
Introduccion
El reactor de E / S ( bucle de evento de subproceso único ) es un patrón para escribir software altamente cargado que se utiliza en muchas soluciones populares:
En este artículo, consideraremos los entresijos del reactor de E / S y el principio de su funcionamiento, escribiremos una implementación para menos de 200 líneas de código y forzaremos a un servidor HTTP simple a procesar más de 40 millones de solicitudes / min.
Prólogo
- El artículo fue escrito con el objetivo de ayudar a comprender el funcionamiento del reactor de E / S y, por lo tanto, darse cuenta de los riesgos al usarlo.
- Para dominar el artículo, se requieren conocimientos básicos del lenguaje C y un poco de experiencia en el desarrollo de aplicaciones de red.
- Todo el código está escrito en C estrictamente de acuerdo con ( cuidadosamente: PDF largo ) el estándar C11 para Linux y está disponible en GitHub .
¿Por qué se necesita esto?
Con la creciente popularidad de Internet, los servidores web necesitaban procesar una gran cantidad de conexiones al mismo tiempo y, por lo tanto, se intentaron dos enfoques: bloqueo de E / S en una gran cantidad de hilos del sistema operativo y E / S sin bloqueo en combinación con un sistema de notificación de eventos, también llamado "sistema selector "( epoll / kqueue / IOCP / etc).
El primer enfoque consistió en crear un nuevo hilo del sistema operativo para cada conexión entrante. Su desventaja es la escasa escalabilidad: el sistema operativo tendrá que hacer muchas transiciones de contexto y llamadas al sistema . Son operaciones costosas y pueden conducir a una falta de RAM libre con una cantidad impresionante de conexiones.
La versión modificada asigna un número fijo de subprocesos (conjunto de subprocesos), evitando así que el sistema detenga anormalmente la ejecución, pero al mismo tiempo presenta un nuevo problema: si en el momento dado el conjunto de subprocesos está bloqueado por operaciones de lectura largas, entonces otros sockets que ya pueden recibir datos No será capaz de hacer esto.
El segundo enfoque utiliza el sistema de notificación de eventos (selector de sistema) que proporciona el sistema operativo. Este artículo analiza el tipo más común de selector de sistema basado en alertas (eventos, notificaciones) sobre la preparación para operaciones de E / S, en lugar de alertas sobre su finalización . Un ejemplo simplificado de su uso puede representarse mediante el siguiente diagrama de flujo:

La diferencia entre estos enfoques es la siguiente:
- El bloqueo de las operaciones de E / S suspende la secuencia del usuario hasta que el sistema operativo desfragmente correctamente los paquetes IP entrantes en la secuencia de bytes ( TCP , recibiendo datos) o liberando suficiente espacio en los búferes de escritura internos para su posterior envío a través de NIC (envío de datos).
- Después de un tiempo, el selector del sistema notifica al programa que el sistema operativo ya ha desfragmentado los paquetes IP (TCP, recibiendo datos) o que ya hay suficiente espacio disponible en los búferes de grabación internos (envío de datos).
Para resumir, reservar el hilo del sistema operativo para cada E / S es un desperdicio de poder de cómputo, porque en realidad, los hilos no están ocupados con el trabajo útil (el término "interrupción de software" tiene sus raíces en él ). El selector del sistema resuelve este problema al permitir que el programa del usuario consuma recursos de la CPU de manera mucho más económica.
Modelo de E / S del reactor
Un reactor de E / S actúa como una capa entre el selector del sistema y el código de usuario. El principio de su funcionamiento se describe en el siguiente diagrama de flujo:
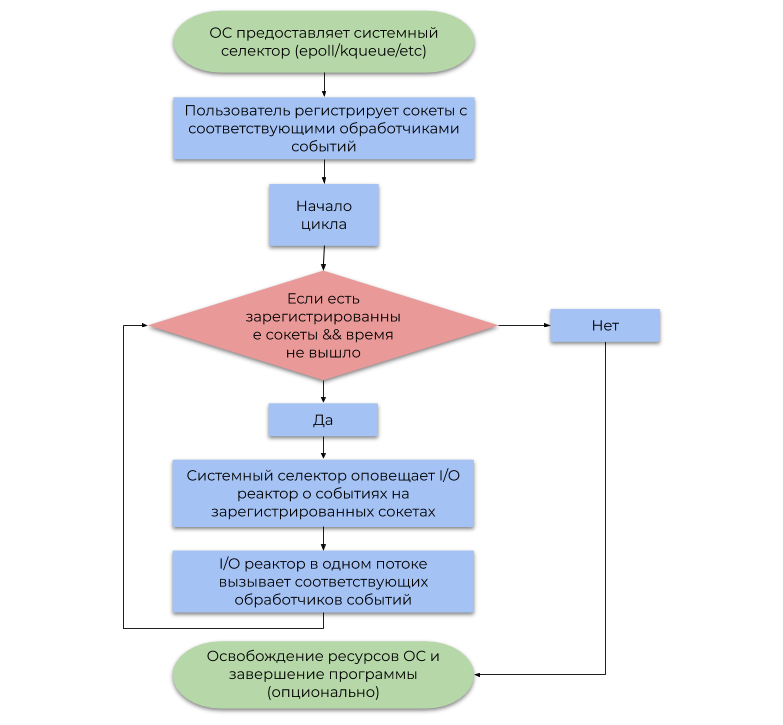
- Permítame recordarle que un evento es una notificación de que un determinado socket puede realizar una operación de E / S sin bloqueo.
- Un controlador de eventos es una función llamada por el reactor de E / S cuando se recibe un evento, que luego realiza una operación de E / S sin bloqueo.
Es importante tener en cuenta que el reactor de E / S es, por definición, de un solo subproceso, pero nada impide usar el concepto en un entorno de subprocesos múltiples con respecto a 1 flujo: 1 reactor, por lo que utiliza todos los núcleos de la CPU.
Implementación
Ponemos la interfaz pública en el archivo reactor.h , y la implementación en reactor.c . reactor.h constará de las siguientes declaraciones:
Mostrar anuncios en reactor.h typedef struct reactor Reactor; typedef void (*Callback)(void *arg, int fd, uint32_t events); Reactor *reactor_new(void); int reactor_destroy(Reactor *reactor); int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_deregister(const Reactor *reactor, int fd); int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_run(const Reactor *reactor, time_t timeout);
La estructura de E / S del reactor consta de un descriptor de archivo selector de epoll y una tabla hash GHashTable , que cada socket se asigna a CallbackData (una estructura de un controlador de eventos y un argumento de usuario para ello).
Mostrar Reactor y CallbackData struct reactor { int epoll_fd; GHashTable *table;
Tenga en cuenta que hemos utilizado la capacidad de manejar un tipo incompleto por puntero. En reactor.h declaramos la estructura del reactor , y en reactor.c definimos, evitando así que el usuario cambie explícitamente sus campos. Este es uno de los patrones de ocultación de datos que se adapta orgánicamente a la semántica de C.
Las reactor_register , reactor_deregister y reactor_reregister actualizan la lista de sockets de interés y los controladores de eventos correspondientes en el selector del sistema y en la tabla hash.
Mostrar funciones de registro #define REACTOR_CTL(reactor, op, fd, interest) \ if (epoll_ctl(reactor->epoll_fd, op, fd, \ &(struct epoll_event){.events = interest, \ .data = {.fd = fd}}) == -1) { \ perror("epoll_ctl"); \ return -1; \ } int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; } int reactor_deregister(const Reactor *reactor, int fd) { REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0) g_hash_table_remove(reactor->table, &fd); return 0; } int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; }
Después de que el reactor de E / S intercepta el evento con el descriptor fd , llama al controlador de eventos correspondiente, al que pasa fd , la máscara de bits de los eventos generados y el puntero del usuario para void .
Mostrar la función reactor_run () int reactor_run(const Reactor *reactor, time_t timeout) { int result; struct epoll_event *events; if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL) abort(); time_t start = time(NULL); while (true) { time_t passed = time(NULL) - start; int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) {
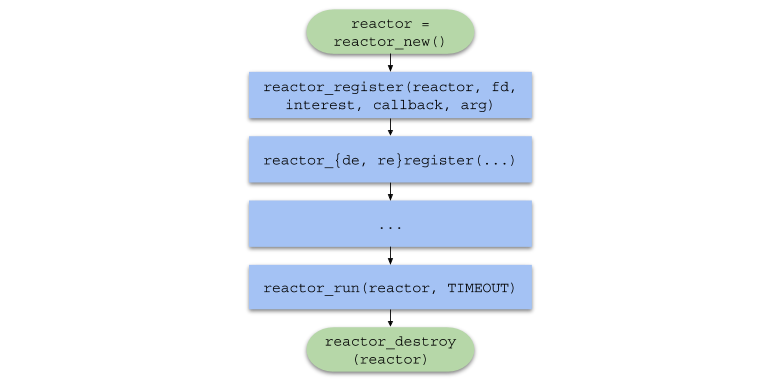
Para resumir, la cadena de llamadas de función en código de usuario tomará la siguiente forma:
Servidor de un solo hilo
Para probar el reactor de E / S bajo alta carga, escribiremos un servidor web HTTP simple para responder a cualquier solicitud con una imagen.
Referencia rápida del protocolo HTTPHTTP es un protocolo de nivel de aplicación utilizado principalmente para la interacción del servidor con un navegador.
HTTP se puede usar fácilmente sobre el protocolo de transporte TCP , enviando y recibiendo mensajes del formato definido por la especificación .
<> <URI> < HTTP>CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
CRLF es una secuencia de dos caracteres: \r y \n , que separa la primera línea de consulta, encabezados y datos.<> es uno de CONNECT , DELETE , GET , HEAD , OPTIONS , PATCH , POST , PUT , TRACE . El navegador enviará un comando GET a nuestro servidor, que significa "Enviarme el contenido del archivo".<URI> es el identificador de recurso unificado . Por ejemplo, si URI = /index.html , el cliente solicita la página principal del sitio.< HTTP> - Versión del protocolo HTTP/XY en formato HTTP/XY . La versión más utilizada hasta la fecha es HTTP/1.1 .< N> es un par clave-valor en el formato <>: <> , enviado al servidor para su posterior análisis.<> : datos requeridos por el servidor para completar la operación. A menudo es solo JSON o cualquier otro formato.
< HTTP> < > < >CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
< > es un número que representa el resultado de una operación. Nuestro servidor siempre devolverá el estado 200 (operación exitosa).< > - representación en cadena del código de estado. Para el código de estado 200, esto está OK .< N> : un encabezado del mismo formato que en la solicitud. Devolveremos los Content-Length (tamaño de archivo) y Content-Type: text/html (return type data).<> - datos solicitados por el usuario. En nuestro caso, esta es la ruta a la imagen en HTML .
El http_server.c (servidor de un solo subproceso) incluye el archivo common.h , que contiene los siguientes prototipos de funciones:
Mostrar prototipos de funciones en común. H static void on_accept(void *arg, int fd, uint32_t events); static void on_send(void *arg, int fd, uint32_t events); static void on_recv(void *arg, int fd, uint32_t events); static void set_nonblocking(int fd); static noreturn void fail(const char *format, ...); static int new_server(bool reuse_port);
La función macro SAFE_CALL() también se describe y se define la función fail() . La macro compara el valor de la expresión con el error, y si se cumple la condición, llama a la función fail() :
#define SAFE_CALL(call, error) \ do { \ if ((call) == error) { \ fail("%s", #call); \ } \ } while (false)
La función fail() imprime los argumentos pasados al terminal (como printf() ) y finaliza el programa con el código EXIT_FAILURE :
static noreturn void fail(const char *format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fprintf(stderr, ": %s\n", strerror(errno)); exit(EXIT_FAILURE); }
La función new_server() devuelve el descriptor de archivo del socket del "servidor" creado por el sistema llama a socket() , bind() y listen() y es capaz de aceptar conexiones entrantes en modo sin bloqueo.
Mostrar función new_server () static int new_server(bool reuse_port) { int fd; SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)), -1); if (reuse_port) { SAFE_CALL( setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)), -1); } struct sockaddr_in addr = {.sin_family = AF_INET, .sin_port = htons(SERVER_PORT), .sin_addr = {.s_addr = inet_addr(SERVER_IPV4)}, .sin_zero = {0}}; SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1); SAFE_CALL(listen(fd, SERVER_BACKLOG), -1); return fd; }
- Tenga en cuenta que el socket se crea inicialmente en modo sin bloqueo utilizando el indicador
SOCK_NONBLOCK , de modo que en la función on_accept() (para leer más), la llamada al sistema accept() no detiene la ejecución de la secuencia. - Si
reuse_port es true , entonces esta función configurará el socket con la opción SO_REUSEPORT usando setsockopt() para usar el mismo puerto en un entorno multiproceso (consulte la sección "Servidor multiproceso").
Se on_accept() controlador de eventos on_accept() después de que el sistema operativo genera un evento EPOLLIN , en este caso, lo que significa que se puede aceptar una nueva conexión. on_accept() acepta una nueva conexión, la cambia al modo sin bloqueo y se registra con el controlador de eventos on_recv() en el reactor de E / S.
Mostrar la función on_accept () static void on_accept(void *arg, int fd, uint32_t events) { int incoming_conn; SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1); set_nonblocking(incoming_conn); SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv, request_buffer_new()), -1); }
El controlador de eventos on_recv() se llama después de que el sistema operativo genera un evento EPOLLIN , en este caso, significa que la conexión registrada on_accept() está lista para recibir datos.
on_recv() lee los datos de la conexión hasta que se haya recibido la solicitud HTTP completa, luego registra el controlador on_send() para enviar la respuesta HTTP. Si el cliente se desconecta, el socket se da de baja y se cierra con close() .
Mostrar la función on_recv () static void on_recv(void *arg, int fd, uint32_t events) { RequestBuffer *buffer = arg;
Se on_send() controlador de eventos on_send() después de que el sistema operativo genera un evento EPOLLOUT , lo que significa que la conexión registrada por on_recv() está lista para enviar datos. Esta función envía una respuesta HTTP que contiene HTML con la imagen al cliente y luego cambia el controlador de eventos a on_recv() nuevamente.
Mostrar la función on_send () static void on_send(void *arg, int fd, uint32_t events) { const char *content = "<img " "src=\"https://habrastorage.org/webt/oh/wl/23/" "ohwl23va3b-dioerobq_mbx4xaw.jpeg\">"; char response[1024]; sprintf(response, "HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: " "text/html" DOUBLE_CRLF "%s", strlen(content), content); SAFE_CALL(send(fd, response, strlen(response), 0), -1); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1); }
Y finalmente, en el archivo http_server.c , en la función main() , creamos un reactor de E / S usando reactor_new() , creamos un socket de servidor y lo registramos, reactor_run() el reactor usando reactor_run() exactamente un minuto, y luego reactor_run() los recursos y salimos del programa
Mostrar http_server.c #include "reactor.h" static Reactor *reactor; #include "common.h" int main(void) { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL( reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); }
Verifique que todo funcione como se esperaba. chmod a+x compile.sh && ./compile.sh ( chmod a+x compile.sh && ./compile.sh en la raíz del proyecto) e chmod a+x compile.sh && ./compile.sh , abrimos http://127.0.0.1:18470 en el navegador y observamos lo que se esperaba:
Medida de rendimiento
Mostrar las características de mi auto $ screenfetch MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic MMd /++ -sNMd: Uptime: 2h 34m MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217 ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20 NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080 NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10 NMm dMM -MMm `MMM dMM. dMM WM: Muffin NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y) NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3] hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y -NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9 -dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C] `/dMNmy+/:-------------:/yMMM GPU: NV136 ./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB \.MMMMMMMMMMMMMMMMMMM
Medimos el rendimiento de un servidor de subproceso único. ./http_server dos terminales: en uno ejecutamos ./http_server , en el otro - wrk . Después de un minuto, se mostrarán las siguientes estadísticas en el segundo terminal:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 493.52us 76.70us 17.31ms 89.57% Req/Sec 24.37k 1.81k 29.34k 68.13% 11657769 requests in 1.00m, 1.60GB read Requests/sec: 193974.70 Transfer/sec: 27.19MB
Nuestro servidor de subproceso único pudo procesar más de 11 millones de solicitudes por minuto, originando a partir de 100 conexiones. No es un mal resultado, pero ¿se puede mejorar?
Servidor multiproceso
Como se mencionó anteriormente, se puede crear un reactor de E / S en flujos separados, utilizando así todos los núcleos de la CPU. Apliquemos este enfoque en la práctica:
Mostrar http_server_multithreaded.c #include "reactor.h" static Reactor *reactor; #pragma omp threadprivate(reactor) #include "common.h" int main(void) { #pragma omp parallel { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); } }
Ahora cada hilo posee su propio reactor:
static Reactor *reactor; #pragma omp threadprivate(reactor)
Tenga en cuenta que el argumento de new_server() es true . Esto significa que estamos configurando el socket del servidor a la opción SO_REUSEPORT para usarlo en un entorno de subprocesos múltiples. Puedes leer más aquí .
Segunda carrera
Ahora mediremos el rendimiento de un servidor multiproceso:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 1.14ms 2.53ms 40.73ms 89.98% Req/Sec 79.98k 18.07k 154.64k 78.65% 38208400 requests in 1.00m, 5.23GB read Requests/sec: 635876.41 Transfer/sec: 89.14MB
¡El número de solicitudes procesadas en 1 minuto aumentó en ~ 3.28 veces! Pero hasta el número redondo, solo ~ dos millones no fueron suficientes, intentemos solucionarlo.
Primero, mira las estadísticas generadas por perf :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded Performance counter stats for './http_server_multithreaded': 242446,314933 task-clock (msec) # 4,000 CPUs utilized 1 813 074 context-switches # 0,007 M/sec 4 689 cpu-migrations # 0,019 K/sec 254 page-faults # 0,001 K/sec 895 324 830 170 cycles # 3,693 GHz 621 378 066 808 instructions # 0,69 insn per cycle 119 926 709 370 branches # 494,653 M/sec 3 227 095 669 branch-misses # 2,69% of all branches 808 664 cache-misses 60,604330670 seconds time elapsed
Al usar la afinidad de la CPU , compilar con -march=native , PGO , aumentar el número de visitas en la memoria caché , aumentar MAX_EVENTS y usar EPOLLET no dio un aumento significativo en el rendimiento. Pero, ¿qué sucede si aumenta el número de conexiones simultáneas?
Estadísticas para 352 conexiones simultáneas:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 352 connections Thread Stats Avg Stdev Max +/- Stdev Latency 2.12ms 3.79ms 68.23ms 87.49% Req/Sec 83.78k 12.69k 169.81k 83.59% 40006142 requests in 1.00m, 5.48GB read Requests/sec: 665789.26 Transfer/sec: 93.34MB
Se obtuvo el resultado deseado, y con él un gráfico interesante que muestra la dependencia del número de solicitudes procesadas en 1 minuto con respecto al número de conexiones:
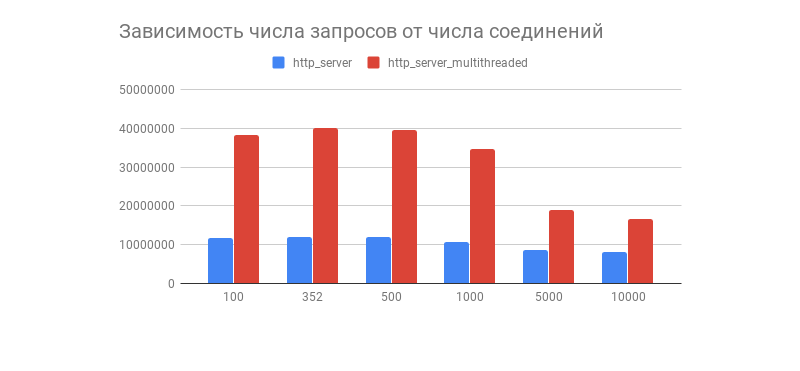
Vemos que después de un par de cientos de conexiones, el número de solicitudes procesadas de ambos servidores cae bruscamente (en una versión multiproceso, esto es más notable). ¿Está relacionado con la implementación de la pila TCP / IP de Linux? Siéntase libre de escribir sus suposiciones sobre dicho comportamiento gráfico y las optimizaciones de las opciones de subprocesos y subprocesos múltiples en los comentarios.
Como se señaló en los comentarios, esta prueba de rendimiento no muestra el comportamiento del reactor de E / S a cargas reales, porque casi siempre el servidor interactúa con la base de datos, muestra registros, usa criptografía con TLS , etc., como resultado de lo cual la carga se vuelve heterogénea (dinámica). Las pruebas junto con los componentes de terceros se realizarán en un artículo sobre el proactor de E / S.
Desventajas del reactor de E / S
Debe comprender que el reactor de E / S no está exento de inconvenientes, a saber:
- Usar un reactor de E / S en un entorno multiproceso es algo más difícil porque Tienes que gestionar manualmente los flujos.
- La práctica muestra que en la mayoría de los casos la carga es heterogénea, lo que puede llevar al hecho de que un subproceso se soltará mientras que el otro se carga con trabajo.
- Si un controlador de eventos bloquea la transmisión, el selector del sistema también se bloqueará, lo que puede provocar errores difíciles de detectar.
El supervisor de E / S resuelve estos problemas, a menudo con un programador que distribuye la carga de manera uniforme al grupo de subprocesos y también tiene una API más conveniente. Se discutirá más adelante en mi otro artículo.
Conclusión
En esto, nuestro viaje desde la teoría directamente al perfilador de escape llegó a su fin.
No se detenga en esto, porque hay muchos otros enfoques igualmente interesantes para escribir software de red con diferentes niveles de conveniencia y velocidad. Interesante, en mi opinión, los enlaces se dan a continuación.
Hasta pronto!
Proyectos interesantes
¿Qué más leer?