Hola, me llamo Eugene. Trabajo en la infraestructura de búsqueda Yandex.Market. Quiero contarle a la comunidad Habr sobre la cocina interna del Mercado, pero hay algo que contar. En primer lugar, cómo funciona la búsqueda de mercado, los procesos y la arquitectura. ¿Cómo lidiamos con situaciones de emergencia: qué sucede si un servidor falla? ¿Y si hay 100 de esos servidores?
También aprenderá de inmediato cómo implementamos nuevas funciones en un grupo de servidores. Y cómo probar servicios complejos directamente en producción, sin dar a los usuarios ningún inconveniente. En general, cómo funciona la búsqueda del Mercado, para que todos estén bien.
Un poco sobre nosotros: ¿qué problema resolvemos?
Cuando ingresa texto, busca productos por parámetros o compara precios en diferentes tiendas, todas las solicitudes llegan al servicio de búsqueda. La búsqueda es el servicio más grande en el mercado.
Procesamos todas las consultas de búsqueda: desde market.yandex.ru, beru.ru, el servicio Supercheck, Yandex.Advisor y aplicaciones móviles. También incluimos ofertas de bienes en los resultados de búsqueda en yandex.ru.
Por servicio de búsqueda, me refiero no solo a la búsqueda directa, sino también a una base de datos con todas las ofertas del mercado. La escala es la siguiente: se procesan más de mil millones de consultas de búsqueda por día. Y todo debería funcionar rápidamente, sin interrupciones y siempre producir el resultado deseado.
Qué es qué: arquitectura de mercado
Describa brevemente la arquitectura actual del mercado. Convencionalmente, se puede describir mediante el siguiente esquema:
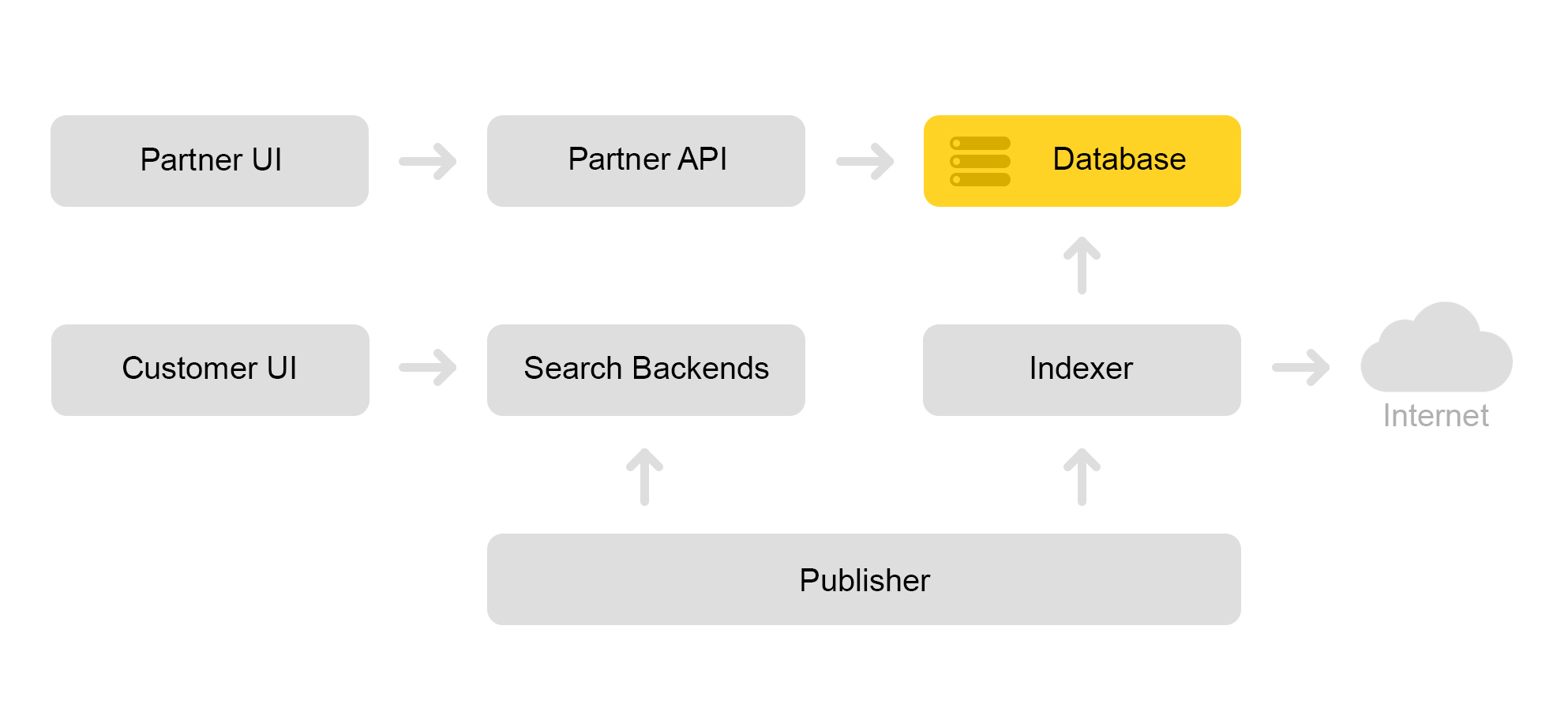
Digamos que una tienda asociada viene a nosotros. Dice que quiero vender un juguete: este gato malvado con un chirrido. Y un gato malvado sin un tweeter. Y solo un gato. Luego, la tienda necesita preparar ofertas en las que el mercado busca. La tienda forma un xml especial con ofertas y comunica la ruta a este xml a través de una interfaz de socio. Luego, el indexador descarga periódicamente este xml, busca errores y almacena toda la información en una gran base de datos.
Hay muchos xml guardados. Se crea un índice de búsqueda a partir de esta base de datos. El índice se almacena en formato interno. Después de crear el índice, el servicio de diseños lo carga en los motores de búsqueda.
Como resultado, aparece un gato malvado con un chirrido en la base de datos y aparece un índice de gato en el servidor.
Hablaré sobre cómo buscamos un gato en la parte sobre la arquitectura de búsqueda.
Arquitectura de búsqueda de mercado
Vivimos en el mundo de los microservicios: cada solicitud entrante a
market.yandex.ru genera muchas subconsultas y docenas de servicios participan en su procesamiento. El diagrama muestra solo unos pocos:
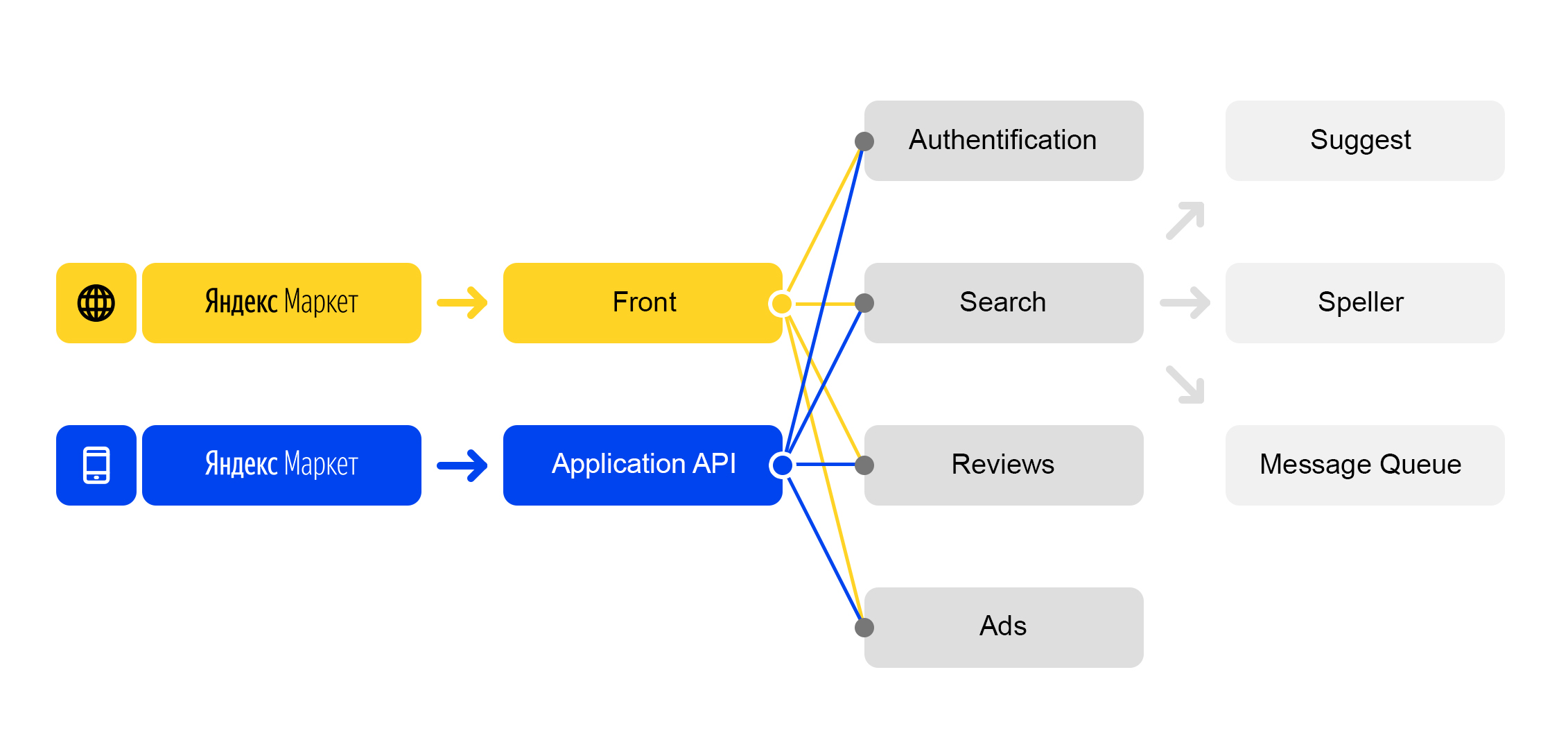 Esquema de procesamiento de solicitud simplificado
Esquema de procesamiento de solicitud simplificadoCada servicio tiene algo maravilloso: su propio equilibrador con un nombre único:
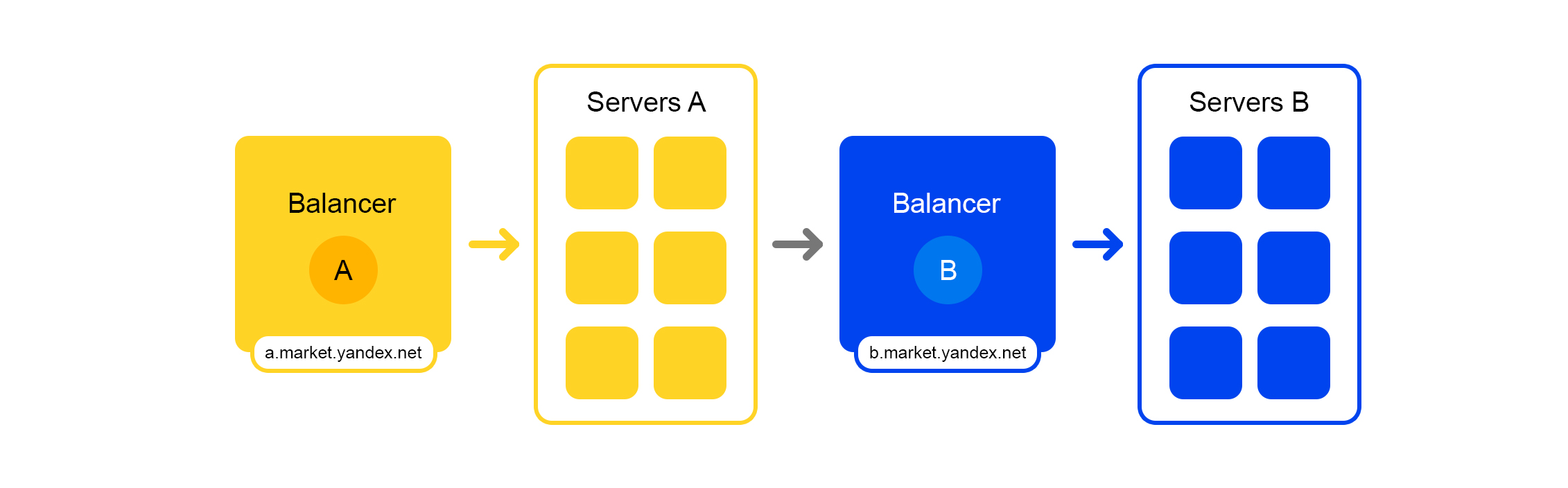
El equilibrador nos brinda una gran flexibilidad para administrar el servicio: por ejemplo, puede apagar los servidores, que a menudo se requieren para las actualizaciones. El equilibrador ve que el servidor no está disponible y redirige automáticamente las solicitudes a otros servidores o centros de datos. Cuando agrega o elimina un servidor, la carga se redistribuye automáticamente entre los servidores.
El nombre único del equilibrador no depende del centro de datos. Cuando el servicio A realiza una solicitud a B, de manera predeterminada, el equilibrador B redirige la solicitud al centro de datos actual. Si el servicio no está disponible o está ausente en el centro de datos actual, la solicitud se redirige a otros centros de datos.
Un solo FQDN para todos los centros de datos permite que el servicio A generalmente se desconecte de las ubicaciones. Su solicitud de servicio B siempre será procesada. Una excepción es el caso cuando el servicio está en todos los centros de datos.
Pero no todo es tan optimista con este equilibrador: tenemos un componente intermedio adicional. El equilibrador puede ser inestable y este problema se resuelve con servidores redundantes. También hay un retraso adicional entre los servicios A y B. Pero en la práctica, es inferior a 1 ms y para la mayoría de los servicios esto no es crítico.
Combatir lo inesperado: servicios de búsqueda equilibrados y resistentes
Imagine que ocurrió un colapso: necesita encontrar un gato con un chirrido, pero el servidor falla. O 100 servidores. ¿Cómo salir? ¿Realmente dejaremos al usuario sin un gato?
La situación es terrible, pero estamos listos para ello. Te lo diré en orden.
La infraestructura de búsqueda se encuentra en varios centros de datos:
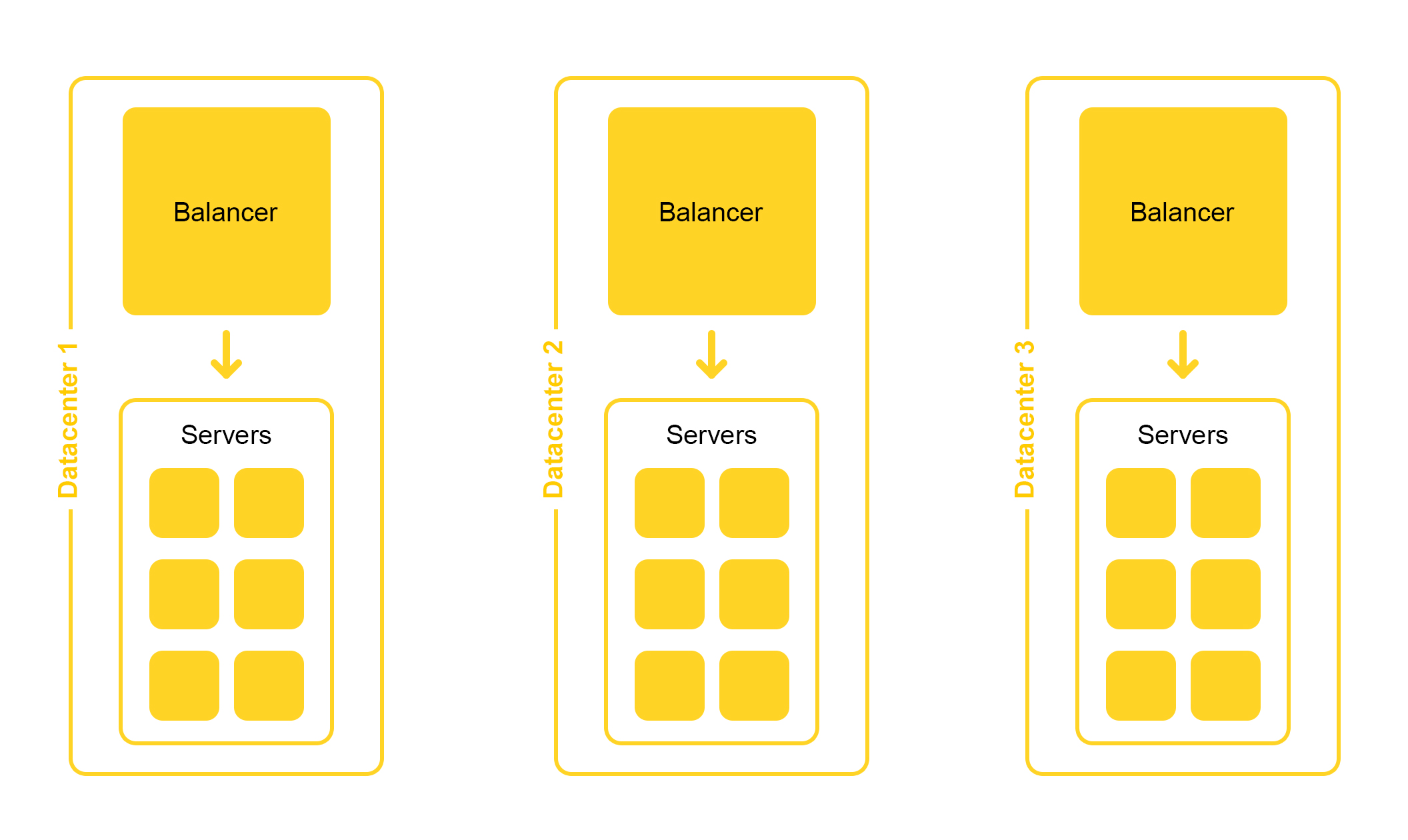
Al diseñar, ponemos la posibilidad de deshabilitar un centro de datos. La vida está llena de sorpresas: por ejemplo, una excavadora puede cortar un cable subterráneo (sí, así fue). Las capacidades en los centros de datos restantes deberían ser suficientes para soportar la carga máxima.
Considere un solo centro de datos. En cada centro de datos, el mismo esquema de equilibradores:
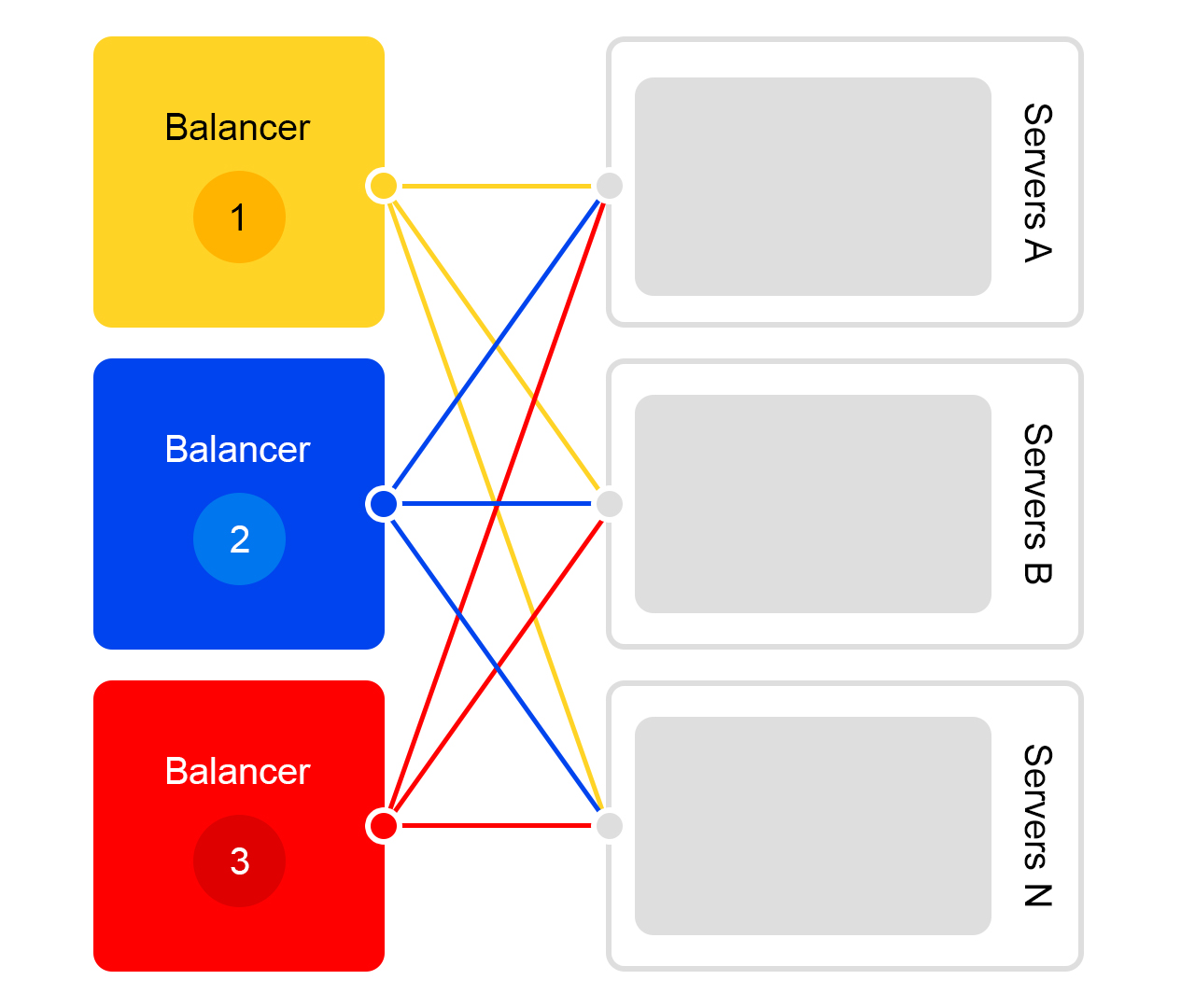
Un equilibrador es al menos tres servidores físicos. Tal redundancia está hecha para la confiabilidad. Los equilibradores trabajan en HAProx.
Elegimos HAProx debido a su alto rendimiento, requisitos de recursos pequeños y amplia funcionalidad. Dentro de cada servidor funciona nuestro software de búsqueda.
La probabilidad de falla de un servidor es pequeña. Pero si tiene muchos servidores, aumentará la probabilidad de que al menos uno caiga.
Esto es lo que sucede en realidad: los servidores se están bloqueando. Por lo tanto, debe monitorear constantemente el estado de todos los servidores. Si el servidor deja de responder, se desconecta automáticamente del tráfico. Para esto, HAProxy tiene un control de salud incorporado. Se dirige a todos los servidores con solicitud HTTP "/ ping" una vez por segundo.
Otra característica de HAProxy: agent-check le permite cargar todos los servidores de manera uniforme. Para hacer esto, HAProxy se conecta a todos los servidores, y devuelven su peso dependiendo de la carga actual de 1 a 100. El peso se calcula en función del número de solicitudes en la cola de procesamiento y la carga del procesador.
Ahora sobre encontrar un gato. Las consultas de la forma
/ búsqueda? Texto = angry + cat llegan a
buscar . Para que la búsqueda sea rápida, todo el índice cat debe colocarse en la RAM. Incluso leer desde un SSD no es lo suficientemente rápido.
Érase una vez, la base de la oferta era pequeña, y había suficiente RAM para un servidor. A medida que la base de datos de la propuesta creció, todo dejó de caber en esta RAM y los datos se dividieron en dos partes: fragmento 1 y fragmento 2.

Pero siempre sucede: cualquier solución, incluso una buena, genera otros problemas.
El equilibrador aún fue a cualquier servidor. Pero en la máquina donde llegó la solicitud, solo había la mitad del índice. El resto estaba en otros servidores. Por lo tanto, el servidor tuvo que ir a alguna máquina vecina. Después de recibir datos de ambos servidores, los resultados se combinaron y reorganizaron.
Dado que el equilibrador distribuye las solicitudes de manera uniforme, todos los servidores se dedicaron a reorganizar, y no solo a proporcionar datos.
El problema se produjo si el servidor vecino no estaba disponible. La solución fue especificar varios servidores con diferentes prioridades como el servidor "vecino". Primero, la solicitud se envió a los servidores en el bastidor actual. Si no se recibió respuesta, la solicitud se envió a todos los servidores en este centro de datos. Y por último, pero no menos importante, la solicitud se envió a otros centros de datos.
A medida que aumentó el número de propuestas, los datos se dividieron en cuatro partes. Pero este no era el límite.
Ahora se usa una configuración de ocho fragmentos. Además, para ahorrar más memoria, el índice se dividió en la parte de búsqueda (por la cual se realiza la búsqueda) y la parte de fragmento (que no está involucrada en la búsqueda).
Un servidor contiene información sobre un solo fragmento. Por lo tanto, para realizar una búsqueda en el índice completo, debe buscar en ocho servidores que contengan fragmentos diferentes.
Los servidores se agrupan en grupos. Cada grupo contiene ocho motores de búsqueda y un fragmento.
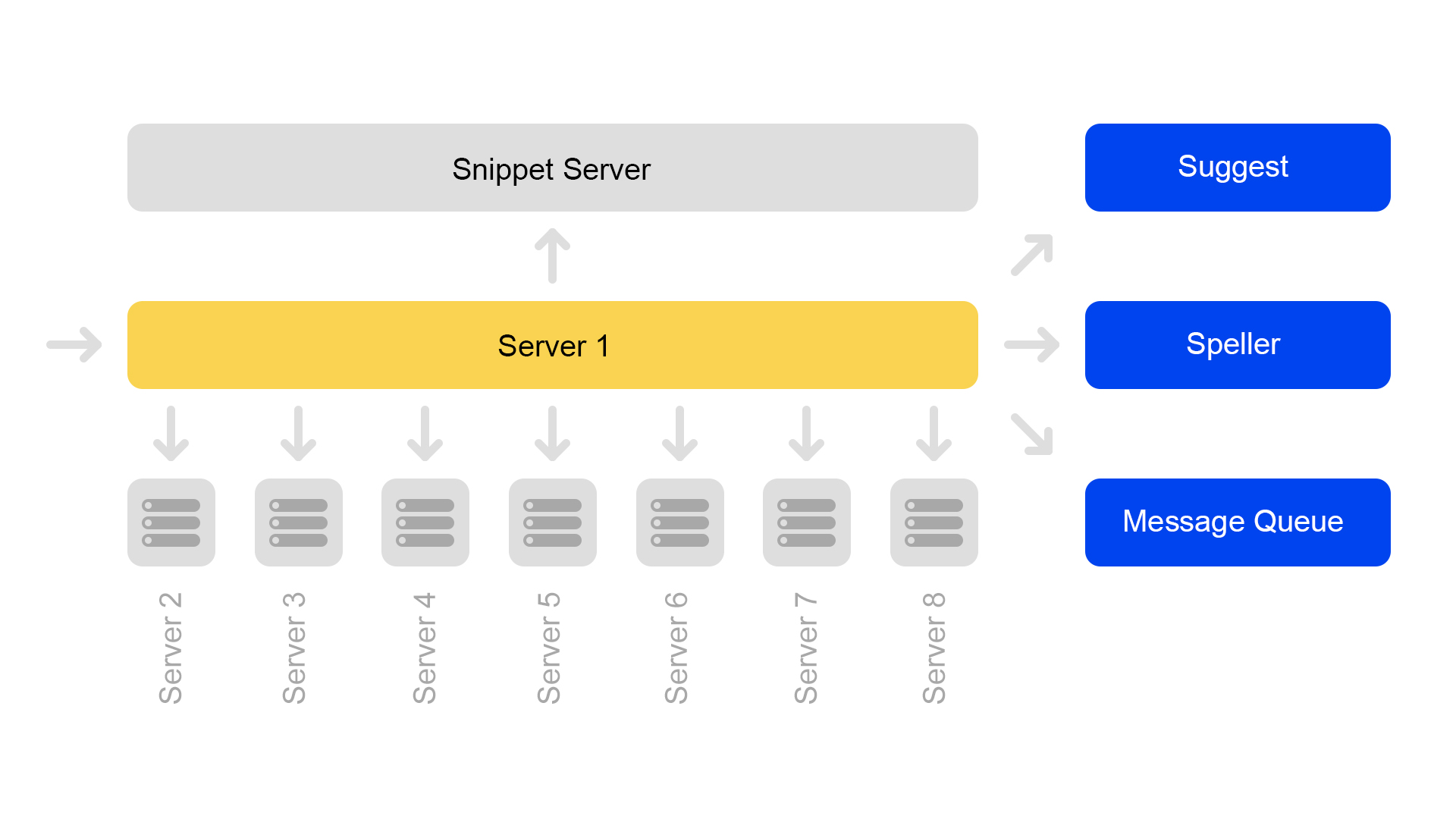
La base de datos de valores clave con datos estáticos se está ejecutando en el servidor de fragmentos. Son necesarios para emitir documentos, por ejemplo, una descripción de un gato con un chirrido. Los datos se extraen especialmente en un servidor separado para no cargar la memoria de los motores de búsqueda.
Dado que las ID de documentos son únicas solo en el marco de un índice, podría surgir una situación en la que no hay documentos en los fragmentos. Bueno o eso en una ID habrá otro contenido. Por lo tanto, para que la búsqueda funcione y la búsqueda ocurra, ha surgido la necesidad de la consistencia de todo el clúster. Más adelante hablaré sobre cómo monitoreamos la consistencia.
La búsqueda en sí está organizada de la siguiente manera: una consulta de búsqueda puede llegar a cualquiera de los ocho servidores. Digamos que vino al servidor 1. Este servidor procesa todos los argumentos y entiende qué y cómo buscar. Dependiendo de la solicitud entrante, el servidor puede realizar solicitudes adicionales a servicios externos para obtener la información necesaria. Una solicitud puede ser seguida por hasta diez solicitudes a servicios externos.
Después de recopilar la información necesaria, comienza una búsqueda en la base de datos de ofertas. Para hacer esto, se realizan subconsultas para los ocho servidores en el clúster.
Después de recibir las respuestas, los resultados se combinan. Al final, para generar el problema, es posible que necesite varias subconsultas más para el servidor de fragmentos.
Las consultas de búsqueda dentro del clúster son:
/ shard1? Text = angry + cat . Además, las subconsultas de la forma:
/ status se realizan constantemente entre todos los servidores dentro del clúster una vez por segundo.
La solicitud
/ status detecta una situación en la que el servidor no está disponible.
También controla que en todos los servidores la versión del motor de búsqueda y la versión del índice sean las mismas, de lo contrario habrá datos inconsistentes dentro del clúster.
A pesar del hecho de que un servidor de fragmentos procesa las solicitudes de ocho motores de búsqueda, su procesador tiene una carga muy ligera. Por lo tanto, ahora transferimos datos de fragmentos a un servicio separado.
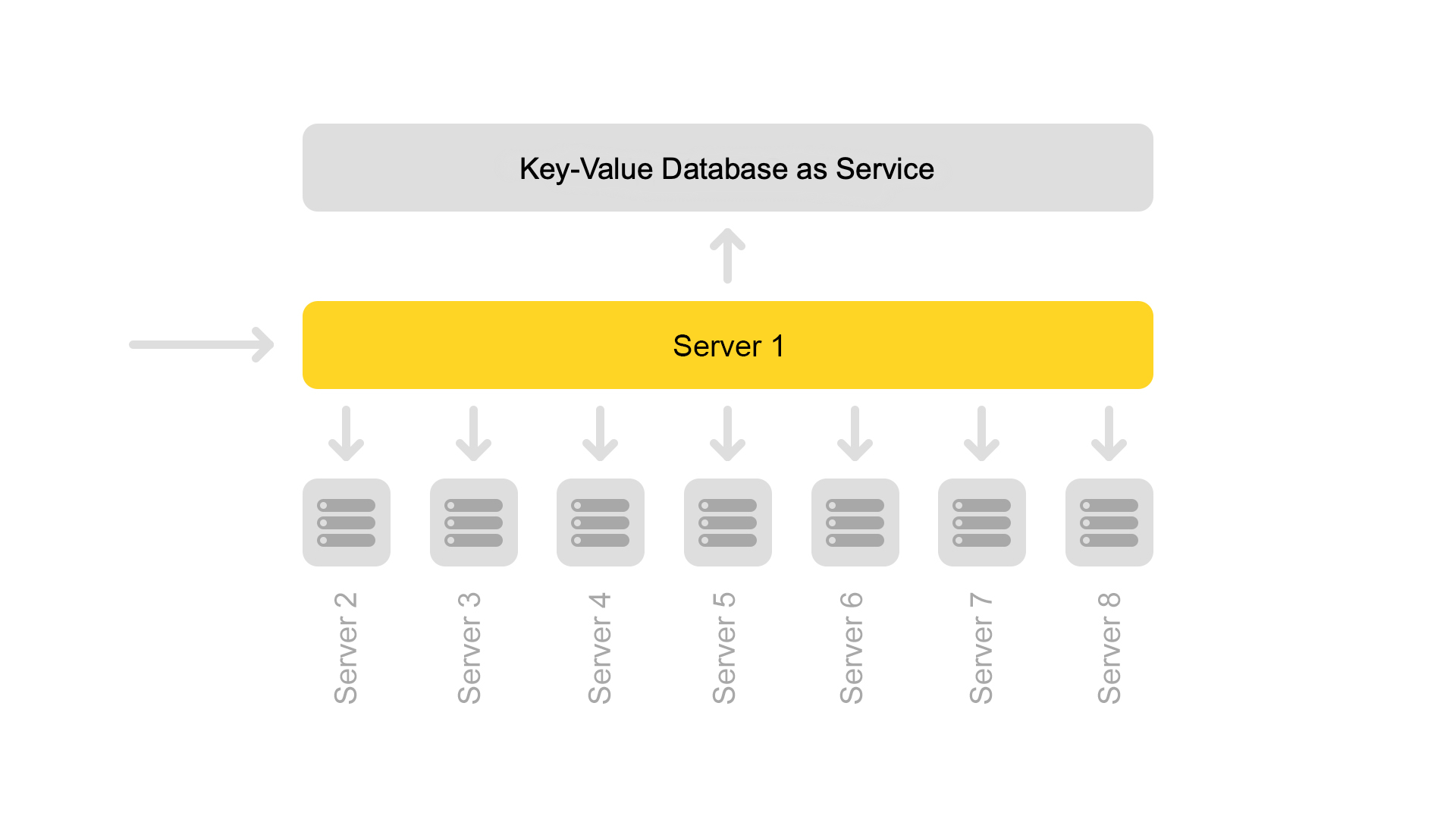
Para transferir datos, introdujimos claves universales para documentos. Ahora la situación es imposible cuando una clave devuelve contenido de otro documento.
Pero la transición a otra arquitectura aún no está completa. Ahora queremos deshacernos del servidor de fragmentos dedicado. Y luego, generalmente, aléjese de la estructura del clúster. Esto nos permitirá continuar escalando fácilmente. Una ventaja adicional es un importante ahorro de hierro.
Y ahora a las historias de miedo con un final feliz. Considere varios casos de indisponibilidad del servidor.
Terrible sucedió: un servidor no está disponible
Digamos que un servidor no está disponible. Luego, los otros servidores en el clúster pueden continuar respondiendo, pero los resultados de la búsqueda estarán incompletos.
A través de una verificación de estado, los servidores vecinos entienden que uno no está disponible. Por lo tanto, para mantener la integridad, todos los servidores en el clúster comienzan a responder a la solicitud
/ ping al equilibrador de que tampoco están disponibles. Resulta que todos los servidores en el clúster murieron (que no es el caso). Este es el principal inconveniente de nuestro esquema de clúster; por lo tanto, queremos alejarnos de él.
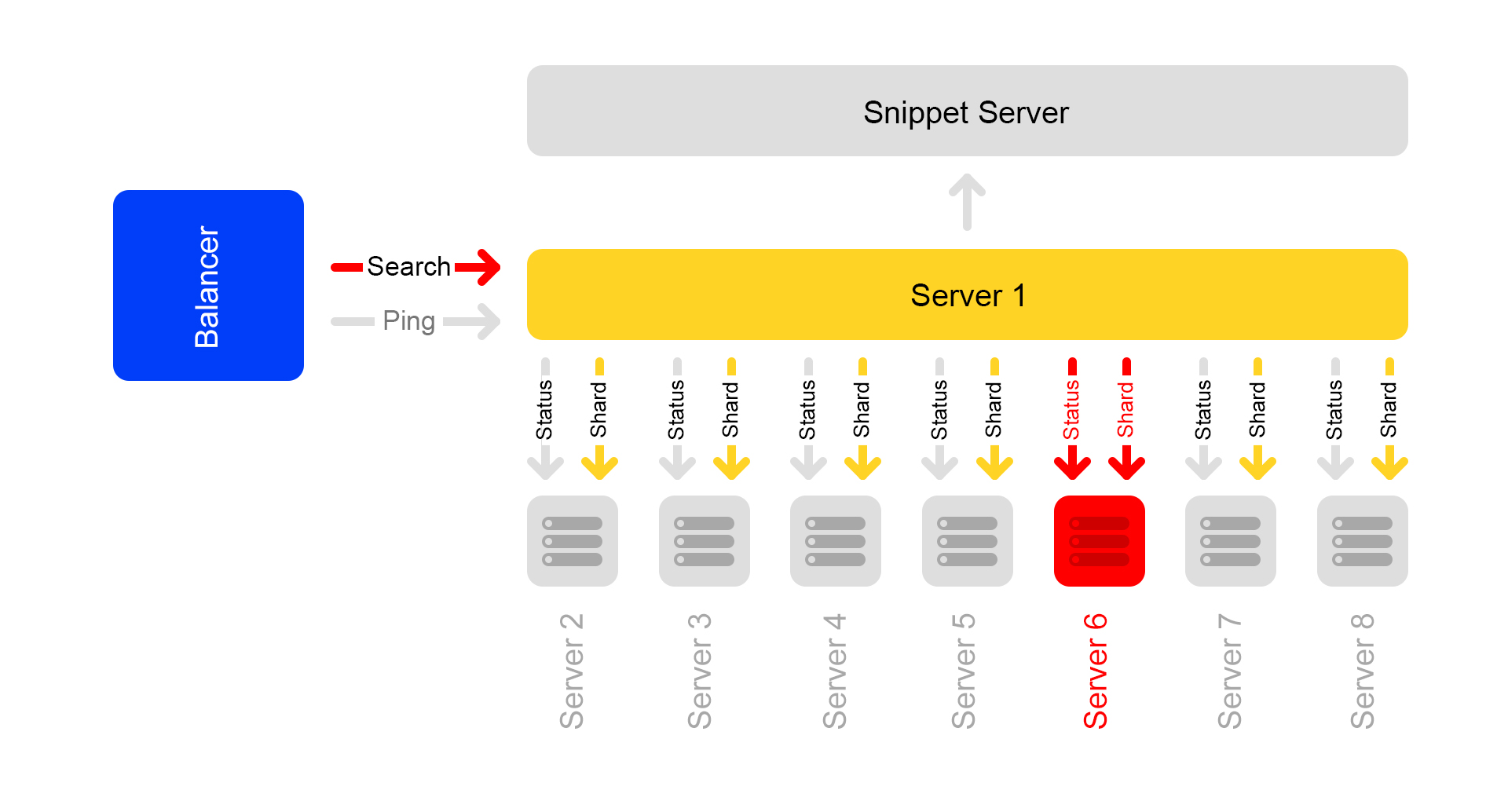
Solicitudes que terminaron con un error, el equilibrador vuelve a preguntar en otros servidores.
Además, el equilibrador deja de enviar tráfico de usuarios a servidores muertos, pero continúa verificando su estado.
Cuando el servidor está disponible, comienza a responder a
/ ping . Tan pronto como las respuestas normales a los pings de los servidores muertos comienzan a llegar, los balanceadores comienzan a enviar tráfico de usuarios allí. El grupo está restaurado, aplausos.
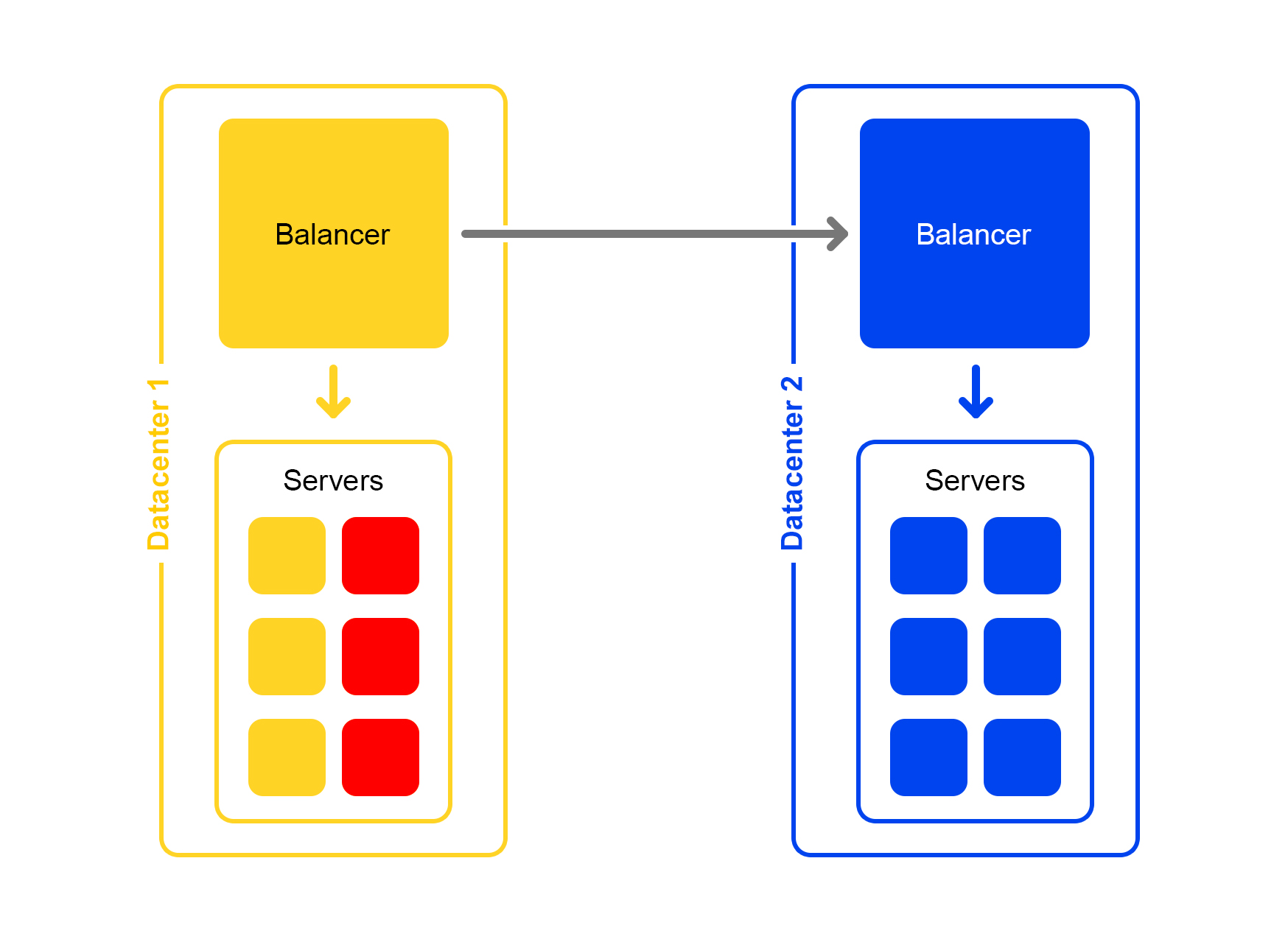
Peor aún: muchos servidores no están disponibles
Una parte importante de los servidores en el centro de datos se corta. ¿Qué hacer, dónde correr? El equilibrador viene al rescate nuevamente. Cada equilibrador mantiene constantemente en la memoria el número actual de servidores en vivo. Siempre considera la cantidad máxima de tráfico que puede manejar el centro de datos actual.
Cuando caen muchos servidores en el centro de datos, el equilibrador comprende que este centro de datos no puede procesar todo el tráfico.
Luego, el exceso de tráfico comienza distribuido aleatoriamente a otros centros de datos. Todo funciona, todos están felices.
Cómo lo hacemos: lanzamientos de lanzamiento
Ahora sobre cómo publicamos los cambios realizados en el servicio. Aquí tomamos el camino de los procesos de racionalización: el lanzamiento de una nueva versión está casi completamente automatizado.
Cuando se acumula un cierto número de cambios en el proyecto, se crea automáticamente una nueva versión y se inicia su ensamblaje.
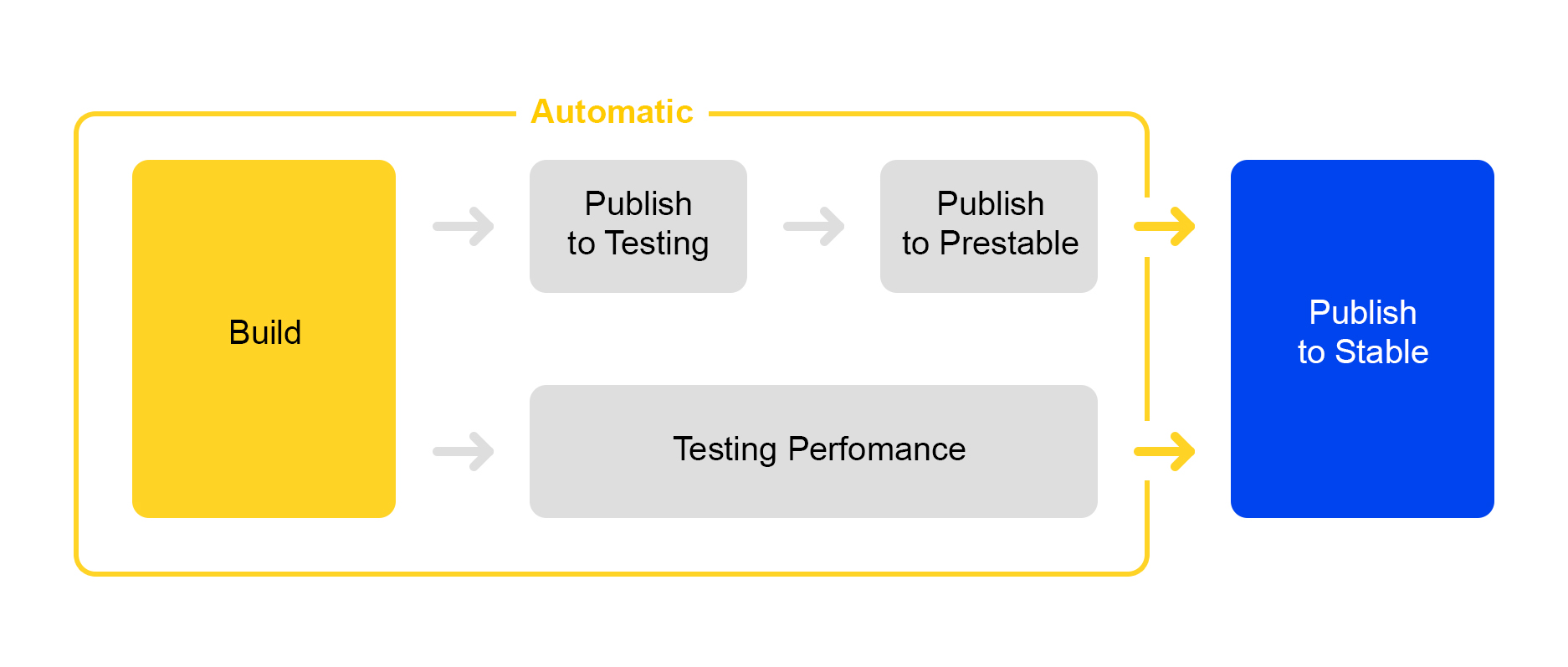
Luego, el servicio se implementa en pruebas, donde se verifica la estabilidad.
Al mismo tiempo, se lanza la prueba automática de rendimiento. Él se dedica a un servicio especial. No hablaré de él ahora: su descripción es digna de un artículo separado.
Si la publicación en la prueba es exitosa, la publicación de la versión en preestablecida comienza automáticamente. Prestable es un clúster especial donde se dirige el tráfico normal de usuarios. Si devuelve un error, el equilibrador se reinicia en producción.
En predecible, los tiempos de respuesta se miden y comparan con el lanzamiento anterior en producción. Si todo está bien, entonces la persona se conecta: verifica los gráficos y los resultados de las pruebas de carga y luego comienza a implementarse en producción.
Todo lo mejor para el usuario: pruebas A / B
No siempre es obvio si los cambios en el servicio traerán beneficios reales. Para medir la utilidad del cambio, a las personas se les ocurrió una prueba A / B. Hablaré un poco sobre cómo funciona esto en Yandex. Búsqueda de mercado.
Todo comienza con la adición de un nuevo parámetro CGI que incluye una nueva funcionalidad. Deje que nuestro parámetro sea:
market_new_functionality = 1 . Luego, en el código, habilite esta funcionalidad con la bandera:
If (cgi.experiments.market_new_functionality) {
Nueva funcionalidad se implementa en producción.
Existe un servicio dedicado para automatizar las pruebas A / B, que se
describe en detalle
aquí . Se crea un experimento en el servicio. La cuota de tráfico se establece, por ejemplo, 15%. El interés no se establece para las solicitudes, sino para los usuarios. También se indica el tiempo del experimento, por ejemplo, una semana.
Se pueden comenzar varios experimentos al mismo tiempo. En la configuración, puede especificar si es posible la intersección con otros experimentos.
Como resultado, el servicio agrega automáticamente el argumento
market_new_functionality = 1 al 15% de los usuarios. También calcula automáticamente las métricas seleccionadas. Después del experimento, los analistas miran los resultados y sacan conclusiones. En base a los hallazgos, se toma la decisión de implementar la producción o el refinamiento.
Mano ágil del mercado: pruebas de producción
A menudo sucede que es necesario verificar el funcionamiento de la nueva funcionalidad en la producción, pero no hay certeza de cómo se comportará en condiciones de "combate" bajo cargas pesadas.
Hay una solución: los indicadores en los parámetros CGI se pueden usar no solo para las pruebas A / B, sino también para probar nuevas funcionalidades.
Creamos una herramienta que le permite cambiar instantáneamente la configuración en miles de servidores sin exponer el servicio a riesgos. Se llama "Stop Crane". La idea original era la capacidad de desactivar rápidamente algunas funciones sin diseño. Luego, la herramienta se expandió y se volvió más compleja.
El esquema del servicio se presenta a continuación:
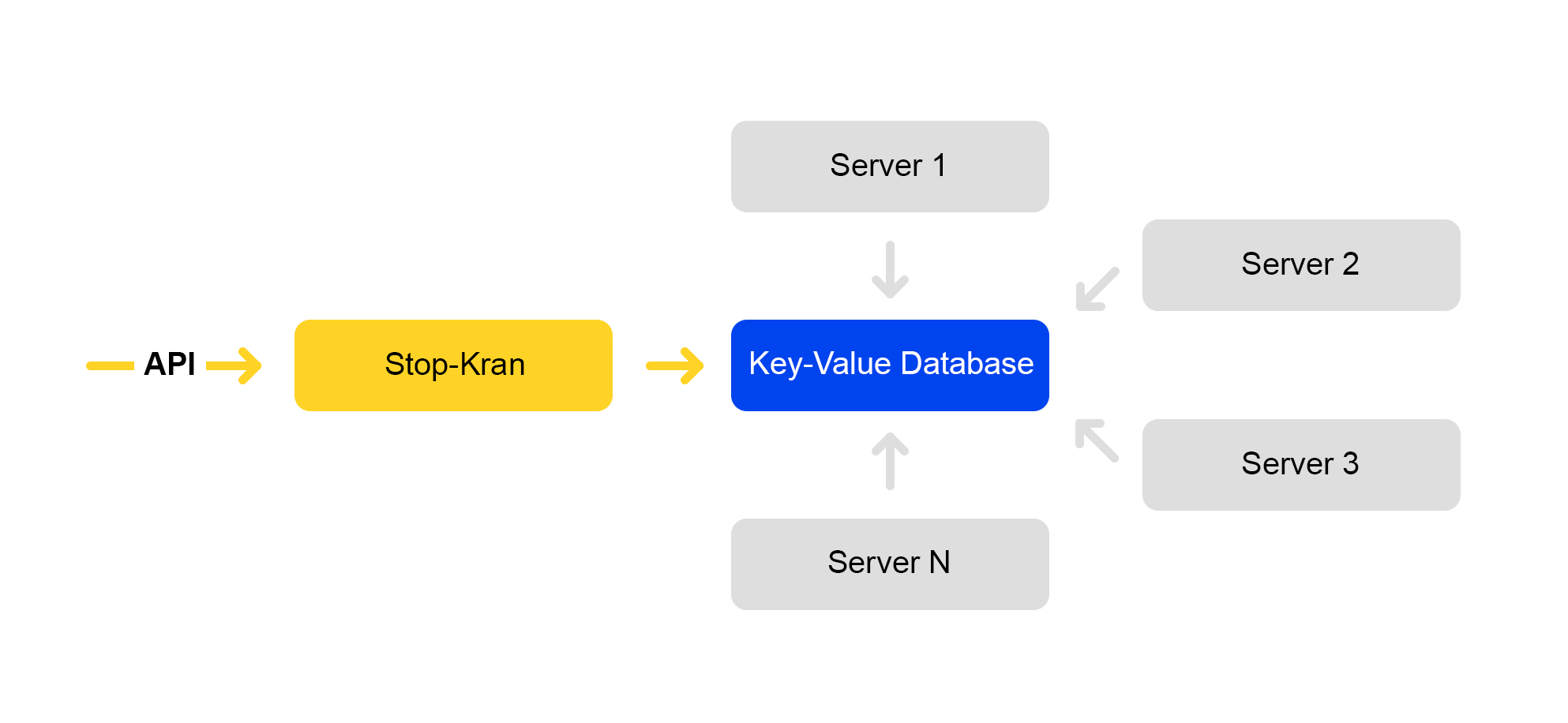
La API establece valores de bandera. El servicio de gestión almacena estos valores en una base de datos. Todos los servidores van a la base de datos una vez cada diez segundos, bombean los valores de las banderas y aplican estos valores a cada solicitud.
En Stop Crane, puede establecer dos tipos de valores:
1) Expresiones condicionales. Aplicar cuando se ejecuta uno de los valores. Por ejemplo:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
El valor "3" se aplicará cuando la solicitud se procese en la ubicación DC1. Y el valor es "4" cuando la solicitud se procesa en el segundo clúster para el sitio beru.ru.
2) Valores incondicionales. Se usan por defecto si no se cumple ninguna de las condiciones. Por ejemplo:
valor, valor!Si el valor termina con un signo de exclamación, se le da una prioridad más alta.
El analizador de los parámetros CGI analiza la URL. Luego aplica los valores del stop tap.
Se aplican valores con las siguientes prioridades:
- Mayor prioridad de detener el toque (signo de exclamación).
- El valor de la consulta.
- El valor predeterminado es desde el grifo de parada.
- El valor predeterminado en el código.
Hay muchos indicadores que se indican en valores condicionales; son suficientes para todos los escenarios que conocemos:
- Centro de datos.
- Medio ambiente: producción, pruebas, sombra.
- Lugar: mercado, beru.
- Número de grupo
Con esta herramienta, puede habilitar una nueva funcionalidad en un grupo de servidores (por ejemplo, solo en un centro de datos) y verificar el funcionamiento de esta funcionalidad sin mucho riesgo para todo el servicio. Incluso si cometió un error grave en alguna parte, todo comenzó a caer y todo el centro de datos cayó, los equilibradores redirigirán las solicitudes a otro centro de datos. Los usuarios finales no notarán nada.
Si observa un problema, puede devolver inmediatamente el valor anterior de la bandera, y los cambios se revertirán.
Este servicio tiene sus inconvenientes: a los desarrolladores les encanta y, a menudo, intentan introducir todos los cambios en Stop Crane. Estamos tratando de combatir el mal uso.
El enfoque Stop Crane funciona bien cuando ya tiene un código estable, listo para implementarse en producción. Al mismo tiempo, aún tiene dudas y desea verificar el código en condiciones de "combate".
Sin embargo, la llave de paso no es adecuada para realizar pruebas durante el desarrollo. Para los desarrolladores, hay un clúster separado llamado "clúster sombra".
Prueba encubierta: cluster de sombra
Las solicitudes de uno de los clústeres se duplican en el clúster de sombra. Pero el equilibrador ignora por completo las respuestas de este clúster. El esquema de su trabajo se presenta a continuación.
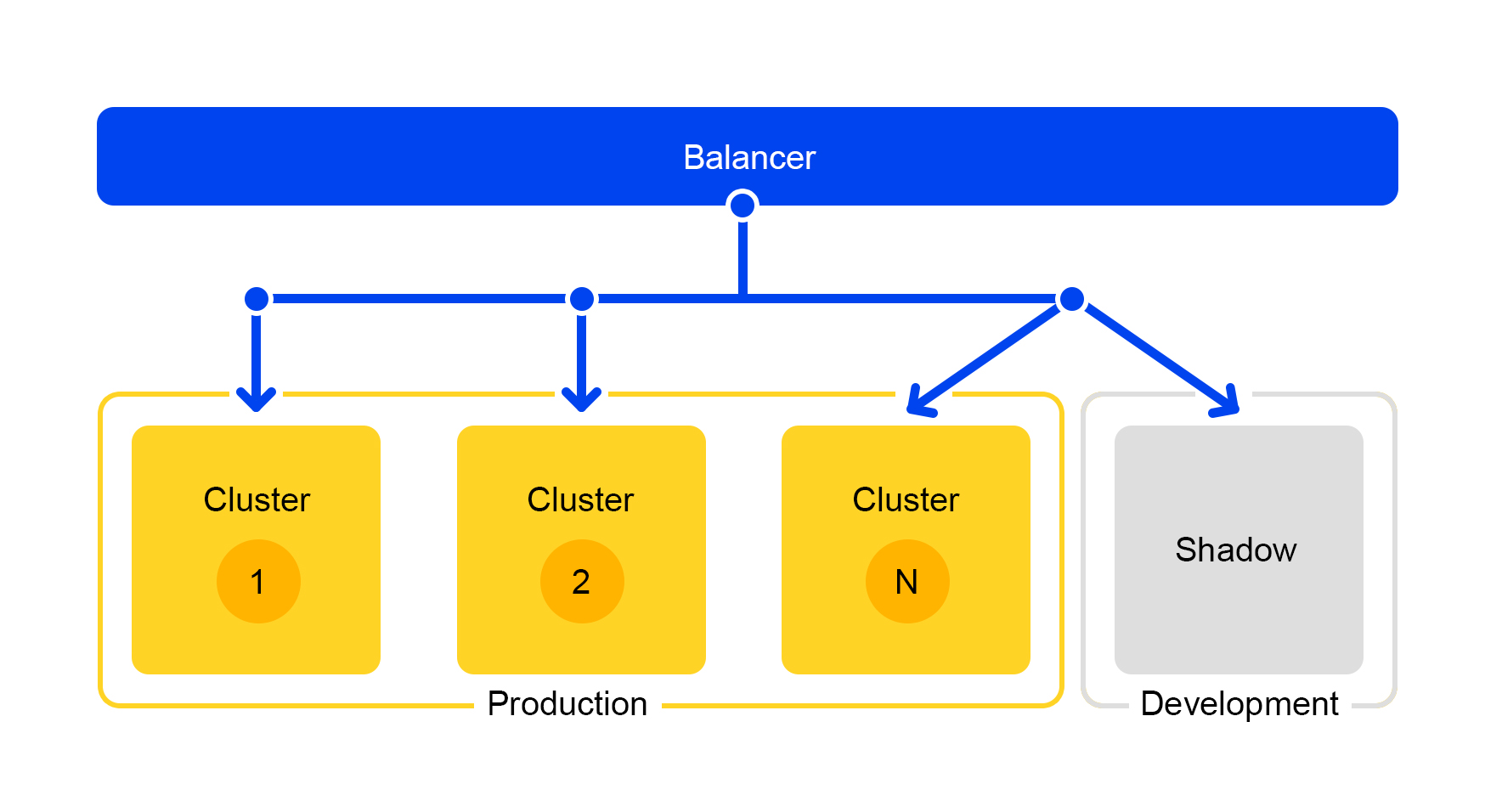
Obtenemos un grupo de prueba que está en condiciones reales de "combate". El tráfico normal de usuarios vuela allí. El hardware en ambos clústeres es el mismo, por lo que puede comparar el rendimiento y los errores.
Y dado que el equilibrador ignora por completo las respuestas, los usuarios finales no verán las respuestas del clúster de sombra. Por lo tanto, no da miedo cometer un error.
Conclusiones
Entonces, ¿cómo construimos una búsqueda de mercado?
Para que todo funcione sin problemas, separamos la funcionalidad en servicios separados. Por lo tanto, puede escalar solo los componentes que necesitamos y simplificar los componentes. Es fácil dar un componente separado a otro equipo y compartir responsabilidades para trabajar en él. Y un ahorro significativo en hierro con este enfoque es una ventaja obvia.
El clúster de sombra también nos ayuda: puede desarrollar servicios, probarlos en el proceso y al mismo tiempo no molestar al usuario.
Bueno y verifica la producción, por supuesto. ¿Necesita cambiar la configuración en mil servidores? Fácil, use una grúa de parada. Por lo tanto, puede implementar inmediatamente una solución compleja lista para usar y volver a una versión estable si surgen problemas.
Espero haber podido mostrar cómo hacemos que el mercado sea rápido y estable con una base de ofertas cada vez mayor. Cómo resolver problemas del servidor, atender una gran cantidad de solicitudes, mejorar la flexibilidad del servicio y hacerlo sin interrumpir los procesos de trabajo.