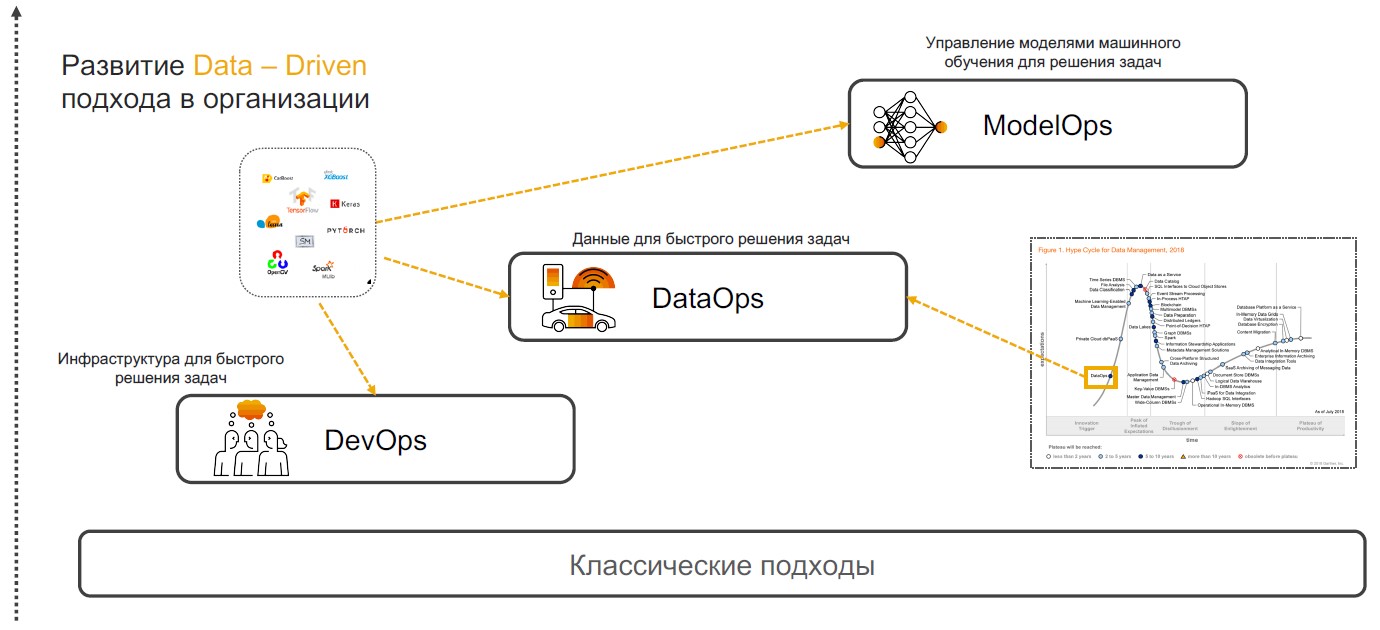
DevOps + DataOps + ModelOps
Las prácticas basadas en información se basan en DevOps, DataOps y ModelOps. Hablemos de por qué una combinación de estas prácticas particulares puede garantizar la implementación completa del enfoque.
 DevOps + DataOps
DevOps + DataOps . DevOps implica reducir el tiempo de lanzamiento del producto, sus actualizaciones y minimizar el costo de un mayor soporte mediante el uso de herramientas para el control de versiones, integración continua, pruebas y monitoreo, administración de lanzamientos. Si agregamos a estas prácticas una comprensión de qué datos están dentro de la empresa, cómo administrar su formato y estructura, etiquetar, realizar un seguimiento de la calidad, transformación, agregación y tener la capacidad de analizar y visualizar rápidamente, entonces obtenemos
DataOps . El enfoque de este enfoque es la implementación de escenarios utilizando modelos de aprendizaje automático que brindan apoyo para la toma de decisiones, búsqueda de información y pronósticos.
ModelOps . Tan pronto como la compañía comience a usar activamente modelos de aprendizaje automático, será necesario administrarlos, monitorear métricas de calidad, capacitar, comparar, actualizar y versionar. ModOps es un conjunto de prácticas y enfoques que simplifican la gestión del ciclo de vida de dichos modelos. Es utilizado por empresas que se ocupan de una gran cantidad de modelos en diversas áreas del negocio, por ejemplo, servicios de transmisión.
Implementar el enfoque Insight-Driven en una empresa no es una tarea trivial. Pero para aquellos que aún quisieran comenzar a trabajar con él, les diremos cómo hacerlo.
Búsqueda y preparación de datos.
La implementación de las prácticas basadas en Insight comienza con la búsqueda y preparación de datos. Más tarde se analizan y se utilizan para construir modelos de MO, pero se determinan previamente casos en los que los algoritmos inteligentes pueden ser útiles.
Definición de tareas . En esta etapa, la compañía establece objetivos comerciales, por ejemplo, aumentar las ganancias en el mercado. A continuación, se determinan las métricas empresariales para lograrlas, como un aumento en el número de nuevos clientes, el tamaño del cheque promedio y el porcentaje de conversión. Por lo tanto, hay escenarios en los que ya es posible buscar datos relevantes.
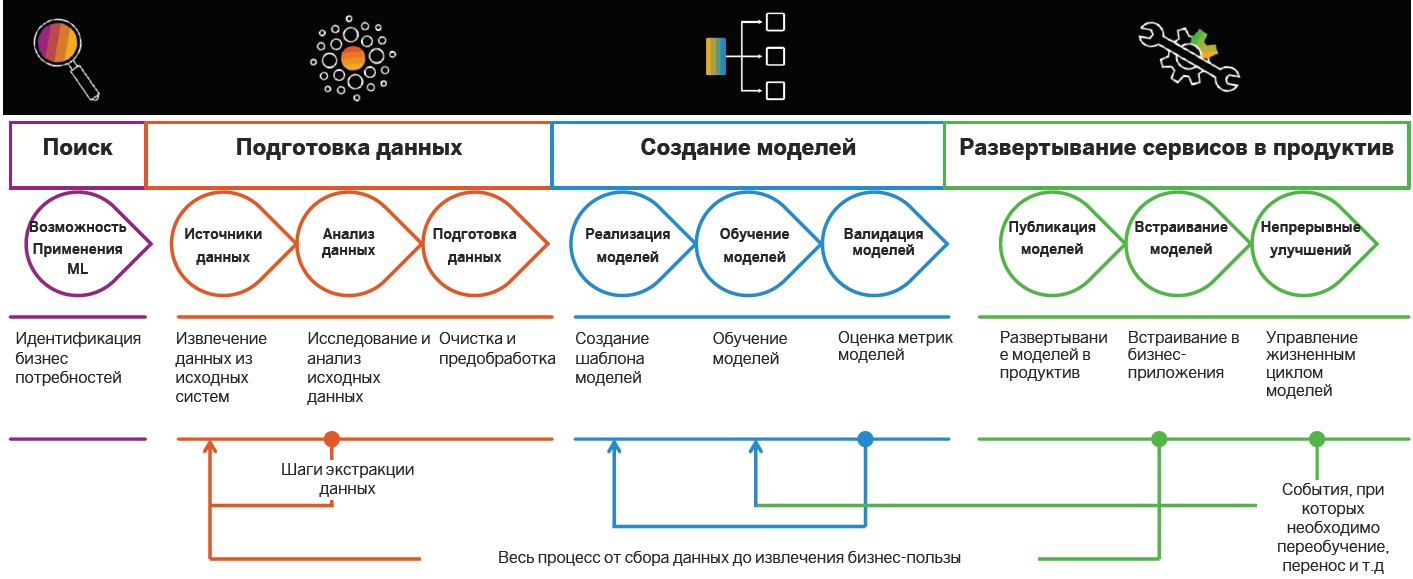 Abastecimiento y análisis de datos
Abastecimiento y análisis de datos . Cuando se definen los objetivos y las instrucciones para la recuperación de datos, llega el momento de analizar las fuentes. Esta y las etapas posteriores del desarrollo de escenarios inteligentes que se relacionan con la preparación
toman del 70 al 80% de los presupuestos de las empresas en la implementación. El hecho es que la calidad del conjunto de datos afecta la precisión de los modelos de aprendizaje automático diseñados. Pero la información necesaria a menudo está "dispersa" en varios sistemas: puede encontrarse en bases de datos relacionales, como MS SQL, Oracle, PostgreSQL, en la plataforma Hadoop y en muchas otras fuentes. Y en esta etapa, debe comprender dónde están los datos relevantes y cómo recopilarlos.
A menudo, los analistas descargan y procesan todo manualmente, lo que ralentiza enormemente los procesos y aumenta el riesgo de errores. En SAP, ofrecemos a nuestros clientes la implementación de un meta-sistema que se conecta a las fuentes correctas y recopila datos a pedido.
Por lo tanto, puede catalogar todas las tablas, grupos externos con datos no estructurados y otras fuentes: establecer etiquetas (incluidas las jerárquicas) y recopilar rápidamente información relevante. Condicionalmente, si la información sobre un cliente se encuentra en diferentes bases de datos, entonces es suficiente para indicar estas entidades. La próxima vez que necesite un "conjunto de datos del cliente", elegirá un escaparate listo para usar.
Una vez que se identifican las fuentes de datos, puede pasar
al seguimiento y al perfil de la calidad de los datos . Esta operación es necesaria para comprender el número de lagunas, valores únicos y verificar la calidad general de los datos. Para todo esto, puede crear paneles con reglas y rastrear cualquier cambio.
Transformación de datos . El siguiente paso es el trabajo directo con datos que deberían resolver las tareas. Para hacer esto, los datos se borran: se verifican, se deduplican, se rellenan los huecos. Este proceso se puede simplificar con la programación basada en flujo. En este caso, estamos tratando con una secuencia de operaciones: una tubería. Su salida se puede enviar a una interfaz gráfica u otro sistema para el trabajo posterior. Aquí, los manejadores de datos se ensamblan como un constructor (y dependiendo del escenario). Esto puede ser un procesamiento periódico o de transmisión, o un servicio REST.

El concepto de programación basada en flujo es adecuado para resolver una amplia gama de tareas: desde la previsión de ventas y la evaluación de la calidad del servicio hasta la búsqueda de razones para la pérdida de clientes. Hay dos herramientas para buscar y preparar datos en SAP. El primero es
SAP Data Intelligence para analistas de datos. A diferencia de plataformas similares, esta solución funciona con datos distribuidos y no requiere centralización: proporciona un entorno unificado para la implementación, publicación, integración, escalado y soporte de modelos. La segunda herramienta es
SAP Agile Data Preparation , un pequeño servicio de preparación de datos dirigido a analistas y usuarios comerciales. Tiene una interfaz simple que ayuda a recopilar un conjunto de datos, filtrar, procesar y asignar información. Se puede publicar en un escaparate para transferir BI de autoservicio: sistemas de autoservicio para crear escenarios analíticos (no requieren un conocimiento profundo en el campo de la ciencia de datos).
Creación de modelos
Después de la preparación, es el turno de crear modelos de aprendizaje automático. Aquí se distinguen: investigación, creación de prototipos y productividad. La última etapa incluye la implementación de tuberías para capacitación y aplicación de modelos.
Investigación y creación de prototipos . Actualmente, hay muchos marcos temáticos y bibliotecas disponibles. Los líderes en la frecuencia de uso son TensorFlow y PyTorch, cuya popularidad durante el año pasado ha
crecido en un 243%. La plataforma SAP le permite usar cualquiera de estos marcos y puede complementarse de manera flexible con bibliotecas como CatBoost de Yandex, LightGBM de Microsoft, scikit-learn y pandas. Todavía puede usar el
Marco de
datos HANA en la biblioteca hanaml. Esta API imita a los pandas y HANA le permite procesar grandes cantidades de datos utilizando "computación diferida".
Para modelos de prototipos, ofrecemos Jupyter Lab. Esta es una herramienta de código abierto para profesionales de la ciencia de datos. Lo incorporamos al ecosistema de SAP, al tiempo que ampliamos la funcionalidad. Jupyter Lab funciona en la plataforma de Inteligencia de datos y, debido a la biblioteca sapdi incorporada, puede conectarse a cualquier fuente de datos conectada en los pasos anteriores, monitorear experimentos y métricas de calidad para un análisis posterior.
Por separado, vale la pena señalar que las computadoras portátiles, los conjuntos de datos, la capacitación y las
canalizaciones de inferencia , así como los servicios para la implementación de modelos deben ser consistentes. Para combinar todos estos objetos, use el script ML (objeto versionado).
Modelo de entrenamiento . Hay dos opciones para trabajar con scripts de ML. Hay modelos que no necesitan ser entrenados en absoluto. Por ejemplo, en SAP Data Intelligence ofrecemos sistemas de reconocimiento facial, traducción automática, OCR (reconocimiento óptico de caracteres) y otros. Todos trabajan fuera de la caja. Por otro lado, están aquellos modelos que necesitan ser entrenados y productivos. Esta capacitación puede realizarse tanto en el clúster de Data Intelligence como en recursos informáticos externos que están conectados solo durante la duración de los cálculos.
"Bajo el capó" en SAP Data Intelligence está la plataforma Kubernetes, por lo que todos los operadores están vinculados a los contenedores acoplables. Para trabajar con el modelo, es suficiente describir el archivo acoplable y adjuntarle etiquetas para las bibliotecas y versiones utilizadas.
Otra forma de crear modelos es con AutoML. Estos son sistemas MO automatizados. Dichas herramientas son desarrolladas por
H2O ,
Microsoft ,
Google, etc. Trabajan
en esta dirección
en el MIT . Pero los ingenieros universitarios no se centran en la integración y la productividad. SAP también tiene un sistema AutoML que se enfoca en resultados rápidos. Ella trabaja en HANA y tiene acceso directo a los datos; no es necesario moverlos ni modificarlos a ningún lado. Ahora estamos desarrollando una solución que se centra en la calidad de los modelos: anunciaremos un lanzamiento más adelante.
Gestión del ciclo de vida . Las condiciones cambian, la información se vuelve obsoleta, por lo que la precisión de los modelos MO disminuye con el tiempo. En consecuencia, al haber acumulado nuevos datos, podemos volver a capacitar el modelo y refinar los resultados. Por ejemplo, un importante productor de bebidas
utiliza la información de preferencia del consumidor en 200 países diferentes para reentrenar los sistemas inteligentes. La compañía tiene en cuenta los gustos de las personas, la cantidad de azúcar, el contenido calórico de las bebidas e incluso los productos que ofrecen las marcas competidoras en los mercados objetivo. Los modelos MO determinan automáticamente cuál de los cientos de productos aceptará mejor la compañía en una región determinada.
 Reutilización de componentes basados en agentes en SAP Data Hub
Reutilización de componentes basados en agentes en SAP Data HubPero las versiones y los modelos de actualización también deben realizarse a medida que se lanzan nuevos algoritmos y actualizaciones de componentes de hardware. Su implementación puede mejorar la precisión y la calidad de los modelos utilizados en el trabajo.
Insight-Driven para el crecimiento empresarial
El enfoque para administrar las etapas del ciclo de vida de los modelos de aprendizaje automático descritos anteriormente es, de hecho, un marco universal que permite a una empresa convertirse en Insight-Driven y utilizar el trabajo con datos como un motor clave para el crecimiento empresarial. ¡Las organizaciones que incorporan este concepto saben más, crecen más rápido y, en nuestra opinión, trabajan mucho más interesantes en esta tecnología de vanguardia!
Obtenga más información sobre cómo crear el concepto Insight-Driven en nuestra
biblioteca de materiales útiles de gestión de datos , donde hemos recopilado videos, folletos útiles y accesos de prueba a los sistemas SAP.