Hola Hoy les contaré a los lectores de Habr cómo creamos la tecnología de reconocimiento de texto que funciona en 45 idiomas y que es accesible para los usuarios de Yandex.Cloud, qué tareas configuramos y cómo las resolvimos. Será útil si está trabajando en proyectos similares o quiere saber cómo sucedió que hoy solo necesita fotografiar el letrero de la tienda turca para que Alice lo traduzca al ruso.

La tecnología de reconocimiento óptico de caracteres (OCR) se ha desarrollado en el mundo durante décadas. En Yandex, comenzamos a desarrollar nuestra propia tecnología OCR para mejorar nuestros servicios y ofrecer a los usuarios más opciones. Las imágenes son una gran parte de Internet, y sin la capacidad de comprenderlas, la búsqueda en Internet será incompleta.
Las soluciones de análisis de imágenes son cada vez más populares. Esto se debe a la proliferación de redes neuronales artificiales y dispositivos con sensores de alta calidad. Está claro que, en primer lugar, estamos hablando de teléfonos inteligentes, pero no solo de ellos.
La complejidad de las tareas en el campo del reconocimiento de texto está en constante crecimiento; todo comenzó con el reconocimiento de documentos escaneados. Luego se agregó el
reconocimiento de imágenes Born-Digital con texto de Internet. Luego, con la creciente popularidad de las cámaras móviles, el reconocimiento de buenas tomas de cámara (
texto de escena enfocado ). Y cuanto más lejos, más complicados son los parámetros: el texto puede ser borroso (
texto de escena incidental ),
escrito con cualquier curva o en espiral, de varias categorías, desde
fotografías de recibos hasta
estantes y letreros.
En que dirección fuimos
El reconocimiento de texto es una clase separada de tareas de visión por computadora. Como muchos algoritmos de visión por computadora, antes de la popularidad de las redes neuronales, se basaba principalmente en características manuales y heurísticas. Sin embargo, recientemente, con la transición a los enfoques de redes neuronales, la calidad de la tecnología ha crecido significativamente. Mira el ejemplo en la foto. Cómo sucedió esto, lo contaré más.
Compare los resultados de reconocimiento de hoy con los resultados de principios de 2018:
¿Qué dificultades encontramos al principio?
Al comienzo de nuestro viaje, creamos tecnología de reconocimiento para ruso e inglés, y los principales casos de uso fueron fotografías de páginas de texto e imágenes de Internet. Pero en el transcurso del trabajo, nos dimos cuenta de que esto no es suficiente: el texto de las imágenes se encontró en cualquier idioma, en cualquier superficie, y las imágenes a veces resultaron ser de una calidad muy diferente. Esto significa que el reconocimiento debería funcionar en cualquier situación y en todos los tipos de datos entrantes.
Y aquí nos enfrentamos a una serie de dificultades. Aquí hay algunos:
- Detalles Para una persona que está acostumbrada a obtener información del texto, el texto de la imagen es párrafos, líneas, palabras y letras, pero para una red neuronal todo parece diferente. Debido a la naturaleza compleja del texto, la red se ve obligada a ver tanto la imagen como un todo (por ejemplo, si las personas se unieron y construyeron una inscripción), y los detalles más pequeños (en el idioma vietnamita, los símbolos similares ử y ừ cambian el significado de las palabras). Los desafíos separados son reconocer texto arbitrario y fuentes no estándar.
- Multilingüismo Cuantos más idiomas agregamos, más nos enfrentamos con sus detalles: en cirílico y latín las palabras se componen de letras separadas, en árabe se escriben juntas, en japonés no se distinguen palabras separadas. Algunos idiomas usan ortografía de izquierda a derecha, algunos de derecha a izquierda. Algunas palabras se escriben horizontalmente, algunas verticalmente. Una herramienta universal debe tener en cuenta todas estas características.
- La estructura del texto . Para reconocer imágenes específicas, como cheques o documentos complejos, es crucial una estructura que tenga en cuenta el diseño de los párrafos, las tablas y otros elementos.
- Rendimiento La tecnología se utiliza en una amplia variedad de dispositivos, incluso fuera de línea, por lo que tuvimos que tener en cuenta los estrictos requisitos de rendimiento.
Selección del modelo de detección
El primer paso para reconocer el texto es determinar su posición (detección).
La detección de texto se puede considerar como una tarea de reconocimiento de objetos, donde los
caracteres individuales,
palabras o
líneas pueden actuar como un objeto.
Para nosotros era importante que el modelo se escalara posteriormente a otros idiomas (ahora admitimos 45 idiomas).
Muchos artículos de investigación sobre detección de texto utilizan modelos que predicen la posición de
palabras individuales. Pero en el caso de un
modelo universal, este enfoque tiene varias limitaciones: por ejemplo, el concepto mismo de una palabra para el idioma chino es fundamentalmente diferente del concepto de una palabra, por ejemplo, en inglés. Las palabras individuales en chino no están separadas por un espacio. En tailandés, solo las oraciones individuales se descartan con un espacio.
Aquí hay ejemplos del mismo texto en ruso, chino y tailandés:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วLas líneas , a su vez, son muy variables en términos de relación de aspecto. Debido a esto, las posibilidades de tales modelos de detección comunes (por ejemplo, basados en SSD o RCNN) para la predicción de línea son limitadas, ya que estos modelos se basan en regiones candidatas / cuadros de anclaje con muchas relaciones de aspecto predefinidas. Además, las líneas pueden tener una forma arbitraria, por ejemplo, curva, por lo tanto, para una descripción cualitativa de las líneas, no es suficiente describir exclusivamente el cuadrángulo, incluso con un ángulo de rotación.
A pesar del hecho de que las posiciones de los
caracteres individuales
son locales y se describen, su inconveniente es que se requiere un paso de procesamiento posterior separado: debe seleccionar la heurística para pegar caracteres en palabras y líneas.
Por lo tanto, tomamos
el modelo SegLink como base para la detección, cuya idea principal es descomponer líneas / palabras en dos entidades locales más: segmentos y relaciones entre ellas.
Arquitectura del detector
La arquitectura del modelo se basa en SSD, que predice la posición de los objetos en varias escalas de características. Solo además de predecir las coordenadas de "segmentos" individuales también se predicen "conexiones" entre segmentos adyacentes, es decir, si dos segmentos pertenecen a la misma línea. Las "conexiones" se predicen tanto para segmentos vecinos en la misma escala de signos como para segmentos ubicados en áreas adyacentes en escalas vecinas (los segmentos de diferentes escalas de signos pueden variar ligeramente en tamaño y pertenecen a la misma línea).
Para cada escala, cada celda de entidad está asociada con un "segmento" correspondiente. Para cada segmento s
(x, y, l) en el punto (x, y) en una escala l, se entrena lo siguiente:
- p
s si el segmento dado es texto;
- x
s , y
s , w
s , h
s , θ
s - el desplazamiento de las coordenadas de la base y el ángulo de inclinación del segmento;
- 8 puntaje para la presencia de "conexiones" con segmentos adyacentes a la escala l-ésima (L
w s, s ' , s' de {s
(x ', y', l) } / s
(x, y, l) , donde x –1 ≤ x '≤ x + 1, y - 1 ≤ y' ≤ y + 1);
- 4 puntaje para la presencia de "conexiones" con segmentos adyacentes a la escala l-1 (L
c s, s ' , s' de {s
(x ', y', l-1) }, donde 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (lo cual es cierto debido al hecho de que la dimensión de las características en escalas vecinas difiere exactamente 2 veces).
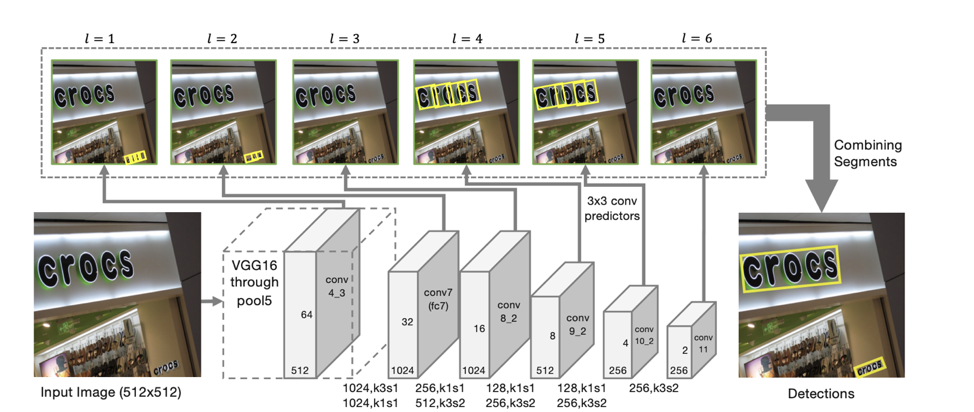
De acuerdo con tales predicciones, si tomamos como vértices todos los segmentos para los cuales la probabilidad de que sean texto es mayor que el umbral α, y como bordes todos los enlaces cuya probabilidad es mayor que el umbral β, entonces los segmentos forman componentes conectados, cada uno de los cuales describe una línea de texto .
El modelo resultante tiene una
alta capacidad de generalización : incluso capacitado en los primeros enfoques sobre datos en ruso e inglés, encontró cualitativamente texto en chino y árabe.
Diez guiones
Si para la detección pudimos crear un modelo que funciona inmediatamente para todos los idiomas, entonces para el reconocimiento de líneas encontradas dicho modelo es mucho más difícil de obtener. Por lo tanto, decidimos usar un
modelo separado para cada escritura (cirílico, latín, árabe, hebreo, griego, armenio, georgiano, coreano, tailandés). Se usa un modelo general separado para chino y japonés debido a la gran intersección en jeroglíficos.
El modelo común a todo el script difiere del modelo separado para cada idioma en menos de 1 p.p. calidad Al mismo tiempo, la creación e implementación de un modelo es más simple que, por ejemplo, 25 modelos (la cantidad de idiomas latinos admitidos por nuestro modelo). Pero debido a la presencia frecuente de inglés en todos los idiomas, todos nuestros modelos pueden predecir, además del guión principal, caracteres latinos.
Para comprender qué modelo debe usarse para el reconocimiento, primero determinamos si las líneas recibidas pertenecen a uno de los 10 scripts disponibles para el reconocimiento.
Debe notarse por separado que no siempre es posible determinar de manera única su script a lo largo de la línea. Por ejemplo, los números o caracteres latinos individuales están contenidos en muchos scripts, por lo que una de las clases de salida del modelo es un script "indefinido".
Definición de guión
Para definir el script, creamos un clasificador separado. La tarea de definir un script es mucho más simple que la tarea de reconocimiento, y la red neuronal se vuelve a entrenar fácilmente con datos sintéticos. Por lo tanto, en nuestros experimentos, se dio una mejora significativa en la calidad del modelo mediante
la capacitación previa sobre el problema del reconocimiento de cuerdas . Para hacer esto, primero capacitamos a la red para el problema de reconocimiento de todos los idiomas disponibles. Después de eso, la columna vertebral resultante se usó para inicializar el modelo en la tarea de clasificación del script.
Si bien un guión en una línea individual suele ser bastante ruidoso, la imagen en su conjunto a menudo contiene texto en un idioma, además del principal intercalado con inglés (o en el caso de nuestros usuarios rusos). Por lo tanto, para
aumentar la estabilidad, agregamos las predicciones de líneas de la imagen para obtener una predicción más estable del guión de la imagen. Las líneas con una clase prevista de "indefinido" no se tienen en cuenta en la agregación.
Reconocimiento de línea
El siguiente paso, cuando ya hemos determinado la posición de cada línea y su guión, debemos
reconocer la secuencia de caracteres del guión dado que se muestra en ella, es decir, de la secuencia de píxeles para predecir la secuencia de caracteres. Después de muchos experimentos, llegamos al siguiente modelo basado en la secuencia de atención secuencial:

El uso de CNN + BiLSTM en el codificador le permite obtener signos que capturan contextos locales y globales. Para el texto, esto es importante: a menudo se escribe en una fuente (es mucho más fácil distinguir letras similares con información de fuente). Y para distinguir dos letras escritas con un espacio de las consecutivas, también se necesitan estadísticas globales para la línea.
Una observación interesante : en el modelo resultante, las salidas de la máscara de atención para un símbolo particular se pueden usar para predecir su posición en la imagen.
Esto nos inspiró a tratar de
"enfocar" claramente la atención del modelo . Dichas ideas también se encontraron en artículos, por ejemplo, en el artículo
Atención centrada: hacia el reconocimiento preciso de texto en imágenes naturales .
Dado que el mecanismo de atención proporciona una distribución de probabilidad sobre el espacio de características, si tomamos como pérdida adicional la suma de las salidas de atención dentro de la máscara correspondiente a la letra predicha en este paso, obtenemos la parte de la "atención" que se enfoca directamente en ella.
Al introducir pérdida-registro (∑
i, j∈M t α
i, j ), donde M
t es la máscara de la letra tth, α es la salida de la atención, fomentaremos la "atención" para centrarse en el símbolo dado y así ayudar Las redes neuronales aprenden mejor.
Para aquellos ejemplos de entrenamiento para los que la ubicación de los caracteres individuales es desconocida o inexacta (no todos los datos de entrenamiento tienen marcas a nivel de caracteres individuales, no palabras), este término no se tuvo en cuenta en la pérdida final.
Otra buena característica: esta arquitectura le permite predecir el
reconocimiento de líneas de derecha a izquierda sin cambios adicionales (que es importante, por ejemplo, para idiomas como el árabe, el hebreo). El modelo en sí comienza a emitir reconocimiento de derecha a izquierda.
Modelos rápidos y lentos
En el proceso, encontramos un problema:
para las fuentes "altas" , es decir, las fuentes alargadas verticalmente, el modelo funcionó mal. Esto fue causado por el hecho de que la dimensión de los signos en el nivel de atención es 8 veces menor que la dimensión de la imagen original debido a avances y tirones en la arquitectura de la parte convolucional de la red. Y las ubicaciones de varios caracteres vecinos en la imagen de origen pueden corresponder a la ubicación del mismo vector de características, lo que puede conducir a errores en tales ejemplos. El uso de la arquitectura con un estrechamiento menor de la dimensión de las características condujo a un aumento en la calidad, pero también a un aumento en el tiempo de procesamiento.
Para resolver este problema y
evitar aumentar el tiempo de procesamiento , realizamos las siguientes mejoras en el modelo:
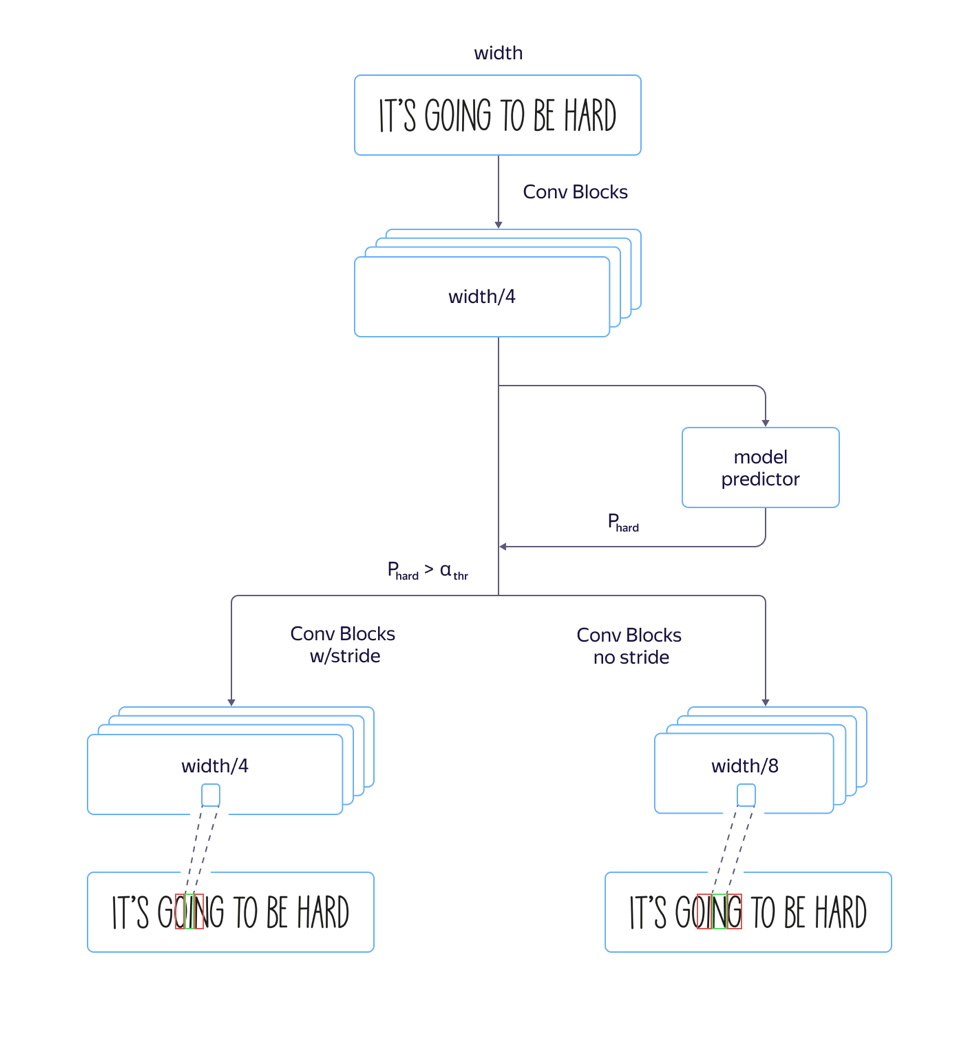
Entrenamos tanto un modelo rápido con muchos avances como uno lento con menos. En la capa donde los parámetros del modelo comenzaron a diferir, agregamos una salida de red separada que predijo qué modelo tendría menos error de reconocimiento. La pérdida total del modelo se compuso de L
pequeño + L
grande + L de
calidad . Así, en la capa intermedia, el modelo aprendió a determinar la "complejidad" de este ejemplo. Además, en la etapa de aplicación, se consideró la parte general y la predicción de la "complejidad" del ejemplo para todas las líneas, y dependiendo de su salida, en el futuro se utilizó un modelo rápido o lento utilizando el valor umbral. Esto nos permitió obtener una calidad que casi no es diferente de la calidad de un modelo largo, mientras que la velocidad aumentó solo un 5% por ciento en lugar del 30% estimado.
Datos de entrenamiento
Una etapa importante en la creación de un modelo de alta calidad es la preparación de una muestra de entrenamiento grande y variada. La naturaleza "sintética" del texto permite generar grandes cantidades de ejemplos y obtener resultados decentes en datos reales.
Después del primer enfoque para la generación de datos sintéticos, observamos cuidadosamente los resultados del modelo obtenido y descubrimos que el modelo no reconoce bien las letras individuales 'I' debido al sesgo en los textos utilizados para crear el conjunto de entrenamiento. Por lo tanto, claramente generamos un
conjunto de ejemplos "problemáticos" , y cuando lo agregamos a los datos iniciales del modelo, la calidad aumentó significativamente. Repetimos este proceso muchas veces, agregando cortes cada vez más complejos, en los que queríamos mejorar la calidad del reconocimiento.
El punto importante es que los
datos generados
deben ser diversos y similares a los reales . Y si desea que el modelo funcione en fotografías de texto en hojas de papel, y todo el conjunto de datos sintéticos contiene texto escrito en la parte superior de los paisajes, entonces esto puede no funcionar.
Otro paso importante es usar para entrenar aquellos ejemplos en los cuales el reconocimiento actual está equivocado. Si hay una gran cantidad de imágenes para las que no hay marcado, puede tomar esas salidas del sistema de reconocimiento actual en el que no está segura y marcarlas solo, reduciendo así el costo del marcado.
Para ejemplos complejos, solicitamos a los usuarios del servicio Yandex.Tolok una tarifa para fotografiar y enviarnos
imágenes de un determinado grupo "complejo" , por ejemplo, fotos de paquetes de productos:


Calidad del trabajo en datos "complejos"
Queremos brindar a nuestros usuarios la oportunidad de trabajar con fotografías de cualquier complejidad, ya que puede ser necesario reconocer o traducir texto no solo en la página de un libro o un documento escaneado, sino también en un letrero de la calle, publicidad o empaque del producto. Por lo tanto, mientras mantenemos la alta calidad del trabajo en el flujo de libros y documentos (dedicaremos una historia separada a este tema), prestamos especial atención a los "conjuntos complejos de imágenes".
De la manera descrita anteriormente, hemos compilado un conjunto de imágenes que contienen texto en la naturaleza que pueden ser útiles para nuestros usuarios: fotografías de letreros, anuncios, tabletas, portadas de libros, textos sobre electrodomésticos, ropa y objetos. En este conjunto de datos (cuyo enlace se encuentra a continuación), evaluamos la calidad de nuestro algoritmo.
Como medida de comparación, utilizamos la medida estándar de precisión e integridad del reconocimiento de palabras en el conjunto de datos, así como la medida F. Una palabra reconocida se considera encontrada correctamente si sus coordenadas corresponden a las coordenadas de la palabra marcada (IoU> 0.3) y el reconocimiento coincide con el marcado exactamente al caso. Cifras sobre el conjunto de datos resultante:
El conjunto de datos, las métricas y los scripts para reproducir los resultados están disponibles
aquí .
Upd. Amigos, comparar nuestra tecnología con una solución similar de Abbyy causó mucha controversia. Respetamos las opiniones de la comunidad y los pares de la industria. Pero al mismo tiempo confiamos en nuestros resultados, así que decidimos de esta manera: eliminaremos los resultados de otros productos de la comparación, discutiremos la metodología de prueba con ellos nuevamente y volveremos a los resultados en los que llegamos a un acuerdo general.
Próximos pasos
En la unión de los pasos individuales, como la detección y el reconocimiento, siempre surgen problemas: los cambios más leves en el modelo de detección implican la necesidad de cambiar el modelo de reconocimiento, por lo que estamos experimentando activamente con la creación de una solución de extremo a extremo.
Además de las formas ya descritas de mejorar la tecnología, desarrollaremos una dirección para analizar la estructura del documento, que es fundamentalmente importante cuando se extrae información y es una demanda entre los usuarios.
Conclusión
Los usuarios ya están acostumbrados a las tecnologías convenientes y sin dudarlo encienden la cámara, señalan el letrero de la tienda, el menú del restaurante o la página del libro en un idioma extranjero y reciben rápidamente una traducción. Reconocemos el texto en 45 idiomas con precisión comprobada, y las oportunidades solo se expandirán. Un conjunto de herramientas dentro de Yandex.Cloud permite a cualquiera que quiera usar las mejores prácticas que Yandex ha estado haciendo por sí mismas durante mucho tiempo.
Hoy puede simplemente tomar la tecnología terminada, integrarla en su propia aplicación y usarla para crear nuevos productos y automatizar sus propios procesos. La documentación de nuestro OCR está disponible
aquí .
Que leer:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh y PP Roy, "ICDAR 2011 concurso de lectura robusta-desafío 1: leer texto en imágenes digitales nacidas (web y correo electrónico)", en Análisis y reconocimiento de documentos (ICDAR ), 2011 Conferencia Internacional sobre. IEEE, 2011, pp. 1485-1490.
- Karatzas D. y col. Concurso ICDAR 2015 sobre lectura robusta // 13a Conferencia Internacional 2015 sobre Análisis y Reconocimiento de Documentos (ICDAR). - IEEE, 2015 .-- S. 1156-1160.
- Chee-Kheng Chng y col. al. ICDAR2019 Desafío de lectura robusta sobre texto en forma arbitraria (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 Desafío de lectura robusta en recibos escaneados OCR y extracción de información rrc.cvc.uab.es/?ch=13
- ShopSign: un conjunto de datos de texto de escenas diversas de carteles de tiendas chinas en Street Views [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai, Serge Belongie Detección de texto orientado en imágenes naturales mediante la vinculación de segmentos [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, Shuigeng Zhou Atención concentrada: hacia el reconocimiento preciso de texto en imágenes naturales [ arxiv: 1709.02054 ].