Buen día y mi respeto, lectores de Habr!
Antecedentes
En nuestro lugar, es costumbre intercambiar hallazgos interesantes en los equipos de desarrollo. En la próxima reunión, discutiendo el futuro de .NET y .NET 5 en particular, mis colegas y yo nos enfocamos en ver una plataforma unificada a partir de esta imagen:
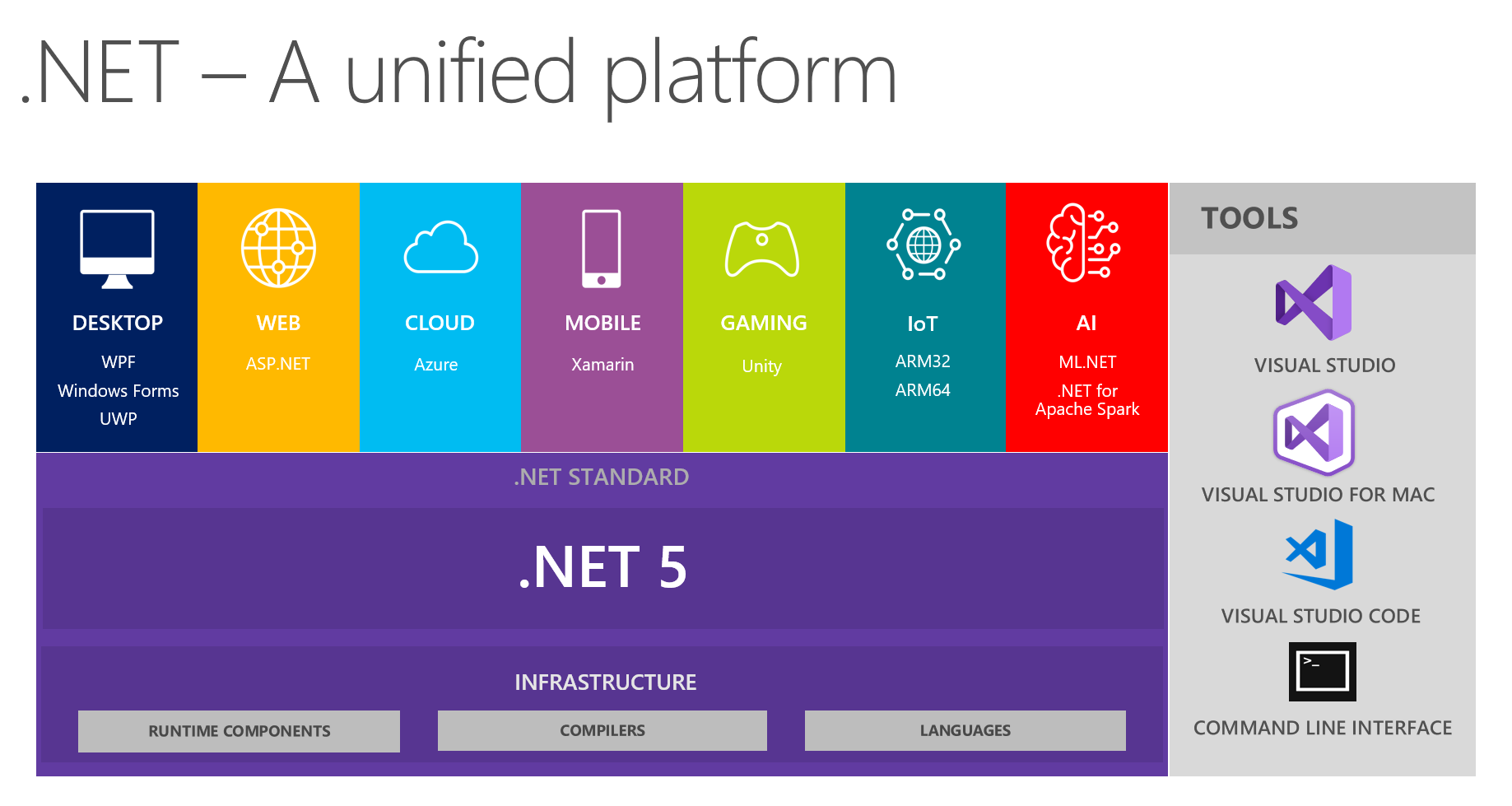
Muestra que la plataforma combina DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT e AI. Tuve la idea de mantener una conversación en forma de un pequeño informe + preguntas / respuestas sobre cada tema en las próximas reuniones. La persona responsable de un tema en particular se está preparando preliminarmente, leyendo información sobre las principales innovaciones, tratando de implementar algo usando la tecnología elegida y luego compartiendo sus pensamientos e impresiones con nosotros. Como resultado, todo el mundo recibe comentarios reales sobre las herramientas de una fuente confiable de primera mano: es muy conveniente, dado que intentar y asaltar todos los temas usted mismo puede no ser útil, sus manos no llegarán.
Como he estado interesado activamente en el aprendizaje automático como un pasatiempo durante algún tiempo (y a veces lo uso para tareas no comerciales en el trabajo), obtuve el tema de AI y ML.NET. En el proceso de preparación, me encontré con herramientas y materiales maravillosos, para mi sorpresa descubrí que hay muy poca información sobre ellos en Habré. Anteriormente en el blog oficial, Microsoft escribió sobre el lanzamiento de ML.Net y Model Builder en particular. Me gustaría compartir cómo llegué a él y qué impresiones obtuve al trabajar con él. El artículo trata más sobre Model Builder que ML en .NET en su conjunto; trataremos de ver lo que MS ofrece al desarrollador promedio de .NET, pero con los ojos de una persona experta en ML. Al mismo tiempo, intentaré mantener un equilibrio entre volver a contar el tutorial, masticar absolutamente para principiantes y describir los detalles para especialistas en ML, que por alguna razón tenían que venir a .NET.
Cuerpo principal
Entonces, un rápido google sobre ML en .NET me lleva a la página del tutorial :
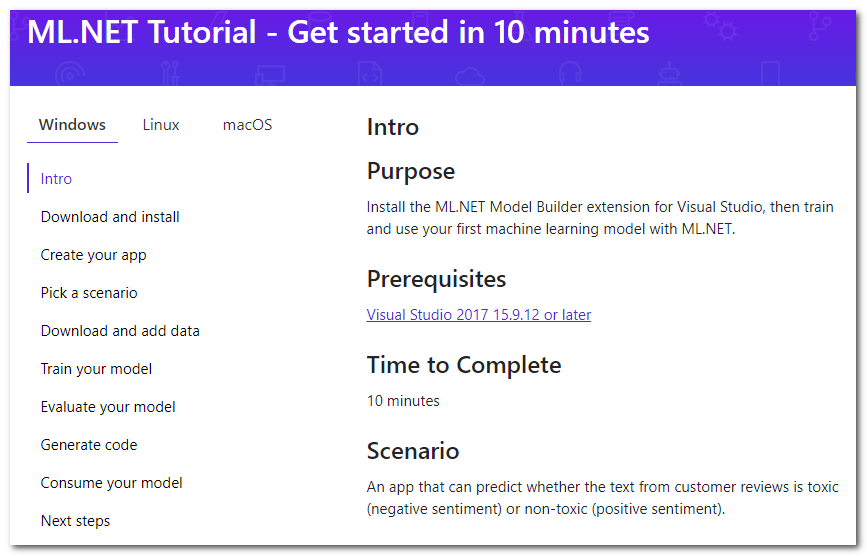
Resulta que hay una extensión especial para Visual Studio llamada Model Builder, que "le permite agregar aprendizaje automático a su proyecto con el botón derecho del mouse" (traducción gratuita). Revisaré brevemente los pasos principales del tutorial que se ofrecen para hacer, agregaré detalles y mis pensamientos.
Descargar e instalar
Presione el botón, descargue, instale. El estudio tendrá que reiniciar.
Crea tu aplicación
Primero, cree una aplicación C # normal. En el tutorial se propone crear Core, pero también se adapta al Framework. Y luego, de hecho, comienza ML: haga clic derecho en el proyecto, luego Agregar -> Aprendizaje automático. Se analizará la ventana que aparecerá para crear el modelo, porque es allí donde sucede toda la magia.
Elige un escenario
Seleccione el "script" de su aplicación. Por el momento, 5 están disponibles (el tutorial está un poco desactualizado, hay 4 hasta ahora):
- Análisis de sentimientos: análisis de tonalidad, clasificación binaria (clasificación binaria), el texto determina su color emocional, positivo o negativo.
- Clasificación de problemas: la clasificación multiclase, la etiqueta de destino para el problema (ticket, errores, llamadas de soporte, etc.) se puede seleccionar como una de las tres opciones mutuamente excluyentes
- Predicción de precios: regresión, el clásico problema de regresión cuando la salida es un número continuo; En el ejemplo, esta es una estimación de apartamento
- Clasificación de imágenes: clasificación multiclase, pero ya para imágenes
- Escenario personalizado: su escenario; Me veo obligado a lamentar que no haya nada nuevo en esta opción, solo en una etapa posterior me permitirán elegir una de las cuatro opciones descritas anteriormente.
Tenga en cuenta que no existe una clasificación de múltiples capas cuando el método de destino puede ser múltiple al mismo tiempo (por ejemplo, una declaración puede ser ofensiva, racista y obscena al mismo tiempo, y puede no ser nada de esto). Para las imágenes, no hay opción para seleccionar una tarea de segmentación. Supongo que con la ayuda del marco generalmente son solucionables, sin embargo, hoy nos centramos en el constructor. Parece que escalar el asistente para expandir el número de tareas no es una tarea difícil, por lo que debe esperarlas en el futuro.
Descargar y agregar datos
Se propone descargar el conjunto de datos. Debido a la necesidad de descargarlo en su máquina, concluimos automáticamente que la capacitación se llevará a cabo en nuestra máquina local. Esto tiene ambas ventajas:
- Usted controla todos los datos, puede corregirlos, cambiarlos localmente y repetir los experimentos.
- No sube datos a la nube, manteniendo así la privacidad. Después de todo, no subir, sí Microsoft ? :)
y contras:
- La velocidad de aprendizaje está limitada por los recursos de su máquina local.
Se propone además seleccionar el conjunto de datos descargado como una entrada del tipo "Archivo". También hay una opción para usar "SQL Server": deberá especificar los detalles necesarios del servidor y luego seleccionar la tabla. Si entiendo correctamente, todavía no es posible especificar un script específico. A continuación escribo sobre los problemas que tuve con esta opción.
Entrena tu modelo
En este paso, se entrenan varios modelos secuencialmente, se muestra la velocidad de cada uno y al final se selecciona el mejor. Ah, sí, olvidé mencionar que esto es AutoML, es decir El mejor algoritmo y parámetros (no estoy seguro, ver más abajo) se seleccionarán automáticamente, por lo que no necesita hacer nada. Se propone limitar el tiempo máximo de entrenamiento a la cantidad de segundos. Heurística para la definición de este tiempo: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . En mi máquina, en los 10 segundos predeterminados, solo un modelo aprende, así que tengo que apostar mucho más. Comenzamos, esperamos.
Aquí realmente quiero agregar que los nombres de los modelos personalmente me parecieron un poco inusuales, por ejemplo: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. La palabra "Perceptron" no se usa muy a menudo en estos días, "Ova" es probablemente uno contra todos, y "FastTree" me resulta difícil decir qué.
Otro hecho interesante es que LightGbmMulti se encuentra entre los algoritmos candidatos. Si entiendo correctamente, este es el mismo LightGBM, el motor de aumento de gradiente que, junto con CatBoost, ahora está compitiendo con la regla de XGBoost. Está un poco frustrado con su velocidad en el rendimiento actual: según mis datos, su entrenamiento tomó la mayor parte del tiempo (aproximadamente 180 segundos). Aunque la entrada es texto, después de vectorizar miles de columnas más que los ejemplos de entrada, este no es el mejor caso para impulsar y los árboles en general.
Evalúa tu modelo
En realidad, la evaluación de los resultados del modelo. En este paso, puede ver qué métricas objetivo se han logrado, así como conducir el modelo en vivo. Sobre las métricas en sí se pueden leer aquí: MS y sklearn .
Estaba principalmente interesado en la pregunta: ¿en qué se probó? Una búsqueda en la misma página de ayuda da una respuesta: la partición es muy conservadora, del 80% al 20%. No encontré la capacidad de configurar esto en la interfaz de usuario. En la práctica, me gustaría controlar esto, porque cuando realmente hay muchos datos, la partición puede ser incluso 99% y 1% (según Andrew Ng, yo mismo no trabajé con esos datos). También sería útil poder establecer un muestreo aleatorio de datos de semillas, porque la repetibilidad durante la construcción y selección del mejor modelo es difícil de sobreestimar. Parece que agregar estas opciones no es difícil, para mantener la transparencia y la simplicidad, puede ocultarlas detrás de algunas casillas de verificación de opciones adicionales.
En el proceso de construcción del modelo, las tabletas con indicadores de velocidad se muestran en la consola, cuyo código de generación se puede encontrar en los proyectos del siguiente paso. Podemos concluir que el código generado realmente funciona, y su salida honesta es salida, no falsa.
Una observación interesante: mientras escribía el artículo, una vez más seguí los pasos del constructor, usé el conjunto de datos propuesto de comentarios de Wikipedia. Pero como tarea elegí "Personalizado", luego una clasificación multiclase como objetivo (aunque solo hay dos clases). Como resultado, la velocidad resultó ser aproximadamente un 10% peor (aproximadamente 73% versus 83%) que la velocidad de la captura de pantalla con clasificación binaria. Para mí esto es un poco extraño, porque el sistema podría haber adivinado que solo hay dos clases. En principio, los clasificadores del tipo uno contra todos (uno contra todos, cuando el problema de clasificación multiclase se reduce a la solución secuencial de problemas N-binarios para cada una de las N clases) también deben mostrar una velocidad binaria similar en esta situación.
Generar código
En este paso, se generarán dos proyectos y se agregarán a la solución. Uno de ellos tiene un ejemplo completo del uso del modelo, y el otro solo debe observarse si los detalles de implementación son interesantes.
Por mí mismo, descubrí que todo el proceso de aprendizaje está formado de manera concisa en una tubería (hola a las disciplinas de sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(Toqué ligeramente el formato del código para que se ajuste bien)
¿Recuerdas que estaba hablando de los parámetros? No veo ningún parámetro personalizado, todos los valores predeterminados. Por cierto, usando la etiqueta SentimentText_tf en la salida de FeaturizeText podemos concluir que este es un término de frecuencia (la documentación dice que estos son n-gramos y char-gramos del texto; me pregunto si hay una IDF, frecuencia de documento inversa).
Consume tu modelo
En realidad, un ejemplo de uso. Solo puedo notar que Predict se realiza de manera elemental.
Bueno, eso es todo, en realidad: examinamos todos los pasos del constructor y notamos los puntos clave. Pero este artículo estaría incompleto sin una prueba de sus propios datos, porque cualquiera que haya encontrado ML y AutoML sabe muy bien que cualquier máquina es buena para tareas estándar, pruebas sintéticas y conjuntos de datos de Internet. Por lo tanto, se decidió verificar el constructor en sus tareas; en lo sucesivo siempre se trabaja con texto o texto + características categóricas.
No fue coincidencia que tuviera a mano un conjunto de datos con algunos errores / problemas / defectos registrados en uno de los proyectos. Tiene 2949 líneas, 8 clases objetivo desequilibradas, 4mb.
ML.NET (carga, conversiones, algoritmos de la lista a continuación; tomó 219 segundos)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(huecos punzantes en la placa para encajar en Markdown)
Mi versión de Python (carga, limpieza , conversión, luego LinearSVC; tardó 41 segundos):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0.80 vs 0.747 Micro y 0.73 vs 0.542 Macro (puede haber alguna imprecisión en la definición de Macro, si es interesante, se lo diré en los comentarios).
Estoy gratamente sorprendido, solo el 5% de la diferencia. En algunos otros conjuntos de datos, la diferencia era aún menor, y a veces no lo era en absoluto. Al analizar la magnitud de la diferencia, vale la pena tener en cuenta el hecho de que el número de muestras en los conjuntos de datos es pequeño y, a veces, después de la siguiente carga (se elimina algo, se agrega algo), observé movimientos de velocidad de 2-5 por ciento.
Mientras estaba experimentando por mi cuenta, no hubo problemas al usar el constructor. Sin embargo, durante la presentación, los colegas aún se encontraron con varias jambas:
- Intentamos cargar honestamente uno de los conjuntos de datos de la tabla en la base de datos, pero nos topamos con un mensaje de error poco informativo. Tenía una idea de qué tipo de plan estaban allí los datos de texto, e inmediatamente descubrí que el problema podría estar en los avances de línea. Bueno, descargué el conjunto de datos usando pandas.read_csv , lo limpié de \ n \ r \ t, lo guardé en tsv y seguí adelante.
- Durante el entrenamiento del siguiente modelo, recibieron una excepción informando que una matriz de tamaño ~ 220,000 por 1000 no puede caber cómodamente en la memoria, por lo que se detiene el entrenamiento. Al mismo tiempo, el modelo tampoco fue generado. Lo que hay que hacer a continuación no está claro; salimos de la situación sustituyendo el límite de tiempo de aprendizaje "a simple vista", de modo que el algoritmo de caída no tenga tiempo para comenzar a funcionar.
Por cierto, del segundo párrafo podemos concluir que el número de palabras y n-gramos durante la vectorización no está realmente limitado por el límite superior, y que "n" es probablemente igual a dos. Puedo decir por experiencia propia que 200k es claramente demasiado. Por lo general, se limita a las ocurrencias más frecuentes o se aplica sobre varios tipos de algoritmos de reducción dimensional, por ejemplo, SVD o PCA.
Conclusiones
El constructor ofrece una selección de varios escenarios en los que no encontré lugares críticos que requieren inmersión en ML. Desde este punto de vista, es perfecto como herramienta para "comenzar" o resolver problemas simples típicos aquí y ahora. Los casos de uso reales dependen totalmente de su imaginación. Puede elegir las opciones que ofrece MS:
- para resolver el problema de la evaluación de sentimientos (análisis de sentimientos), por ejemplo, en los comentarios sobre los productos en el sitio
- clasificar entradas por categorías o equipos (clasificación de problemas)
- seguir burlándose de los boletos, pero con la ayuda de la predicción de precios: calcule los costos de tiempo
Y puede agregar algo propio, por ejemplo, para automatizar la tarea de distribuir errores / incidentes entrantes entre desarrolladores, reduciéndolo a la tarea de clasificación por texto (etiqueta de destino - ID / Apellido del desarrollador). O puede complacer a los operadores de la estación de trabajo interna que completan los campos de la tarjeta con un conjunto fijo de valores (lista desplegable) para otros campos o descripción de texto. Para hacer esto, solo necesita preparar una selección en csv (incluso varios cientos de líneas son suficientes para los experimentos), enseñar el modelo directamente desde UI Visual Studio y aplicarlo en su proyecto copiando el código del ejemplo generado. Llevo al hecho de que ML.NET en mi opinión es bastante adecuado para resolver tareas prácticas, pragmáticas y mundanas que no requieren calificaciones especiales y en vano tiempo de comer. Además, se puede aplicar en el proyecto más común, que no pretende ser innovador. Cualquier desarrollador de .NET que esté listo para dominar una nueva biblioteca puede convertirse en el autor de dicho modelo.
Tengo un poco más de experiencia en ML que el desarrollador promedio de .NET, así que decidí por mí mismo: para imágenes, probablemente no, para casos complejos, pero para tareas de tabla simples, definitivamente sí. Por el momento, es más conveniente para mí hacer cualquier tarea de ML en la pila de tecnología Python / numpy / pandas / sk-learn / keras / pytorch más familiar, sin embargo, habría hecho un caso típico para incrustarlo más tarde en una aplicación .NET usando ML.NET .
Por cierto, es bueno que el marco de texto funcione perfectamente sin ningún gesto innecesario y sin necesidad de ajustes por parte del usuario. En general, esto no es sorprendente, porque en la práctica, en pequeñas cantidades de datos, los viejos TfIDF con clasificadores como SVC / NaiveBayes / LR funcionan bastante bien. Esto se discutió en el DataFest de verano en un informe de iPavlov: en algunos paquetes de pruebas se compararon word2vec, GloVe, ELMo (más o menos) y BERT con TfIdf. En la prueba, fue posible lograr la superioridad de un par de por ciento en solo un caso de 7-10 casos, aunque la cantidad de recursos gastados en capacitación no es comparable en absoluto.
PD: La popularización de ML entre las masas ahora está en tendencia, incluso tomando la " herramienta de Google para crear IA, que incluso un niño de escuela puede usar ". Todo es divertido e intuitivo para el usuario, pero lo que realmente está sucediendo detrás de escena en la nube no está claro. En esto, para los desarrolladores de .NET, ML.NET con un generador de modelos parece una opción más atractiva.
La presentación de PSS se disparó, los colegas estaban motivados para intentar :)
Retroalimentación
Por cierto, uno de los boletines con el título "ML.NET Model Builder" dijo:
Danos tu opinión
Si tiene algún problema, siente que falta algo o realmente ama algo sobre ML.NET Model Builder, infórmenos creando un problema en nuestro repositorio de GitHub.
Model Builder todavía está en Vista previa, y sus comentarios son muy importantes para conducir la dirección que tomamos con esta herramienta.
¡Este artículo puede considerarse un comentario!
Referencias
En ML.NET
A un artículo anterior con orientación